中国造不出chatGPT是因为互联网大厂割据造成的数据孤岛?
中国造不出chatGPT是因为互联网大厂割据造成的数据孤岛?

引
前段时间部分科技界、科学界的大佬签署了一份倡议书,呼吁停止AGI的研发6个月。直到我们能够确保:
- 能够理解AI
- 能够真正限定AI的边界
- 甚至是必要的时候可以阻断AI
关于这个倡议,我个人认为是非常有必要的。它告诉了我们,这不是危言耸听,也并非杞人忧天,历史已经在我们打开潘多拉魔盒的时候进入了新的篇章。
但在这个事情上面我身边的大多数人,基本都秉承了我们一直以来的文化习惯,喜欢面对着历史,背对未来地去观察问题。在一个重大历史时刻面前,大多数时候我们会选择从历史的角度出发,尝试去找出一个类似的历史事件去进行类比。比如说:以前也曾经发生过多次工业革命,最终不都证明人类会适应科技带来的变化吗?
如果说,我们能够足够了解我们所发明的东西,比如蒸汽机、比如电、比如互联网。我们知道它们的工作原理,能够妥善控制它们。那么我们面对的就是人类社会内部分工大洗牌的问题。
但现在这波AI革命并非如此,我们在不了解现有模型是怎么从一个单字填词的、基于所学习内容概率分布的、用于预测下一个字的循环预测系统,是如何衍生出推理能力的,乃至成为图灵完备并在智慧上超过人类的智能体之前,我们不该过多地强调它为社会带来的价值,要强行推进。
因为,没有AI的情况下,人类文明已经好好地发展了7000多年。我们不差这6个月。就像是史前人类,不巧在村子旁发现了一个冒黑色石油的天然油井,石油可以让火把得以点燃,火源为村民带来了便利。但现在有人要把村子旁这整个油井都点燃,显然风险大于收益。
不过今天我们的目的并不是讨论要不要停止,因为猜疑链已经形成,我们已经回不去了。

而形成猜疑链的原因可能就真的这么搞笑:Guess who's not goona stop: China
对,中国一定会造出自己的chatGPT,而且不会停下来,会集中资源向前奔跑,力争如同新能源汽车一样,实现AI革命时代的弯道超车。
所以,我们今天主要是驳斥一个非常可笑的观点,就是有人说:中国造不出chatGPT是因为互联网大厂割据造成的数据孤岛
1
chatGPT的训练,需要海量的优质互联网数据
我们很早之前就在说,数据,将是这个时代的石油。我们人类在复杂社会中做出有效、精准决策的前提是拥有足够帮助我们做出做出决策的数据。对于AI模型来说,这个论断同样成立。
特别是数据必须要大到一定程度,才可能导致推理结构在神经网络里突然自发涌现的现象。
去年十月份 Google 的一篇论文 Emergent Abilities of Large Language Models 对这个现象做了很好的综述。简单地说:量变导致质变。
那么,我们看看chatGPT需要多少数据?
具体的数据我们不知道,但至少GPT3是有据可查的:45TB的数据。

这个数据算是海量吗?对于由机器产生的数据来说,这并非海量,很多互联网大厂服务器一天产生的日志量就远大于这个数。
所以,前提是优质。也就是数据中要包含的语义关系、语法规律、以及大量的语言表达范例,这部分数据的来源会主要来自于互联网。
从GPT-3的训练数据,我们就可以看到60%来自于网络爬虫爬取的通用互联网数据中提取出的文字部分。以及22%来自原一些问答网站,比如Reddit、Stack overflow的3星以上的帖子。最后才是电子书和维基百科。
而chatGPT能够支持多种语言的理解,我们从语言的角度看数据的分布,GPT-3其用于训练的中文语料并不是特别多:
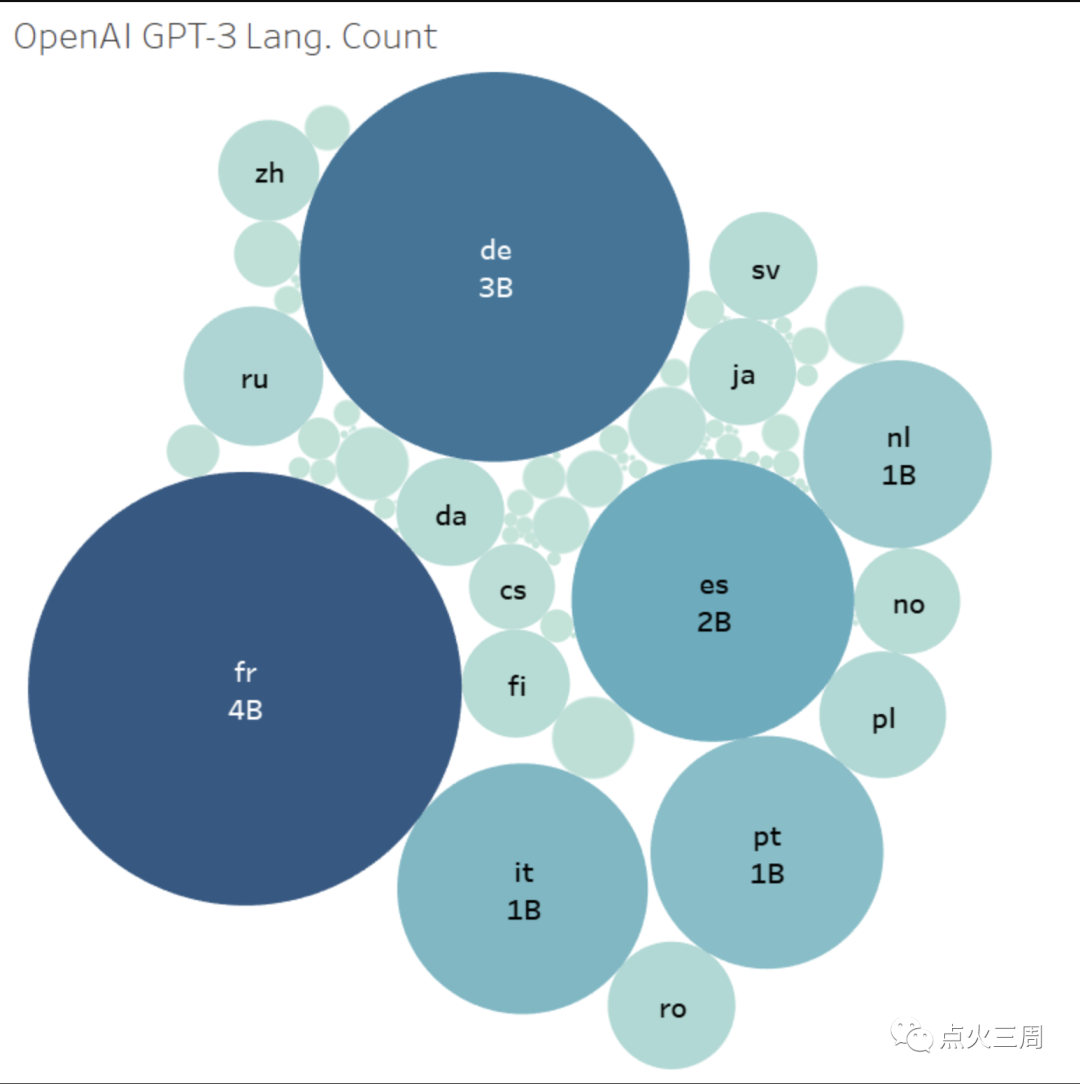
也就是说,从整个45的TB的数据总集上看, 肉眼估计,这部分中文数据甚至还不到1个TB。
那我们在使用chatGPT的时候有感觉中文的理解不流畅,chatGPT不能理解你吗?显然,并没有,GPT-4甚至能够为你解答什么叫做“小镇做题家”、“电摇嘲讽”、“鸡你太美”等网络流行词。
而从实际的测试看,GPT-4在Mandarin(普通话)上的理解准确度,虽然和英语有差异。但实际上差距并不大。并且,我们完全可以通过加一道翻译任务的方式,完成跟chatGPT的对话

所以,要训练出中国的、能够弯道超车chatGPT的模型需要的数据多吗? 可能会很多。
但我们能获得这么多数据吗?
这个答案显然是能。
2
“缺乏数据”的伪命题
其实细想我们就能明白,互联网大厂目前构造的App生态,数据获取和互通的所谓护城河,并不是一个阻碍我们弯道超车的关键点。
连OpenAI都能够找到足够的数据来训练GPT-5。我们有什么理由做不到呢?
中美作为世界上最大的两个互联网大国,两国拥有最多的互联网分享数据和UGC数据。
而OpenAI所有的数据都是在国外互联网生态上通过爬虫获取的,虽然听起来有点无耻,但这就意味着,我们也可以以同样的方式获得同样的数据。而国内App内的数据则是OpenAI无法获取的。
在中国的这部分数据,会成为我们的优势。在国家意志面前,即使存在数据孤岛问题,但这并不意味着所有数据都不能被访问。很多企业和研究机构可以通过合作、分享和整合资源的方式解决这个问题。
3
中国超车的可能性
人们往往喜欢从表面去进行推导。
就像特斯拉刚推出,开始引领电车未来的时候,就有人说:为什么中国造不出特斯拉来?
那时,如果你说5年后,中国会实现新能源汽车的弯道超车,估计你会被周围的悲观者的口水淹死。
但现在回过头来看,中国在新能源汽车领域确实实现了一定程度的弯道超车。这得益于政府的大力支持、庞大的市场需求、技术创新和完整的产业链等因素。
现在,许多中国新能源汽车品牌已经在国际市场上崭露头角,赢得了消费者的认可。
这这些打法,完全可以在人工智能领域重做一遍。
实际上,中国在人工智能领域具有强大的研发能力和市场潜力。
首先,中国的人工智能领域拥有众多优秀的科研人员和企业,他们在很多方面都取得了显著的成果。此外,中国庞大的互联网用户和数据资源为人工智能技术的发展提供了宝贵的原材料。
其次,政府可以制定一系列政策措施,如提供研发资金支持、税收优惠等,以鼓励企业和研究机构投入人工智能领域的研究和开发。
再者,促进数据资源整合:解决数据孤岛问题,推动数据资源的整合和共享。充分利用现有数据资源,为人工智能产品提供丰富的训练数据。
因此,尽管中国的移动互联网环境存在一定挑战,但这并不意味着中国无法发展出类似ChatGPT的人工智能产品。
❶它缺乏有效互动,ChatGPT可以持续对话。 ❷它重视考试成绩,ChatGPT重视实践技能。 ❸它一味灌输知识,ChatGPT培养提问能力。 ❹它轻视创造力,ChatGPT鼓励发挥创造力。 ❺它忽略个性化,ChatGPT提供个性化教育。