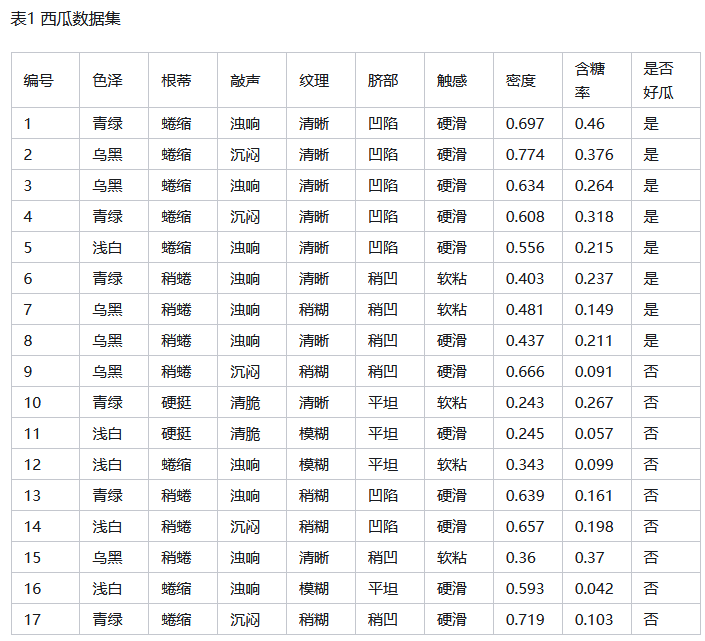
机器学习-04-分类算法-01决策树

总结
本系列是机器学习课程的系列课程,主要介绍机器学习中分类算法,本篇为分类算法开篇与决策树部分。
本门课程的目标
完成一个特定行业的算法应用全过程:
懂业务+会选择合适的算法+数据处理+算法训练+算法调优+算法融合 +算法评估+持续调优+工程化接口实现
机器学习定义
关于机器学习的定义,Tom Michael Mitchell的这段话被广泛引用: 对于某类任务T和性能度量P,如果一个计算机程序在T上其性能P随着经验E而自我完善,那么我们称这个计算机程序从经验E中学习。
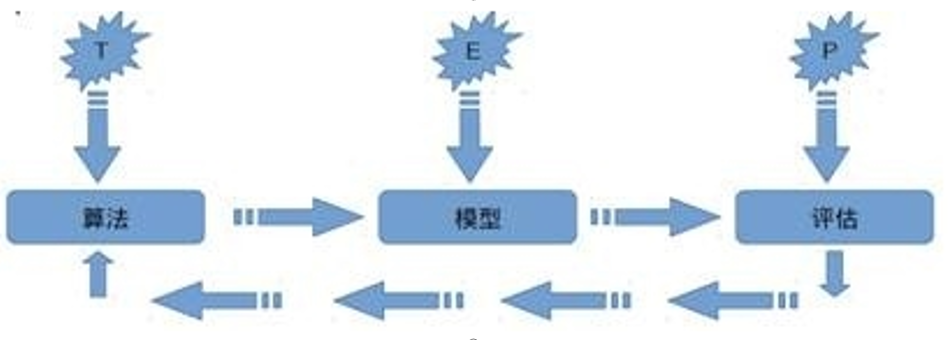
分类方法的定义


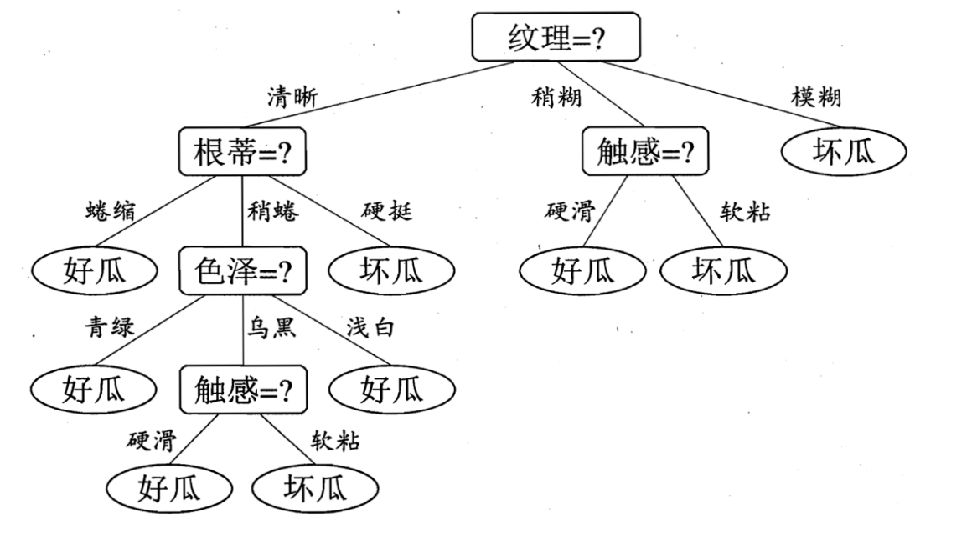
决策树算法
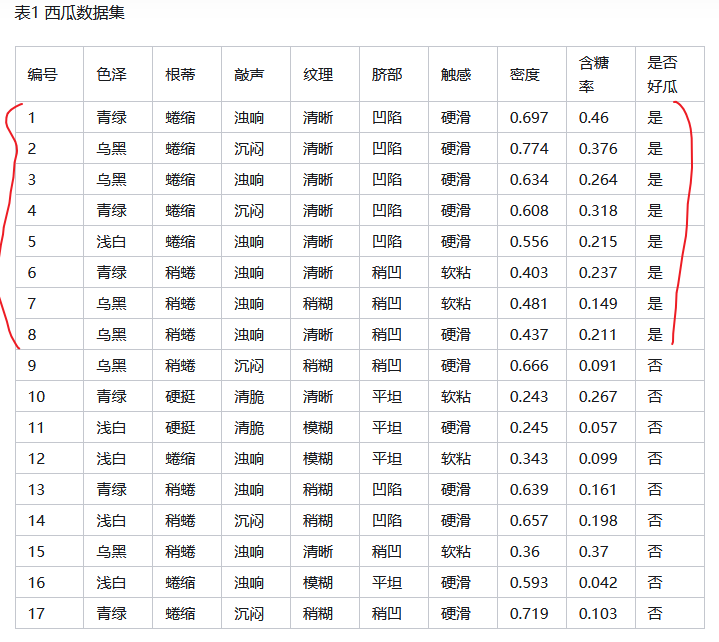
什么是好瓜

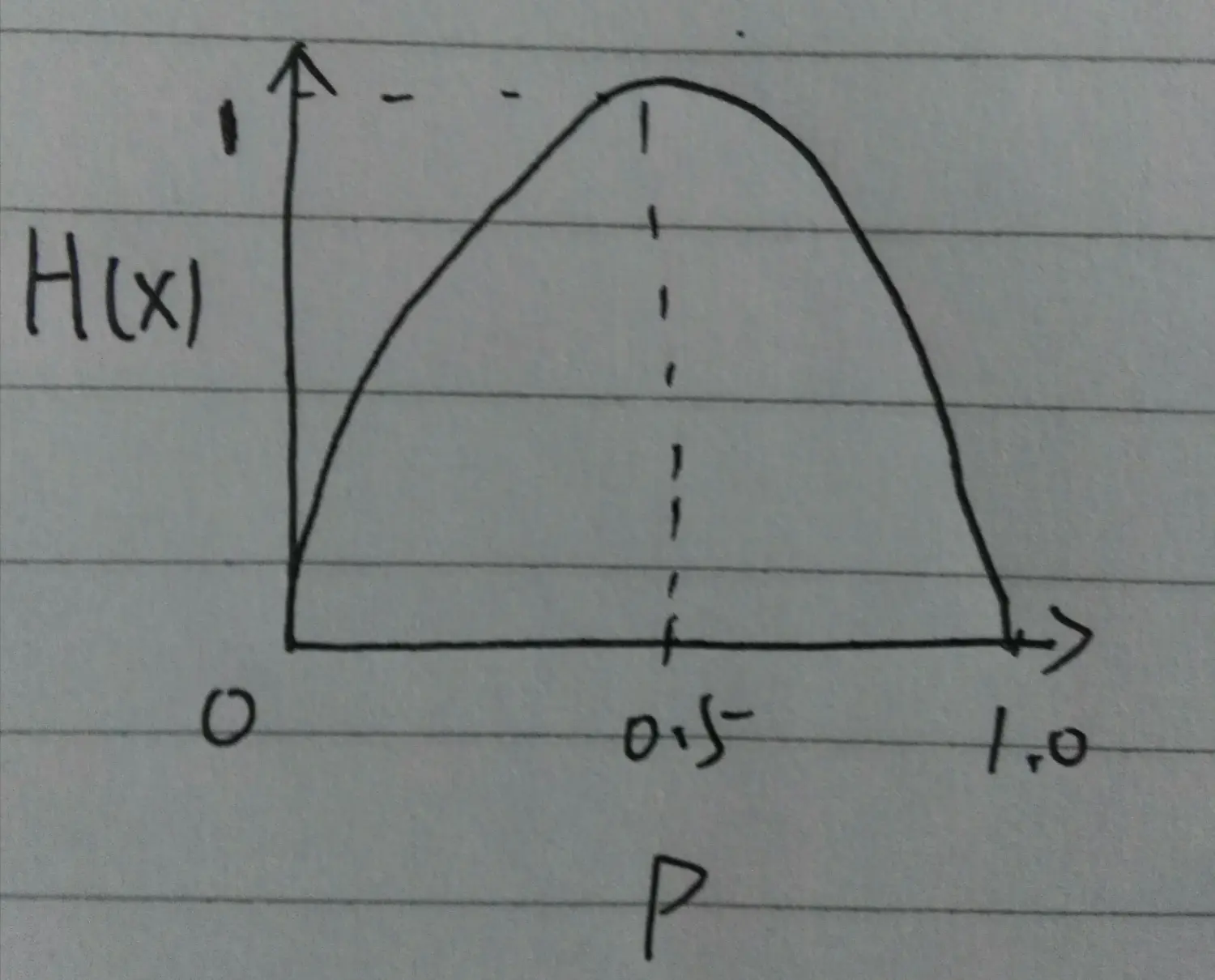
熵的概念来源于热力学。在热力学中熵的定义是系统可能状态数的对数值,称为热熵。它是用来表达分子状态杂乱程度的一个物理量。热力学指出,对任何已知孤立的物理系统的演化,热熵只能增加,不能减少。 信息的基本作用就是消除人们对事物了解的不确定性。美国信息论创始人香农发现任何信息都存在冗余,冗余的大小与信息的每一个符号出现的概率和理想的形态有关。信息熵表示的是信息的混乱程度。当均匀分布时,信息熵最大。当熵除一个值之外,其他值均为0,信息熵最小。 和热力学中的熵相反的是,信息熵只能减少,不能增加。 所以热熵和信息熵互为负量。且已证明,任何系统要获得信息必须要增加热熵来补偿,即两者在数量上是有联系的。
信息熵信息量的量化过程:
例如: 事件A:明天的太阳会从东边升起。 事件B:虽然明天的太阳还是从东边升起,但是明天要下雪。 信息量没有量化
信息量的表达式应该满足的条件:
(1)信息量和事件发生的概率有关,当事件发生的概率越低或者越高,传递的信息量越大; (2)信息量应当是非负的,必然发生的信息量为0; (3)两个事件的信息量可以相加,并且两个独立事件的联合信息量应该是他们各自信息量的和;
信息熵的量化过程:


熵随着概率的变化为:
信息增益的计算
信息增益=信息熵-条件熵 g(D,A)=H(D) –H(D|A)
条件熵是另一个变量Y熵对X(条件)的期望。
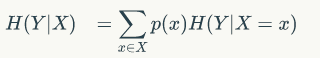
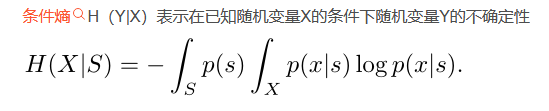
信息增益(Information Gain):熵A-条件熵B,是信息量的差值。也就是说,一开始是A,用了条件后变成了B,则条件引起的变化是A-B,即信息增益。好的条件就是信息增益越大越好。因此我们在树分叉的时候,应优先使用信息增益最大的属性,这样降低了复杂度,也简化了后边的逻辑。
比如下面数据:
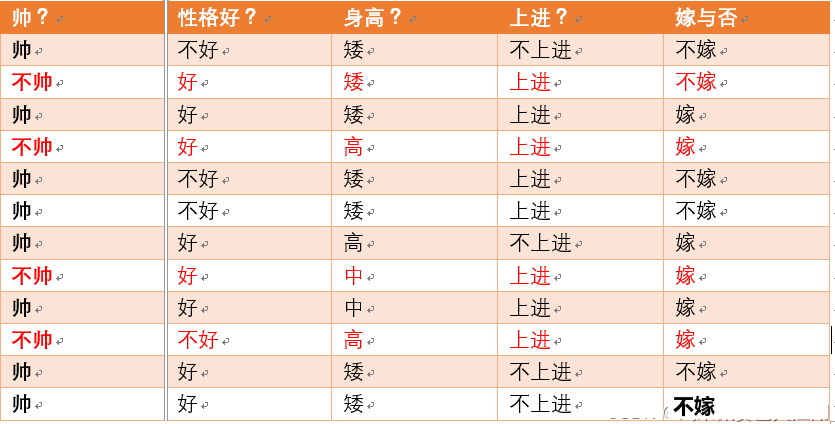
初始的信息熵H(A)为:
一共12人,嫁的有6人,不嫁的有6人 H(A) = -1/2 * (log1/2) -1/2 * (log1/2)=-log1/2
可以得出,
当已知不帅的条件下,满足条件的只有4个数据了,这四个数据中,不嫁的个数为1个,占1/4,嫁的个数为3个,占3/4 那么此时的 H(Y|X = 不帅) = -1/4log1/4 - 3/4log3/4 p(X = 不帅) = 4/12 = 1/3
同理我们可以得到:
当已知帅的条件下,满足条件的有8个数据了,这八个数据中,不嫁的个数为5个,占5/8 ,嫁的个数为3个,占3/8 那么此时的 H(Y|X = 帅) = -5/8log5/8 - 3/8log3/8 p(X = 帅) = 8/12 = 2/3
计算结果
有了上面的铺垫之后,我们终于可以计算我们的条件熵了,我们现在需要求: H(Y|X = 长相) 也就是说,我们想要求出当已知长相的条件下的条件熵。 根据公式我们可以知道,长相可以取帅与不帅俩种,然后将上面已经求得的答案带入即可求出条件熵! H(Y|X=长相) = p(X =帅)*H(Y|X=帅)+p(X =不帅)*H(Y|X=不帅) =2/3 * (-5/8log5/8 - 3/8log3/8) + 1/3 *(-1/4log1/4 - 3/4log3/4) =
此时的信息增益计算为:
g(D,A) =H(D) –H(D|A) = -log1/2 - (2/3 * (-5/8log5/8 - 3/8log3/8) + 1/3 *(-1/4log1/4 - 3/4log3/4))
其实条件熵意思是按一个新的变量的每个值对原变量进行分类,比如上面这个题把嫁与不嫁按帅,不帅分成了俩类。 然后在每一个小类里面,都计算一个小熵,然后每一个小熵乘以各个类别的概率,然后求和。 我们用另一个变量对原变量分类后,原变量的不确定性就会减小了,因为新增了X的信息,可以感受一下。不确定程度减少了多少就是信息的增益。
再举一个例子
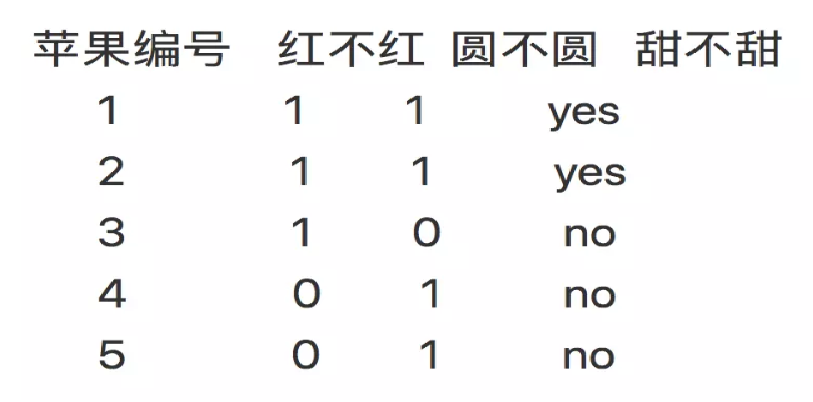

如果采用苹果编号为条件,会发现,此时信息增益最大,因为编号1的叶子节点只有yes,此时的信息熵为0,最后会导致,信息增益会选择苹果编号为分割条件。
举例:



信息增益率的计算

基尼系数的计算