冒充人类作者,ChatGPT等滥用引担忧,一文综述AI生成文本检测方法
冒充人类作者,ChatGPT等滥用引担忧,一文综述AI生成文本检测方法

机器之心专栏
作者:唐瑞祥(莱斯大学)
大型语言模型(LLM)的出现导致其生成的文本非常复杂,几乎与人类编写的文本难以区分。本文旨在提供现有大型语言模型生成文本检测技术的概述,并加强对语言生成模型的控制和管理。
自然语言生成 (NLG) 技术的最新进展显着提高了大型语言模型生成文本的多样性、控制力和质量。一个值得注意的例子是 OpenAI 的 ChatGPT,它在回答问题、撰写电子邮件、论文和代码等任务中展示了卓越的性能。然而,这种新发现的高效生成文本的能力也引起了人们对检测和防止大型语言模型在网络钓鱼、虚假信息 和学术造假等任务中滥用的担忧。例如,由于担心学生利用 ChatGPT 写作业,纽约公立学校全面禁止了 ChatGPT 的使用,媒体也对大型语言模型产生的假新闻发出警告。这些对大型语言模型 滥用的担忧严重阻碍了自然语言生成在媒体和教育等重要领域的应用。
最近关于是否可以正确检测大型语言模型生成的文本以及如何检测的讨论越来越多,这篇文章对现有检测方法进行了全面的技术介绍。

- 论文地址:https://github.com/datamllab/The-Science-of-LLM-generated-Text-Detection
- 相关研究地址:https://github.com/datamllab/awsome-LLM-generated-text-detection/tree/main
现有的方法大致可分为两类:黑盒检测和白盒检测。
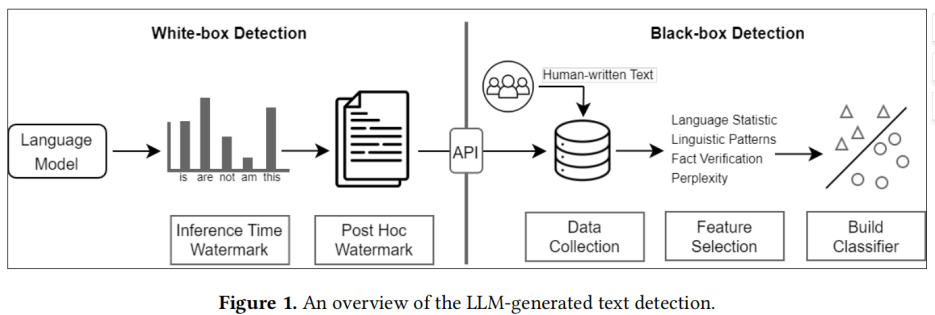
大型语言模型生成文本检测概述
- 黑盒检测方法对大型语言模型通常只有 API 级别的访问权限。因此,这类方法依靠于收集人类和机器的文本样本来训练分类模型;
- 白盒检测,这类方法拥有对大型语言模型的所有访问权限,并且可以通过控制模型的生成行为或者在生成文本中加入水印(watermark)来对生成文本进行追踪和检测。
在实践中,黑盒检测器通常由第三方构建,例如 GPTZero,而白盒检测器通常由大型语言模型开发人员构建。
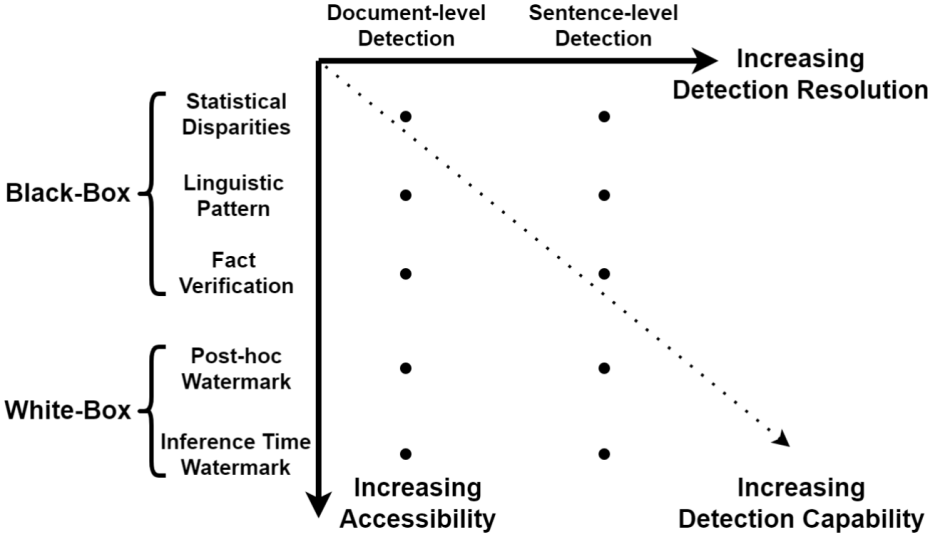
大型语言模型生成的文本检测分类学
黑盒检测
黑盒检测一般有三个步骤,分别是数据收集,特征选择和模型建立。
对于人类文本的收集,一种方法是招募专业人员进行数据采集,但是这种方法费时费力,不适于大型数据集的收集,更加高效的方法是利用现有的人类文本数据,比如从维基百科上收集各种专家编辑的词条,或者是从媒体上收集数据,例如 Reddit。
特征的选取一般分为统计特征,语言特征和事实特征。其中统计特征一般是用来检查大型语言模型生成文本是否在一些常用的文本统计指标上于人类文本不同,常用的有 TFIDF、齐夫定律等。语言特征一般是找一些语言学特征,比如词性,依存分析,情感分析等。最后,大型语言模型常常会生成一些反事实的言论,因此事实验证也可以提供一些区分大型语言模型生成文本的信息。
现有的分类模型一般分为传统的机器学习模型,例如 SVM 等。最新的研究倾向于利用语言模型来做主干, 例如 BERT,RoBERTa, 并且取得了更高的检测表现。

这两种文本之间有明显的不同。human-written 文本来自 Chalkbeat New York。
白盒检测
白盒检测一般默认是大型语言模型开发人员提供的检测。不同于黑盒检测,白盒检测对模型拥有完全访问权力, 因此能通过改变模型的输出来植入水印,以此达到检测的目的。
目前的检测方法可以分为 post-hoc 水印和 inference time 水印:
- 其中 post-hoc 水印是在大型语言模型生成完文本后,再在文本中加入一些隐藏的信息用于之后的检测;
- Inference time 水印则是改变大型语言模型对 token 的采样机制来加入水印,在大型语言模型生成每一个 token 的过程中,其会根据所有 token 的概率和预设的采样策略来选择下一个生成的词,这个选择的过程就可以加入水印。

Inference time 水印
作者担忧
(1)对于黑盒模型,数据的收集是非常关键的一步,但是这个过程非常容易引入偏见(biases)。例如现有的数据集主要集中在问答,故事生成几个任务,这就引入了主题的偏见。此外,大模型生成的文本经常会出现固定的风格或者格式。这些偏见常常会被黑盒分类器作为分类的主要特征而降低了检测的鲁棒性。
随着大型语言模型能力的提升,大型语言模型生成的文本和人类的差距会越来越小,导致黑盒模型的检测准确性越来越低,因此白盒检测是未来更有前景的检测方式。
(2)现有的检测方法默认大型语言模型是被公司所有,因而所有的用户都是通过 API 来获得公司的大型语言模型服务,这种多对一的关系非常有利用检测系统的部署。但是如果公司开源了大型语言模型,这将导致现有的检测方法几乎全部失效。
对于黑盒检测,因为用户可以微调他们的模型,改变模型输出的风格或者格式,从而导致黑盒检测无法找到通用的检测特征。
白盒检测可能是一个解决办法,公司在开源模型之前可以给模型中加入一个水印。但是用户同样可以通过微调模型,改变模型 token 的采样机制来移除水印。现在还没有一种水印技术能够抵御用户的这些潜在攻击。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com