模拟实现stack && queue/dequeue/适配器/优先级队列/仿函数

模拟实现stack && queue/dequeue/适配器/优先级队列/仿函数

二肥是只大懒蓝猫
发布于 2023-03-30 14:38:56
发布于 2023-03-30 14:38:56
⭐前言:学习C++的STL,我们不仅仅要要求自己能够熟练地使用上层语法,我们还必须要求自己了解其底层原理,不需要了解得太深入,但一定得知道我们写出的各种代码后面,究竟采用了哪种设计思想,为什么要这样设计,有什么好处?这将会帮助我们打下坚实地C++基础,不再是只会表面语法的伪高手!
适配器,也就是适配器模式,它跟迭代器模式一样,属于设计模式(设计模式是一套被反复使用的、多数人知晓的、经过分类编目的、代码设计经验的总结)的一种,该种模式是将一个类的接口转换成客户希望的另外一个接口。就好比插座的适配器一样。
适配器模式:用现有的东西封装转换出我们想要的东西 迭代器模式:通过封装从而不暴露底层细节,在上层的中按照统一的方式进行使用。
使用适配器模式模拟实现stack
数据结构中的栈,可以通过顺序表,也能通过链表实现,不过大多数情况,都会使用顺序表来实现,但是在STL中,不管哪种方法,我们都可以兼顾,那就是通过类模板即可。
实现stack,很简单,我们只需将vector或list作为适配器,利用适配器里面的接口进行封装转换就能完成stack的模拟实现。
首先先写出基本的框架。对于T,是stack使用的类型,而Container是适配器,就是我们想要stack是适配器是vector还是list,就传进去。而Container的缺省值是deque<T>。
#include<vector>
#include<list>
namespace my_Stack {
template<class T,class Container = deque<T>>
class stack
{
public:
private:
Container _con;
};
}接下来就好办了,复用适配器中的接口,实现在栈顶入,栈顶出,取栈顶元素,获取元素个数,判空等待。
①在栈顶插入数据:
void push(const T& x)
{
_con.push_back(x);
}②在栈顶出数据:
void pop()
{
_con.pop_back();
}③获取栈顶元素:
T& top()
{
return _con.back();
}④判空
bool empty()
{
return _con.empty();⑤获取元素个数
size_t size()
{
return _con.size();
}我们不需要写析构函数,构造函数,拷贝构造函数等待,因为成员函数的类型是适配器推演出来的类型,它会去调用自己本身的构造函数和析构函数!
使用适配器模式模拟实现queue
要实现queue,跟实现stack一样!简单得很。数据结构中的队列,可以通过顺序表,也能通过链表实现,不过大多数情况,都会使用链表来实现,一样地,我们可以通过类模板来兼顾各种情况。
#include<vector>
#include<list>
namespace my_Queue {
template<class T,class Container = deque<T>>
class queue
{
public:
private:
Container _con;
};
}跟stack不一样的,无非就是对头出数据,队尾入数据,然后是可以取队头和队尾的数据。
①队尾入:
void push(const T& x)
{
_con.push_back(x);
}②队头出:
void pop()
{
_con.pop_front();
}③取队头或队尾数据:
const T& front()//取队头数据
{
return _con.front();
}
const T& back()//取队尾数据
{
return _con.back();
}了解deque
我们可以发现不管是stack还是queue,它们的适配器的缺省值是deque。使用deque的原因是有以下:
①stack理想的适配器是vector,而vector的缺点是扩容消耗,不支持头插头删和中间插入,因为这样效率很低。 ②queue理想的适配器是vector,而list的缺点是不能随机访问。
对于deque,可以兼具vector和list的优点,解决掉缺点。
deque(双端队列):是一种双开口的"连续"空间的数据结构,双开口的含义是:可以在头尾两端进行插入和删除操作,且时间复杂度为O(1),与vector比较,头插效率高,不需要搬移元素;与list比较,空间利用率比较高。

deque并不是真正连续的空间,而是由一段段连续的小空间拼接而成的,实际deque类似于一个动态的二维数组,其底层结构如下图所示:

双端队列底层是一段假象的连续空间,实际是分段连续的,为了维护其“整体连续”以及随机访问的假象,落在了deque的迭代器身上,其设计结构如下:
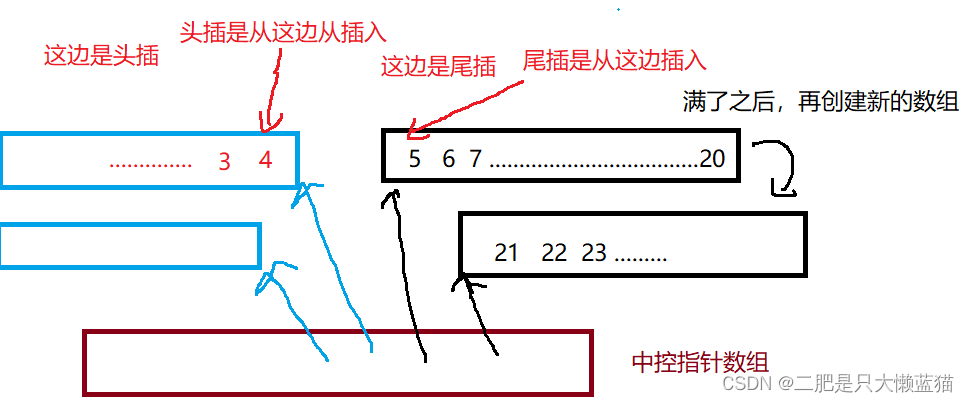
从图中我们可以知道,头插尾插的时候,不需要挪动数据。而随机访问,比如每个数组的容量为10,我们要找20,那么就先计算出20是在第几个数组中(用20/10 = 2),然后再算出在这个数组的哪里(找到是在第二个数组后,再20%10 = 0,在第0个下标上)。
deque的缺陷
①与vector比较,deque的优势是:头部插入和删除时,不需要搬移元素,效率特别高,而且在扩容时,也不需要搬移大量的元素,因此其效率是比vector高的,但是在中间位置插入,也依然效率低,需要挪动数据。 ②与list比较,其底层是连续空间,空间利用率比较高,不需要存储额外字段。 ③但是,deque有一个致命缺陷:不适合遍历,因为在遍历时,deque的迭代器要频繁的去检测其是否移动到某段小空间的边界,导致效率低下,而序列式场景中,可能需要经常遍历,因此在实际中,需要线性结构时,大多数情况下优先考虑vector和list,deque的应用并不多,而目前能看到的一个应用就是,STL用其作为stack和queue的底层数据结构。
选择deque作为stack和queue的底层默认适配容器的原因:
stack是一种后进先出的特殊线性数据结构,因此只要具有push_back()和pop_back()操作的线性结构,都可以作为stack的底层容器,比如vector和list都可以;queue是先进先出的特殊线性数据结构,只要具有push_back和pop_front操作的线性结构,都可以作为queue的底层容器,比如list。但是STL中对stack和queue默认选择deque作为其底层容器,主要是因为:
①stack和queue不需要遍历(因此stack和queue没有迭代器),只需要在固定的一端或者两端进行操作。 ②在stack中元素增长时,deque比vector的效率高(扩容时不需要搬移大量数据);queue中的元素增长时,deque不仅效率高,而且内存使用率高
仿函数
仿函数是一个类,它的对象叫做函数对象。函数对象可以像函数一样去使用。仿函数的类要求重载一个函数:operator()()
下面就来实现一下,priority_queue中的仿函数:less和greater。
namespace my_functor
{
template<class T>
class less
{
public:
bool operator()(const T& x, const T& y)
{
return x < y;
}
};
template<class T>
class greater
{
public:
bool operator()(const T& x, const T& y)
{
return x > y;
}
};
}
int main()
{
my_functor::less<int> lessFunc;
//这样调用起来,看起来lessFunc是一个函数,但其实它是一个对象
//因此,类less叫做仿函数,lessFunc叫做函数对象
lessFunc(1, 2);
return 0;
}仿函数的好处
还记得冒泡排序吗,在C语言中,一般情况下,我们写的排序算法,一般都是写死的,即只能用于降序,或用于升序,但这样显示不好,那么有没有办法让冒泡排序可以灵活点呢?站在上层的角度,每次调用冒泡排序的时候,我们可以多传一个参数进去,这个参数可以改变冒泡排序的排序形式!这时候,仿函数闪亮登场!
template <class T,class Compare>//添加泛型和仿函数
void BubbleSort(T* a, int n,Compare com)//多添加一个函数对象
{
for (int j = 0; j < n; ++j)
{
int exchage = 0;
for (int i = 1; i < n - j; ++i)
{
//if (a[a[i] < a[i-1])
if(com(a[i-1] , a[i])//不需要写死,排序方式交给函数对象即可!
{
swap(a[i - 1], a[i]);
exchage = 1;
}
}
if (exchage == 0)
{
break;
}
}
}此时调用的时候,就应该是这样的:
要升序是吧,简单!
int a[] = { 6,2,5,4,8,9,3,1,7 };
my_functor::less<int> lessFunc;
BubbleSort(a, sizeof(a) / sizeof(int), lessFunc);//有名对象
BubbleSort(a, sizeof(a) / sizeof(int), my_functor::less<int>());//匿名对象要降序是吧,好说!
my_functor::greater<int> greaterFunc;
BubbleSort(a, sizeof(a) / sizeof(int), greaterFunc);总的来说仿函数的好处就是,可以将函数改造成函数对象,有了这个函数对象,我们可以把它写进类模板里面,为代码程序添加更多功能。
优先级队列priority_queue
优先级队列不是队列,它跟普通的队列不一样,普通的队列是先进先出,但是优先级队列是具有优先级的数据先出。因此优先级队列本质上就是一个堆,它是一种容器适配器(用vector来适配),根据严格的弱排序标准,它的第一个元素总是它所包含的元素中最大的(即默认是大的数据优先级高,大堆)。
模拟实现优先级队列priority_queueq
优先级队列是一个堆,因此其核心是会建堆,以及调整堆排序。关于堆排序的相关知识,已经在二叉树的这篇文章中有了。二叉树----堆排序。因此这里就不再进行解析。
需要说明的是:因为我们在建堆的时候,可能会需要用到它的迭代器区间构造,因此需要实现一下,这就导致我们需要写一个无参构造,但这个无参构造并不需要写任何东西,因为适配器的对象会调用自己的初始化列表。
需要注意的是,根据文档:优先级队列中less表示的是大堆,即升序,greater表示的小堆,即降序。

namespace my_priority_queue
{
//less类,仿函数
template<class T>
class less
{
public:
bool operator()(const T& x, const T& y)
{
return x < y;
}
};
//greater类仿函数
template<class T>
class greater
{
public:
bool operator()(const T& x, const T& y)
{
return x > y;
}
};
template<class T,class Container = vector<T>,class Compare = less<T>>
class priority_queue
{
public:
//迭代器区间构造,不需要实现迭代器
template<class InputIterator>
priority_queue(InputIterator first,InputIterator last)
:_con(first,last)//调用vector或其它适配器的迭代器区间构造
{
//建堆,采用向下调整比较好
for (int i = (_con.size() - 2) / 2; i >= 0; --i)
{
adjust_down(i);
}
}
//无参构造,会去调用适配器的初始化列表
priority_queue()
{}
//向下调整
void adjust_up(size_t child)
{
Compare com;
size_t parent = (child - 1) / 2;
while (child > 0)
{
//less-->x < y -->parent < child 默认大堆
if(com(_con[parent],_con[child]))
{
swap(_con[child], _con[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
//向上调整
void adjust_down(size_t parent)
{
Compare com;
size_t child = parent * 2 + 1;
while (child < _con.size())
{
//默认左孩子大于右孩子 less-->x < y -->child < child+1
if (child + 1 < _con.size() && com(_con[child] , _con[child + 1]))
{
child++;
}
//less-- > x < y-->child < parent
if (com(_con[parent] , _con[child]))
{
swap(_con[parent], _con[child]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
//插入数据
void push(const T& x)
{
_con.push_back(x);
//向上调整
adjust_up(_con.size() - 1);
}
//将堆顶元素pop掉
void pop()
{
swap(_con[0], _con[_con.size() - 1]);
_con.pop_back();
//向下调整
adjust_down(0);
}
//取堆顶元素
const T& top() const
{
return _con[0];
}
bool empty()
{
return _con.empty();
}
size_t size() const
{
return _con.size();
}
private:
Container _con;
};
}本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2023-01-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号