神经网络算法——损失函数(Loss Function)

神经网络算法——损失函数(Loss Function)

JOYCE_Leo16
发布于 2024-03-19 17:21:59
发布于 2024-03-19 17:21:59
前言
本文将从损失函数的本质、损失函数的原理、损失函数的算法三个方面,详细介绍损失函数Loss Function。
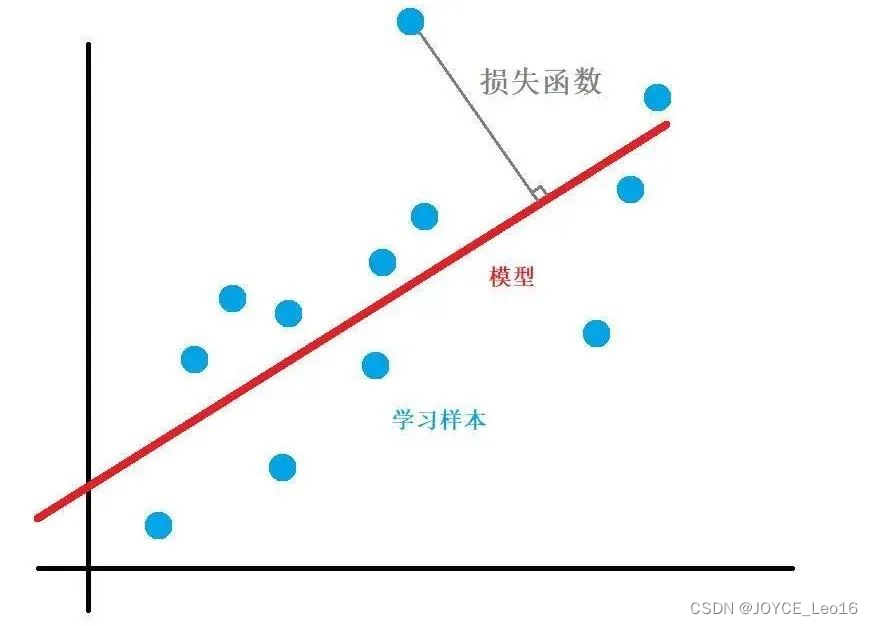
损失函数
1、损失函数的本质
(1)机器学习“三板斧”
选择模型家族,定义损失函数量化预测误差,通过优化算法找到最小损失的最优模型参数。
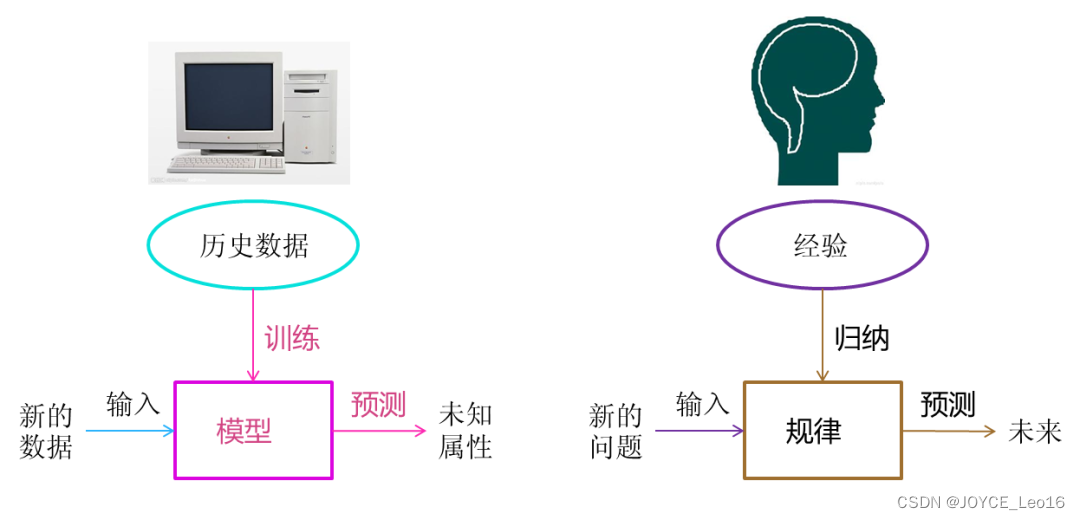
机器学习 VS 人类学习
- 定义一个函数集合(模型选择)
目标:确定一个合适的假设空间或模型家族。
示例:线性回归、逻辑回归、神经网络、决策时等。
考虑因素:问题的复杂性、数据的性质、计算资源等。
- 判断函数的好坏(损失函数)
目标:量化模型预测与真实结果之间的差异。
示例:均方误差(MSE)用于回归;交叉熵损失用于分类。
考虑因素:损失的性质(凸性、可微性等)、易于优化、对异常值的鲁棒性等。
- 选择最好的函数(优化算法)
目标:在函数集中找到最小化损失函数的模型参数。
主要方法:梯度下降及其变种(随机梯度下降、批量梯度下降、Adam等)。
考虑因素:收敛速度、计算效率、参数调整的复杂性等。
(2)损失函数的本质
量化模型预测与真实结果之间的差异。
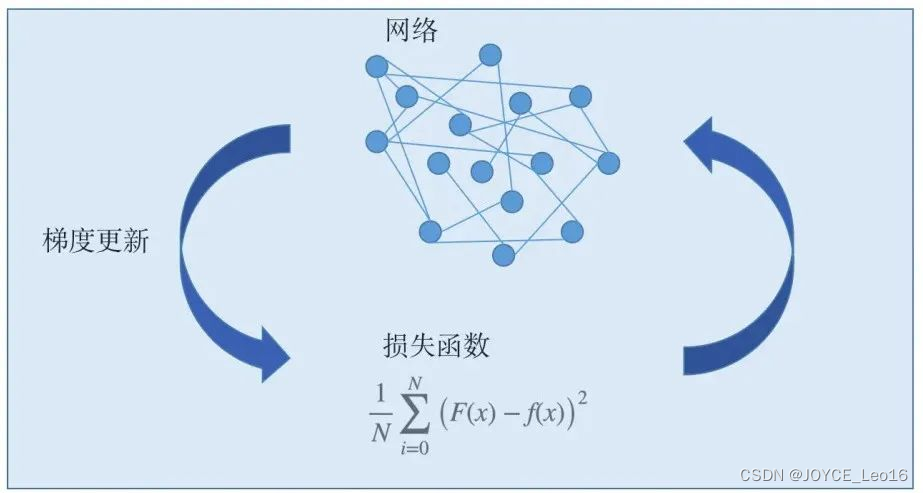
损失函数的本质
- 损失函数的概念:
损失函数用于量化模型预测与真实值之间的差异。
它是预测值与真实值之间差距的计算方法,并通过深度学习框架(如PyTorch、TensorFlow)进行封装。
- 损失函数的重要性:
在机器学习中,目标是使预测值尽可能接近真实值,因此需要通过最小化预测值和真实值之间的差异来实现。
损失函数的选择对于模型的训练速度和效果至关重要,因为不同的损失函数会导致不同的梯度下降速度。
- 损失函数的位置:
损失函数位于机器学习模型的向前传播和向后传播之间。
在向前传播阶段,模型根据输入特征生成预测值。
损失函数接收这些预测值,并计算与真实值之间的差异。
这个差异随后被用于向后传播阶段,以更新模型的参数并减少未来的预测误差。
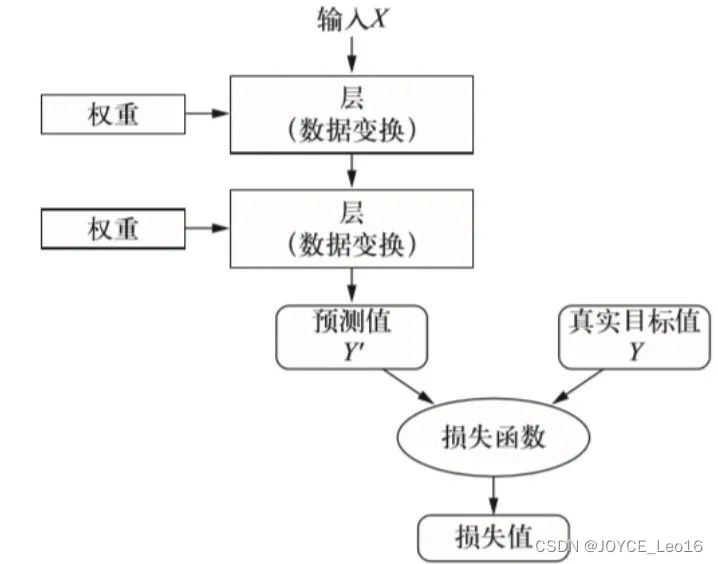
损失函数的位置
2、损失函数的原理
误差反映单个数据点的预测偏差,损失则是整体数据集的预测偏差总和。损失函数运用这两者原理,聚合误差以优化模型,降低总体预测偏差。
(1)误差(Error)
对单个数据点预测结果与真实值之间的差异,用于评估模型在特定数据点上的预测准确性。
- 定义:
误差是指模型在对单个数据点进行预测时,其预测结果与真实值之间的差异或偏离程度。这种差异反映了模型预测的不准确性或偏差。
- 计算:
误差可以通过多种数学公式来计算。其中,绝对误差是预测值与真实值之间差值的绝对值,用于量化预测偏离真实值的实际大小;平方误差则是预测值与真实值之间差值的平方,常用于平方损失函数中,以便更显著地突出较大的误差。
- 误差棒:
误差棒通常以线条或矩形的形式出现在数据点的上方、下方或两侧,其长度或大小代表了误差的量级。这种可视化方法有助于识别潜在的问题区域,并指导进一步的模型改进或数据分析。
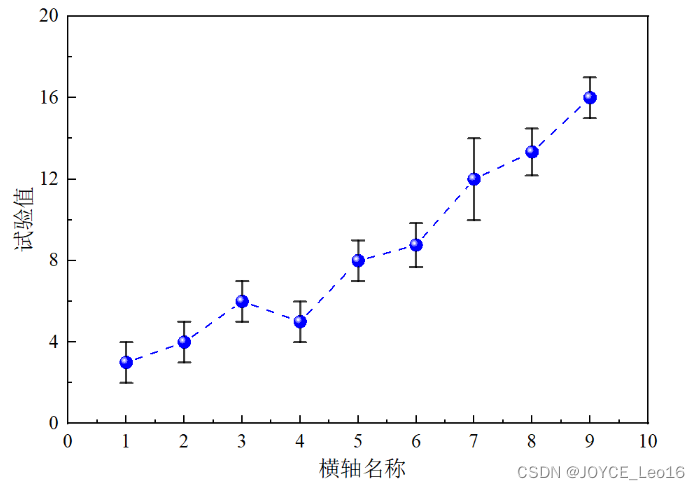
横轴名称
(2)损失(Loss)
损失是衡量机器学习模型在整个数据集上预测不准确性的总体指标,通过最小化损失可以优化模型参数并改进预测性能。
- 定义:
损失是衡量机器学习模型在整个数据集上预测的总体不准确性的指标。它反映了模型预测与真实值之间的差异,并将这些差异进行聚合,以提供一个标量值来表示预测的总体不准确性。
- 计算:
损失的具体计算是通过损失函数来完成的。损失函数接受模型的预测值和真实值作为输入,并输出一个标量值,即损失值,表示模型在整个数据集上的总体预测误差。
- 损失曲线:
损失曲线直观地呈现了模型在训练过程中损失值的变化趋势。通过绘制训练损失和验证损失随迭代次数的变化,我们能够洞察模型是否遭遇过拟合或欠拟合等问题,进而调整模型结构和训练策略。
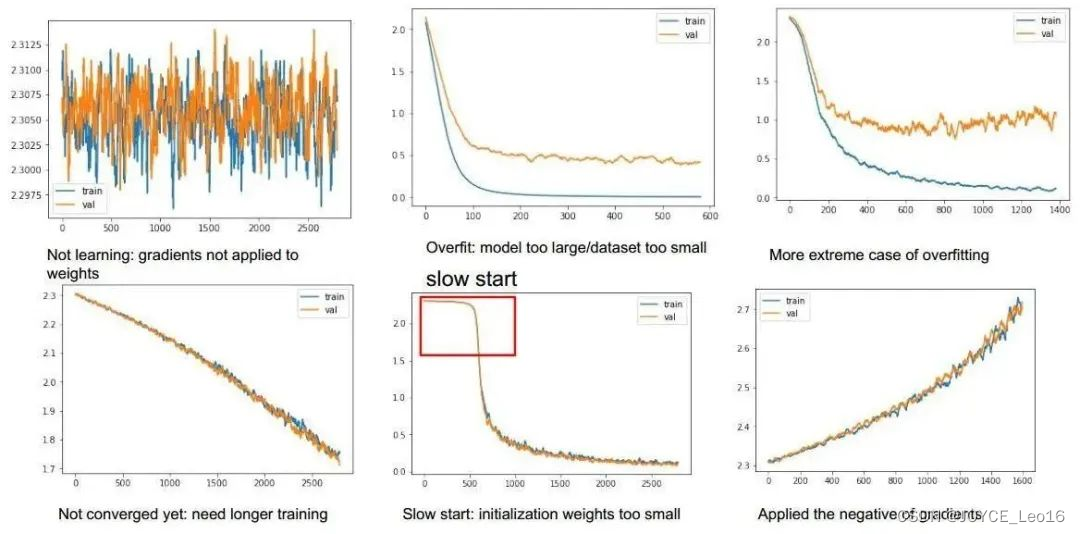
损失曲线
3、损失函数的算法
损失函数的算法
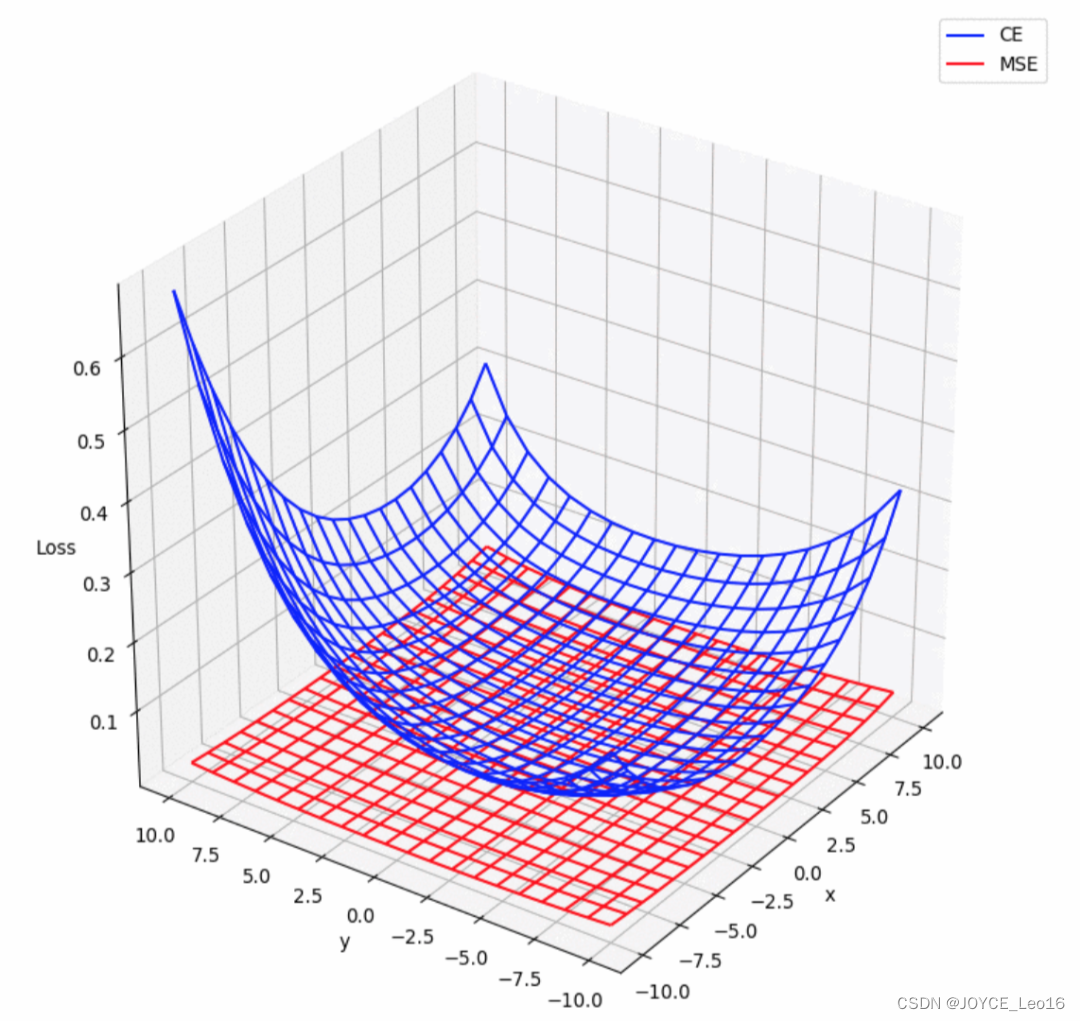
(1)均方差损失函数(MSE)
通过计算模型预测值与真实值之间差值的平方的平均值,衡量回归任务中预测结果的准确性,旨在使预测值尽可能接近真实值。
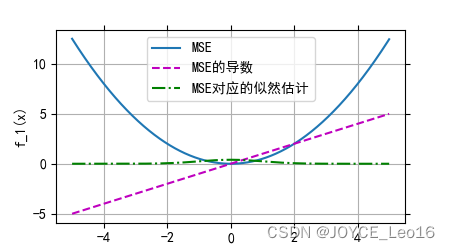
均方差损失函数(MSE)
- 应用场景:
主要用于回归问题,即预测连续值的任务。
- 公式:
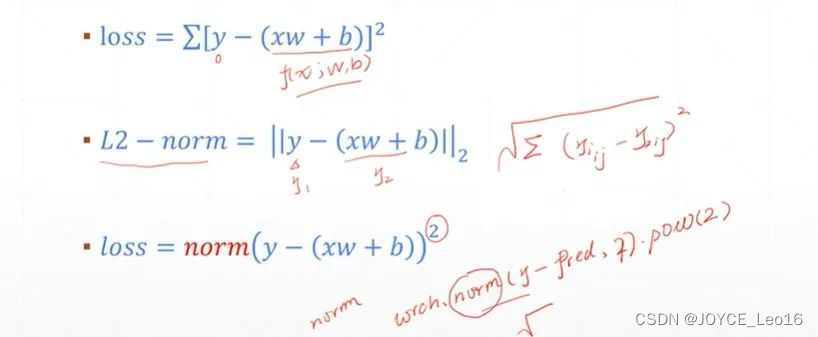
均方差损失函数(MSE)公式
- 特点:
当预测值接近真实值时,损失值较小。
当预测值与真实值差距较大时,损失值迅速增大。
由于其梯度形式简单,易于优化。
- 优化目标:
最小化均方差损失,使得模型的预测值尽可能接近真实值。
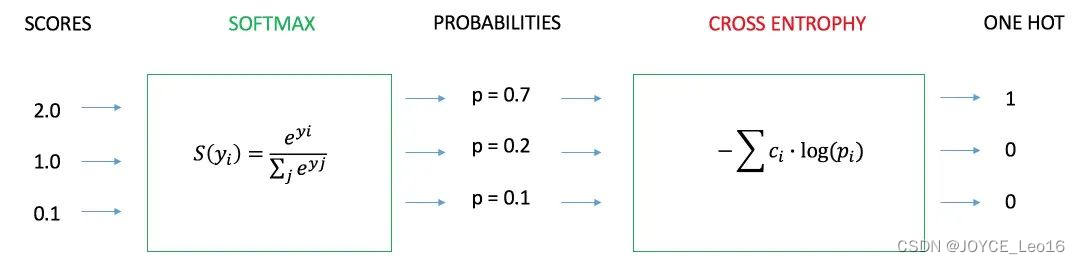
(2)交叉熵损失函数(CE)
用于衡量分类任务中模型预测的概率分布与真实标签之间的差异,旨在通过最小化损失来使模型预测更加接近真实类别。
交叉熵损失函数(CE)
- 应用场景:
主要用于分类问题,尤其是多分类问题。
- 公式:
交叉熵损失函数(CE)公式
- 特点:
当预测概率分布与真实概率分布相近时,损失值较小。
对预测概率的微小变化非常敏感,尤其当真实标签的概率接近0或1时。
适用于概率输出的模型,如逻辑回归、softmax分类器等。
- 优化目标:
最小化交叉熵损失,使得模型对每个类别的预测概率尽可能接近真实概率分布。
参考:架构师带你玩转AI
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-03-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号