ChatGPT 和 Elasticsearch的结合:在私域数据上使用ChatGPT
原创ChatGPT 和 Elasticsearch的结合:在私域数据上使用ChatGPT
原创

如何结合 Elasticsearch 的搜索相关性和 OpenAI 的 ChatGPT 的问答功能来查询您的数据?在此博客中,您将了解如何使用 Elasticsearch 将 ChatGPT 连接到专有数据存储,并为您的数据构建问答功能。

什么是ChatGPT?
近几个月来,人们对 ChatGPT 充满了热情,这是一种由 OpenAI 创建的开创性人工智能模型。但 ChatGPT 到底是什么?
基于强大的 GPT 架构,ChatGPT 旨在理解文本输入并生成类似人类的响应。GPT 代表“生成式预训练Transformer(Generative Pre-trained Transformer)”。Transformer 是一种尖端模型架构,彻底改变了自然语言处理 (NLP) 领域。这些模型在海量数据上进行了预训练,能够理解上下文、生成相关响应,甚至进行对话. 要了解更多关于 transformer 模型的历史和 Elastic Stack 中的一些 NLP 基础知识,请务必查看很棒的Elastic ML 工程师 Josh Devins 的演讲。
ChatGPT 的主要目标是促进人机之间有意义且引人入胜的交互。通过利用 NLP 的最新进展,ChatGPT 模型可以提供广泛的应用程序,从聊天机器人和虚拟助手到内容生成、代码完成等等。这些人工智能驱动的工具已迅速成为无数行业的宝贵资源,帮助企业简化流程并增强服务。
然而,尽管 ChatGPT 具有不可思议的潜力,但用户仍应注意某些限制。一个值得注意的限制是知识截止日期。目前,ChatGPT 接受的数据训练截至 2021 年 9 月,这意味着它不知道此后发生的事件、发展或变化。因此,用户在依赖 ChatGPT 获取最新信息时应牢记这一限制。在讨论快速变化的知识领域(例如软件增强和功能甚至世界大事)时,这可能会导致反应过时或不正确。
ChatGPT 虽然是一种令人印象深刻的 AI 语言模型,但偶尔会在其响应中产生幻觉,当它无法访问相关信息时通常会加剧这种情况。这种过度自信会导致向用户提供不正确的答案或误导性信息。重要的是要意识到这一限制,并在必要时以一定程度的怀疑态度、交叉检查和验证信息来处理 ChatGPT 生成的响应,以确保准确性和可靠性。
ChatGPT 的另一个限制是它缺乏关于特定领域内容的知识。虽然它可以根据接受过培训的信息生成连贯且与上下文相关的响应,但它无法访问特定领域的数据或提供依赖于用户独特知识库的个性化答案。例如,它可能无法深入了解组织的专有软件或内部文档。因此,用户在直接从 ChatGPT 寻求有关此类主题的建议或答案时应谨慎行事。
最小化这些限制的一种方法是为 ChatGPT 提供对与您的域和问题相关的特定文档的访问权限,并启用 ChatGPT 的语言理解功能以生成定制的响应。
这可以通过将 ChatGPT 连接到 Elasticsearch 等搜索引擎来实现。
Elasticsearch——you know, for search!
Elasticsearch 是一个高效的搜索引擎,旨在提供相关文档检索,确保用户可以快速准确地访问他们需要的信息。Elasticsearch 的主要重点是向用户提供最相关的结果、简化搜索过程并增强用户体验。
Elasticsearch 拥有众多可确保一流搜索性能的功能,包括支持传统关键字和基于文本的搜索 ( BM25 )以及一个具备精确匹配和近似kNN的AI向量搜索(k-Nearest Neighbor)。这些高级功能使 Elasticsearch 不仅可以检索相关的结果,还可以检索使用自然语言表达的查询的结果。通过利用传统、向量或混合搜索 (BM25 + kNN),Elasticsearch 可以提供无与伦比的精确结果,帮助用户轻松找到他们需要的信息。
Elasticsearch 的主要优势之一是其强大的 API,它可以与其他服务无缝集成以扩展和增强其功能。通过将 Elasticsearch 与各种第三方工具和平台集成,用户可以根据自己的特定需求创建功能强大的自定义搜索解决方案。这种灵活性和可扩展性使 Elasticsearch 成为希望提高搜索能力并在竞争激烈的数字环境中保持领先地位的企业的理想选择。
通过与 ChatGPT 等高级人工智能模型协同工作,Elasticsearch 可以为 ChatGPT 提供最相关的文档以用于其响应。Elasticsearch 和 ChatGPT 之间的这种协同作用可确保用户收到与其查询相关的事实、上下文相关和最新的答案。从本质上讲,Elasticsearch 的检索能力与 ChatGPT 的自然语言理解能力相结合,提供了无与伦比的用户体验,为信息检索和 AI 支持的协助树立了新标准。
如何将 ChatGPT 与 Elasticsearch 结合使用
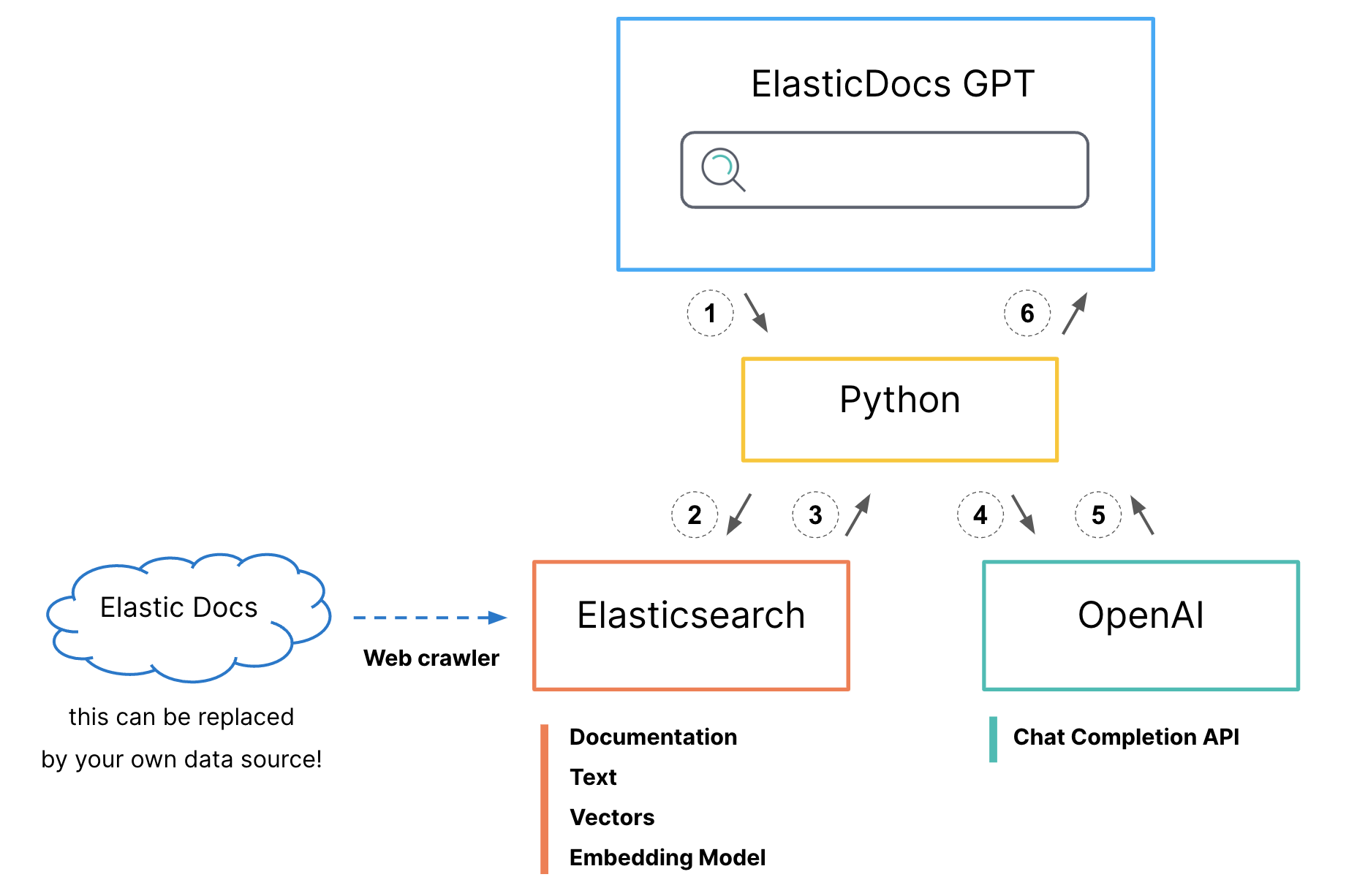
- Python API接受用户提问。
为 Elasticsearch 生成混合搜索请求
- title字段上的 BM25 匹配
- kNN 搜索title向量字段
- 提升 kNN 搜索结果以对齐分数
- 设置 size=1 只返回得分最高的文档
2.搜索请求发送到Elasticsearch。
3.文档正文和原始url返回给python应用程序。
- 对 OpenAI ChatCompletion 进行 API 调用:
- prompt:"answer this question <question> using only this document <body_content from top search result>"
- 生成的响应返回给 python。
- Python 将原始文档源 url 添加到生成的响应中,并将其打印到屏幕上供用户使用。
ElasticDoc ChatGPT 流程利用 Python 界面接受用户问题并为 Elasticsearch 生成混合搜索请求,结合 BM25 和 kNN 搜索方法从 Elastic的官方文档中查找最相关的文档,这些文档现已在 Elasticsearch 中编制索引。但是,您不必使用混合搜索甚至向量搜索。Elasticsearch 可以灵活地使用最适合您需求的搜索模式,并为您的特定数据集提供最相关的结果。
在检索到最佳结果后,该程序会为 OpenAI 的 ChatCompletion API 制作Prompt,指示它仅使用所选文档中的信息来回答用户的问题。此提示是确保 ChatGPT 模型仅使用官方文档中的信息、这是减少ChatGPT产生幻觉的关键。
最后,该程序向用户展示 API 生成的响应和源文档的链接,提供无缝且用户友好的体验,集成了前端交互、Elasticsearch 查询和 OpenAI API 使用以实现高效的问答。
请注意,虽然为简单起见我们只返回得分最高的文档,但最佳做法是返回多个文档以为 ChatGPT 提供更多上下文。可以在不止一个文档页面中找到正确的答案,或者如果我们要为完整的正文文本生成向量,那么这些较大的文本正文可能需要分块并存储在多个 Elasticsearch 文档中。通过利用 Elasticsearch 与传统搜索方法协同搜索大量矢量字段的能力,您可以显着提高您的顶级文档召回率。
技术设置
技术要求相当低,但需要一些步骤才能将所有部分组合在一起。对于此示例,我们将配置Elasticsearch 网络爬虫以摄取 Elastic 文档并在摄取时为title生成向量。您可以跟随本文并复制此设置,或使用自己的数据。为了跟随本文,我们需要:
- Elasticsearch集群
- Eland Python 库
- OpenAI API 账号
- 运行我们的 python 前端和 api 后端的服务器
Elastic Cloud设置
本节中的步骤假设您当前没有在 Elastic Cloud 中运行的 Elasticsearch 集群。如果你已经有一个 Elastic Cloud
的集群,可以跳到下一部分。
注册
如果您还没有 Elasticsearch 集群,您可以通过Elastic Cloud注册免费试用。
创建部署
注册后,系统会提示您创建第一个部署。
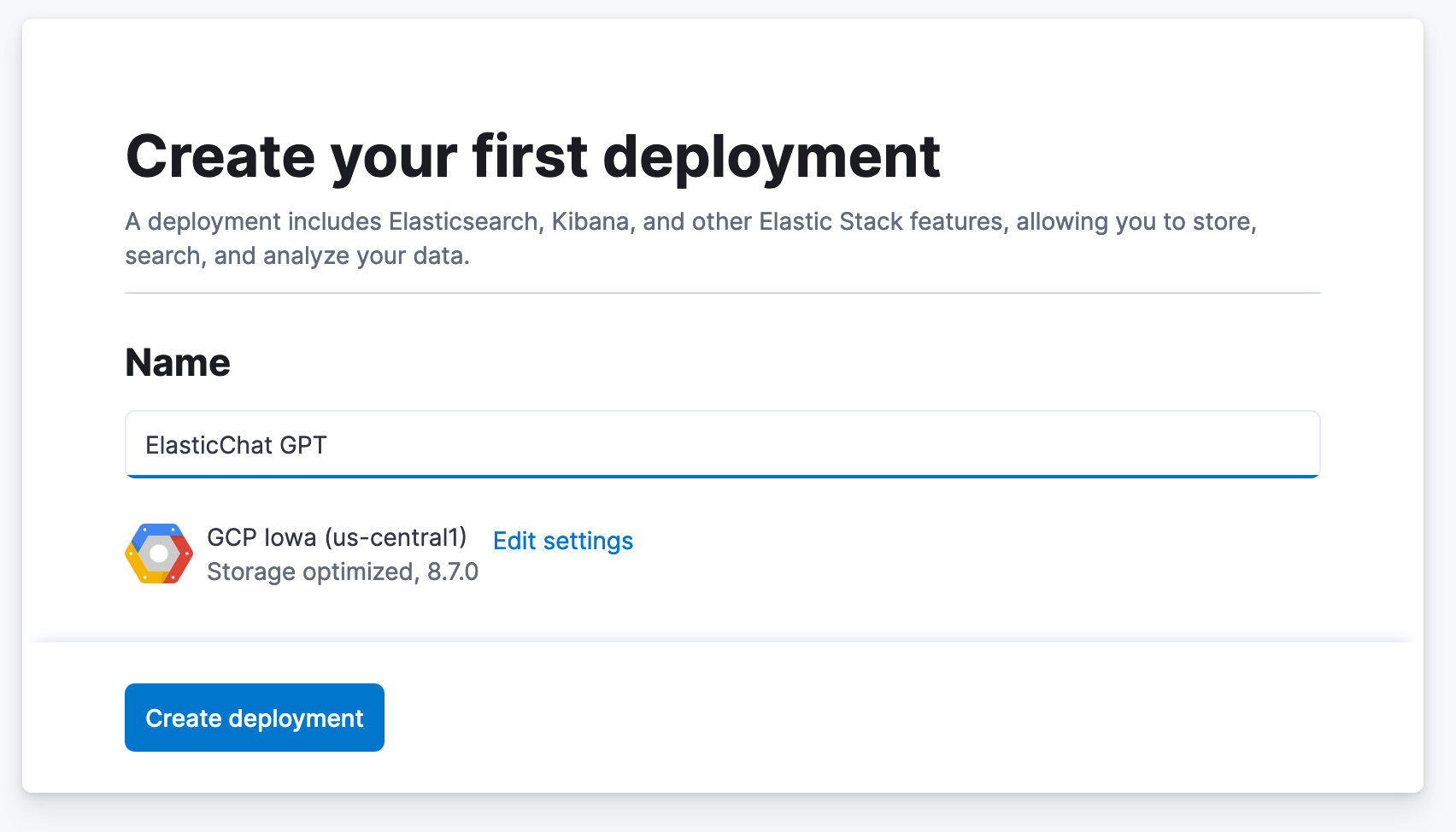
- 为您的部署创建一个名称。
- 您可以接受默认的云提供商和区域,或单击“编辑设置”并选择其他位置。
- 单击创建部署。很快将为您配置一个新的部署,您将登录到 Kibana。
回到云端
在继续之前,我们需要在 Cloud Console 中做几件事:
单击左上角的导航图标并选择管理此部署。

添加机器学习节点。
- 返回 Cloud Console,单击左侧导航栏中部署名称下的Edit。

- 向下滚动到 Machine Learning instances 框并单击 +Add Capacity。
- 在Size per zone下,单击并选择 2 GB RAM大小的机器学习节点
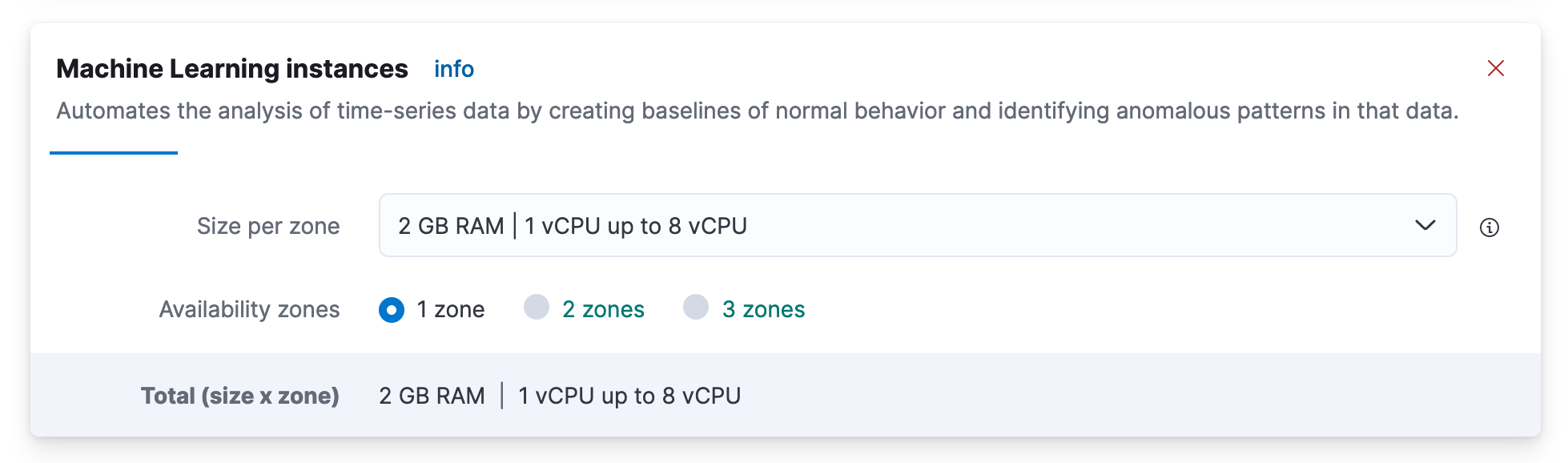
- 向下滚动并单击保存:

- 在弹出的 summarizing the architecture changes 窗口中,单击“Confirm”。

- 片刻之后,您的部署现在将能够运行机器学习模型!

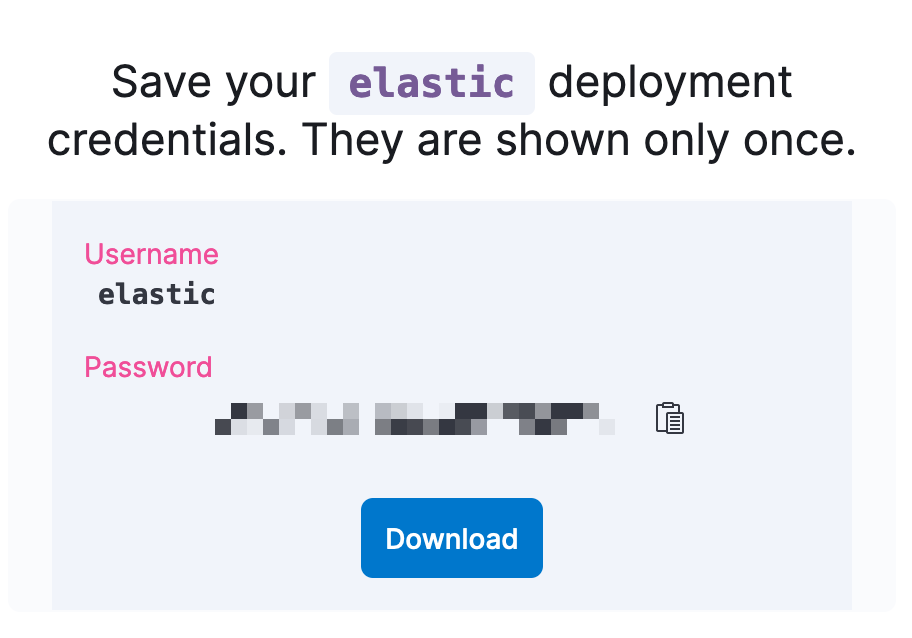
重置 Elasticsearch 部署用户和密码:
- 单击部署名称下方左侧导航栏中的安全性。
- 单击重置密码并使用重置进行确认。(注意:因为这是一个新集群,所以不应使用此 Elastic 密码。)
- 下载为“elastic”用户新创建的密码。(我们将使用它从 Hugging Face 和我们的 python 程序中加载我们的模型。)
复制 Elasticsearch 部署云 ID。
- 单击您的部署名称以转到概览页面。
- 在右侧单击复制图标以复制您的 Cloud ID。(保存此以备后用连接到 Deployment。)

Eland
接下来,我们需要将embedding模型加载到 Elasticsearch 中,用于为我们的博客title生成向量,以及为用户的搜索问题生成向量。我们将使用由 SentenceTransformers 训练并托管在 Hugging Face 模型中心上的all-distilroberta-v1模型。在此示例中,我们之所以选择这个模式,是因为它是在涵盖广泛主题的非常大的数据集上训练的,适合一般用途。但是,我们并非一定要选择这个模型,对于向量搜索用例,使用针对您的特定数据集进行微调的模型通常会提供最佳相关性。
为此,我们将使用Elastic 创建的Eland python 库。该库提供了广泛的数据科学功能,但我们将使用它作为桥梁,将模型从 Hugging Face 模型中心加载到 Elasticsearch,以便它可以部署在机器学习节点上以供推理使用。
Eland 可以作为 python 脚本的一部分运行,也可以在命令行上运行。该存储库还为希望走这条路的用户提供了一个 Docker 容器。今天我们将在一个小型 python notebook中运行 Eland ,它可以在网络浏览器中免费运行在谷歌的 Colab 中。
打开程序链接并单击顶部的“在 Colab 中打开”按钮以在 Colab 中启动笔记本。

将变量 hf_model_id 设置为模型名称。此模型已在示例代码中设置,但如果您想使用不同的模型可自行修改:
hf_model_id='sentence-transformers/all-distilroberta-v1'- 从 Hugging Face 复制模型名称。最简单的方法是单击模型名称右侧的复制图标。
运行 cloud auth 部分,系统会提示您输入:
- Cloud ID(您可以在 Elastic Cloud 控制台中找到它)
- Elasticsearch 用户名(最简单的方法是使用在创建部署时创建的“Elastic”用户)
- Elasticsearch的密码
运行剩余的步骤:
- 这将从 Hugging face 下载模型,将其分块,并将其加载到 Elasticsearch 中。
- 将模型部署(启动)到机器学习节点上。
Elasticsearch 索引和网络爬虫
接下来我们将创建一个新的 Elasticsearch 索引来存储我们的 Elastic 文档,将网络爬虫配置为自动抓取这些文档并为其编制索引,并使用摄取管道为文档title生成向量。
请注意,您可以在此步骤中使用您的专有数据,以创建适合您的领域的问答体验。
- 如果您尚未打开 Kibana,请从 Cloud Console 打开它。
- 在 Kibana 中,导航到Enterprise Search -> Overview。单击创建 Elasticsearch 索引。

- 使用 Web Crawler 作为摄取方法,输入 elastic-docs 作为索引名称。然后,单击创建索引。

- 单击“ingest Pipeline”选项卡。
- 单击 Ingest Pipeline 中的 Copy and customize。
- 单击 Add Inference Pipeline

- 为新管道输入名称 elastic-docs_title-vector。
- 选择您在上面的 Eland 步骤中加载的经过训练的 ML 模型。
- 选择title作为源字段。
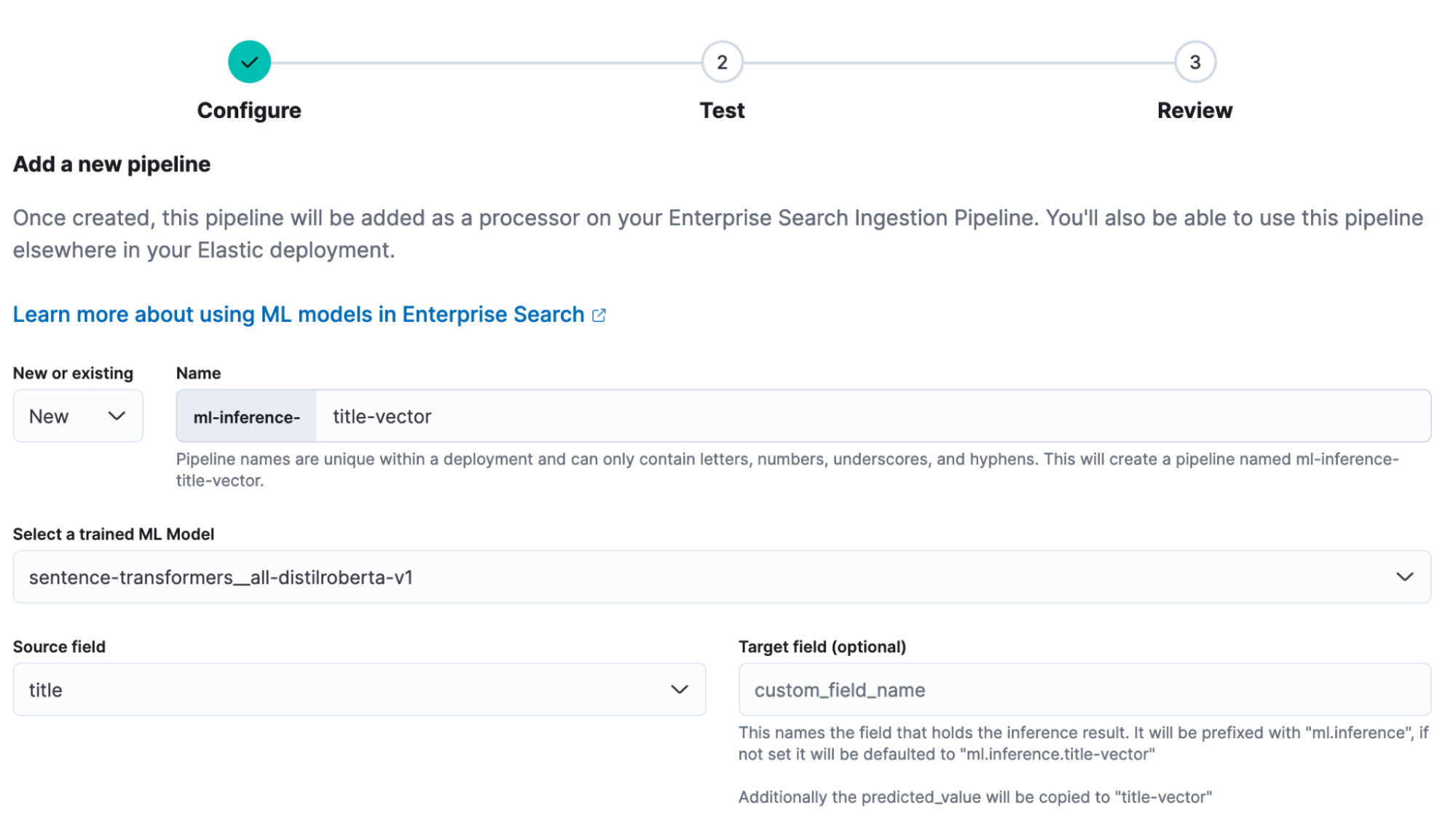
- 单击Continue,然后在测试阶段再次单击Continue
- 在 Review 阶段点击 Create Pipeline
更新 dense_vector 字段的映射。(注意:对于 Elasticsearch 8.8+ 版本,此步骤应该是自动的。)
- 在导航菜单中,单击 Dev Tools。如果这是您第一次打开 Dev Tools,您可能必须在带有文档的弹出窗口中单击“关闭”。
- 在 Console 选项卡的 Dev Tools 中,使用以下代码更新
dense_vector目标字段的映射。您只需将其粘贴到代码框中,然后单击第 1 行右侧的小箭头。
POST search-elastic-docs/_mapping
{
"properties": {
"title-vector": {
"type": "dense_vector",
"dims": 768,
"index": true,
"similarity": "dot_product"
}
}
}了解详情- 您应该会在屏幕的右半部分看到以下响应:
{
"acknowledged": true
}- 这将允许我们稍后在title字段上运行 kNN 向量搜索。
配置网络爬虫以爬取 Elastic官方文档:
- 再次单击导航菜单,然后单击 Enterprise Search -> Overview。
- 在内容下,单击索引。
- 单击 search-elastic-docs。

- 单击“Manage Domains”选项卡。
- 单击“Add domain”。
- 输入https://www.elastic.co/guide/en,然后单击验证域。
- 检查运行后,单击Add domain。然后单击抓取规则。
- 逐个添加以下爬行规则。从底部开始,逐步向上。规则按照第一个匹配进行评估。
Disallow | Contains | release-notes |
|---|---|---|
Allow | Regex | /guide/en/.*/current/.* |
Disallow | Regex | .* |

- 准备好所有规则后,单击页面顶部的抓取。然后,单击“ Crawl all domains on this index”。
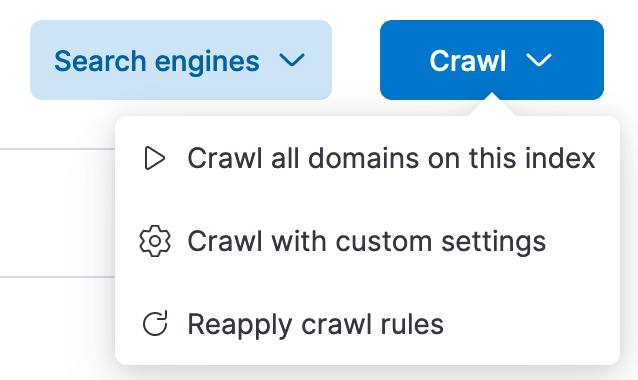
Elasticsearch 的网络爬虫现在将开始爬取文档站点,为title字段生成向量,并对文档和向量建立索引。

第一次爬网需要一些时间才能完成。同时,我们可以设置 OpenAI API 凭证和 Python 后端。
与 OpenAI API 连接
要向 ChatGPT 发送文档和问题,我们需要一个 OpenAI API 帐户和密钥。如果您还没有帐户,可以创建一个免费帐户,您将获得初始数量的免费积分。
- 前往https://platform.openai.com并点击注册。您可以通过电子邮件地址和密码进行注册,也可以使用Google或Microsoft登录。
创建帐户后,您需要创建一个 API 密钥:
- 单击API Key。
- 单击创建新密钥。
- 复制新密钥并将其保存在安全的地方,因为您将无法再次查看该密钥。

Python 后端设置
克隆或下载python程序
- 安装所需的 python 库。我们在具有隔离环境的 Replit 中运行示例程序。如果您在笔记本电脑或 VM 上运行它,最佳做法是为 python 设置一个VENV。
- 运行 pip install -r requirements.txt
2.设置身份验证和连接环境变量(例如,如果在命令行上运行:export openai_api=”123456abcdefg789”)
- openai_api - OpenAI API Key
- cloud_id - Elastic Cloud ID
- cloud_user - Elasticsearch 集群用户
- cloud_pass - Elasticsearch 用户密码
3.运行streamlit程序。有关 streamlit 的更多信息可以在其文档中找到。
- Streamlit 有自己的启动命令:streamlit run elasticdocs_gpt.py
- 这将启动网络浏览器,并将 url 打印到命令行。
聊天响应的示例
一切都已摄取且前端启动并运行后,您可以开始询问有关 Elastic 官方文档的问题。
询问“Show me the API call for an inference processor”现在会返回一个 API 调用的例子和有关配置设置的信息。
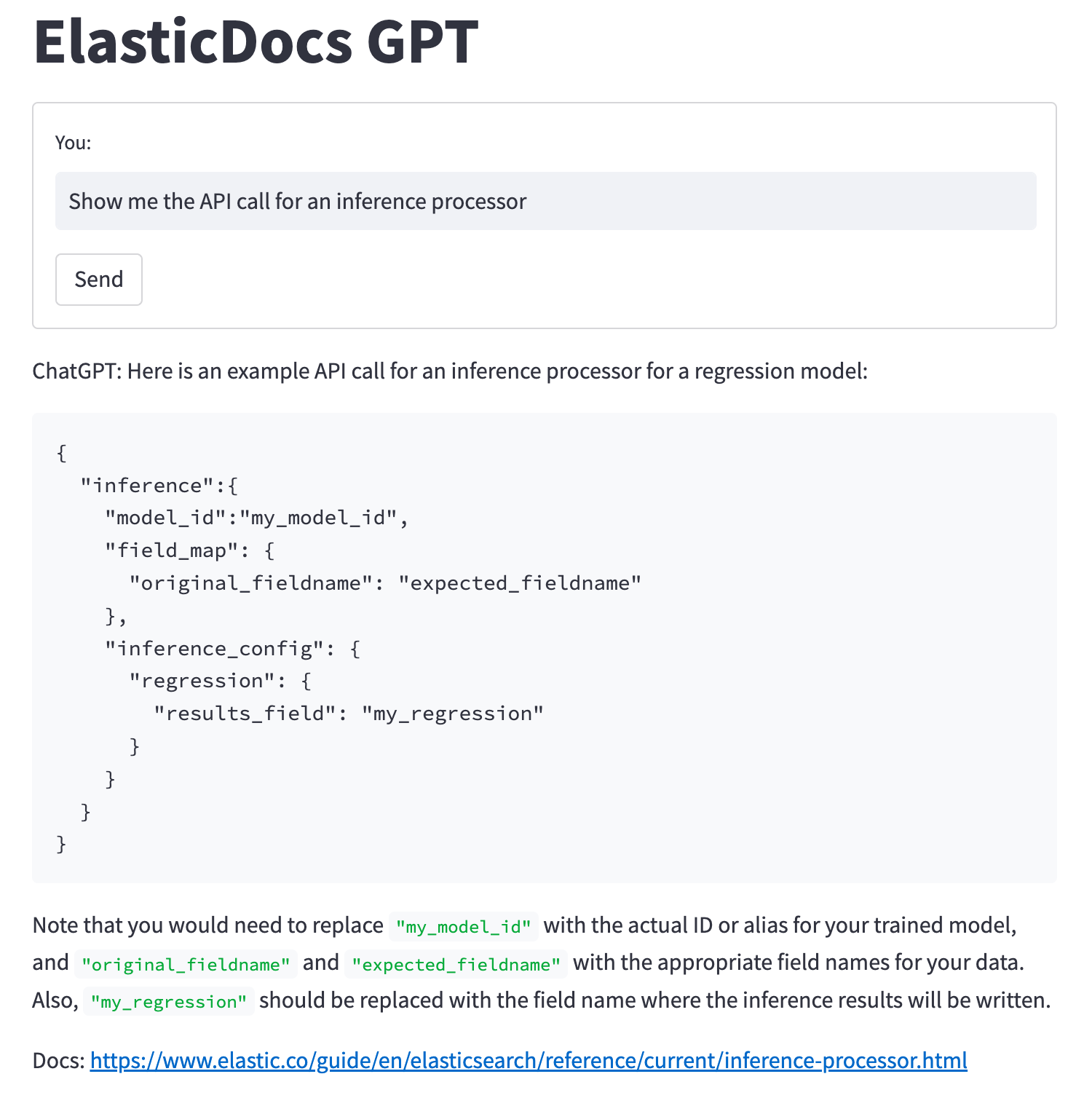
询问将新集成添加到 Elastic Agent 的步骤:

如前所述,允许 ChatGPT 仅根据训练过的数据回答问题的风险之一是它容易产生错误答案的幻觉。该项目的目标之一是为 ChatGPT 提供包含正确信息的数据,并让它制定答案。
那么当我们给 ChatGPT 一个不包含正确信息的文档时会发生什么?比方说,请它告诉您如何造船(Elastic 的官方文档不包含此内容):
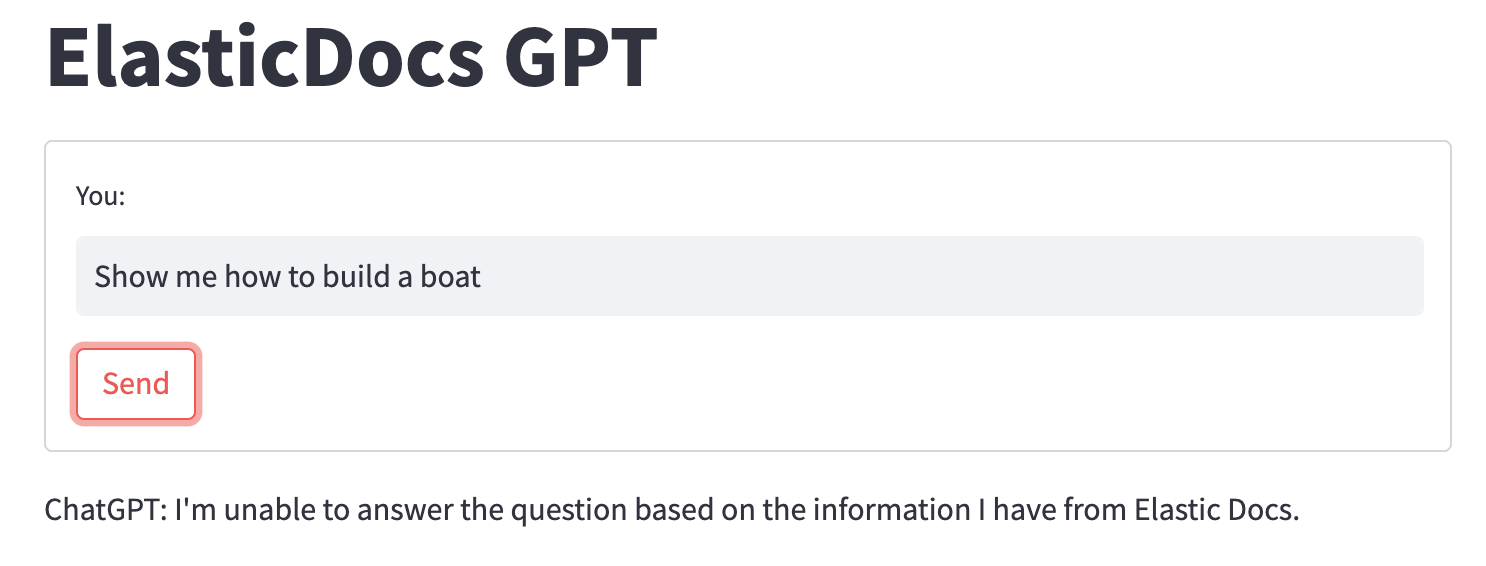
当 ChatGPT 无法在我们提供的文档中找到问题的答案时,它会退回到我们的提示指令,简单地告诉用户它无法回答问题。
Elasticsearch 的强大检索 + ChatGPT 的强大功能
在这个例子中,我们展示了如何将Elasticsearch强大的搜索检索功能与GPT模型生成的最新进展的AI响应集成,从而将用户体验提升到一个全新的水平。
这些组件可以根据您的具体要求进行定制,并进行调整以提供最佳结果。虽然我们使用了Elastic网络爬虫来摄取公共数据,但您并不局限于此方法。你随意尝试其他embedding模型,尤其是那些针对特定领域数据进行微调的模型。
您今天可以尝试本博客中讨论的所有功能!要构建您自己的 ElasticDocs GPT 体验,请注册一个Elastic 试用帐户,然后查看此示例代码库以开始使用。
如果您想了解更多Elasticsearch在搜索相关性上的新可能,可以尝试以下两个:
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
