【机器学习】:分类任务的常用评价指标


提要

哈喽,大家好!本期给大家介绍机器学习分类任务的常用评价指标:Accuracy、Precision、Recall、F1-score。
TL;DR
* 机器学习的分类任务
* Confusion Matrix(混淆矩阵)
* Accuracy
* Pricision
* Recall
* F1-score
一、分类任务?
分类是机器学习的基础任务,比如:新闻分类、事件分类、情感分类、话题分类、主题分类、图片分类、视频分类等等。
分类是指将数据分成不同的类别,或者说是贴上各种标签。比如:
- 将病人的检查结果分为有病和健康。
- 植物类别识别。

- 光学字符识别。

- 电影类型分类。

- 垃圾邮件识别、微商广告识别,黄赌毒内容识别、医学中的疾病诊断。
二、评价指标?
评价指标是针对将相同的数据,输入不同的算法模型,或者输入不同参数的同一种算法模型,而给出这个算法或者参数好坏的定量指标。
不同的机器学习任务,有不同的评价指标。
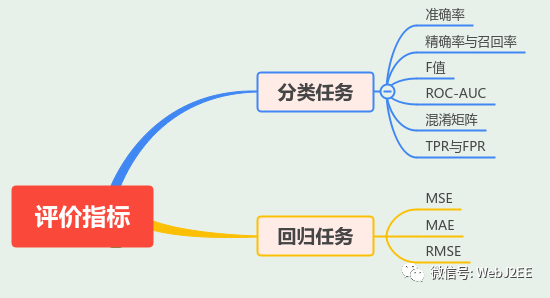
本文重点说明分类任务的评价指标。
三、举个例子:好瓜检测仪
假设,我们有一个“好瓜检测仪”,用于区分好瓜和坏瓜。然后我们用这个检测仪检测了一批西瓜,并得到了下表所示的结果。
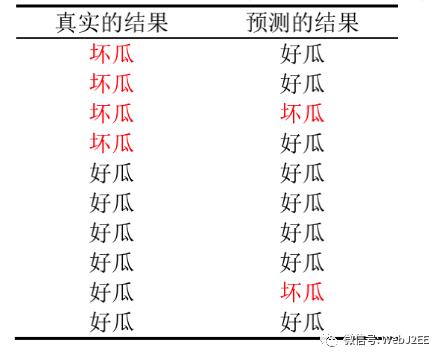
注:我在这里使用“好瓜检测仪”这个词,而不是使用“西瓜分类器”这种词汇,是用于凸显出,在好瓜和坏瓜中,我们更加关注的是“好瓜”。
那么我们如何定量分析这个“好瓜检测仪”的性能指标?
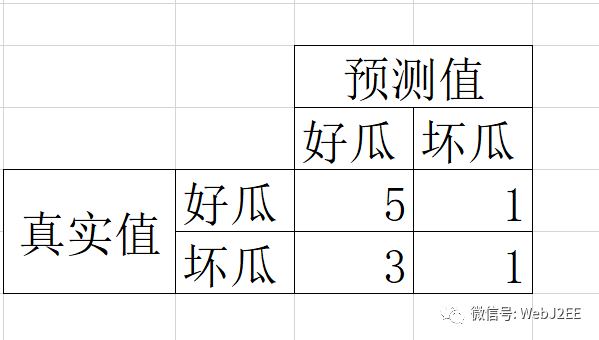
四、混淆矩阵(Confusion Matrix)
混淆矩阵(Confusion Matrix)又被称为错误矩阵,通过它可以直观地观察到算法的效果。它的每一列是样本的预测分类,每一行是样本的真实分类(反过来也可以),顾名思义,它反映了分类结果的混淆程度。
我们需要定义分类结果中的正类(positive)和负类(negative),在机器学习中,我们通常将更关注的事件定义为正类事件。
P(Positive):代表1,表示预测为正样本
N(Negative):代表0,表示预测为负样本
T(True):代表预测正确
F(False):代表预测错误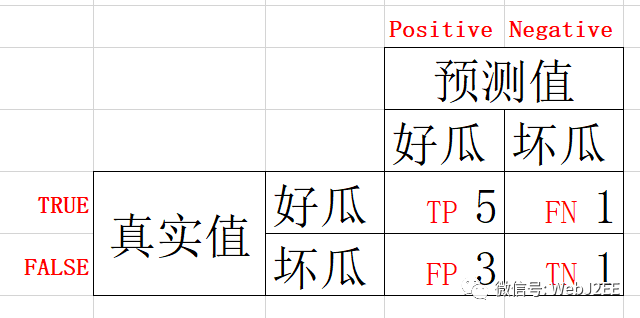
4.1. Accuracy(准确率)
正确分类的样本数与总样本数的比例。
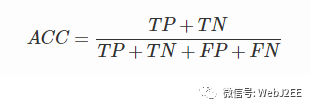
所以“好瓜检测仪”的Accuracy是:
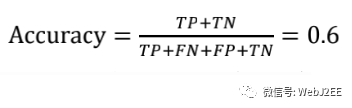
注:这个指标存在局限性,比如一个不平衡样本,分类中一个占比特别多一个特别少,把少的全预测错了,而分类准确率依然很高。假设我们分类的目标是识别好人和坏人,好人有 95个坏人只有5个(样本不平衡)。如果我们设计的模是将所有的人全部都识别成好人那么分类准确率为95%,但是这个模型并没啥用,因为一个坏人都没别识别出来。
4.2. Precision(精确率)
精准率代表对正样本结果中的预测准确程度,而准确率则代表整体的预测准确程度,既包括正样本,也包括负样本。

所以“好瓜检测仪”的 Precision 是:

注:FP,False Positive,也是代表误报,是统计学中的 Type 1 error。
4.3. Recall(召回率)
召回率(Recall)又叫查全率,它是针对原样本而言的,它的含义是在实际为正的样本中被预测为正样本的概率。

所以“好瓜检测仪”的Recall是:

通常,Precision 和 Recall 是负相关的。

注:FN,False Negative,也是代表漏报,是统计学中的 Type 2 error。
4.4. F1-score(召回率)
Precision和Recall指标有时是此消彼长的,即精准率高了,召回率就下降。有时候我们需要在精确率与召回率间进行权衡,在一些场景下要兼顾精准率和召回率,最常见的方法就是F-Measure,又称F-Score。F-Measure是P和R的加权调和平均(harmonic mean)。
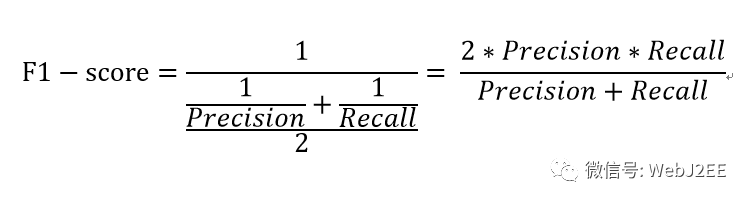
两个数之间的调和平均倾向于靠近两个数中比较小的那一个数,因此我们追求尽量高的F1 measure,能够保证我们的精确度和召回率都比较高。
参考:
Understanding Confusion Matrix: https://towardsdatascience.com/understanding-confusion-matrix-a9ad42dcfd62 What is the F-score?: https://deepai.org/machine-learning-glossary-and-terms/f-score Type I & Type II Errors | Differences, Examples, Visualizations: https://www.scribbr.com/statistics/type-i-and-type-ii-errors/ Youden's J statistic: https://en.wikipedia.org/w/index.php?title=Youden%27s_J_statistic&oldid=909973188 Harmonic Mean Definition: Formula and Examples: https://www.investopedia.com/terms/h/harmonicaverage.asp

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-06-20,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号