机器学习扩展包MLXtend绘制多种图形
原创机器学习扩展包MLXtend绘制多种图形
原创
公众号:尤而小屋 编辑:Peter 作者:Peter
大家好,我是Peter~
mlxtend(machine learning extensions,机器学习扩展)是一个用于日常数据分析、机器学习建模的有用Python库。mlxtend可以用作模型的可解释性,包括统计评估、数据模式、图像提取等。
今天给大家介绍一个强大的机器学习建模扩展包:mlxtend的多种绘图,主要内容见思维导图:
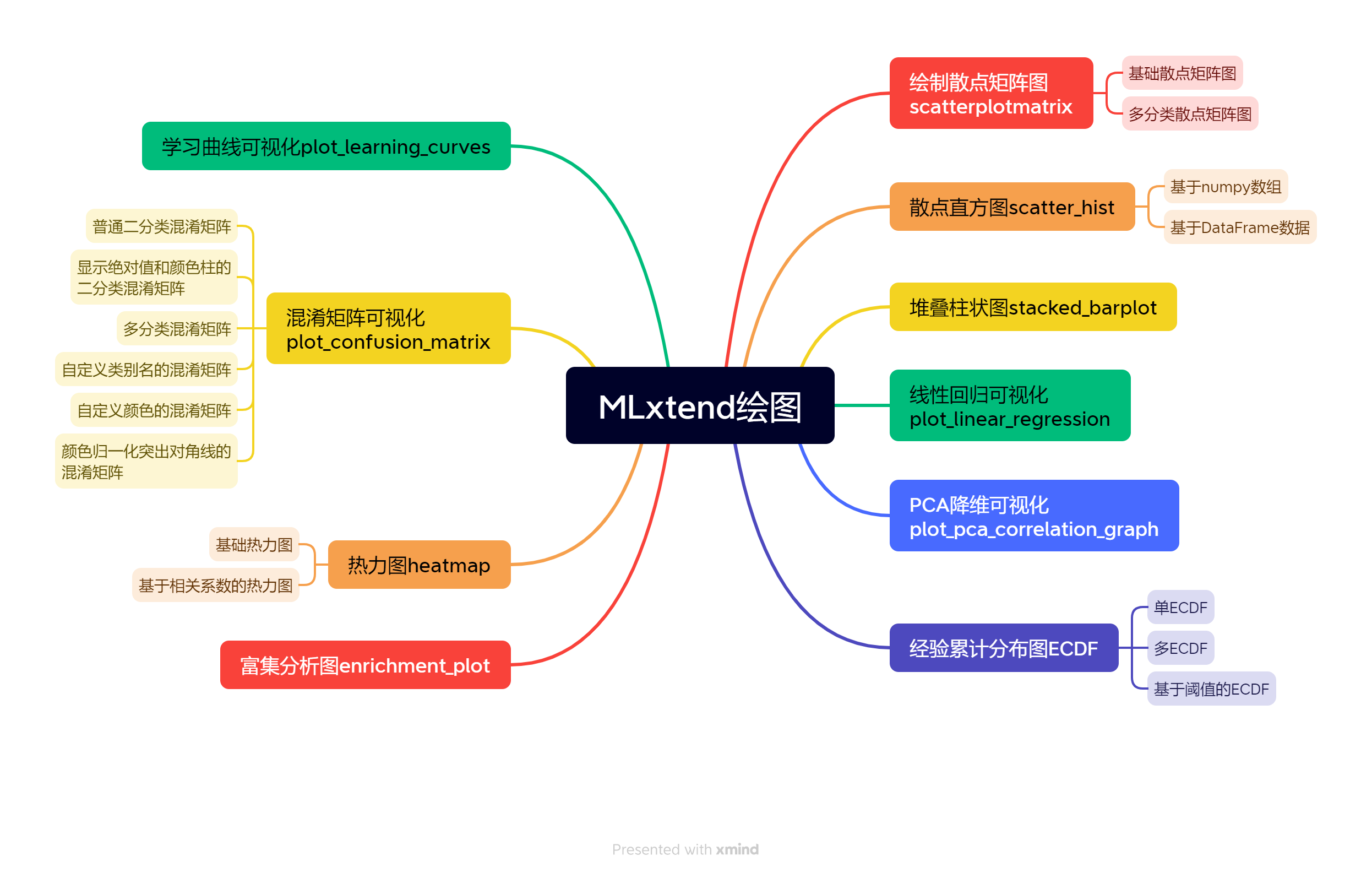
1 MLxtend特点
mlxtend是一个Python第三方库,用于支持机器学习和数据分析任务。其主要功能:
- 数据处理
- 数据:提供了数据集加载和预处理的功能,方便用户处理各种格式的数据集。
- 预处理:包括数据清洗、标准化、归一化等,确保数据质量,提高模型性能等
- 特征选择
- 基于特征重要性的方法:这种方法通过评估各个特征对模型预测能力的贡献度来选择特征。
- 递归特征消除:这是一种通过递归地考虑越来越小的特征子集来选择特征的方法。
- 基于特征子集搜索的方法:这种方法通过搜索最优特征子集来选择特征,通常使用启发式或优化技术来实现。
- 模型评估
- 分类器:提供了多种分类算法的实现,帮助用户进行分类任务的建模和评估。
- 聚类器:提供了多种聚类算法,用于无监督学习中的样本分组。
- 回归器:提供了回归分析的工具,用于预测连续值输出。
- 评估方法:提供了模型性能评估的方法,如交叉验证、得分指标等。
- 数据可视化
- 绘图:提供了丰富的绘图功能,帮助用户在数据探索和分析过程中可视化数据分布和模型结果。
- 图像:支持图像数据的处理和分析,扩展了机器学习在视觉领域的应用。
官方学习地址:https://rasbt.github.io/mlxtend/
2 导入库
In 1:
import numpy as np
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
from matplotlib import cm
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
import itertools
from sklearn.linear_model import LogisticRegression # 逻辑回归分类
from sklearn.svm import SVC # SVC
from sklearn.ensemble import RandomForestClassifier # 随机森林分类
from mlxtend.classifier import EnsembleVoteClassifier # 从mlxtend导入集成投票表决分类算法
from mlxtend.data import iris_data # 内置数据集
from mlxtend.plotting import plot_decision_regions # 绘制决策边界
import warnings
warnings.filterwarnings('ignore')3 绘制散点矩阵图scatterplotmatrix
scatterplotmatrix(
X, # 待绘图的数据
fig_axes=None, # (fig,axes)的元组
names=None, # 名称
figsize=(8, 8), # 图形大小
alpha=1.0 # 透明度
)返回值是fig_axes:(fig, axes)的元组;fig对象+axes对象,fig,axes=plt.subplots(...)
3.1 基础散点矩阵图
In 2:
import matplotlib.pyplot as plt
from mlxtend.data import iris_data
from mlxtend.plotting import scatterplotmatrix # 散点矩阵图
X, y = iris_data()
yOut2:
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])In 3:
scatterplotmatrix(X, figsize=(10, 8))
plt.tight_layout()
plt.show()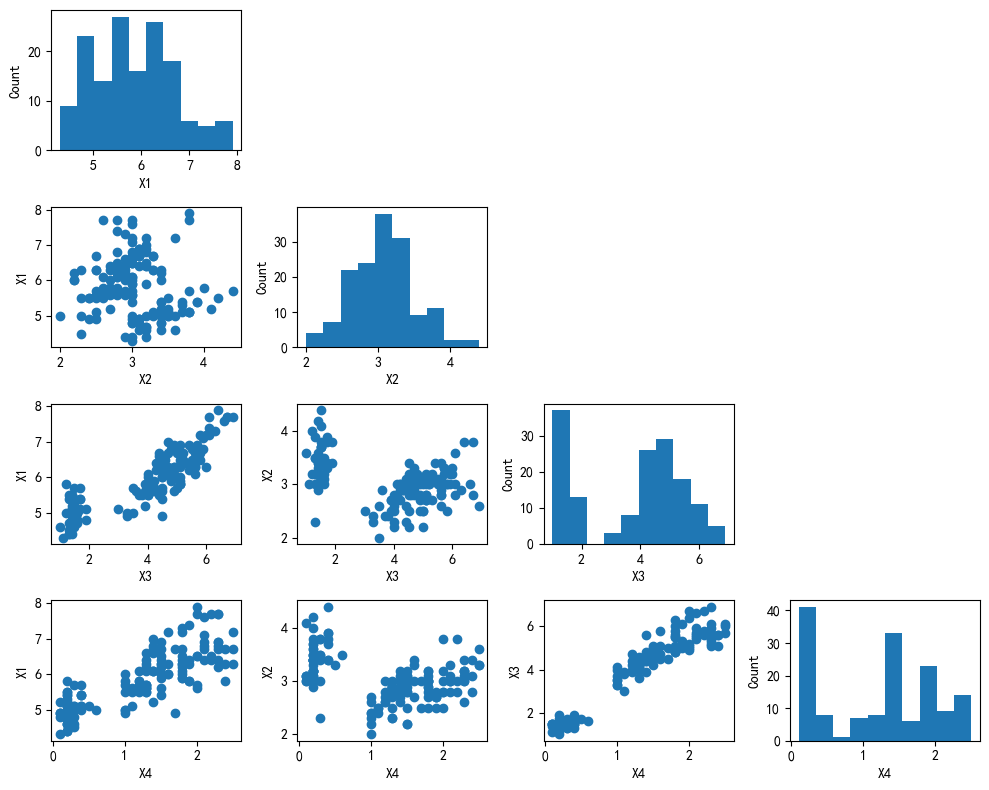
3.2 多分类散点矩阵图
In 4:
names = ['sepal length', 'sepal width','petal length', 'petal width']
fig, axes = scatterplotmatrix(X[y==0], figsize=(10, 8), alpha=0.5) # y=0的数据
fig, axes = scatterplotmatrix(X[y==1], fig_axes=(fig, axes), alpha=0.5) # y=0的数据
fig, axes = scatterplotmatrix(X[y==2], fig_axes=(fig, axes), alpha=0.5, names=names)
plt.tight_layout()
plt.show()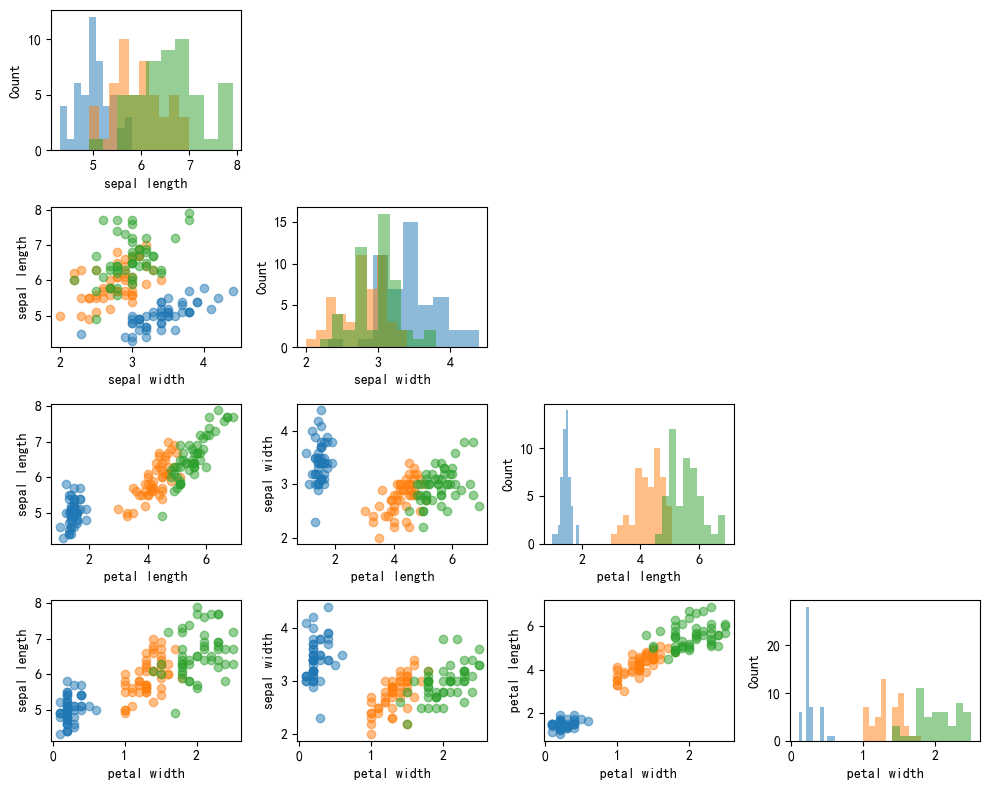
4 散点直方图scatter_hist
In 5:
from mlxtend.data import iris_data
from mlxtend.plotting import scatter_hist
import pandas as pd4.1 基于numpy数组的散点直方图
In 6:
X,y = iris_data()
X[:3] # numpy数组形式Out6:
array([[5.1, 3.5, 1.4, 0.2],
[4.9, 3. , 1.4, 0.2],
[4.7, 3.2, 1.3, 0.2]])In 7:
fig = scatter_hist(X[:,0], X[:,1]) # 传入两列数据
plt.show()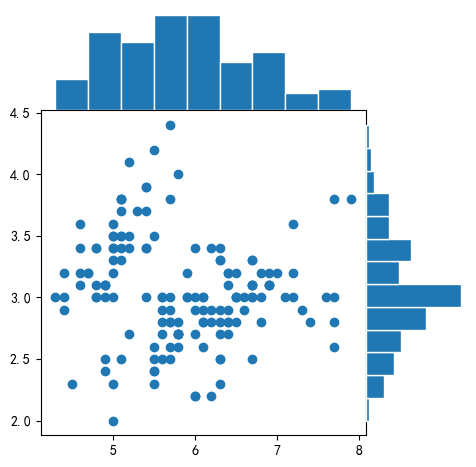
4.2 基于DataFrame数据的散点直方图
In 8:
df = pd.DataFrame(X) # 生成DataFrame数据
df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width']
df.head()Out8:
sepal length | sepal width | petal length | petal width | |
|---|---|---|---|---|
0 | 5.1 | 3.5 | 1.4 | 0.2 |
1 | 4.9 | 3.0 | 1.4 | 0.2 |
2 | 4.7 | 3.2 | 1.3 | 0.2 |
3 | 4.6 | 3.1 | 1.5 | 0.2 |
4 | 5.0 | 3.6 | 1.4 | 0.2 |
In 9:
from mlxtend.plotting import scatter_hist
fig = scatter_hist(df["sepal length"], df["sepal width"])
plt.show()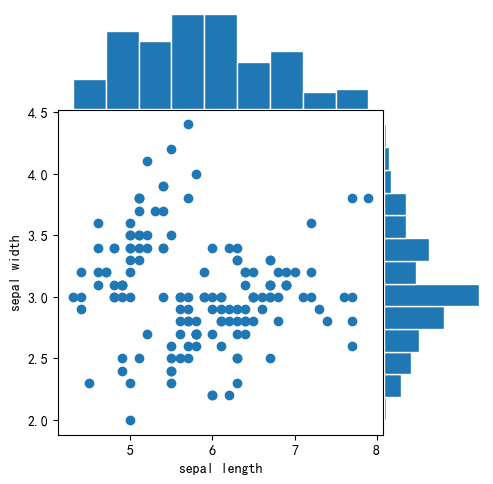
5 堆叠柱状图stacked_barplot
In 10:
import pandas as pd
s1 = [1.0, 2.0, 3.0, 4.0]
s2 = [1.4, 2.1, 2.9, 5.1]
s3 = [1.9, 2.2, 3.5, 4.1]
s4 = [1.4, 2.5, 3.5, 4.2]
data = [s1, s2, s3, s4]
df = pd.DataFrame(data, columns=['X1', 'X2', 'X3', 'X4'])
df.index = ['Sample1', 'Sample2', 'Sample3', 'Sample4']
dfOut10:
X1 | X2 | X3 | X4 | |
|---|---|---|---|---|
Sample1 | 1.0 | 2.0 | 3.0 | 4.0 |
Sample2 | 1.4 | 2.1 | 2.9 | 5.1 |
Sample3 | 1.9 | 2.2 | 3.5 | 4.1 |
Sample4 | 1.4 | 2.5 | 3.5 | 4.2 |
In 11:
import matplotlib.pyplot as plt
from mlxtend.plotting import stacked_barplot
plt.figure(figsize=(5,3))
fig = stacked_barplot(df, rotation=45, legend_loc='best')
plt.show()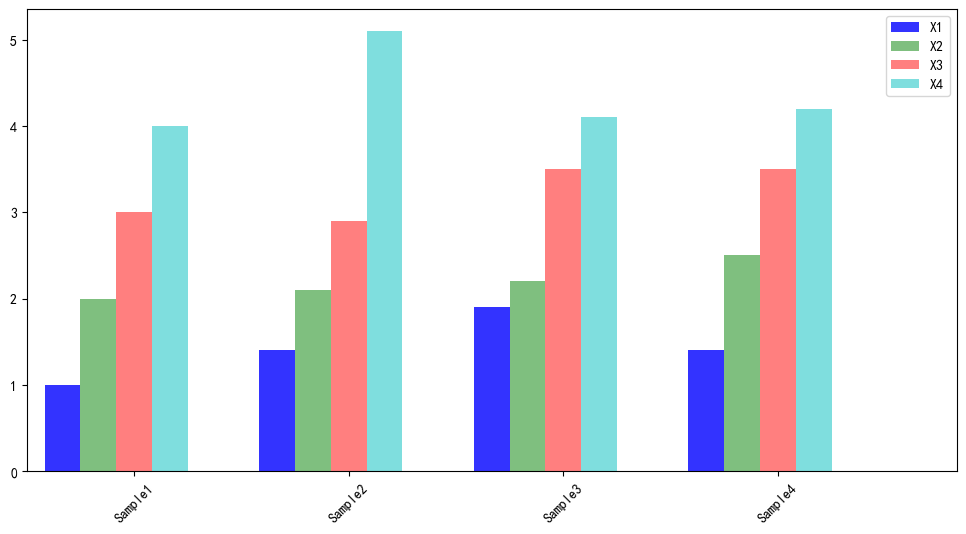
6 线性回归可视化plot_linear_regression
plot_linear_regression(
X,
y,
model=LinearRegression(),
corr_func='pearsonr',
scattercolor='blue',
fit_style='k--',
legend=True,
xlim='auto'
)plot_linear_regression函数用于绘制线性回归线的拟合图。这个函数接收多个参数,具体含义如下:
X:一个一维的numpy数组,表示样本的特征数据。y:一个一维的numpy数组,表示样本的目标值。model:一个线性回归模型对象,默认为LinearRegression(),用于拟合数据线性关系。corr_func:一个字符串或函数,默认为'pearsonr',用于计算相关性系数。如果为'pearsonr',则使用皮尔逊相关系数;如果为其他函数,则需要该函数能够接受两个输入并返回一个包含相关系数和另一个不需要的值的元组。scattercolor:一个字符串,默认为'blue',表示散点图中点的颜色。fit_style:一个字符串,默认为'k--',表示线性回归线的样式。legend:一个布尔值,默认为True,表示是否在图中显示图例。xlim:一个数组或字符串,默认为'auto',表示X轴的限制范围。如果为'auto',则自动计算合适的X轴范围。
这里有修改关于绘图的源代码:

In 12:
import matplotlib.pyplot as plt
from mlxtend.plotting import plot_linear_regression
import numpy as np
X = np.array([4, 8, 13, 26, 31, 10, 12, 20, 5, 28, 18, 6, 31, 12,12, 27, 11, 6, 14, 25, 7, 13,4, 15, 21, 15])
y = np.array([14, 24, 22, 59, 66, 25, 18, 53, 18, 55, 41, 28, 61, 35,36, 52, 23, 19, 25, 73, 16, 32, 14, 31, 43, 34])
intercept, slope, corr_coeff = plot_linear_regression(X, y)
plt.show()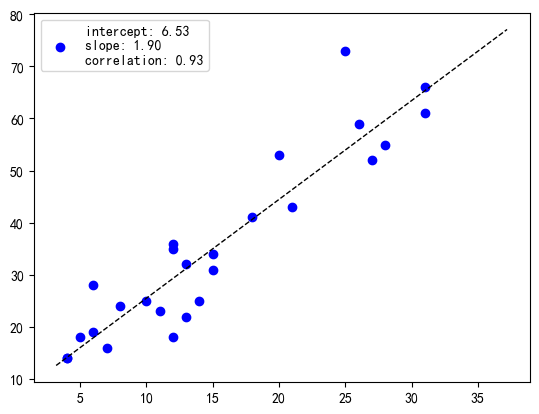
7 PCA降维plot_pca_correlation_graph
绘制基于PCA降维的主成分关系图:
In 13:
import numpy as np
from mlxtend.data import iris_data
from mlxtend.plotting import plot_pca_correlation_graphIn 14:
X, y = iris_data()
X_norm = X / X.std(axis=0) # 数据标准化
feature_names = ['sepal length','sepal width','petal length','petal width']
figure, correlation_matrix = plot_pca_correlation_graph(X_norm, # 数据
feature_names, # 特征
dimensions=(1, 2), # 选择的维度
figure_axis_size=7)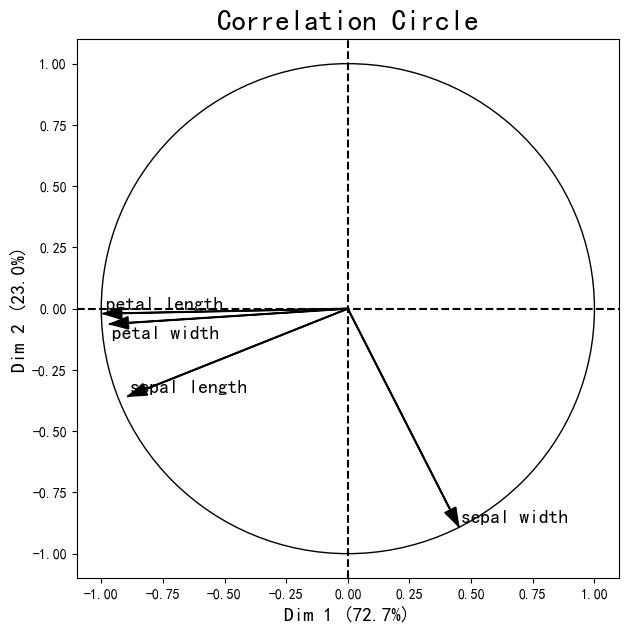
选择其他的特征进行可视化:
In 15:
figure, correlation_matrix = plot_pca_correlation_graph(X_norm, # 数据
feature_names, # 特征
dimensions=(2, 4), # 选择的维度
figure_axis_size=7)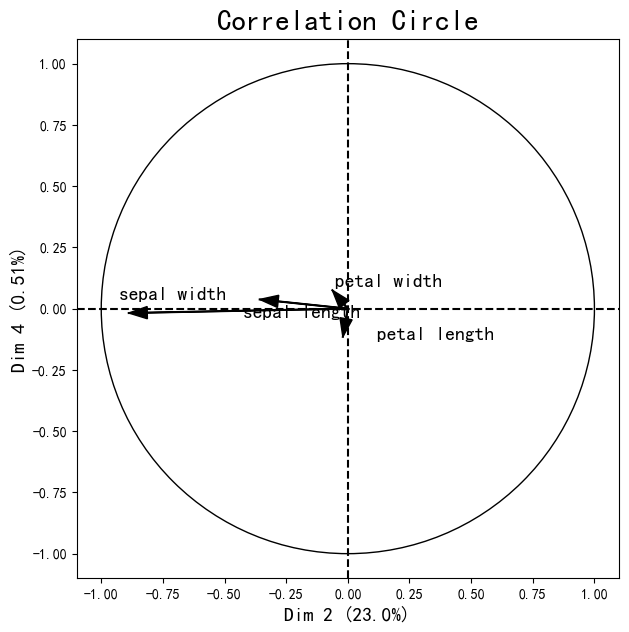
8 经验累计分布图ECDF(empirical cumulative distribution function)
ecdf(x,
y_label='ECDF',
x_label=None,
ax=None,
percentile=None,
ecdf_color=None,
ecdf_marker='o',
percentile_color='black',
percentile_linestyle='--')返回值:
- ax:matplotlib.axes绘图对象
- percentile_threshold:阈值
- percentile_count:阈值以下的样本数
8.1 单ECDF
In 16:
from mlxtend.data import iris_data
from mlxtend.plotting import ecdf
import matplotlib.pyplot as plt
X, y = iris_data()
ax, _, _ = ecdf(x=X[:, 1], x_label='sepal length (cm)')
plt.show()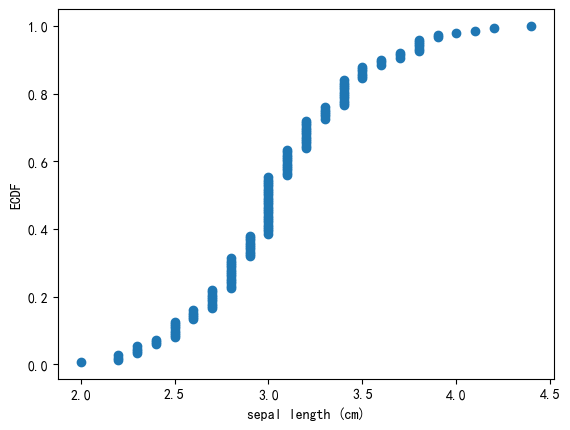
8.2 多ECDF
In 17:
from mlxtend.data import iris_data
from mlxtend.plotting import ecdf
import matplotlib.pyplot as plt
X, y = iris_data()
# 两个图
x1 = X[:, 0]
ax, _, _ = ecdf(x1, x_label='cm')
x2 = X[:, 1]
ax, _, _ = ecdf(x2, ax=ax)
plt.legend(['sepal length', 'sepal width'])
plt.show()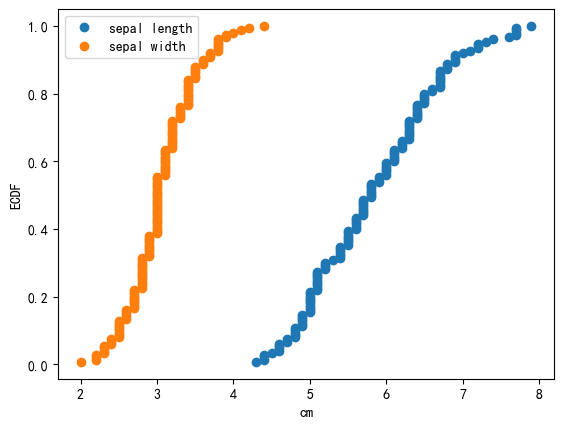
8.3 基于阈值的ECDF
In 18:
from mlxtend.data import iris_data
from mlxtend.plotting import ecdf
import matplotlib.pyplot as plt
X, y = iris_data()
ax, threshold, count = ecdf(x=X[:, 0],
x_label='sepal length (cm)',
percentile=0.8)
plt.show()
print('Feature threshold at the 80th percentile:', threshold)
print('Number of samples below the threshold:', count)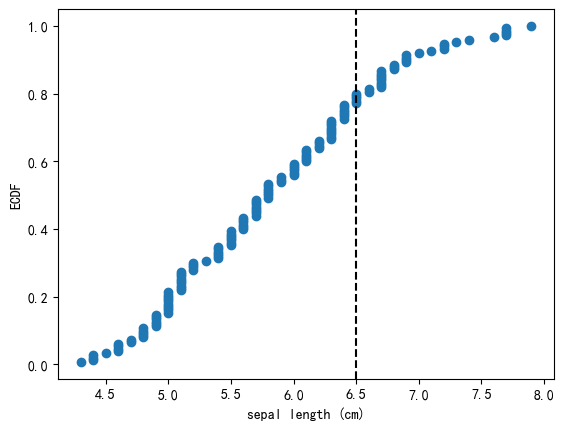
Feature threshold at the 80th percentile: 6.5
Number of samples below the threshold: 1209 富集分析图enrichment_plot
通常用于在生物信息学中,特别是在基因本体论(Gene Ontology, GO)分析或通路分析(Pathway Analysis)中,以可视化不同组之间基因或功能的富集情况。它可以帮助研究人员快速识别和比较不同条件下的生物学过程、分子功能或细胞组分的富集程度。
enrichment_plot(
df,
colors='bgrkcy',
markers=' ',
linestyles='-',
alpha=0.5,
lw=2,
where='post',
grid=True,
count_label='Count',
xlim='auto',
ylim='auto',
invert_axes=False,
legend_loc='best',
ax=None)enrichment_plot函数用于绘制富集分析图。以下是各个参数的解释:
df:输入的数据框,包含富集分析的结果。colors:颜色列表,用于指定每个富集项的颜色,默认为'bgrkcy'。markers:标记样式列表,用于指定每个富集项的标记样式,默认为空格。linestyles:线条样式列表,用于指定每个富集项的线条样式,默认为实线。alpha:透明度,用于设置图形的透明度,默认为0.5。lw:线宽,用于设置线条的宽度,默认为2。where:指定箭头的位置,可选值为'pre'(箭头在数据点之前)或'post'(箭头在数据点之后),默认为'post'。grid:是否显示网格线,默认为True。count_label:计数标签,用于设置计数标签的文本,默认为'Count'。xlim:x轴范围,可以设置为'auto'(自动调整)或一个元组(如(0, 10)),默认为'auto'。ylim:y轴范围,可以设置为'auto'(自动调整)或一个元组(如(0, 10)),默认为'auto'。invert_axes:是否反转坐标轴,默认为False。legend_loc:图例位置,可以是字符串(如'best')或一个元组(如(1, 0)),默认为'best'。ax:绘图的坐标轴对象,如果为None,则创建一个新的坐标轴对象。
In 19:
df = pd.DataFrame({"x1":[1,2,3,4,5], "x2":[1.5,2.5,3.5,4.5,5.5]})
dfOut19:
x1 | x2 | |
|---|---|---|
0 | 1 | 1.5 |
1 | 2 | 2.5 |
2 | 3 | 3.5 |
3 | 4 | 4.5 |
4 | 5 | 5.5 |
In 20:
import matplotlib.pyplot as plt
from mlxtend.plotting import enrichment_plot
ax = enrichment_plot(df, legend_loc='upper left')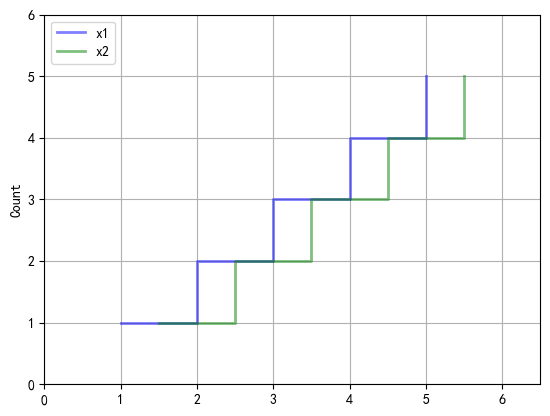
10 热力图heatmap
heatmap(matrix,
hide_spines=False,
hide_ticks=False,
figsize=None,
cmap=None,
colorbar=True,
row_names=None,
column_names=None,
column_name_rotation=45,
cell_values=True,
cell_fmt='.2f',
cell_font_size=None,
text_color_threshold=None)参数解释:
- matrix:形状为n_rows, n_columns的任意二维数组。
- hide_spines:布尔值,默认为False。如果为True,则隐藏坐标轴脊线。
- hide_ticks:布尔值,默认为False。如果为True,则隐藏坐标轴刻度。
- figsize:元组,默认为(2.5, 2.5)。表示图形的高度和宽度。
- cmap:matplotlib颜色映射,默认为None。如果为None,则使用matplotlib.pyplot.cm.viridis。
- colorbar:布尔值,默认为True。如果为True,则显示颜色条。
- row_names:形状为n_rows的数组,默认为None。用作y轴刻度标签的行名称列表。
- column_names:形状为n_columns的数组,默认为None。用作x轴刻度标签的列名称列表。
- column_name_rotation:整数,默认为45。列x刻度标签的旋转角度(以度为单位)。
- cell_values:布尔值,默认为True。如果为True,则绘制单元格值。
- cell_fmt:字符串,默认为'.2f'。单元格值的格式说明(如果cell_values=True)。
- cell_font_size:整数,默认为None。单元格值的字体大小(如果cell_values=True)。
- text_color_threshold:浮点数,默认为None。文本注释的黑/白阈值。默认(None)尝试使用np.max(normed_matrix) / 2自动推断一个好阈值。
In 21:
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
np.random.seed(123)
from mlxtend.plotting import heatmap # 绘制热力图10.1 基础热力图
In 22:
array = np.random.random((10,20)) # 模拟数据 10行20列
array[:1]Out22:
array([[0.69646919, 0.28613933, 0.22685145, 0.55131477, 0.71946897,
0.42310646, 0.9807642 , 0.68482974, 0.4809319 , 0.39211752,
0.34317802, 0.72904971, 0.43857224, 0.0596779 , 0.39804426,
0.73799541, 0.18249173, 0.17545176, 0.53155137, 0.53182759]])In 23:
# 绘制图形
heatmap(array,
figsize=(14,7),
#cell_values=False # 是否显示单元格的数值,默认为True
)
plt.show()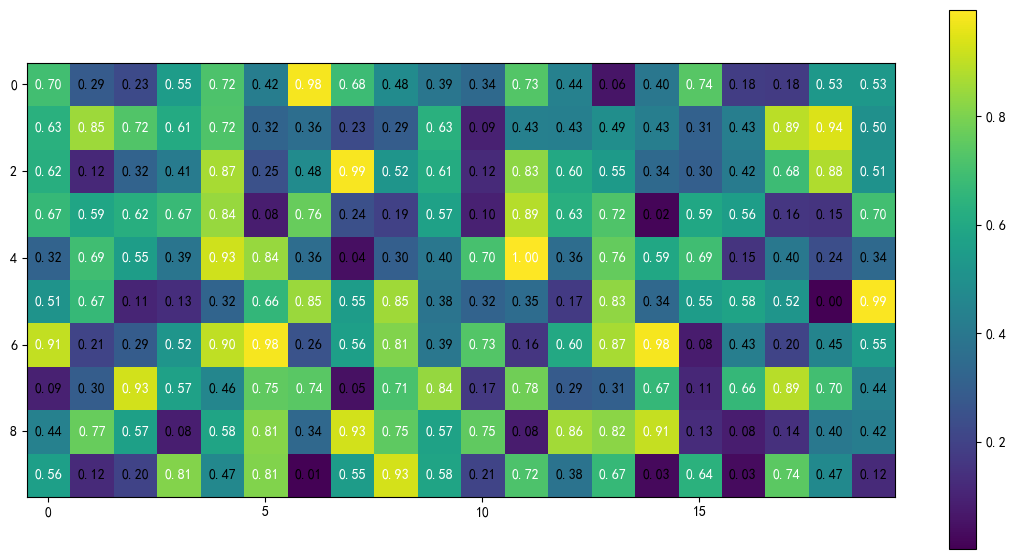
10.2 基于相关系数矩阵热力图
In 24:
# 使用iris数据集
X, y = iris_data()
cols = ['sepal length','sepal width','petal length','petal width']
df1 = pd.DataFrame(X, columns=cols)
df1.head()Out24:
sepal length | sepal width | petal length | petal width | |
|---|---|---|---|---|
0 | 5.1 | 3.5 | 1.4 | 0.2 |
1 | 4.9 | 3.0 | 1.4 | 0.2 |
2 | 4.7 | 3.2 | 1.3 | 0.2 |
3 | 4.6 | 3.1 | 1.5 | 0.2 |
4 | 5.0 | 3.6 | 1.4 | 0.2 |
计算相关系数矩阵:
In 25:
corrmat = df1.corr().values
# corrmat = np.corrcoef(df1[cols].values.T)
corrmatOut25:
array([[ 1. , -0.10936925, 0.87175416, 0.81795363],
[-0.10936925, 1. , -0.4205161 , -0.35654409],
[ 0.87175416, -0.4205161 , 1. , 0.9627571 ],
[ 0.81795363, -0.35654409, 0.9627571 , 1. ]])In 26:
fig, ax = heatmap(
corrmat, # 相关系数矩阵
column_names=cols, # 列名
row_names=cols, # 行名
cmap=cm.Pastel1_r
)
# 设置颜色柱体
for im in ax.get_images():
im.set_clim(-1,1)
plt.show()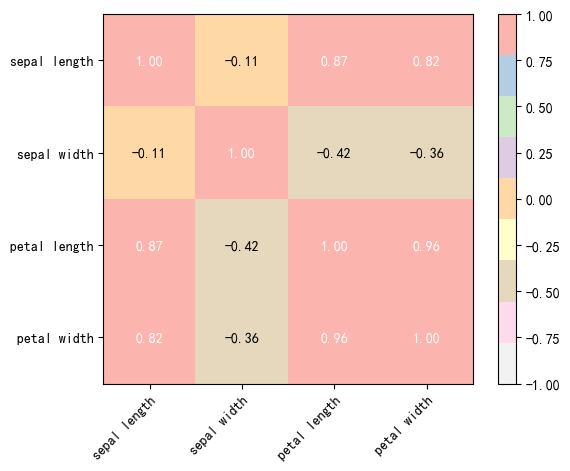
其他不同的参数设置:
In 27:
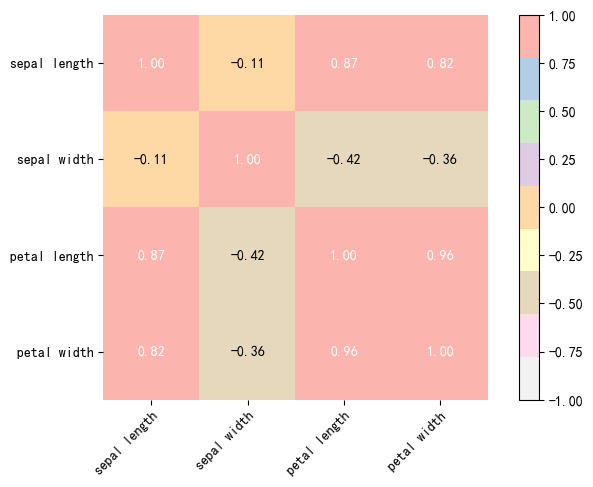
fig, ax = heatmap(
corrmat, # 相关系数矩阵
column_names=cols, # 列名
row_names=cols, # 行名
cmap=cm.Pastel1_r, # 颜色
hide_spines=True, # 是否隐藏边框线
hide_ticks=False, # 是否隐藏坐标轴的标注
figsize=(8,5), # 大小
colorbar=True, # 是否显示颜色柱
column_name_rotation=45, # 列名旋转角度
cell_values=True, # 是否显示单元格的数据
cell_fmt='.2f', # 显示小数位
cell_font_size=10, # 单元格字体大小
text_color_threshold=None # 文本颜色阈值
)
for im in ax.get_images():
im.set_clim(-1,1)
11 混淆矩阵可视化plot_confusion_matrix
plot_confusion_matrix函数用于绘制混淆矩阵的可视化图形。混淆矩阵是一个在机器学习和模式识别中常用的表,它展示了算法在特定数据集上的分类性能。具体来说,混淆矩阵显示了算法预测的类别与实际类别之间的关系。
plot_confusion_matrix(
conf_mat,
hide_spines=False,
hide_ticks=False,
figsize=None,
cmap=None,
colorbar=False,
show_absolute=True,
show_normed=False,
class_names=None,
figure=None,
axis=None,
fontcolor_threshold=0.5
)参数解释如下:
conf_mat:混淆矩阵,通常由分类模型的confusion_matrix属性生成。hide_spines:是否隐藏坐标轴的边框线,默认为False。hide_ticks:是否隐藏坐标轴的刻度,默认为False。figsize:设置图像的大小,例如(10, 8),默认为None。cmap:用于绘制混淆矩阵的颜色映射,默认为None。colorbar:是否显示颜色条,默认为False。show_absolute:是否显示绝对值,默认为True。show_normed:是否显示归一化后的值,默认为False。class_names:类别标签列表,用于在混淆矩阵的轴上显示类别名称,默认为None。figure:Matplotlib的Figure对象,如果提供,则在该对象上绘制混淆矩阵,否则创建一个新的Figure对象,默认为None。axis:Matplotlib的Axes对象,如果提供,则在该对象上绘制混淆矩阵,否则创建一个新的Axes对象,默认为None。fontcolor_threshold:字体颜色阈值,用于根据单元格中的数值大小来调整字体颜色,默认为0.5。
11.1 二分类混淆矩阵
In 28:
from mlxtend.plotting import plot_confusion_matrix
import matplotlib.pyplot as plt
import numpy as np
binary1 = np.array([[2.5, 1],
[1, 2]])
fig, ax = plot_confusion_matrix(conf_mat=binary1,figsize=(3,3))
plt.show()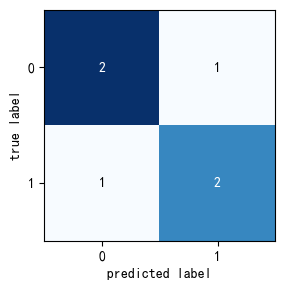
11.2 显示绝对值和颜色柱的二分类混淆矩阵
In 29:
from mlxtend.plotting import plot_confusion_matrix
import matplotlib.pyplot as plt
import numpy as np
binary1 = np.array([[2.5, 1],
[1, 2]])
fig, ax = plot_confusion_matrix(
conf_mat=binary1,
show_absolute=True, # 绝对值
show_normed=True, # 标注化
colorbar=True, # 显示颜色柱
figsize=(5,5) # 大小
)
plt.show()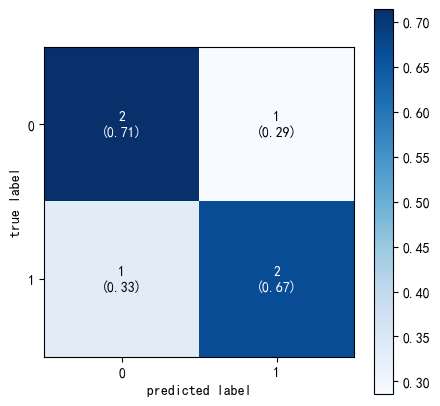
11.3 多分类的混淆矩阵
In 30:
multiclass_array = np.array(
[[2, 1, 0, 0],
[1, 2, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]]
)
fig, ax = plot_confusion_matrix(
conf_mat=multiclass_array, # 多分类矩阵
colorbar=True, # 颜色柱
show_absolute=False, # 不显示绝对值
show_normed=True # 是否标准化
)
plt.show()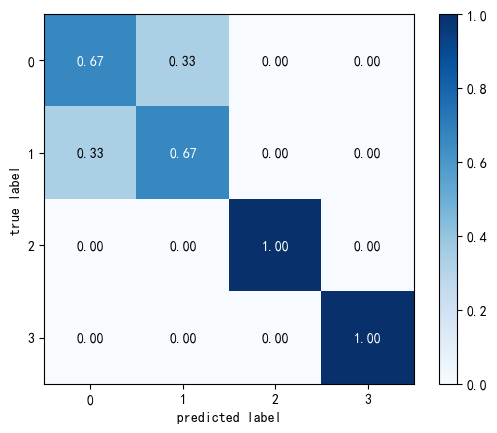
11.4 自定义类别名的混淆矩阵
使用自定义的类别名:二分类默认是0-1;多分类默认是0,1,2,3...
In 31:
multiclass_array = np.array(
[[2, 1, 0, 0],
[1, 2, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]]
)
names = ["c1","c2","c3","c4"]
fig, ax = plot_confusion_matrix(
conf_mat=multiclass_array, # 多分类矩阵
class_names=names, # 使用自定义的类别名
colorbar=True, # 颜色柱
show_absolute=False, # 不显示绝对值
show_normed=True # 是否标准化
)
plt.show()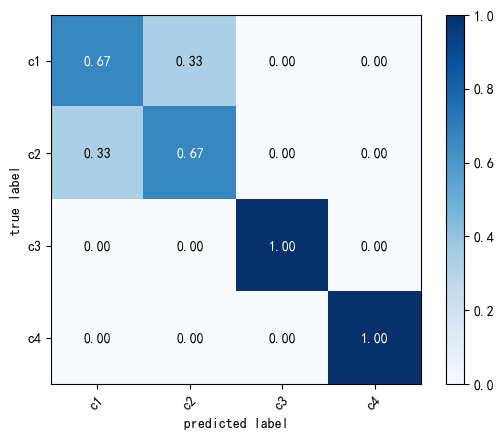
11.5 自定义颜色的混淆矩阵
In 32:
fig, ax = plot_confusion_matrix(
conf_mat=binary1,
figsize=(5,5),
colorbar=True,
cmap="GnBu_r", # 颜色柱
fontcolor_threshold=1 # 字体颜色阈值设置
)
plt.show()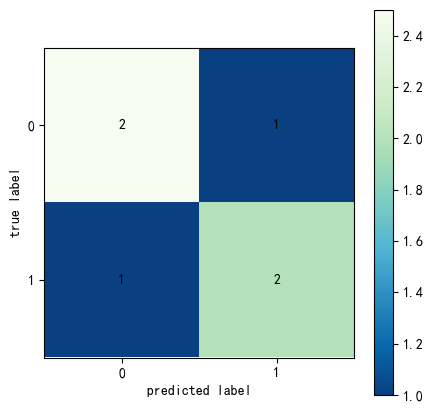
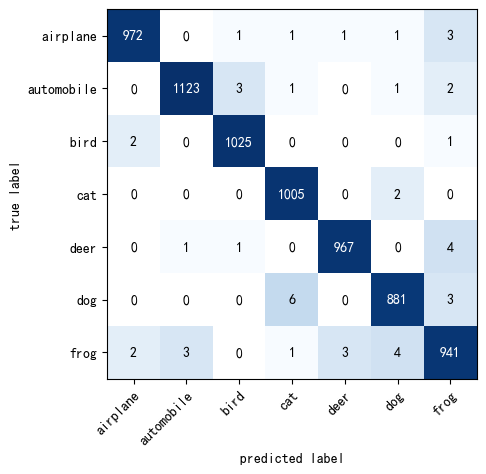
11.6 归一化颜色突出对角线的混淆矩阵
In 33:
class_dict = {0: 'airplane',1: 'automobile',2: 'bird',3: 'cat',4: 'deer',5: 'dog',6: 'frog'}
cmat = np.array([[972, 0, 1, 1, 1, 1, 3],
[0, 1123, 3, 1, 0, 1, 2],
[2, 0, 1025, 0, 0, 0, 1],
[0, 0, 0, 1005, 0, 2, 0],
[0, 1, 1, 0, 967, 0, 4],
[0, 0, 0, 6, 0, 881, 3],
[2, 3, 0, 1, 3, 4, 941]])
fig, ax = plot_confusion_matrix(
conf_mat=cmat,
class_names=class_dict.values(),
norm_colormap=matplotlib.colors.LogNorm() # 归一化颜色对象
)
12 学习曲线可视化plot_learning_curves
plot_learning_curves(
X_train,
y_train,
X_test,
y_test,
clf,
train_marker='o',
test_marker='^',
scoring='misclassification error',
suppress_plot=False,
print_model=True,
title_fontsize=12,
style='default',
legend_loc='best'
)plot_learning_curves函数用于绘制学习曲线,以评估模型在不同训练集大小下的性能。以下是参数的解释:
X_train:训练数据集的特征。y_train:训练数据集的标签。X_test:测试数据集的特征。y_test:测试数据集的标签。clf:分类器或回归器对象,需要实现fit和predict方法。train_marker:训练集学习曲线上的标记样式,默认为'o'。test_marker:测试集学习曲线上的标记样式,默认为'^'。scoring:评估指标,默认为'misclassification error'(误分类错误)。suppress_plot:是否禁止绘图,默认为False。print_model:是否打印模型信息,默认为True。title_fontsize:图表标题的字体大小,默认为12。style:绘图风格,默认为'default'。legend_loc:图例位置,默认为'best'。
In 34:
from mlxtend.plotting import plot_learning_curves
import matplotlib.pyplot as plt
from mlxtend.data import mnist_data
from mlxtend.preprocessing import shuffle_arrays_unison
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
import numpy as np
X, y = mnist_data()
X, yOut34:
(array([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]),
array([0, 0, 0, ..., 9, 9, 9]))In 35:
# 切分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=0)报错解决:AttributeError: ‘NoneType’ object has no attribute ‘split’,更新threadpoolctl版本:
pip install threadpoolctl==3.1.0In 36:
clf = KNeighborsClassifier(n_neighbors=7)
plot_learning_curves(X_train, y_train, X_test, y_test, clf)
plt.show()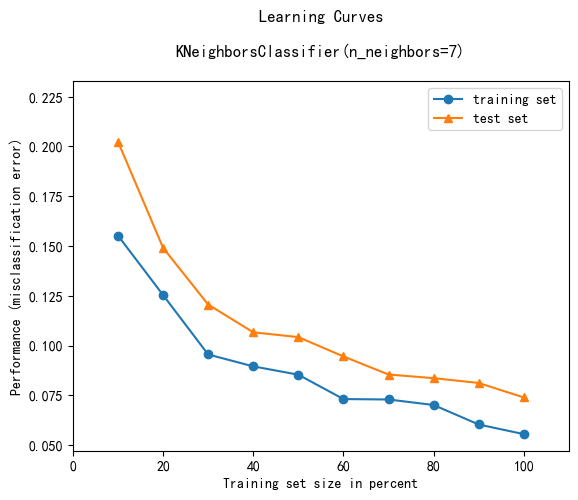
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。