R语言K-Means(K-均值)聚类、朴素贝叶斯(Naive Bayes)模型分类可视化
原创
R语言K-Means(K-均值)聚类、朴素贝叶斯(Naive Bayes)模型分类可视化
原创
拓端
发布于 2023-05-10 21:21:27
发布于 2023-05-10 21:21:27
全文链接:http://tecdat.cn/?p=32355
原文出处:拓端数据部落公众号
分类是把某个对象划分到某个具体的已经定义的类别当中,而聚类是把一些对象按照具体特征组织到若干个类别里。虽然都是把某个对象划分到某个类别中,但是分类的类别是已经预定义的,而聚类操作时,某个对象所属的类别却不是预定义的。所以,对象所属类别是否为事先,是二者的最基本区别。而这个区别,仅仅是从算法实现流程来看的。
本文帮助客户对数据进行聚类和分类,需要得到的结果是,聚类的二维效果图,聚类个数,聚类中心点值。 用聚类得到的结果贝叶斯建模后去预测分类。需要得到贝叶斯的模型精度,分类预测结果。
K-Means聚类成3个类别
聚类算法(clustering analysis)是指将一堆没有标签的数据自动划分成几类的方法,属于无监督学习方法。 K-means算法,也被称为K-平均或K-均值,是一种广泛使用的聚类算法,或者成为其他聚类算法的基础,它是基于点与点距离的相似度来计算最佳类别归属。几个相关概念:
K值:要得到的簇的个数;
质心:每个簇的均值向量,即向量各维取平均即可;
距离量度:常用欧几里得距离和余弦相似度(先标准化);
kmeans(data, 3)聚类中心

聚类绘图
lusplot(data, fit$cluster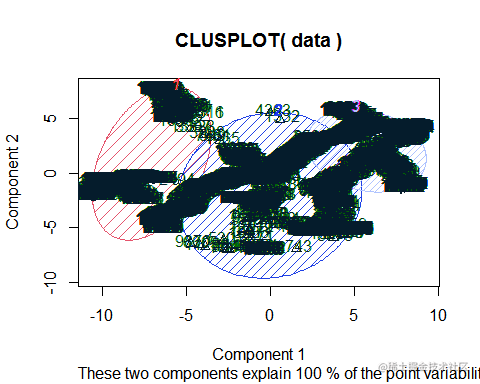
将数据使用kmean算法分成3个类别后可以看到 每个类别之间分布呈不同的簇,交集较少 ,因此 可以认为得到的聚类结果较好。
计算贝叶斯训练模型
朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法 。
和决策树模型相比,朴素贝叶斯分类器(Naive Bayes Classifier 或 NBC)发源于古典数学理论,有着坚实的数学基础,以及稳定的分类效率。同时,NBC模型所需估计的参数很少,对缺失数据不太敏感,算法也比较简单。
朴素贝叶斯算法(Naive Bayesian algorithm) 是应用最为广泛的分类算法之一。
也就是说没有哪个属性变量对于决策结果来说占有着较大的比重,也没有哪个属性变量对于决策结果占有着较小的比重。
虽然这个简化方式在一定程度上降低了贝叶斯分类算法的分类效果,但是在实际的应用场景中,极大地简化了贝叶斯方法的复杂性。
head(train)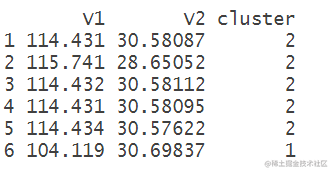
建立贝叶斯模型
naiveBayes(as.factor(clus
贝叶斯的模型精度
tab=table(preds,train[,ncol(train)])#分类混淆矩阵
tab
进行预测
predict(m, datapred,type="clas预测分类
preds
K-Means聚成两个类别
fit <- kmeans(dat聚类中心
fit$centers
usplot(data, fit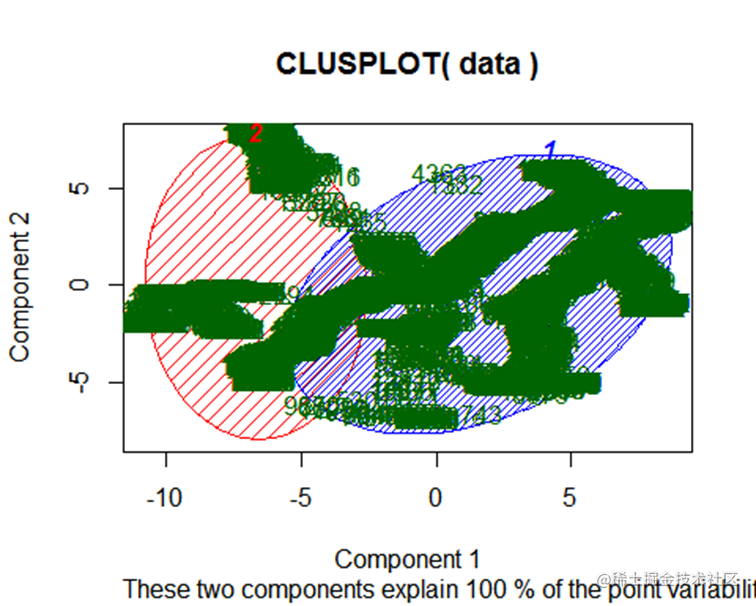
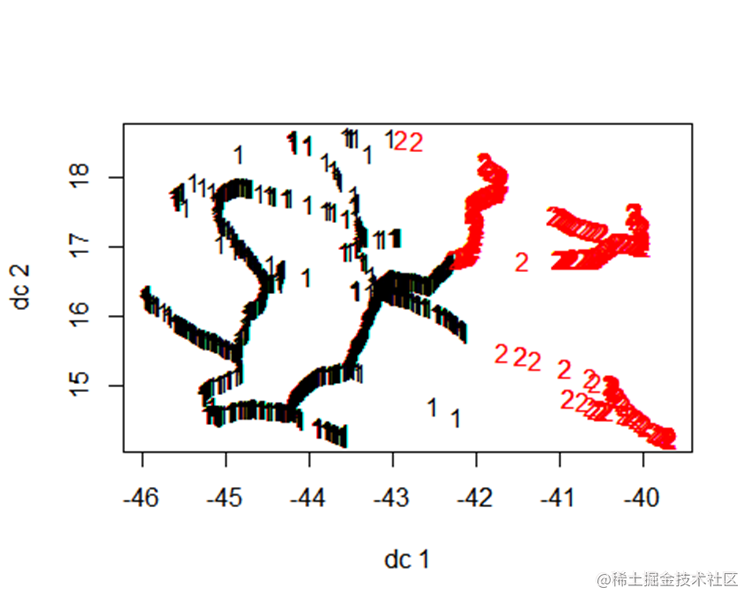
将数据使用kmean算法分成2个类别后可以看到每个类别之间分布呈不同的簇,交集较少 ,因此可以认为得到的聚类结果较好。
建立贝叶斯模型
naiveBayes(as.factor(clu
贝叶斯的模型精度
table(preds,train[,n
进行预测
predict(m, datapred,type="cla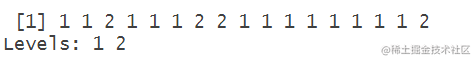
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号