Midjourney入门


思维导图

前言
Midjourney AI是一种先进的人工智能技术,通过自然语言命令生成图像、视频和其他数字内容。这项技术利用先进的深度学习算法根据用户输入生成独特而有创意的输出。
速查表
/imagine (e.g. /imagine a dog)
生成基于您提供的提示的图像的主要命令。您还可以添加参数到此命令以指定图像的纵横比、大小、随机性等。
/imagine a dog - -q4 - -iw 0.25
/help (info about the bot)
显示有关机器人及其使用的信息。
/info (info about your profile)
显示有关您的个人资料的信息,例如您的订阅状态、生成的作业数量等等。
/subscribe (subscribe to the bot)
允许您订阅该机器人并获得有关新功能、改进等的更新。
/fast (your jobs will be incrementally billed)
此命令使您的工作逐步计费,意味着您将根据生成每个图像的时间而被收费,而不是一次性全部收费。
/relax (your jobs do not cost, but takes longer to generate)
一次性生成,需要更长时间
/show (revive any job)
此命令可激活任何您先前生成的工作。您只需要为您想要激活的图像提供工作ID即可。
/show 123456
/private (your jobs are private)
此命令使您的工作成为私有,意味着只有您才能看到它们。
/public (your jobs are public)
命令使您的工作公开,意味着任何人都可以查看它们。
参数
质量参数(- -q)
这些参数控制生成图像的质量,其值范围为0.25到5。值为0.25表示生成的图像速度更快、更不详细,而值为5则表示速度更慢、更详细。你选择的值将取决于你的项目的特定要求以及速度、细节和成本之间的权衡。
生成的图像的质量将设置为0.5,从而产生更快、更简单的图像,但成本更低。
风格化参数(- -stylize)
这些参数控制图像的艺术风格,其值范围为0到1000。值为45表示不太风格化的图像,而值为900表示高度风格化的图像。你选择的值将取决于你的个人偏好和想要在图像中实现的风格。
生成的图像将具有200的风格化强度,从而产生更具艺术性的图像。
/imagine a dog - stylize 200
图像提示权重参数(- -iw)
这些参数控制分配给图像提示的权重,使你能够强调或减弱图像的某些元素。例如,如果你想让一只狗成为图像的主要焦点,你会增加“狗”提示的权重。
/imagine a dog - -iw 0.25

宽度和高度参数(- -w和- -h)
这些参数控制生成图像的大小。通过指定特定的宽度或高度,你可以确保图像适合你的项目的限制。
生成的图像将具有 1000 像素的宽度,从而得到更广阔的城市天际线。
/imagine a city skyline - -w 1000

种子参数(- -seed和- -sameseed)
这些参数控制图像生成过程的随机性。通过指定种子值,你可以确保每次生成的图像都是相同的,从而创建一致的图像。- -sameseed参数以相同的方式影响生成的所有图像,允许你创建一系列一致的图像。
生成的图像将使用种子值“123456”,从而得到特定且可重复的图像。
/imagine a cityscape - -seed 123456

纵横比(- -aspect或- -ar)
纵横比参数控制生成图像的宽度与高度之比。通过指定特定的纵横比,你可以确保图像适合你的项目的限制。例如,如果你指定2:1的纵横比,则图像的宽度将是高度的两倍。
生成的图像将具有 2:1 的宽高比,从而得到更宽的景观视图。
/imagine a landscape - -aspect 2:1

所有生成的图像将受到相同的种子值影响,从而为多个图像产生一致的外观。
/imagine a cityscape - -sameseed
-beta:
-beta参数指定使用实验算法进行图像生成。使用该参数将生成不同于使用- -hd参数的图像。使用- -beta参数的结果可能是不可预测的,但可能会导致新的创新图像。
生成的图像将使用实验性 beta 算法,产生独特且不可预测的图像。
/imagine a dog - -beta
-hd:
-hd参数指定使用旧算法进行图像生成。该参数生成更高分辨率的图像,但可能需要更长时间生成。
生成的图像将使用旧版高清算法,产生更高分辨率的图像。
/imagine a portrait - -hd

混沌(- -chaos)
混沌参数控制图像生成过程的随机性。通过指定混沌值,你可以创建具有不同随机性水平的图像。值为0表示高度结构化的图像,而值为1则表示高度随机的图像。
生成的图像将具有混乱值0.5,导致图像更随机和混乱
/imagine a sunset - -chaos 0.5
快速(- -fast)
快速参数加快图像生成过程,从而加快图像生成时间。但结果可能不太一致、不太详细。
生成的图像将更快,但一致性较差且成本较低
/imagina a dog - -fast {- -quality 0.25}
停止(- -stop)
停止参数停止图像生成过程,从而不生成图像。
/imagine a city skyline --stop 25
照亮(- -uplight)
照亮参数使用“光”缩放器,从而生成更明亮、更生动的图像。
/imagina a mountain landscape --uplight
视频(- -video)
视频参数将图像生成过程保存为视频,允许你查看图像随时间的变化过程。
/imagina a city skyline - -version 3 - -video
排除(- -no)
不参数允许你从图像生成过程中排除某些元素,例如“植物”或“汽车”。
所生成的图像将显示一只狗在公园玩耍,但没有云。
/imagine a dog playing in a park - -no clouds

V1和V2(- -v1和- -v2)
v1和v2参数指定使用旧算法进行图像生成。使用v1或v2将生成与使用- -beta参数不同的图像。使用v1或v2的结果可能是不可预测的,但可能会导致新的创新图像。
/imagina a flower - -v 2
版本4风格4a、4b和4c
Midjourney模型版本4有三种略微不同的“风味”,对模型的风格调整略有不同。通过在V4提示的末尾添加--style 4a、--style 4b或--style 4c来尝试这些版本。
—v 4 —style 4c是当前的默认值,无需添加到提示的末尾。
关于Style 4a和4b的说明:—style 4a和—style 4b仅支持1:1、2:3和3:2纵横比。—style 4c支持高达1:2或2:1的纵横比。
Niji模型
niji模型是Midjourney和Spellbrush之间的合作,旨在生产动漫和插图风格。—niji模型对动漫、动漫风格和动漫美学有更广泛的了解。它在动态和动作镜头方面表现出色,并且通常是以人物为重点的构图。
美化图像
要使用样式化值,您需要在“/imagine”命令的末尾添加“--s”选项,后跟一个数字。
样式的默认值现在为100,使用默认V4模型时,它接受0到1000的整数值。这里是样式化值及其在使用V4模型时对图像生成的影响的解释:
- --s 0-50: 这是最少艺术风格的值,生成具有很少甚至没有风格的图像。结果更加真实,但不太吸引人的视觉效果。
- --s 50-99: 这个值产生中等水平的风格,使它们在视觉上更具吸引力,但不太严格。结果在现实和样式之间有良好的平衡。
- --s 100: 这是默认的样式化值,可以产生在现实感和艺术风格之间有很好平衡的图片。结果吸引人,但不太远离现实。
- --s 101-500: 这个值产生高度样式化的图像,样式占据了现实感。结果更加艺术化,不太真实。
- --s 500-1000: 这是样式化值中最高的值,生成高度样式化的图像,更多的是艺术而不是真实感。结果视觉上很吸引人,但可能不准确地代表现实。
调整图像质量
- -q 0.25:速度4倍,结果粗糙,价格低廉
- -q 0.5:2倍快速,细节较少,成本低
- -q 1:默认值,标准速度和质量
- -q 2:2倍更慢,更详细,费用高
- -q 5:实验性的,生成高度详细的图像,但可能需要更长的时间并且成本更高
图像URL灵感
/imagine https://upload.wikimedia.org/wikipedia/commons/thumb/6/62/Starsinthesky.jpg black hole
好处:更准确和详细的图像
多提示
所有权重总和必须是正数
- ::提示不同部分,如hot:: dog
- 提示权重:hot::2 dog,热的重要性是狗的2倍
- 负提示权重:vibrant tulip fields:: red::-.5,将产生喜欢红色的郁金香有更小的可能性的郁金香田
- --no:vibrant tulip fields --no red
偏好设置
/settings
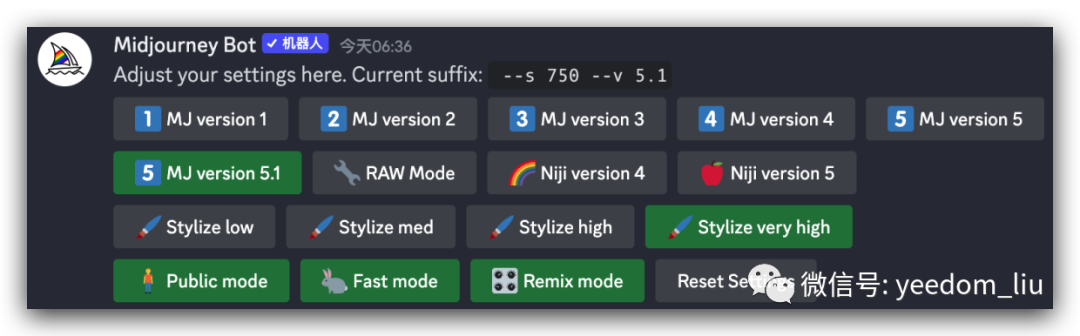
实践
prompt创建
- 选择创建主题,从特定对象(例如树木或建筑物)到更广泛的概念(例如“怀旧”或“冒险”)。
- 构思一个与之相关的单词、短语或图像列表,这些列表可以用作提示。
- 尝试使用不同的提示结构和组合,看看哪种适合您的特定需求。
prompt
- 文本
- 图像
- 多提示
调整
- 参数
- 风格(现实、抽象、卡通)
- 颜色(color)
- 质量
- 其他(noise:纹理和细节)
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-06-22,如有侵权请联系 cloudcommunity@tencent.com 删除
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号