Opencv中goodFeaturesToTrack函数(Harris角点、Shi-Tomasi角点检测)算子速度的进一步优化(1920*1080测试图11ms处理完成)。

Opencv中goodFeaturesToTrack函数(Harris角点、Shi-Tomasi角点检测)算子速度的进一步优化(1920*1080测试图11ms处理完成)。

用户1138785
发布于 2023-11-02 10:16:15
发布于 2023-11-02 10:16:15
搜索到某个效果很好的视频去燥的算法,感觉效果比较牛逼,就是速度比较慢,如果能做到实时,那还是很有实用价值的。于是盲目的选择了这个课题,遇到的第一个函数就是角点检测,大概六七年用过C#实现过Harris角点以及SUSAN角点。因此相关的理论还是有所了解的,不过那个时候重点在于实现,对于效率没有过多的考虑。
那个代码里使用的Opencv的函数叫 goodFeaturesToTrack, 一开始我还以为是个用户自定义的函数呢,在代码里就根本没找到,后面一搜原来是CV自带的函数,其整个的调用为:
goodFeaturesToTrack(img0Gray, featurePtSet0, 10000, 0.05, 5);
这个的意思是从img0Gray图像中,找到10000个角点,角点之间的最小距离是5,使用Shi-Tomasi角点检测算子。
我们查看了下Opencv的代码,写的不是很复杂,但是我是想对一副1920*1080的视频进行去燥,尝试了下仅仅运行goodFeaturesToTrack其中的一个子函数cvCornerHarris,大概就需要50多毫秒。这怎么玩的下去啊。
CV里关于这个函数的代码位于:Opencv 3.0\opencv\sources\modules\imgproc\src\featureselect.cpp中,为了节省篇幅,我删除其一些辅助性的代码和检测,大概就是如下所示:
void cv::goodFeaturesToTrack( InputArray _image, OutputArray _corners,
int maxCorners, double qualityLevel, double minDistance,
InputArray _mask, int blockSize,
bool useHarrisDetector, double harrisK )
{
Mat image = _image.getMat(), eig, tmp;
if( useHarrisDetector )
cornerHarris( image, eig, blockSize, 3, harrisK );
else
cornerMinEigenVal( image, eig, blockSize, 3 );
double maxVal = 0;
minMaxLoc( eig, 0, &maxVal, 0, 0, _mask );
threshold( eig, eig, maxVal*qualityLevel, 0, THRESH_TOZERO );
dilate( eig, tmp, Mat());
Size imgsize = image.size();
std::vector<const float*> tmpCorners;
// collect list of pointers to features - put them into temporary image
Mat mask = _mask.getMat();
for( int y = 1; y < imgsize.height - 1; y++ )
{
const float* eig_data = (const float*)eig.ptr(y);
const float* tmp_data = (const float*)tmp.ptr(y);
const uchar* mask_data = mask.data ? mask.ptr(y) : 0;
for( int x = 1; x < imgsize.width - 1; x++ )
{
float val = eig_data[x];
if( val != 0 && val == tmp_data[x] && (!mask_data || mask_data[x]) )
tmpCorners.push_back(eig_data + x);
}
}
std::sort( tmpCorners.begin(), tmpCorners.end(), greaterThanPtr() );
std::vector<Point2f> corners;
size_t i, j, total = tmpCorners.size(), ncorners = 0;
if (minDistance >= 1)
{
// Partition the image into larger grids
}
else
{
}
Mat(corners).convertTo(_corners, _corners.fixedType() ? _corners.type() : CV_32F);
}先调用cornerHarris或者cornerMinEigenVal函数,得到初步的特征数据,后面的就是进行筛选,minMaxLoc得到最大值,然后根据最大值以及一个用户参数得到一个阈值maxVal*qualityLevel,根据阈值剔除掉一些候选点,这里使用的是threshold函数,然后在进行dilate求局部最大值,然后进行非极大值抑制,再进行最小距离的验证。
一、我们抛开最小距离的验证不说,因为那个的计算量可以忽略不计。先来看看后面的几个部分。
大的开源软件之类的一般都比较讲究函数调用,一般最小粒度的函数会进行一些特别的优化,然后其他一些复杂的函数就实行函数调用,这是一种比较正常的思维,但这种做法必然不可避免的会出现一些重复的计算和冗余,在我这个算法的后半半部分这个就有比较明显的表现,我们先来看看啊:
minMaxLoc这个函数找到最大值没有办法,必须进行,threshold、dilate(三成三的最大值)以及后续的候选点选择,我们仔细分析下,完全是可以写到一个函数里的。在候选点选择里,它使用了判断语句:if( val != 0 && val == tmp_data[x] && (!mask_data || mask_data[x]) ) 抛开后续的mask的判断部分,前面的 val != 0 的判断依据是前面进行threshold后,所有小于maxVal*qualityLevel的部分都已经等于零0,那也就是等价于判断 val >= maxVal*qualityLevel是否成立。 判断val == tmp_data[x]两者是否相等,是判断当前值是否是3*3领域内的最大值的意思,程序里先求出3*3领域的最大值,然后在判断是否相等,这里其实是有所浪费资源的。 我们知道,每次加载内存和保存数据到内存在某种程度上来说都是有着较大的消耗的,但是在CPU内核里进行一些计算速度是相当快的,因此,既然上述这是几个功能其实可以集中到一起实现,我们就没有必然分散到各个函数中,而是可以全部集中到一个代码中,
下面是我使用C语言初步整理的一个过程:
在CV的代码里,也是忽略了边缘以一圈的判断的,因为边缘部分不太可能符合角点的定义的。
我们看上述代码,其中的Max >= MaxValue取代了threshold的功能, Max == P4完成了最大值计算以及后续的判断是否相等的问题。而整个过程只需要遍历一次全图,且内部的判断量是一样的,而原始的代码需要遍历三次内存数据,并且需要保存到临时的内存中。
上述代码也非常容易进行指令集的优化。
另外,当我们使用注释掉的 // float Max = IM_Max(Max0, Max1)语句时, 后面的判断Max == P4修改为Max <= P4,还可以减少一次判断。
二、cornerHarris或者cornerMinEigenVal的优化
这两个函数位于Opencv 3.0\opencv\sources\modules\imgproc\src\corner.cpp路径下,核心的部分如下所示:
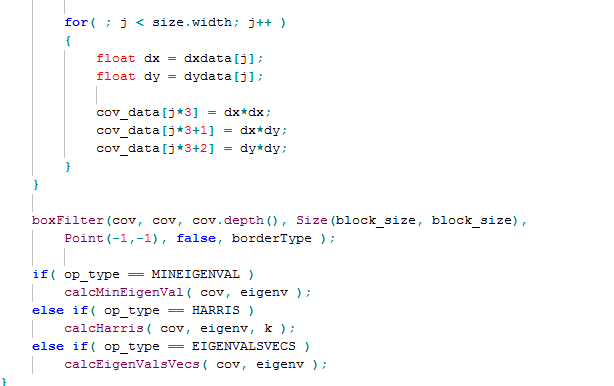
dx\dy是X和Y方向的一阶导数,cv实现的比较复杂,可以支持较大尺寸的,但是常用的就是3*3领域的,我前面用CV做速度测试也是用的3*3的,这个的优化获取可以见我博客的SSE图像算法优化系列九:灵活运用SIMD指令16倍提升Sobel边缘检测的速度(4000*3000的24位图像时间由480ms降低到30ms) 。
为了速度起见,我觉得这里的dx,dy没有必要用float类型来表达,直接使用int类型应该是足够的,但是opencv这种数据的排布方式我觉得不太科学,他是dx*dx, dy*dy,dx*dy保存在连续的内存中,类似于图像格式中的RGB24格式,这个格式在一些涉及到领域的算法里不太友好,而本例后续就需要使用有关的领域算法。因此,我觉得应该是把他们分别保存到单独的内存空间中。
后续的boxFilter必须有,而且一般我觉得半径为1,即block_size等于3就完全可以满足要求了,而这个半径的模糊是可以做一些特别的优化的。
后续的calcHarris函数没有啥特别的,只能按部就班的计算,但是可以考虑的是,上面的minMaxLoc获取最大值函数其实是可以在calcHarris函数里一并执行的,这样又可以减少一次遍历和循环。
这里要优化的重点还是这个dx*dx, dy*dy,dx*dy的获取以及方框模糊的优化。
第一: 肯定是可以用指令集去处理的。当我们的中间结果都用int类型来表达时,我们中间涉及到部分的优化细节如下(纯做记录):
我们通过某些计算得到了dx和dy值,他们值是可以用short类型来记录的,这个时候我们求dx * dy一般情况是通过如下语句实现:
__m128i DxDy_L = _mm_mullo_epi32(_mm_cvtepi16_epi32(Dx), _mm_cvtepi16_epi32(Dy));
__m128i DxDy_H = _mm_mullo_epi32(_mm_cvtepi16_epi32(_mm_srli_si128(Dx, 8)), _mm_cvtepi16_epi32(_mm_srli_si128(Dy, 8)));其实我们也可以通过如下代码实现:
__m128i L = _mm_mullo_epi16(Dx, Dy);
__m128i H = _mm_mulhi_epi16(Dx, Dy);
__m128i DxDy_L = _mm_unpacklo_epi16(L, H);
__m128i DxDy_H = _mm_unpackhi_epi16(L, H);效果是相同的,但是会少两条指令,速度要稍微优异一点。
第二:如果我们将dx\dy归整到-255到255之间(这个也是正常的需求,一般这些一阶二阶的算子的系数之和都应该是0,这样,他们所能取到的最大值就是这个范围),那么dx *dx以及dy*dy的范围就在unsigned short所能表达的范围内了,而dx * dy还是必须使用int类型来表示。这样做的好处有很多。 首先是数据类型的变小,是的我们可以用指令集一次性处理更多的数据,二是写入内存或者从内存读取数据的工作量变小了。
别看这点改动,我们实测发现至少有15%以上的速度提升。
第三:我们看看boxFilter这里的优化,当我们使用半径为1的优化时,这也是这个算子最常用的取值, 我们需要,计算3*3的领域后除以9,如果老老实实的除以9,不管是浮点数,还是整形,也不管是用乘以0.1111111111代替,还是咋样,反正都要计算量,其实我们完全可以不用除,前期是dx*dx, dy*dy,dx*dy大家都不除,因为我们发现后续的计算里这个分母是可以消除的。 这样只要保存3*3的和就OK了。
更进一步,如果我们将dx\dy归整到-127到127之间,我们发现dx*dx以及dy*dy的最大值就将被限制在16129之间,这样在做boxFilter时,其中四个dx * dx的累加可以直接使用_mm_adds_epu16实现,而不用转换到32位使用_mm_add_epi32,可进一步提高速度。
而如果极限压缩dx\dy归整到-63到63之间,则3*3的累加完全可以直接使用_mm_adds_epu16而不溢出,此时对于 dx * dy,一方面他也可以直接使用short类型来保存,另外,9次领域的这个值相加也是可以直接借助_mm_adds_epi16而保证不溢出的(相邻的9点的dx * dy 不可能同时到最大值)。
比如使用规整到-63到63之间的 boxFilter就可以使用如下算子实现:
int IM_FastestBoxBlur3X3_I16(short *Src, short *Dest, int Width, int Height)
{
if ((Src == NULL) || (Dest == NULL)) return IM_STATUS_NULLREFRENCE;
if ((Width <= 0) || (Height <= 0)) return IM_STATUS_INVALIDPARAMETER;
short *RowCopy = (short *)malloc((Width + 2) * 3 * sizeof(short));
if (RowCopy == NULL) return IM_STATUS_OUTOFMEMORY;
short *First = RowCopy;
short *Second = RowCopy + (Width + 2);
short *Third = RowCopy + (Width + 2) * 2;
memcpy(Second, Src, sizeof(short));
memcpy(Second + 1, Src, Width * sizeof(short)); // 拷贝数据到中间位置
memcpy(Second + (Width + 1), Src + (Width - 1), sizeof(short));
memcpy(First, Second, (Width + 2) * sizeof(short)); // 第一行和第二行一样
memcpy(Third, Src + Width, sizeof(short)); // 拷贝第二行数据
memcpy(Third + 1, Src + Width, Width * sizeof(short));
memcpy(Third + (Width + 1), Src + Width + (Width - 1), sizeof(short));
int BlockSize = 8, Block = Width / BlockSize; // 测试表面一次性处理4个像素处理8个要快一些
for (int Y = 0; Y < Height; Y++)
{
short *LinePS = Src + Y * Width;
short *LinePD = Dest + Y * Width;
if (Y != 0)
{
short *Temp = First; First = Second; Second = Third; Third = Temp;
}
if (Y == Height - 1)
{
memcpy(Third, Second, (Width + 2) * sizeof(short));
}
else
{
memcpy(Third, Src + (Y + 1) * Width, sizeof(short));
memcpy(Third + 1, Src + (Y + 1) * Width, Width * sizeof(short)); // 由于备份了前面一行的数据,这里即使Src和Dest相同也是没有问题的
memcpy(Third + (Width + 1), Src + (Y + 1) * Width + (Width - 1), sizeof(short));
}
for (int X = 0; X < Block * BlockSize; X += BlockSize)
{
__m128i P0 = _mm_loadu_si128((__m128i *)(First + X));
__m128i P1 = _mm_loadu_si128((__m128i *)(First + X + 1));
__m128i P2 = _mm_loadu_si128((__m128i *)(First + X + 2));
__m128i P3 = _mm_loadu_si128((__m128i *)(Second + X));
__m128i P4 = _mm_loadu_si128((__m128i *)(Second + X + 1));
__m128i P5 = _mm_loadu_si128((__m128i *)(Second + X + 2));
__m128i P6 = _mm_loadu_si128((__m128i *)(Third + X));
__m128i P7 = _mm_loadu_si128((__m128i *)(Third + X + 1));
__m128i P8 = _mm_loadu_si128((__m128i *)(Third + X + 2));
__m128i Sum0123 = _mm_adds_epi16(_mm_adds_epi16(P0, P1), _mm_adds_epi16(P2, P3));
__m128i Sum5678 = _mm_adds_epi16(_mm_adds_epi16(P5, P6), _mm_adds_epi16(P7, P8));
__m128i Sum = _mm_adds_epi16(_mm_adds_epi16(Sum0123, Sum5678), P4);
_mm_storeu_si128((__m128i *)(LinePD + X), Sum);
}
for (int X = Block * BlockSize; X < Width; X++)
{
int P0 = First[X], P1 = First[X + 1], P2 = First[X + 2];
int P3 = Second[X], P4 = Second[X + 1], P5 = Second[X + 2];
int P6 = Third[X], P7 = Third[X + 1], P8 = Third[X + 2];
LinePD[X] = P0 + P1 + P2 + P3 + P4 + P5 + P6 + P7 + P8;
}
}
free(RowCopy);
return IM_STATUS_OK;
}三、其他小细节的优化
还有很多细节上的东西对速度有一定的影响,我们发现,要尽量减少内存的分配,如果能共用的内存,就一定要共用,特别是读和写的内存如果是同一个,会对速度产生一定的加速,比如,我们分配的dx 和 dy内存就可以和后续的Eignev内存共用同一个地址,因为dx和dy后续就不需要使用了,这样即节省了内存又提高了速度。
另外, 因为角点不会存在于图像周边一圈像素中,因此,边缘就不可以不用计算,这在减少计算量的同时,对于部分算法,也可以减少一些内存复制。
四、速度优化结果探讨
经过一系列的操作,我做了5个版本的测试,第一个是基本重复Opencv的代码,第二个是按照上述描述吧threshold, dilate等过程集中到一起,第三个使用-255到255范围内的dx/dy,第四个是用使用-127到127范围内的dx/dy,第五个是用-63到63范围内的dx/dy, 对一副1920*1024大小的测试图像,做同参数的角点测试,耗时基本如下:
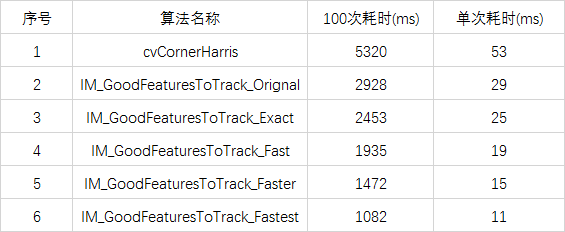
Opencv中我测试的还只是其goodFeaturesToTrack中的部分算子,估计全部加起来可能要90ms一次,因此,可以看到提速的比例和空间相当大。
当然,这里并不是说CV不好,而是针对某些具体的场景,我们还可以进一步增强其实用性。
在回到我们的初衷,我们想实现的视频的实时增强,这个一般要求单帧的处理耗时不易大于20ms, 看来即使使用我这个最简化的版本,实时的梦想还是不太靠谱啊,哎,还是得靠GPU来做。 不够如果把视频大小改为1024*768呢,那这个的耗时可以减低到5ms,也许还有希望。
五、结果比较
选择了几个比较常用的测试图做比较,发现原始的版本和最速版基本上么有大的区别,只有局部有几个点有偏移,而且从视觉上看也不能说最速版的结果就不正确。




原始版 最速版 原始版 最速版
如果是对于实际中的比较复杂的图,虽有波动,但对结果的影响应该说是比较小的。
分享一个测试DEMO: https://files.cnblogs.com/files/Imageshop/CornerDetect.rar?t=1698823382&download=true
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2023-11-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者
