Java Parallel Streams 并行流

Java Parallel Streams 并行流

测试蔡坨坨
发布于 2024-06-18 14:46:23
发布于 2024-06-18 14:46:23
“阅读本文大概需要16分钟。
你好,我是测试蔡坨坨。
在上一篇文章(Java Stream 优雅编程)中,我们详细介绍了Java Stream流的工作原理以及实现步骤,相信大家应该已经对流的具体使用方法有了一定的了解。另外,目前为止所有示例都是基于对顺序流的操作,它是单线程顺序执行的,Stream API 还提供了一种更高效的解决方案,那就是并行流,它能够借助多核处理器的并行计算能力,加速数据处理,特别适合大型数据集,或计算密集型任务。
所以,本篇我们就来学习一下Parallel Streams(并行流)。
Parallel Streams核心原理
并行流的核心工作原理:
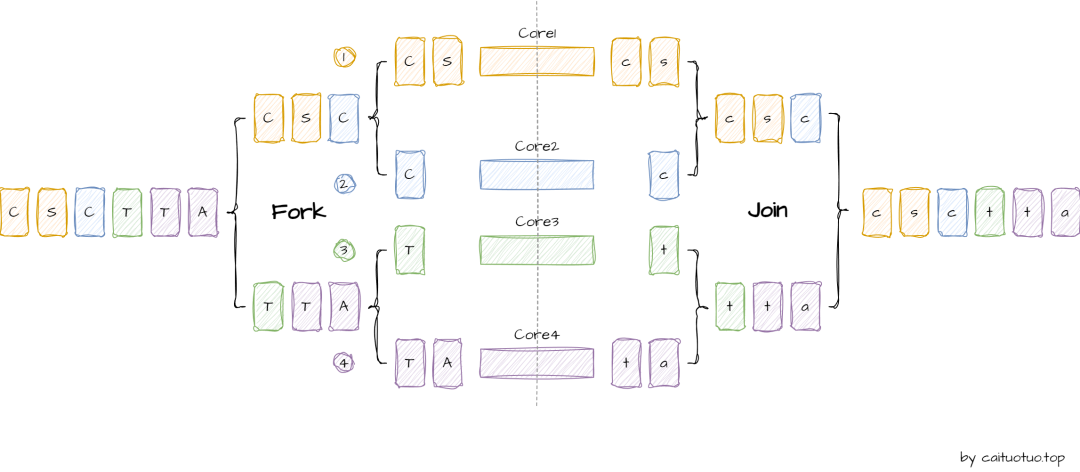
并行流在开始时,分割迭代器Spliterator会将数据分割成多个片段,分割过程通常采用递归的方式动态进行,以平衡子任务的工作负载,提高资源利用率;然后Fork/Join框架会将这些数据片段分配到多个线程和处理器核心上进行并行处理;处理完成后,结果将会被汇总合并,其核心是任务的分解Fork和结果的合并Join。
在操作上,无论是并行流还是顺序流,两者都提供了相同的中间操作和终端操作。这意味着你可以用几乎相同的方式进行数据处理和结果收集。
forEachOrdered
由于并行流是多线程操作,可能存在处理结果顺序问题,我们可以通过forEachOrdered()这个方法来进行处理。forEachOrdered之所以能够保持结果与输入相同的出现顺序,这归功于Spliterator和Fork/Join框架的协作,其工作原理是这样的:
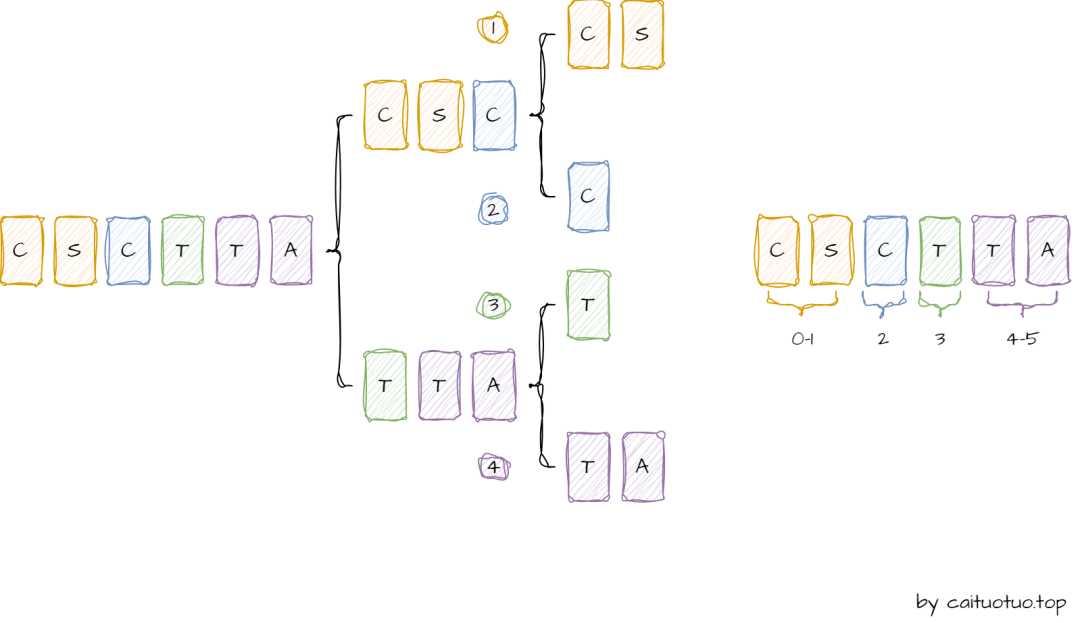
在处理并行流时,对于有序数据源,比如List,Spliterator会对数据源进行递归分割,分隔通常是基于逻辑上的,而非物理上的复制数据,通过划分数据源的索引范围来实现,每次分割都会产生一个新的Spliterator实例,该实例内部维护了指向源数据的索引范围,这种分割机制可以让数据的出现顺序得以保持;然后Fork/Join框架会将分割后的数据块分配给不同的子任务执行,对于forEachOrdered的操作,Fork/Join框架会依据Spliterator维护的顺序信息来调度方法的执行顺序,这意味着即使某个子任务较早的完成,如果其关联的方法执行顺序还未到来,那么系统将会缓存顺序并暂停执行该方法,直到所有前序任务都已完成,并执行了各自的相关方法,这种机制确保了即使在并行处理的情况下,每个数据也会按照原始数据的出现顺序执行,当然这么做也可能会牺牲一些并行执行的效率。
另外,值得注意的是forEachOrdered只专注于按出现顺序执行指定操作,不需要对数据进行合并和收集。
而对于forEach,尽管Spliterator分割策略相同,依旧保持着顺序信息,但Fork/Join框架执行时会忽略这些顺序信息,因此执行不保证遵循原始顺序,但能够提供更高的执行效率。
forEach操作会在不同的线程上独立执行,这意味着如果操作的是共享资源,那么必须确保这些操作是线程安全的。如果没有适当的同步措施,可能会引发线程安全问题,因此,在并行流中,forEach更适合执行无状态操作或处理资源独立的场景。
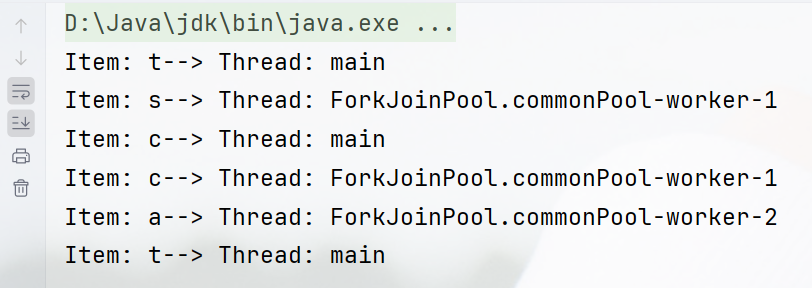
list.parallelStream()
.map(String::toLowerCase)
.forEach(item -> {
System.out.println("Item: " + item + "--> Thread: " + Thread.currentThread().getName());
});
运行结果:可以看到在不同的线程上执行
collect的顺序问题
接下来,我们来看一下并行流在收集数据时的顺序问题。
例如我们将数据收集到List中:
package top.caituotuo.intermediate.streamDemo;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.stream.Collectors;
/**
* author: 测试蔡坨坨 caituotuo.top
* datetime: 2024/6/10 13:15
* function:
*/
public class ParallelStreamsDemo2 {
public static void main(String[] args) {
// 创建由6个大写字母组成的list
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "C", "S", "C", "T", "T", "A");
List<String> list1 = list.parallelStream()
.map(String::toLowerCase)
.collect(Collectors.toList());
System.out.println(list1); // [c, s, c, t, t, a]
}
}
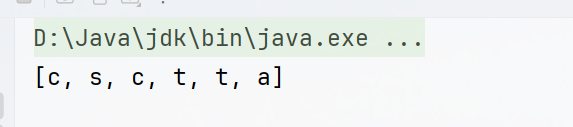
从运行结果可以看到收集到List中的顺序和原始数据的顺序是相同的。
其实,收集到List和forEachOrdered操作很相似,尤其是在数据的分割和并行处理阶段,主要的区别在于collect操作需要在最终合并收集数据,而forEachOrdered则不需要:
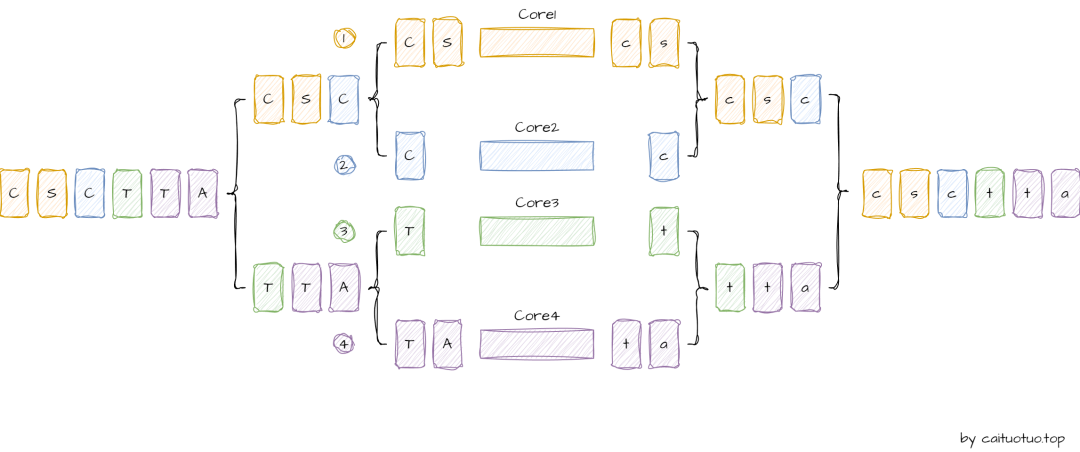
每个并行执行的任务在完成处理后,会将其结果存储到一个临时数据结构中,Fork/Join框架会利用Spliterator提供的区段顺序信息,引导这些临时结果按顺序的合并。同样,即使某个逻辑上靠后的数据段先处理完成,合并时也不会让这个结果前置,整个合并过程递归进行,直至所有的结果都合并完毕。
我们可以自定义一个收集器,来实现toList方法:
package top.caituotuo.intermediate.streamDemo;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.stream.Collector;
import java.util.stream.Collectors;
/**
* author: 测试蔡坨坨 caituotuo.top
* datetime: 2024/6/10 13:15
* function: 自定义收集器,实现toList
*/
public class ParallelStreamsDemo2 {
public static void main(String[] args) {
ArrayList<String> arrayList = new ArrayList<>();
Collections.addAll(arrayList, "C", "S", "C", "T", "T", "A");
List<String> collect = arrayList.parallelStream()
.map(String::toLowerCase)
.collect(Collector.of(
// 定义一个spliterator分割迭代器,创建一个新的List实例,作为数据容器
() -> {
// 监控创建过程
System.out.println("Supplier(new ArrayList): " + " Thead: " + Thread.currentThread().getName());
return new ArrayList<>();
},
// Accumulator累加器
(ArrayList<String> list, String item) -> {
// 监控累加过程
System.out.println("Accumulator(add): " + item + " Thead: " + Thread.currentThread().getName());
// 累加操作,将元素添加到list中
list.add(item);
},
// Combiner组合器 顺序流和并行流的区别之一是并行流需要合并步骤
(ArrayList<String> left, ArrayList<String> right) -> {
// 监控合并过程
System.out.println("Combiner(addAll): " + left + "+" + right + " Thead: " + Thread.currentThread().getName());
// 合并操作,将list2中的元素添加到list1中
left.addAll(right);
return left;
},
// Characteristics characteristics 定义流操作的特性
// IDENTITY_FINISH 表示流操作的最终结果与输入参数相同,即最终结果是ArrayList<String>
Collector.Characteristics.IDENTITY_FINISH
));
System.out.println(collect); // [c, s, c, t, t, a]
}
}
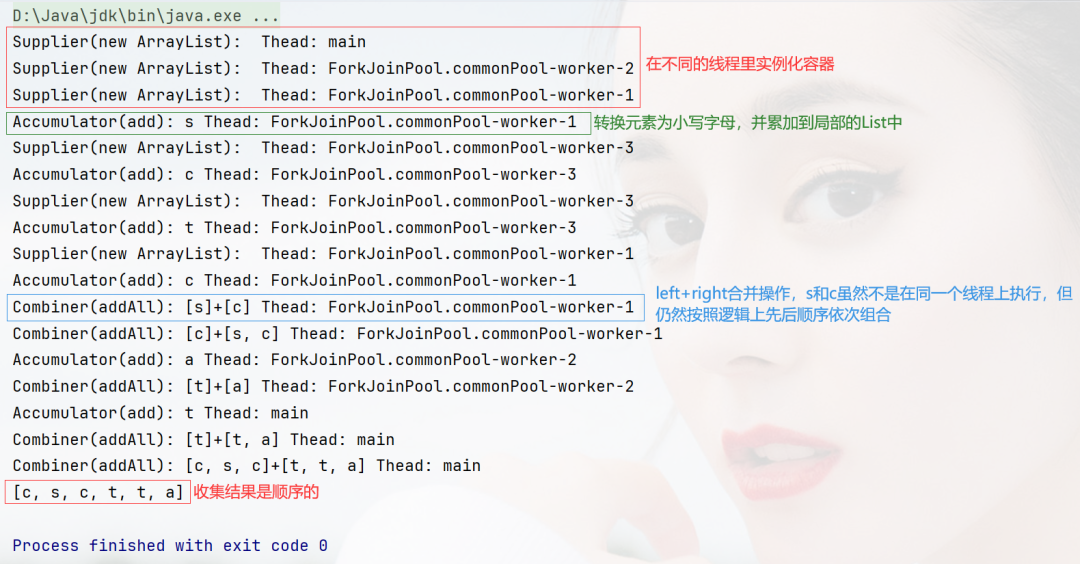
当我们将toList操作改成toSet操作,结果就会呈现无序,并且还有做去重操作:
package top.caituotuo.intermediate.streamDemo;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.Set;
import java.util.stream.Collector;
import java.util.stream.Collectors;
/**
* author: 测试蔡坨坨 caituotuo.top
* datetime: 2024/6/10 13:15
* function: toSet
*/
public class ParallelStreamsDemo3 {
public static void main(String[] args) {
ArrayList<String> arrayList = new ArrayList<>();
Collections.addAll(arrayList, "C", "S", "C", "T", "T", "A");
Set<String> collect = arrayList.parallelStream()
.map(String::toLowerCase)
.collect(Collectors.toSet());
System.out.println(collect); // [a, c, s, t]
}
}
这是因为Set数据结构的性质导致的,而不是并行处理本身导致的。
需要强调的是,无论采用toList还是toSet收集数据,整个处理过程,包括Spliterator的分割策略,Fork/Join框架的执行和合并策略都没变。因为这些策略是由数据源的性质决定的,而数据源是同一个List,唯一不同的是合并前存储局部结果的临时数据结构,一个是List,一个是Set。
同样我们也来自定义toSet的实现:
package top.caituotuo.intermediate.streamDemo;
import java.util.*;
import java.util.stream.Collector;
import java.util.stream.Collectors;
/**
* author: 测试蔡坨坨 caituotuo.top
* datetime: 2024/6/10 13:15
* function: 自定义收集器,实现toSet
*/
public class ParallelStreamsDemo3 {
public static void main(String[] args) {
ArrayList<String> arrayList = new ArrayList<>();
Collections.addAll(arrayList, "C", "S", "C", "T", "T", "A");
Set<String> collect = arrayList.parallelStream()
.map(String::toLowerCase)
.collect(Collector.of(
// 定义一个spliterator分割迭代器,创建一个新的List实例,作为数据容器
() -> {
// 监控创建过程
System.out.println("Supplier(new HashSet): " + " Thead: " + Thread.currentThread().getName());
return new HashSet<>();
},
// Accumulator累加器
(HashSet<String> list, String item) -> {
// 监控累加过程
System.out.println("Accumulator(add): " + item + " Thead: " + Thread.currentThread().getName());
// 累加操作,将元素添加到list中
list.add(item);
},
// Combiner组合器 顺序流和并行流的区别之一是并行流需要合并步骤
(HashSet<String> left, HashSet<String> right) -> {
// 监控合并过程
System.out.println("Combiner(addAll): " + left + "+" + right + " Thead: " + Thread.currentThread().getName());
// 合并操作,将list2中的元素添加到list1中
left.addAll(right);
return left;
},
// Characteristics characteristics 定义流操作的特性
// IDENTITY_FINISH 表示流操作的最终结果与输入参数相同,即最终结果是HashSet<String>
Collector.Characteristics.IDENTITY_FINISH
));
System.out.println(collect); // [a, c, s, t]
}
}
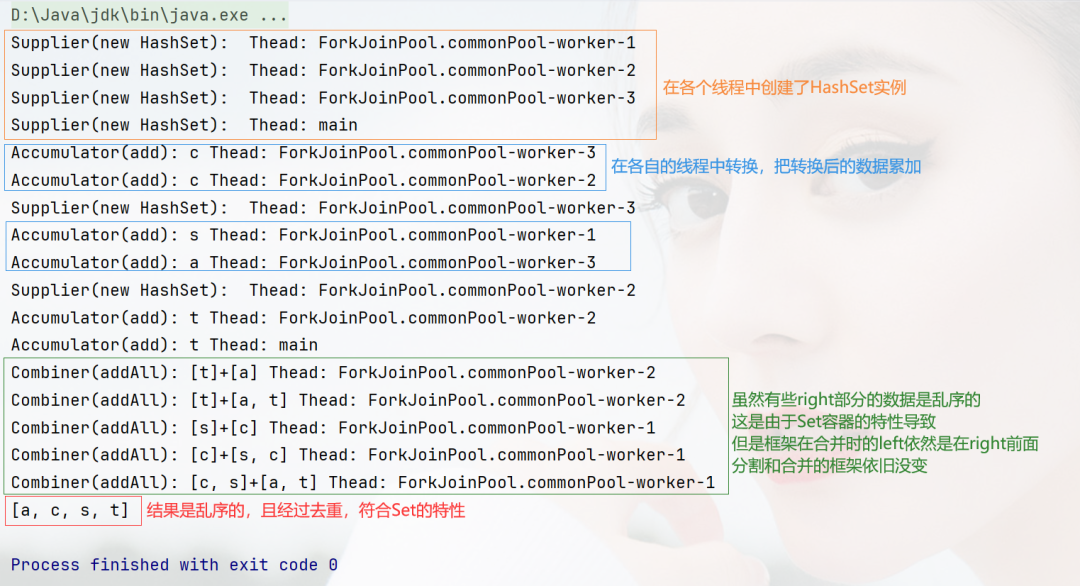
Characteristics
UNORDERED
另外,关于Characteristics中的UNORDERED和CONCURRENT两个特性也经常会引起一些误解和混淆。

特别是UNORDERED,许多人可能会误以为一旦设置了UNORDERED,处理结果就会呈现无序状态,然而结果往往还是有序的:
Collector.Characteristics.UNORDERED


可以看到,即便加了UNORDERED,结果仍然是顺序的。
这是因为即便Collector被标记为UNORDERED,如果数据源或流操作本身是有序的,系统的执行策略通常仍会保持这些元素的出现顺序,只有在特定场景下,系统才会针对那些被标记为UNORDERED的流进行优化,从而打破约束。
CONCURRENT
在标准的并行流处理中,每个线程处理数据的一个子集维护自己的局部结果容器,在所有的结果处理完成后,这些局部结果会用过一个Combiner的函数合并成一个最终结果。
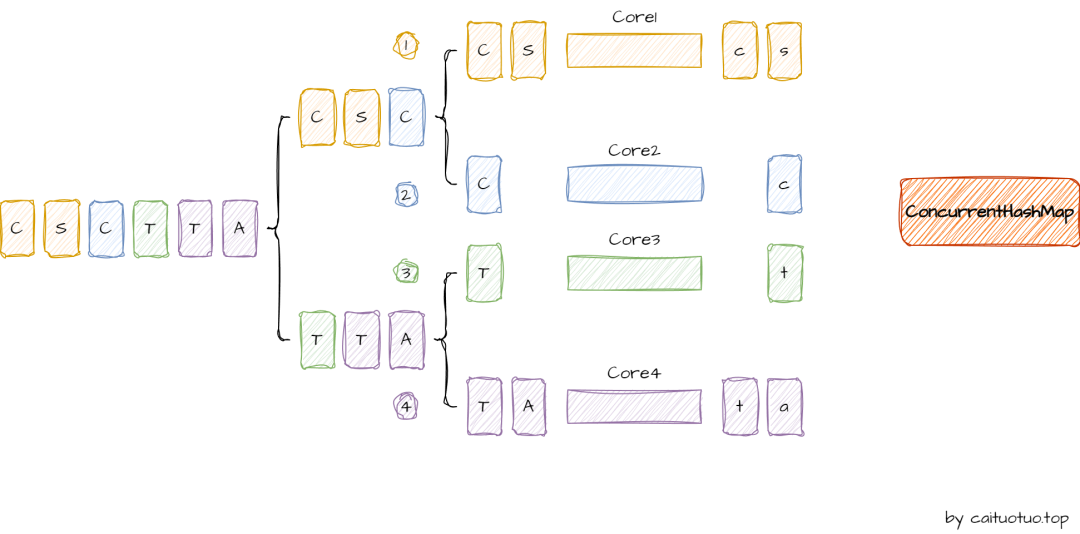
使用CONCURRENT特性后,所有线程将共享一个结果容器,而不是维护独立的局部结果,从而减少了合并的需要,这通常会带来性能上的提升,特别是当结果容器较大,或合并操作较为复杂时。这也就意味着供应函数只会被调用一次,只创建一个结果容器,而且这个容器必须是线程安全的,例如ConcurrentHashMap,此外合并函数将不会再执行。
由于ArrayList不是线程安全的,即使被标记为CONCURRENT,也不会生效,所以我们将数据源换成线程安全的ConcurrentHashMap:
package top.caituotuo.intermediate.streamDemo;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.ConcurrentHashMap;
import java.util.stream.Collector;
/**
* author: 测试蔡坨坨 caituotuo.top
* datetime: 2024/6/10 13:15
* function:
*/
public class ParallelStreamsDemo4 {
public static void main(String[] args) {
ArrayList<String> arrayList = new ArrayList<>();
Collections.addAll(arrayList, "C", "S", "C", "T", "T", "A");
ConcurrentHashMap<String, String> collect = arrayList.parallelStream()
.map(String::toLowerCase)
.collect(Collector.of(
() -> {
System.out.println("Supplier(new ConcurrentHashMap): " + " Thead: " + Thread.currentThread().getName());
return new ConcurrentHashMap<>();
},
(ConcurrentHashMap<String, String> map, String item) -> {
System.out.println("Accumulator(add): " + item + " Thead: " + Thread.currentThread().getName());
map.put(item.toUpperCase(), item.toLowerCase());
},
(ConcurrentHashMap<String, String> left, ConcurrentHashMap<String, String> right) -> {
System.out.println("Combiner(addAll): " + left + "+" + right + " Thead: " + Thread.currentThread().getName());
left.putAll(right);
return left;
},
Collector.Characteristics.IDENTITY_FINISH,
Collector.Characteristics.CONCURRENT
));
System.out.println(collect);
}
}
运行结果:
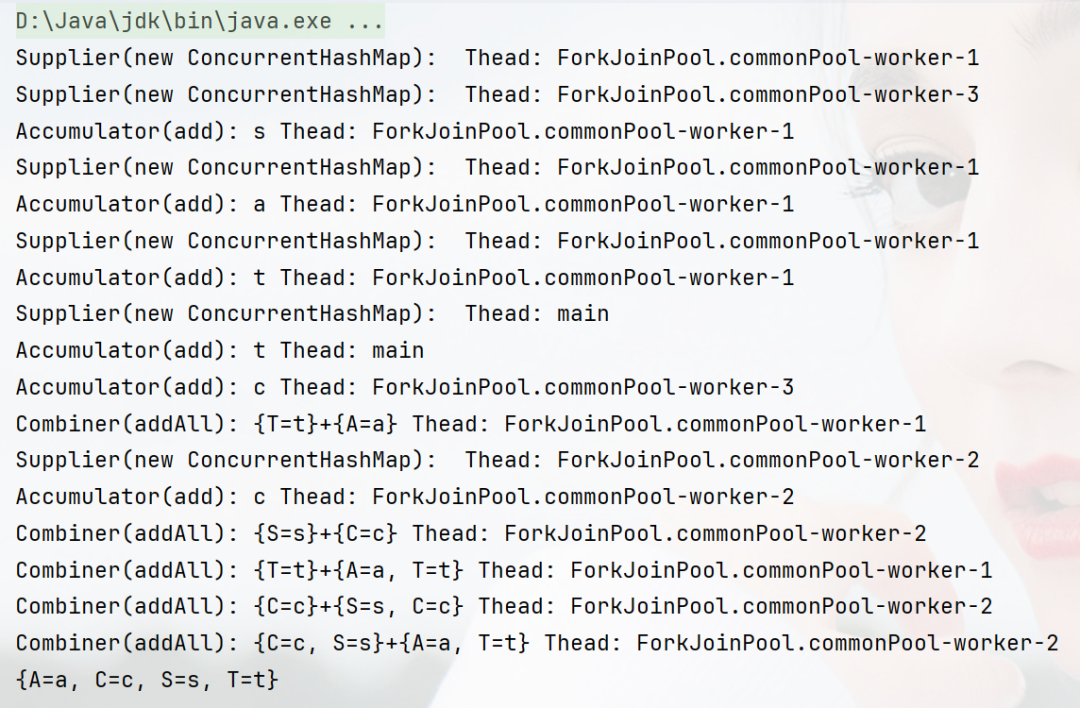
运行后发现Supplier函数仍被多次调用,依旧会按照默认策略在多个线程中创建ConcurrentHashMap实例,这是因为在处理有序流的情况下,如果多个线程并发更新同一个共享的累加器容器,那么元素更新的顺序将变得不确定,为了避免这种情况,框架通常会忽略有序源的CONCURRENT特性,除非同时还指定了UNORDERED特性。
Collector.Characteristics.IDENTITY_FINISH,
Collector.Characteristics.CONCURRENT,
Collector.Characteristics.UNORDERED
运行结果:

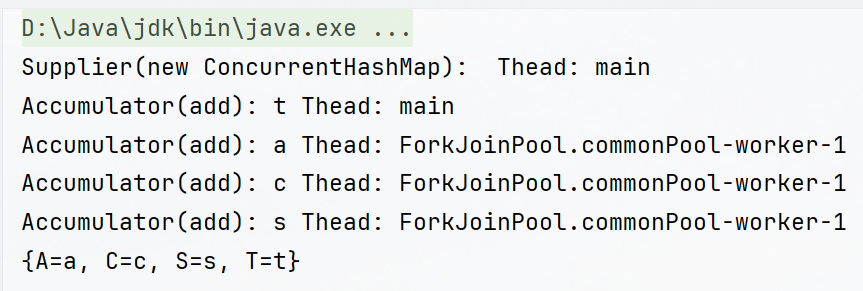
我们可以看到Supplier只执行了一次,只new了一个ConcurrentHashMap,Combiner就没有执行,也就是说这个时候CONCURRENT特性生效了。
我们再把UNORDERED删除,把数据源List改成Set:
package top.caituotuo.intermediate.streamDemo;
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashSet;
import java.util.concurrent.ConcurrentHashMap;
import java.util.stream.Collector;
/**
* author: 测试蔡坨坨 caituotuo.top
* datetime: 2024/6/10 13:15
* function:
*/
public class ParallelStreamsDemo5 {
public static void main(String[] args) {
HashSet<String> set = new HashSet<>();
Collections.addAll(set, "C", "S", "C", "T", "T", "A");
ConcurrentHashMap<String, String> collect = set.parallelStream()
.map(String::toLowerCase)
.collect(Collector.of(
() -> {
System.out.println("Supplier(new ConcurrentHashMap): " + " Thead: " + Thread.currentThread().getName());
return new ConcurrentHashMap<>();
},
(ConcurrentHashMap<String, String> map, String item) -> {
System.out.println("Accumulator(add): " + item + " Thead: " + Thread.currentThread().getName());
map.put(item.toUpperCase(), item.toLowerCase());
},
(ConcurrentHashMap<String, String> left, ConcurrentHashMap<String, String> right) -> {
System.out.println("Combiner(addAll): " + left + "+" + right + " Thead: " + Thread.currentThread().getName());
left.putAll(right);
return left;
},
Collector.Characteristics.IDENTITY_FINISH,
Collector.Characteristics.CONCURRENT
// Collector.Characteristics.UNORDERED
));
System.out.println(collect);
}
}
运行结果:
结果也是只实例化了一个容器,也就是说CONCURRENT生效了,对于无序数据源不需要加UNORDERED。
并行流和顺序流的一致性问题
通过以上示例,我们不难发现,并行流和顺序流的API基本都是通用的。
但是,由于顺序流是单线程的,并行流是多线程的,对于多线程操作,很多时候我们会担心是否会导致与顺序流在结果上的不一致,以及哪些情况可能会引起这种差异。
实际上,对于并行流,通过系统内部精确的执行策略,绝大数的终端操作都能产生与顺序流一致的结果。比如count、min、max、sum、average这些聚合操作并不依赖于元素的出现顺序,只需要将各个子任务的计算结果合并最终结果,系统的策略是先分片计算再合并计算;还有比如anyMatch、allMatch、noneMatch、findFirst、findAny这些短路操作,不仅能够保证结果的一致性,而且在某些情况下还显著提高了执行效率,当一个子任务发现另一个子任务已满足或不满足给定条件时,它将立即终止处理,返回结果,同时通知其它尚未完成的子任务停止执行;即便是涉及distinct、sorted这两个有状态的中间操作,也不影响最终结果的一致性,系统会对每个分片的任务结果进行单独排序或去重,然后在合并结果的过程中再次进行排序或去重处理,以此类推,在进行多次合并处理,完成最终的排序或去重,不过这种方式也会带来额外的性能开销。
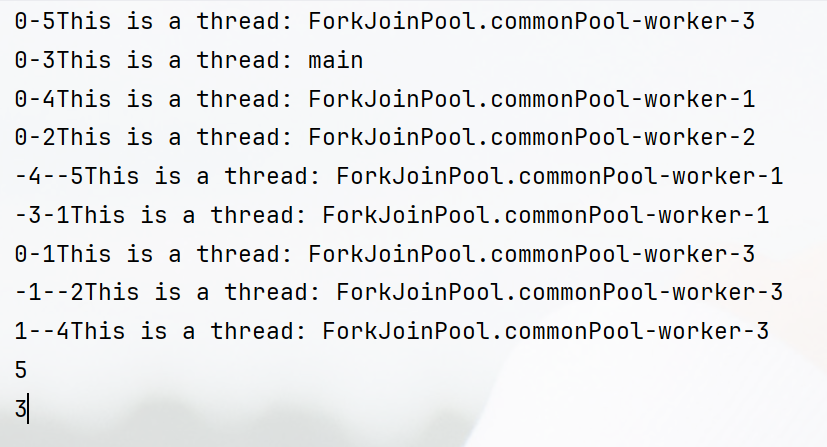
然而,并非所有的操作都能保持一致的结果,比如forEach和某些形式的reduce,reduce操作结果是否一致取决于操作是否关联,比如以下栗子:
package top.caituotuo.intermediate.streamDemo.ParallelStreamsDemo;
import java.util.stream.Stream;
/**
* author: 测试蔡坨坨 caituotuo.top
* datetime: 2024/6/16 14:30
* function: 顺序流和并行流结果一致性问题
*/
public class ParallelStreamDemo6 {
public static void main(String[] args) {
// reduce创建一个累加器,因为加法满足交换律和结合律,即a+b和b+a的结果相同,所以reduce的结果是确定的
Integer sum1 = Stream.of(1, 2, 3, 4, 5).parallel().reduce(0, (a, b) -> a + b);
Integer sum2 = Stream.of(1, 2, 3, 4, 5).reduce(0, Integer::sum);
System.out.println(sum1); // 15
System.out.println(sum2); // 15
// 减法不满足交换律和结合律,所以reduce的结果不一致
Integer sub1 = Stream.of(1, 2, 3, 4, 5).parallel().reduce(0, (a, b) -> a - b);
Integer sub2 = Stream.of(1, 2, 3, 4, 5).reduce(0, (a, b) -> b - a);
System.out.println(sub1); // 5
System.out.println(sub2); // 3
}
}
总而言之,并行流能够充分发挥多核处理的优势,特别处理大数据量和计算密集型任务,然而,对于数据量规模较小或涉及IO操作的情况,顺序流可能会更合适,这是因为并行处理涉及线程管理和协调的额外开销,这些开销可能会抵消甚至超过了并行执行带来的性能提升,所以在是否使用并行流之前,应该先评估任务的性质、数据的规模以及预期的性能收益,以做出最合适的选择。
以上,完。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-06-16,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号