一个超强算法全总结,SVM !!

一个超强算法全总结,SVM !!

Python编程爱好者
发布于 2023-12-05 17:59:30
发布于 2023-12-05 17:59:30
哈喽,我是Johngo~
很多同学对于 支持向量机·非常感兴趣,也是初学者在学习过程中,超级喜欢的一种算法模型。
也是最重要的算法模型之一!
老规矩:大家伙如果觉得近期文章还不错!欢迎大家点个赞、转个发,让更多的朋友看到。
今天咱们再来聊聊关于 SVM 的细节,分别从 2 方面进行解释~
- SVM 的基础内容
- 线性可分SVM
- 非线性 SVM 和核方法
- 软间隔和正则化
- 优化问题(软间隔)
- 绘制一个 3D 超平面
- 最适合利用 SVM 解决的问题之一,二分类问题
支持向量机(SVM)是一种监督学习算法,主要用于分类问题,但也可以用于回归问题。SVM 的核心思想是找到一个最优的超平面,以最大化不同类别之间的边距。
SVM 原理性内容
1. 线性可分 SVM
在最简单的情况下,当数据是线性可分的,即可以通过一个直线(在二维空间)或平面(在三维空间)等超平面来完美分隔不同类别的数据点。
- 最优超平面:这个超平面的选择是使得最近的数据点(支持向量)到超平面的距离最大化。在二维空间中,这个超平面是一条直线。
- 数学表达:超平面可以用以下方程表示:
其中
是超平面的法向量,
是偏置项。
- 决策规则:分类决策是通过符号函数根据超平面来进行的:
- 优化问题:目标是最大化边距,这可以转化为以下优化问题:
2. 非线性 SVM 和核方法
当数据不是线性可分的时,可以使用核方法。核方法通过一个非线性映射将原始特征空间映射到一个更高维的空间,在这个新空间中数据可能是线性可分的。
- 核函数:常用的核函数包括多项式核、径向基函数(RBF,也称为高斯核)等。
- 核函数的作用:核函数允许在原始空间中计算出点积,而不需要显式地在高维空间中表示数据点。
3. 软间隔和正则化
在现实世界的数据中,很少有完全线性可分的情况。因此,引入软间隔的概念,允许一些数据点违反边距规则。
- 松弛变量:通过引入松弛变量
来处理重叠和非可分的情况。
- 正则化参数 C:参数 C 控制着边距的硬度和对于错误分类的惩罚,是一个正则化参数。
4. 优化问题(软间隔)
对于软间隔 SVM,优化问题变为:
绘制 SVM 超平面
下面代码,咱们利用 matplotlib 和 scikit-learn 库来训练 SVM 模型并绘制一个三维超平面。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm
from sklearn.datasets import make_blobs
# 创建 2D 数据集
X, y = make_blobs(n_samples=40, centers=2, random_state=6)
# 训练 SVM 模型
clf = svm.SVC(kernel='linear', C=1000)
clf.fit(X, y)
# 绘制数据点
plt.scatter(X[:, 0], X[:, 1], c=y, s=30, cmap=plt.cm.Paired)
# 绘制决策边界
ax = plt.gca()
xlim = ax.get_xlim()
ylim = ax.get_ylim()
# 创建网格来评估模型
xx = np.linspace(xlim[0], xlim[1], 30)
yy = np.linspace(ylim[0], ylim[1], 30)
YY, XX = np.meshgrid(yy, xx)
xy = np.vstack([XX.ravel(), YY.ravel()]).T
Z = clf.decision_function(xy).reshape(XX.shape)
# 绘制决策边界和边距
ax.contour(XX, YY, Z, colors='k', levels=[-1, 0, 1], alpha=0.5, linestyles=['--', '-', '--'])
# 标记支持向量
ax.scatter(clf.support_vectors_[:, 0], clf.support_vectors_[:, 1], s=100, linewidth=1, facecolors='none', edgecolors='k')
plt.show()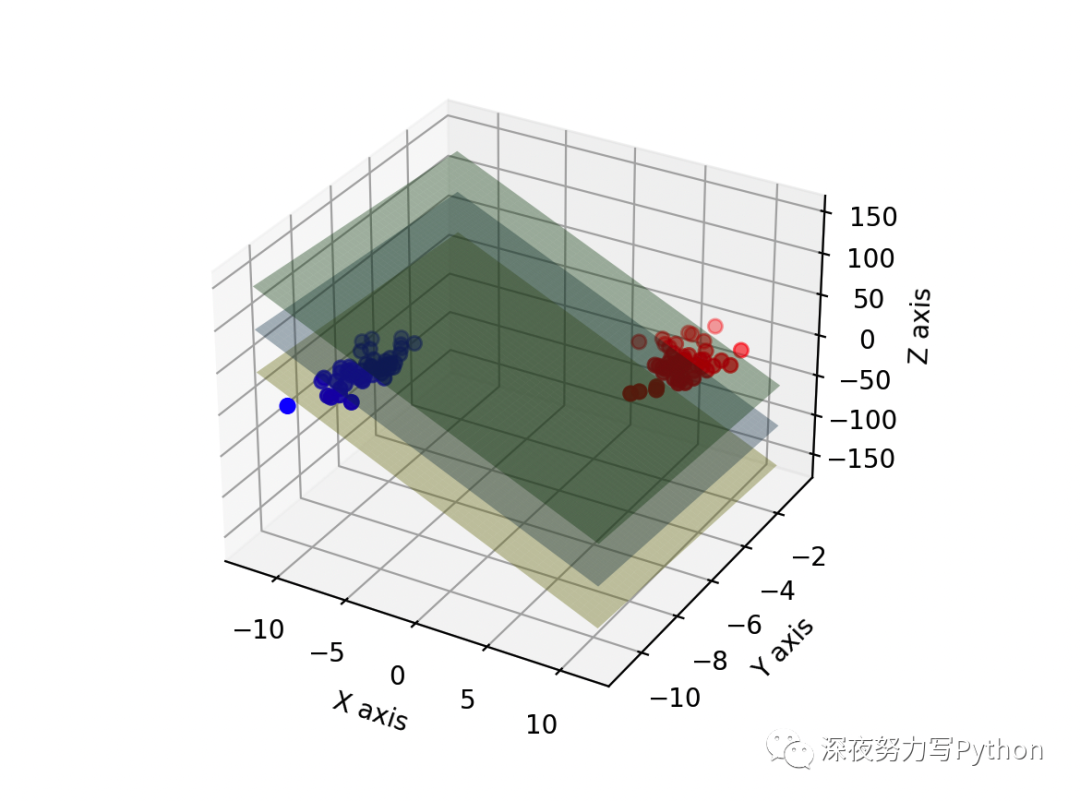
生成一个 3D 图,其中包含数据点、决策超平面以及两个表示软间隔的平面。
下面,咱们利用鸢尾花数据集,做一个项目。
一个案例
项目简介
本项目利用支持向量机(SVM)在鸢尾花(Iris)数据集上进行分类。项目的重点是通过网格搜索寻找最佳的SVM参数,并可视化不同参数对决策边界的影响。项目的最终目标是理解SVM参数如何影响模型性能,并通过数据可视化加深这一理解。
算法原理
在分类任务中,SVM 的目标是找到一个超平面,该平面能够最好地分隔不同类别的数据点。
- 核函数:SVM 通过使用核技巧来处理线性不可分的数据,常见的核包括线性核、多项式核和径向基函数(RBF)核。
- 正则化参数(C):这个参数控制着决策边界的平滑程度。较小的 C 值导致更平滑的决策边界,而较大的 C 值则让模型更多地适应训练数据。
- Gamma:在 RBF 核中,gamma 参数定义了单个训练样本的影响范围。较小的 gamma 值意味着更大的影响范围,而较大的 gamma 会使影响范围变小。
算法步骤
- 数据预处理:加载鸢尾花数据集,进行标准化处理。
- 参数网格定义:定义一个参数网格,包括不同的 C 和 gamma 值。
- 网格搜索:使用
GridSearchCV在参数网格上进行搜索,找到最佳的参数组合。 - 模型训练:使用找到的最佳参数,在全数据集上训练 SVM 模型。
- 决策边界可视化:在 2D 数据上训练多个 SVM 模型,并可视化这些模型的决策边界。
- 绘制热图:绘制一个热图,展示不同参数组合下的模型性能。
完整代码
import numpy as np
from matplotlib.colors import Normalize
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import GridSearchCV, StratifiedShuffleSplit
from sklearn.svm import SVC
import matplotlib.pyplot as plt
# 自定义归一化类
class MidpointNormalize(Normalize):
def __init__(self, vmin=None, vmax=None, midpoint=None, clip=False):
self.midpoint = midpoint
Normalize.__init__(self, vmin, vmax, clip)
def __call__(self, value, clip=None):
x, y = [self.vmin, self.midpoint, self.vmax], [0, 0.5, 1]
return np.ma.masked_array(np.interp(value, x, y))
# 数据加载和预处理
iris = load_iris()
X = iris.data
y = iris.target
# 二维化数据,只保留两个特征和两个类别
X_2d = X[:, :2]
X_2d = X_2d[y > 0]
y_2d = y[y > 0]
y_2d -= 1
# 数据标准化
scaler = StandardScaler()
X = scaler.fit_transform(X)
X_2d = scaler.fit_transform(X_2d)
# 参数网格和网格搜索
C_range = np.logspace(-2, 10, 13)
gamma_range = np.logspace(-9, 3, 13)
param_grid = dict(gamma=gamma_range, C=C_range)
cv = StratifiedShuffleSplit(n_splits=5, test_size=0.2, random_state=42)
grid = GridSearchCV(SVC(), param_grid=param_grid, cv=cv)
grid.fit(X, y)
print("The best parameters are %s with a score of %0.2f" % (grid.best_params_, grid.best_score_))
# 训练用于可视化的分类器
C_2d_range = [1e-2, 1, 1e2]
gamma_2d_range = [1e-1, 1, 1e1]
classifiers = []
for C in C_2d_range:
for gamma in gamma_2d_range:
clf = SVC(C=C, gamma=gamma)
clf.fit(X_2d, y_2d)
classifiers.append((C, gamma, clf))
# 决策边界可视化
plt.figure(figsize=(8, 6))
xx, yy = np.meshgrid(np.linspace(-3, 3, 200), np.linspace(-3, 3, 200))
for k, (C, gamma, clf) in enumerate(classifiers):
Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.subplot(len(C_2d_range), len(gamma_2d_range), k + 1)
plt.title("gamma=10^%d, C=10^%d" % (np.log10(gamma), np.log10(C)), size="medium")
plt.pcolormesh(xx, yy, -Z, cmap=plt.cm.RdBu)
plt.scatter(X_2d[:, 0], X_2d[:, 1], c=y_2d, cmap=plt.cm.RdBu_r, edgecolors="k")
plt.xticks(())
plt.yticks(())
plt.axis("tight")
# 热图绘制
scores = grid.cv_results_["mean_test_score"].reshape(len(C_range), len(gamma_range))
plt.figure(figsize=(8, 6))
plt.subplots_adjust(left=0.2, right=0.95, bottom=0.15, top=0.95)
plt.imshow(
scores,
interpolation="nearest",
cmap=plt.cm.hot,
norm=MidpointNormalize(vmin=0.2, midpoint=0.92),
)
plt.xlabel("gamma")
plt.ylabel("C")
plt.colorbar()
plt.xticks(np.arange(len(gamma_range)), gamma_range, rotation=45)
plt.yticks(np.arange(len(C_range)), C_range)
plt.title("Validation accuracy")
plt.show()代码中:
- **自定义归一化类 (
MidpointNormalize)**:用于热图中的分数归一化,使热图的中点可自定义。 - 加载和预处理数据:加载鸢尾花数据集,对数据进行二维化和标准化处理。
- 定义参数网格和网格搜索:设置 SVM 的
C和gamma参数范围,使用GridSearchCV进行网格搜索。 - 训练分类器:在二维数据上训练多个 SVM 分类器,每个分类器使用不同的
C和gamma组合。 - 可视化:绘制每个 SVM 分类器的决策边界,并绘制热图以展示不同参数组合下的性能。
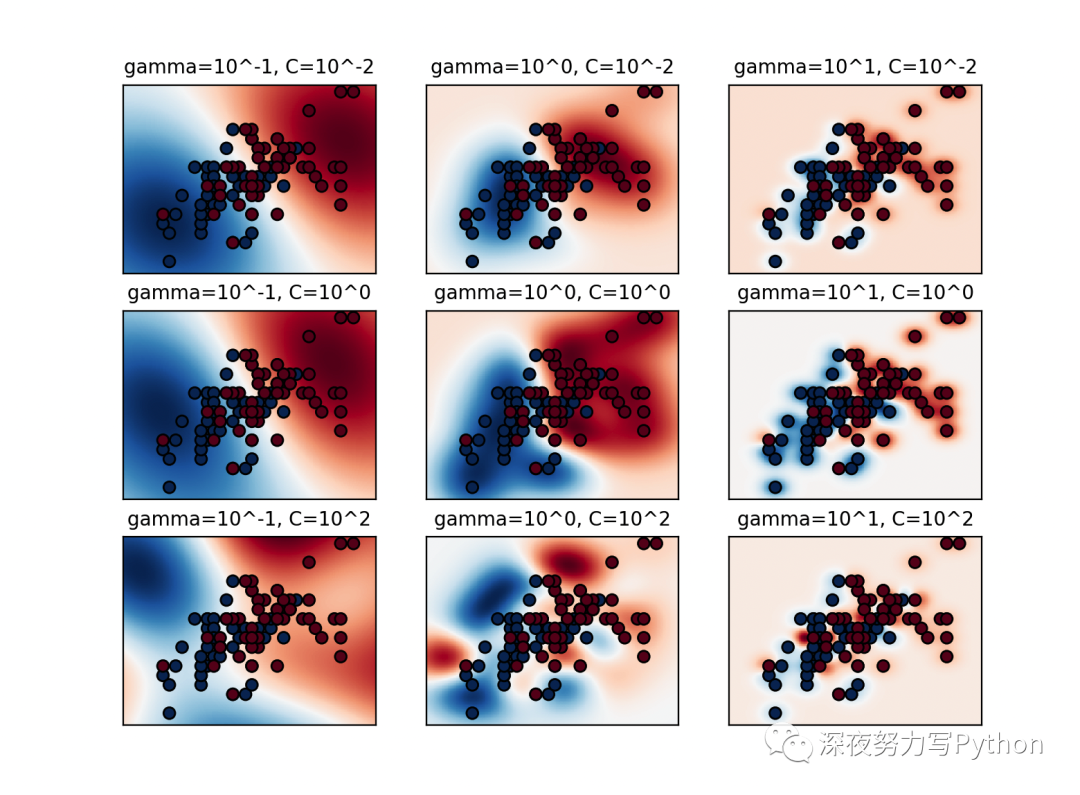
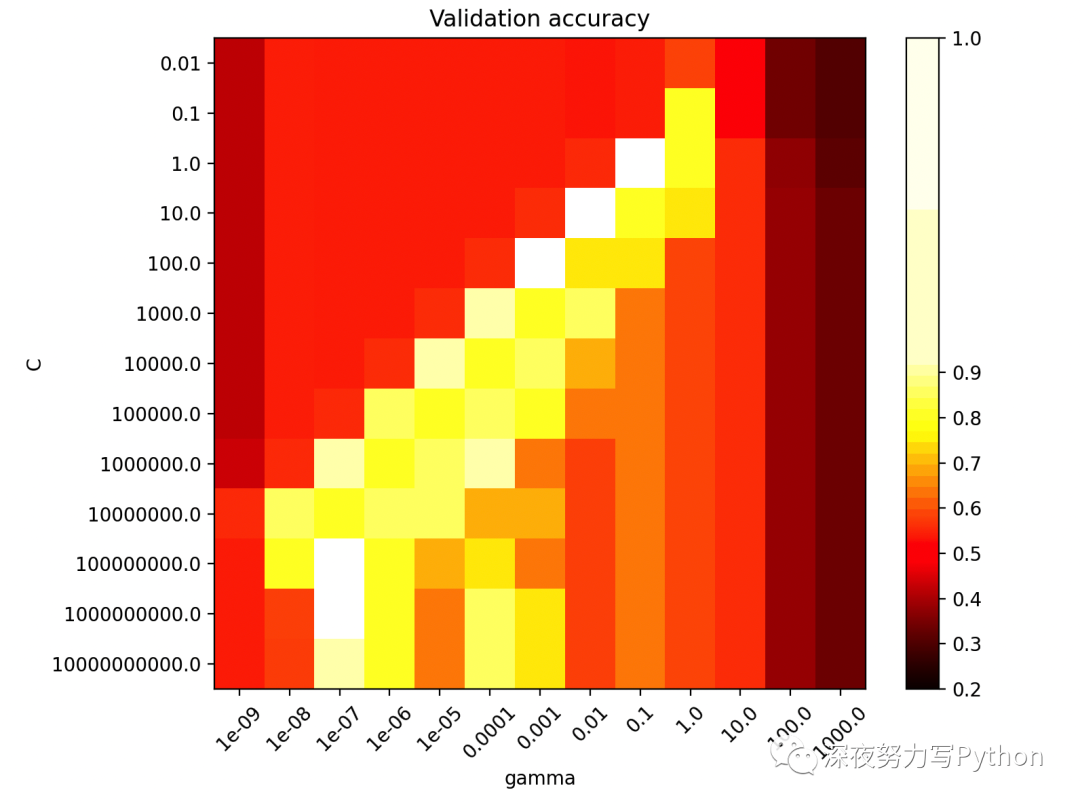
在这个项目中,核心使用的算法是支持向量机(SVM)。这里的实现主要集中在使用 SVM 进行二分类问题的处理。
最后聊聊 SVM 主要特点
- 最大化边际:SVM 的目标是找到一个最优超平面,使得不同类别的数据点之间的边际(即最近的点到超平面的距离)最大化。
- 核技巧:当数据不是线性可分时,SVM 可以通过核函数将数据映射到更高维的空间中,以找到一个合适的决策边界。在这个项目中,尽管没有明确指定核函数,但默认情况下,
sklearn.svm.SVC使用的是径向基函数(RBF)核。 - 正则化:通过调整参数 C(在此项目中进行了调优),可以控制分类间隔的宽度和分类错误之间的平衡。较小的 C 值鼓励更宽的间隔(更强的正则化),而较大的 C 值则允许更小的间隔,让模型更多地适应训练数据。
- 适用性:SVM 在小到中等规模的数据集上表现出色,特别是在高维空间中。
上述项目中,SVM 主要用于在鸢尾花数据集上进行分类任务,同时通过网格搜索优化参数 C 和 gamma,以达到更好的分类效果。这种方法特别适合于那些需要精确调整以获得最佳性能的场景。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-12-03,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号