BBP:超越二元偏好的点击率预测模型 | KDD 2024
原创BBP:超越二元偏好的点击率预测模型 | KDD 2024
原创
BBP:超越二元偏好的点击率预测模型 | KDD 2024
| 导语: 腾讯游戏社交算法团队和上海交通大学共同研发了超越二元偏好的点击率预测模型(BBP),落地应用在多个游戏场景中,显著提升了社交推荐系统的性能。相关工作成果已被国际数据挖掘顶级会议KDD 2024录用。

背景
点击率(CTR)预测任务在推荐系统中至关重要,其旨在用户点击某个item的概率值。预测的概率值将被运用到各类推荐系统的下游任务中,在工业场景中点击率预测模型主要有两个场景:
● 排序:根据预测出的点击率生成一个排序的列表,为用户推荐点击概率更高的 item。
● 校准:使得预测出的点击概率和用户的真实点击一致,这有助于更广泛的下游任务的建模,比如估算推荐的预期收益等。
因此,在工业场景中希望点击率预测模型能够输出实际的点击概率(校准能力),并且将用户更喜欢的 item 预测出更高的概率(排序能力)。校准能力的训练可以简单通过 pointwise loss(二分类交叉熵)实现。而对于排序损失,现在有些方法将 Learning-to-Rank (LTR) 的学习方式,即 pairwise 和 listwise 的损失函数引入。pointwise,pairwise和listwise的示意图如下图所示。

问题的挑战点:二元偏好导致大量平局
CTR 预测任务与其他的 LTR 任务在标签分布上有很大不同。LTR 的排序标签可能是一个有序的列表,或者一个有多层分级的文档(比如1-5分)。然而在点击率估计场景下,用户的点击与否被视为一个二元偏好,如果用户点击了某个 item 则说明用户对他感兴趣,反之说明不感兴趣。换句话说,在训练时只能知道一部分标签全为1,一部分标签全为0。这就会导致在排序训练时出现大量的平局情况。
假设用户有 n 个 item 需要排序,那么理论上最多的可比较的 item 对数是 n(n-1)/2 (高中的排列组合题)。然而,由于标签的二元属性,若有 a 个正样本,可以比较的 item 对实际上只有 a 个正样本和 n-a 个负样本的两两组合,即 a(n-a)。当正样本和负样本的个数正好等于 n/2 时,可以取到最多的实际可比较对数,此时约为理论上最大值的一半左右。而当样本的分布越不均匀,可比较的对数占比也越小。在下图中,给出了正样本比例和可比较对数占比的可视化。直觉上理解,对于同样点击的样本,无法获知他更喜欢哪个的;同理对于没点击的样本,也无法获知他更讨厌哪个。
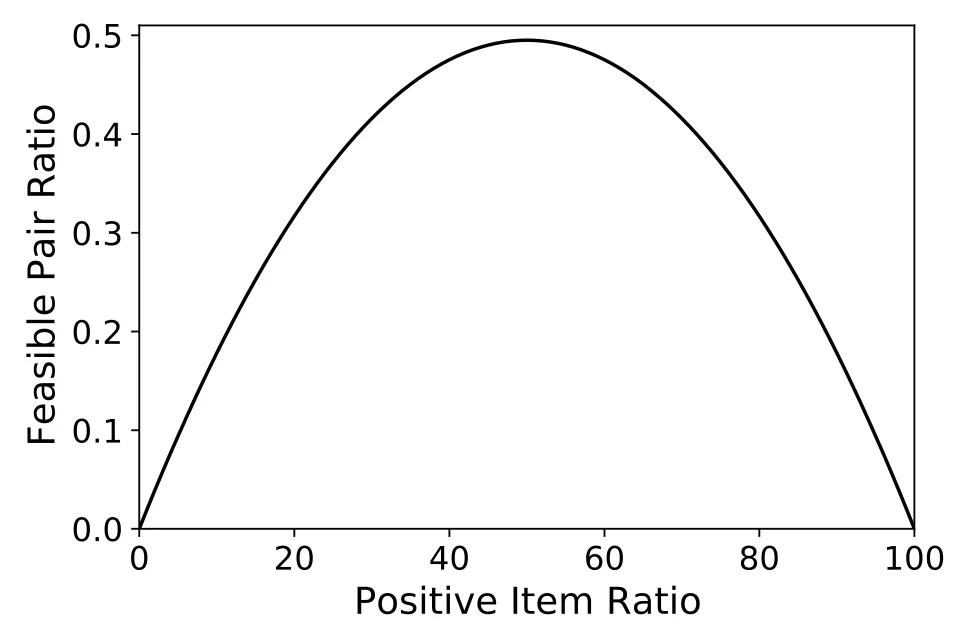
在现实的推荐场景,比如游戏社交网络的好友推荐中,点击的标签占比总是十分稀疏。这导致实际上的训练中,浪费了绝大部分理论上可比较的样本。如果只有10%的样本是正样本,那么将有80%以上的比较情况将被浪费,而现实中这个比例只会比10%更小。
主要贡献与创新点
为了解决这一问题,我们提出了超越二元偏好 (Beyond Binary Preference, 简称 BBP) 训练框架。核心思路是将训练集的标签从二元取值范围增广为连续的取值范围,这样可以保证几乎所有的样本对之间都可以训练,以成倍地扩展可用的训练集规模。这种标签增广方案基于贝叶斯方法,根据对业务数据的洞察,将历史数据视为伯努利实验序列,并通过贝叶斯平滑为每一个训练集的用户和item学习各自的后验概率分数。这样,在优化排序损失时就可以综合考虑点击标签以及后验概率分数。本方案的贡献点列举如下:
● 发现并解决了 CTR预测任务中二元偏好带来的大量平局问题。
● 提出了 BBP 训练框架,其通过贝叶斯方法建模并估计了训练集中用户和 item 的后验概率。BBP以此生成了一系列连续可比较的排序分数标签来打破二元偏好带来的大量平局。
● 在大量的离线实验和在线 A/B Test 中验证了本方案的方法,BBP 在排序和校准能力上均显著(p值<0.05)优于目前的所有 SOTA 方法。在两个腾讯游戏的在线部署上,BBP都相对提升了至少 10.28% 的新增好友数目。
方法介绍
点击行为建模
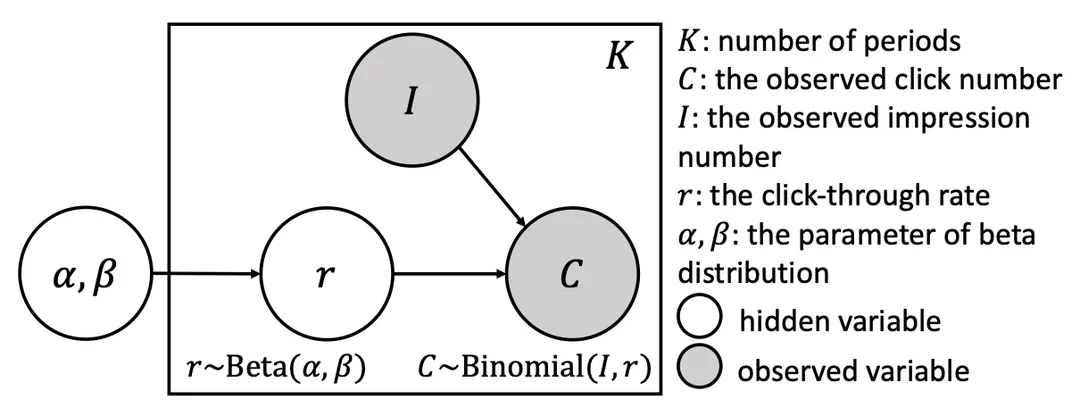
点击行为建模如下图所示:当用户收到某个 item 的曝光时,用户根据自己的兴趣决定是否点击。考虑到点击行为的二元性质,将每个用户的 item 曝光视为具有潜在概率 r 的伯努利实验,即 C~Binomial(I,r)。
此外,假设用户点击某个 item 的概率 r 服从 beta 分布,即 r~Beta(α,β)
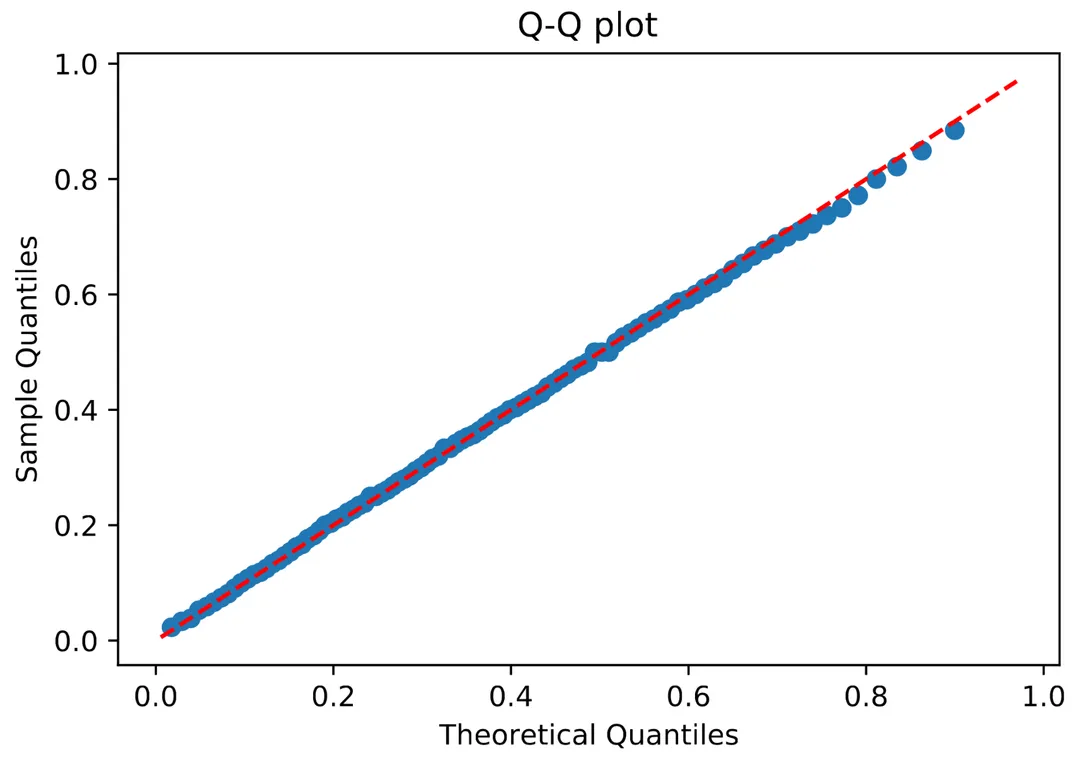
点击率服从 beta 分布的假设源自对真实用户点击行为的洞察。为了验证这一假设,根据用户的点击频率和以此估计出的beta分布绘制了一个 Q-Q 图(分位数-分位数图)。如果 Q-Q 图的理论分位数(x轴)和采样出的实际分位数(y轴)一致,那么说明点击行为的概率分布符合假设。可以从下图看出,点击率的分布在红色虚线上,这说明假设是与现实的用户行为是符合的。
估计个性化后验概率
基于上述的行为建模,旨在通过贝叶斯方法估计每个用户行为的分布,以用于后续的排序。本方案的idea是将历史数据根据时间顺序整理为行为序列,并逐渐更新用户自己的个性化 beta 分布。并从这个 beta 分布推出个性化后验概率。
值得一提的是,这个行为建模可以同时套在用户和 item 上。对于用户,就是他点击的后验概率;对于 item,就是它被点击的后验概率。
接下来逐步介绍本方案的处理流程:
数据整理
首先,将训练集按照时间顺序划分为 K 份。这个时间步长可以是一天、一周等,极端情况下也可以是一个时间戳。
接下来,以一个 item v 为例,根据划分好的数据集可以获得长度为 K 的曝光序列 I^v=\left(I_1^v, I_2^v, \cdots, I_K^v\right) 和点击序列 C^v=\left(C_1^v, C_2^v, \cdots, C_K^v\right),序列的每个取值分别为该时间段内的item v 的曝光次数和被点击次数。
初始化beta分布
为了更好的估计所有用户和item的分布,特别是针对历史数据不足的情况,首先通过全体的历史数据对beta分布进行初始化。初始化的分布 Beta(α0,β0) 计算方式如下:
\alpha_0=\frac{1}{|\mathcal{V}|} \sum_{v \in \mathcal{V}} \sum_{u \in \mathcal{U}_v} y^{u, v}, \beta_0=\frac{1}{|\mathcal{V}|} \sum_{v \in \mathcal{V}} \sum_{u \in \mathcal{U}_v}\left(1-y^{u, v}\right)
其中 |V| 是 item 的个数,y是二元的点击标签。
更新个性化分布
已知beta分布 Beta(αv, βv),可以根据曝光和点击序列计算似然:
P\left(C^v \mid I^v ; \alpha^v, \beta^v\right)=\prod_{k=1}^K \frac{\Gamma\left(\alpha^v+\beta^v\right)}{\Gamma\left(I_k^v+\alpha^v+\beta^v\right)} \frac{\Gamma\left(\alpha^v+C_k^v\right)}{\Gamma\left(\alpha^v\right)} \frac{\Gamma\left(I_k^v-C_k^v+\beta^v\right)}{\Gamma\left(\beta^v\right)},
其中 是 gamma 函数。为了最大化似然,计算对数似然对参数 α 和 β 的偏微分:
\begin{aligned} \frac{d \log P\left(C^v \mid I^v ; \alpha^v, \beta^v\right)}{d \alpha^v}= & \sum_{k=1}^K\left[\psi\left(\alpha^v+\beta^v\right)-\psi\left(I_k^v+\alpha^v+\beta^v\right)\right. \\ & \left.+\psi\left(\alpha^v+C_k^v\right)-\psi\left(\alpha^v\right)\right], \\ \frac{d \log P\left(C^v \mid I^v ; \alpha^v, \beta^v\right)}{d \beta^v}= & \sum_{k=1}^K\left[\psi\left(\alpha^v+\beta^v\right)-\psi\left(I_k^v+\alpha^v+\beta^v\right)\right. \\ & \left.+\psi\left(I_k^v-C_k^v+\beta^v\right)-\psi\left(\beta^v\right)\right], \end{aligned}
其中 \Gamma(\cdot) 是 Psi 函数,可以通过 Bernardo 算法快速计算。
接下来,可以通过不动点迭代法计算最终的解:
\begin{aligned} & \alpha_n^v=\alpha_{n-1}^v \frac{\sum_{k=1}^K\left[\psi\left(\alpha_{n-1}^v+C_k^v\right)-\psi\left(\alpha_{n-1}^v\right)\right]}{\sum_{k=1}^K\left[-\psi\left(\alpha_{n-1}^v+\beta_{n-1}^v\right)+\psi\left(I_k^v+\alpha_{n-1}^v+\beta_{n-1}^v\right)\right]}, \\ & \beta_n^v=\beta_{n-1}^v \frac{\sum_{k=1}^K\left[\psi\left(I_k^v-C_k^v+\beta_{n-1}^v\right)-\psi\left(\beta_{n-1}^v\right)\right]}{\sum_{k=1}^K\left[-\psi\left(\alpha_{n-1}^v+\beta_{n-1}^v\right)+\psi\left(I_k^v+\alpha_{n-1}^v+\beta_{n-1}^v\right)\right]}, \end{aligned}
其中 n 是不动点迭代的轮数下标,设置了最大的迭代轮数 N。以保证预计算的计算复杂度与数据规模始终是线性关系。
获取后验概率
通过上述步骤,已经获得了更新后的个性化 Beta 分布参数。根据时序数据的最后一次曝光I和点击次数C,可以获得item v 被点击的后验概率:
P_{\text {clicked }}^v=\frac{\alpha^v+C_k^v}{I_k^v+\alpha^v+\beta^v}
超越二元偏好排序
如之前所说,同样的流程既可以计算 item v 被点击的概率 P_{\text {clicked }}^v,也可以计算用户 u 点击的概率 P_{\text {clicked }}^u。使用了一个聚合函数 agg() 综合考虑这两个概率,作为增广的排序分数:
P_{\text {agg }}=\operatorname{agg}\left(P_{\text {click }}^u, P_{\text {clicked }}^v\right),
其中聚合函数可以是最大值或平均数等等。在实验中,发现最大值和平均数聚合的结果没有显著差异。
本方案的增广排序分数构建也十分简单,就是聚合后的概率与二元的点击标签相加:
z=P_{\text {agg }}+y
使用最大或者平均数聚合还有一个好处,其聚合后的取值范围是 (0,1),这保证实际上未点击的分数标签取值范围为 (0,1),而点击的分数标签为 (1,2)。这样增广后的分数依然能保证点击样本排序在未点击样本之前,而发生变化的偏序关系只存在于本来平局的样本之间,从不可比到可比。
接下来,对于两个用户样本对 (u, v), (u', v'),构建这样的偏序关系标签:
\Delta z^{(u, v)>\left(u^{\prime}, v^{\prime}\right)}=z^{(u, v)}-z^{\left(u^{\prime}, v^{\prime}\right)}, \mathbb{I}\left(\Delta z^{(u, v)>\left(u^{\prime}, v^{\prime}\right)}\right)= \begin{cases}1, & \text { if } \Delta z^{(u, v)>\left(u^{\prime}, v^{\prime}\right)}>0 \\ 0, & \text { otherwise }\end{cases}
值得一提的是,SOTA的pairwise和listwise通常比较的是同一个用户交互的不同item,因此在训练时需要根据用户id构建训练集的pair或list,需要而额外的开销。而因为已经将用户和item的先验知识通过贝叶斯方法引入到排序标签之中,可以在任意用户和任意item之间进行比较。这进一步拓宽了可用的样本数量。
除了可比较的样本数更多之外,由于无需在用户id上进行对齐,其可以通过最简单的 pairwise 数据集进行并行计算,本方案的排序损失计算方法如下:
\mathcal{L}_{\text {rank }}=-\frac{1}{M} \sum^M \log \left(\sigma\left(\Delta s^{(u, v)>\left(u^{\prime}, v^{\prime}\right)} \cdot \mathbb{I}\left(\Delta z^{(u, v)>\left(u^{\prime}, v^{\prime}\right)}\right)\right)\right),
其中 $M=(^B_2)$ 是可比较的对数,B是当前的 batch size。在训练时,可以将一个 batch 的任意用户-item pair进行两两组合。σ是Sigmoid函数,s是模型的输出。
除此之外,为了兼顾CTR预测模型的排序能力,对每个 batch 使用二元交叉熵进行优化:
\mathcal{L}_{\mathrm{cal}}=-\frac{1}{B} \sum_{(u, v, y)} y^{u, v} \log \sigma(s)^{u, v}+\left(1-y^{u, v}\right) \log \left(1-\sigma(s)^{u, v}\right)
最终的训练损失是排序和校准损失之和。
实验结果
公开数据集
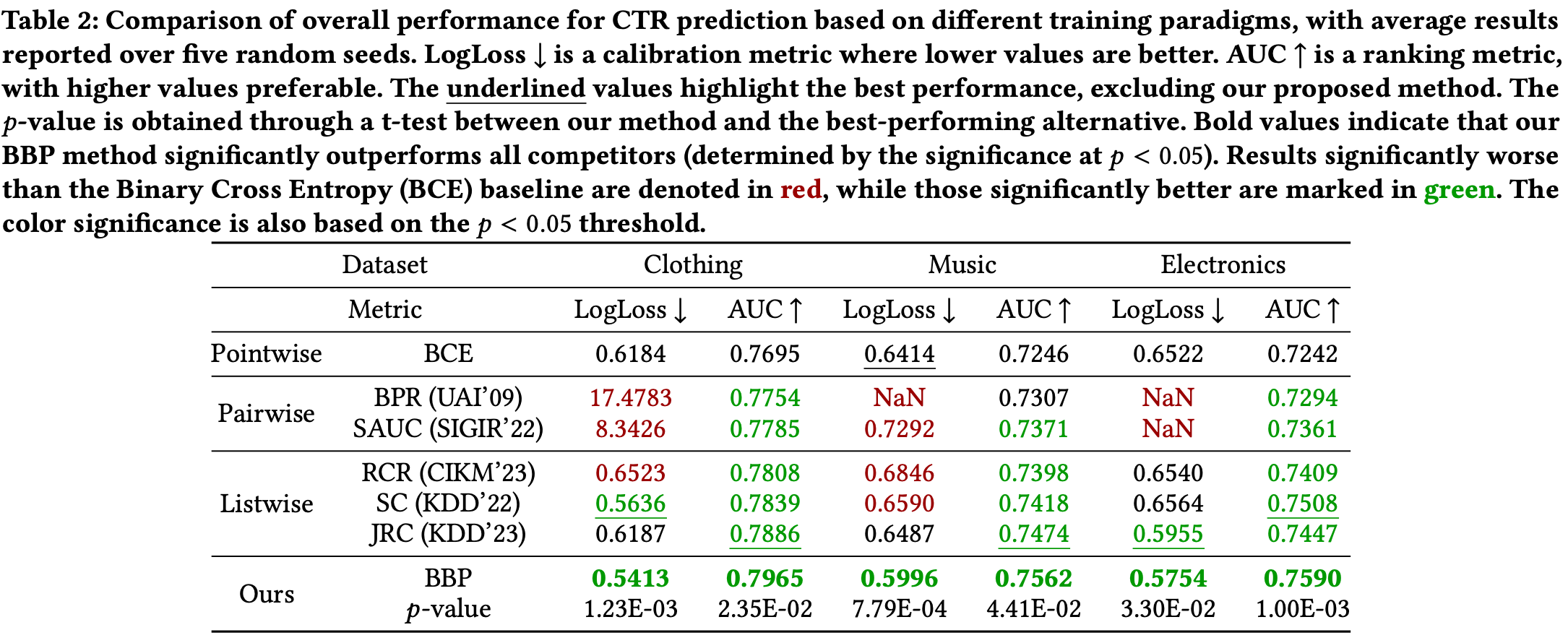
在 Amazon 数据集的三个自己上将本方案与众多CTR预测的训练方式进行比较,在公开数据集上以 LogLoss 作为校准能力的指标,以 AUC 作为排序能力的指标。实验结果说明本方案的效果的所有指标均显著优于目前的所有方法。
业务数据
在腾讯的一个手机端战术竞技类游戏 X 和一个手机端休闲派对游戏 Y 上进行实验。由于研究的任务是游戏社交的好友推荐任务,因此每个玩家既是进行点击的用户,也是可能被点击的item。
首先在时长一周的历史数据上进行离线测试。值得一提的是,为了避免预处理中可能存在的标签泄露问题,本方案使用 User id 来严格划分训练集、验证集和测试集。只对训练集中的数据进行贝叶斯平滑以避免标签泄露。在离线实验中使用 NDCG 和 HIT rate 作为评价指标,将本方案与最好的两个SOTA SC 和 JRC 进行比较,对比结果如下表所示:
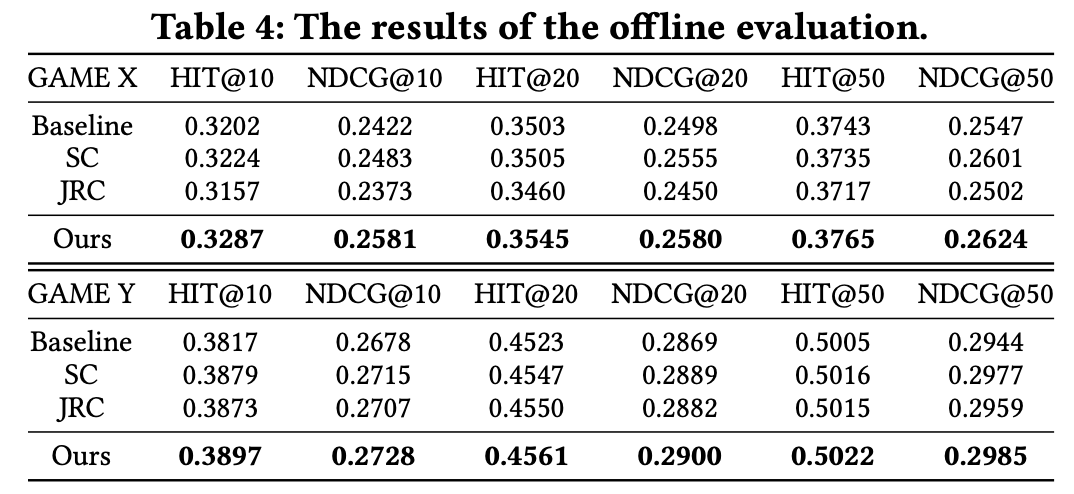
离线结果表明,本方案依然能在所有指标上超越所有SOTA方法,这进一步说明BBP在现实的推荐场景中能够更有效地获得玩家的排序列表。
除了离线实验之外,也进行了时长一周的 A/B Test 在线实验,在游戏 X 和 Y 的陌生人好友推荐模块中部署了 BBP以及两个 SOTA。在这个陌生人好友推荐模块中,若玩家访问该模块,会接受一个陌生人排序列表作为曝光,列表中的玩家与该玩家都暂无好友关系。玩家可以选择感兴趣的陌生人发送邀请,而受到邀请的接收方玩家也可以选择是否同意好友邀请。若接收方玩家同意,则两位玩家顺利组成新的游戏内好友关系。
根据推荐模块的功能,计算了如下三个指标:
● 点击率(Click Rate):接受曝光的玩家点击至少一个陌生人的比例。
● 同意率(Approval Rate):邀请接收方同意好友邀请的比例。
● 好友率(Friend Rate):接受曝光的玩家获得至少一个新增好友的比例。
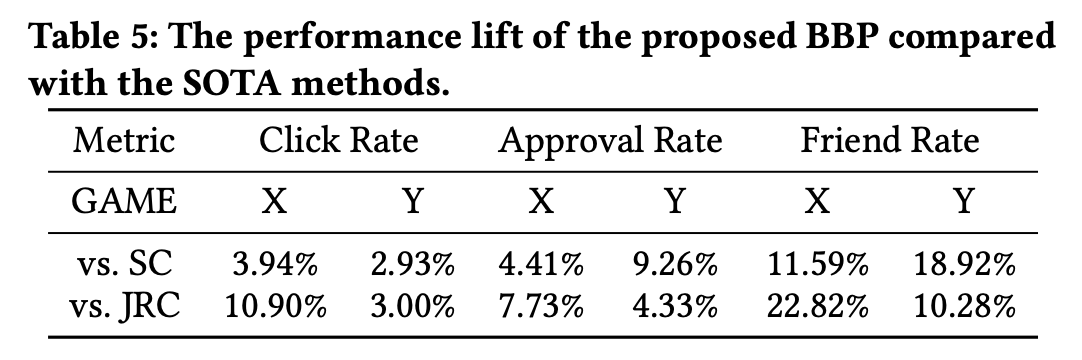
可以看到,在时长为一周的 A/B 测试中,BBP相对于两个 SOTA 在三个指标上均有提升。且至少带来了10.28%的相对新增好友收益。
团队介绍
腾讯游戏社交算法团队 (https://socialalgo.github.io/)致力于研发高效且有效的社交网络智能算法和分析技术,挖掘海量丰富的图数据,构建高性能的图模型,服务于大量游戏的多样社交场景,旨在提升用户留存和游戏收益。团队负责的场景包括好友推荐、社群推荐、社交传播、社交营销、社交分析等围绕大规模社交网络的应用。团队研发的技术已落地应用于30+款腾讯游戏,包括和平精英、王者荣耀、英雄联盟手游、QQ飞车手游、元梦之星、金铲铲之战等游戏。目前,团队已获得多项腾讯公司级荣誉奖项,包括卓越运营奖、业务突破奖、腾讯专利奖、腾讯代码奖、犀牛鸟精英人才计划优秀学生和导师等,并且在国际前沿学术会议和期刊上已发表了20+篇论文。
参考资料
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
