总览
本文指导您通过腾讯云 TI 平台的在线服务模块,使用开源推理镜像(vLLM 或 SGLang)部署自定义大模型推理服务。
准备模型
请先将需要部署的模型文件上传到自己的 CFS 文件存储系统中,推荐以下两种上传方式:
模型要从 Hugging Face 或 Model Scope 下载:通过 TIONE 的 训练工坊 > 开发机 模块挂载 CFS,安装 Hugging Face 或 Model Scope 的 SDK 并使用对应的下载命令下载模型。
部署在线服务
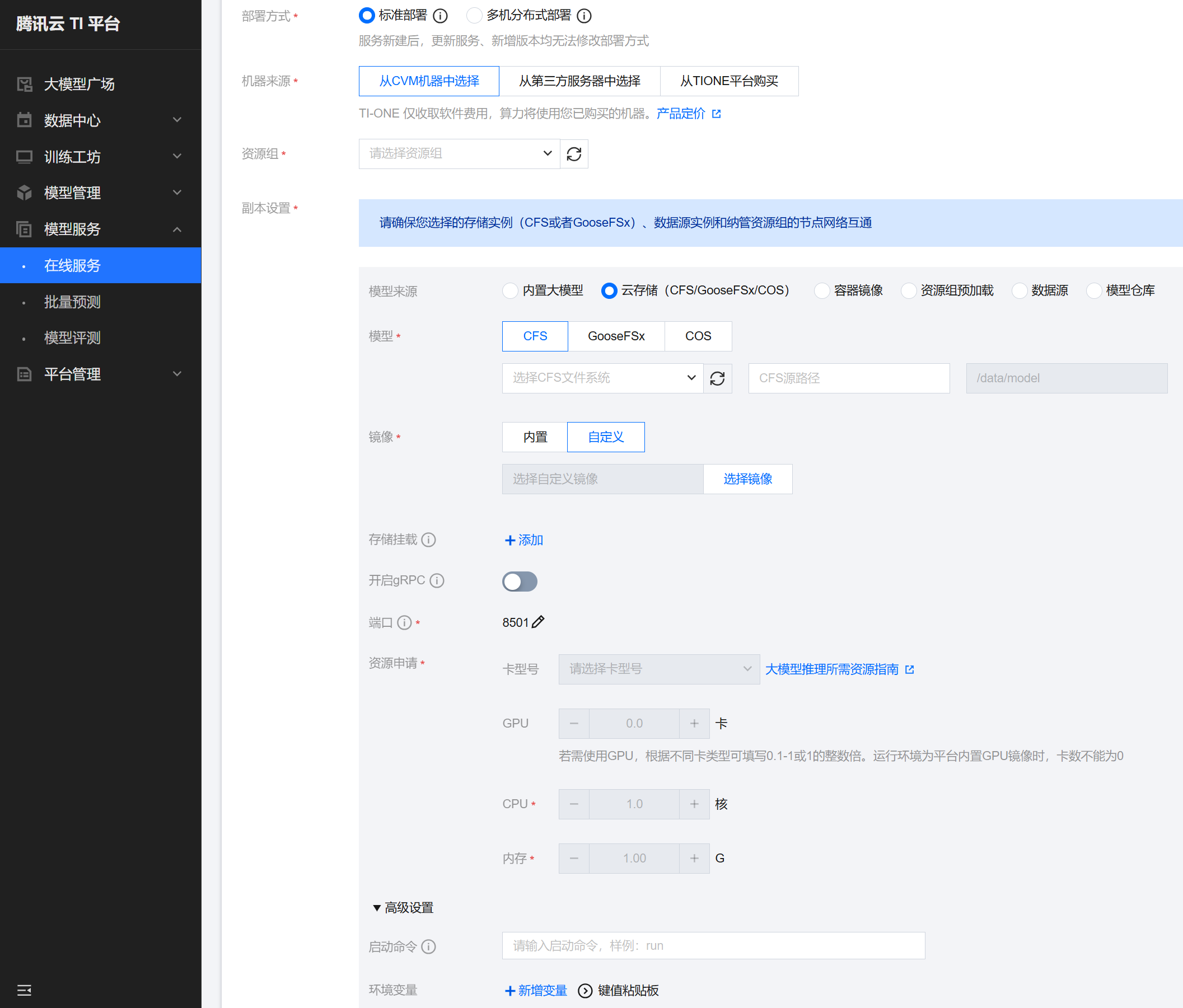
创建服务
部署方式:若模型单台机器的 GPU 即可部署,请选择标准部署;若模型非常大,需要至少2台机器才能部署,请选择多机分布式部署。
机器来源:按需选择,推荐从CVM机器中选择,并选择对应的资源组。
副本设置:
模型来源:选择云存储;若您想加速服务启动,且您资源组的 CVM 有足够的硬盘大小,可参考 文件预加载 将模型文件提前加载至机器硬盘,然后选择资源组预加载。
模型:若来源是 CFS,则选择模型在 CFS 上的文件路径。
镜像:选择自定义,在弹出的对话框中选择镜像地址,然后填写需要使用的镜像地址,具体指引参照 选择镜像。
存储挂载:可选,如果服务除了模型以外还需挂载其他数据路径等,则可以配置,一般不需要配置。
开启 gRPC:不勾选。
端口:推荐使用默认值 8501。
资源申请:按需配置需要的 GPU、CPU、内存资源,如果是多机分布式部署,请额外配置单个模型服务的资源实例数,如2个。
高级设置:配置启动命令,具体指引参照 启动命令。
选择镜像
您可以在 Docker Hub 检索可用的开源镜像版本:
vLLM
SGLang
比较推荐使用带版本号的稳定版本镜像部署模型,如 vllm/vllm-openai:v0.11.0,lmsysorg/sglang:v0.5.5。
某些较新的开源模型可能需要依赖开源框架的开发分支来部署,您也可以尝试使用 nightly 版本具体 commit 的镜像部署。
说明:
1. 为了加速拉取 Docker Hub 的镜像,在填写镜像地址时,可以添加 mirror.ccs.tencentyun.com 这个腾讯云镜像拉取代理前缀。例如:开源镜像地址为 vllm/vllm-openai:v0.11.0,则镜像地址填写 mirror.ccs.tencentyun.com/vllm/vllm-openai:v0.11.0。
2. 为了保证使用的镜像版本固定,不推荐使用类似 latest、dev、main、nightly 的 tag,这些不带版本号、commit号或日期的 tag 对应的镜像可能会频繁更新,可能会导致服务重启时实际镜像发生改变,从而可能引发不兼容问题。
3. 无论是开源镜像的稳定版本还是开发版本,都不可避免地可能存在 bug,建议您经过充分测试后再将推理服务接入生产。
启动命令
vLLM 框架
标准部署
基本启动命令如下:
vllm serve /data/model --port 8501 --host 0.0.0.0 --served-model-name $SERVED_MODEL_NAME -tp $TP
其中:
SERVED_MODEL_NAME:填写服务的模型名称,vLLM 默认会校验请求中的 model 字段是否和启动时设置的 --served-model-name 参数一致。
TP:若服务用多卡 TP 并行,填写服务所用的卡数。
多机分布式部署
vLLM 多机分布式部署时稍微复杂一些,需要先初始化 Ray 集群,再在 Ray 集群的 head 节点启动推理服务,基本启动命令如下:
if [ "$RANK" = "0" ]; then \\ray start --head --port 6700 --include-dashboard false --disable-usage-stats \\&& vllm serve /data/model --port 8501 --host 0.0.0.0 --served-model-name $SERVED_MODEL_NAME -tp $TP; \\else ray start --address $MASTER_ADDR:6700 --block; fi
其中:
SERVED_MODEL_NAME:填写服务的模型名称,vllm 默认会校验请求中的 model 字段是否和启动时设置的 --served-model-name 参数一致。
TP:若服务用多卡 TP 并行,填写服务所用的卡数,例如两机16卡 TP 并行,请填写16。
MASTER_ADDR、RANK:平台自动注入的多机分布式环境变量,这里无需修改。
说明:
vLLM 框架在 v0.11.0 版本调整了环境变量
VLLM_ALLREDUCE_USE_SYMM_MEM 的默认值为 1,这个会导致非整机使用多机分布式部署时 vLLM 获取显卡序号异常,可以设置环境变量 VLLM_ALLREDUCE_USE_SYMM_MEM=0 暂时规避。SGLang 框架
标准部署
基本启动命令如下:
python3 -m sglang.launch_server --model-path /data/model --host 0.0.0.0 --port 8501 --enable-metrics --tp $TP
其中:
--enable-metrics:SGLang 框架默认未开启监控指标上报,推荐开启以便平台可以采集服务的大模型监控指标。
TP:若服务用多卡 TP 并行,填写服务所用的卡数。
多机分布式部署
基本启动命令如下:
python3 -m sglang.launch_server --model-path /data/model --host 0.0.0.0 --port 8501 --enable-metrics --tp $TP \\--dist-init-addr $MASTER_ADDR:$MASTER_PORT --nnodes $WORLD_SIZE --node-rank $RANK
其中:
TP:若服务用多卡 TP 并行,填写服务所用的卡数,例如两机16卡 TP 并行,请填写16。
MASTER_ADDR、MASTER_PORT、WORLD_SIZE、RANK:平台自动注入的多机分布式环境变量,这里无需修改。
常见问题
当使用的 GPU 卡数小于 1 卡时,开源 vLLM 镜像启动报错 CUDA Out of Memory?
当 GPU 配置为小于 1 卡时,会自动开启 qGPU 功能,该功能当前暂不兼容 CUDA 版本高于 12.2。因此如果 vllm 镜像的 CUDA 版本高于 12.2,会导致显存 profiling 阶段统计异常,然后 CUDA OOM 退出。需要使用 cuda-compat-12-2 来降级容器中的 CUDA runtime 版本才可正常使用 qGPU 能力。可以按如下指引修改启动命令:
wget "https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-compat-12-2_535.216.01-0ubuntu1_amd64.deb" \\&& dpkg -i cuda-compat-12-2_535.216.01-0ubuntu1_amd64.deb \\&& export LD_LIBRARY_PATH=/usr/local/cuda-12.2/compat:$LD_LIBRARY_PATH \\&& vllm serve ...
其中若由于网络问题 cuda-compat 包下载失败,推荐您先下载好并上传到自己的 COS 中,并在启动时从 COS 下载。也可以传到 CFS 中作为额外存储挂载。
GPU 显存是放得下模型权重的,但是还是启动时报错 CUDA Out of Memory?
大模型推理的显存占用除了模型权重本身以外,KV Cache 还会占用比较多的显存,这块显存与配置的上下文长度有关系。一些开源模型默认的上下文长度比较长(如 256K、1M),实际很多场景不需要用到那么大上下文,那么可以在启动时调小上下文长度,启动命令示例如下:
# vllmvllm serve ... --max-model-len 16384# sglangpython3 -m sglang.launch_server ... --context-length 16384
从 CFS 加载模型权重的过程很慢,如何加速?
当前开源框架默认的模型权重加载逻辑是根据模型在本地存储优化的,但是针对类似 NFS 的网络文件存储(如CFS通用标准型),这种加载方式效率比较低。我们可以调整权重加载模式来优化速度,但是可能会增加内存占用,建议容器分配的内存大于或等于显存。
vLLM 框架从 v0.10.2 版本开始支持 safetensors-load-strategy 参数
SGLang 框架从 v0.5.1 版本开始支持 weight-loader-disable-mmap 参数
启动命令参考:
# vllmvllm serve ... --safetensors-load-strategy eager# sglangpython3 -m sglang.launch_server ... --weight-loader-disable-mmap
此外,若服务可能频繁更新或重启,推荐使用平台的文件预加载功能进一步加速模型权重加载,这种方式属于本地存储加载,无需额外配置参数。



