视频技术快览 0x2 - 视频传输和网络对抗

视频技术快览 0x2 - 视频传输和网络对抗

Cellinlab
发布于 2023-05-17 16:52:09
发布于 2023-05-17 16:52:09
# RTP & RTCP
# RTP 协议
RTP(Real-time Transport Protocol)协议,全称是实时传输协议。它主要用于音视频数据的传输。
一般在实时通信的时候,需要传输音频和视频数据。通常是这样做的,先将原始数据经过编码压缩之后,再将编码码流传输到接收端。在传输的时候通常不会直接将编码码流进行传输,而是先将码流打包成一个个 RTP 包再进行发送。
之所以要打包,是因为接收端要能够正确地使用这些音视频编码数据,不仅仅需要原始的编码码流,还需要一些额外的信息, 如视频编码标准(H264、H265、VP8、VP9 或 AV1)、视频播放速度等。
RTP 包包括两个部分:
- RTP 头部
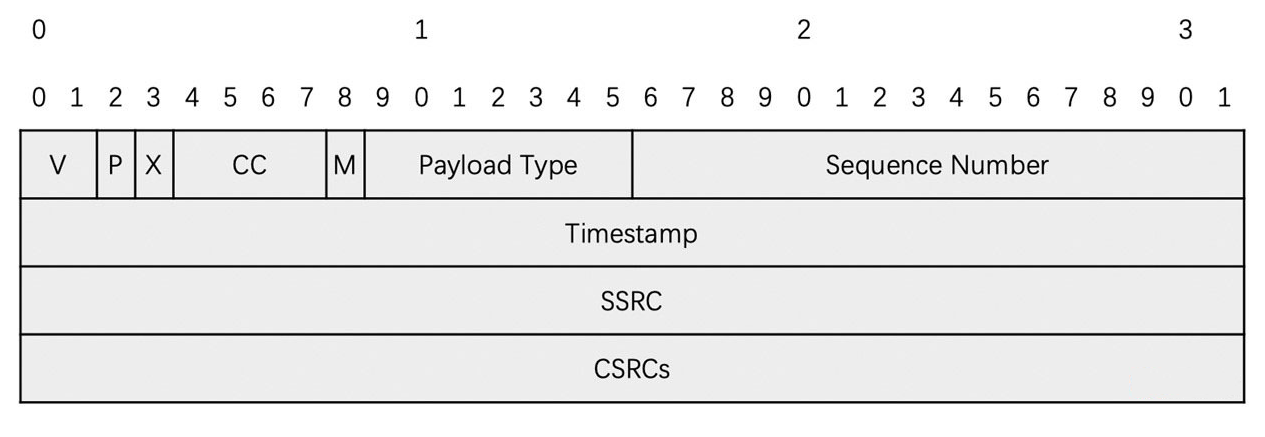
- 字段占用的位数和具体的含义
- RTP 扩展头
- 当扩展头标志位 X 为 1 的时候,说明有 RTP 扩展头
- RTP 扩展头平时很少用,主要是用来给用户自定义扩展使用的
- 在 RTC 场景中,尤其是 WebRTC 中经常会用到
- RTP 扩展头在带宽预测的时候也会用到
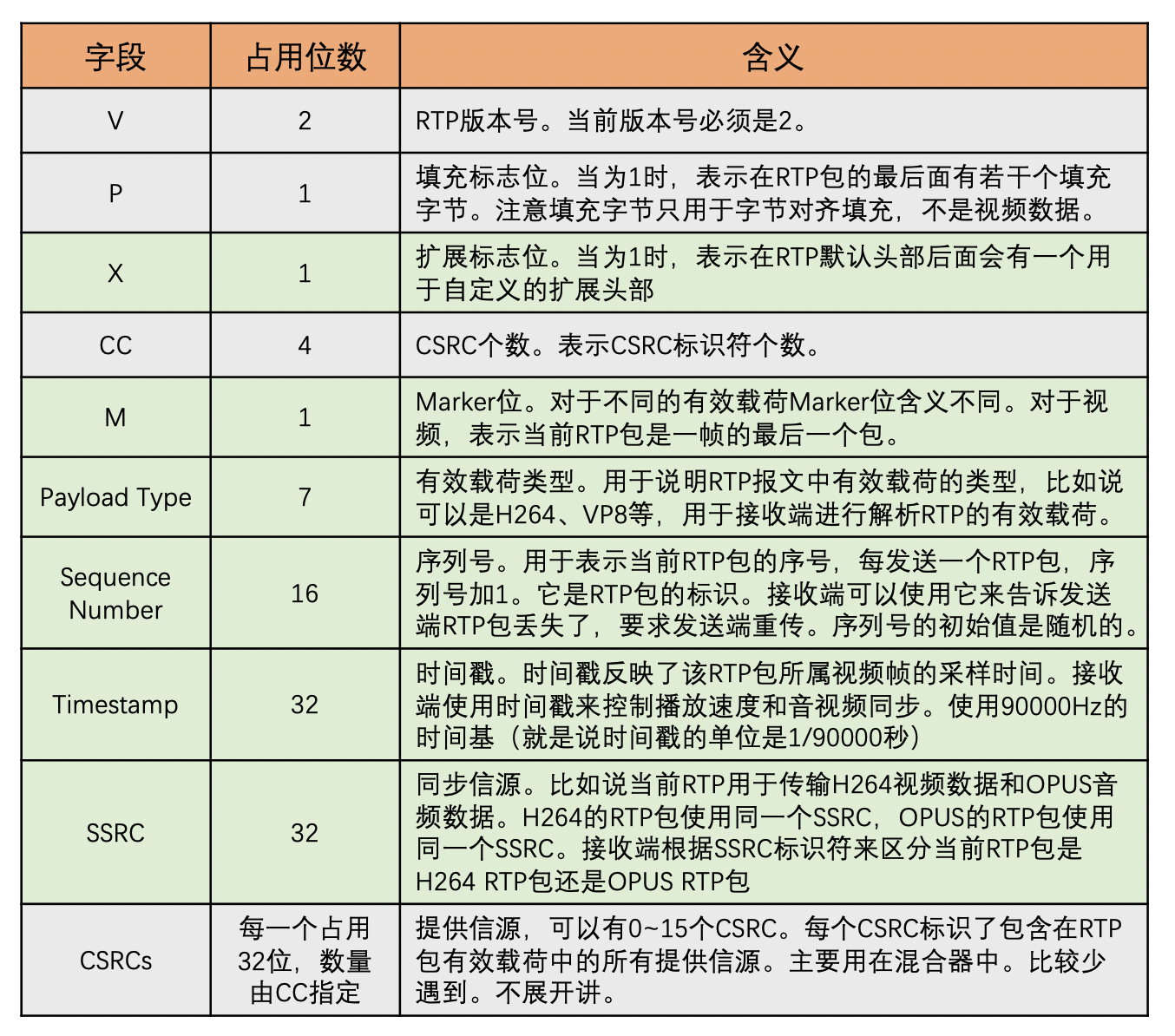
- RTP 有效载荷
- 有效载荷,就是 RTP 包里面的实际数据
- 如果是 H264 编码打包成 RTP 包,那有效载荷就是经过 H264 编码的码流;如果是 VP8 编码呢,那就是 VP8 码流
- 有效载荷,就是 RTP 包里面的实际数据
有了 RTP 协议,就能够将码流打包成 RTP 包发给接收端了。如果只负责传输 RTP 包,而不需要管传输过程中有没有丢包,以及传输 RTP 包的时候有没有引起网络拥塞的话,那只需要使用 RTP 协议就可以了。比如说,选择使用 TCP 协议传输 RTP 包的话就可以不用管这些事情,因为 TCP 协议具有丢包重传、拥塞控制等功能。
通常情况下,在传输音视频数据的时候不会使用 TCP 协议作为传输层协议。因为 TCP 协议更适合传输文本和文件等数据,而不适合传输实时音频流和视频流数据,所以通常会使用 UDP 协议作为音视频数据的传输层协议。但 UDP 协议不具有丢包重传和拥塞控制的功能,需要自己实现。
# RTCP 协议
RTCP(Real-time Transport Control Protocol)协议,全称是实时传输控制协议。它是辅助 RTP 协议使用的。RTCP 报文有很多种,分别负责不同的功能。常用的报文有发送端报告(SR)、接收端报告(RR)、RTP 反馈报告(RTPFB)等。而每一种报告的有效载荷都是不同的。通过这些报告在接收端和发送端传递当前统计的 RTP 包的传输情况的。使用这些统计信息来做丢包重传,以及预测带宽。
RTCP 协议只是用来传递 RTP 包的传输统计信息,本身不具有丢包重传和带宽预测的功能,而这些功能需要自己来实现。
RTP 是用来传输实际的视频数据的。它就像一个快递盒,先装好视频,然后填好运送的视频基本信息和收件人信息,最后将视频运送到收件人手上。而 RTCP 协议则像是一个用来统计快递运送情况的记录表。
# H264 RTP 打包
RTP H264 码流打包分为三种方式:
- 单 NALU 封包方式
- 一个 NALU 打一个 RTP 包
- 单 NALU 封包方式非常简单,在 RTP 头部的后面,直接放置 NALU 数据即可
- 注意,根据 RTP 的规定,这里需要将 NALU 数据前面的起始码去除,不要将起始码也带入 RTP 包中
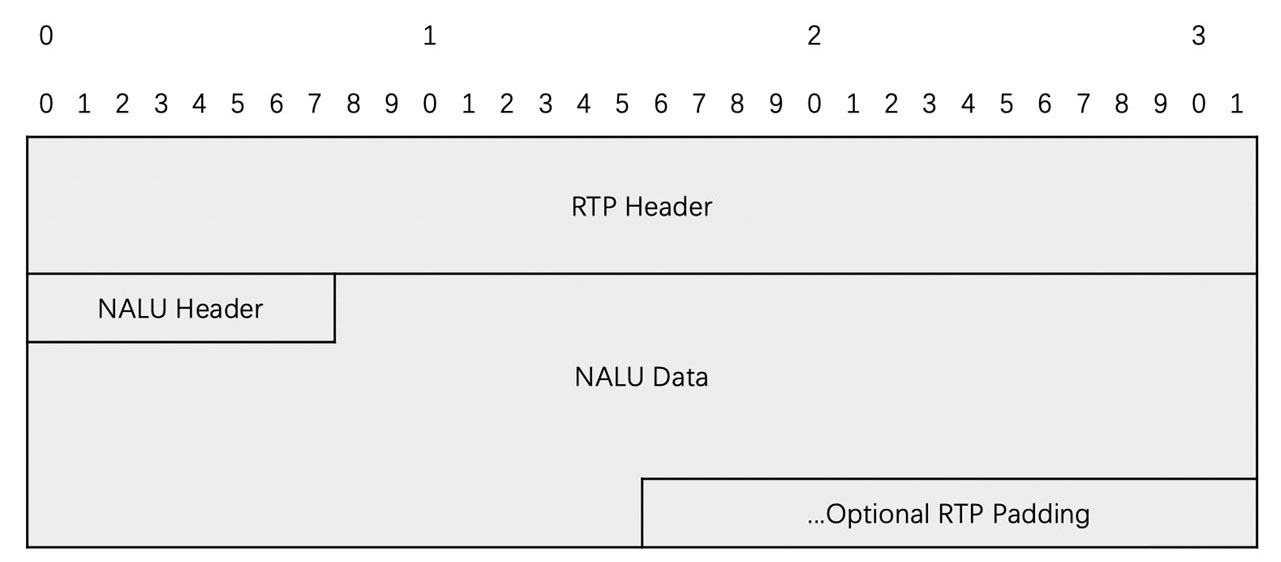
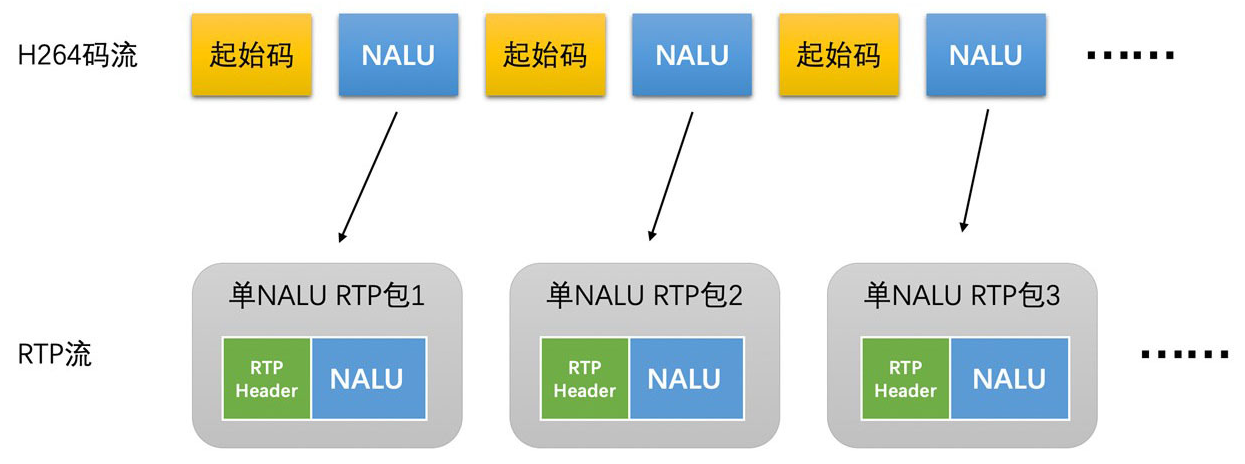
- 这种打包方式适合于单个 RTP 包小于 1500 字节(MTU 大小)的时候,一般来说,一些 P 帧和 B 帧编码之后比较小,就可以使用这种打包方式
- 组合封包方式
- 将多个 NALU 放置在一个 RTP 包中
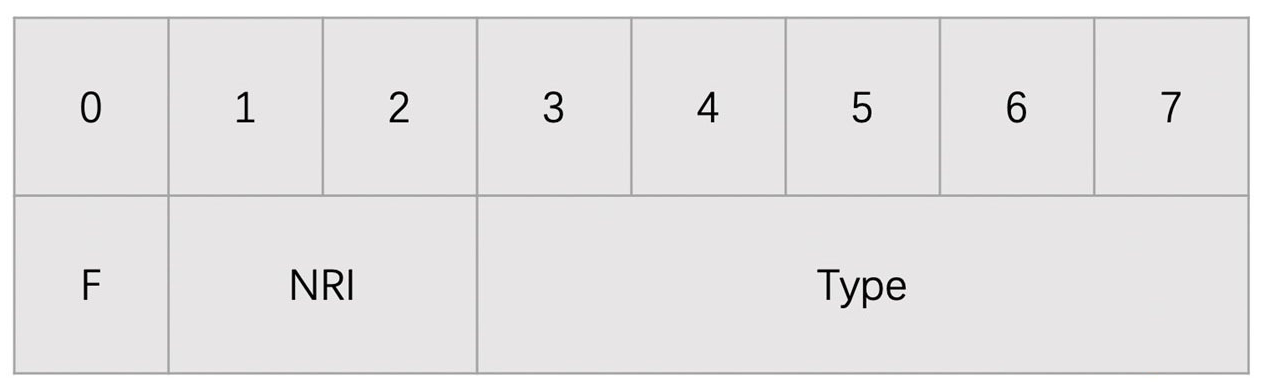
- 在 RTP 头部之后,且放置 NALU 数据之前,需要放置一个 1 字节的 STAP-A 的头部
- STAP-A Header 跟 NALU Header 的格式是一样的,只是 Type 字段的值不一样
- 放置完 STAP-A Header 之后,在每一个 NALU 的前面需要放置一个 2 字节的 size 字段,用于表示后面的 NALU 的大小,之后才是 NALU 的数据,记住同样需要去掉起始码
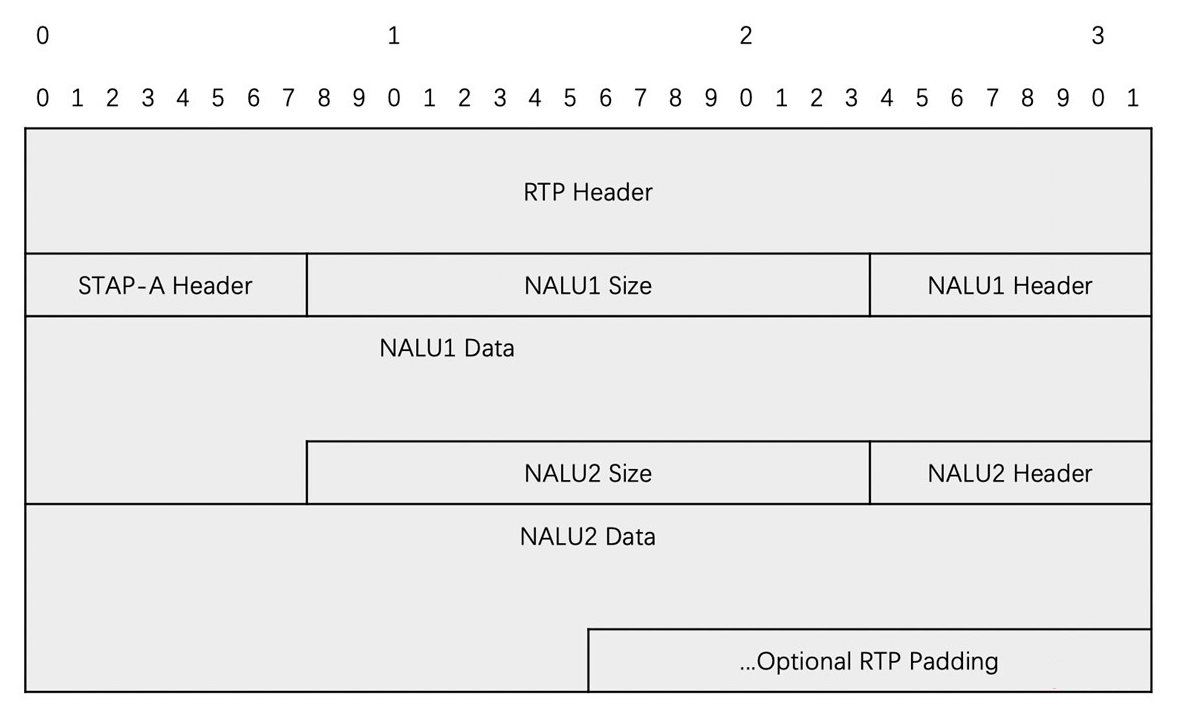
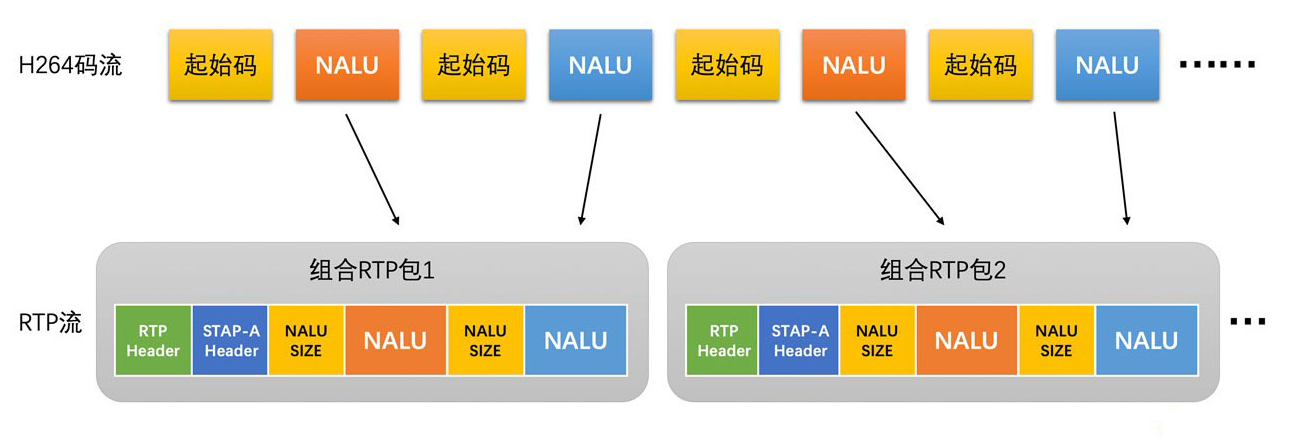
- 这种打包方式适合于单个 NALU 很小的时候,将多个 NALU 打包到一起也小于 1500 字节的时候就可以使用
- 由于一般多个视频帧加到一起还小于 1500 的情况比较少,所以视频数据的 RTP 打包一般来说用组合封包方式的情况也很少
- 分片封包方式
- 分片封包就更复杂一些了,但却是经常用到的打包方式
- 将一个 NALU 分开打包在连续的多个 RTP 包中,首先需要一个 1 字节的 FU indicator 来表示当前 RTP 包是不是分片封包方式,再用一个 1 字节的 FU Header 来表示当前这个 RTP 包是不是 NALU 的第一个包,是不是 NALU 的最后一个包,以及 NALU 的类型
- 分片封装中的 FU indicator 跟 NALU Header 的格式也是一样的,也只是 Type 字段的值不同
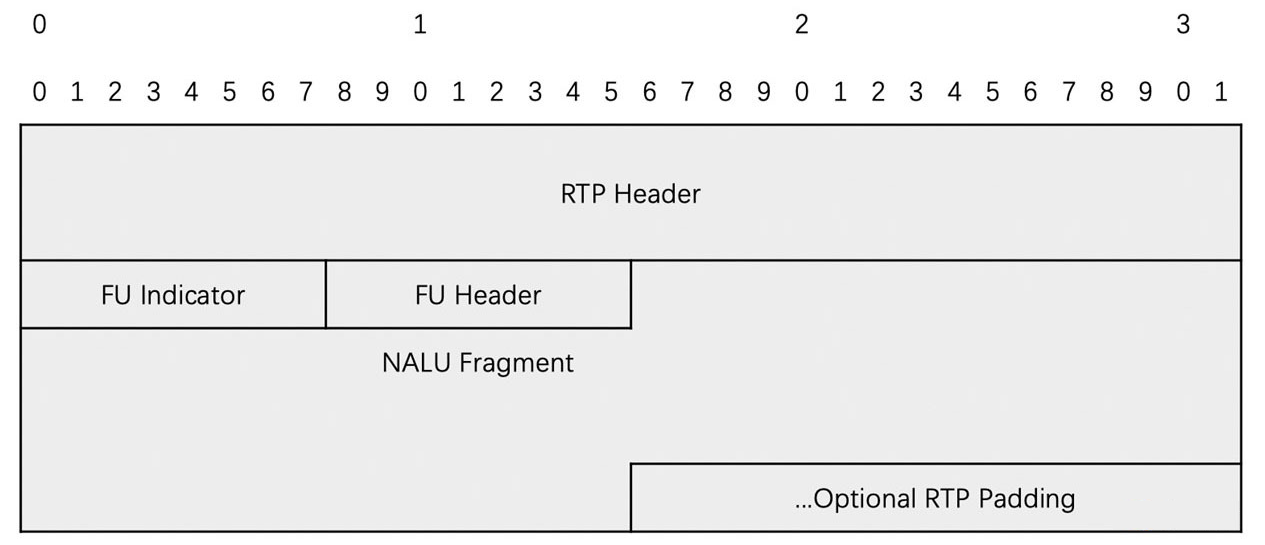
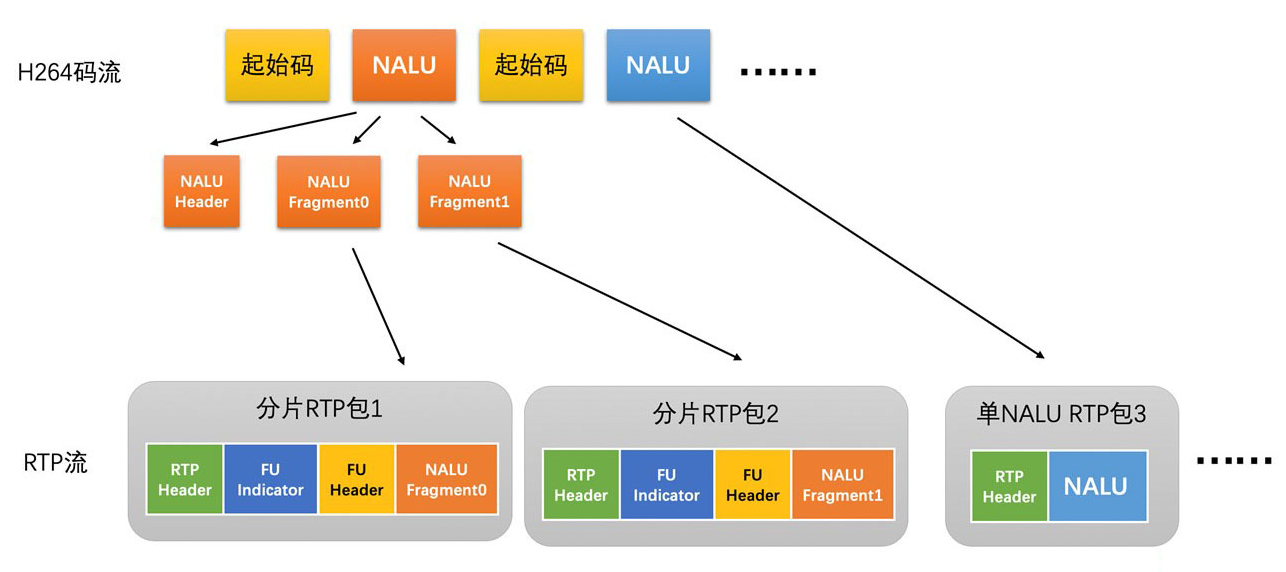
- 这种打包方式主要用于将 NALU 数据打包成一个 RTP 包时大小大于 1500 字节的时候,这是经常使用的视频 RTP 打包方法
怎么选择使用哪种方式打包呢?
一般来说,在一个 H264 码流中会混合使用多种 RTP 打包方式。一般来说,对于小的 P 帧、B 帧还有 SPS、PPS 可以使用单个 NALU 封包方式。而对于大的 I 帧、P 帧或 B 帧,使用分片封包方式。
# 带宽预测
一般情况下,音视频场景中的拥塞控制和丢包重传等算法的基础就是 RTP 和 RTCP 协议。需要通过 RTP 包的信息和 RTCP 包中传输的统计信息来做拥塞控制和丢包重传等操作。
带宽预测,就是实时预测当前的网络带宽大小。预测出实际的带宽之后,就可以控制音视频数据的发送数据量。如控制音视频数据的编码码率或者直接控制发送 RTP 包的速度,这都是可以的。控制住音视频发送的数据量是为了不会在网络带宽不够的时候,还发送超过网络带宽承受能力的数据量,最后导致网络出现长延时和高丢包等问题,继而引发接收端出现延时高或者卡顿的问题。
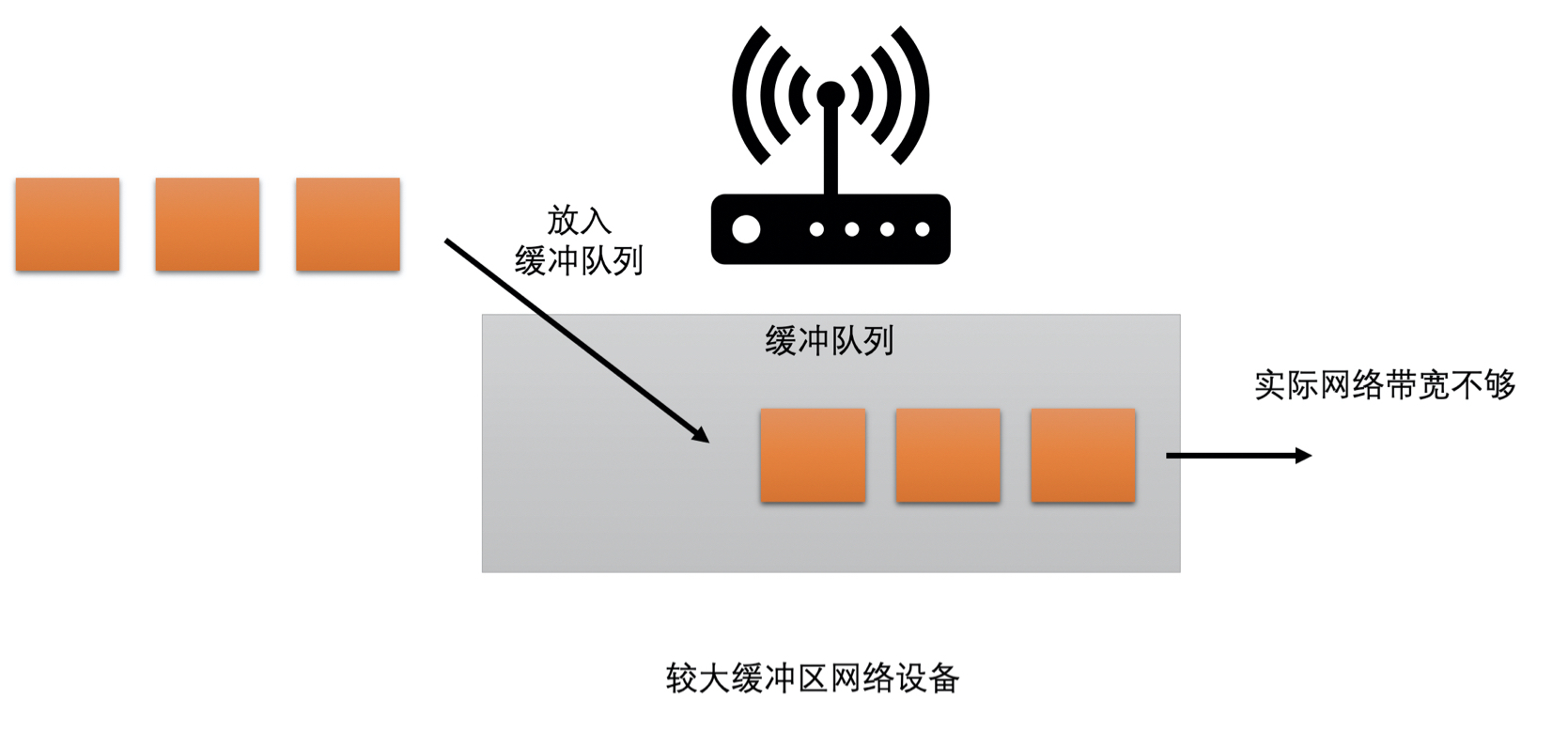
现在的网络中,大多存在两种类型的网络设备:
- 有较大缓存的
- 在网络中需要转发数据过多的时候,会把数据先缓存在自己的缓冲队列中,等待前面的数据发送完之后再发送当前数据
- 会在网络带宽不够的时候,需要当前数据等一段时间才能发送,因此表现出来的现象就是网络不好时,延时会加大
- 没有缓存或者缓存很小的
- 在网络中需要发送的数据过多的时候,会直接将超过带宽承受能力的数据丢弃掉
- 在网络带宽不够的时候,出现高丢包的现象
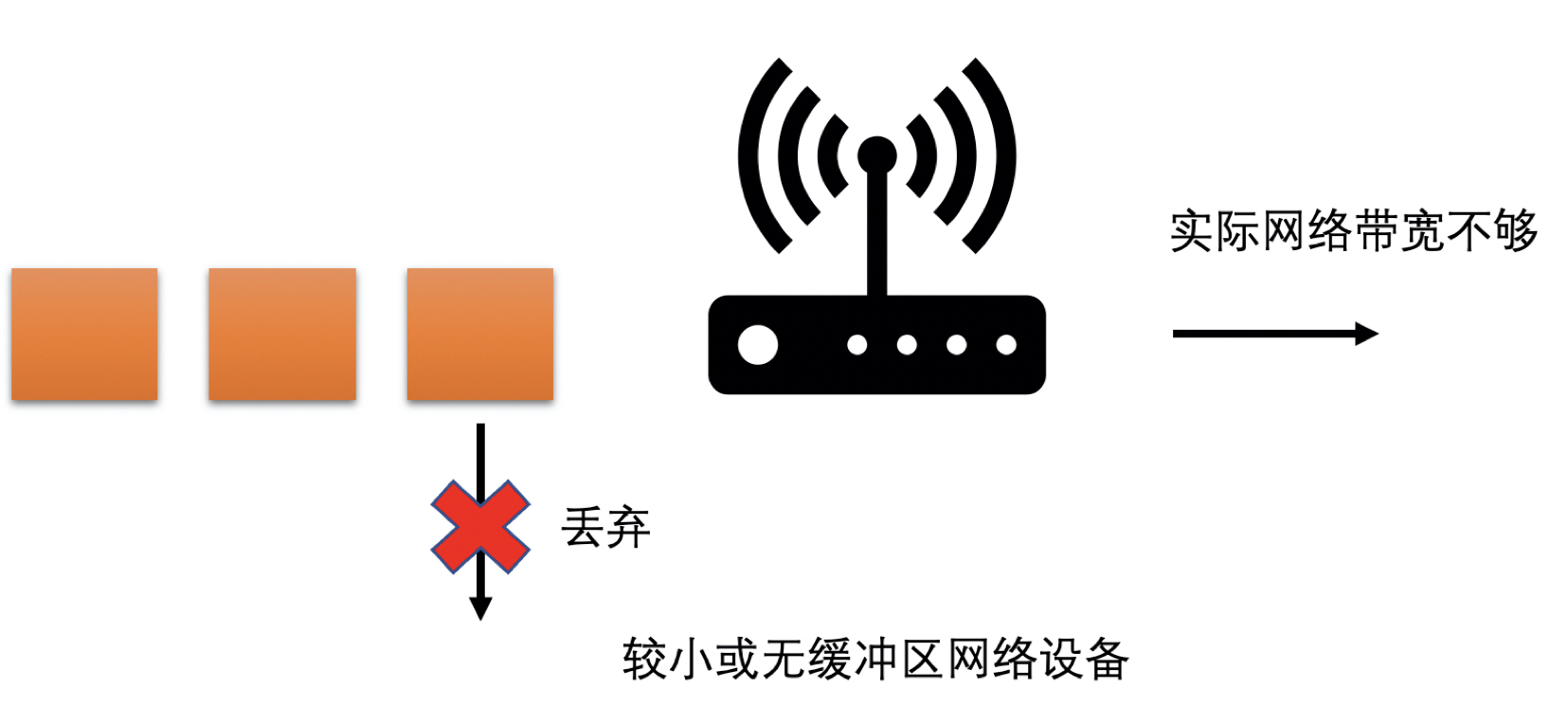
因为互联网中这两种类型的网络设备都存在,为了能够兼顾这两种类型的网络,WebRTC 中设计了两个主要的带宽预测算法:一个是基于延时的带宽预测算法;一个是基于丢包的带宽预测算法。
# 基于延时的带宽预测算法
基于延时的带宽预测算法主要是通过计算一组 RTP 包它们的发送时长和接收时长,来判断当前延时的变化趋势,并根据当前的延时变化趋势来调整更新预测的带宽值。

基于延时的带宽预测算法,主要有 4 个步骤:
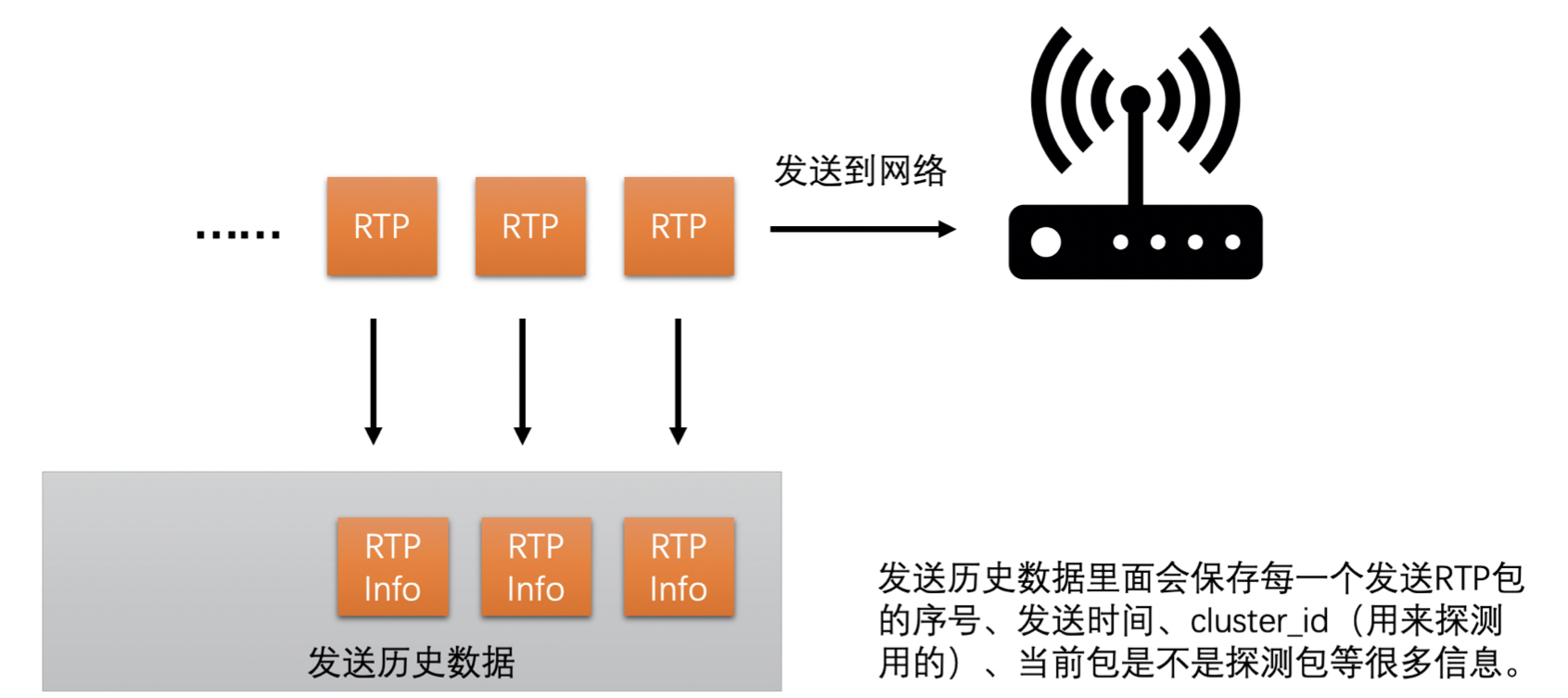
- 计算一组 RTP 包的发送时长和接收时长,并计算延时
- WebRTC 中计算延时的时候是将 RTP 包按照发送时间来分组的,并且要求当前组中的第一个包和最后一个包的发送时间相差不能大于 5ms,而大于 5ms 则是新的一组的开始
- 由于 UDP 会出现包乱序到达的情况,可能导致后面包的发送时间比前面包的还小,为了防止这种情况的发生,要求乱序的包不参与计算
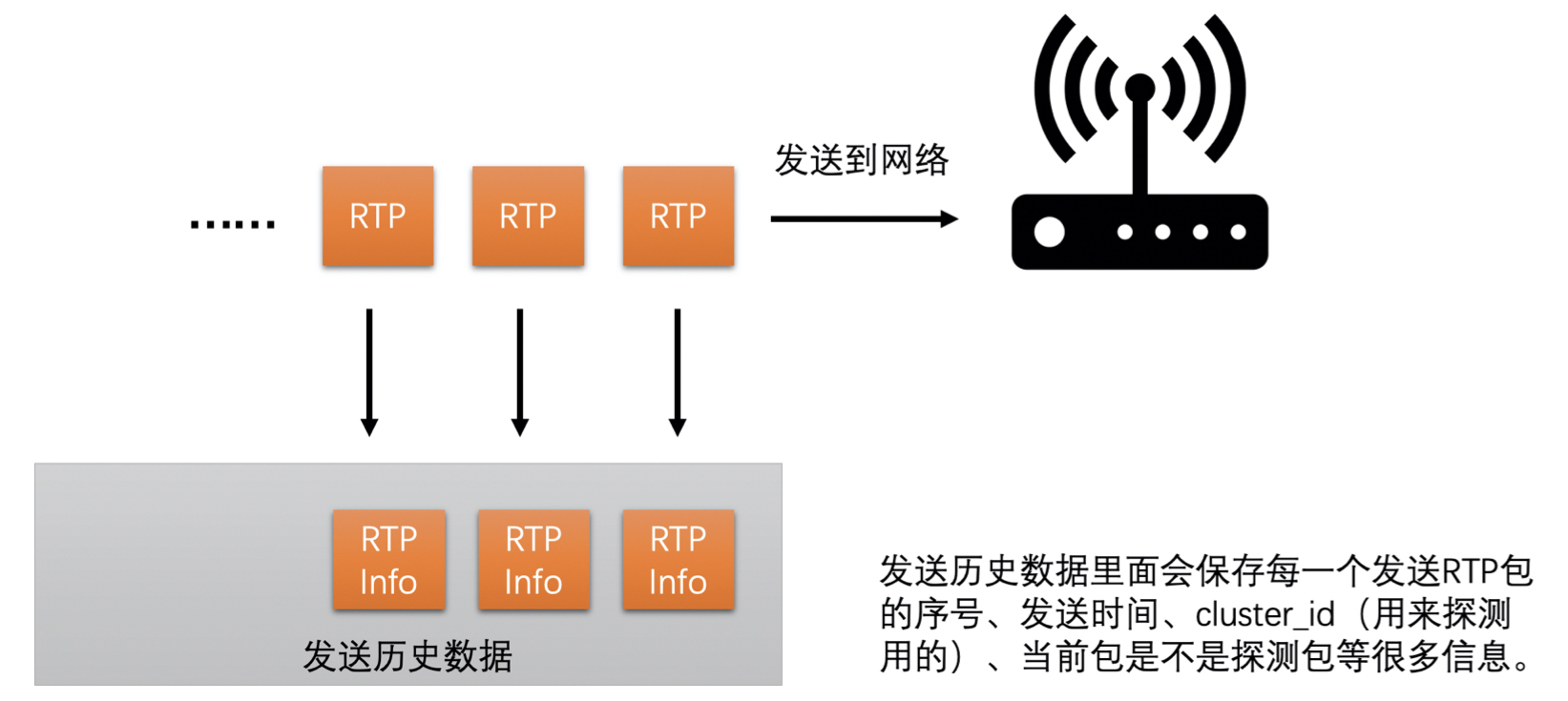
- 发送端在发送每一个 RTP 包的时候会记录每一个包的包序号和实际发送时间,并把这些信息记录到一个发送历史数据里面方便之后计算使用
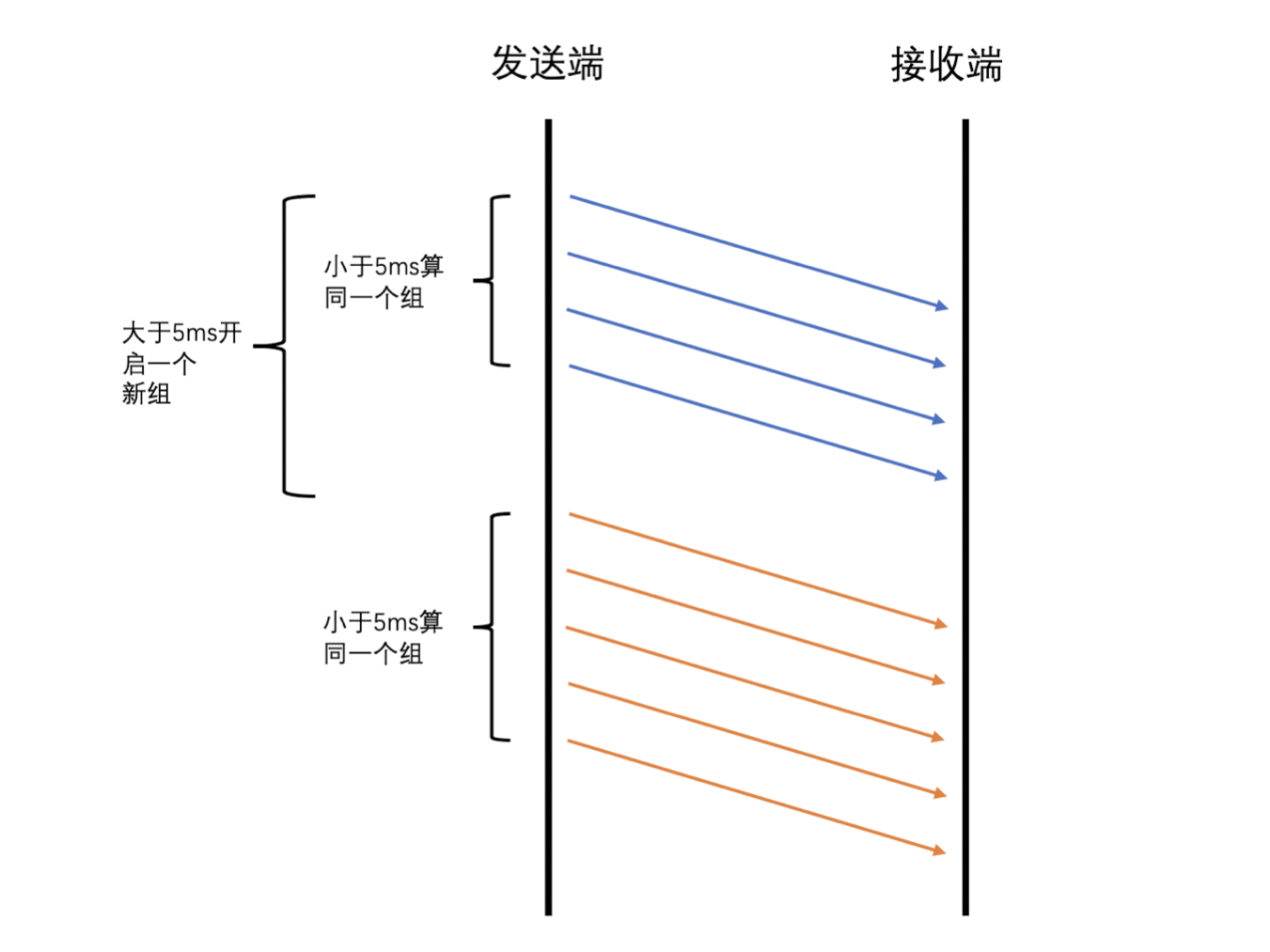
- 接收端收到每一个包的时候也会记录包的包序号和实际的接收时间,每隔一段时间就会将这些统计信息发送到发送端
- 现在的 WebRTC 版本中接收端是通过 RTCP 协议的 Transport-CC 报文反馈接收信息的,这个报文主要包含两个信息:
- 每一个包序号对应的包是不是接收到了
- 实际的这个包相比前一个包的接收间隔
- 现在的 WebRTC 版本中接收端是通过 RTCP 协议的 Transport-CC 报文反馈接收信息的,这个报文主要包含两个信息:
- 如果发送端收到这个报文,就可以知道每一个 RTP 包有没有接收到了。如果没有接收到就是丢包了。同时也可以知道没有丢失的 RTP 包的接收时间
- 发送端可以根据发送历史数据中各个包的发送时间和 Transport-CC 报文中计算得到的各个包的接收时间,来计算出前后两组包之间的发送时长和接收时长
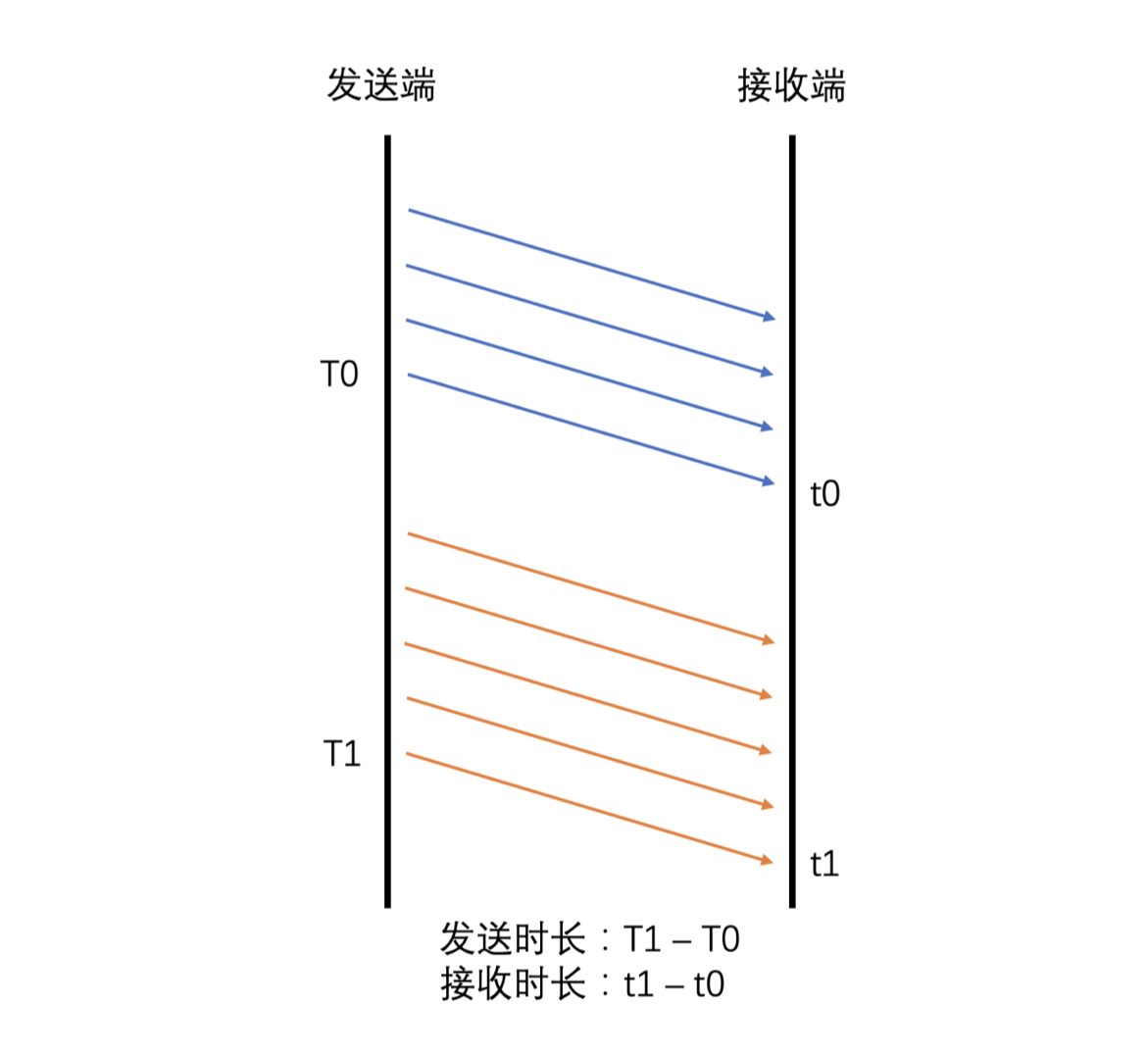
- 有了发送时长和接收时长,将接收时长减去发送时长就是延时 - 如果接收时长大于发送时长,延时就大于 0,说明当前网络有点承受不了当前的发送数据量,产生了缓存,继而产生了延时 - 如果接收时长几乎等于发送时长,延时就几乎为 0,说明当前网络可以承受当前的发送量,因此几乎没有延时 - 如果接收时长小于发送时长,也就是延时小于 0 呢?这种情况比较特殊,一般出现在之前因为网络带宽不够已经缓存了一部分数据,但是网络在明显变好,从而网络设备快速地将缓存中的数据发送出去的时候。这种情况下就会出现接收时长很短,导致接收时长还小于发送时长,这个时候延时就是一个负数
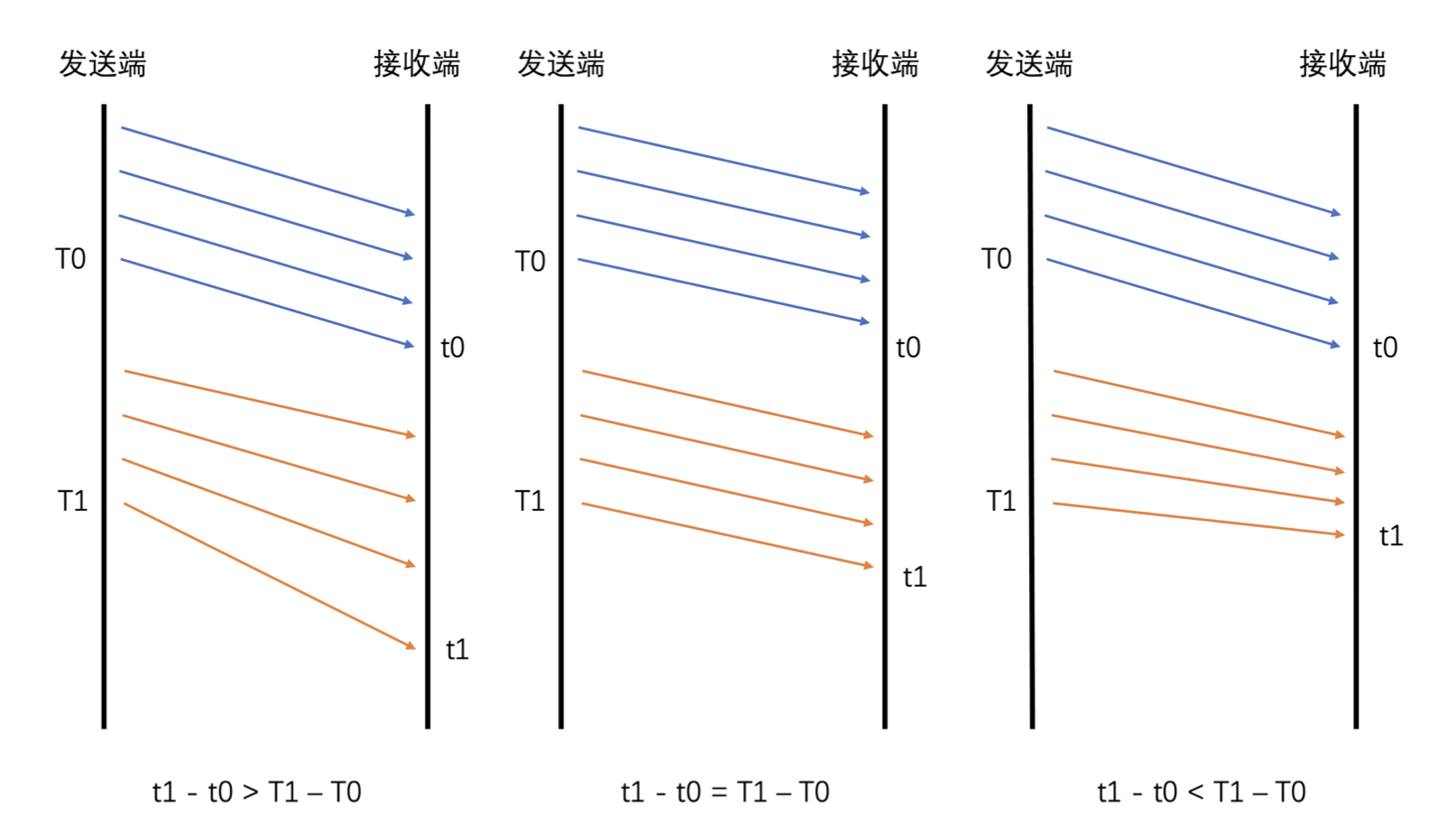
能直接使用延时来判断网络的好坏吗? 不能直接使用这个延时来判断网络的好坏,因为网络变化很快而且存在噪声,有的时候延时会因为网络噪声突然变大或变小。因此,需要通过当前延时和历史延时数据来判断延时变化的趋势,来平滑掉网络噪声引起的单个延时抖动。
- 需要根据当前延时和历史延时的大小来计算延时变化的趋势
- Trendline Filter 中保存了 20 个最近的延时数据,这些延时数据跟前面直接计算的延时还不完全一样。它们包含了两个部分:
- 当前这个 RTP 包组所属的 Transport-CC 报文到达发送端的时间
- 经过平滑后的累积延时,它是通过前面计算得到的延时和历史累积延时加权平均计算之后得到的
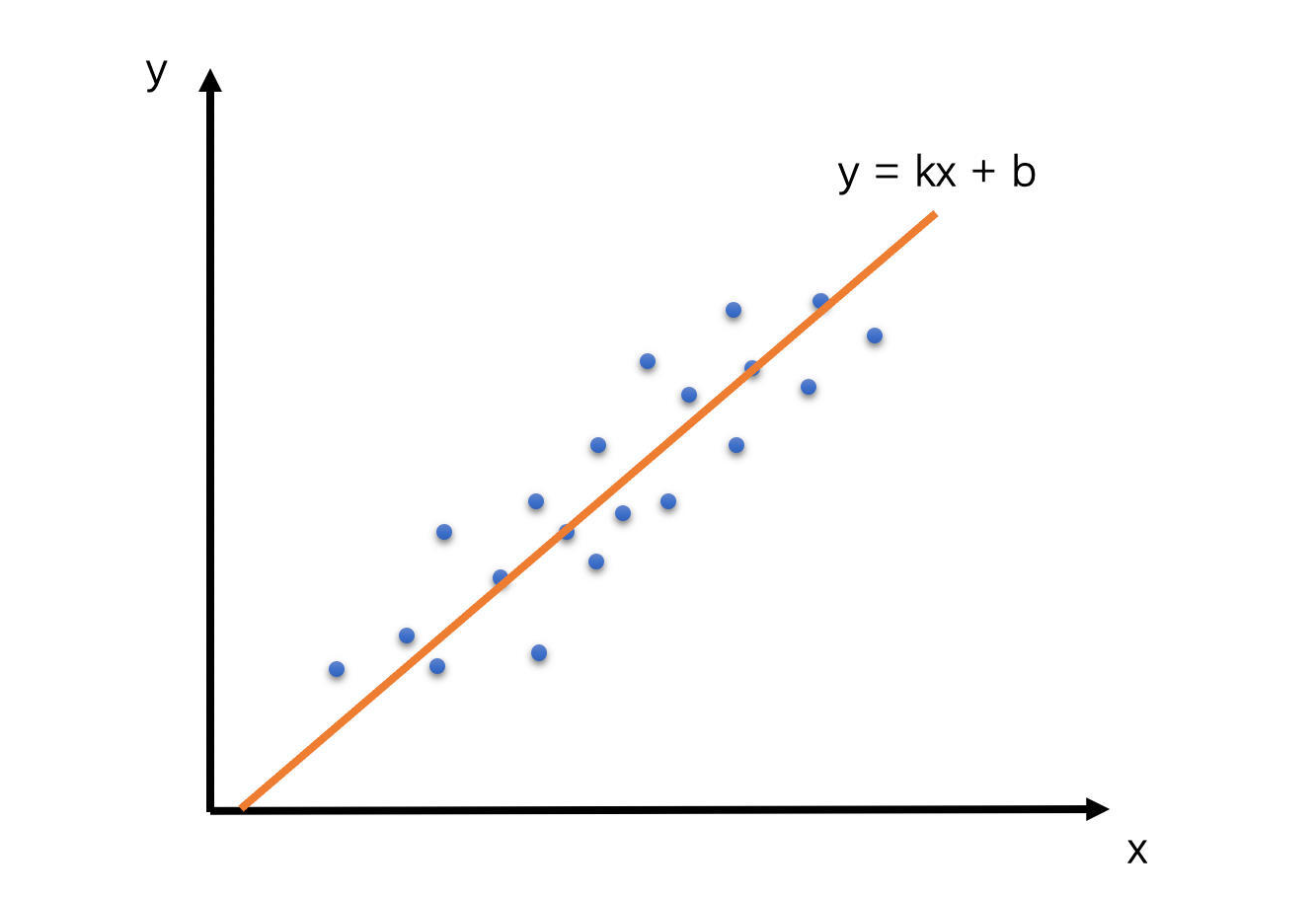
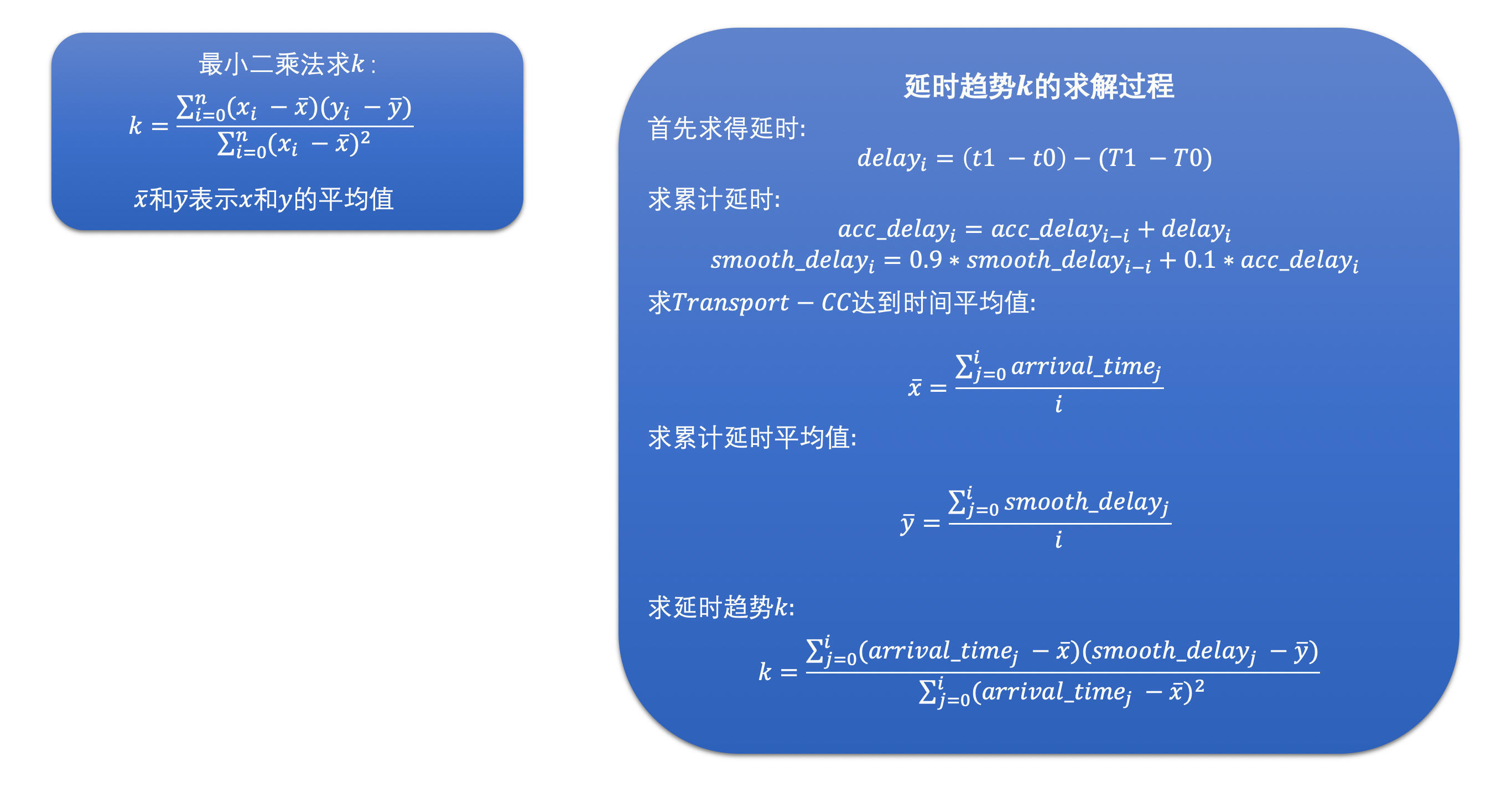
- 在 WebRTC 看来,如果设 RTP 包组所属的 Transport-CC 报文的到达时间为 x,累积延时为 y 的话,那么 x 和 y 应该是呈线性关系,也就是说 y = kx + b
- Trendline Filter 就是使用 20 个延时数据,通过线性回归的方法,求得其中的 k 值,也就是斜率。这个斜率就表示延时变化的趋势。其中线性回归的求解方式用的是最小二乘法。
- 当斜率 k > 0 时,表示有延时;
- 当 k = 0 时,表示几乎没有延时
- 当 k < 0 时,表示不仅没有延时,反而接收速度更快。
- Trendline Filter 中保存了 20 个最近的延时数据,这些延时数据跟前面直接计算的延时还不完全一样。它们包含了两个部分:
- 根据延时变化趋势判断网络状况
- 延时变化趋势还不能直接说明网络当前的变化方向。因为网络是变化无常的,不能因为测到延时稍有变大就认为网络变差,延时稍有变小就认为网络变好。需要一个根据当前延时趋势和延时阈值,来判断网络是不是真的变好和变坏的模块——过载检测器
- 过载检测器有两个主要的工作
- 通过当前的延时趋势和延时阈值来判断当前网络是处于过载、欠载还是正常状态
- 通过当前的延时趋势来更新延时阈值,延时阈值不是静态不变的,阈值是跟着延时趋势不断自适应调整的
- 网络状态的判断其实比较简单,就是将延时趋势 k 乘以一个固定增益 4 和包组的数量(包组数量最大是 60)作为当前的修改后延时值。将当前的修改后延时值跟延时阈值进行比较,然后根据比较的结果来判断网络状态
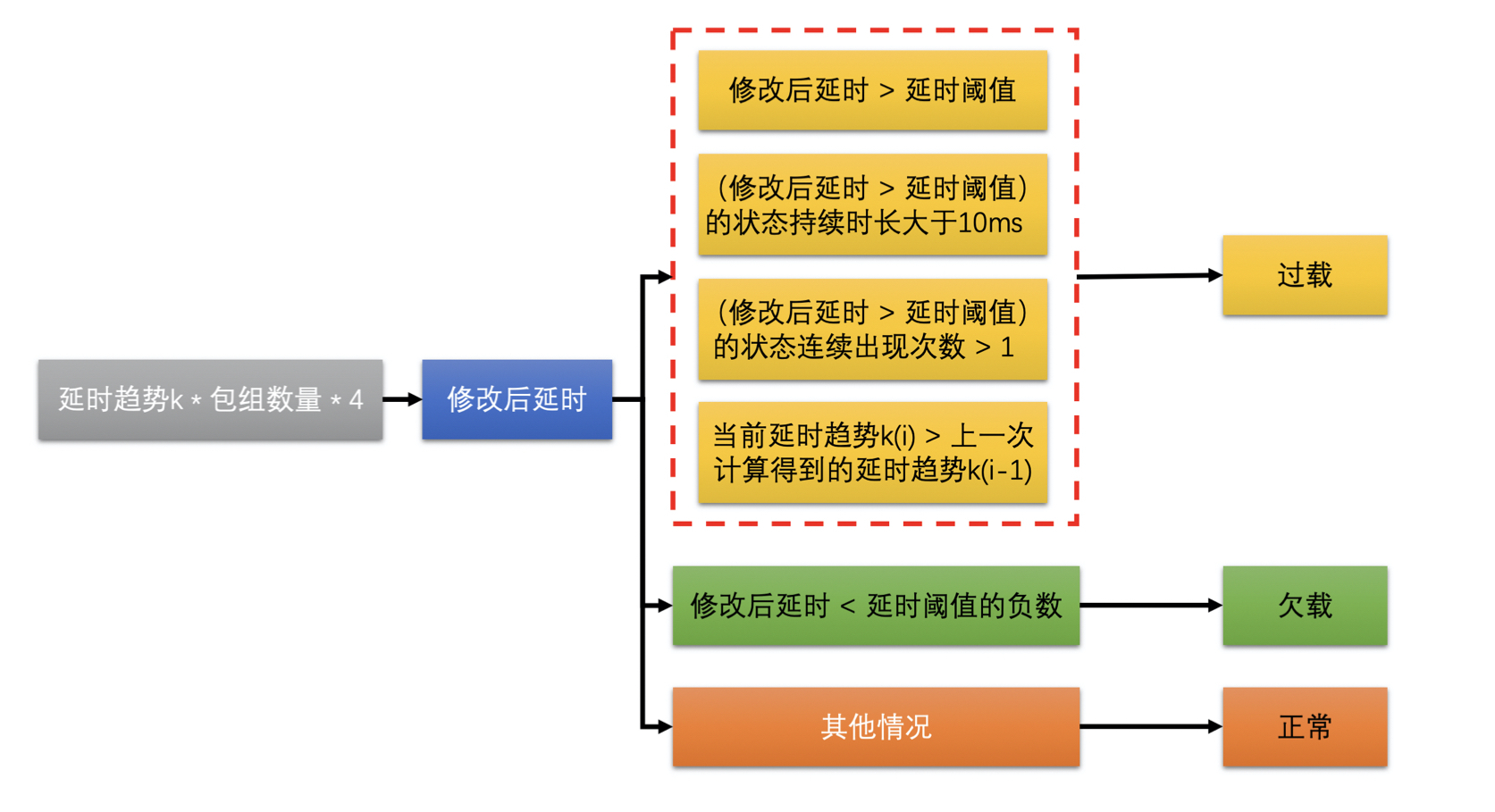
- 延时阈值的更新是因为网络是不断变化的,延时变化也很快,而有的时候延时很大,有的时候又很小。为了防止阈值太大,网络状况检测不够灵敏,同时也防止阈值太小,网络状况检测太敏感了。所以延时阈值会随着当前的延时做缓慢的调整

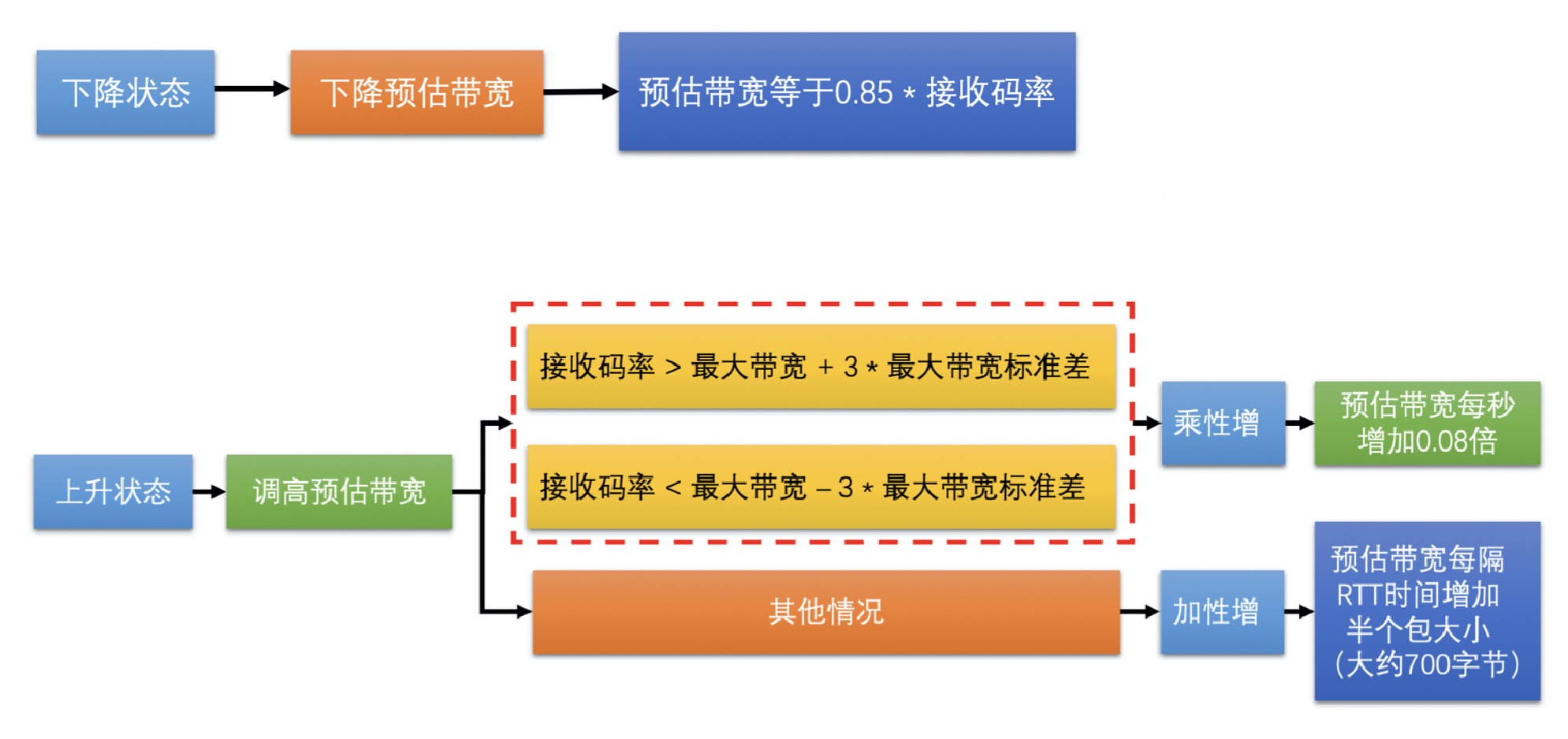
- 根据网络状况调整更新预测带宽值
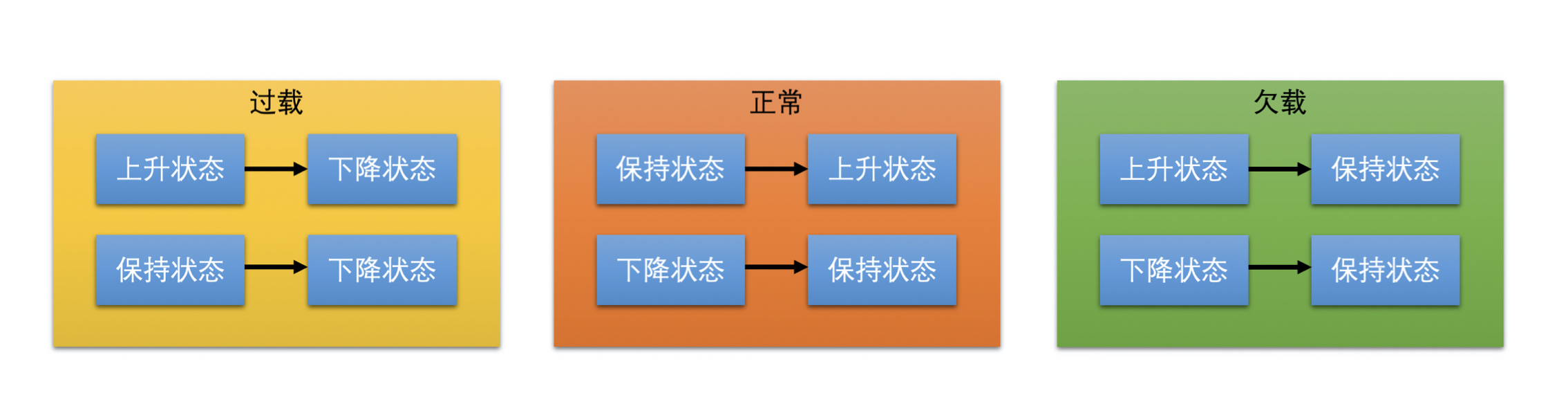
- 速率控制器的主要工作就是更新预测带宽值。它里面维护着一个状态机。
- 状态机主要用来根据过载检测器检测到的网络状态和状态机目前所处的状态,来更新状态机的状态的。
- 状态机有三个状态
- 上升,速率控制器需要提升带宽值
- 保持,需要降低带宽值
- 下降,不更新带宽值
# 基于丢包的带宽预测算法
基于丢包的带宽预测算法相比基于延时的带宽预测算法简单很多,整体思路就是根据 Transport-CC 报文反馈的信息计算丢包率,然后再根据丢包率的多少直接进行带宽调整更新。
- 丢包率计算
- 接收端会将接收到的每一个包的信息放到 Transport-CC 报文中,包括每一个 RTP 包的序号以及这个包有没有接收到。而没有接收到就代表这个包丢失了。

- 带宽调整
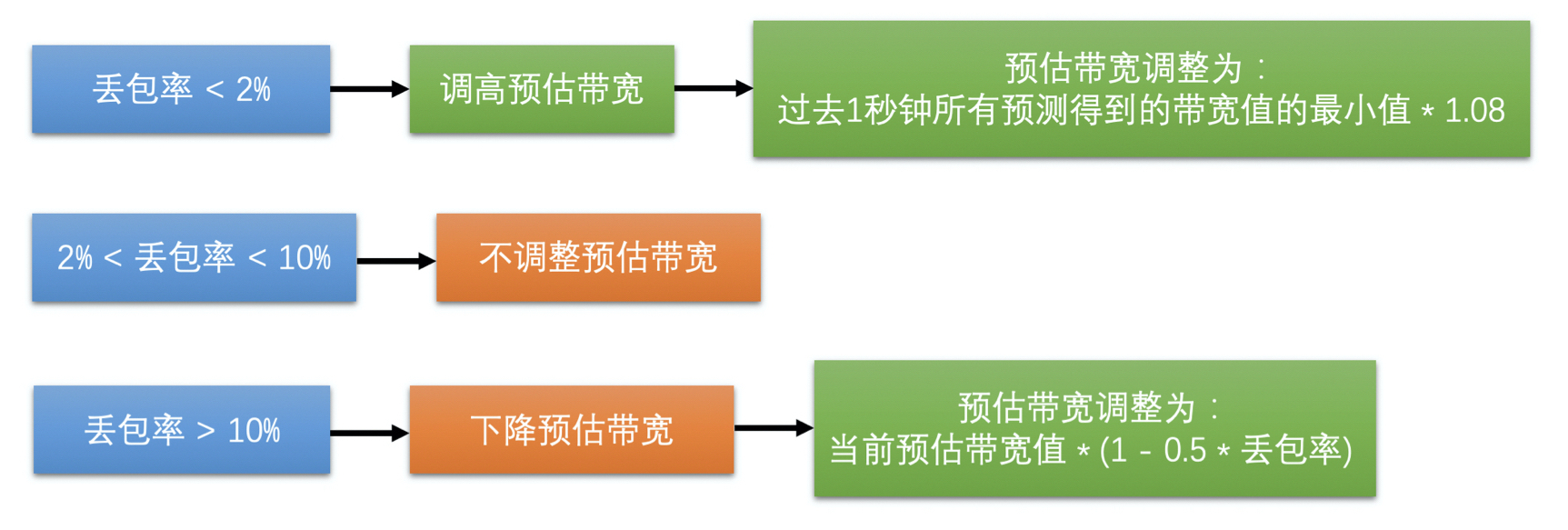
# 最大带宽探测算法
最大带宽探测算法主要过程:
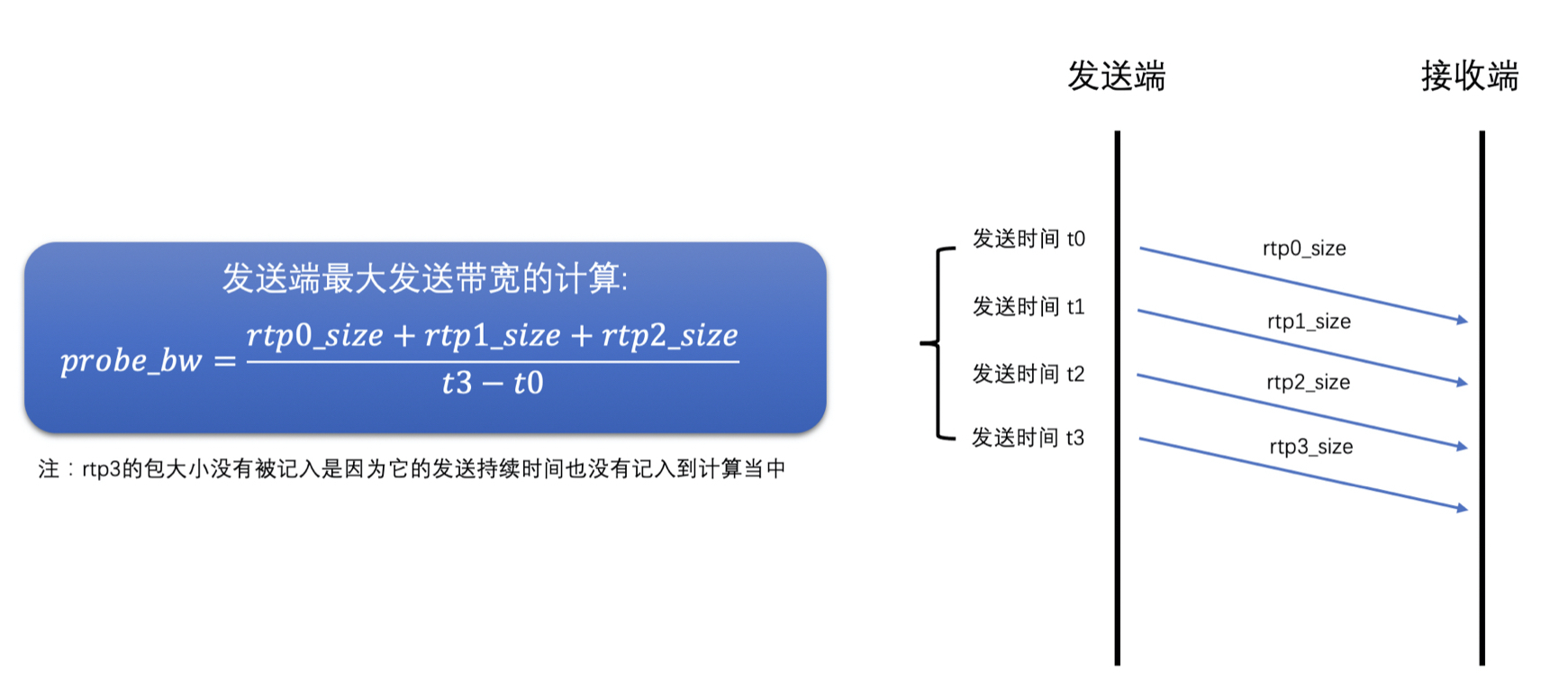
- 发送端设定一个探测的目标带宽,一般设置为当前带宽的 2 倍、3 倍或者 6 倍
- 发送端在发送数据的时候就以这个探测目标带宽的速度快速发送 RTP 包,一般发送时间(探测时间)是 15ms,同时将这段时间用于探测使用的 RTP 包信息保存在发送端
- 并给这些 RTP 包标上是探测包的标记以及探测的 cluster_id,每一次探测使用的 cluster_id 都不同,用于区分每次探测的 RTP 包,防止多次探测时弄混了
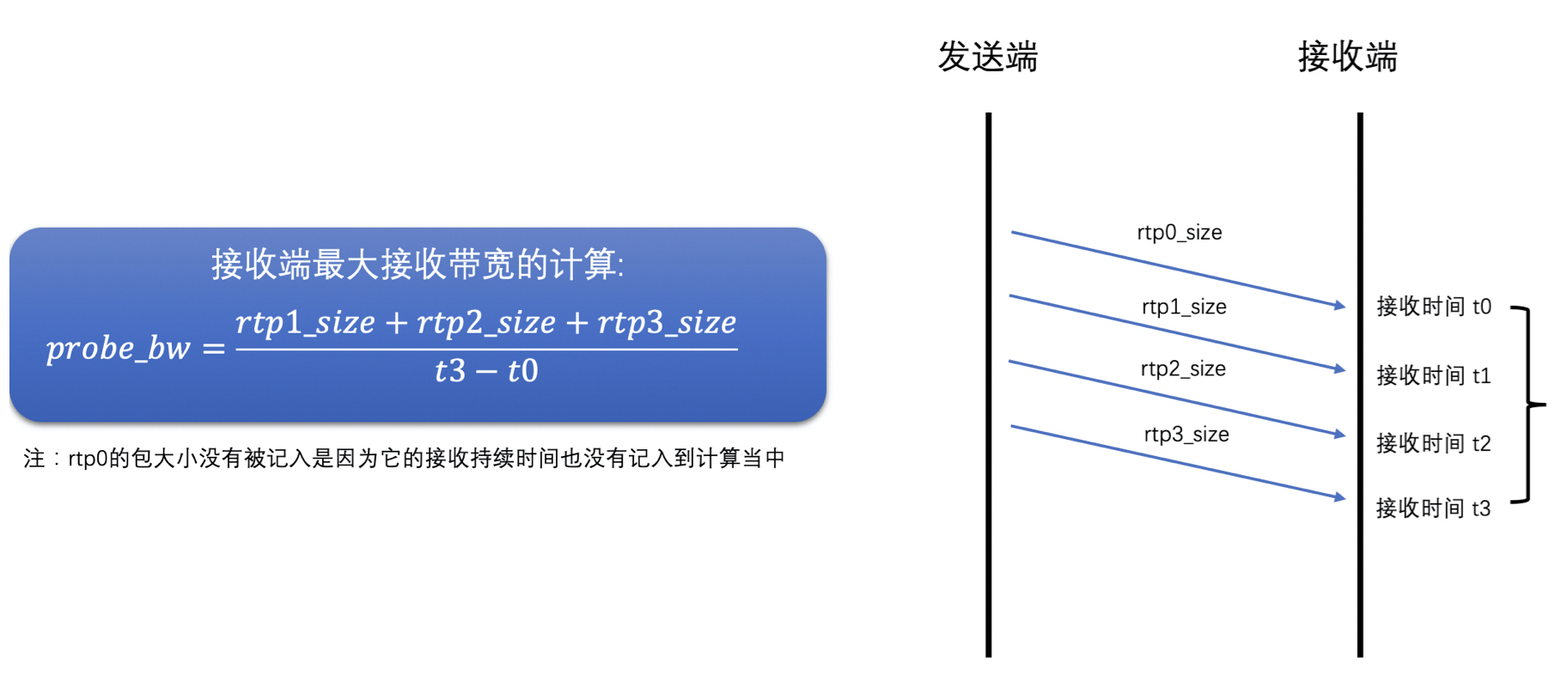
- 接收端并不关注当前包是不是探测包,而是直接统计每一个包的序号和接收时间,将统计结果组成 Transport-CC 报文反馈给发送端
- 发送端接收到 Transport-CC 报文之后,会看报文中的每一个包是不是探测包
- 如果是探测包,就从发送端发送的历史数据中,取出其 cluster_id 和发送时间,并且从 Transport-CC 报文中得到接收时间,再把这些信息送入到探测带宽计算器中,当探测带宽计算器中相同 cluster_id 的 RTP 包信息数量达到一定值之后,就可以计算最终探测到的带宽值了
# 最终的预估带宽值
WebRTC 中带宽预测主要分为基于延时的带宽预测算法、基于丢包的带宽预测算法以及最大带宽探测算法。
基于延时的带宽预测算法主要是解决网络中含有大缓冲网络设备场景的带宽预测。基于丢包的带宽预测算法主要是解决网络中有小缓冲或无缓冲网络设备场景的带宽预测。最终预估带宽等于这两者预测到的带宽值中的最小值。
为了防止出现发送码率大幅低于实际网络带宽而导致网络带宽预估偏低的问题,还引入了最大带宽探测算法,可以周期性的探测网络的最大带宽。如果当前网络不是处于过载状态同时又探测到了最大带宽的话,就将预估带宽更新为探测到的最大带宽。
带宽预测的作用
如果不能够很好地预测出实际带宽,那有可能引起数据超发,导致发送数据量大于实际网络的承受能力,继而引起视频画面的延时和卡顿;也有可能预测的带宽太低,导致发送的数据量远低于实际网络的承受能力,不能很好地利用网络带宽,最终导致视频画面模糊和很明显的马赛克现象。
# 码控算法
好的带宽预测算法还只是开始,如何在预测出带宽之后能够控制数据的发送码率,使其尽量符合当前的网络带宽也是非常重要的。如果没有做好发送码率的控制,想发送多少数据就发送多少数据的话,那跟没有网络带宽预测是一样的效果。要不就画面卡顿,要不就很模糊。
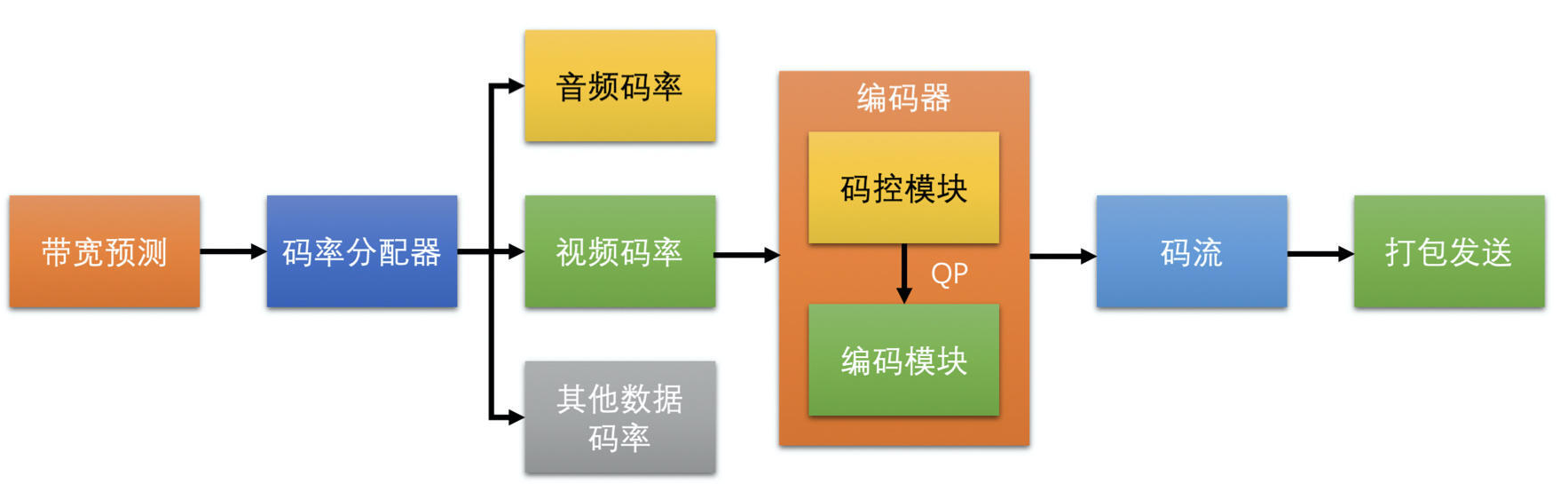
# 码控原理
码率控制,是编码器的一个重要模块,主要的作用就是用算法来控制编码器输出码流的大小。虽然它是编码器的一个非常重要的部分,但是它并不是编码标准的一部分,也就是说,标准并没有给码控设定规则。平时用的编码器的码控都是编码器程序自己实现的。
码控的原理就是为每一帧编码图像选择一个合适的 QP 值的过程。
当一帧图像的画面确定了之后,画面的复杂度和 QP 值几乎决定了它编码之后的大小。由于编码器无法决定画面的复杂度,因此,码控的目标就是选择一个合适的 QP 值,以此来控制编码后码流的大小。当然有些码控算法是可以直接外部指定使用哪个 QP 值去编码的,就不需要编码器的码控算法去做决策了。
# 码控类型
- VBR(Variable Bit Rate),动态码率
- 编码器输出码率随着原始视频画面复杂度的变化不断的变化
- 当画面复杂或者说运动比较多的时候使用的码率会比较高
- 当画面比较简单的时候使用的码率会比较低
- 主要的目标是保证视频画面质量,因此比较适合视频点播和短视频场景使用
- 编码器输出码率随着原始视频画面复杂度的变化不断的变化
- CQP(Constant QP),恒定 QP
- 从头到尾每一个画面都是用同一个 QP 值去编码
- 画面复杂时,残差比较大,相同 QP 值做量化之后的残差还是比较大的,编码之后的图像大小就会比较大
- 画面简单时,残差很小,同一个 QP 值量化之后残差可能很小,甚至都为 0 了,编码之后的大小就会很小
- CQP 一般用来衡量编码算法的性能,在实际工程当中不会使用
- 从头到尾每一个画面都是用同一个 QP 值去编码
- CRF(Constant Rate Factor),恒定码率因子
- x264 默认的码控算法,与 CQP 不同的是它的 QP 是会变化的
- 画面运动大时,会根据具体算法提高 QP 值
- 画面运动小时,会降低 QP 值
- 思想是:运动很大的时候,人眼不太关注细节,因此 QP 可以稍微大一点;运动比较小的时候,人眼会将注意力放在细节上面,因此 QP 稍微小一点
- 相比 CQP,CRF 能够更省码率一些
- CRF 码控总体上得到的编码后图像的大小,还是随着图像的画面复杂度在变化的
- x264 默认的码控算法,与 CQP 不同的是它的 QP 是会变化的
- CBR(Constant Bit Rate),恒定码率
- 用户需要设置一个目标码率值给编码器,编码器在编码的时候不管图像画面复杂或简单、运动多或运动少的时候,都尽量使得输出的码率接近设置的目标码率
- 非常适合 RTC 场景,因为 RTC 场景希望编码的码率跟实际预测的带宽值接近,不能超出目标码率太多,也希望能够尽量有效地利用可用带宽,不能太低于目标码率,从而尽量保证编码后图像画面清晰
- 在 RTC 场景中,会将预估带宽分出一定比例给视频数据,并将这部分带宽值当作目标码率设置给编码器
- 需要编码器的码控算法,能够在各种网络状况下和各种画面变化的情况下,都能使得输出的码率尽量接近于当前预估带宽得到的目标码率
# CBR 码控算法
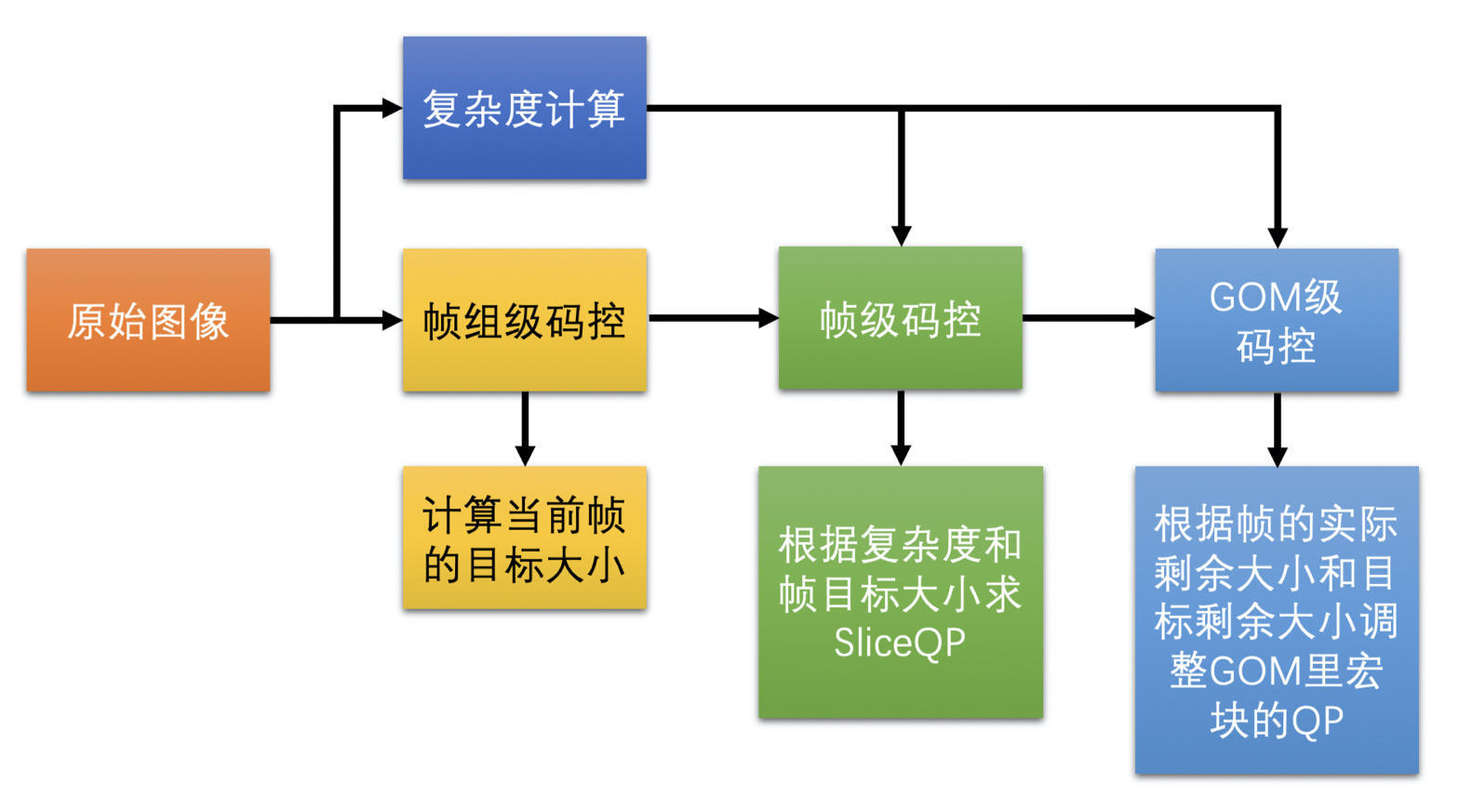
为了实现恒定码率,需要做很多个步骤,一步步的将输出码率逼近目标码率,而不是一步到位确定 QP 就可以实现恒定码率的目标的。所以,会分很多级做调整,分别是帧组级、帧级、宏块组 GOM(Group of MB)级。
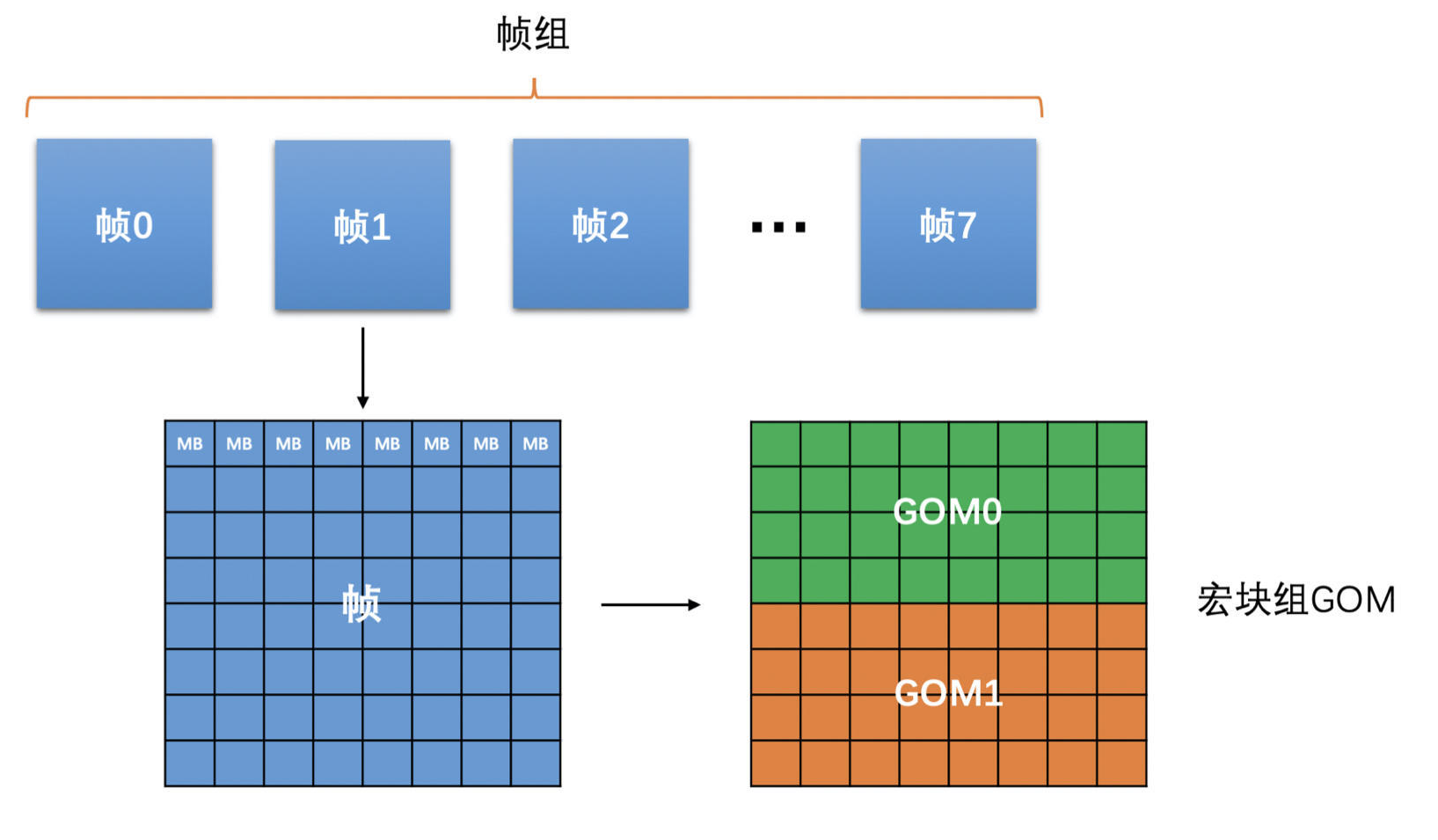
具体处理过程如下:
- 先确定帧组级(帧组就是将连续的几个帧组成一组,一般选择 8 个帧一组)的输出大小尽量接近目标码率
- 确定组内的每一帧具体应该分配多少的大小(目标帧大小),才能保证帧组最后输出的大小可以达到要求
- 再根据这个目标帧大小,确定一个帧级的 QP 值
- 确定帧内的宏块组(宏块组就是连续的几行宏块组成的一组宏块,一般可以选 4 行宏块)应该分配多少大小,来保证当前帧最后的输出大小能接近于目标帧大小
- 再确定宏块的 QP 值
# 复杂度求解
需要能够保证在不同的画面复杂度和不同的运动程度的情况下,并且输出码率都要尽量接近目标码率的话,还需要先计算得到当前帧的复杂度。复杂度能够大概衡量当前帧在做完预测之后残差值的总体大小的。残差的大小和 QP 值决定了最后图像编码后的大小。
根据帧类型复杂度求解可以分为两种算法:
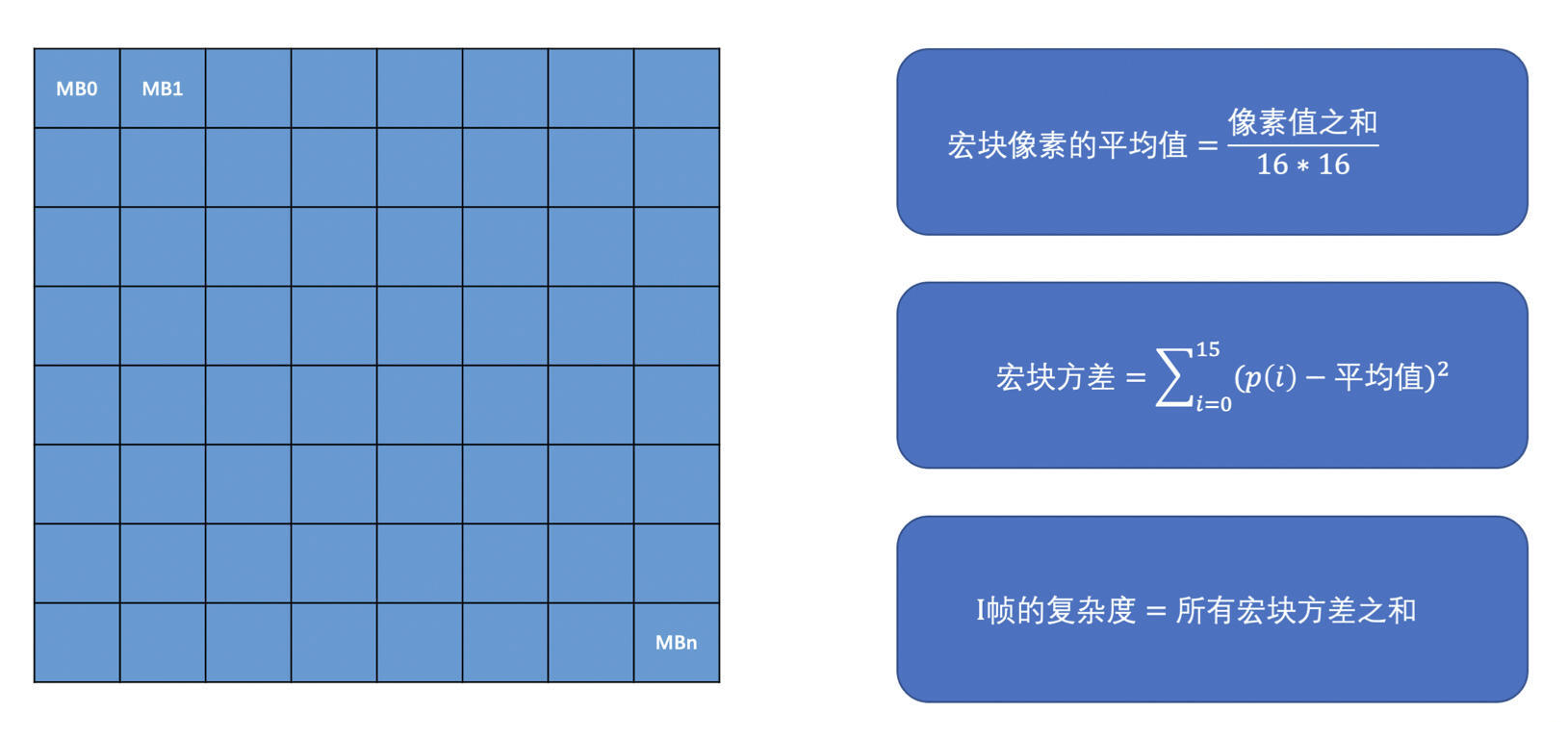
- I 帧的复杂度计算
- I 帧只做帧内预测,而帧内预测是用编码块周围已编码的像素来预测当前编码块的像素值的
- 方差是一个比较能够表示 I 帧复杂度的值
- 为方差越大,表示帧的内部变化程度越剧烈,而用周围的像素去预测当前编码块的像素值的话,有很大的可能会产生较大的残差
- 方差越小的话,说明帧内部变化比较小,因此周围像素有较大的概率能够比较好的预测出待编码块的像素值
- 计算 I 帧的复杂度的时候,是求每一个宏块的方差,最后将帧的所有宏块的方差之和作为帧的复杂 度
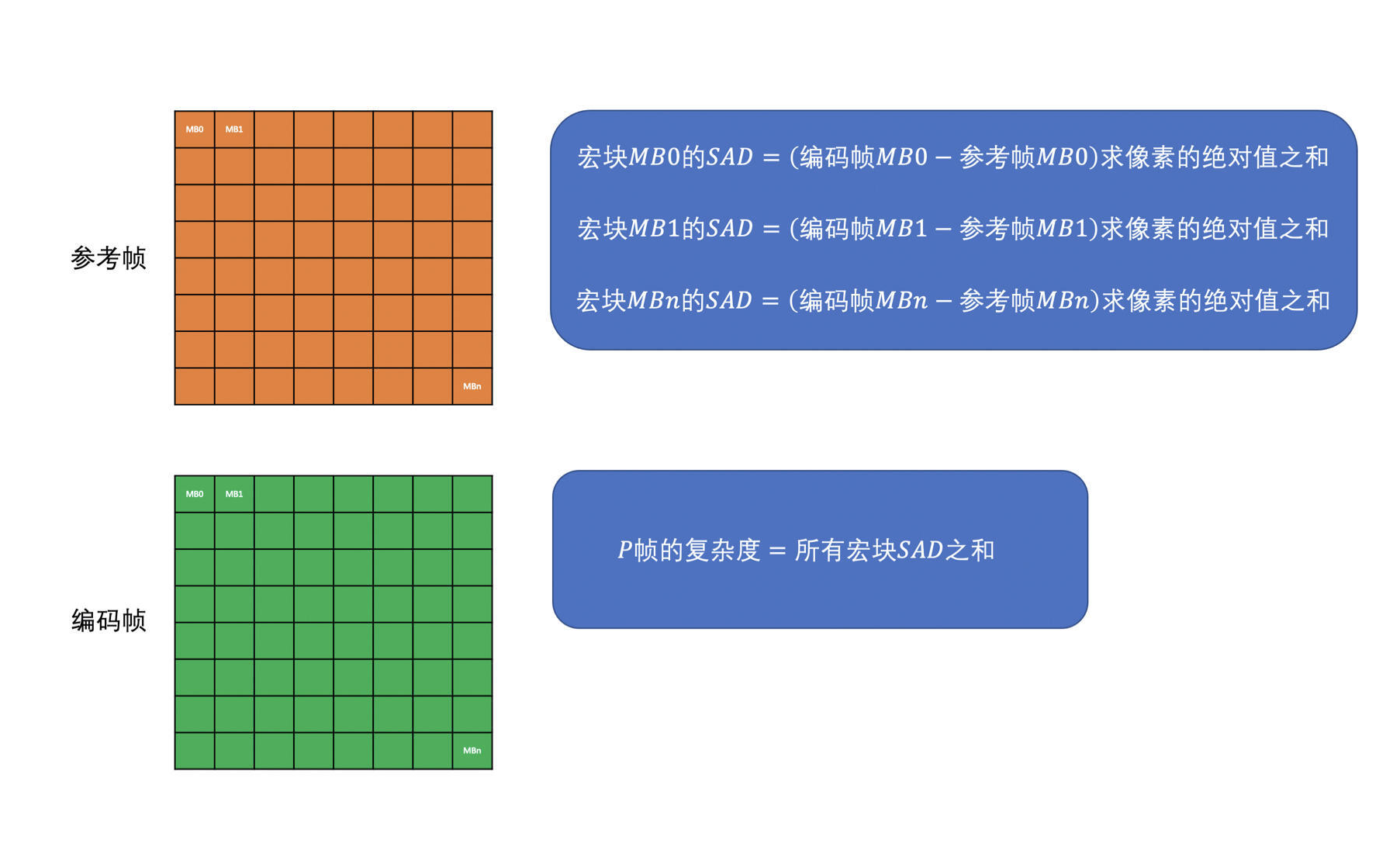
- P 帧的复杂度计算
- P 帧,主要是做帧间预测
- 帧间预测是去参考帧中找一个块来作为当前帧编码块的预测块,因此,选择使用将当前帧的宏块减去参考帧对应位置的宏块,求 SAD 值,并将所有宏块的 SAD 值加起来作为 P 帧的复杂度
# 帧组级
CBR 虽然是恒定码率,但它的意思是保证一段时间内的输出码率接近目标码率,比如说 1 秒或者几百毫秒,而不是保证每一帧输出都严格接近目标码率的。
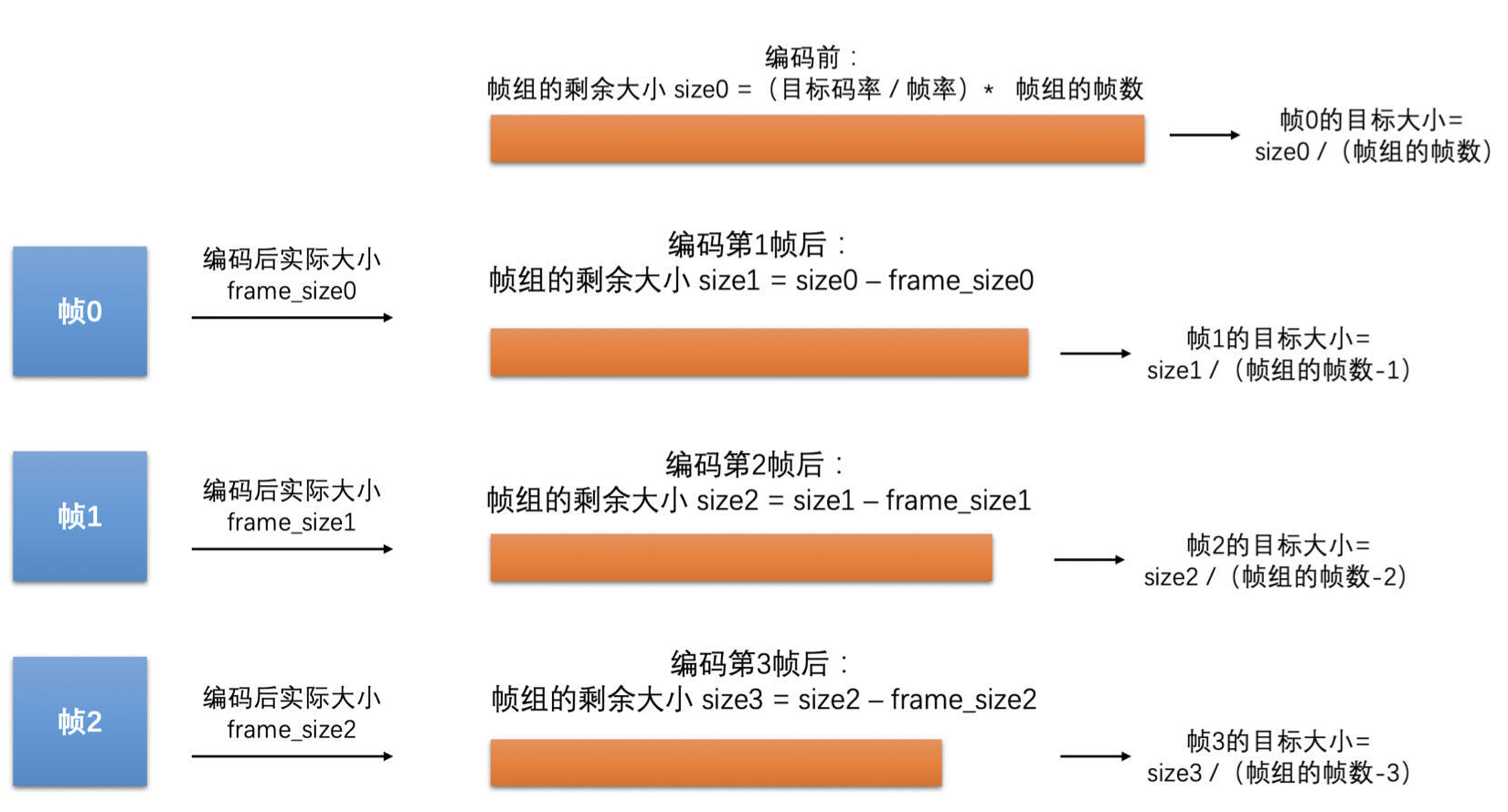
算法是根据一段时间内前面已经编码的结果来调节还未编码帧的 QP,从而来达到一组帧的输出大小尽量接近目标码率的。因此,在开始的时候,需要根据目标码率来确定帧组的目标大小,之后再确定帧组内每一帧的目标大小。
先根据设定的目标码率和帧率值将两者相除,就可以计算得到每一帧的平均大小。然后将帧组的帧数(一般 8 个帧作为一组)乘以帧的平均大小,就是帧组的目标大小了。
在编码器刚开始编码的时候,帧组的剩余大小就是帧组的目标大小。当编码帧组中第一帧的时候,将帧组的剩余大小除以帧组的帧数,就得到帧组中第一帧的目标帧大小。当帧组中的第一帧编码完成之后,需要用第一帧的实际编码后的大小来更新帧组的剩余大小。随着帧组中的一帧帧不断编码,不断更新帧组的剩余大小,不断调整帧的目标大小。
# 帧级
根据前面计算得到的当前编码帧的帧复杂度和目标帧大小,再加上前面已经编码完成了的帧的复杂度和编码使用的 QStep(与 QP 一一对应)以及使用这个 QStep 编码之后实际的编码大小来计算当前帧的 SliceQP 。

大体思想:一帧编码后的大小应该是和帧的复杂度成正比的,并且跟帧使用的 QStep 是成反比的。
# GOM 级
在开始编码一个 GOM 之前,需要计算一下帧的实际剩余大小和帧的目标剩余大小。帧的实际剩余大小是用帧的目标大小减去帧中已编码 GOM 的实际大小。再使用帧的实际剩余大小加上前一个 GOM 的实际编码大小,减去该 GOM 的目标大小,就是帧的目标剩余大小。
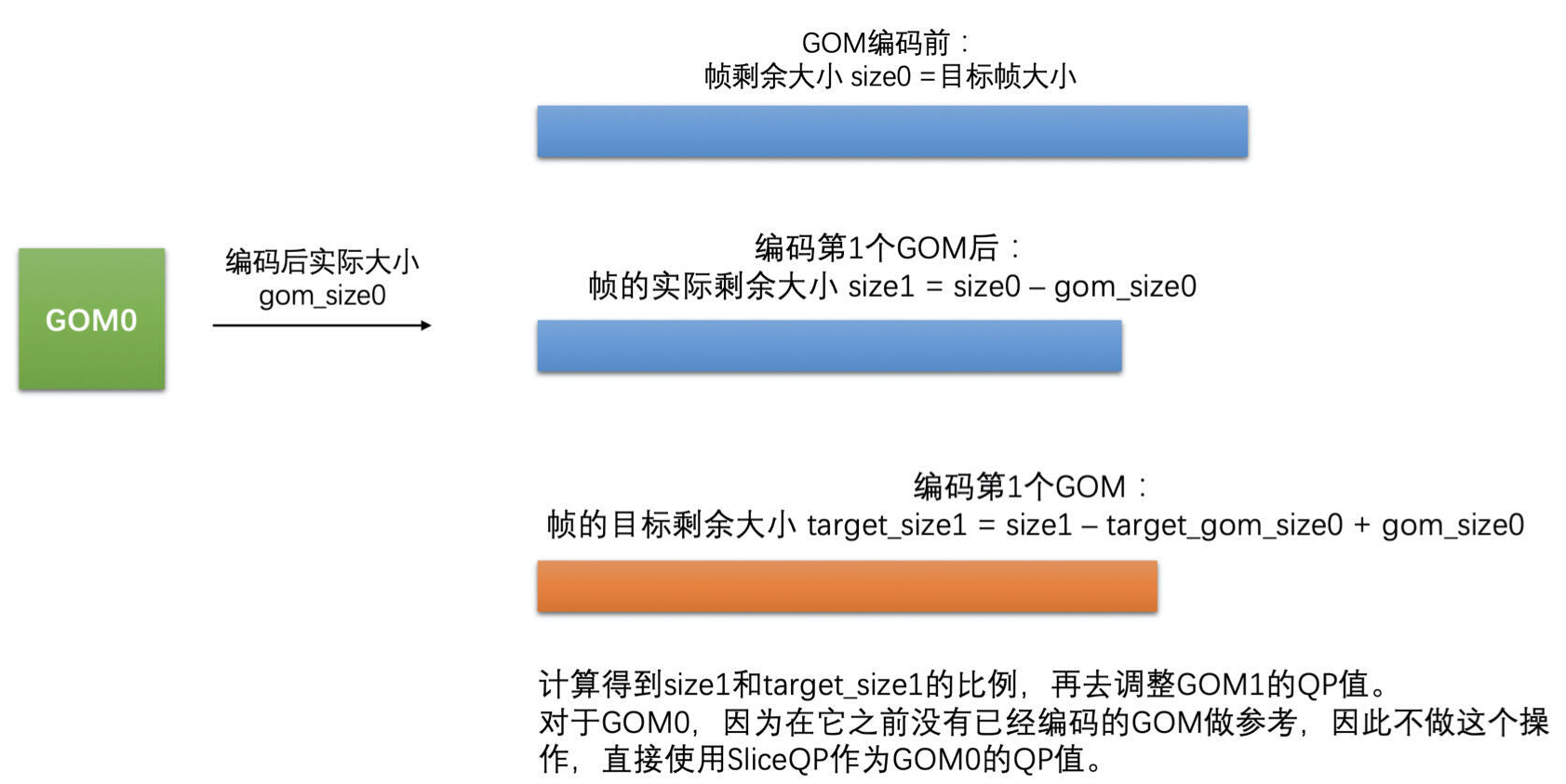
还有一个步骤需要做,就是需要计算一下当前 GOM 的目标大小,以备下一个 GOM 编码的时候做 GOM 级码控计算的时候使用。

CBR 码控算法的整体流程
# Jitter Buffer
在实际情况中,很多时候还会遇到各种各样的卡顿和花屏的问题。Jitter Buffer 模块,是好几个卡顿和花屏问题的处理模块。
Jitter Buffer 工作在接收端,主要功能就是在接收端收到包之后进行组帧,并判断帧的完整性、可解码性、发送丢包重传请求、发送关键帧请求以及估算网络抖动的。

# 卡顿问题
一般来说,人眼在帧率达到 10fps 并且均匀播放时就不太能看出来卡顿了。如果两帧之间的播放时间间隔超过了 200ms,人眼就可以明显看出卡顿了。
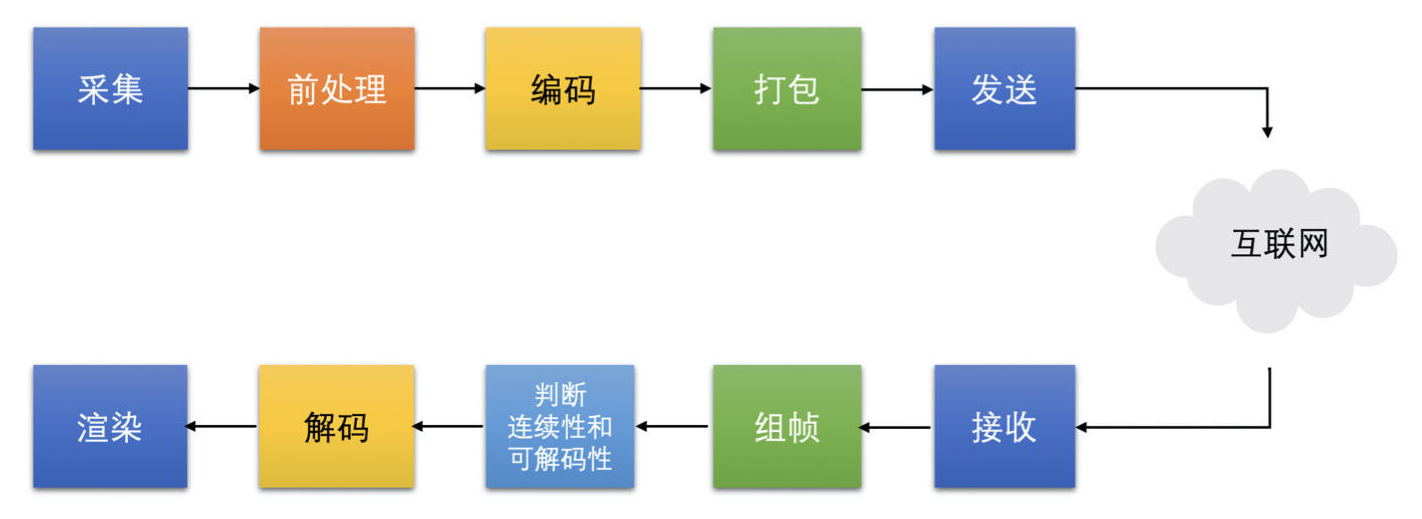
采集到渲染这条链路中每一个都可能引起卡顿问题:
- 帧率不够
- 如果实际采集到的帧率或者设置的帧率本身就只有 5fps,即便是均匀播放,两帧之间的间隔也会达到 200ms,这种情况下肯定会出现卡顿
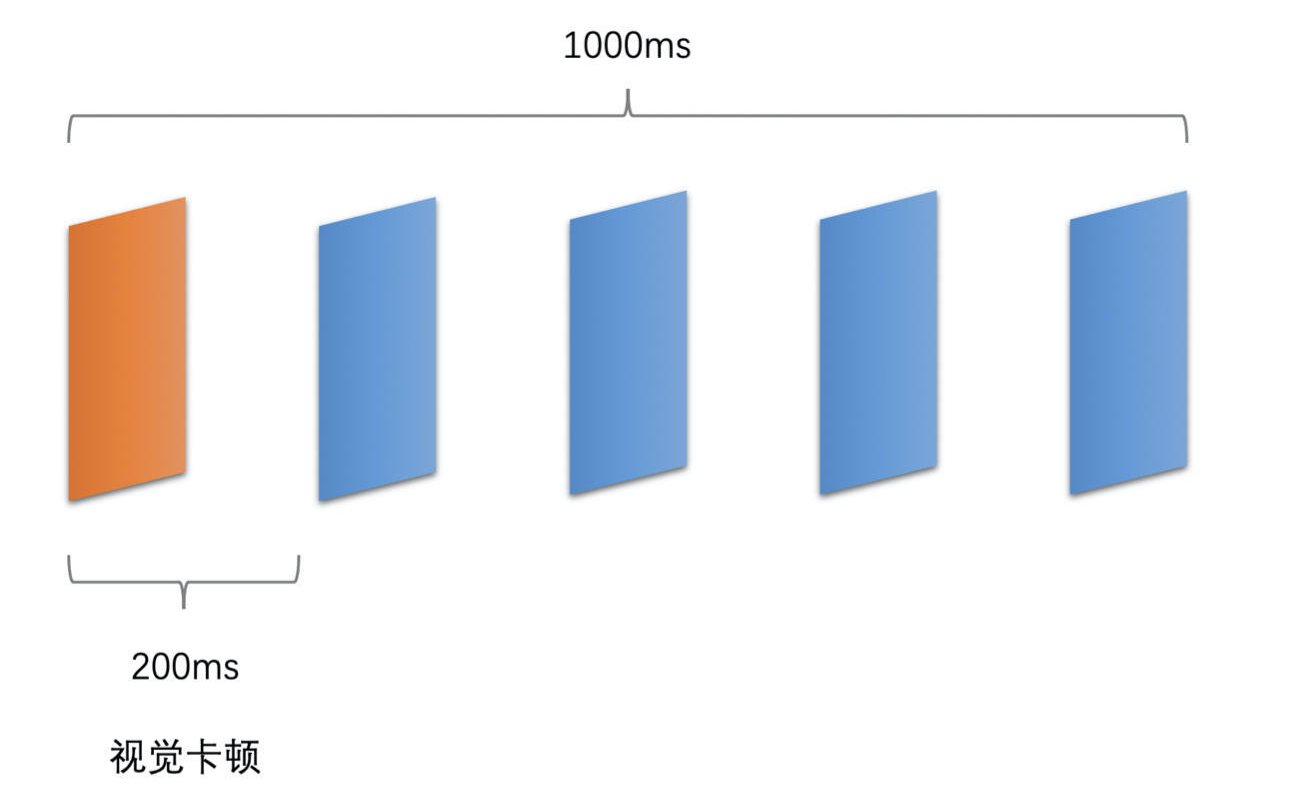
- 解决方法就是提高帧率了,如提高到 15fps 或者更高
- 机器性能不够,导致前处理或编码耗时过长
- 在实时通话场景中,画面是需要实时地做前处理(美颜等操作)并编码之后发送到对端进行解码播放的
- 如果本身机器性能不够,而画面分辨率又很高,那么这可能会导致前处理一帧或者编码器编码一帧的耗时很高
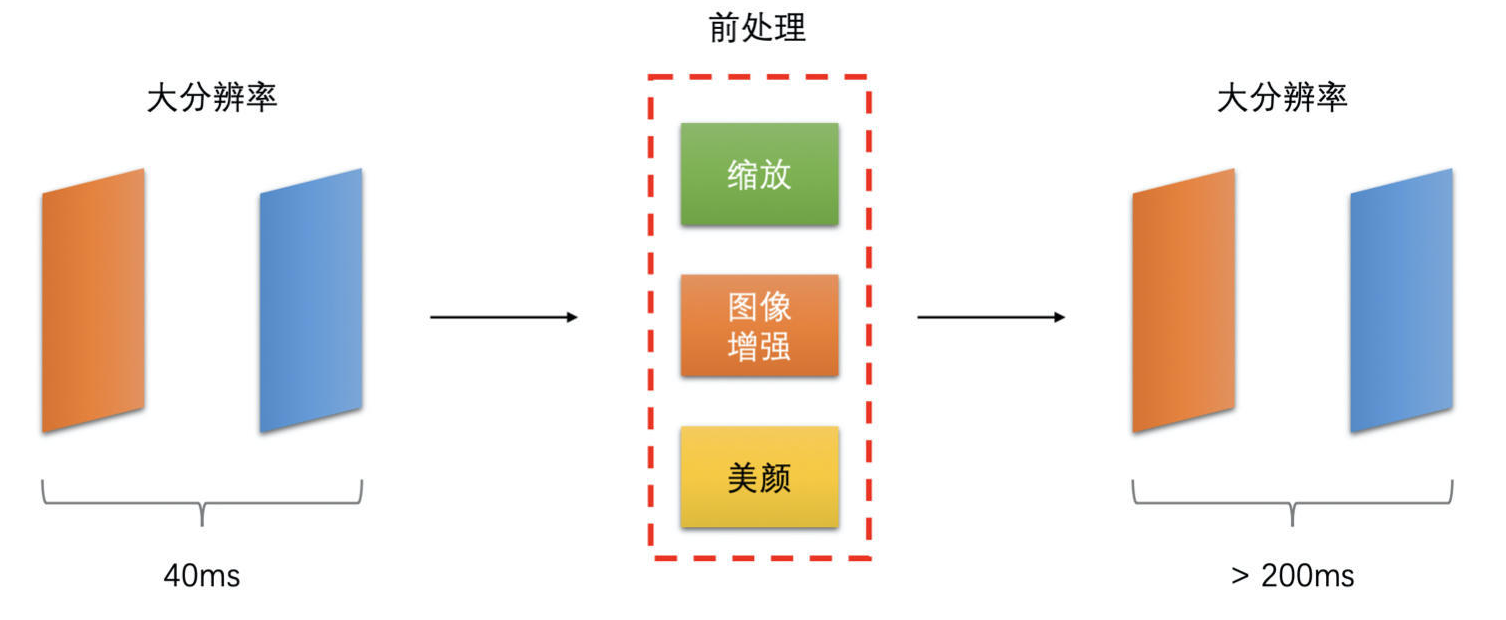
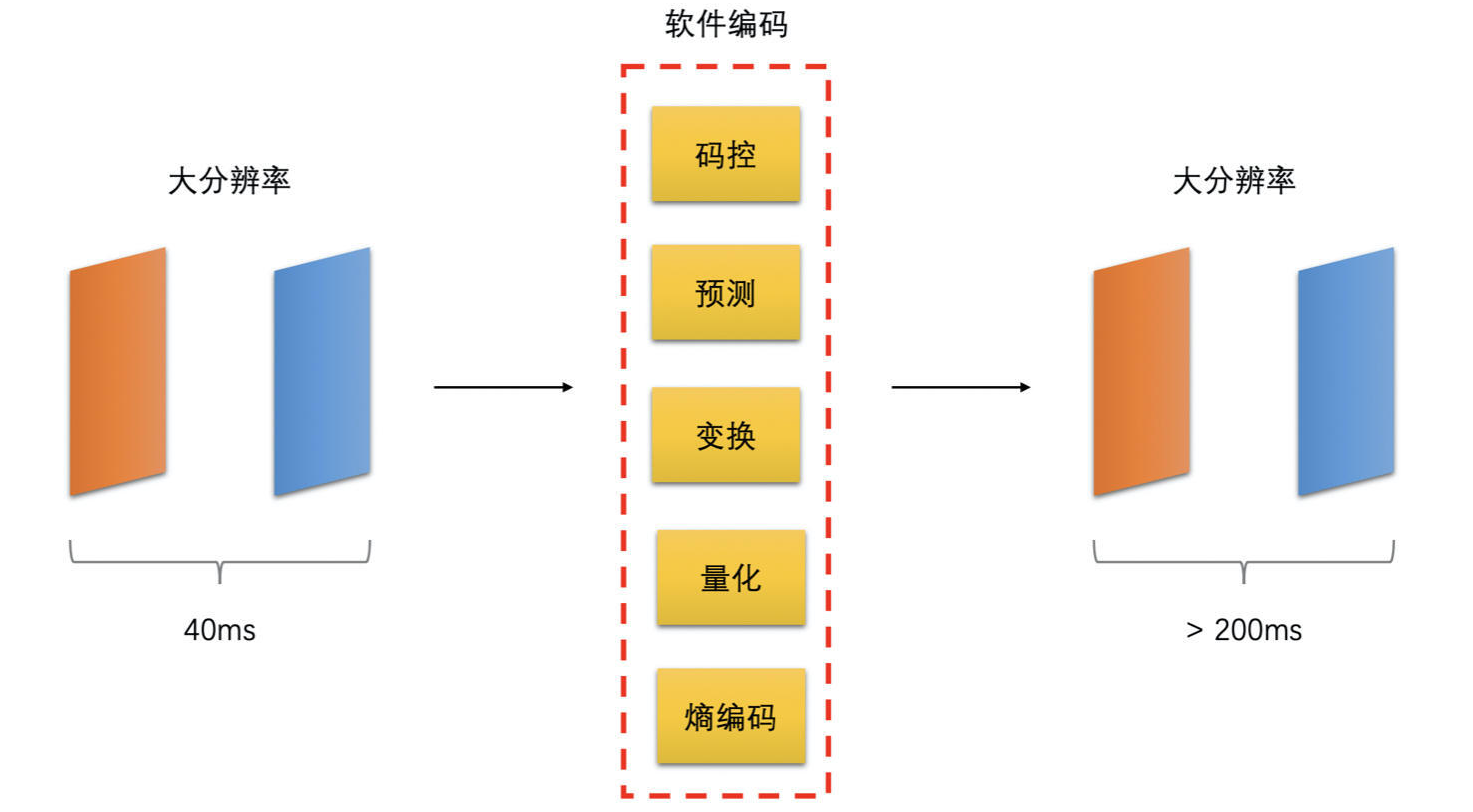
- 这种情况下,即便是采集的帧率很高,但是前处理和编码操作机器处理不过来,从而最后导致两帧被发送出去的间隔也会很高,这时发送到对端,对端就可能会出现明显的卡顿
- 可以在高分辨率的时候尽量使用 GPU 做前处理,并使用硬件编码或者将软件编码设置为快速档加快处理的速度
- GPU 做前处理和硬件编码消耗 CPU 比较小,并且速度更快
- 软件编码设置为快速档时很多费时间的编码工具都被关闭了,因此可以提高编码的速度
- 注意,这会导致压缩率下降
- 编码器输出码率超过实际网络带宽
- RTC 实时通话场景中卡顿问题最常见的根因
- 出现的时候往往会引起比较长时间的卡顿,有可能持续 1 ~ 2 秒钟时间
- 有时网络突然变差,从而网络预估出来的带宽很小,但是实际播放的画面很复杂,且需要的编码码率又比较高,这样就比较容易出现发送码率大于实际带宽的问题
- 对于有缓冲区的网络设备,一开始会将包放在缓冲区,且当缓冲区放不下了还是会丢包
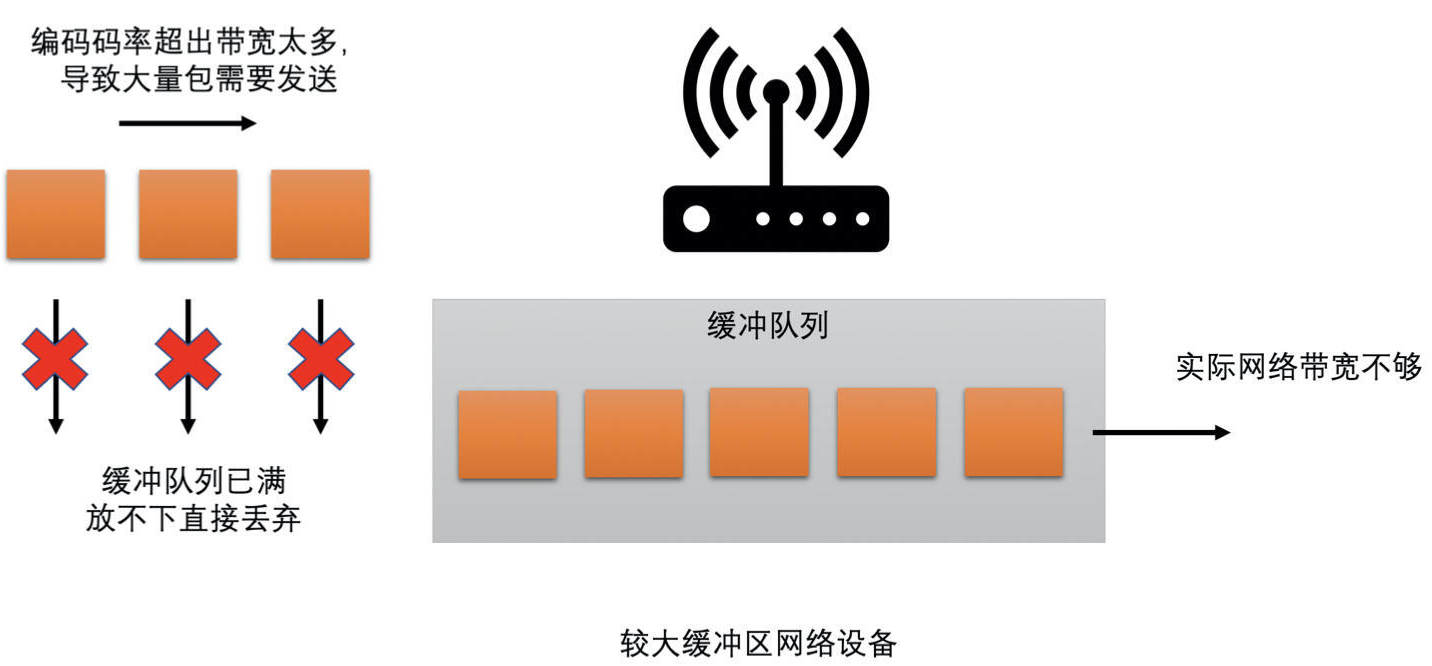
- 对于没有缓冲区的网络设备,直接丢包
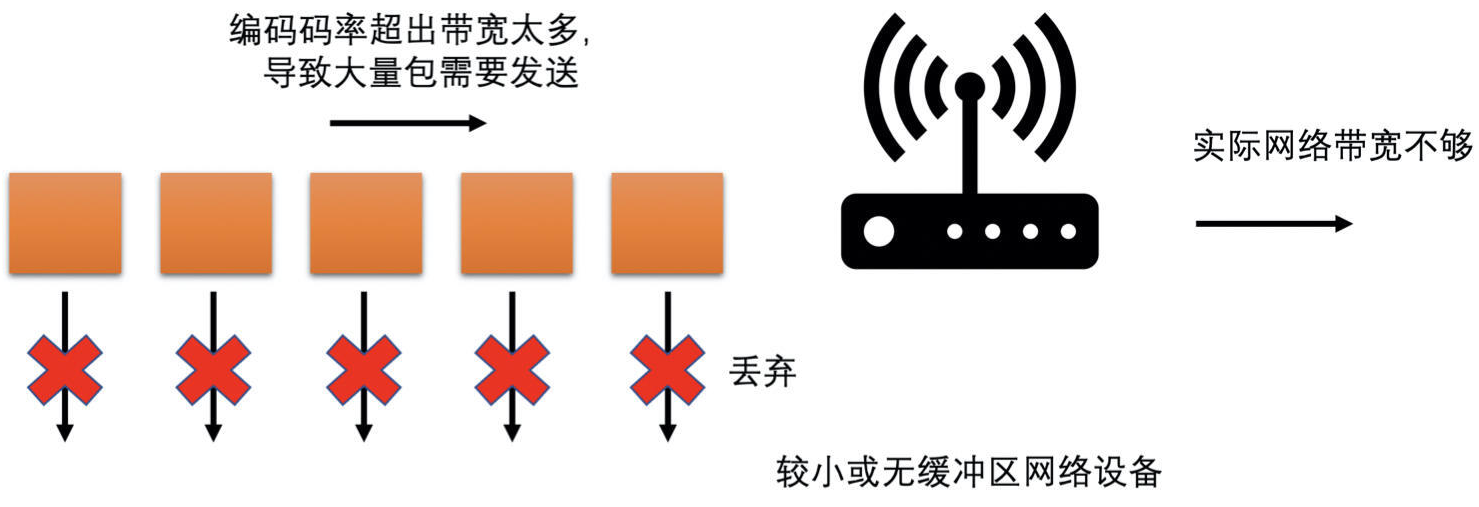
- 当包被丢弃了,对端就不能完整地恢复出一帧图像了。而且,当一帧图像不能解码,那么之后所有参考它的图像就都不能解码
- 在 RTC 场景中,一般使用连续参考的参考帧结构,就是后面的 P 帧参考它的前一帧,这也就会导致在下一个 IDR 帧到来之前画面都会卡死,这样卡顿的时间就会很长
- 需要对发送码率做严格的限制,防止它超过预估带宽,需要编码器的输出码率要能够贴合预估带宽
- 在 RTC 视频通话场景下最好选择 CBR 的码控算法,从而保证输出码率能够比较好地贴合预估带宽
- RTC 实时通话场景中卡顿问题最常见的根因
- 复杂帧编码后过大或 I 帧比较大
- 如果一次性将大帧打包出来的所有包都直接发送到网络中,则会在一瞬间加剧网络的负担,从而容易引起网络丢包,继而引起卡顿的可能
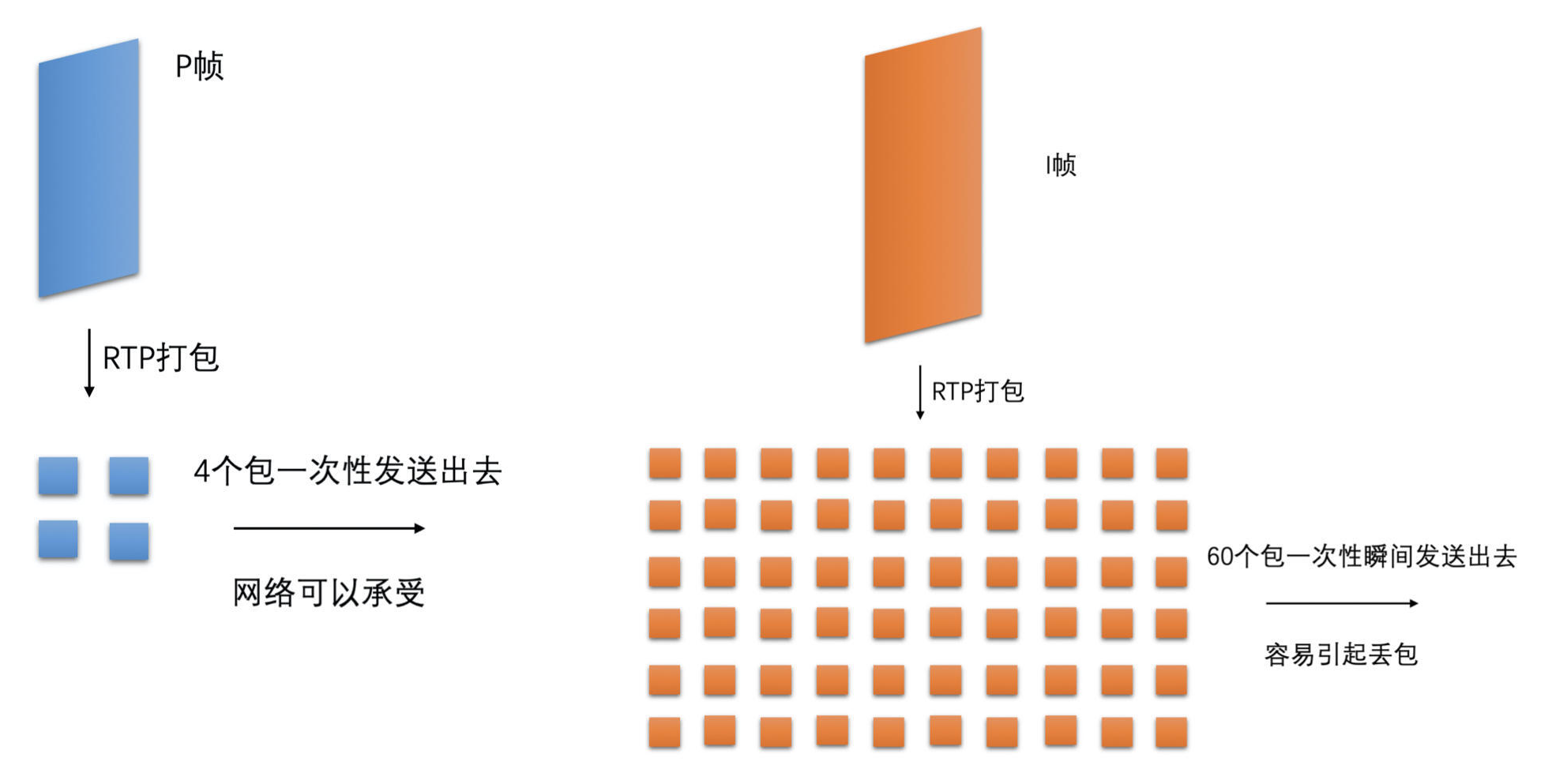
- 为了能够减小这种大帧带来的瞬时网络波动,可以在编码打包之后、发送之前,加一个平滑发送的模块来平滑地发送视频包
- 在 WebRTC 中叫做 PacedSender(节奏发送器)
- 主要的工作原理就是编码输出的码流打包之后先放到它的缓冲区中,而不是直接发送
- 之后它再按照预估带宽大小对应的发送速度,将缓冲区中的数据发送到网络当中
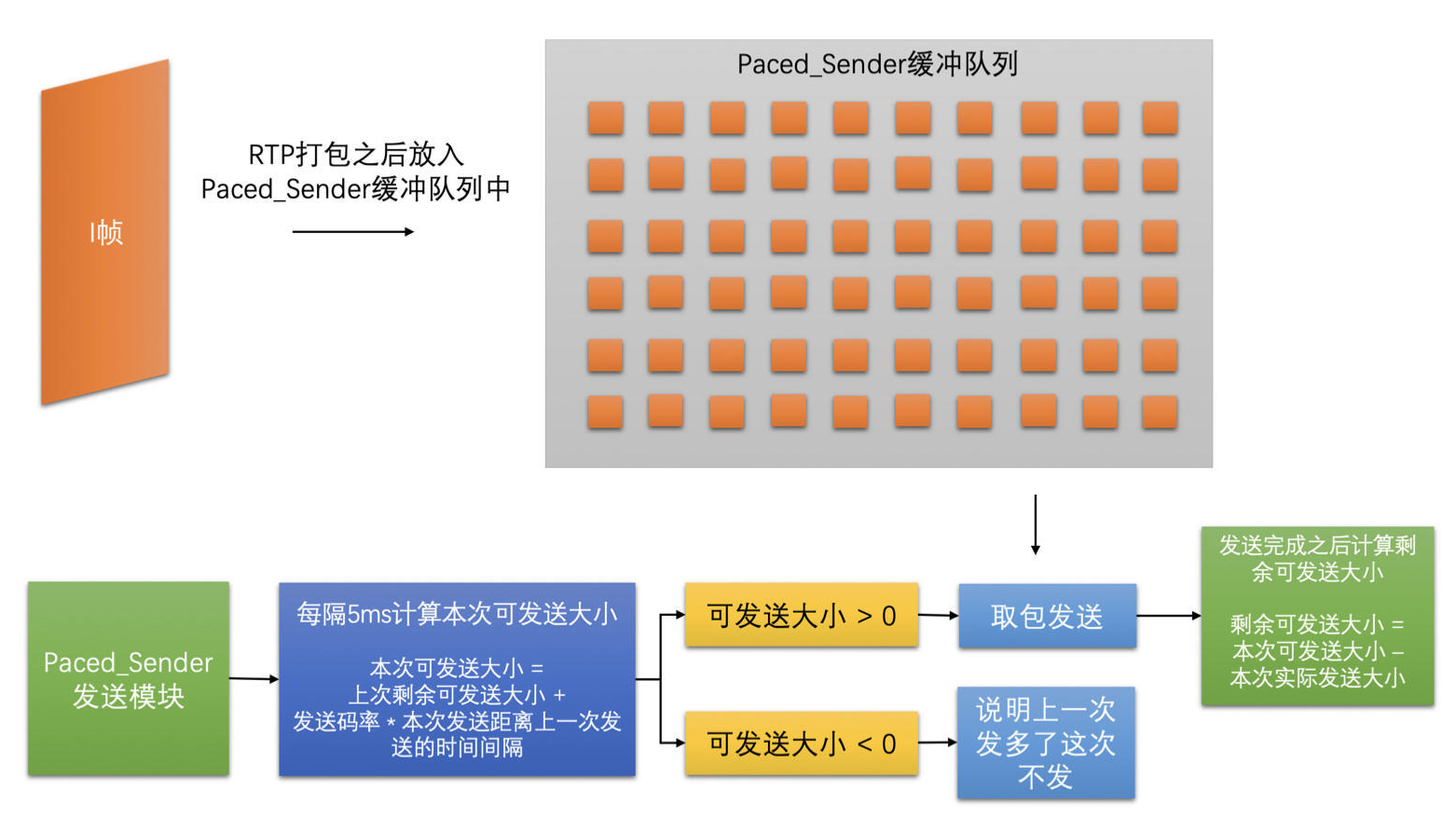
- PacedSender 是通过控制实际发送码率来平滑发送的,这样能防止编码输出码率超过网络带宽太多,直接将包一次性发送到网络导致卡顿
- 要注意,如果编码器输出码率差网络带宽太多,也会导致 PacedSender 缓冲太多数据包,从而引起延时太长
- 编码器码控还是需要贴合网络预估带宽的,PacedSender 大多时候是用来防止一两帧编码后太大引起数据量突增造成丢包
- 在 WebRTC 中叫做 PacedSender(节奏发送器)
- 网络本身的丢包率
- 有时网络变化太快了或者处在一个无线网络环境下,就是会有一定的丢包概率
- 如果真的出现丢包了,那么必须想办法将包恢复,其中,最常用的方法就是丢包重传
- 丢包重传请求策略是在 Jitter Buffer 里面实现的
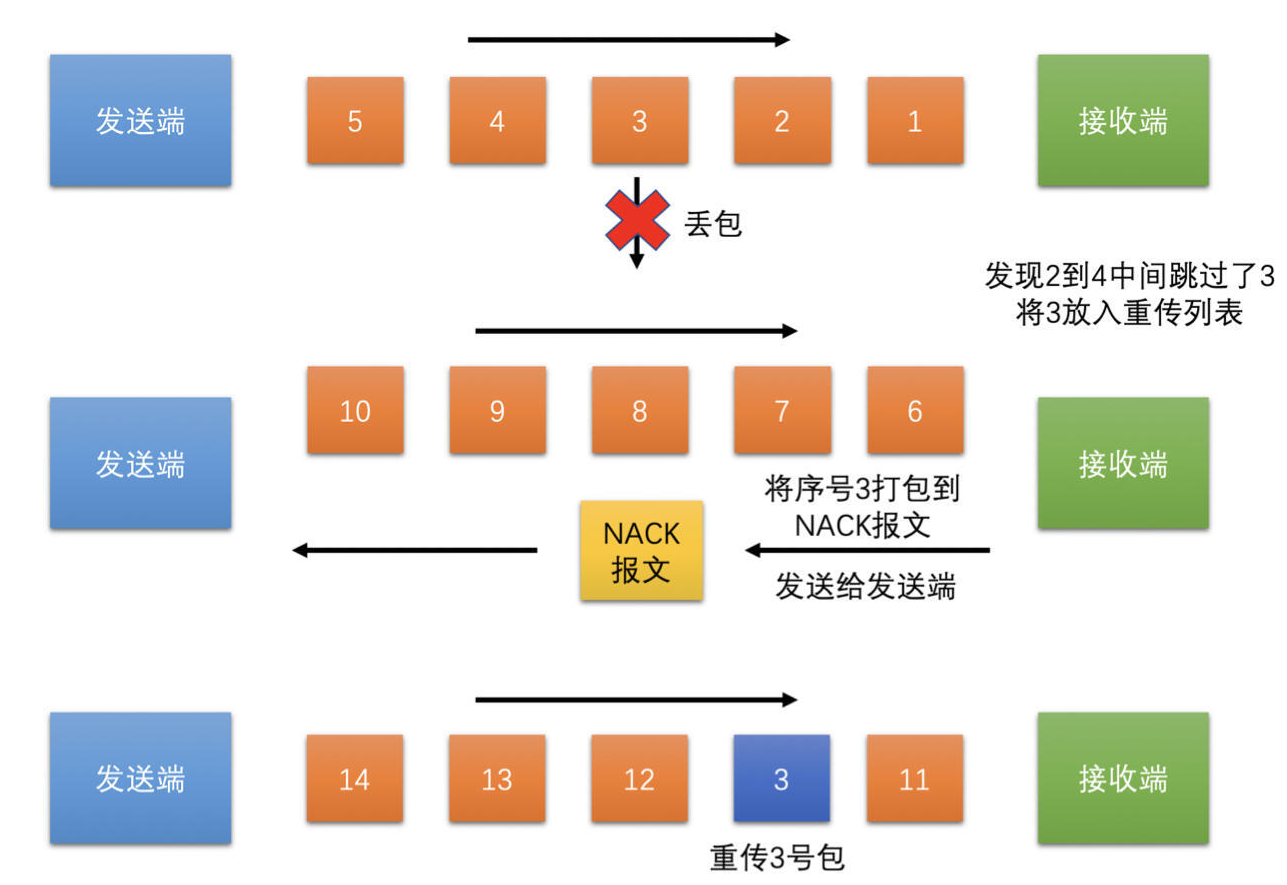
- 重传也没有收到包 -有时会有极端情况出现,前面策略都用上了,还是出现了有包没有收到,导致帧不完整,继而导致没有帧可以解码成功的话
- 此时需要使用 关键帧请求,也叫 I 帧请求,它使用 RTCP 协议中的 FIR 报文,这个策略也是工作在 Jitter Buffer 中的
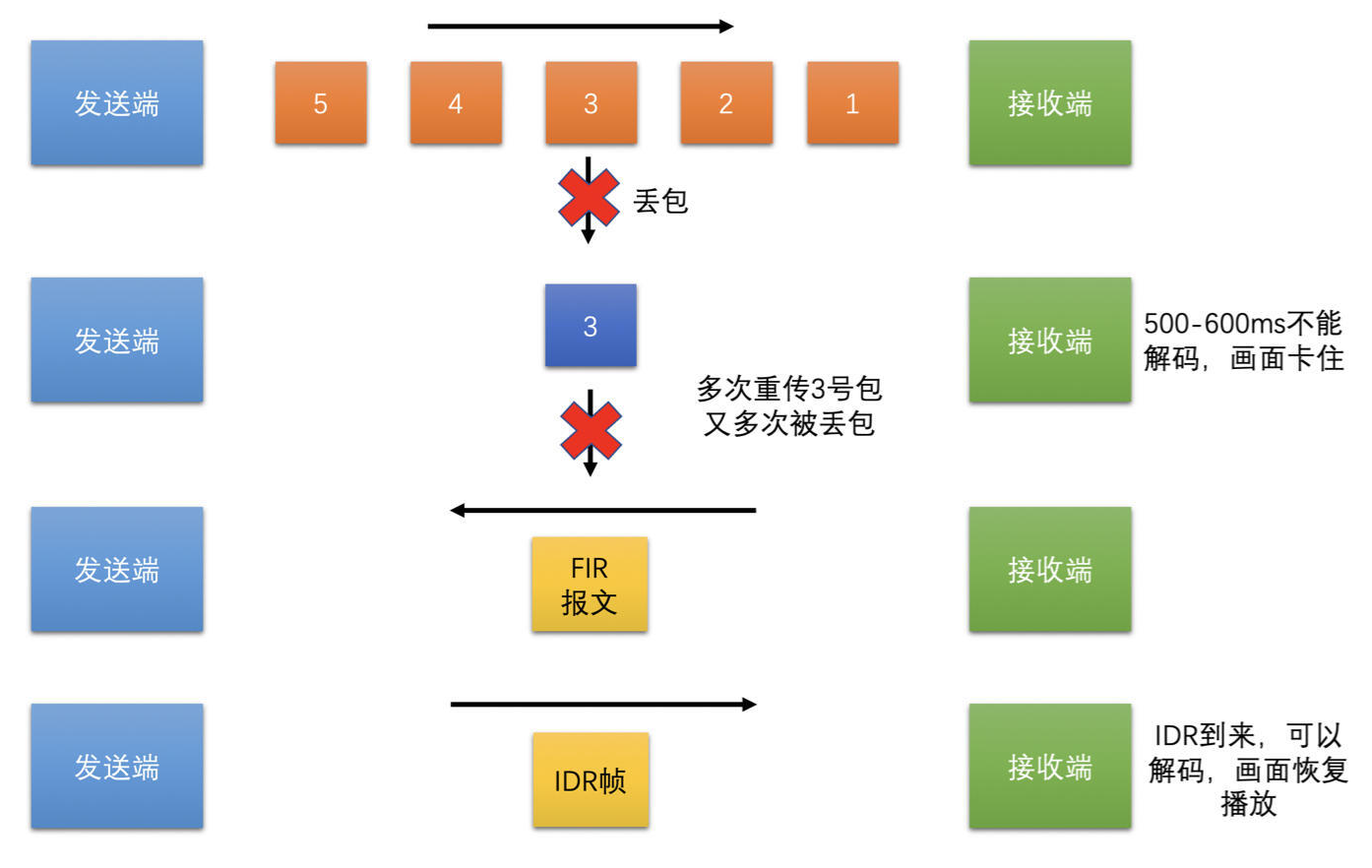
# 花屏问题
- 帧不完整
- 如果帧出现了丢包就送去解码的话,若能解码成功,肯定会出现解码花屏的问题,在解码一帧数据之前一定要保证帧是完整的
- 尤其是 ffmpeg 作为解码器的时候,帧不完整也有很大的概率成功解码,但是得到解码后的图像却是花屏的
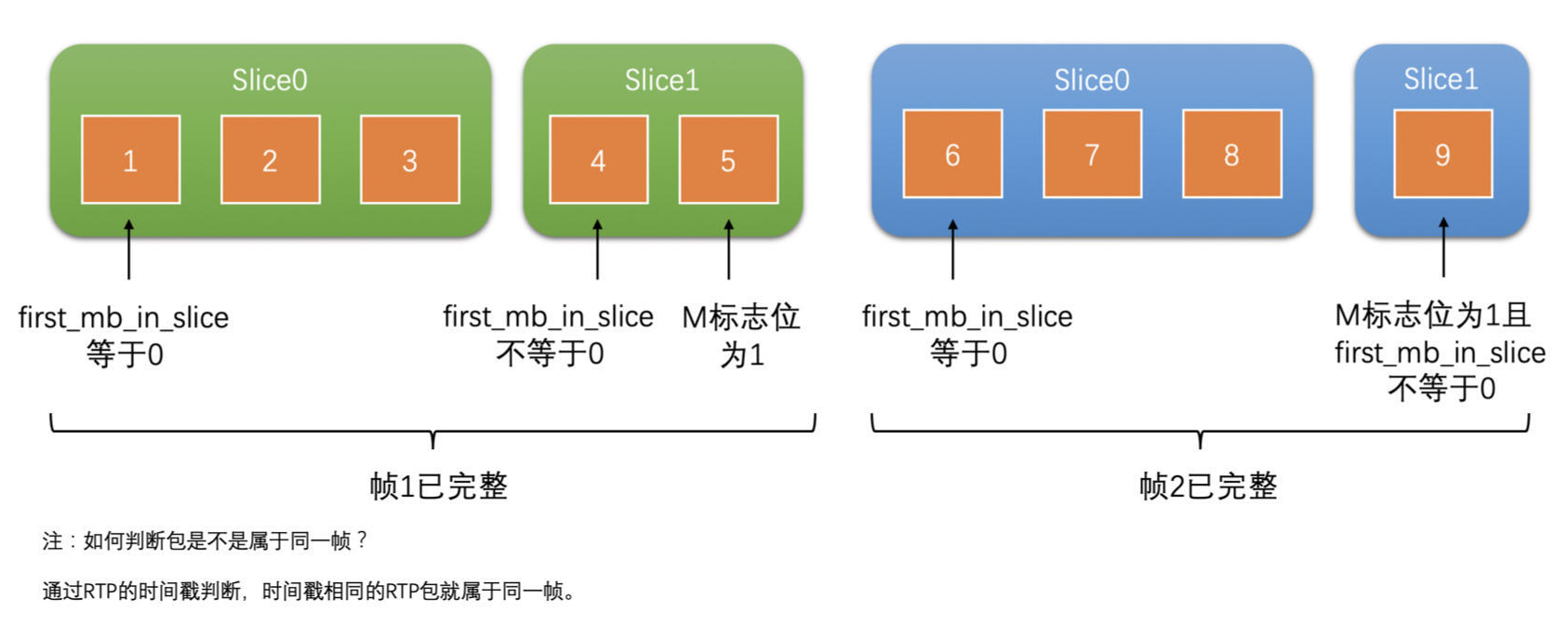
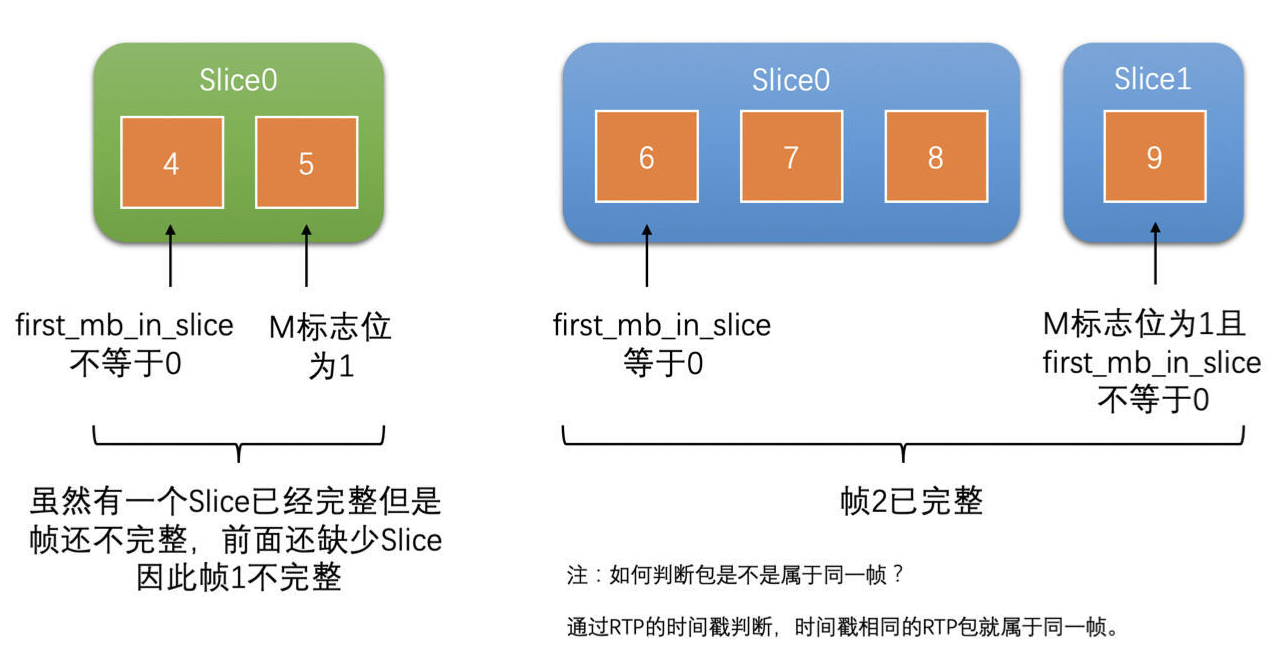
- 在 RTP 打包的时候是以 Slice 为单位打包的,而不是以帧为单位打包的,在 Jitter Buffer 中来对帧进行完整性判断
- 首先,使用前面的方式判断 Slice 的完整性,保证一个个 Slice 是完整的
- 然后使用 slice_header 中的 first_mb_in_slice 字段,来判断当前 Slice 是不是第一个 Slice
- 找到帧的第一个 Slice,而 Slice 也判断了是完整的,再通过 RTP 头的 M 标志位判断了帧的最后一个包
- 如果第一个 Slice 的第一个包到帧的最后一个包之间的 RTP 包都收到了,那就代表帧完整了
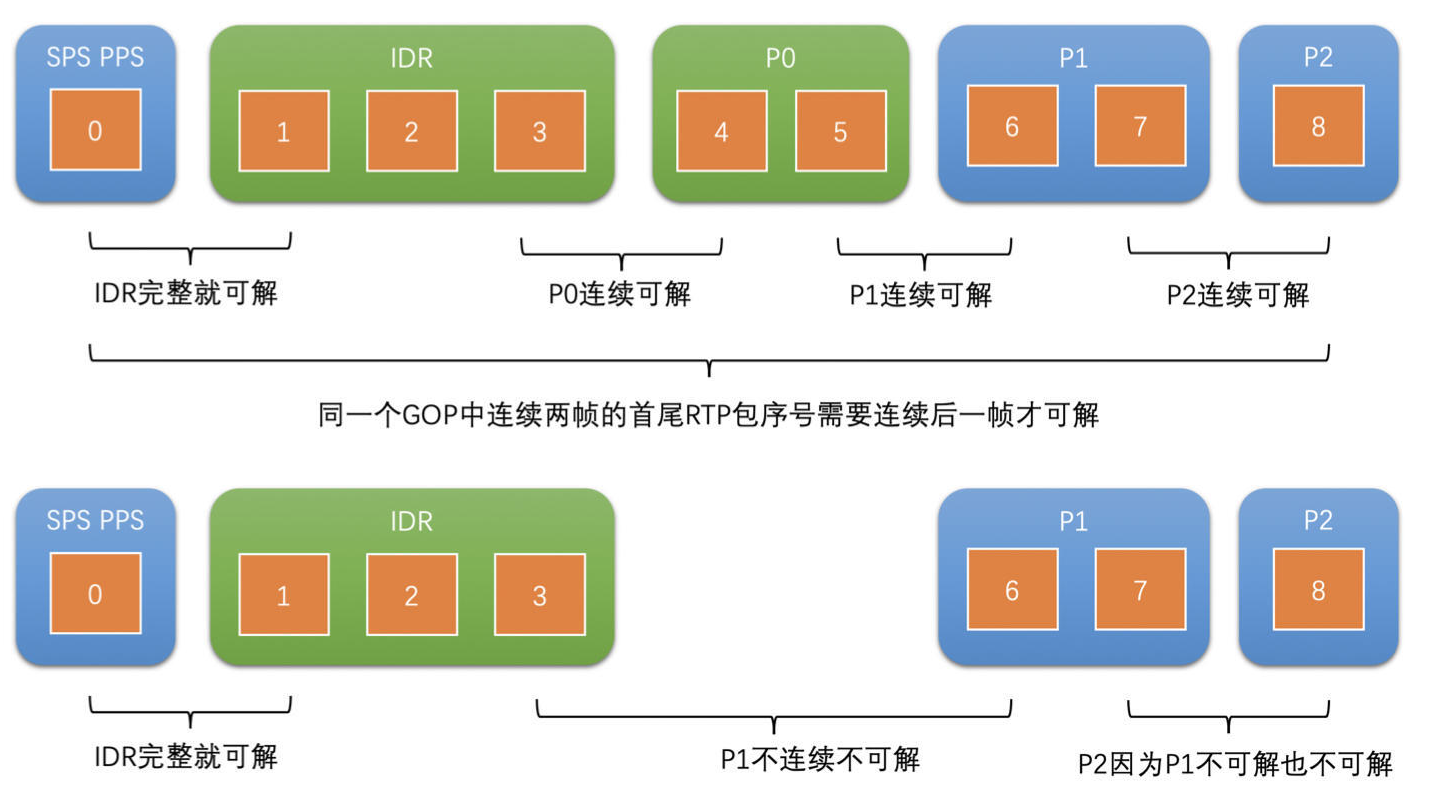
- 参考帧不完整
- 需要参考帧也是完整的才能送解码,并且参考帧的参考帧也要是完整的才行。如果参考帧不完整或者丢失,会出现如下图所示的花屏

- 如果是连续参考的话,或者说不知道编码器使用的参考结构的话,就需要保证从 IDR 帧开始到当前帧为止所有的帧都是完整的,并且前面的帧都已经解码了,那当前帧才能送去解码,只要有一帧没有解码就会出现花屏
- YUV 格式问题
- 渲染的时候 YUV 格式弄错,也会出现花屏
- 特点是图像的大体轮廓是对的,但是颜色是有问题的
- Stride 问题
- 解码后渲染前一定要处理好 YUV 的 Stride 问题,不要和宽度弄混,否则也会出现花屏

# SVC
# SVC 要解决的问题
以视频通话为例,在一对一的场景中,发送端网络好,接收端网络较差时,发送端可以通过基于延时和基于丢包的带宽预测算法估算出发送端到接收端之间的网络带宽值。得得到这个带宽值之后,发送端的视频码控算法就会将码率降下来,同时,码率下降引起 QP 上升,画面质量下降,但是流畅性变好,不会一直卡死。
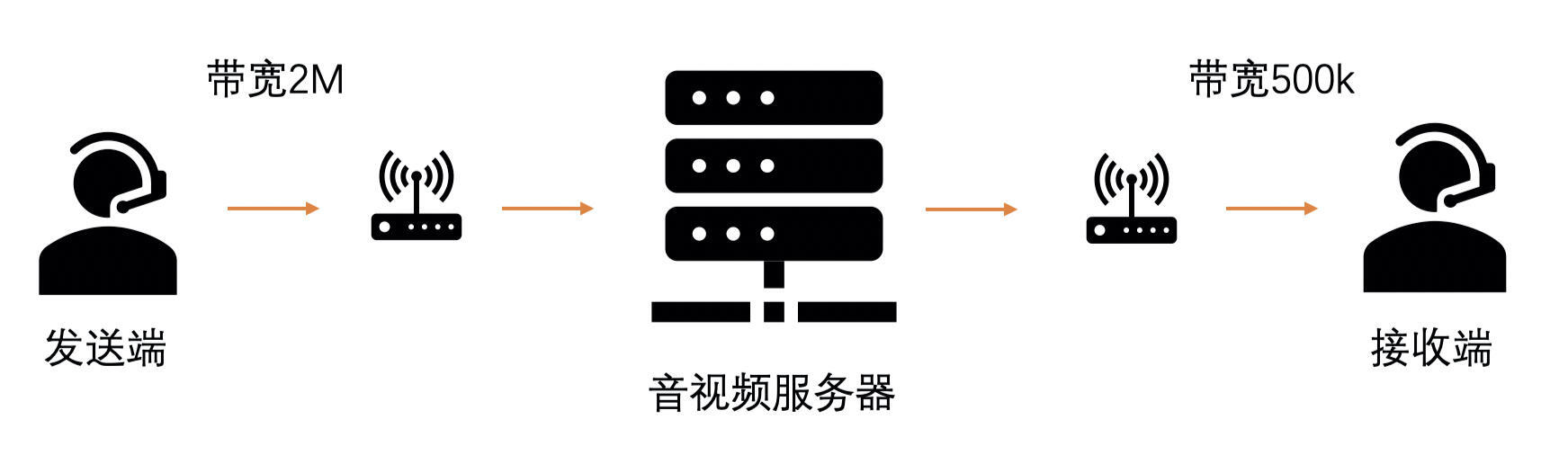
但是,当多人视频通话时,如果按最低带宽设置,会大概率牺牲其他用户的体验。
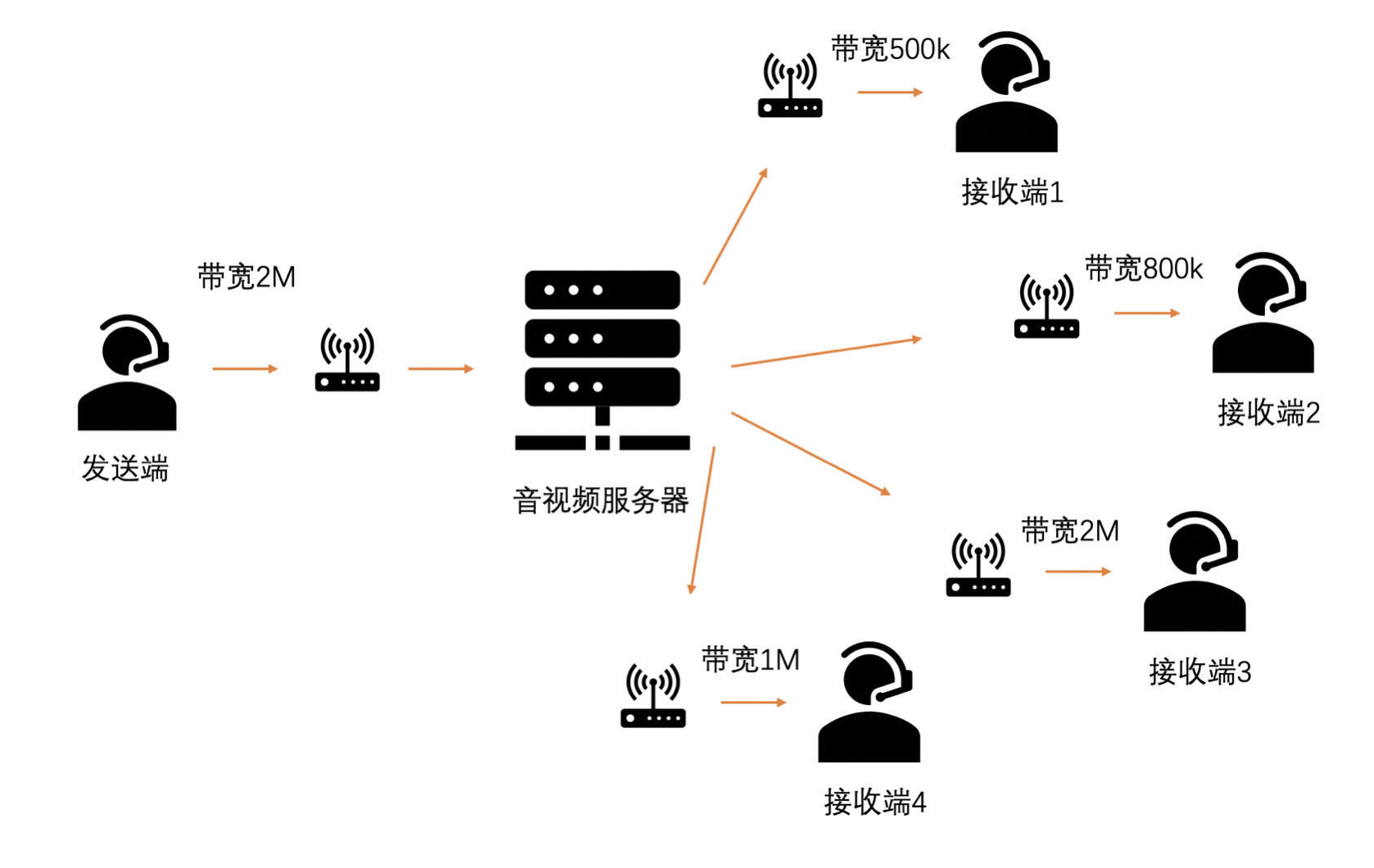
# SVC 是什么
SVC 是指一个码流当中,可以分成好几层,如分成三层:
- 第 0 层是最底层,可以独立进行编解码,不依赖第 1 层和第 2 层;
- 第 1 层编解码依赖于第 0 层,但是不依赖于第 2 层;
- 第 2 层的编解码需要依赖于第 0 层和第 1 层;
并且,第 0 层质量最低,第 0 层加第 1 层次之,三层加在一起的时候质量最高。这里的质量不是直接指的画面质量,而是帧率、分辨率的高低所代表的质量。
分层的好处是编码一个码流,可以组合出好几个不同的可解码码流出来。如说上面三层 SVC 的例子:第 0 层就是一个可以独立解码的码流;第 0 层加 上第 1 层也是一个可以独立解码的码流;第 0 层加上第 1 层和第 2 层也是一个可以解码的码流。这样可以根据不同接收端的带宽情况,由服务器转发不同组合的码流,每个接收端都能获得最佳的画面质量。
# SVC 的分类
- 时域 SVC
- 以在帧率上做 SVC
- 一般在 RTC 场景中选择使用连续参考的参考结构来做编码
- 这种参考结构非常简单,但是有一个很大的问题就是只要有一帧被丢弃或不完整,就会导致后面的帧都不能解码,强行解码就会出现花屏

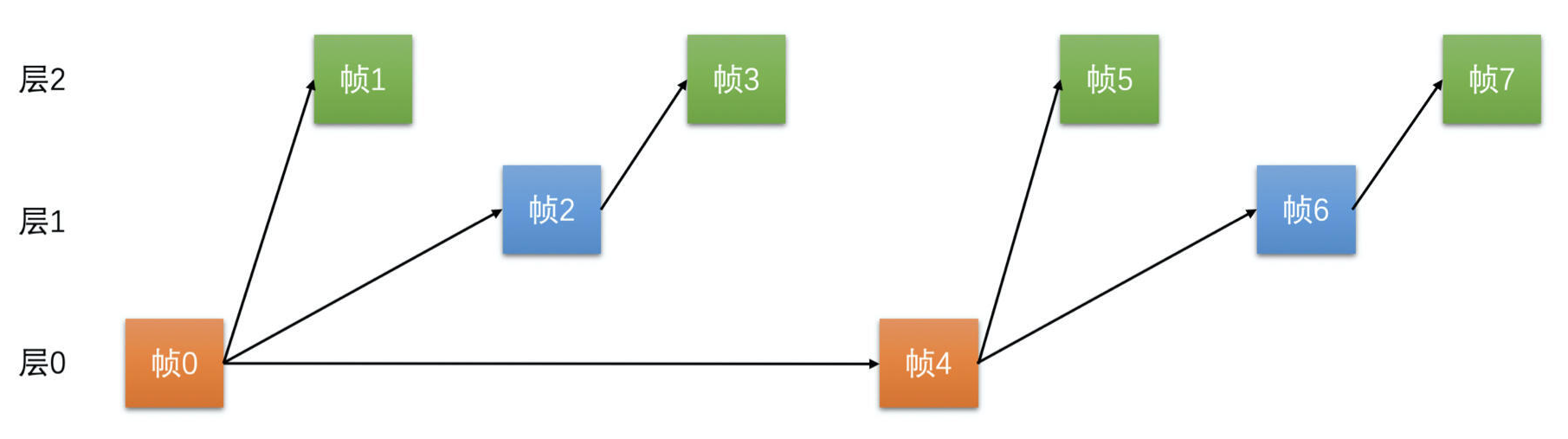
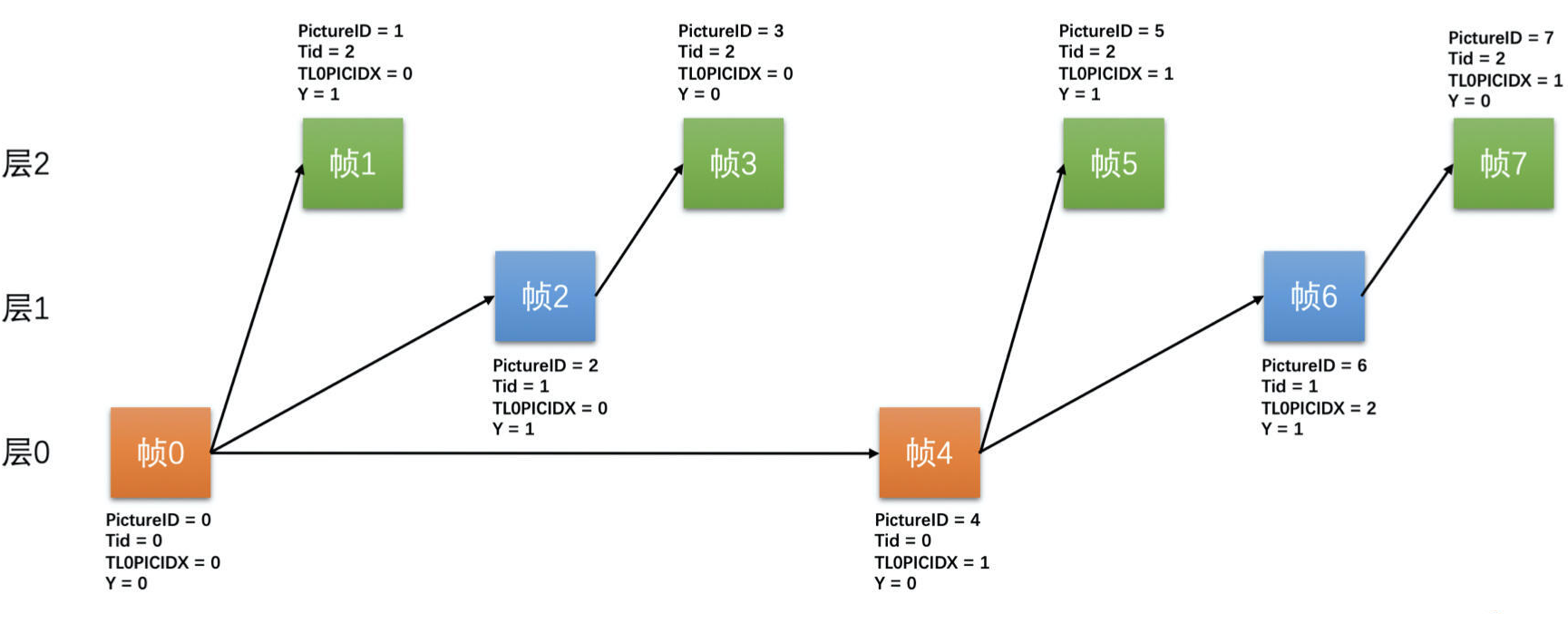
- 为了让编码参考结构具有伸缩性,把参考帧结构稍微换一下,隔一帧参考一帧,变成一个两层的结构,就可以解决连续参考的问题
- 帧 0 是 I 帧不需要参考,且是第 0 层的帧
- 帧 1 是 P 帧,参考帧 0,且是第 1 层的帧
- 帧 2 是 P 帧,参考帧 0,不参考帧 1,是第 0 层的帧
- 帧 3 是 P 帧,参考帧 2,是第 1 层的帧,一直用这种模式不断地循环下去

- 三层时域 SVC 编码的参考帧结构
- 优点
- 通过调整参考帧结构就能实现分层编码,低层的帧不会参考高层的帧
- 丢弃高层的帧,低层的帧也是可以顺利地完成解码而不会出现花屏的,只是帧率会降低
- 缺点
- 一般自然运动是连续的,选择前一帧作为参考帧一般压缩率会比较高,因为前后相邻的两帧很相似,而时域 SVC 这种跨帧参考的方式会使得压缩率有一定的下降
- 两层 SVC 编码效率大概下降 10%,三层大概下降 15%
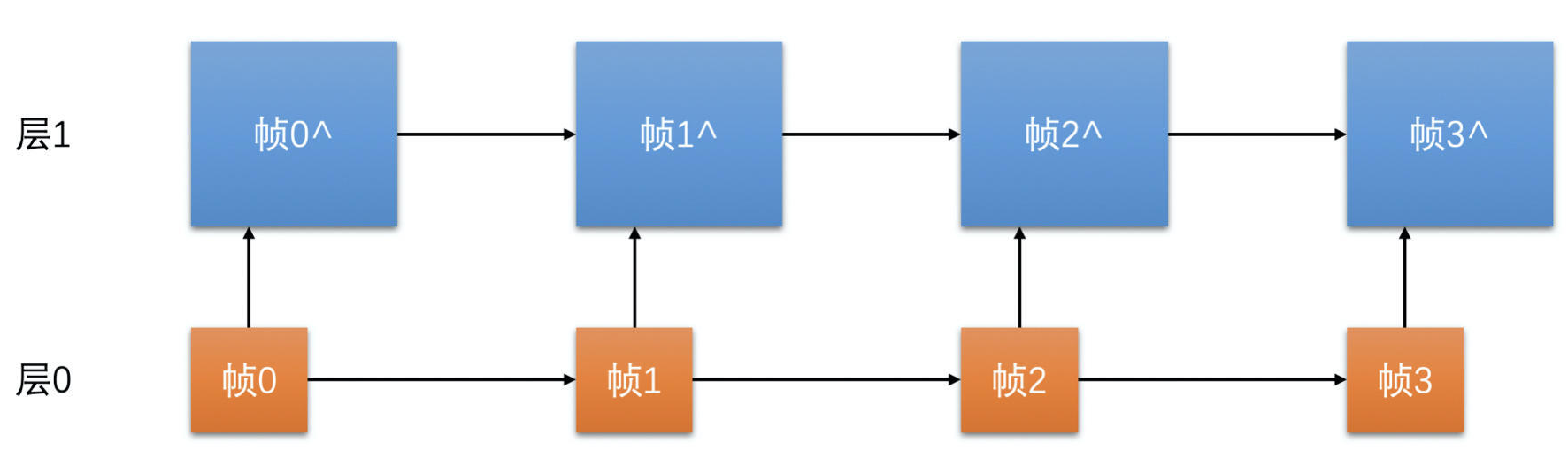
- 空域 SVC
- 空域 SVC 是在分辨率上做分层
- 如需要编码一个 720P 的视频,可以分成两层:第 0 层是 360P 的分辨率;第 0 层加第 1 层是 720P 的分辨率
- 优点
- 可以在一个码流当中分出多个码流出来
- 注意:H264、H265、VP8 这些常用的编码标准(除了扩展)都是不支持空域 SVC 的,市面上的绝大多数的解码器也都不支持空域 SVC 这种一个码流里面含有多种分辨率的视频码流解码
- 这种多分辨率的空域 SVC 相比多个编码器编码不同分辨率的方式,在压缩率上也没有多少优势,而且还不符合常规的标准
- 在 WebRTC 中直接使用多个编码器编码多种分辨率的方式代替空域 SVC
# 时域 SVC 如何实现可伸缩
首先,需要一些字段来描述码流中当前帧的层号、帧序号等 SVC 信息。因为这些字段只有在编码器编码的时候才知道。需要在编码出来一帧之后,在 RTP 包里面打包上这些信息发送给服务器和接收端。
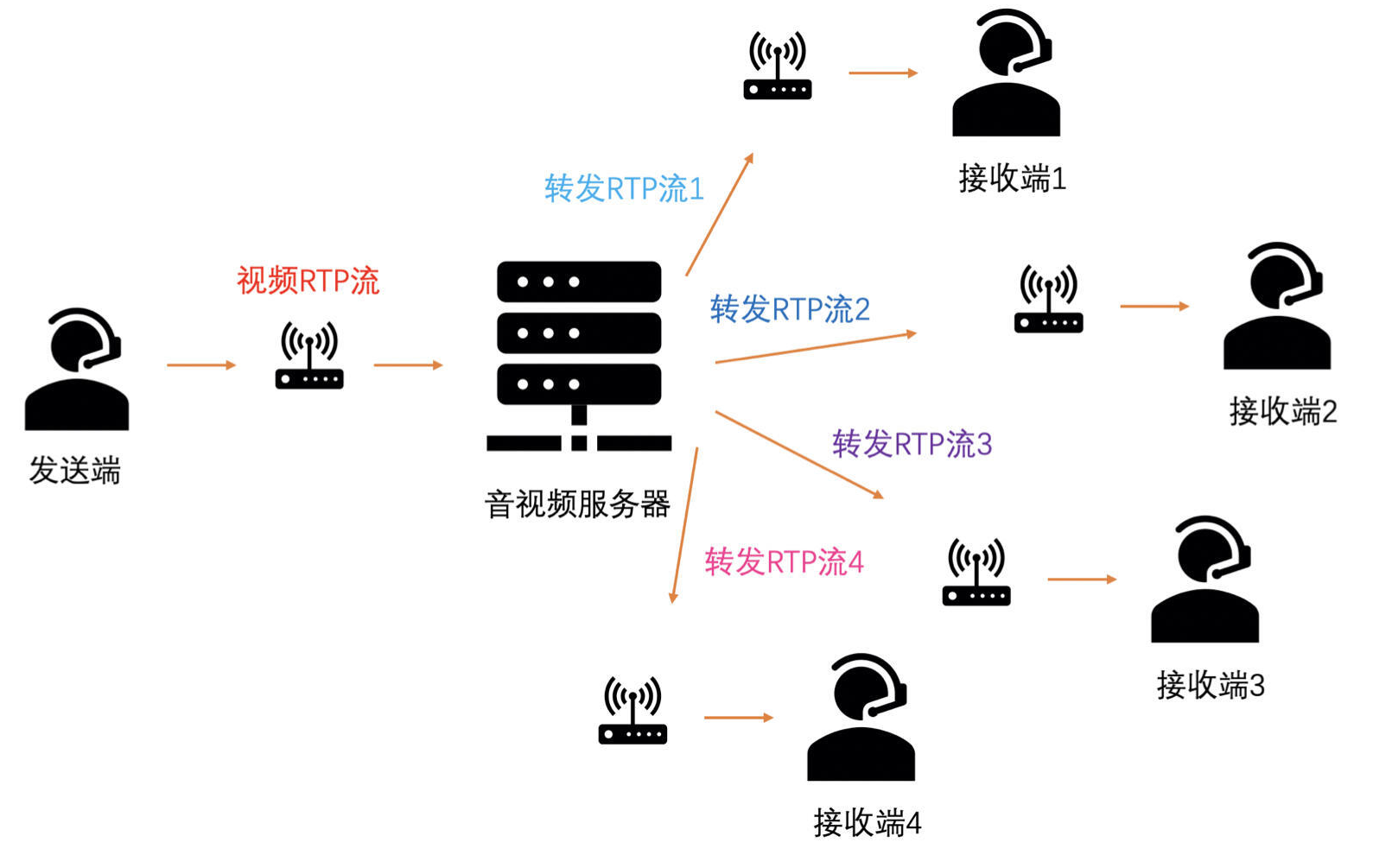
服务器到接收端的链路上,服务器是发送端,在服务器上也需要做带宽预测,预测算法是一样的。
服务器会预测得到每一个接收端和服务器之间链路的带宽值。发送端发送 RTP 包到服务器,服务器需要通过计算 RTP 包的大小和当前 RTP 包所属的帧属于哪一层得到每一层对应的码率。这样服务器在转发的时候,就可以根据到接收端之间链路的带宽值和对应的每一层的码率来选择到底转发几层。
参考 VP8 编码的 RTP 协议标准。VP8 的 RTP 协议在 RTP 头和 VP8 码流数据的中间还有一个 RTP 描述头,这个描述头主要用来放帧号、层号等信息的。
服务器可以从 RTP 描述头得到 RTP 包对应的层号,就可以通过 RTP 的层号和 RTP 的包大小来估算每一层的码率了。而接收端可以根据帧号、层号和层同步标志位等信息来判断当前帧是不是可以解码,而不用去解码视频码流。
服务器就可以通过丢层的方式来实现对不同带宽的接收端下发不同帧率码率的码流。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2021/12/8,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号