MOMENT:CMU发布首个开源的时间序列基础大模型

时间序列分析是一个重要领域,涵盖从天气预报和到使用心电图检测不规则心跳,再到识别异常软件部署等一系列广泛应用。
然而,对这类数据进行建模通常需要大量的领域专业知识、时间和特定任务的设计。为了应对这些挑战,MOMENT 研究者汇编了一个大型且多样的公共时间序列集合,称为时间序列堆栈(Time-series Pile),并系统地解决了时间序列特有的挑战,以解锁大规模多数据集预训练。
MOMENT是美国卡内基梅隆大学(CMU)的研究者发布的首个开源大型预训练时间序列模型系列。这个系列的模型(1)可以作为多样化时间序列分析任务(如预测、分类、异常检测和插补等)的基础构建块;(2)即插即用,即无需(或只需少量)特定任务的样本(例如,零样本预测、少样本分类等);(3)可以使用分布内和任务特定数据进行调优,以提高性能。

论文标题:MOMENT: A Family of Open Time-series Foundation Models
论文地址:https://arxiv.org/abs/2402.03885
论文源码:https://anonymous.4open.science/r/BETT-773F/README.md
模型方法
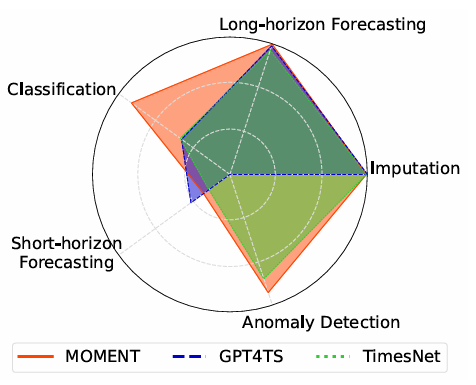
图1 MOMENT完成多个时间序列分析任务的表现对比
研究者首先收集了大量的公共时间序列数据,并将其整合成“时间序列堆栈”(Time-series Pile),然后利用这些数据在遮蔽时间序列预测任务上预训练一个 Transformer 模型。
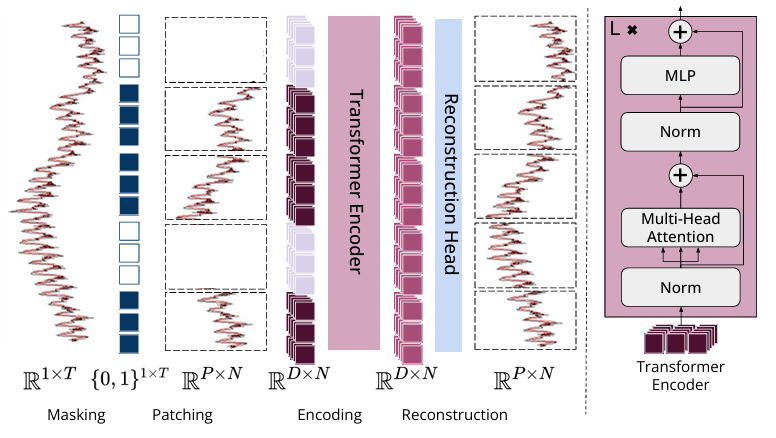
图2 Moment模型概况
时间序列被分割成不重叠的固定长度的子序列,称为 patches,每个 patches 被映射到D维的片段嵌入中。在预训练期间,通过使用特殊的掩码嵌入[MASK]来替换 patches 嵌入,从而均匀随机地对 patches 进行掩码。预训练的目标是学习 patches 嵌入,这些嵌入可以使用轻量级的重建头来重建输入时间序列。
总结来说,MOMENT 紧密遵循了 transformer 设计,研究者能够利用它们扩展高效的实现方式(例如,梯度检查点、混合精度训练)。
而将时间序列分割成片段可以二次减少 MOMENT 的内存占用和计算复杂度,并线性增加其可以接收的输入时间序列的长度。研究者通过沿着批量维度独立操作每个通道来处理多变量时间序列。
此外,研究者使用轻量级的预测头,而不是与编码器相同大小的解码器,以便在保持编码器的大部分参数和高级特征不变的同时,对有限数量的可训练参数进行任务特定的微调,从而进行必要的架构修改。
实验效果
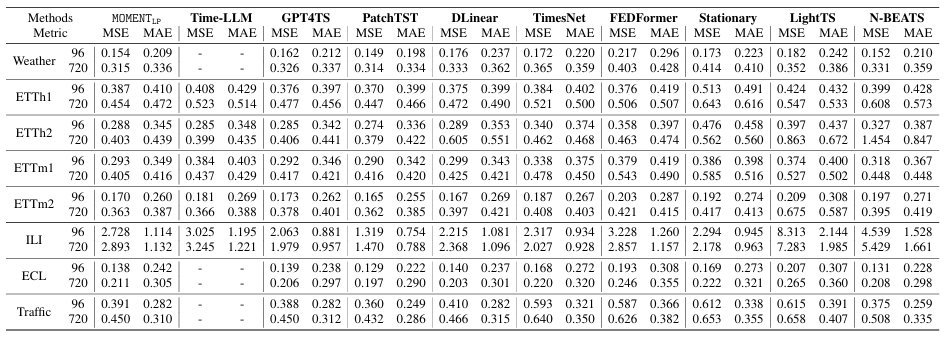
数据集方面,研究者使用了与 TimesNet 相同的数据集进行预测和插补。然而,对于分类和异常检测任务,研究者在 UCR 分类归档和 UCR 异常归档中选择了更大且系统的数据集子集进行实验。
具体来说,研究者在所有91个时间序列数据集上运行分类实验,每个时间序列的长度不超过512个时间步长。对于异常检测,在选择时间序列子集时,优先考虑了 UCR 异常归档中不同领域和数据源的覆盖情况。
从论文中呈现的实验数据效果来看,MOMENT 可以在有限的监督设置下解决多个时间序列建模任务。具体为以下几个方面:
长期预测。线性探测 MOMENT 在大多数数据集和时间范围上实现了接近最先进的性能,仅次于通常实现最低 MSE 的 PatchTST。
零样本短期预测。在所有任务中,零样本短期预测的改进空间最大。统计方法如 Theta 和 ETS 的表现优于它们的深度学习对应方法。然而,在一些数据集上,MOMENT 实现了比 ARIMA 更低的 sMAPE。

分类。无需任何针对数据的微调,MOMENT 可以学习不同数据类别的独特表示,并且在其表示上训练的 SVM 的性能优于除四种专为时间序列分类模型构建的方法外的所有方法,并且这些方法在每个单独的数据集上都进行了训练。
异常检测。在 UCR 异常检测档案中的44个时间序列上,MOMENT 在零样本和线性探测配置下,始终优于 TimesNet 和 GPT4TS,以及两种专为异常检测定制的最先进的深度学习模型。
插补。使用线性探测的 MOMENT 在所有 ETT 数据集上实现了最低的重建误差。在零样本设置中,MOMENT 始终优于所有统计插值方法,除了线性插值。

总结
研究者发布了首个开源的时间序列基础模型系列——MOMENT,并且系统地解决了几个时间序列特有的挑战,这些挑战一直阻碍着对大规模多数据集预训练的广泛探索。研究者使用时间序列堆栈和这些策略来预训练三种不同大小的转换器模型。
在论文中,研究者强调对时间序列数据进行大规模、多数据集的预训练,对隐含的时间序列特征(如趋势和频率)进行编码,并展示了这种方法的好处。
总体来看,MOMENT的卓越性能,特别是在通常数据集较小的异常检测和分类问题上,可以归因于预训练。此外,研究者还证明了在许多任务中,较小的统计方法和较浅的深度学习方法也能取得合理的性能。
腾讯云开发者
