深度学习500问——Chapter06: 循环神经网络(RNN)(4)
深度学习500问——Chapter06: 循环神经网络(RNN)(4)

6.14 常见的RNNs扩展和改进模型
6.14.1 Simple RNNs(SRNs)
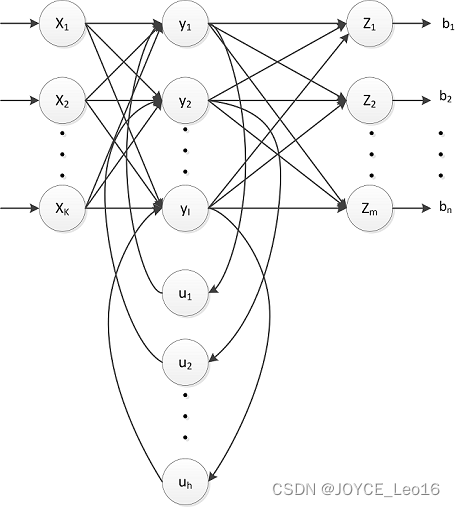
- SRNs是一个三层网络,其在隐藏层增加了上下文单元。下图中的
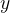
是隐藏层,
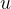
是上下文单元。上下文单元节点与隐藏层中节点的连接是固定的,并且权值也是固定的。上下文节点与隐藏层节点一一对应,并且值是确定的。
- 在每一步中,使用标准的前向反馈进行传播,然后使用学习算法进行学习。上下文每一个节点保存其连接隐藏层节点上一步输出,即保存上文,并作用于当前步对应的隐藏层节点状态,即隐藏层的输入由输出与上一步的自身状态所决定。因此SRNs能够解决标准多层感知机(MLP)无法解决的对序列数据进行预测的问题。SRNs网络结构如下图所示:
6.14.2 Bidirectional RNNs
Bidirectional RNNs(双向网络)将两层RNNs叠加在一起,当前时刻输出(第t步的输出)不仅仅与之前序列有关,还与之后序列有关。例如:为了预测一个语句中的缺失词语,就需要该词汇的上下文信息。Bidirectional RNNs是一个相对较简单的RNNs,是由两个RNNs上下叠加在一起组成的。输出由前向RNNs和后向RNNs共同决定。如下图所示:
6.14.3 Deep RNNs
Deep RNNs与Bidirectional RNNs相似,其也是有多层RNNs叠加,因此每一步的输入有了多层网络。该网络具有更强大的表达与学习能力,但是复杂性也随之提高,同时需要更多的训练数据。Deep RNNs的结构如下图所示:
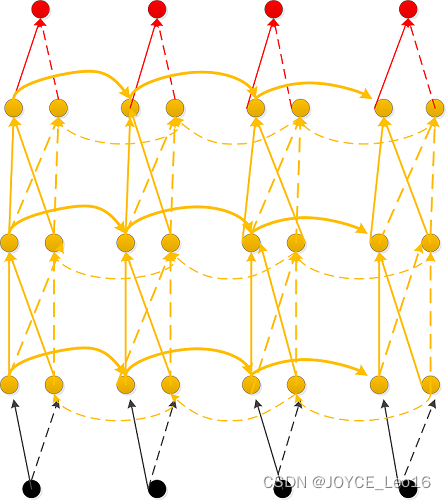
6.14.4 Echo State Networks(ESNs)
ESNs特点:
- 它的核心结构为一个随机生成、且保持不变的储备池(Reservoir)。储备池是大规模随机生成稀疏连接(SD通常保持1%~5%,SD表示储备池中互相连接的神经元占总神经元个数N的比例)的循环结构;
- 从储备池到输出层的权值矩阵是唯一需要调整的部分;
- 简单的线性回归便能够完成网络训练。
ESNs基本思想:
使用大规模随机连接的循环网络取代经典神经网络中的中间层,从而简化网络的训练过程。网络中的参数包括:
(1)W-储备池中节点间连接权值矩阵;
(2)Win-输入层到储备池之间连接权值矩阵,表明储备池中的神经元之间是相互连接;
(3)Wback-输出层到储备池之间的反馈连接权值矩阵,表明储备池会有输出层来的反馈;
(4)Wout-输入层、储备池、输出层到输出层的连接权值矩阵,表明输出层不仅与储备池连接,还与输入层和自己连接;
(5)Woutbias-输出层的偏置项。
ESNs的结构如下图所示:

6.14.5 Gated Recurrent Unit Recurrent Neural Networks
GRUs是一般的RNNs的变型版本,其主要是从以下两个方面进行改进:
- 以语句为例,序列中不同单词处的数据对当前隐藏层状态的影响不同,越前面的影响越小,即每个之前状态对当前的影响进行了距离加权,距离越远,权值越小。
- 在产生误差error时,其可能是由之前某一个或几个单词共同造成,所以应当对对应的单词weight进行更新。GRUs的结构如下图所示。GRUs首先根据当前输入单词向量word vector以及前一个隐藏层状态hidden state计算出update gate和reset gate。再根据reset gate、当前word vector以及前一个hidden state计算新的记忆单元内容(new memory content)。当reset gate为1的时候,new memory content忽略之前所有的memory content,最终的memory是由之前的hidden state与new memory content一起决定。
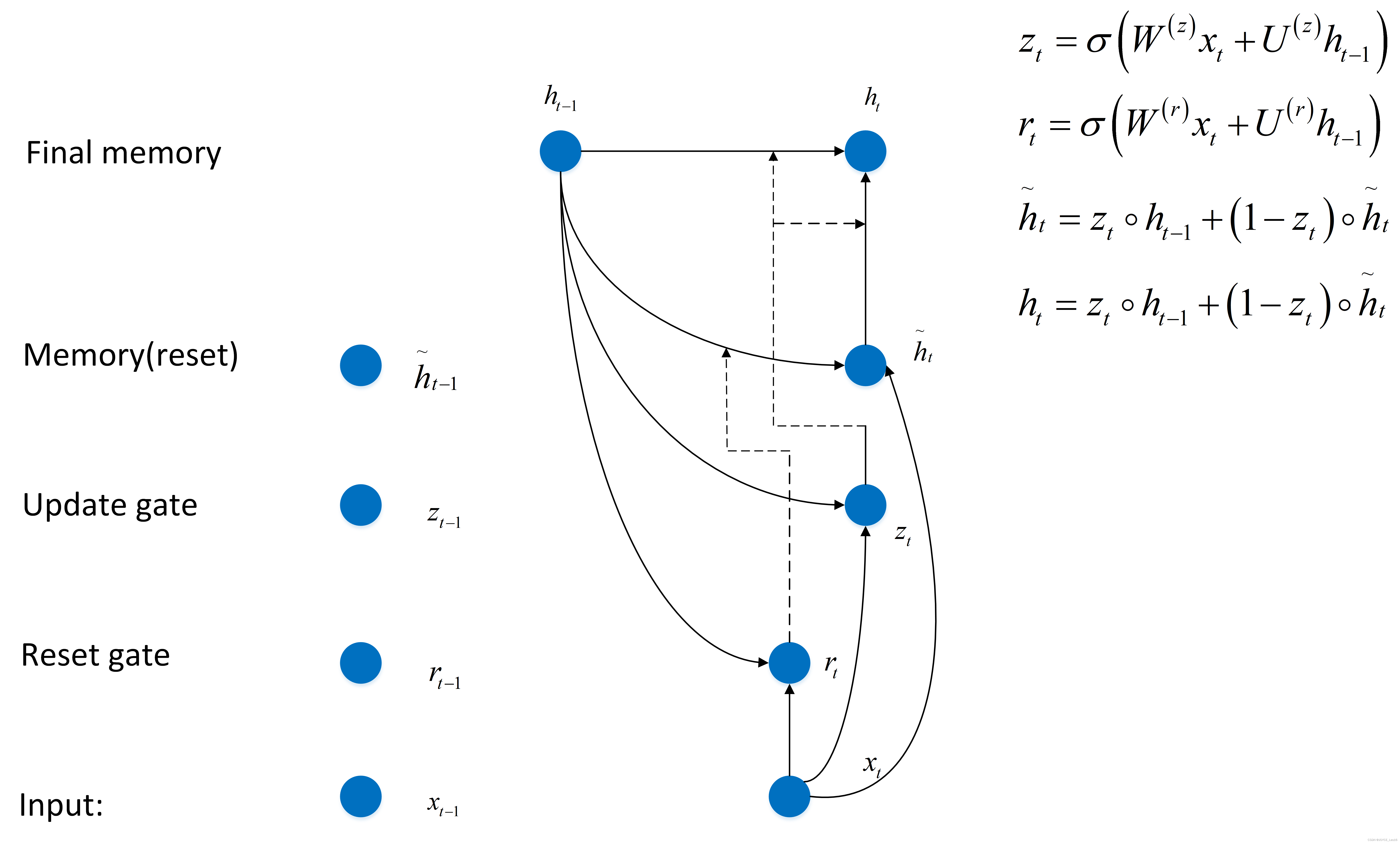
6.14.6 Bidirectional LSTMs
- 与bidirectional RNNs类似,bidirectional LSTMs有两层LSTMs。一层处理过去的训练信息。另一层处理将来的训练信息。
- 在bidirectional LSTMs中,通过前向LSTMs获得前向隐藏状态,后向LSTMs获得后向隐藏状态,当前隐藏状态是前向隐藏状态与后向隐藏状态的组合。
6.14.7 Stacked LSTMs
- 与deep rnns 类似,stacked LSTMs通过将多层LSTMs叠加起来得到一个更加复杂的模型。
- 不同于bidirectional LSTMs,stacked LSTMs只利用之前步骤的训练信息。
6.14.8 Clockwork RNNs(CW-RNNs)
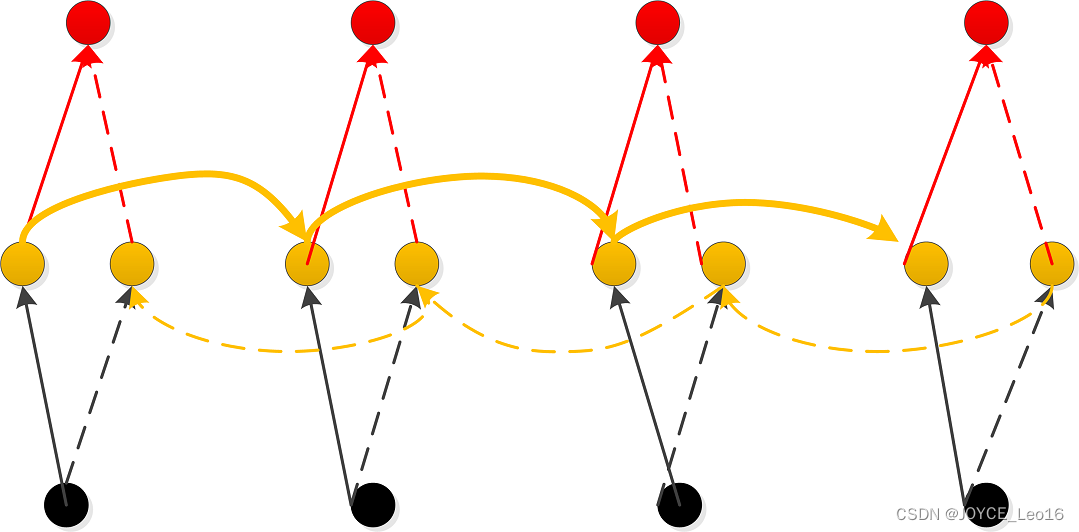
CW-RNNs是RNNs的改良版本,其使用时钟频率来驱动。它将隐藏层分为几个块(组,Group/Module),每一组按照自己规定的时钟频率对输入进行处理。为了降低RNNs的复杂度,CW-RNNs减少了参数数量,并且提高了网络性能,加速网络训练。CW-RNNs通过不同隐藏层模块在不同时钟频率下工作来解决长时依赖问题。将时钟时间进行离散化,不同的隐藏层组将在不同时刻进行工作。因此,所有的隐藏层组在每一步不会全部同时工作,这样便会加快网络的训练。并且,时钟周期小组的神经元不会连接到时钟周期大组的神经元,只允许周期大的神经元连接到周期小的(组与组之间的连接以及信息传递是有向的)。周期大的速度慢,周期小的速度快,因此是速度慢的神经元连速度快的神经元,反之则不成立。
CW-RNNs与SRNs网络结构类似,也包括输入层(Input)、隐藏层(Hidden)、输出层(Output),它们之间存在前向连接,输入层到隐藏层连接,隐藏层到输出层连接。但是与SRN不同的是,隐藏层中的神经元会被划分为若干个组,设为,每一组中的神经元个数相同,设为,并为每一个组分配一个时钟周期,每一组中的所有神经元都是全连接,但是组到组的循环连接则需要满足大于。如下图所示,将这些组按照时钟周期递增从左到右进行排序,即,那么连接便是从右到左。例如:隐藏层共有256个节点,分为四组,周期分别是[1,2,4,8],那么每个隐藏层组256/4=64个节点,第一组隐藏层与隐藏层的连接矩阵为64\times64的矩阵,第二层的矩阵则为矩阵,第三组为矩阵,第四组为矩阵。这就解释了上一段中速度慢的组连接到速度快的组,反之则不成立。
CW-RNNs的网络结构如下图所示:
6.14.9 CNN-LSTMs
为了同时利用CNN以及LSTMs的优点,CNN-LSTMs被提出。在该模型中,CNN用于提取对象特征,LSTMs用于预测。CNN由于卷积特性,其能够快速而且准确地捕捉对象特征。LSTMs的优点在于能够捕捉数据间的长时依赖性。
参考文献
[1] 何之源.完全图解RNN、RNN变体、Seq2Seq、Attention机制 - 知乎.
[2] http://colah.github.io/posts/2015-08-Understanding-LSTMs/
[3] RNN-CSDN博客
[4] Graves A. Supervised Sequence Labelling with Recurrent Neural Networks[J]. Studies in Computational Intelligence, 2008, 385.
[5] Graves A. Generating Sequences With Recurrent Neural Networks[J]. Computer Science, 2013.
[6] Greff K , Srivastava R K , Koutník, Jan, et al. LSTM: A Search Space Odyssey[J]. IEEE Transactions on Neural Networks & Learning Systems, 2015, 28(10):2222-2232.
[7] Lanchantin J, Singh R, Wang B, et al. DEEP MOTIF DASHBOARD: VISUALIZING AND UNDERSTANDING GENOMIC SEQUENCES USING DEEP NEURAL NETWORKS.[J]. Pacific Symposium on Biocomputing Pacific Symposium on Biocomputing, 2016, 22:254.
[8] Pascanu R , Mikolov T , Bengio Y . On the difficulty of training Recurrent Neural Networks[J]. 2012.
[9] Hochreiter S. The Vanishing Gradient Problem During Learning Recurrent Neural Nets and Problem Solutions[J]. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, 1998, 06(02):-.
[10] Dyer C, Kuncoro A, Ballesteros M, et al. Recurrent Neural Network Grammars[C]// Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2016.
[11] Mulder W D , Bethard S , Moens M F . A survey on the application of recurrent neural networks to statistical language modeling.[M]. Academic Press Ltd. 2015.
[12] Graves A. Generating Sequences With Recurrent Neural Networks[J]. Computer Science, 2013.
[13] Zhang B, Xiong D, Su J. Neural Machine Translation with Deep Attention[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, PP(99):1-1.
[15] Deep Learning,Ian Goodfellow Yoshua Bengio and Aaron Courville,Book in preparation for MIT Press,2016;
[16] http://colah.github.io/posts/2015-08-Understanding-LSTMs/
[17] Greff K, Srivastava R K, Koutník J, et al. LSTM: A Search Space Odyssey[J]. IEEE Transactions on Neural Networks & Learning Systems, 2016, 28(10):2222-2232.
[18] Yao K , Cohn T , Vylomova K , et al. Depth-Gated Recurrent Neural Networks[J]. 2015.
[19] Koutník J, Greff K, Gomez F, et al. A Clockwork RNN[J]. Computer Science, 2014:1863-1871.
[20] Gers F A , Schmidhuber J . Recurrent nets that time and count[C]// Neural Networks, 2000. IJCNN 2000, Proceedings of the IEEE-INNS-ENNS International Joint Conference on. IEEE, 2000.
[21] Li S, Wu C, Hai L, et al. FPGA Acceleration of Recurrent Neural Network Based Language Model[C]// IEEE International Symposium on Field-programmable Custom Computing Machines. 2015.
[22] Mikolov T , Kombrink S , Burget L , et al. Extensions of recurrent neural network language model[C]// Acoustics, Speech and Signal Processing (ICASSP), 2011 IEEE International Conference on. IEEE, 2011.
[23] Graves A . Generating Sequences With Recurrent Neural Networks[J]. Computer Science, 2013.
[24] Sutskever I , Vinyals O , Le Q V . Sequence to Sequence Learning with Neural Networks[J]. 2014.
[25] Liu B, Lane I. Joint Online Spoken Language Understanding and Language Modeling with Recurrent Neural Networks[J]. 2016.
[26] Graves A, Mohamed A R, Hinton G. Speech recognition with deep recurrent neural networks[C]// IEEE International Conference on Acoustics. 2013.
[27] Deep Visual-Semantic Alignments for Generating Image Descriptions
[28] Cho K, Van Merriënboer B, Gulcehre C, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation[J]. arXiv preprint arXiv:1406.1078, 2014.