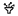功能介绍
多角色部署(PD 分离)
多角色部署(PD 分离)是 TI-ONE 平台在线服务面向大模型推理场景的高级部署模式,支持用户将推理流程拆分为多个角色,如 Prefill(预填充)、Decode(解码)、Proxy(代理)等独立角色,每个角色拥有独立容器配置、实例列表、监控、日志、扩缩容能力,解决传统混部资源利用率低、时延波动大问题。
PD 分离部署中三个默认角色的核心作用如下:
默认角色 | 核心作用 |
Prefill(预填充角色) | 主要负责处理用户输入文本的预处理与编码工作,将输入的自然语言转换为模型可识别的 Token 序列,并完成注意力机制的预计算,为后续解码过程奠定基础,是大模型推理的前置核心环节,直接影响首 Token 输出时延。 |
Decode(解码角色) | 承接 Prefill 角色的处理结果,按照自回归生成逻辑,逐一生成输出 Token,是决定模型响应流畅度的关键角色,其性能直接影响非首 Token 时延、输出速率等核心体验指标,适合配置高显存、高算力资源。 |
Proxy(代理角色) | 作为服务流量的入口角色,负责接收用户调用请求、分发请求至对应 Prefill/Decode 角色实例、汇总处理结果并返回给用户,同时承担请求限流、负载均衡、链路转发等管控职责,保障多角色协同运行的稳定性与高效性。 |
适合多角色部署(PD 分离)的业务场景有:
大语言模型高并发推理(长文本、高吞吐、低时延的要求)。
Prefill 与 Decode 各角色的资源需求差异大(算力型/显存型异构调度)。
需要独立扩缩容、独立排查问题的生产级服务。
内置大模型 GLM-5-FP8
大模型广场内置了 GLM-5 系列大模型,旨在应对复杂系统工程和长周期智能体任务;其中平台还为 GLM-5-FP8 模型提供了专用于 PD 分离部署的腾讯自研 TACO 推理加速镜像。TACO 镜像采用全异步设计,在推理性能、显存占用、启动耗时等方面显著优于社区方案。用户使用多角色部署方式部署内置的 GLM-5-FP8 大模型时,平台会默认填充 Proxy、Prefill、Decode 角色需要的推理镜像及其最佳实践的启动命令、环境变量等超参配置。
前置要求
GLM-5-FP8 是智谱 AI 开源的大型稀疏混合专家(MoE)模型的 FP8 量化版本,在此架构下,模型的专家并行计算需要依赖 DeepEP 通信库(DeepSeek 开源的高性能 MoE 通信组件)来实现跨服务器高速数据交换。为确保 DeepEP 在您的集群环境中正常运行,请联系腾讯云工程师 协助进行必要的节点驱动更新与重启操作,以完成环境适配。
操作步骤
步骤一:创建服务
1. 登录 TI-ONE 控制台,在左侧菜单栏选择模型服务 > 在线服务。
2. 在在线服务列表页,单击新建服务,完成新建服务的参数配置。新建表单主要分为以下几类参数:
基础信息
参数名称 | 参数说明 |
服务名称 | 自定义服务名称,需符合命名规则(不超过60个字符,仅支持中英文、数字、下划线"_"、短横"-",只能以中英文、数字开头)。 |
服务版本 | 服务版本号,平台默认生成,不支持用户修改。 |
服务描述 | 选填,填写服务描述信息,不超过500个字。 |
地域 | 默认展示用户当前所在地域,不可修改,服务按地域隔离。 |
网关配置&部署方式&机器来源
参数名称 | 参数说明 |
网关类型 | 平台默认提供公共网关,支持用户自定义选择“负载均衡调度算法”,您可根据业务场景自定义选择。 轮询:将所有请求依次分发到服务中的每个实例。 一致性哈希:基于 Header 信息进行负载均衡,确保携带相同信息的请求可固定访问部署中的同一个实例。 |
部署方式 | 此处,用户选择“多角色部署(PD 分离)”模式。请注意服务新建后,更新服务、新增版本均无法修改部署方式。 |
机器来源 | 按用户实际情况选择部署服务的机器来源,推荐使用 HCCPNV6 机型进行部署。 |
副本设置 - 模型配置
多角色部署的“副本设置”部分分为模型和角色两个配置维度,“模型配置”是按服务的维度进行配置,多角色间的模型配置是一致的;“角色配置”是按角色的维度单独配置,不同角色可以配置不同的镜像、资源、高级参数等。
参数名称 | 参数说明 |
模型来源 | 内置大模型:目前仅支持 GLM-5-FP8,针对平台内置支持 PD 分离部署的大模型,“角色配置”部分会自动填充角色信息、推理镜像及启动命令/环境变量等高级参数。 云存储、容器镜像、资源组预加载、数据源:可配置用户自定义的模型文件或镜像地址 此最佳实践中我们选择内置大模型“GLM-5 系列模型 / GLM-5-FP8”。  |
存储挂载 | 当用户选择的模型来源是云存储、容器镜像、资源组预加载、数据源时,还支持用户自定义配置额外的存储挂载,用于模型之外的数据、配置等文件。当用户选择的模型来源是内置大模型时,不需要配置存储挂载参数。 |
端口 | 当用户选择的模型来源是云存储、容器镜像、资源组预加载、数据源时,支持用户自定义修改容器端口。当用户选择的模型来源是内置大模型时,不支持用户自定义端口号。 |
副本设置 - 角色配置
当用户选择内置大模型“GLM-5 系列模型 / GLM-5-FP8”进行 PD 分离部署时,“角色配置”部分平台会默认填充角色、镜像、启动命令、环境变量参数。
参数名称 | 参数说明 |
角色管理 | 新增角色:默认提供 proxy、prefill、decode 三种角色,也支持用户单击“添加角色  编辑角色:针对已选中的角色,单击“设置  删除角色:支持删除不需要的角色(注意:删除角色会清除该角色的已有配置内容)。 流量入口:为服务指定流量入口角色  |
镜像 | 支持用户自定义配置每个角色的镜像,镜像支持“内置/自定义”两种来源。针对 GLM-5-FP8 内置大模型 PD 分离部署,平台会默认选中腾讯自研的 TACO 推理加速镜像,首字延迟(TTFT)加速2倍以上,包间延迟(TPOT)提速5倍以上。 |
资源申请 | 针对每个角色独立配置部署资源。不同角色的资源需求可能不同,请根据角色的实际负载情况合理配置。针对 GLM-5-FP8 内置大模型建议使用 HCCPNV6 机型,该机型的 CPU 和内存可尽量用满(例如单副本配置 300C2000G),预留 8c32g 给 proxy 角色即可。推荐实例数配置:prefill 4个实例,decode 2个实例;最少实例数配置:prefill 2个实例,decode 2个实例。 |
副本调节 | |
高级设置 | 注意:对于多角色部署,滚动更新是针对每个角色独立进行的,不会跨角色互相影响。 针对 GLM-5-FP8 内置大模型 PD 分离部署,平台会默认填充适合 TACO 推理加速镜像的高级参数设置,用户无需修改即可一键部署。 |
完成上述所有配置后,单击启动服务,平台将根据配置为每个角色创建独立的实例容器。
说明:
服务启动过程可能需要一定时间,请耐心等待。
步骤二:服务管理
待服务成功部署后,服务状态会更新为“运行中”。

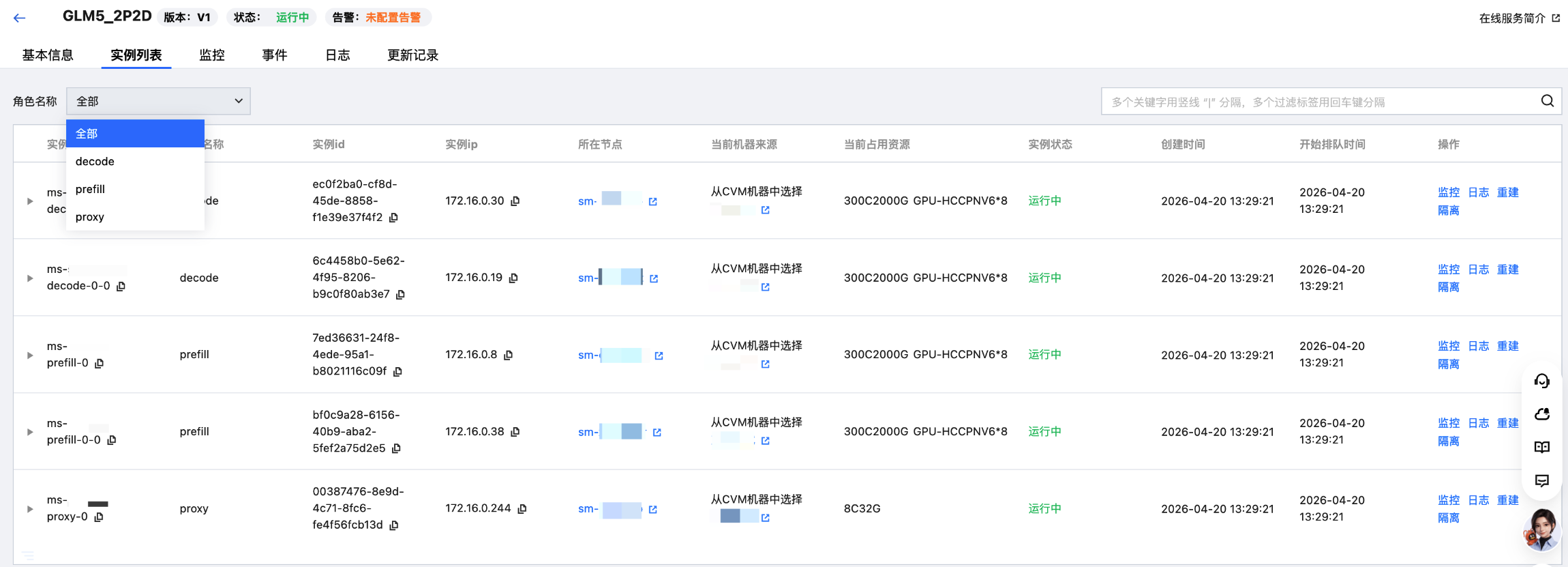
1. 单击服务名称进入服务详情页面,在服务管理 Tab 页面可以看到该服务下的多个角色列表,按照角色的维度展示“运行/期望副本数量”、“单副本实例数量”、“当前占用资源”、“更新时间”等信息。
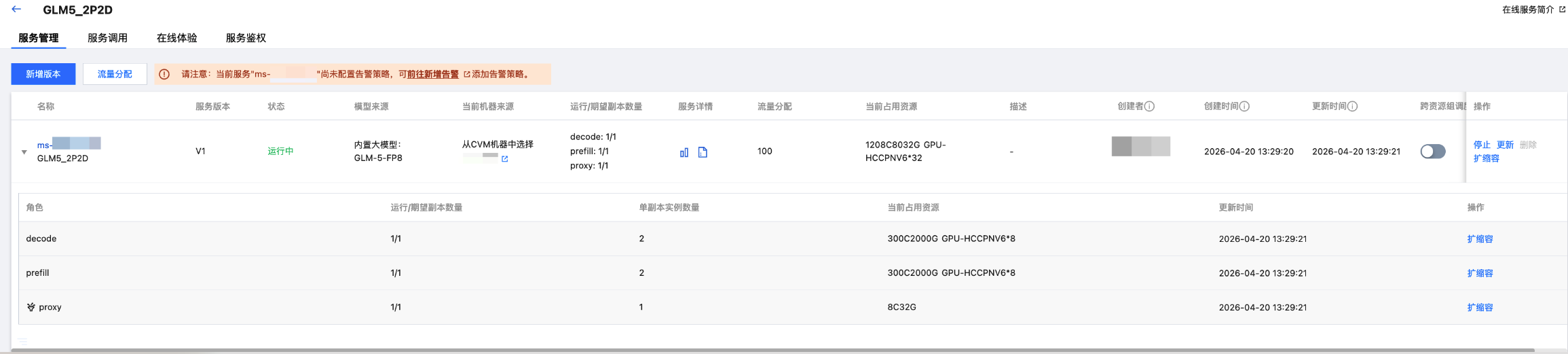
针对多角色部署的服务,同时支持服务维度和角色维度的扩缩容配置:
服务维度支持同时对多个角色一起进行扩缩容。
角色维度支持单独配置扩缩容,单个角色的扩缩容不会影响其他角色。
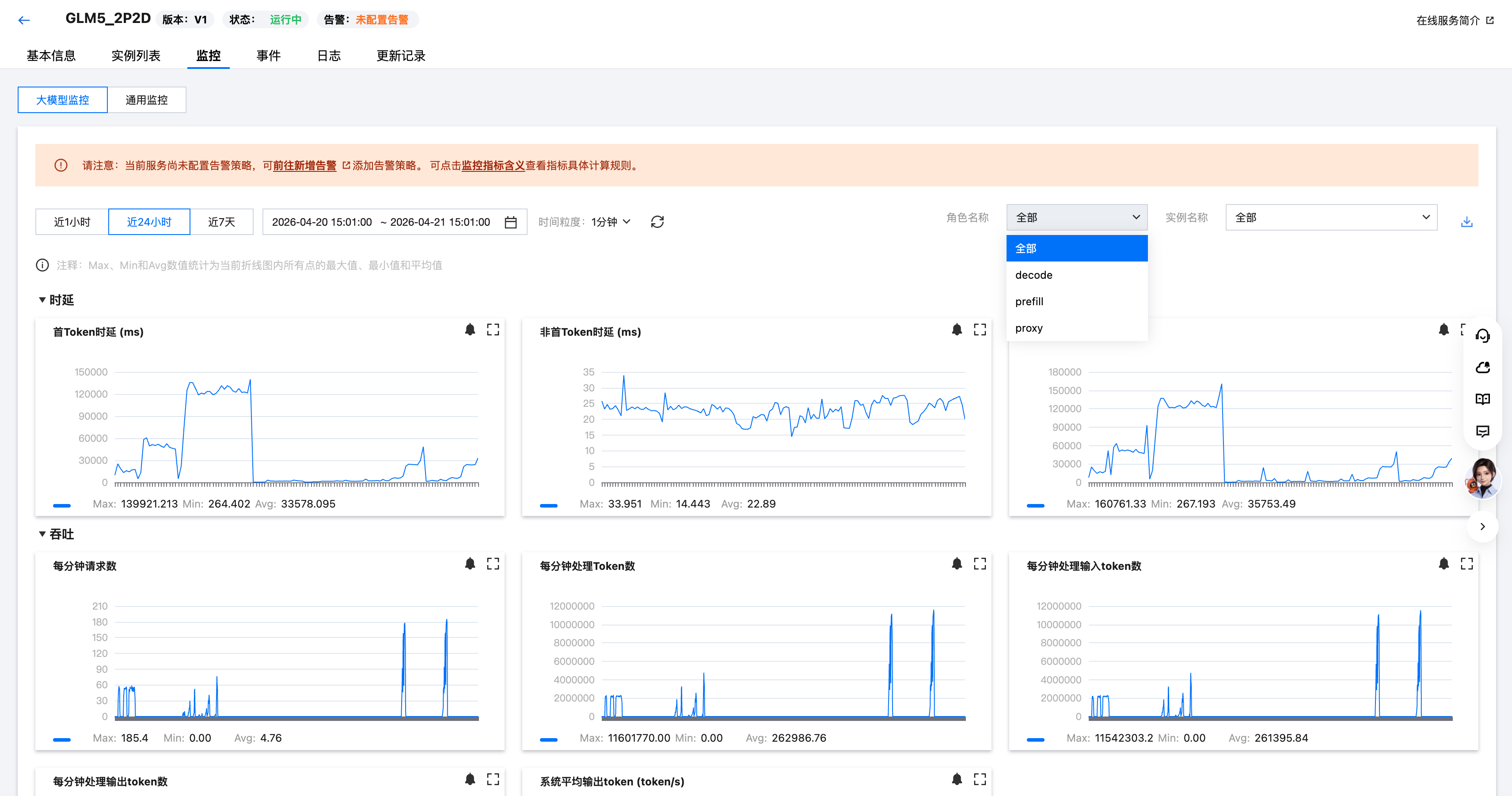
2. 单击服务管理列表页的服务名称,进入服务版本的详情页面:实例列表、监控、事件、日志、更新记录信息均支持用户按角色维度筛选查看。
实例监控信息:
步骤三:服务调用
1. 在在线服务列表页,单击服务名称进入服务详情页。
2. 在服务调用 Tab 页可查看调用地址。TI-ONE 平台提供了多种服务调用模式(详情请参考 在线服务调用)。
针对多角色部署的服务,会统一由流量入口的角色承担请求流量(流量入口标识是