每日论文速递 | 一次编码平行解码:高效Transformer解码
每日论文速递 | 一次编码平行解码:高效Transformer解码

深度学习自然语言处理 分享 整理:pp

摘要:基于Transformer的 NLP 模型功能强大,但计算成本较高,限制了应用场景。经过微调的编码器-解码器模型在专业领域很受欢迎,其性能优于 GPT-4 等大型通用解码器模型。我们为编码器-解码器模型引入了一种新的配置,它能提高结构化输出和问题解答任务的效率,在这些任务中,一个输入需要多个输出。我们的方法,即提示中解码器(PiD),对输入进行一次编码,对输出进行并行解码,通过避免重复输入编码来提高训练和推理效率,从而减少解码器的内存占用。在对话状态跟踪、总结和问题解答任务方面,我们实现了与子任务数量大致成比例的计算量减少,与性能相当或更好的一流模型相比,速度提高了 4.6 倍。
https://arxiv.org/abs/2403.13112
Q1: 这篇论文试图解决什么问题?
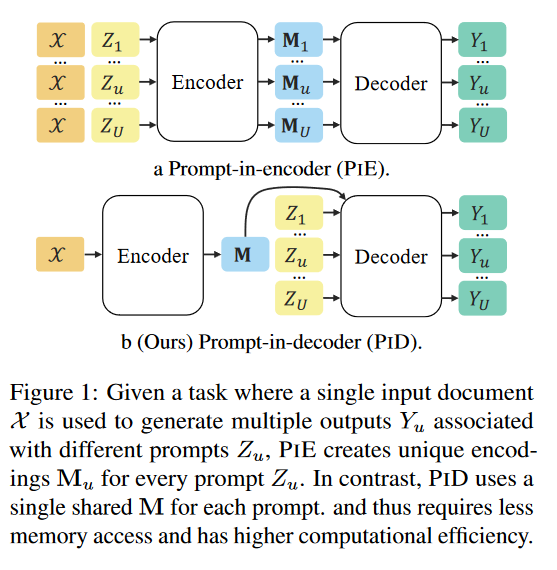
A:这篇论文试图解决的问题是Transformer基础的自然语言处理(NLP)模型在部署时面临的高计算成本问题。具体来说,论文针对的是在使用编码器-解码器(encoder-decoder)模型处理需要单个输入产生多个输出的结构化输出和问答任务时的效率问题。这些任务包括多用户查询同一文档的场景,以及将复杂任务分解为更简单的子任务的场景。为了提高这些任务的训练和推理效率,论文提出了一种新的配置方法,称为“prompt-in-decoder”(PID),它通过一次性编码输入并在并行解码时共享输出来避免重复的输入编码,从而减少了解码器的内存占用。这种方法在多个子任务上实现了计算量的减少,并且在对话状态跟踪、摘要和问答任务上取得了与现有最先进模型相当或更好的性能,同时实现了高达4.6倍的速度提升。总结来说,论文的主要贡献是提出了一种新的、更高效的多查询任务解码策略,并在多个任务上进行了验证。
Q2: 有哪些相关研究?
A:这篇论文提到了多个与Transformer模型效率提升相关的研究领域,具体包括:
- 模型压缩:通过模型压缩技术如知识蒸馏(Hinton et al., 2015; Gou et al., 2021; Udagawa et al., 2023; Yao et al., 2022)和量化(Zadeh et al., 2020; Dettmers et al., 2022; Yao et al., 2022; Dettmers et al., 2023)来减少模型大小和计算资源的需求。
- 模型架构修改:通过修改Transformer模型的架构,如稀疏注意力机制(Roy et al., 2021; Liu et al., 2022)和多查询注意力(Shazeer, 2019; Ainslie et al., 2023)来提高效率。
- 解码优化:通过投机性解码(Leviathan et al., 2023)和GPU内核优化(Dao et al., 2022; Ye et al., 2024a)来减少解码过程中的计算量和延迟。
- 并行解码:通过并行解码的方法来提高解码效率,例如使用预训练的语言模型生成概要轮廓,然后通过并行解码请求填充细节(Ning et al., 2023)。
- 跨注意力开销减少:研究如何减少Transformer模型在推理时的自注意力计算开销,例如通过多查询注意力(MQA)和分组查询注意力(GQA)来减少带宽限制(Shazeer, 2019; Ainslie et al., 2023)。
这些相关研究表明,提高Transformer模型效率的方法多种多样,包括模型压缩、架构优化、解码策略改进等。论文提出的PID方法与这些工作相辅相成,理论上可以与其他效率技术结合使用,以进一步提高效率。

Q3: 论文如何解决这个问题?
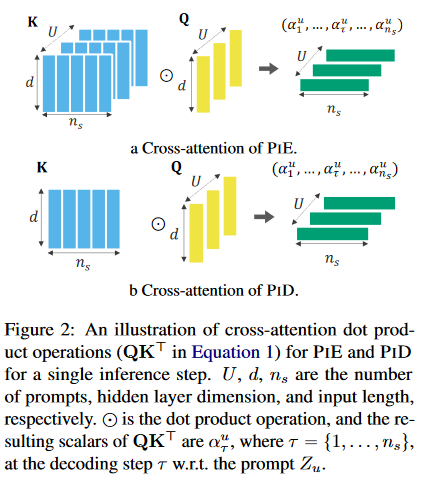
A: 论文提出了一种名为“prompt-in-decoder”(PID)的新方法来解决Transformer模型在处理多输出任务时的效率问题。PID方法的核心思想是将输入一次性编码,然后在解码时并行生成多个输出,避免了在编码器中对每个提示(prompt)重复编码的开销。具体来说,PID方法包括以下几个关键步骤:
- 编码器的一次性编码:编码器仅对输入文本进行一次编码,生成一组嵌入向量(embeddings),这些嵌入向量随后在解码过程中被重复使用。
- 解码器中的并行输出生成:解码器接收编码器生成的嵌入向量,并根据每个特定的提示(prompt)并行生成对应的输出序列。这种方法允许模型在解码过程中共享输入嵌入,减少了内存访问次数。
- 减少内存占用:由于避免了对每个提示重复编码输入,PID方法显著减少了解码器的内存占用,从而提高了计算效率。
- 保持或提高性能:通过实验表明,PID方法在多个任务上(如对话状态跟踪、摘要和问答任务)实现了与现有最先进模型相当或更好的性能,同时实现了显著的计算速度提升。
- 开源代码和模型:为了促进研究和应用,论文作者还公开了训练/推理代码和检查点。
通过这种方法,PID在减少计算成本的同时,还能够处理结构化输出和问答任务中的多个子任务,实现了在保持性能的同时提高效率的目标。
Q4: 论文做了哪些实验?
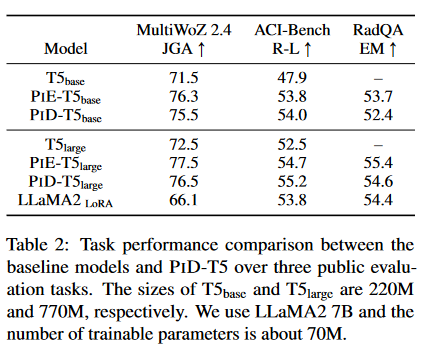
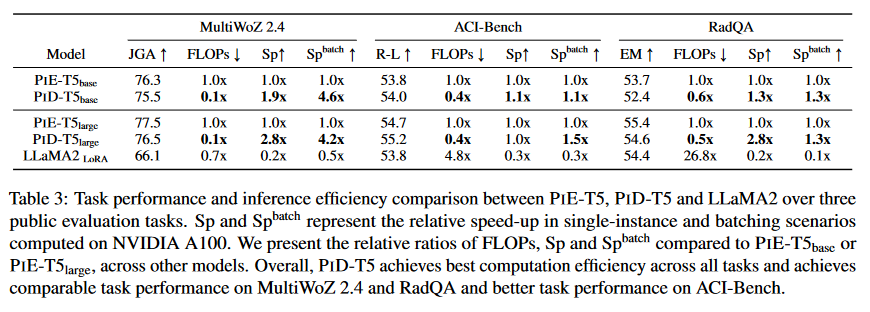
A:论文中进行了一系列实验来验证PID方法的有效性和效率。具体的实验包括:
- 任务性能比较:作者比较了标准的T5模型、带有提示的编码器(PIE-T5)和提出的PID方法(PID-T5)在三个公共评估任务上的性能。这些任务包括:
- 对话状态跟踪(DST):使用MultiWoZ 2.4数据集,以联合目标准确率(JGA)作为评估指标。
- 摘要:使用ACI-Bench数据集,以ROUGE-L分数作为评估指标。
- 问答:使用RadQA数据集,以精确匹配(EM)作为评估指标。
- 计算效率分析:作者分析了PIE和PID在内存访问和算术运算方面的差异,并通过实验比较了它们在单实例和批量推理场景下的浮点运算(FLOPs)和延迟。
- 与最新技术的比较:作者将PID方法与现有的最先进模型进行了比较,包括在上下文学习(in-context learning)和完全微调(full finetuning)方法。
- 低资源设置下的效率:作者还探讨了在低资源设置中,使用PID方法的微调模型与上下文学习方法之间的效率差异。
- 不同子任务粒度的影响:在MultiWoZ 2.4数据集上,作者研究了使用不同子任务粒度(如按领域或领域-槽对分组)对模型性能和推理速度的影响。
- 长输出任务中的子任务效果:在ACI-Bench数据集上,作者分析了PID方法如何处理长输出任务,并比较了标准T5模型、PIE-T5和PID-T5在不同部分的摘要输出性能。
- 不同GPU上的延迟比较:作者比较了在不同级别的GPU上(如NVIDIA A100和RTX 2080Ti)PID方法与其他方法的延迟。
- 不同子任务规模的比较:作者比较了在MultiWoZ 2.4上使用不同数量的子任务(例如,30个领域槽或5个领域)对模型性能和效率的影响。
这些实验不仅证明了PID方法在多个任务上的有效性,还展示了其在计算效率方面的优势,特别是在处理需要多个输出的任务时。
Q5: 有什么可以进一步探索的点?
A:论文中提到了几个可以进一步探索的点:
- 适用任务类型的扩展:PID方法目前适用于具有共享输入文档的任务。探索该方法是否适用于更广泛的任务,例如那些不依赖于共享输入的任务,可能会增加PID的适用性。
- 自动学习子任务策略:目前,子任务策略是由人类设计者根据任务需求(如结构化输出部分)定义的。研究如何让模型自动学习如何进行子任务划分,可能会使PID方法适用于更多任务,并可能提高效率。
- 与其他模型类型的兼容性:虽然PID方法在实验中使用了编码器-解码器模型,但作者认为该策略理论上也适用于解码器-only模型。进行实验分析PID与解码器-only模型的兼容性,可能会进一步扩展PID的应用范围。
- 与其他效率技术的结合:PID方法可以与其他提高效率的技术(如模型压缩、量化和注意力机制优化)结合使用。探索这些技术与PID结合的潜在效果,可能会带来额外的效率提升。
- 更大规模的数据集和模型:在更大规模的数据集上训练和评估PID方法,可能会揭示其在处理更复杂任务时的性能和效率。
- 长期影响和道德考量:研究提高生成模型效率的长期影响,包括对资源使用、模型可访问性和潜在的误用或滥用的影响。
- 实时或低延迟应用:探索PID方法在需要实时或低延迟响应的应用中的性能,例如在线客服、实时翻译或游戏内的交互。
这些探索点可以为未来的研究提供方向,帮助进一步提高NLP模型的效率和实用性。
Q6: 总结一下论文的主要内容?
A:这篇论文的主要内容可以总结如下:
- 问题陈述:论文针对Transformer基础的NLP模型在实际部署中的高计算成本问题,特别是在需要单个输入产生多个输出的任务上,如结构化输出和问答。
- 方法介绍:提出了一种名为“prompt-in-decoder”(PID)的新方法,它通过一次性编码输入并在解码时并行生成多个输出来提高效率,避免了在编码器中对每个提示重复编码的开销。
- 实验验证:通过在对话状态跟踪、摘要和问答等任务上的实验,验证了PID方法在减少计算成本的同时,能够保持或提高任务性能。
- 效率分析:详细分析了PID方法在内存访问和算术运算方面的效率,并通过与其他方法的比较,展示了其在单实例和批量推理场景下的效率优势。
- 应用前景:讨论了PID方法在不同任务类型、自动子任务学习、与其他模型类型的兼容性以及与其他效率技术的结合等方面的潜在应用和进一步探索的方向。
- 道德考量:论文最后提到了对生成模型效率提升研究的道德考量,强调了在实际应用中需要注意的潜在风险。
总体而言,这篇论文为提高Transformer模型在特定任务上的效率提供了一种新的解决方案,并通过实验验证了其有效性。同时,它也为未来的研究提供了多个有价值的探索方向。
以上内容均由KimiChat生成,深入了解论文内容仍需精读论文