Hive 性能优化


Hive 性能优化,可以从三个方面来考虑,即存储优化、执行过程优化和作业调度流程优化。
存储优化
Hive 数据存储是 Hive 操作数据的基础。选择一个合适的数据存储文件格式,能够带来 Hive 查询性能的质的提升。
存储格式
Hive 支持的存储文件格式有如下几种:
- TextFile 文本格式
- SequenceFile 二进制序列化文件
- RCFile 行列式文件
- Apache Parquet
- ORCFile 优化的行列式文件
其中,ORCFile 和 Apache Parquet 具有高效的数据存储和数据处理性能,在实际生产环境中应用广泛。
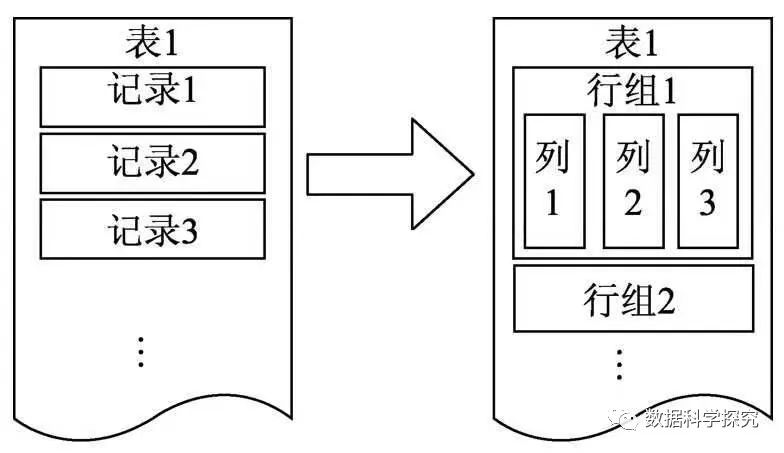
ORC 存储文件是一种带有模式描述的行列式存储文件。它将数据先按行进行分组切分,一个行组内包含若干行,每一个行组再按行列进行存储。如下图所示:
Parquet 是另外一种高性能行列式存储结构,适用于多种计算框架。Hive、Impala、Drill 等查询引擎均支持该存储格式。
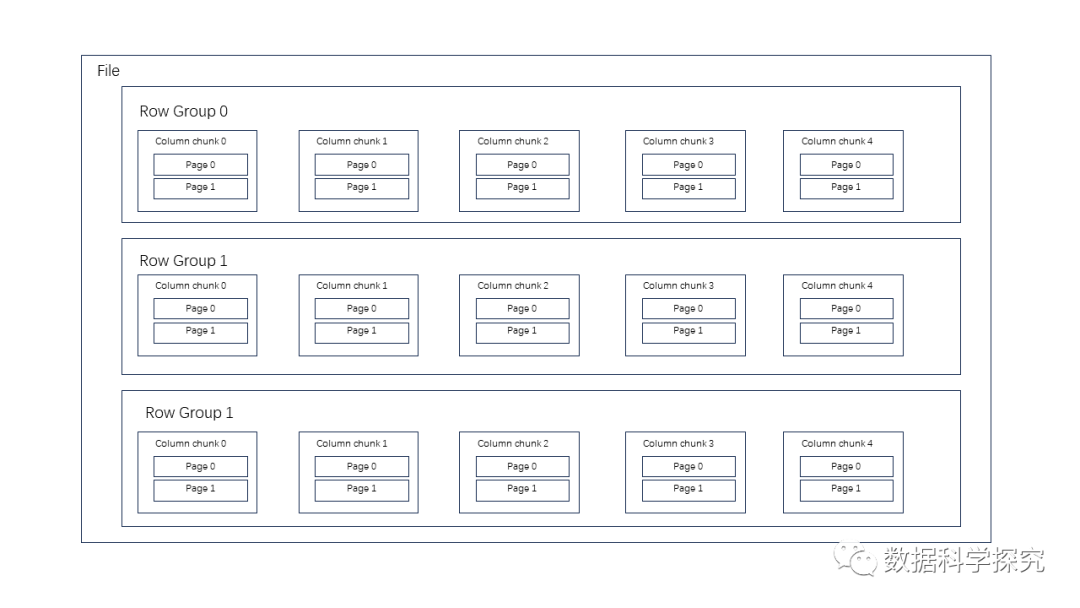
在一个 Parquet 类型的 Hive 表文件中,数据被切分为多个行组,每个列块被拆分为若干页,如下图所示:
对比 ORC 和 Apache Parquet,ORC 具有更高的存储效率和更优的查询性能,且支持 ACID 事务特征、update 以及 delete 等操作,推荐使用。
使用分区
分区是 Hive 中一个有用的概念。它用于根据某些列划分大表,以便将整个数据划分为小块。它允许你将数据存储在表内的子目录下。考虑到未来的数据以及数据量,非常建议你使用分区。使用分区后,查询条件命中分区的情况下,将很快的返回查询结果。
Hive 分区分为静态分区和动态分区,默认为静态分区。要开启动态分区,可以在会话中执行 set hive.exec.dynamic.partition=true; 或者 set hive.exec.dynamic.partition.mode=nonstrict; 来开启设置(会话级别生效)。
使用分桶
分桶是将数据划分为若干个存储文件,并规定存储文件的数量。
Hive分桶的实现原理是将数据按照某个字段值分成若干桶,并将相同字段值的数据放到同一个桶中。在存储数据时,桶内的数据会被写入到对应数量的文件中,最终形成多个文件。
分桶可以提高分布式查询的效率。它能够通过将数据划分为若干数据块来将大量数据分发到多个节点,使得数据均衡分布到多个机器上处理。这样分发到不同节点的数据可以在本地进行处理,避免了数据的传输和网络带宽的浪费,同时提高了查询效率。
在会话中执行 set hive.enforce.bucketing=true; 来开启设置(会话级别生效)。
执行过程优化
开启 MapJoin
在 Hive 中,hive.auto.convert.join 参数用于控制是否自动将非 MapJoin 转换为 MapJoin。
MapJoin 是一种优化技术,可以在将数据加载到内存时,将小表完整地加载到内存中,然后将大表的匹配数据通过哈希匹配加入到结果集中。这可以减少磁盘 I/O,提高查询性能。而非 MapJoin 则是将数据通过数据传输进行联接,当数据量较大时,可能会导致性能下降。
可以修改 hive-site.xml 中的 hive.auto.convert.join 的参数值为 true 来开启 MapJoin(永久生效,但是需要重启集群),也可以在会话中执行 set hive.auto.convert.join=true;来开启设置(会话级别生效)。
通过调整 hive.auto.convert.join 参数,你可以控制 Hive 是否自动将非 MapJoin 转换为 MapJoin,从而优化查询性能。
开启 skewjoin
在 Hive 中,hive.optimize.skewjoin 参数用于控制是否启用倾斜连接(Skew Join)优化。
倾斜连接指的是在连接操作中,某些键的数据分布非常不均匀,导致部分任务的处理时间明显超过其他任务。这会导致任务负载不平衡,严重影响查询性能。
启用 hive.optimize.skewjoin 参数后,Hive 会自动监测连接操作中的倾斜情况,并尝试采用优化策略,如动态重分区、动态调整任务大小等来解决倾斜连接问题,使查询任务可以更均匀地分布在集群上,提高查询性能。
可以修改 hive-site.xml 中的 hive.optimize.skewjoin 的参数值为 true 来开启 SkewJoin(永久生效,但是需要重启集群),也可以在会话中执行 set hive.optimize.skewjoin=true; 来开启设置(会话级别生效)。
开启 Bucketed Map Join
在 Hive 中,hive.optimize.bucketmapjoin 参数用于控制是否启用桶映射连接(Bucket Map Join)优化。
桶映射连接是一种基于桶表(bucketed table)的连接优化技术。桶表是通过对数据进行散列分桶而创建的表,在桶表上进行连接操作时,可以直接映射到对应的桶上,减少了数据扫描和对全表进行连接的开销,从而提高查询性能。
可以修改 hive-site.xml 中的 hive.optimize.bucketmapjoin 的参数值为 true 来开启 Bucketed Map Join(永久生效,但是需要重启集群),也可以在会话中执行 set hive.optimize.bucketmapjoin=true;来开启设置(会话级别生效)。
开启并行执行
Hive 在执行过程中,将查询过程分为如下几个阶段:

开启并行执行之后,上述某些阶段可以并行执行,从而加快查询的速度。为此,你需要在会话中执行 set hive.exec.parallel = true; 来开启设置(会话级别生效)。
开启矢量化
矢量化一次批量执行 1024 行而不是每次执行单行,从而有效提高了所有操作(如扫描、聚合、筛选器和联结)的查询性能。为此,需要你在会话中执行如下命令以开启矢量化(会话级别生效)。
set hive.vectorized.execution.enabled = true;
set hive.vectorized.execution.reduce.enabled = true;
开启 CBO 特性
CBO 特性是基于 Apache Calcite 的,Hive 的 CBO 通过查询成本(有analyze收集的统计信息)会生成有效率的执行计划,最终会减少执行的时间和资源利用。在会话中执行如下命令以开启 CBO(会话级别生效)。
set hive.cbo.enable=true;
set hive.compute.query.using.stats=true;
set hive.stats.fetch.column.stats=true;
set hive.stats.fetch.partition.stats=true;
注:如上优化开关不是万能钥匙,并非适用于所有情况,有时需要关闭,请结合具体的查询场景和 SQL 来设置。
作业调度流程优化
生产环境中,作业的业务优先级是不同的,但是纯粹按照优先级来进行流程调度的话,优先级低的任务长时间不能执行。
根据经验,建议根据作业业务优先级将作业任务分为高、中、低三类,并对应设置 YARN 中的三个队列。通过配置不同的资源配额,比如 7/2/1,在队列设置中实现资源的有效隔离,防止资源抢占和无谓的等待,从而达到整体资源的有效利用。这样的设置可以使高优先级任务获得更多的资源,保证其快速执行,而低优先级任务可以使用较少的资源,以便在资源紧张的情况下仍有机会运行。这种作业调度策略可以提高整个集群的资源利用效率,并确保各优先级作业任务得以顺利执行。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-09-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号