AI绘图Stable Diffusion中关键技术:U-Net的应用

AI绘图Stable Diffusion中关键技术:U-Net的应用

double
发布于 2024-03-18 16:33:36
发布于 2024-03-18 16:33:36
你好,我是郭震
引言
在人工智能和深度学习的迅猛发展下,图像生成技术已经取得了令人瞩目的进展。特别是,Stable Diffusion模型以其文本到图像的生成能力吸引了广泛关注。本文将深入探讨Stable Diffusion中一个关键技术——U-Net架构的应用,揭示它如何在生成细节丰富且与文本描述紧密相连的图像中发挥核心作用。
U-Net架构概述
U-Net最初设计用于医学图像分割,其特点是一种对称的编码器-解码器结构,中间通过跳跃连接直接传递特征图。这种结构能够在图像的不同层次中保留丰富的细节信息,是U-Net在图像处理任务中表现出色的关键。
Unet提出的初衷是为了解决医学图像分割的问题;一种U型的网络结构来获取上下文的信息和位置信息;在2015年的ISBI cell tracking比赛中获得了多个第一,一开始这是为了解决细胞层面的分割的任务的。
这个结构的巧妙之处,通过下面例子我们看下:
说一开始的图片是224x224的,那么就会变成112x112,56x56,28x28,14x14四个不同尺寸的特征。然后我们对14x14的特征图做上采样或者反卷积,得到28x28的特征图,这个28x28的特征图与之前的28x28的特征图进行通道上的拼接concat,
然后再对拼接之后的特征图做卷积和上采样,得到56x56的特征图,
再与之前的56x56的特征拼接,卷积,再上采样,经过四次上采样可以得到一个与输入图像尺寸相同的224x224的预测结果。
归纳下U-Net:
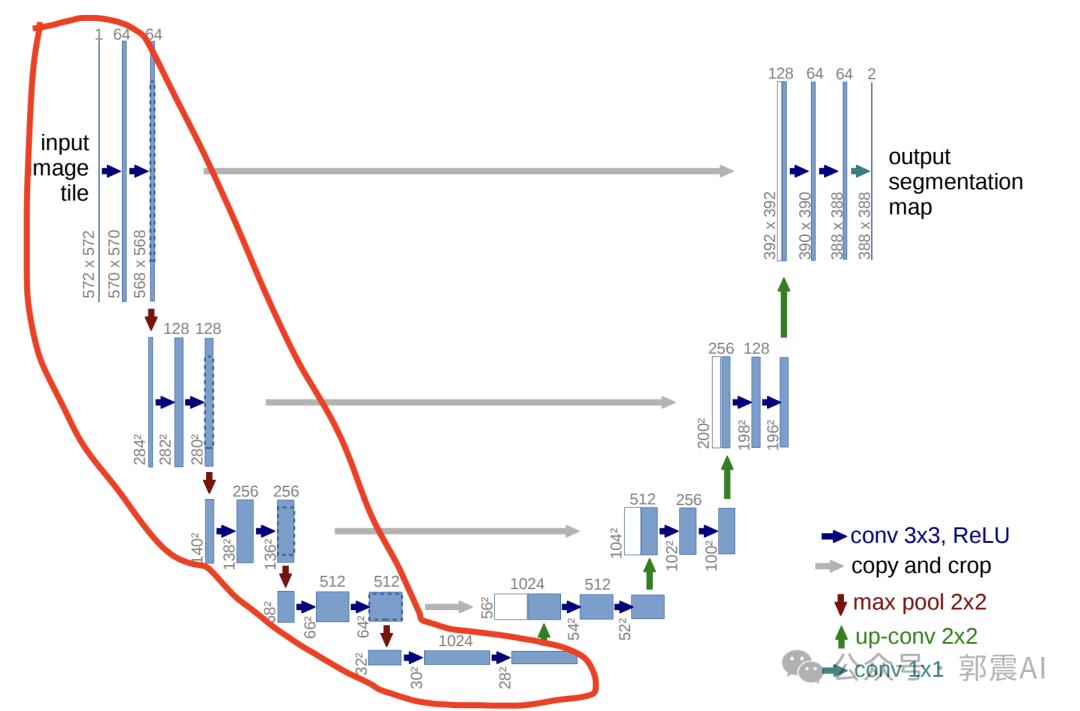
特征提取与降采样:在U-Net架构的编码器部分,输入图像首先经过一系列卷积层和池化层进行处理,目的是提取图像的特征并逐渐降低图像的空间维度(尺寸)。这一过程中,图像的尺寸会经过几个阶段的缩减。例如,一个224x224的图像首先降采样为112x112,然后变为56x56,接着是28x28,最后达到14x14。每一步降采样都旨在捕获图像的高级特征,同时减少计算量。
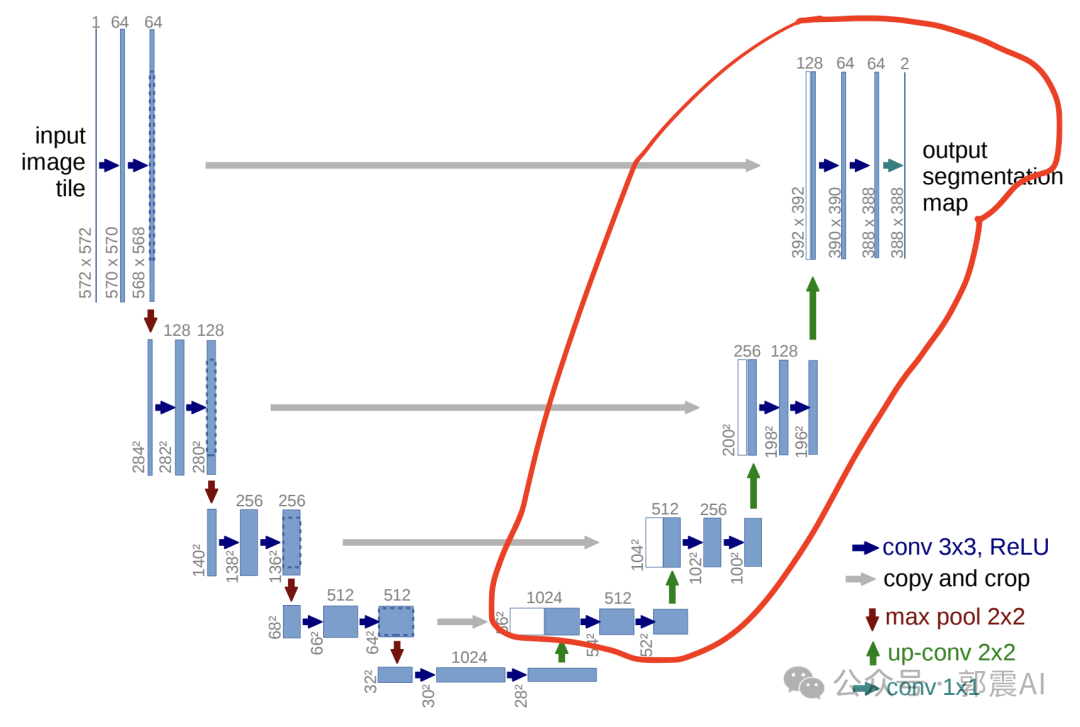
上采样和特征融合:在U-Net的解码器部分,通过上采样(或反卷积)操作逐步恢复图像的尺寸。这一过程不仅仅是简单地增加图像的尺寸,更重要的是恢复图像的细节信息。以14x14的特征图为例,我们首先通过上采样或反卷积得到28x28的特征图。然后,这个新生成的28x28特征图会与编码器阶段对应尺寸(28x28)的特征图进行通道上的拼接(concatenation)。这一步是U-Net架构的关键,称为“跳跃连接”(Skip Connection)。
以下是一个简化的PyTorch代码示例,展示如何将解码器阶段的新生成的28x28特征图与编码器阶段相对应尺寸的28x28特征图进行通道上的拼接。
import torch
import torch.nn as nn
import torch.nn.functional as F
class UNet(nn.Module):
def __init__(self):
super(UNet, self).__init__()
# 编码器部分
self.encoder_conv1 = nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, padding=1)
# 假设有更多的卷积层和池化层...
# 解码器部分
self.decoder_conv1 = nn.Conv2d(in_channels=128, out_channels=64, kernel_size=3, padding=1) # 注意输入通道数是由于拼接而翻倍
# 假设有更多的卷积层...
# 上采样
self.up_sample = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
def forward(self, x):
# 编码器路径
enc1 = F.relu(self.encoder_conv1(x))
# 假设有更多编码器操作...
# 以下代码跳过了中间的操作,直接到上采样和拼接的部分
# 假设enc1是我们需要拼接的编码器阶段的28x28特征图
# 解码器路径 - 上采样
upsampled = self.up_sample(enc1) # 假设从14x14上采样到28x28
# 解码器卷积操作...
dec1 = F.relu(self.decoder_conv1(upsampled))
# 特征图拼接
# 假设dec1是解码器阶段新生成的28x28特征图
# enc1是与之拼接的编码器阶段的28x28特征图
concat_features = torch.cat((enc1, dec1), 1) # 1表示在通道维度上拼接
# 继续解码器操作...
return concat_features
# 假设的输入
input_image = torch.randn(1, 3, 224, 224) # Batch size 1, 3 channels, 224x224 pixels
model = UNet()
output_features = model(input_image)
print(output_features.shape) # 输出拼接后的特征图的尺寸
在PyTorch中,torch.cat函数用于沿指定维度拼接给定的张量序列。在您提到的操作 torch.cat((enc1, dec1), 1) 中,enc1 和 dec1 是两个张量,它们将会在维度1(即通道维度)上进行拼接。这种操作在图像处理任务中特别常见,尤其是在需要合并来自不同网络层的特征信息时。
具体来说,这里的步骤解释如下:
- 参数解释:
(enc1, dec1):这是一个元组,包含了两个要拼接的张量。在U-Net结构中,enc1通常是从编码器路径中得到的特征图,而dec1是解码器路径(可能经过上采样)中得到的特征图。1:这个数字指定了拼接的维度。对于一个形状为(N, C, H, W)的张量(其中N是批量大小,C是通道数,H是高度,W是宽度),维度0对应于批量大小,维度1对应于通道数。因此,1表明拼接发生在通道维度上,这意味着这两个张量的高度和宽度必须相匹配,但它们的通道数可以不同。
- 操作结果:
- 拼接后的张量将具有相同的批量大小
N和相同的空间维度H和W,但其通道数C是两个输入张量通道数的和。如果enc1的形状是(N, C1, H, W),而dec1的形状是(N, C2, H, W),那么拼接后的张量形状将是(N, C1+C2, H, W)。
- 拼接后的张量将具有相同的批量大小
在这个示例中,torch.cat函数用于在通道维度(dim=1)上拼接特征图。这里的enc1和dec1代表要拼接的两个特征图,分别来自于U-Net的编码器和解码器部分。注意,在实际的U-Net实现中,会有多个这样的拼接操作,对应于不同层级的特征图。此外,模型的其他部分,如更多的卷积层、池化层、激活函数等,在这里为了简化被省略了。
跳跃连接的作用:跳跃连接的主要作用是将编码器阶段捕获的高级别、全局特征与解码器阶段的局部、细节特征结合起来。这种结合帮助模型在恢复图像尺寸的同时,也能够精确地恢复图像的细节和结构,这对于图像分割和生成任务至关重要。
通过这种方式,U-Net能够有效地处理和生成高质量的图像,不仅保留了图像的全局信息,也精确地恢复了局部细节,从而在许多图像处理任务中实现了优异的性能。
Stable Diffusion是一种先进的文本到图像生成模型,它能够根据简短的文本提示生成复杂、高质量的图像。其核心在于理解文本的含义,并转化为视觉内容,这一过程中U-Net的架构扮演了至关重要的角色。
U-Net在Stable Diffusion中的应用
- 细节的捕捉与增强:Stable Diffusion利用U-Net的跳跃连接来维持和增强图像的细节。这些连接允许在生成过程中直接使用来自编码器的高分辨率特征,从而在解码器阶段细化图像的细节。
- 多尺度特征融合:通过U-Net的编码器-解码器结构,Stable Diffusion能够融合不同尺度的特征,这对于生成与文本描述相匹配的复杂图像至关重要。这种结构使模型能够在保持全局一致性的同时,精确控制图像的局部细节。
- 迭代细化:Stable Diffusion在图像生成过程中采用迭代细化的策略,每一步都利用U-Net架构对图像进行进一步的优化和细化。这种方式使得最终生成的图像不仅细节丰富,而且与输入的文本描述高度一致。
结语
U-Net在Stable Diffusion中的应用不仅展示了其在图像分割之外的广泛适用性,也体现了在复杂的图像生成任务中对细节和质量的极致追求。通过深入分析U-Net架构如何在Stable Diffusion中发挥作用,我们不仅能够更好地理解这一先进模型的内部机制,还能够激发出更多创新的应用思路,推动人工智能技术在图像生成领域的发展。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-03-13,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 程序员郭震zhenguo 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号