自有知识库训练-进阶篇


上一篇文章介绍了,如何利用自有知识库的训练:突破chatGPT的局限性 这一篇文章,将继续探讨这一话题,把里面的一些技术细节展开
第一个细节,如何将文本分段
我们要理解为什么分段,本质是什么?
- 把长文章打散,这样就能方便的放到chatGPT的上下文中
- 尽可能要保持每个段落的独立性,如果你把一句话从中截断了,这肯 定会影响最终的效果
如果分段不合理,会有什么影响?
首先,分段不能太长,至少对于chatGPT3.5来讲,你肯定不能超过4096个token,否则第1点就不满足了,另外文本长,也意味着段落的信息足够多,这是一个双刃剑,好处是可能有更好的上下文,坏处是可能有更多的干扰信息
其次,分段也不能太短,太短了,信息就很割裂,上下文可能不会那么完整
所以这里面有一些策略,下面是我自己总结的一些策略:
最好的策略是自定义分段,这个比较适合你对文档很熟悉,你想把这个文档训练之后,提供给别人使用,下图是我的一个实现:
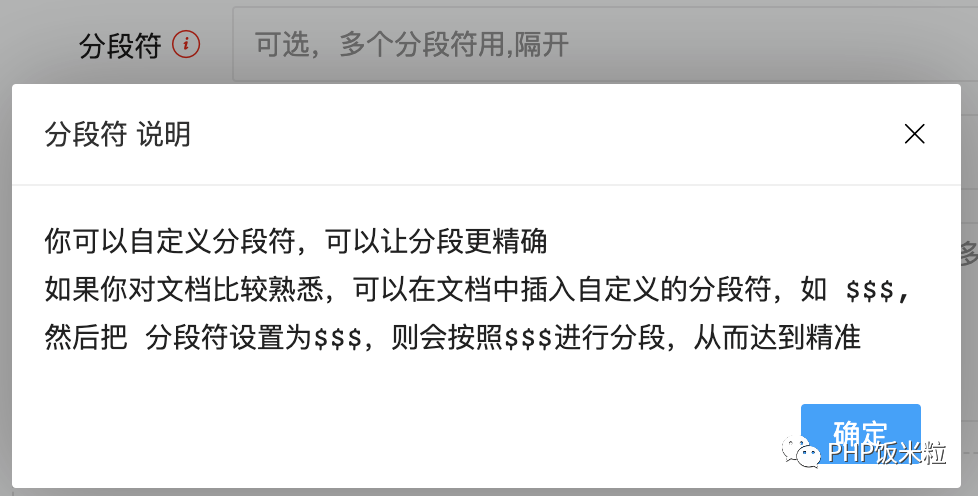
但这个要求比较高,因为我们大多数场景看的并不是自己熟悉的文档
所以常用的策略是按照文档的自然的组织格式进行分段,比如段落和段落之间,一般都是二个换行符或以上,句和句之间,可能是一个换行符或者有空格,千万要避免把一句话从中隔段的情况。
假设我现在想把一个文档分成每500个字一段,那我们该如何实现呢? 1、先按 \n\n切分,如果切分出来的段有大于500个字 2、再按\n切分,如果切分出来的段还有大于500个字 3、最后再按空格切分 4、但如果直接用这个策略切,也会有问题,因为有些段会很短,比如就短短的一句话,所以最后的策略是,再把分出来的段再进行匹配组合,进可能让每一段接近500字 5、最后的最后,过滤掉一些不可见字符,占位符等,向量化,存入数据库,可以节省空间和token数
第二个细节,隐私问题
当我们进行自有知识库进行训练的时候,会有两个环节会把数据投喂到chagGPT:
第一个环节是:向量化的过程,我们会把文本数据调用chagGPT的相关接口拿到向量化后的数据,然后再存入到自有的存储里
第二个环节是:回答的过程,我们通过会通过向量匹配,把相关的段落文本放到chatGPT的context里,然后再通过chatGPT二次加工之后,返回最终的答案
所以这两个环节都可能会泄露你的数据,除非你不用chatGPT,而用自己的llm,否则这个是无法避免的,但也有一些技巧或者方式来尽量避免:
技巧一:在文本分段的时候,进行敏感数据过滤或者加密,比如:
- 过滤一些密码相关的,密钥相关的数据
- 把一些敏感的数据进行过滤或者加密,在最终输出的时候进行解密
如我现在的实现:
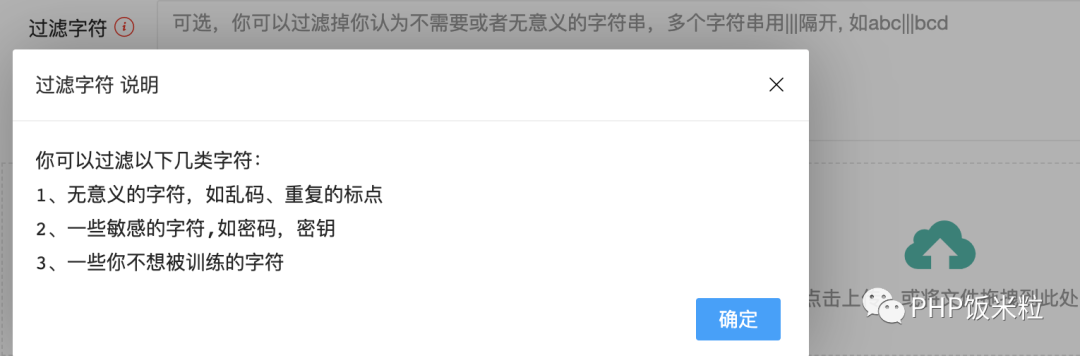
技巧二:如果你是在智能客服场景,或者已经沉淀出了很多标准的SOP或者问答的场景,那么里只要训练问题就行了,然后通过用户的输入去匹配最合适问题,再通过问题返回标准的答案。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-06-05,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号