ECCV 2022 | MixSKD: 用于图像识别的Mixup自蒸馏方法
ECCV 2022 | MixSKD: 用于图像识别的Mixup自蒸馏方法


来源:PaperWeekly
本文约1800字,建议阅读5分钟
本篇文章介绍一下我们于 ECCV-2022 发表的一篇模型自蒸馏文章。
传统的知识蒸馏(Knowledge Distillation,KD)需要一个预训练的教师模型来训练一个学生模型,这种模式的缺点是需要设计并训练额外的教师网络,并且两阶段的训练过程提升了流水线开销。自网络知识蒸馏(Self-Knowledge Distillation,Self-KD),顾名思义,则是不依赖额外的教师网络进行指导,利用网络自身的知识来指导自身的学习,从而实现自我提升。
由于 Self-KD 没有额外的高性能教师模型进行指导,通常性能提升十分有限。最近,我们提出了一种从 Mixup 图像 [1] 中进行 Self-KD 的方法 MixSKD,该方法通过从混合图像中挖掘知识,从而提升了模型图像识别效果,进一步在目标检测和语义分割的下游任务上也表明提出的 MixSKD 能使得 backbone 网络学习到更好的特征。

论文链接:https://arxiv.org/pdf/2208.05768.pdf
代码链接:https://github.com/winycg/Self-KD-Lib*Codebase 中集成了 20 余种流行的 Self-KD 和数据增强方法在图像识别任务上的实现。
01 引言
由于没有额外的教师模型,现有的 Self-KD 工作通常使用辅助结构或者数据增强的方式来捕捉到额外的知识,从而指导自身的学习。基于辅助结构的方法 [2] 通常利用添加的分支来学习主任务,Self-KD 引导辅助分支和主干网络之间进行知识迁移。基于数据增强的方法 [3] 通常在输入端创建来自相同实例的两个不同增强的视角,Self-KD 约束两个视角具有一致的输出。先前 Self-KD 方法的一个共同点是生成的软标签是都是来源于单独的输入样本的。
本文提出将混合图像 Mixup 和 Self-KD 融合为一个联合的框架,名为 MixSKD。MixSKD 整体的思想如图 1 所示。给定两张输入图像 和 ,可以分别得到概率分布 和 ,之后进行线性插值可得到集成的软标签 ,之后将 与 Mixup 图像得到的概率分布进行相互蒸馏。
直觉上,集成的软标签 包含了原始两张图像的预测信息,可以被认为是一个伪教师分布来提供综合的知识。基于 Mixup 的概率分布可以被认为是一个数据增强分布来微调 ,从而学习鲁棒的混合预测和避免过拟合。
除了在最终输出的概率层面,MixSKD 还在中间特征层对插值特征和 Mixup 特征进行互蒸馏。MixSKD 引导网络针对输入图像()及其插值的 Mixup 图像之间产生一致的输出信息,从而使得网络具有线性决策行为。
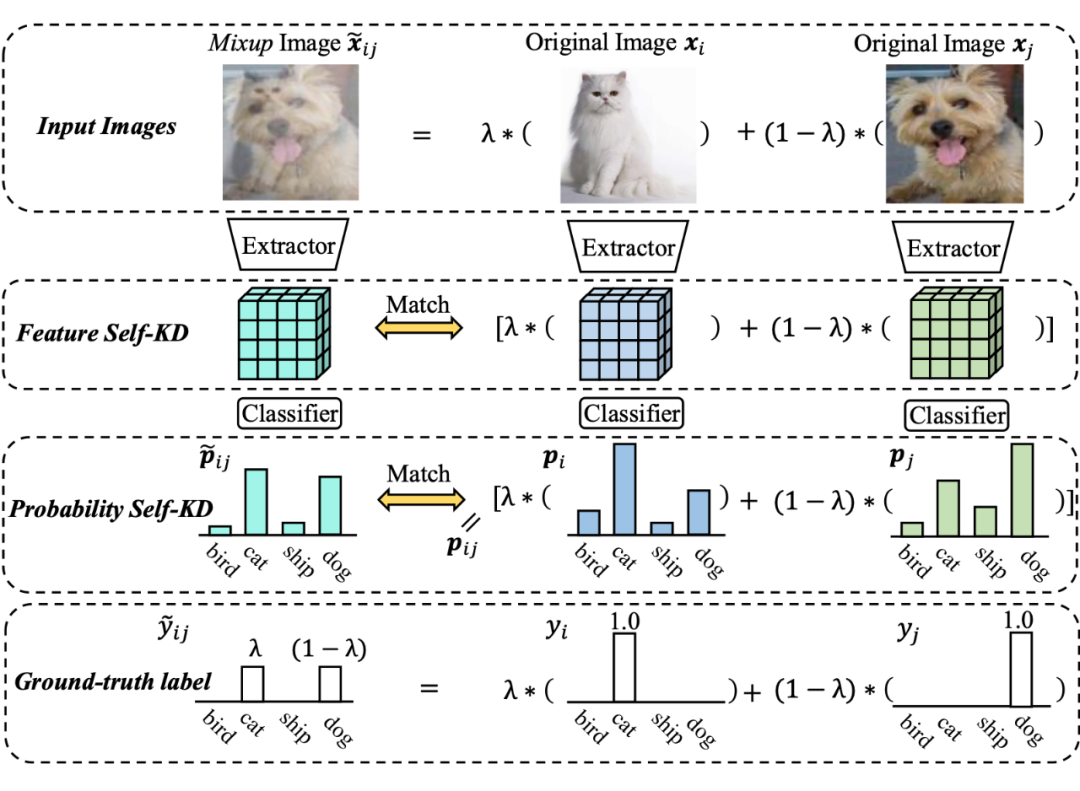
图1. MixSKD的基本思想
02 方法
2.1 任务引导的分类误差
来自结构源的误差:使用原始的交叉熵任务误差来训练主网络 f 和 K-1 个辅助分支,使之获得分类能力和产生语义特征:
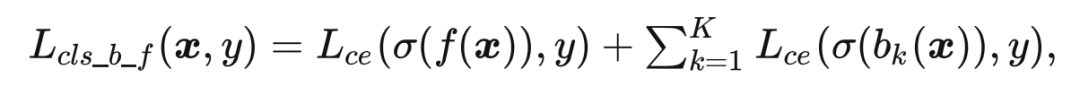
来自数据源的误差:给定输入图像 和 Mixup 图像 ,代入结构源的误差,可以得到任务误差:
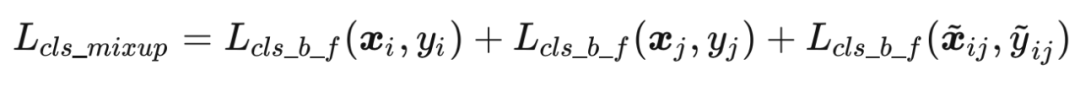
2.2 特征图Self-KD
使用 L2 距离来逼近原始图像插值得到的特征图与 Mixup 图像生成的特征图:
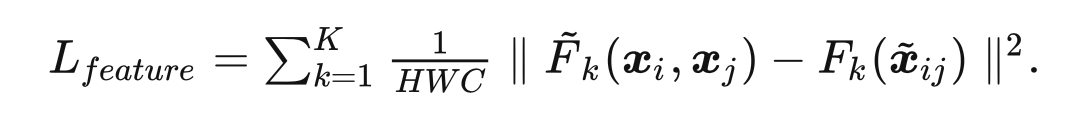
受对抗学习思想的启发,本文引入了一个判别器来判别特征来源于插值还是 Mixup 图像来提升特征逼近的难度,从而使得网络能够学习到有效的语义特征:
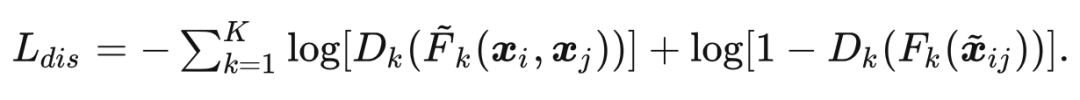
2.3 概率分布Self-KD
本方法使用 KL 散度去逼近原始图像插值得到的概率分布与 Mixup 图像产生的概率。在 K-1 辅助分支上使用如下的误差:
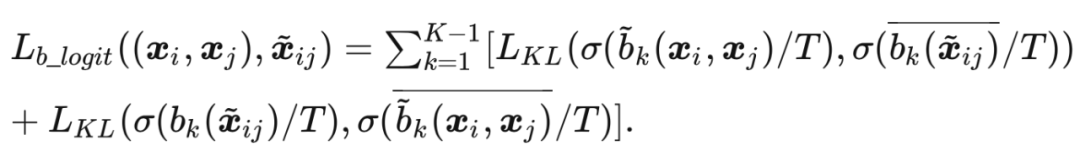
对于最终的主干网络,本方法进一步构造了一个 self-teacher 网络来提供高质量的软标签作为监督信号。self-teacher 网络聚合网络中间层的特征,然后通过一个线性分类器输出类别概率分布,受到 Mixup 插值标签的监督:
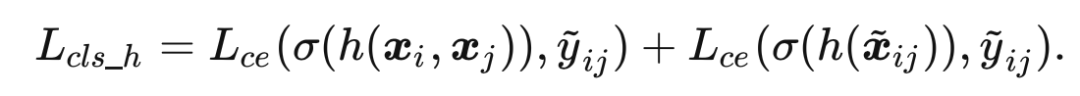
主干网络最终输出的类别概率分布的监督信号来源于 self-teacher 网络:
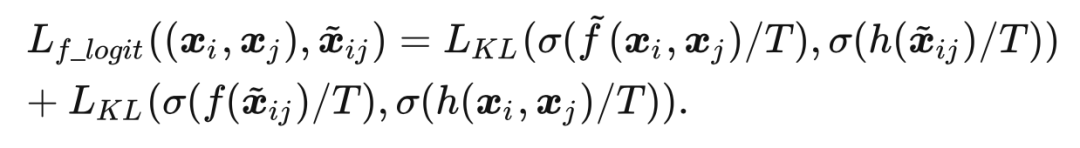
2.4 整体误差
将上述误差联合起来作为一个整体误差进行端到端的优化:
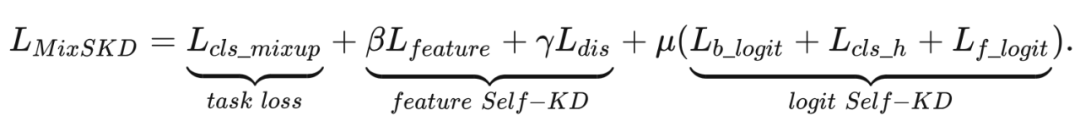
MixSKD 的整体示意图如图 2 所示。本方法引导网络在隐层特征和概率分布空间具有线性决策行为。从 Occam 剃刀原理上讲,线性是一个最直接的行为,因此是一个较好的归纳偏置。此外,线性行为可以在预测离群点时减少震荡。
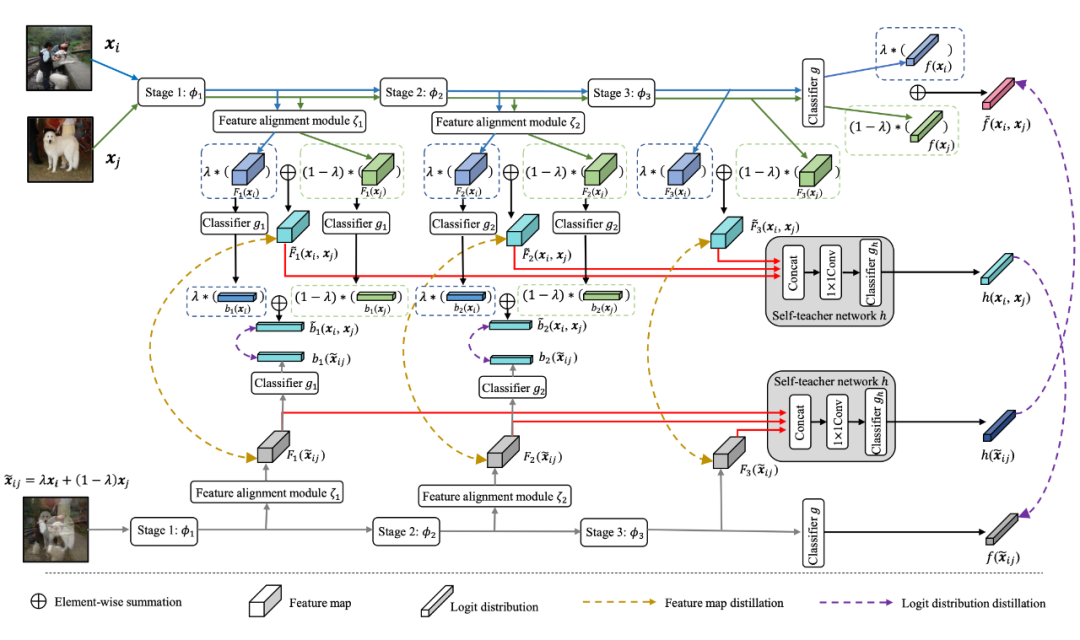
图2. MixSKD整体示意图
03 实验结果
1. MixSKD 用于 CIFAR-100 图像识别,如表 1 所示。MixSKD 在不同网络结构上超越了先前的 Self-KD 与数据增强方法
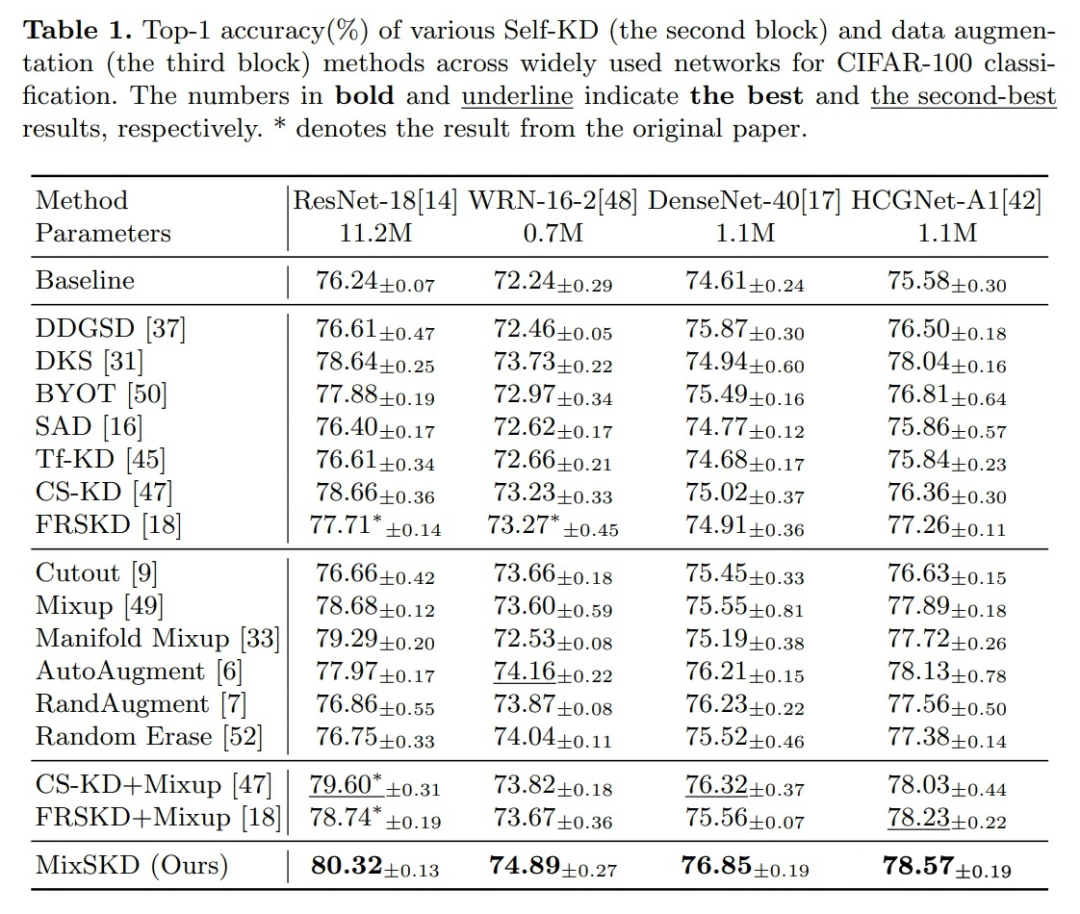
表1. CIFAR-100实验结果
2. 如表 2 所示,MixSKD 用于大规模 ImageNet 图像识别并用于下游的目标检测和语义分割, 获得了最佳的表现。
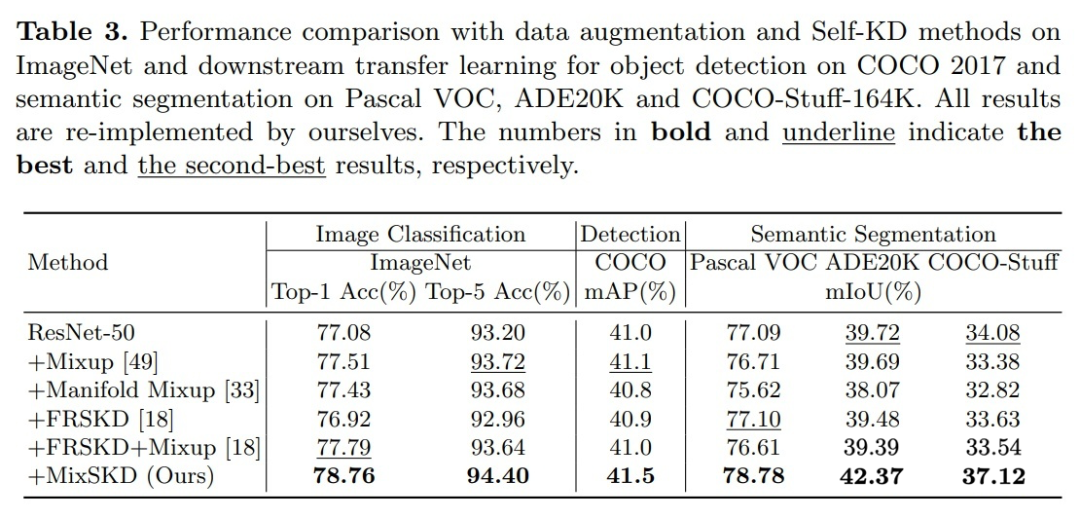
表2. ImageNet分类以及下游检测和分割实验结果
3. 从左边两张图可以看出,MixSKD 相比 baseline 具有更好的预测质量。对于公共分类错误的样本,MixSKD 在错误类别概率上值更小,在正确类别概率上值更大。从第三张图上可以看出,在不同混合系数的混合图像下,MixSKD 相比 Mixup 具有更低的错误率。
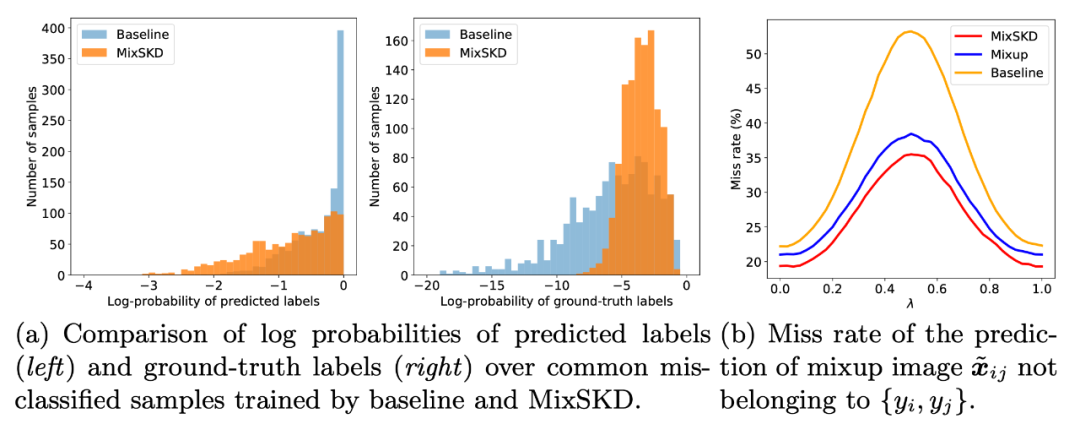
图3. MixSKD预测结果的定量分析
参考文献 [1] Zhang et al. Mixup: beyond empirical risk minimization. ICLR-2018.
[2] Zhang et al. Be your own teacher: Improve the performance of convolutional neural networks via self distillation. ICCV-2019.
[3] Xu et al. Data-distortion guided self-distillation for deep neural networks. AAAI-2019.
编辑:王菁
校对:杨学俊
