深入研究向量数据库


探索向量数据库的幕后到底发生了什么
有一天,我请我最喜欢的大型语言模型(LLM)帮助我向我快 4 岁的孩子解释向量。几秒后,它就催生了一个充满神话生物、魔法和向量的故事。瞧!我为一本新的儿童读物绘制了草图,它给人留下了深刻的印象,因为独角兽被称为"LuminaVec"。
图片由作者提供("LuminaVec"由我快 4 岁的孩子阅读)
该模型是如何帮助创建这种创意魔力的呢?好吧,答案是使用保护(为何在现实生活中)以及最有可能的保护数据库。是这样吗?现在让我解释一下。
向量和嵌入
首先,该模型无法理解我输入的有意义的单词。帮助它理解这些单词的是它们以提供形式表示的数字表示。这些向量帮助模型找到不同单词之间的相似性,同时关注每个单词的有意义的它通过使用嵌入来实现这一点,嵌入是低维向量,试图捕获信息的语义和上下文。
其中,嵌入中的向量是指定对象相对于参考空间的位置的数字列表。这些对象可以是定义数据集中变量的特征。借助这些分数向量值,我们可以确定一个特征与另一个特征的距离有新生儿多近远------它们是相似(接近)还是不相似(远)?
现在这些向量非常强大,但是当我们谈论大语言模型时,我们需要对它们小心,因为"大"这个词。正如这些"大型"模型一样,这些向量可能很快就会变得很长而且更复杂,涵盖数百甚至数千个维度。如果不小心处理,处理速度和安装费用可能会很快变得麻烦!
向量数据库
为了解决这个问题,我们有我们强大的战士:向量数据库。
向量数据库是包含这些向量嵌入的特殊数据库。相似的对象在向量数据库中具有各自更接近的向量,而不是相似的对象具有相距较远的向量。因此,则在每次查询进入时解析数据并生成这些向量嵌入(这会占用大量资源),不如通过模型运行一次数据、将其存储在向量数据库中并根据需要检索它要快速提取。这使得向量数据库成为解决这些大语言模型学位的规模和速度问题最强大的解决方案之一。
所以,回到关于彩虹独角兽、闪闪发光的魔法和强力守护的故事------当我向模型提出这个问题时,它可能会遵循这样的过程------
嵌入模型首先将问题转换为向量嵌入。
然后注意嵌入与数据库中与 5 岁儿童趣味故事和嵌入的相关进行比较。
根据此搜索和比较,返回最相似的处理。结果应包含按照与查询处理的相似度顺序排列的处理列表。
它到底如何运作?
进一步提一下,我们去兜风一下,在局部上解决这些步骤怎么样?是时候回到基础了!感谢 Tom Yeh 教授,我们有了这篇精彩的作品,解释了维护和维护数据库的幕后工作原理。(以下所有图片,除非有说明,均来自 Tom Yeh 教授,来自上述 LinkedIn 帖子,经他许可我进行了编辑。)
现在,我们开始吧:
对于我们的示例,我们有一个由三个组成的数据集,每个句子有 3 个单词(或标记)。
- How are you
- Who are you
- Who am I
我们的疑问是"am I you"这句话。

在生活中,数据库可能包含目前的亿个(想想维基百科、新闻档案、期刊论文或任何文档集合)以及数万个最大数量的标记。现在舞台已经搭建完毕,让流程开始:
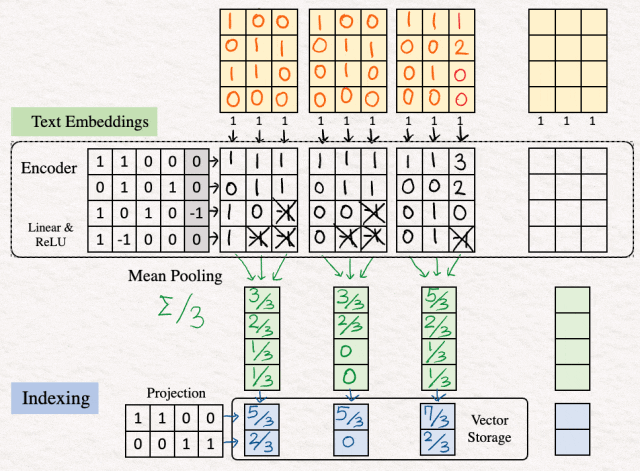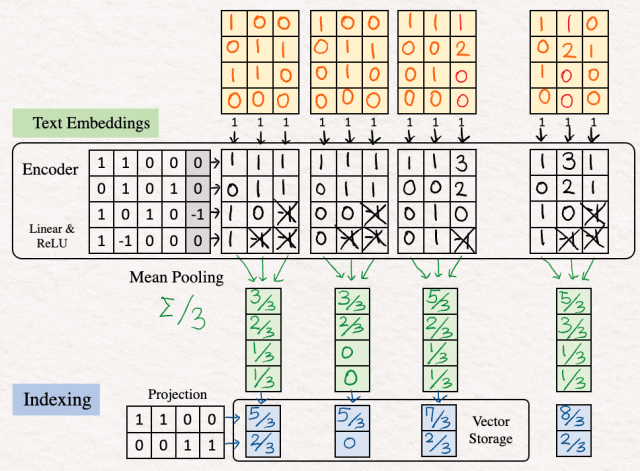
[1]嵌入:第一步是为我们想要使用的所有文本生成提示嵌入。因此,我们在包含 22 个提示的表中搜索相应的单词,其中 22 是我们示例的词汇量。
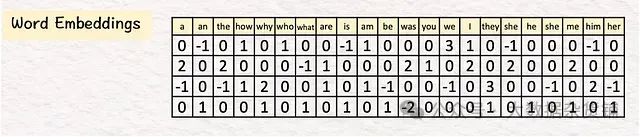
在现实生活中,词汇量可能达到数万。词嵌入维度为数千(例如,1024、4096)。
通过在表中搜索单词" how are you ",它的单词嵌入如下所示:
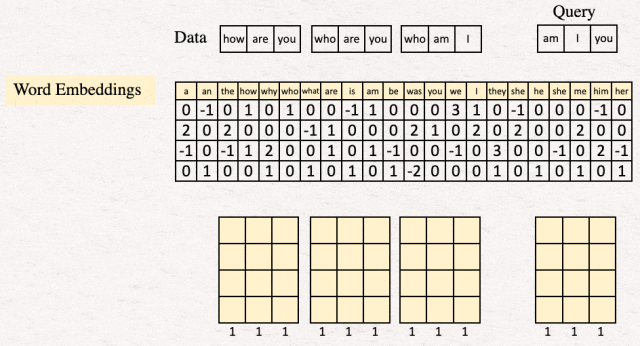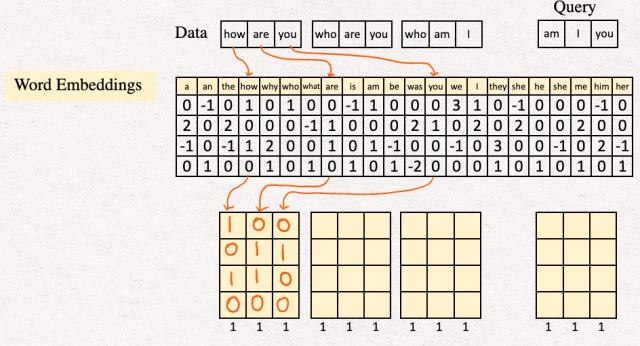
[2]编码:下一步是对词嵌入进行编码序列特征处理,每个词一个。对于我们的示例,编码器是一个简单的采集器,由带有 ReLU 激活函数的线性层组成。
快速回顾一下: 线性变换:输入嵌入向量乘以权重矩阵 W,然后加上偏置向量 b, z = W x+ b,其中 W 是权重矩阵,x 是我们的嵌入词,b* 是偏差补偿。* ReLU 激活函数:接下来,我们将 ReLU 评估这个中间 z。 ReLU 返回输入的逐元素顶和零。数学上,h = max{0,z}。
因此,对于此示例,文本嵌入如下所示:
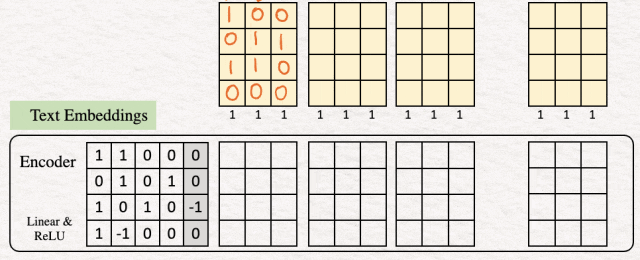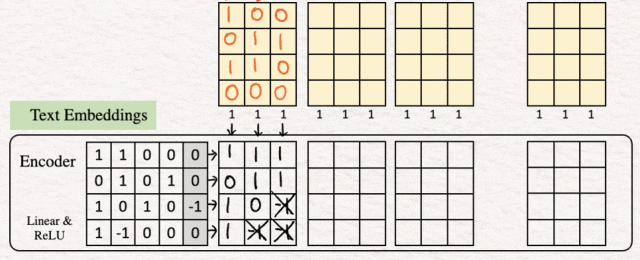
为了展示其工作原理,我们以计算最后一列的值为例。
线性变换:
- [1.0 + 1.1 + 0.0 +0.0] + 0 = 1
- [0.0 + 1.1 + 0.0 + 1.0] + 0 = 1
- [1.0 + (0).1+ 1.0 + 0.0] + (-1) = -1
- [1.0 + (-1).1+ 0.0 + 0.0] + 0 = -1
ReLU
- max {0,1} =1
- max {0,1} = 1
- max {0,-1} = 0
- max {0,-1} = 0
这样我们就得到了特征处理的最后一列。我们可以对其他列重复相同的步骤。
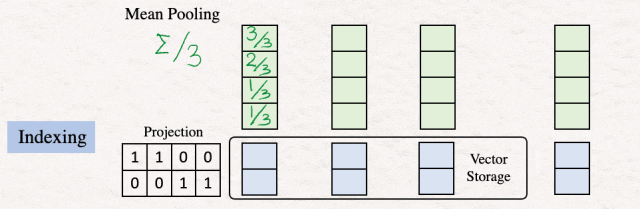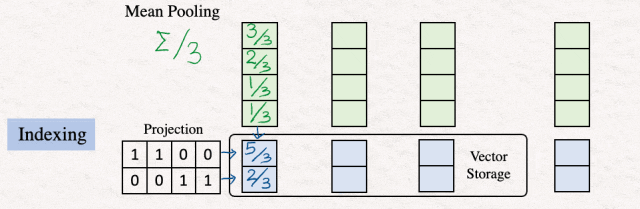
[3]均值池化:在这一步中,我们通过对列进行平均来合并特征来进行聚合标记。这通常称为文本嵌入或句子嵌入。

可以使用其他池化技术,例如 CLS、SEP,但均值池化是使用最广泛的一种。
[4]索引:下一步涉及减少文本嵌入向量的维度,这是在投影矩阵的帮助下完成的。该投影矩阵可以是随机的。这里的想法是获得一个简短的表示,这将允许更快的比较和搜索。
结果保存在存储器中。
[5]重复:对数据集中的其他"你是谁"和"我是谁"重复上述步骤[1]-[4]。
现在我们已经在使用数据库中对数据集进行了索引,我们将继续进行实际查询,看看这些索引如何为我们提供解决方案。
询问:"am I you"
[6]首先,我们重复与上面相同的步骤 - 嵌入、编码和索引查询的 2d 向量表示。
[7]点积(寻找相似性)
完成前面的步骤之后,我们将执行点积。这很重要,因为这些点积向量了查询向量和数据库向量之间的比较的想法。为了执行此步骤,我们转设置查询向量并将其与数据库向量结合起来相乘。
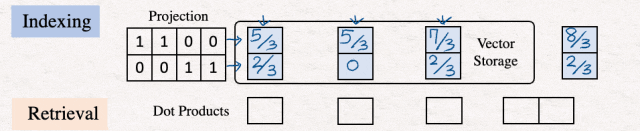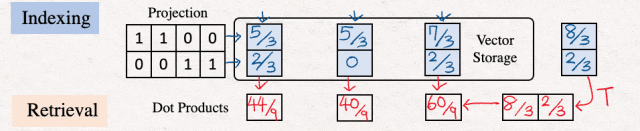
[8]最近邻
最后一步是执行线性扫描,找到最大的点积,在我们的示例中为 60/9。这是"我是谁"的提示表示。在现实生活中,线性扫描可能会非常慢,因为它可能涉及目前,替代方案是使用近似最近邻(ANN)算法,例如分层可导航小世界(HNSW)。

这样我们就结束了这个优雅的方法。
因此,通过使用向量数据库中数据集的向量嵌入,并执行上述步骤,我们能够找到最接近我们的查询的句子。嵌入、编码、均值池、索引和点积构成了该过程的核心。
"大"图
然而,再次引入"大"视角------
- 数据集可能包含数百万或数十亿个句子。
- 每个的代币数量可以达到数万。
- 词嵌入维度可以达到数千。
当我们将所有这些数据和步骤放在一起时,我们正在讨论在像猛犸象一样大小的维度上执行操作。因此,为了应对如此巨大的规模,向量数据库可以发挥作用。自从我们开始这篇文章讨论大语言模型以来,我们可以说,由于向量数据库的规模处理能力,它们在检索增强生成(RAG)中发挥了重要作用。向量数据库提供的可扩展性和速度可以实现 RAG 模型的高效检索,从而为高效的生成模型铺平道路。
总而言之,向量数据库的强大是完全正确的。难怪他们已经在这里有一段时间了------开始他们帮助推荐系统的旅程,现在为大语言模型提供动力,他们的规则仍在继续。随着不同人工智能模式的向量嵌入不断增长,向量数据库似乎将在未来很长一段时间内继续其统治!

原文链接:https://towardsdatascience.com/deep-dive-into-vector-databases-by-hand-e9ab71f54f80
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-04-16,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号