Transformers 4.37 中文文档(十)
Transformers 4.37 中文文档(十)

调试
在多个 GPU 上进行训练可能是一个棘手的任务,无论是遇到安装问题还是 GPU 之间的通信问题。这个调试指南涵盖了一些可能遇到的问题以及如何解决它们。
DeepSpeed CUDA 安装
如果您正在使用 DeepSpeed,您可能已经使用以下命令安装了它。
pip install deepspeedDeepSpeed 编译 CUDA C++代码,当构建需要 CUDA 的 PyTorch 扩展时,这可能是错误的潜在来源。这些错误取决于 CUDA 在您的系统上的安装方式,本节重点介绍了使用* CUDA 10.2 *构建的 PyTorch。
对于任何其他安装问题,请提出问题给 DeepSpeed 团队。
不同的 CUDA 工具包
PyTorch 自带其自己的 CUDA 工具包,但要使用 DeepSpeed 与 PyTorch,您需要在整个系统中安装相同版本的 CUDA。例如,如果您在 Python 环境中安装了cudatoolkit==10.2的 PyTorch,则您还需要在整个系统中安装 CUDA 10.2。如果您的系统中没有安装 CUDA,则应首先安装它。
确切的位置可能因系统而异,但在许多 Unix 系统上,usr/local/cuda-10.2是最常见的位置。当 CUDA 正确设置并添加到您的PATH环境变量时,您可以使用以下命令找到安装位置:
which nvcc多个 CUDA 工具包
您的系统中可能安装了多个 CUDA 工具包。
/usr/local/cuda-10.2
/usr/local/cuda-11.0通常,软件包安装程序会将路径设置为最后安装的版本。如果软件包构建失败,因为找不到正确的 CUDA 版本(尽管它已经在整个系统中安装),则需要配置PATH和LD_LIBRARY_PATH环境变量以指向正确的路径。
首先查看这些环境变量的内容:
echo $PATH
echo $LD_LIBRARY_PATHPATH列出了可执行文件的位置,LD_LIBRARY_PATH列出了共享库的查找位置。较早的条目优先于后续的条目,:用于分隔多个条目。为了告诉构建程序要找到您想要的特定 CUDA 工具包,插入正确的路径以首先列出。此命令在现有值之前而不是覆盖现有值。
# adjust the version and full path if needed
export PATH=/usr/local/cuda-10.2/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-10.2/lib64:$LD_LIBRARY_PATH此外,您还应检查您分配的目录是否实际存在。lib64子目录包含各种 CUDA.so对象(如libcudart.so),虽然您的系统不太可能以不同的名称命名它们,但您应检查实际名称并相应更改。
较旧的 CUDA 版本
有时,较旧的 CUDA 版本可能拒绝与更新的编译器一起构建。例如,如果您有gcc-9但 CUDA 需要gcc-7。通常,安装最新的 CUDA 工具包可以支持更新的编译器。
您还可以安装一个较旧版本的编译器,以及您当前使用的一个(或者可能已经安装,但默认情况下未使用,构建系统无法看到)。要解决此问题,您可以创建一个符号链接,以便构建系统能够看到较旧的编译器。
# adapt the path to your system
sudo ln -s /usr/bin/gcc-7 /usr/local/cuda-10.2/bin/gcc
sudo ln -s /usr/bin/g++-7 /usr/local/cuda-10.2/bin/g++多 GPU 网络问题调试
当使用DistributedDataParallel和多个 GPU 进行训练或推理时,如果遇到进程和/或节点之间的互通问题,您可以使用以下脚本来诊断网络问题。
wget https://raw.githubusercontent.com/huggingface/transformers/main/scripts/distributed/torch-distributed-gpu-test.py例如,要测试 2 个 GPU 如何交互,请执行:
python -m torch.distributed.run --nproc_per_node 2 --nnodes 1 torch-distributed-gpu-test.py如果两个进程都可以相互通信并分配 GPU 内存,每个进程都将打印 OK 状态。
对于更多的 GPU 或节点,请调整脚本中的参数。
您将在诊断脚本中找到更多详细信息,甚至可以了解如何在 SLURM 环境中运行它的方法。
另一个调试级别是添加NCCL_DEBUG=INFO环境变量如下:
NCCL_DEBUG=INFO python -m torch.distributed.run --nproc_per_node 2 --nnodes 1 torch-distributed-gpu-test.py这将输出大量与 NCCL 相关的调试信息,如果发现有问题报告,您可以在网上搜索。或者如果您不确定如何解释输出,可以在 Issue 中分享日志文件。
下溢和溢出检测
此功能目前仅适用于 PyTorch。
对于多 GPU 训练,需要 DDP(torch.distributed.launch)。
此功能可与任何基于nn.Module的模型一起使用。
如果开始出现loss=NaN或模型由于激活或权重中的inf或nan而表现出其他异常行为,需要找出第一个下溢或溢出发生的位置以及导致其发生的原因。幸运的是,您可以通过激活一个特殊模块来轻松实现自动检测。
如果您正在使用 Trainer,您只需要添加:
--debug underflow_overflow除了正常的命令行参数外,在创建 TrainingArguments 对象时,也可以传递debug="underflow_overflow"。
如果您正在使用自己的训练循环或另一个 Trainer,可以通过以下方式实现相同的效果:
from transformers.debug_utils import DebugUnderflowOverflow
debug_overflow = DebugUnderflowOverflow(model)DebugUnderflowOverflow 会在模型中插入钩子,每次前向调用后立即测试输入和输出变量以及相应模块的权重。一旦在激活或权重的至少一个元素中检测到inf或nan,程序将断言并打印类似于这样的报告(这是在 fp16 混合精度下使用google/mt5-small捕获的)。
Detected inf/nan during batch_number=0
Last 21 forward frames:
abs min abs max metadata
encoder.block.1.layer.1.DenseReluDense.dropout Dropout
0.00e+00 2.57e+02 input[0]
0.00e+00 2.85e+02 output [...]
encoder.block.2.layer.0 T5LayerSelfAttention
6.78e-04 3.15e+03 input[0]
2.65e-04 3.42e+03 output[0]
None output[1]
2.25e-01 1.00e+04 output[2]
encoder.block.2.layer.1.layer_norm T5LayerNorm
8.69e-02 4.18e-01 weight
2.65e-04 3.42e+03 input[0]
1.79e-06 4.65e+00 output
encoder.block.2.layer.1.DenseReluDense.wi_0 Linear
2.17e-07 4.50e+00 weight
1.79e-06 4.65e+00 input[0]
2.68e-06 3.70e+01 output
encoder.block.2.layer.1.DenseReluDense.wi_1 Linear
8.08e-07 2.66e+01 weight
1.79e-06 4.65e+00 input[0]
1.27e-04 2.37e+02 output
encoder.block.2.layer.1.DenseReluDense.dropout Dropout
0.00e+00 8.76e+03 input[0]
0.00e+00 9.74e+03 output
encoder.block.2.layer.1.DenseReluDense.wo Linear
1.01e-06 6.44e+00 weight
0.00e+00 9.74e+03 input[0]
3.18e-04 6.27e+04 output
encoder.block.2.layer.1.DenseReluDense T5DenseGatedGeluDense
1.79e-06 4.65e+00 input[0]
3.18e-04 6.27e+04 output
encoder.block.2.layer.1.dropout Dropout
3.18e-04 6.27e+04 input[0]
0.00e+00 inf output示例输出已经为简洁起见进行了修剪。
第二列显示了绝对最大元素的值,因此如果您仔细查看最后几个帧,输入和输出的范围在1e4。因此,当此训练在 fp16 混合精度下进行时,最后一步发生了溢出(因为在fp16下,在inf之前的最大数字是64e3)。为了避免在fp16下发生溢出,激活必须保持远低于1e4,因为1e4 * 1e4 = 1e8,因此任何具有大激活的矩阵乘法都将导致数值溢出条件。
在跟踪的最开始,您可以发现问题发生在哪个批次号(这里Detected inf/nan during batch_number=0表示问题发生在第一个批次)。
每个报告的帧都以声明相应模块的完全限定条目开头。如果我们只看这个帧:
encoder.block.2.layer.1.layer_norm T5LayerNorm
8.69e-02 4.18e-01 weight
2.65e-04 3.42e+03 input[0]
1.79e-06 4.65e+00 output在这里,encoder.block.2.layer.1.layer_norm表示它是编码器第二块的第一层的层归一化。而forward的具体调用是T5LayerNorm。
让我们看一下报告的最后几个帧:
Detected inf/nan during batch_number=0
Last 21 forward frames:
abs min abs max metadata [...]
encoder.block.2.layer.1.DenseReluDense.wi_0 Linear
2.17e-07 4.50e+00 weight
1.79e-06 4.65e+00 input[0]
2.68e-06 3.70e+01 output
encoder.block.2.layer.1.DenseReluDense.wi_1 Linear
8.08e-07 2.66e+01 weight
1.79e-06 4.65e+00 input[0]
1.27e-04 2.37e+02 output
encoder.block.2.layer.1.DenseReluDense.wo Linear
1.01e-06 6.44e+00 weight
0.00e+00 9.74e+03 input[0]
3.18e-04 6.27e+04 output
encoder.block.2.layer.1.DenseReluDense T5DenseGatedGeluDense
1.79e-06 4.65e+00 input[0]
3.18e-04 6.27e+04 output
encoder.block.2.layer.1.dropout Dropout
3.18e-04 6.27e+04 input[0]
0.00e+00 inf output最后一个帧报告了Dropout.forward函数,第一个条目是唯一输入,第二个是唯一输出。您可以看到它是从DenseReluDense类内部的dropout属性调用的。我们可以看到它发生在第二块的第一层,在第一个批次期间。最后,绝对最大的输入元素是6.27e+04,输出也是inf。
您可以在这里看到,T5DenseGatedGeluDense.forward的输出激活结果,其绝对最大值约为 62.7K,非常接近 fp16 的 64K 顶限。在下一个帧中,我们有Dropout,它在将一些元素归零后重新归一化权重,将绝对最大值推到超过 64K,导致溢出(inf)。
正如您所看到的,当数字开始变得非常大时,我们需要查看前面的帧以了解情况。
让我们将报告与models/t5/modeling_t5.py中的代码进行匹配:
class T5DenseGatedGeluDense(nn.Module):
def __init__(self, config):
super().__init__()
self.wi_0 = nn.Linear(config.d_model, config.d_ff, bias=False)
self.wi_1 = nn.Linear(config.d_model, config.d_ff, bias=False)
self.wo = nn.Linear(config.d_ff, config.d_model, bias=False)
self.dropout = nn.Dropout(config.dropout_rate)
self.gelu_act = ACT2FN["gelu_new"]
def forward(self, hidden_states):
hidden_gelu = self.gelu_act(self.wi_0(hidden_states))
hidden_linear = self.wi_1(hidden_states)
hidden_states = hidden_gelu * hidden_linear
hidden_states = self.dropout(hidden_states)
hidden_states = self.wo(hidden_states)
return hidden_states现在很容易看到dropout调用以及所有先前的调用。
由于检测发生在前向挂钩中,这些报告将在每个forward返回后立即打印。
回到完整报告,要对其进行操作并解决问题,我们需要向上移动几帧,找到数字开始增加的地方,并且很可能在这里切换到fp32模式,以便在乘法或求和时数字不会溢出。当然,可能还有其他解决方案。例如,我们可以在将原始forward移入辅助包装器后,暂时关闭amp,如下所示:
def _forward(self, hidden_states):
hidden_gelu = self.gelu_act(self.wi_0(hidden_states))
hidden_linear = self.wi_1(hidden_states)
hidden_states = hidden_gelu * hidden_linear
hidden_states = self.dropout(hidden_states)
hidden_states = self.wo(hidden_states)
return hidden_states
import torch
def forward(self, hidden_states):
if torch.is_autocast_enabled():
with torch.cuda.amp.autocast(enabled=False):
return self._forward(hidden_states)
else:
return self._forward(hidden_states)由于自动检测器仅报告完整帧的输入和输出,一旦您知道要查找的位置,您可能还想分析任何特定forward函数的中间阶段。在这种情况下,您可以使用detect_overflow辅助函数将检测器注入到您想要的位置,例如:
from debug_utils import detect_overflow
class T5LayerFF(nn.Module):
[...]
def forward(self, hidden_states):
forwarded_states = self.layer_norm(hidden_states)
detect_overflow(forwarded_states, "after layer_norm")
forwarded_states = self.DenseReluDense(forwarded_states)
detect_overflow(forwarded_states, "after DenseReluDense")
return hidden_states + self.dropout(forwarded_states)您可以看到我们添加了 2 个这样的内容,现在我们跟踪forwarded_states中是否在中间某处检测到了inf或nan。
实际上,检测器已经报告了这些,因为上面示例中的每个调用都是一个nn.Module,但是假设如果您有一些本地直接计算,这就是您将如何执行的方式。
此外,如果您在自己的代码中实例化调试器,您可以调整从默认值打印的帧数,例如:
from transformers.debug_utils import DebugUnderflowOverflow
debug_overflow = DebugUnderflowOverflow(model, max_frames_to_save=100)特定批次的绝对最小值和最大值跟踪
相同的调试类可以用于关闭下溢/溢出检测功能的每批次跟踪。
假设您想要观察给定批次的每个forward调用的所有成分的绝对最小值和最大值,并且仅对批次 1 和 3 执行此操作。然后,您可以将此类实例化为:
debug_overflow = DebugUnderflowOverflow(model, trace_batch_nums=[1, 3])现在,完整的批次 1 和 3 将使用与下溢/溢出检测器相同的格式进行跟踪。
批次是从 0 开始索引的。
如果您知道程序在某个特定批次号之后开始表现不当,那么您可以直接快进到该区域。以下是这种配置的示例截断输出:
*** Starting batch number=1 ***
abs min abs max metadata
shared Embedding
1.01e-06 7.92e+02 weight
0.00e+00 2.47e+04 input[0]
5.36e-05 7.92e+02 output
[...]
decoder.dropout Dropout
1.60e-07 2.27e+01 input[0]
0.00e+00 2.52e+01 output
decoder T5Stack
not a tensor output
lm_head Linear
1.01e-06 7.92e+02 weight
0.00e+00 1.11e+00 input[0]
6.06e-02 8.39e+01 output
T5ForConditionalGeneration
not a tensor output
*** Starting batch number=3 ***
abs min abs max metadata
shared Embedding
1.01e-06 7.92e+02 weight
0.00e+00 2.78e+04 input[0]
5.36e-05 7.92e+02 output
[...]在这里,您将获得大量的帧转储 - 与您模型中的前向调用数量一样多,因此可能或可能不是您想要的,但有时它可能比普通调试器更容易用于调试目的。例如,如果问题开始在批次号为 150 时发生。因此,您可以为批次 149 和 150 转储跟踪,并比较数字开始发散的地方。
您还可以指定在哪个批次号之后停止训练,例如:
debug_overflow = DebugUnderflowOverflow(model, trace_batch_nums=[1, 3], abort_after_batch_num=3)TensorFlow 模型的 XLA 集成
加速线性代数,简称 XLA,是用于加速 TensorFlow 模型运行时的编译器。来自官方文档:
XLA(加速线性代数)是一个专门用于线性代数的编译器,可以加速 TensorFlow 模型,可能不需要源代码更改。
在 TensorFlow 中使用 XLA 很简单 - 它已经打包在tensorflow库中,并且可以通过任何创建图形函数(例如tf.function)中的jit_compile参数触发。当使用 Keras 方法如fit()和predict()时,您可以通过将jit_compile参数传递给model.compile()来简单启用 XLA。但是,XLA 不仅限于这些方法 - 它还可以用于加速任何任意的tf.function。
🤗 Transformers 中的几个 TensorFlow 方法已经重写为与 XLA 兼容,包括用于模型的文本生成,如GPT2、T5和OPT,以及用于语音处理的模型,如Whisper。
在🤗 Transformers 内部的 TensorFlow 文本生成模型中,加速的确切数量非常依赖于模型,我们注意到速度提升了约 100 倍。本文将解释如何在这些模型中使用 XLA 来获得最大的性能。我们还将提供额外资源的链接,如果您有兴趣了解更多关于基准测试和我们在 XLA 集成背后的设计理念。
使用 XLA 运行 TF 函数
让我们考虑以下 TensorFlow 模型:
import tensorflow as tf
model = tf.keras.Sequential(
[tf.keras.layers.Dense(10, input_shape=(10,), activation="relu"), tf.keras.layers.Dense(5, activation="softmax")]
)上述模型接受维度为(10, )的输入。我们可以使用该模型来运行前向传递,如下所示:
# Generate random inputs for the model.
batch_size = 16
input_vector_dim = 10
random_inputs = tf.random.normal((batch_size, input_vector_dim))
# Run a forward pass.
_ = model(random_inputs)为了使用 XLA 编译函数运行前向传递,我们需要执行以下操作:
xla_fn = tf.function(model, jit_compile=True)
_ = xla_fn(random_inputs)model的默认call()函数用于编译 XLA 图。但是,如果有任何其他模型函数您想要编译成 XLA,也是可能的,例如:
my_xla_fn = tf.function(model.my_xla_fn, jit_compile=True)使用🤗 Transformers 中的 XLA 运行 TF 文本生成模型
要在🤗 Transformers 内启用 XLA 加速生成,您需要安装最新版本的transformers。您可以通过运行以下命令来安装:
pip install transformers --upgrade然后您可以运行以下代码:
import tensorflow as tf
from transformers import AutoTokenizer, TFAutoModelForCausalLM
# Will error if the minimal version of Transformers is not installed.
from transformers.utils import check_min_version
check_min_version("4.21.0")
tokenizer = AutoTokenizer.from_pretrained("gpt2", padding_side="left", pad_token="</s>")
model = TFAutoModelForCausalLM.from_pretrained("gpt2")
input_string = ["TensorFlow is"]
# One line to create an XLA generation function
xla_generate = tf.function(model.generate, jit_compile=True)
tokenized_input = tokenizer(input_string, return_tensors="tf")
generated_tokens = xla_generate(**tokenized_input, num_beams=2)
decoded_text = tokenizer.decode(generated_tokens[0], skip_special_tokens=True)
print(f"Generated -- {decoded_text}")
# Generated -- TensorFlow is an open-source, open-source, distributed-source application # framework for the正如您可以注意到的,在generate()上启用 XLA 只是一行代码。其余代码保持不变。但是,上面代码片段中有一些特定于 XLA 的注意事项。您需要注意这些才能实现 XLA 带来的加速。我们将在下一节中讨论这些。
需要注意的事项
当您首次执行启用 XLA 的函数(如上面的xla_generate())时,它将内部尝试推断计算图,这是耗时的。这个过程被称为“跟踪”。
您可能会注意到生成时间不够快。连续调用xla_generate()(或任何其他启用 XLA 的函数)不需要推断计算图,只要函数的输入遵循最初构建计算图时的相同形状。虽然对于具有固定输入形状的模态(例如图像)这不是问题,但如果您正在处理具有可变输入形状的模态(例如文本),则必须注意。
为了确保xla_generate()始终使用相同的输入形状,您可以在调用分词器时指定padding参数。
import tensorflow as tf
from transformers import AutoTokenizer, TFAutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("gpt2", padding_side="left", pad_token="</s>")
model = TFAutoModelForCausalLM.from_pretrained("gpt2")
input_string = ["TensorFlow is"]
xla_generate = tf.function(model.generate, jit_compile=True)
# Here, we call the tokenizer with padding options.
tokenized_input = tokenizer(input_string, pad_to_multiple_of=8, padding=True, return_tensors="tf")
generated_tokens = xla_generate(**tokenized_input, num_beams=2)
decoded_text = tokenizer.decode(generated_tokens[0], skip_special_tokens=True)
print(f"Generated -- {decoded_text}")这样,您可以确保xla_generate()的输入始终接收与其跟踪时相同形状的输入,从而加快生成时间。您可以使用下面的代码进行验证:
import time
import tensorflow as tf
from transformers import AutoTokenizer, TFAutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("gpt2", padding_side="left", pad_token="</s>")
model = TFAutoModelForCausalLM.from_pretrained("gpt2")
xla_generate = tf.function(model.generate, jit_compile=True)
for input_string in ["TensorFlow is", "TensorFlow is a", "TFLite is a"]:
tokenized_input = tokenizer(input_string, pad_to_multiple_of=8, padding=True, return_tensors="tf")
start = time.time_ns()
generated_tokens = xla_generate(**tokenized_input, num_beams=2)
end = time.time_ns()
print(f"Execution time -- {(end - start) / 1e6:.1f} ms\n")在 Tesla T4 GPU 上,您可以期望输出如下:
Execution time -- 30819.6 ms
Execution time -- 79.0 ms
Execution time -- 78.9 ms第一次调用xla_generate()由于跟踪而耗时,但后续调用速度快得多。请记住,任何时候对生成选项进行更改都会触发重新跟踪,从而导致生成时间变慢。
我们没有在本文档中涵盖🤗 Transformers 提供的所有文本生成选项。我们鼓励您阅读高级用例的文档。
额外资源
在这里,如果您想深入了解🤗 Transformers 中的 XLA 和一般情况下的 XLA,我们为您提供了一些额外资源。
- 这个 Colab 笔记本提供了一个交互式演示,如果您想要尝试 XLA 兼容的编码器-解码器(如T5)和仅解码器(如GPT2)文本生成模型。
- 这篇博客文章提供了 XLA 兼容模型的比较基准概述,以及对 TensorFlow 中 XLA 的友好介绍。
- 这篇博客文章讨论了我们在🤗 Transformers 中为 TensorFlow 模型添加 XLA 支持的设计理念。
- 学习更多关于 XLA 和 TensorFlow 图的推荐帖子:
使用 torch.compile() 优化推理
huggingface.co/docs/transformers/v4.37.2/en/perf_torch_compile
本指南旨在提供有关在🤗 Transformers 中使用 torch.compile() 为计算机视觉模型引入的推理加速的基准测试信息。
torch.compile 的好处
根据模型和 GPU,torch.compile() 在推理过程中可以提高高达 30%的速度。要使用 torch.compile(),只需安装任何版本高于 2.0 的torch。
编译模型需要时间,因此如果您只编译模型一次而不是每次推理时都编译,这将非常有用。要编译您选择的任何计算机视觉模型,请按照以下示例在模型上调用 torch.compile():
from transformers import AutoModelForImageClassification
model = AutoModelForImageClassification.from_pretrained(MODEL_ID).to("cuda")
+ model = torch.compile(model)compile() 有多种编译模式,它们在编译时间和推理开销方面有所不同。max-autotune 比 reduce-overhead 花费更长的时间,但推理速度更快。默认模式在编译速度上最快,但与 reduce-overhead 相比在推理时间上效率不高。在本指南中,我们使用了默认模式。您可以在这里了解更多信息。
我们对torch.compile在不同的计算机视觉模型、任务、硬件类型和批处理大小上进行了基准测试,使用的是torch版本 2.0.1。
基准测试代码
下面您可以找到每个任务的基准测试代码。我们在推理之前对 GPU 进行预热,并使用相同的图像进行 300 次推理的平均时间。
使用 ViT 进行图像分类
import torch
from PIL import Image
import requests
import numpy as np
from transformers import AutoImageProcessor, AutoModelForImageClassification
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
model = AutoModelForImageClassification.from_pretrained("google/vit-base-patch16-224").to("cuda")
model = torch.compile(model)
processed_input = processor(image, return_tensors='pt').to(device="cuda")
with torch.no_grad():
_ = model(**processed_input)使用 DETR 进行目标检测
from transformers import AutoImageProcessor, AutoModelForObjectDetection
processor = AutoImageProcessor.from_pretrained("facebook/detr-resnet-50")
model = AutoModelForObjectDetection.from_pretrained("facebook/detr-resnet-50").to("cuda")
model = torch.compile(model)
texts = ["a photo of a cat", "a photo of a dog"]
inputs = processor(text=texts, images=image, return_tensors="pt").to("cuda")
with torch.no_grad():
_ = model(**inputs)使用 Segformer 进行图像分割
from transformers import SegformerImageProcessor, SegformerForSemanticSegmentation
processor = SegformerImageProcessor.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512")
model = SegformerForSemanticSegmentation.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512").to("cuda")
model = torch.compile(model)
seg_inputs = processor(images=image, return_tensors="pt").to("cuda")
with torch.no_grad():
_ = model(**seg_inputs)下面您可以找到我们进行基准测试的模型列表。
图像分类
- google/vit-base-patch16-224
- microsoft/beit-base-patch16-224-pt22k-ft22k
- facebook/convnext-large-224
- microsoft/resnet-50
图像分割
- nvidia/segformer-b0-finetuned-ade-512-512
- facebook/mask2former-swin-tiny-coco-panoptic
- facebook/maskformer-swin-base-ade
- google/deeplabv3_mobilenet_v2_1.0_513
目标检测
下面您可以找到使用和不使用 torch.compile() 的推理持续时间的可视化,以及每个模型在不同硬件和批处理大小下的百分比改进。
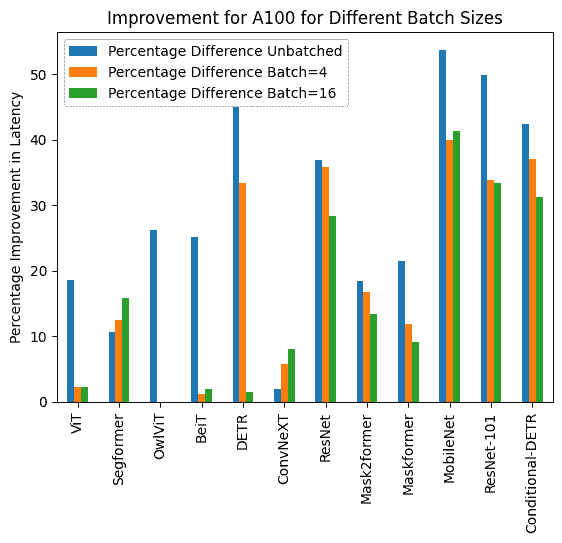
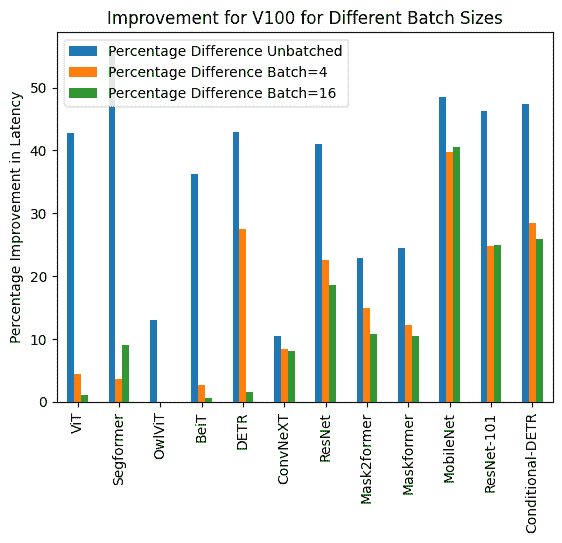
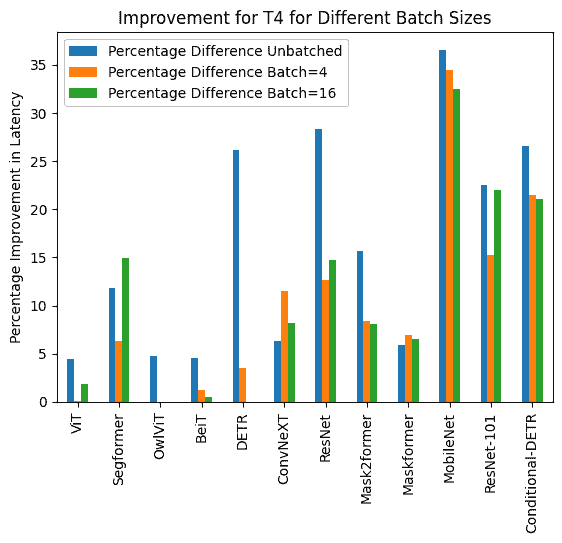
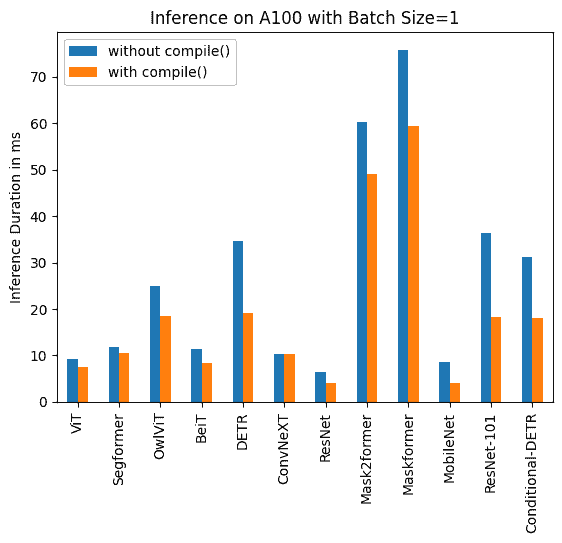
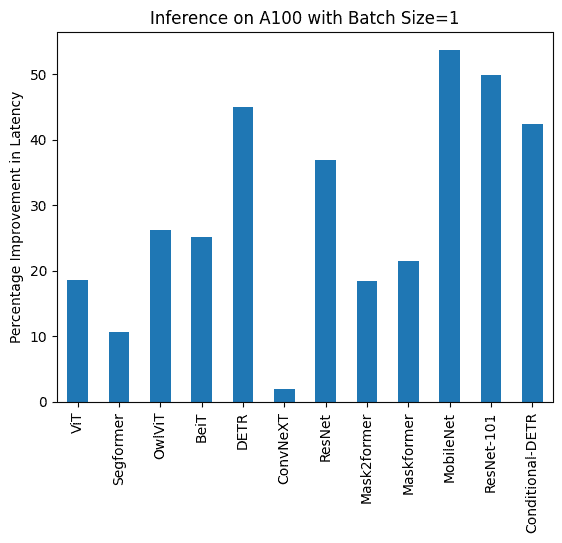
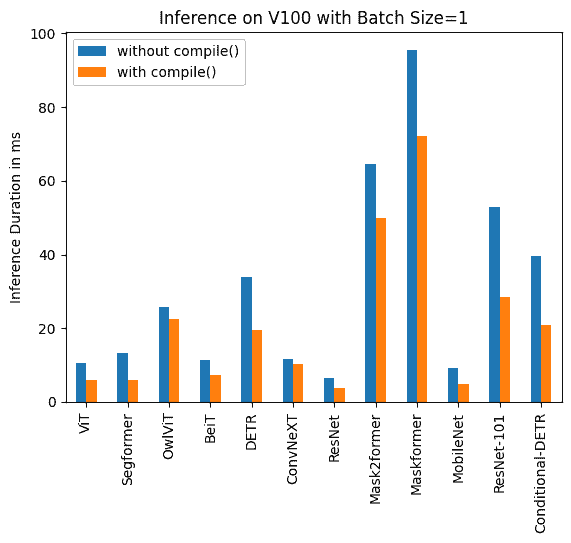
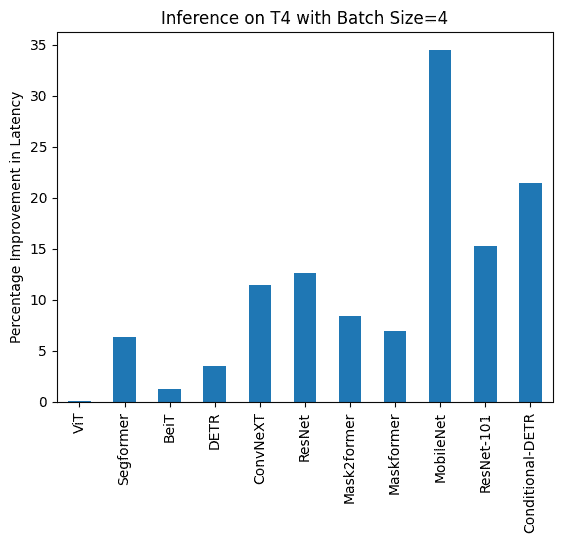
下面您可以找到每个模型使用和不使用 compile() 的推理持续时间(毫秒)。请注意,OwlViT 在较大批处理大小时会导致 OOM。
A100(批处理大小:1)
任务/模型 | torch 2.0 - 无编译 | torch 2.0 - 编译 |
|---|---|---|
图像分类/ViT | 9.325 | 7.584 |
图像分割/Segformer | 11.759 | 10.500 |
目标检测/OwlViT | 24.978 | 18.420 |
图像分类/BeiT | 11.282 | 8.448 |
目标检测/DETR | 34.619 | 19.040 |
图像分类/ConvNeXT | 10.410 | 10.208 |
图像分类/ResNet | 6.531 | 4.124 |
图像分割/Mask2former | 60.188 | 49.117 |
图像分割/Maskformer | 75.764 | 59.487 |
图像分割/MobileNet | 8.583 | 3.974 |
目标检测/Resnet-101 | 36.276 | 18.197 |
目标检测/Conditional-DETR | 31.219 | 17.993 |
A100(批量大小:4)
任务/模型 | torch 2.0 - 无编译 | torch 2.0 - 编译 |
|---|---|---|
图像分类/ViT | 14.832 | 14.499 |
图像分割/Segformer | 18.838 | 16.476 |
图像分类/BeiT | 13.205 | 13.048 |
目标检测/DETR | 48.657 | 32.418 |
图像分类/ConvNeXT | 22.940 | 21.631 |
图像分类/ResNet | 6.657 | 4.268 |
图像分割/Mask2former | 74.277 | 61.781 |
图像分割/Maskformer | 180.700 | 159.116 |
图像分割/MobileNet | 14.174 | 8.515 |
目标检测/Resnet-101 | 68.101 | 44.998 |
目标检测/Conditional-DETR | 56.470 | 35.552 |
A100(批量大小:16)
任务/模型 | torch 2.0 - 无编译 | torch 2.0 - 编译 |
|---|---|---|
图像分类/ViT | 40.944 | 40.010 |
图像分割/Segformer | 37.005 | 31.144 |
图像分类/BeiT | 41.854 | 41.048 |
目标检测/DETR | 164.382 | 161.902 |
图像分类/ConvNeXT | 82.258 | 75.561 |
图像分类/ResNet | 7.018 | 5.024 |
图像分割/Mask2former | 178.945 | 154.814 |
图像分割/Maskformer | 638.570 | 579.826 |
图像分割/MobileNet | 51.693 | 30.310 |
目标检测/Resnet-101 | 232.887 | 155.021 |
目标检测/Conditional-DETR | 180.491 | 124.032 |
V100(批量大小:1)
任务/模型 | torch 2.0 - 无编译 | torch 2.0 - 编译 |
|---|---|---|
图像分类/ViT | 10.495 | 6.00 |
图像分割/Segformer | 13.321 | 5.862 |
目标检测/OwlViT | 25.769 | 22.395 |
图像分类/BeiT | 11.347 | 7.234 |
目标检测/DETR | 33.951 | 19.388 |
图像分类/ConvNeXT | 11.623 | 10.412 |
图像分类/ResNet | 6.484 | 3.820 |
图像分割/Mask2former | 64.640 | 49.873 |
图像分割/Maskformer | 95.532 | 72.207 |
图像分割/MobileNet | 9.217 | 4.753 |
目标检测/Resnet-101 | 52.818 | 28.367 |
目标检测/Conditional-DETR | 39.512 | 20.816 |
V100(批量大小:4)
任务/模型 | torch 2.0 - 无编译 | torch 2.0 - 编译 |
|---|---|---|
图像分类/ViT | 15.181 | 14.501 |
图像分割/Segformer | 16.787 | 16.188 |
图像分类/BeiT | 15.171 | 14.753 |
目标检测/DETR | 88.529 | 64.195 |
图像分类/ConvNeXT | 29.574 | 27.085 |
图像分类/ResNet | 6.109 | 4.731 |
图像分割/Mask2former | 90.402 | 76.926 |
图像分割/Maskformer | 234.261 | 205.456 |
图像分割/MobileNet | 24.623 | 14.816 |
目标检测/Resnet-101 | 134.672 | 101.304 |
目标检测/Conditional-DETR | 97.464 | 69.739 |
V100(批量大小:16)
任务/模型 | torch 2.0 - 无编译 | torch 2.0 - 编译 |
|---|---|---|
图像分类/ViT | 52.209 | 51.633 |
图像分割/Segformer | 61.013 | 55.499 |
图像分类/BeiT | 53.938 | 53.581 |
目标检测/DETR | OOM | OOM |
图像分类/ConvNeXT | 109.682 | 100.771 |
图像分类/ResNet | 14.857 | 12.089 |
图像分割/Mask2former | 249.605 | 222.801 |
图像分割/Maskformer | 831.142 | 743.645 |
图像分割/MobileNet | 93.129 | 55.365 |
目标检测/Resnet-101 | 482.425 | 361.843 |
目标检测/Conditional-DETR | 344.661 | 255.298 |
T4(批量大小:1)
任务/模型 | torch 2.0 - 无编译 | torch 2.0 - 编译 |
|---|---|---|
图像分类/ViT | 16.520 | 15.786 |
图像分割/Segformer | 16.116 | 14.205 |
目标检测/OwlViT | 53.634 | 51.105 |
图像分类/BeiT | 16.464 | 15.710 |
目标检测/DETR | 73.100 | 53.99 |
图像分类/ConvNeXT | 32.932 | 30.845 |
图像分类/ResNet | 6.031 | 4.321 |
图像分割/Mask2former | 79.192 | 66.815 |
图像分割/Maskformer | 200.026 | 188.268 |
图像分割/MobileNet | 18.908 | 11.997 |
目标检测/Resnet-101 | 106.622 | 82.566 |
目标检测/Conditional-DETR | 77.594 | 56.984 |
T4(批量大小:4)
任务/模型 | torch 2.0 - 无编译 | torch 2.0 - 编译 |
|---|---|---|
图像分类/ViT | 43.653 | 43.626 |
图像分割/Segformer | 45.327 | 42.445 |
图像分类/BeiT | 52.007 | 51.354 |
目标检测/DETR | 277.850 | 268.003 |
图像分类/ConvNeXT | 119.259 | 105.580 |
图像分类/ResNet | 13.039 | 11.388 |
图像分割/Mask2former | 201.540 | 184.670 |
图像分割/Maskformer | 764.052 | 711.280 |
图像分割/MobileNet | 74.289 | 48.677 |
目标检测/Resnet-101 | 421.859 | 357.614 |
目标检测/Conditional-DETR | 289.002 | 226.945 |
T4(批量大小:16)
任务/模型 | torch 2.0 - 无编译 | torch 2.0 - 编译 |
|---|---|---|
图像分类/ViT | 163.914 | 160.907 |
图像分割/Segformer | 192.412 | 163.620 |
图像分类/BeiT | 188.978 | 187.976 |
目标检测/DETR | OOM | OOM |
图像分类/ConvNeXT | 422.886 | 388.078 |
图像分类/ResNet | 44.114 | 37.604 |
图像分割/Mask2former | 756.337 | 695.291 |
图像分割/Maskformer | 2842.940 | 2656.88 |
图像分割/MobileNet | 299.003 | 201.942 |
目标检测/Resnet-101 | 1619.505 | 1262.758 |
目标检测/Conditional-DETR | 1137.513 | 897.390 |
PyTorch Nightly
我们还在 PyTorch nightly(2.1.0dev,可以在这里找到)上进行了基准测试,并观察到未编译和编译模型的延迟均有所改善。
A100
任务/模型 | 批量大小 | torch 2.0 - 无编译 | torch 2.0 - 编译 |
|---|---|---|---|
图像分类/BeiT | 未分批 | 12.462 | 6.954 |
图像分类/BeiT | 4 | 14.109 | 12.851 |
图像分类/BeiT | 16 | 42.179 | 42.147 |
目标检测/DETR | 未分批 | 30.484 | 15.221 |
目标检测/DETR | 4 | 46.816 | 30.942 |
目标检测/DETR | 16 | 163.749 | 163.706 |
T4
任务/模型 | 批量大小 | torch 2.0 - 无编译 | torch 2.0 - 编译 |
|---|---|---|---|
图像分类/BeiT | 未分批 | 14.408 | 14.052 |
图像分类/BeiT | 4 | 47.381 | 46.604 |
图像分类/BeiT | 16 | 42.179 | 42.147 |
目标检测/DETR | 未分批 | 68.382 | 53.481 |
目标检测/DETR | 4 | 269.615 | 204.785 |
目标检测/DETR | 16 | OOM | OOM |
V100
任务/模型 | 批量大小 | torch 2.0 - 无编译 | torch 2.0 - 编译 |
|---|---|---|---|
图像分类/BeiT | 未分批 | 13.477 | 7.926 |
图像分类/BeiT | 4 | 15.103 | 14.378 |
图像分类/BeiT | 16 | 52.517 | 51.691 |
目标检测/DETR | 未分批 | 28.706 | 19.077 |
目标检测/DETR | 4 | 88.402 | 62.949 |
目标检测/DETR | 16 | OOM | OOM |
减少开销
我们在夜间对 A100 和 T4 进行了reduce-overhead编译模式的基准测试。
A100
任务/模型 | 批量大小 | torch 2.0 - 无编译 | torch 2.0 - 编译 |
|---|---|---|---|
图像分类/ConvNeXT | 未分批 | 11.758 | 7.335 |
图像分类/ConvNeXT | 4 | 23.171 | 21.490 |
图像分类/ResNet | 未分批 | 7.435 | 3.801 |
图像分类/ResNet | 4 | 7.261 | 2.187 |
目标检测/条件 DETR | 未批处理 | 32.823 | 11.627 |
目标检测/条件 DETR | 4 | 50.622 | 33.831 |
图像分割/MobileNet | 未批处理 | 9.869 | 4.244 |
图像分割/MobileNet | 4 | 14.385 | 7.946 |
T4
任务/模型 | 批处理大小 | torch 2.0 - 无编译 | torch 2.0 - 编译 |
|---|---|---|---|
图像分类/ConvNeXT | 未批处理 | 32.137 | 31.84 |
图像分类/ConvNeXT | 4 | 120.944 | 110.209 |
图像分类/ResNet | 未批处理 | 9.761 | 7.698 |
图像分类/ResNet | 4 | 15.215 | 13.871 |
目标检测/条件 DETR | 未批处理 | 72.150 | 57.660 |
目标检测/条件 DETR | 4 | 301.494 | 247.543 |
图像分割/MobileNet | 未批处理 | 22.266 | 19.339 |
图像分割/MobileNet | 4 | 78.311 | 50.983 |
贡献
贡献给🤗 Transformers
欢迎每个人贡献,我们重视每个人的贡献。代码贡献并不是帮助社区的唯一方式。回答问题,帮助他人,改进文档也是非常有价值的。
如果您帮助传播消息,也会对我们有所帮助!在博客文章中提到这个令人惊叹的项目所可能实现的项目,每次它帮助您时在 Twitter 上大声疾呼,或者简单地⭐️这个存储库以表示感谢。
无论您选择如何贡献,请注意并尊重我们的行为准则。
本指南受到了令人惊叹的scikit-learn 贡献指南的启发。
贡献的方式
有几种方式可以为🤗 Transformers 做出贡献:
- 修复现有代码中的未解决问题。
- 提交与错误或期望的新功能相关的问题。
- 实现新模型。
- 为示例或文档做出贡献。
如果您不知道从哪里开始,有一个特殊的Good First Issue列表。它将为您提供一份友好的初学者的问题列表,并帮助您开始为开源项目做出贡献。只需在您想要处理的问题上发表评论即可。
对于稍微具有挑战性的事情,您还可以查看Good Second Issue列表。总的来说,如果您觉得自己知道在做什么,就去做吧,我们会帮助您实现目标!🚀
所有贡献对社区都同样有价值。🥰
修复未解决的问题
如果您注意到现有代码中存在问题并有解决方案,请随时开始贡献并打开一个拉取请求!
提交与错误相关的问题或功能请求
在提交与错误相关的问题或功能请求时,请尽力遵循这些准则。这将使我们更容易快速回复您并提供良好的反馈。
您发现了一个错误吗?
🤗 Transformers 库之所以强大可靠,要感谢那些报告他们遇到问题的用户。
在报告问题之前,我们真的很感激您确保错误尚未被报告(在 GitHub 的问题下使用搜索栏)。您的问题也应与库本身中的错误有关,而不是您的代码。如果您不确定错误是在您的代码中还是在库中,请先在论坛中询问。这有助于我们更快地回应与库相关的问题,而不是一般问题。
一旦确认错误尚未被报告,请在您的问题中包含以下信息,以便我们能够快速解决:
- 您的操作系统类型和版本以及Python,PyTorch和TensorFlow版本(如果适用)。
- 一个简短的、自包含的代码片段,使我们能够在不到 30 秒内重现错误。
- 完整的异常跟踪信息。
- 附加任何其他可能有助于的信息,如截图。
要自动获取操作系统和软件版本,请运行以下命令:
transformers-cli env您还可以从存储库的根目录运行相同的命令:
python src/transformers/commands/transformers_cli.py env您想要一个新功能吗?
如果您希望在🤗 Transformers 中看到一个新功能,请打开一个问题并描述:
- 这个功能背后的动机是什么?它是否与库中的问题或挫折有关?它是否与您需要的项目相关的功能?它是否是您正在开发的东西,您认为它可能有益于社区? 无论是什么,我们都很乐意听到!
- 尽可能详细地描述您请求的功能。您能告诉我们的越多,我们就能更好地帮助您。
- 提供一个演示功能使用的代码片段。
- 如果功能与论文相关,请包含链接。
如果您的问题写得很好,那么在您创建问题时我们已经完成了 80%的工作。
我们已经添加了模板来帮助您开始解决问题。
您想要实现一个新模型吗?
新模型不断发布,如果您想实现新模型,请提供以下信息
- 模型的简短描述和论文链接。
- 如果实现是开源的,请提供实现的链接。
- 如果模型权重可用,请提供模型权重的链接。
如果您愿意贡献模型,请告诉我们,这样我们就可以帮助您将其添加到🤗 Transformers 中!
我们已经添加了一个详细指南和模板来帮助您开始添加新模型,我们还有一个更详细的指南,介绍了如何向🤗 Transformers 添加模型。
您想添加文档吗?
我们始终在寻找使文档更清晰和准确的改进。请告诉我们如何改进文档,例如拼写错误和任何缺失、不清晰或不准确的内容。如果您有兴趣,我们将很乐意进行更改或帮助您做出贡献!
有关如何生成、构建和编写文档的更多详细信息,请查看文档README。
创建一个 Pull Request
在编写任何代码之前,我们强烈建议您搜索现有的 PR 或问题,以确保没有人已经在处理相同的事情。如果您不确定,最好打开一个问题以获得一些反馈。
您需要基本的git熟练技能才能为🤗 Transformers 做出贡献。虽然git不是最容易使用的工具,但它有最详尽的手册。在 shell 中键入git --help并享受!如果您更喜欢书籍,Pro Git是一个非常好的参考。
您需要**Python 3.8)**或更高版本才能为🤗 Transformers 做出贡献。请按照以下步骤开始贡献:
通过点击存储库页面上的**Fork**按钮来 fork 存储库。这将在您的 GitHub 用户帐户下创建代码副本。
将您的 fork 克隆到本地磁盘,并将基本存储库添加为远程:
git clone git@github.com:<your Github handle>/transformers.git
cd transformers
git remote add upstream https://github.com/huggingface/transformers.git创建一个新分支来保存您的开发更改:
git checkout -b a-descriptive-name-for-my-changes🚨 不要在main分支上工作!
在虚拟环境中运行以下命令设置开发环境:
pip install -e ".[dev]"如果🤗 Transformers 已经安装在虚拟环境中,请在重新安装时使用pip uninstall transformers将其删除,然后使用-e标志以可编辑模式重新安装。
根据您的操作系统,由于 Transformers 的可选依赖项数量正在增加,您可能会在此命令中遇到失败。如果是这种情况,请确保安装您正在使用的深度学习框架(PyTorch、TensorFlow 和/或 Flax),然后执行:
pip install -e ".[quality]"这对大多数用例来说应该足够了。
在您的分支中开发功能。
在编写代码时,您应确保测试套件通过。运行受您更改影响的测试如下:
pytest tests/<TEST_TO_RUN>.py有关测试的更多信息,请查看Testing指南。
🤗 Transformers 依赖于black和ruff来一致格式化其源代码。在进行更改后,应用自动样式更正和代码验证,这些更改无法一次性自动完成:
make fixup此目标还经过优化,仅适用于您正在处理的 PR 修改的文件。
如果您更喜欢逐个运行检查,以下命令适用于样式更正:
make style🤗 Transformers 还使用ruff和一些自定义脚本来检查编码错误。质量控制由 CI 运行,但您也可以使用相同的检查运行:
make quality最后,我们有很多脚本,以确保在添加新模型时不会忘记更新一些文件。您可以使用以下命令运行这些脚本:
make repo-consistency要了解更多关于这些检查以及如何解决其中任何问题的信息,请查看拉取请求上的检查指南。
如果您修改了docs/source目录下的文档,请确保文档仍然可以构建。当您打开拉取请求时,此检查也将在 CI 中运行。要运行本地检查,请确保安装文档生成器:
pip install ".[docs]"从存储库的根目录运行以下命令:
doc-builder build transformers docs/source/en --build_dir ~/tmp/test-build这将在~/tmp/test-build文件夹中构建文档,您可以使用您喜欢的编辑器检查生成的 Markdown 文件。您还可以在打开拉取请求时在 GitHub 上预览文档。
当您对更改满意时,请使用git add添加更改的文件,并使用git commit在本地记录您的更改:
git add modified_file.py
git commit请记得写良好的提交消息,以清楚地传达您所做的更改!
为了使您的代码副本与原始存储库保持最新,请在打开拉取请求之前或维护者要求时,在upstream/branch上对您的分支进行变基:
git fetch upstream
git rebase upstream/main将更改推送到您的分支:
git push -u origin a-descriptive-name-for-my-changes如果您已经打开了一个拉取请求,您需要使用--force标志进行强制推送。否则,如果拉取请求尚未打开,您可以正常推送您的更改。
现在,您可以转到 GitHub 上存储库的分支,并单击拉取请求以打开拉取请求。确保您在下面的检查列表上勾选所有框。当您准备好时,您可以将更改发送给项目维护者进行审查。
如果维护者要求更改,那没关系,我们的核心贡献者也会遇到这种情况!这样每个人都可以在拉取请求中看到更改,您可以在本地分支上工作并将更改推送到您的分支。它们将自动出现在拉取请求中。
拉取请求检查列表
☐ 拉取请求标题应总结您的贡献。
☐ 如果您的拉取请求解决了一个问题,请在拉取请求描述中提及问题编号,以确保它们链接在一起(并且查看问题的人知道您正在处理它)。
☐ 要指示正在进行的工作,请在标题前加上[WIP]。这对于避免重复工作以及将其与准备合并的 PR 区分开很有用。
☐ 确保现有测试通过。
☐ 如果要添加新功能,请为其添加测试。
- 如果要添加新模型,请确保使用
ModelTester.all_model_classes = (MyModel, MyModelWithLMHead,...)来触发常见测试。 - 如果要添加新的
@slow测试,请确保使用RUN_SLOW=1 python -m pytest tests/models/my_new_model/test_my_new_model.py来运行它们。 - 如果要添加新的分词器,请编写测试并确保
RUN_SLOW=1 python -m pytest tests/models/{your_model_name}/test_tokenization_{your_model_name}.py通过。 - CircleCI 不运行慢速测试,但 GitHub Actions 每晚都会运行!
☐ 所有公共方法必须具有信息性的文档字符串(请参阅modeling_bert.py作为示例)。
☐ 由于存储库正在迅速增长,请不要添加任何图像、视频和其他非文本文件,这些文件会显著增加存储库的大小。相反,请使用 Hub 存储库,例如 hf-internal-testing 来托管这些文件,并通过 URL 引用它们。我们建议将与文档相关的图像放在以下存储库中:huggingface/documentation-images。您可以在此数据集存储库上打开一个 PR,并请求 Hugging Face 成员合并它。
有关在拉取请求上运行的检查的更多信息,请查看我们的 拉取请求上的检查 指南。
测试
包含了一个广泛的测试套件,用于测试库的行为和几个示例。库测试可以在 tests 文件夹中找到,示例测试可以在 examples 文件夹中找到。
我们喜欢 pytest 和 pytest-xdist,因为它更快。从存储库的根目录开始,指定一个子文件夹路径或测试文件来运行测试。
python -m pytest -n auto --dist=loadfile -s -v ./tests/models/my_new_model同样,对于 examples 目录,指定一个子文件夹路径或测试文件来运行测试。例如,以下命令测试 PyTorch examples 目录中的文本分类子文件夹:
pip install -r examples/xxx/requirements.txt # only needed the first time
python -m pytest -n auto --dist=loadfile -s -v ./examples/pytorch/text-classification实际上,这就是我们实现 make test 和 make test-examples 命令的方式(不包括 pip install)!
您还可以指定一小组较小的测试,以便仅测试您正在处理的功能。
默认情况下,慢测试会被跳过,但您可以将 RUN_SLOW 环境变量设置为 yes 来运行它们。这将下载许多千兆字节的模型,因此请确保您有足够的磁盘空间、良好的互联网连接或足够的耐心!
记得指定一个子文件夹路径或测试文件来运行测试。否则,您将运行 tests 或 examples 文件夹中的所有测试,这将花费很长时间!
RUN_SLOW=yes python -m pytest -n auto --dist=loadfile -s -v ./tests/models/my_new_model
RUN_SLOW=yes python -m pytest -n auto --dist=loadfile -s -v ./examples/pytorch/text-classification与慢测试类似,还有其他环境变量可用,这些环境变量在测试期间默认未启用:
-
RUN_CUSTOM_TOKENIZERS: 启用自定义分词器的测试。 -
RUN_PT_FLAX_CROSS_TESTS: 启用 PyTorch + Flax 集成的测试。 -
RUN_PT_TF_CROSS_TESTS: 启用 TensorFlow + PyTorch 集成的测试。
更多环境变量和其他信息可以在 testing_utils.py 中找到。
🤗 Transformers 仅使用 pytest 作为测试运行器。它不在测试套件本身中使用任何 pytest 特定功能。
这意味着 unittest 得到了完全支持。以下是如何使用 unittest 运行测试的方法:
python -m unittest discover -s tests -t . -v
python -m unittest discover -s examples -t examples -v样式指南
对于文档字符串,🤗 Transformers 遵循 Google Python Style Guide。查看我们的 文档编写指南 获取更多信息。
在 Windows 上开发
在 Windows 上(除非您在 Windows Subsystem for Linux 或 WSL 中工作),您需要配置 git 将 Windows 的 CRLF 行结束符转换为 Linux 的 LF 行结束符:
git config core.autocrlf input在 Windows 上运行 make 命令的一种方法是使用 MSYS2:
- 下载 MSYS2,我们假设它安装在
C:\msys64中。 - 打开命令行
C:\msys64\msys2.exe(应该可以从开始菜单中找到)。 - 在 shell 中运行:
pacman -Syu并使用pacman -S make安装make。 - 将
C:\msys64\usr\bin添加到您的 PATH 环境变量中。
您现在可以从任何终端(Powershell、cmd.exe 等)使用 make 了!🎉
将派生存储库与上游主存储库同步(Hugging Face 存储库)
更新分叉存储库的主分支时,请按照以下步骤操作,以避免向上游存储库发送引用注释并向参与这些拉取请求的开发人员发送不必要的通知。
- 尽量避免使用分支和拉取请求与上游同步。而是直接合并到分叉主分支。
- 如果绝对必要,使用以下步骤在检出分支后:
git checkout -b your-branch-for-syncing
git pull --squash --no-commit upstream main
git commit -m '<your message without GitHub references>'
git push --set-upstream origin your-branch-for-syncing如何将模型添加到🤗 Transformers?
原文链接:
huggingface.co/docs/transformers/v4.37.2/en/add_new_model
🤗 Transformers 库通常能够通过社区贡献者提供新模型。但这可能是一个具有挑战性的项目,需要深入了解🤗 Transformers 库和要实现的模型。在 Hugging Face,我们正在努力赋予更多社区成员积极添加模型的能力,并为您提供这个指南,以指导您添加一个 PyTorch 模型(确保您已经安装了 PyTorch)。
如果您有兴趣实现一个 TensorFlow 模型,请查看如何将🤗 Transformers 模型转换为 TensorFlow 指南!
沿途,您将:
- 了解开源最佳实践
- 了解最受欢迎的深度学习库背后的设计原则
- 学习如何有效地测试大型模型
- 学习如何集成 Python 实用程序,如
black、ruff和make fix-copies,以确保代码整洁可读
Hugging Face 团队成员将随时为您提供帮助,因此您永远不会孤单。🤗 ❤️
要开始,请为您想在🤗 Transformers 中看到的模型打开一个新模型添加问题。如果您对贡献特定模型不是特别挑剔,您可以按New model label进行筛选,看看是否有任何未认领的模型请求并开始处理。
一旦您打开了一个新模型请求,如果您还不熟悉🤗 Transformers,第一步是熟悉它!
🤗 Transformers 的概述
首先,您应该对🤗 Transformers 有一个总体了解。🤗 Transformers 是一个非常主观的库,因此您可能不同意一些库的理念或设计选择。然而,根据我们的经验,我们发现库的基本设计选择和理念对于有效扩展🤗 Transformers 并保持维护成本在合理水平上至关重要。
更好地了解库的一个很好的起点是阅读我们哲学的文档。由于我们的工作方式,有一些选择我们试图应用于所有模型:
- 通常更喜欢组合而不是抽象
- 复制代码并不总是坏事,如果它极大地提高了模型的可读性或可访问性
- 模型文件尽可能自包含,这样当您阅读特定模型的代码时,理想情况下只需查看相应的
modeling_....py文件。
在我们看来,库的代码不仅仅是提供产品的手段,例如使用 BERT 进行推断的能力,而且也是我们想要改进的产品本身。因此,当添加一个模型时,用户不仅是将使用您的模型的人,还有所有将阅读、尝试理解和可能调整您的代码的人。
有了这个想法,让我们更深入地了解一下一般的库设计。
模型概述
要成功添加一个模型,重要的是要理解您的模型与其配置、PreTrainedModel 和 PretrainedConfig 之间的交互。为了举例说明,我们将要添加到🤗 Transformers 的模型称为BrandNewBert。
让我们看一看:
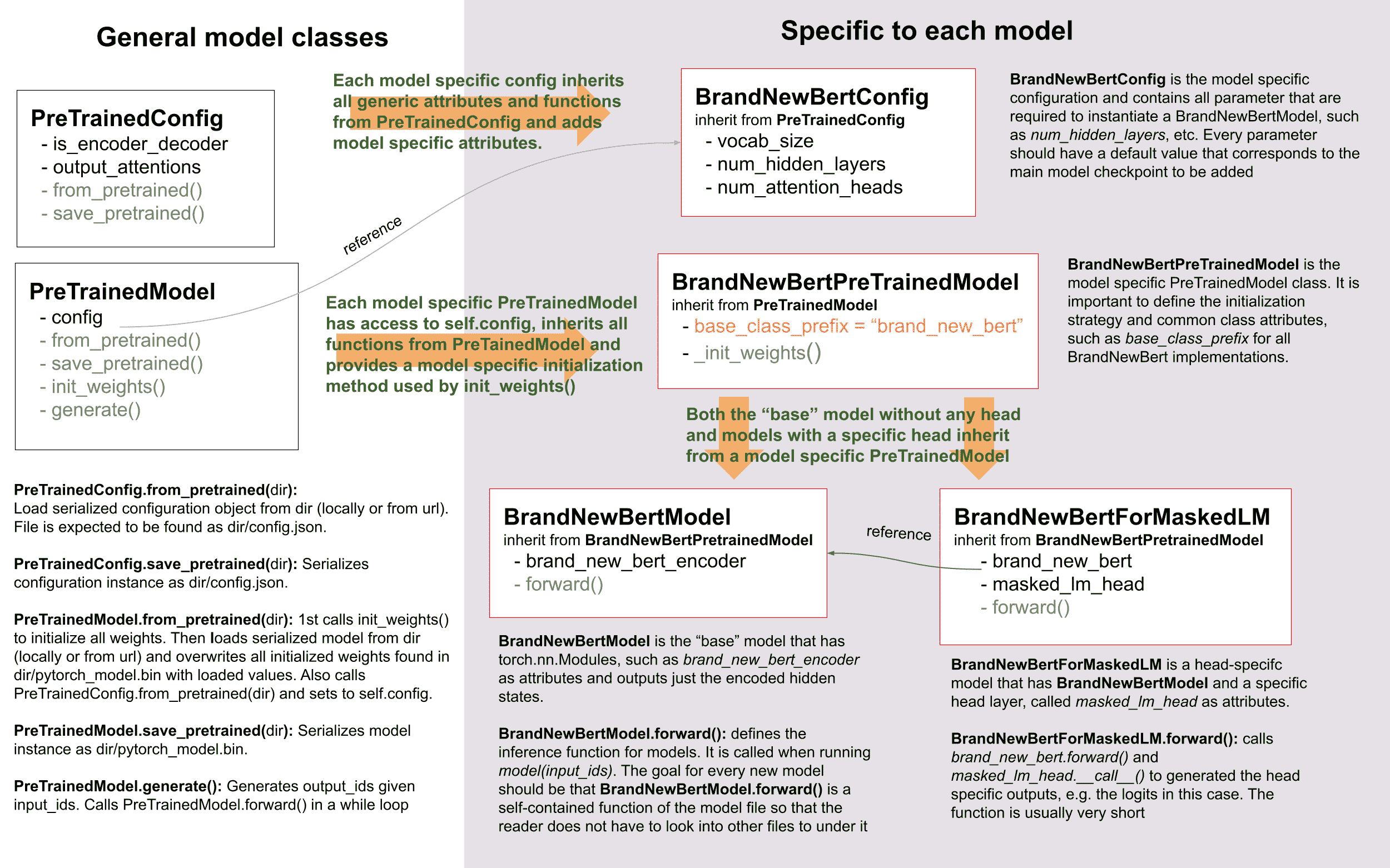
正如您所看到的,我们在🤗 Transformers 中确实使用了继承,但我们将抽象级别保持到绝对最低限度。库中任何模型的抽象级别永远不会超过两个。BrandNewBertModel继承自BrandNewBertPreTrainedModel,后者又继承自 PreTrainedModel,就是这样。一般规则是,我们希望确保新模型仅依赖于 PreTrainedModel。自动提供给每个新模型的重要功能是 from_pretrained()和 save_pretrained(),用于序列化和反序列化。所有其他重要功能,如BrandNewBertModel.forward,应完全在新的modeling_brand_new_bert.py脚本中定义。接下来,我们要确保具有特定头层的模型,如BrandNewBertForMaskedLM,不继承自BrandNewBertModel,而是使用BrandNewBertModel作为可以在其前向传递中调用的组件,以保持抽象级别低。每个新模型都需要一个配置类,称为BrandNewBertConfig。此配置始终存储为 PreTrainedModel 中的属性,因此可以通过config属性访问所有继承自BrandNewBertPreTrainedModel的类:
model = BrandNewBertModel.from_pretrained("brandy/brand_new_bert")
model.config # model has access to its config与模型类似,配置从 PretrainedConfig 继承基本的序列化和反序列化功能。请注意,配置和模型始终以两种不同的格式进行序列化 - 模型保存为pytorch_model.bin文件,配置保存为config.json文件。调用 save_pretrained()将自动调用 save_pretrained(),以便同时保存模型和配置。
代码风格
在编写新模型时,请记住 Transformers 是一个持有意见的库,关于代码应该如何编写,我们有自己的一些怪癖 😃
- 您的模型的前向传递应完全在建模文件中编写,同时完全独立于库中的其他模型。如果要重用另一个模型中的块,请复制代码并在顶部添加
# Copied from注释(请参见此处以获取一个很好的示例,以及此处以获取有关复制的更多文档)。 - 代码应该是完全可理解的,即使对于非母语英语的人也是如此。这意味着您应该选择描述性的变量名称并避免缩写。例如,
activation比act更受欢迎。除非是循环中的索引,否则强烈不建议使用一个字母的变量名。 - 总的来说,我们更喜欢长而明确的代码,而不是短而神奇的代码。
- 在 PyTorch 中避免对
nn.Sequential进行子类化,而是对nn.Module进行子类化并编写前向传递,以便使用您的代码的任何人都可以通过添加打印语句或断点来快速调试它。 - 您的函数签名应该有类型注释。对于其余部分,良好的变量名称比类型注释更可读和可理解。
分词器概述
还不太准备好 😦 此部分将很快添加!
将模型添加到🤗 Transformers 的逐步配方
每个人对如何移植模型都有不同的偏好,因此查看其他贡献者如何将模型移植到 Hugging Face 可能会对您非常有帮助。以下是关于如何移植模型的社区博客文章列表:
- 移植 GPT2 模型 by Thomas
- 移植 WMT19 MT 模型 by Stas
根据经验,我们可以告诉您在添加模型时要牢记的最重要的事情是:
- 不要重复造轮子!您将为新的🤗 Transformers 模型添加的大部分代码已经存在于🤗 Transformers 的某个地方。花些时间找到类似的、已经存在的模型和分词器,您可以从中复制。grep和rg是您的朋友。请注意,您的模型的分词器可能基于一个模型实现,而您的模型的建模代码可能基于另一个模型实现。例如,FSMT 的建模代码基于 BART,而 FSMT 的分词器代码基于 XLM。
- 这更多是一个工程挑战而不是一个科学挑战。您应该花更多时间创建一个高效的调试环境,而不是试图理解论文中模型的所有理论方面。
- 当您遇到困难时,请寻求帮助!模型是🤗 Transformers 的核心组件,因此我们在 Hugging Face 非常乐意在每个步骤帮助您添加您的模型。如果您发现自己没有取得进展,请不要犹豫询问。
接下来,我们尝试为您提供一个我们在将模型移植到🤗 Transformers 时发现最有用的一般步骤。
以下列表总结了添加模型时必须完成的所有工作,并可以作为待办事项清单使用:
□ (可选)理解模型的理论方面
□ 准备🤗 Transformers 开发环境
□ 设置原始存储库的调试环境
□ 创建脚本,成功使用原始存储库和检查点运行forward()传递
□ 成功将模型骨架添加到🤗 Transformers
□ 成功将原始检查点转换为🤗 Transformers 检查点
□ 在🤗 Transformers 中成功运行forward()传递,输出与原始检查点相同
□ 在🤗 Transformers 中完成模型测试
□ 在🤗 Transformers 中成功添加了分词器
□ 运行端到端集成测试
□ 完成文档
□ 将模型权重上传到 Hub
□ 提交拉取请求
□ (可选)添加演示笔记本
通常建议首先对BrandNewBert有一个良好的理论理解。但是,如果您更喜欢在工作中理解模型的理论方面,那么直接深入BrandNewBert的代码库也是完全可以的。如果您的工程技能比理论技能更强,如果您难以理解BrandNewBert的论文,或者如果您更喜欢编程而不是阅读科学论文,那么这个选项可能更适合您。
1. (可选)BrandNewBert 的理论方面
您应该花些时间阅读BrandNewBert的论文,如果存在这样的描述性工作。论文中可能有一些难以理解的大段内容。如果是这种情况,没关系 - 不要担心!目标不是深入理解论文,而是提取在🤗 Transformers 中有效重新实现模型所需的必要信息。也就是说,您不必花太多时间在理论方面,而是要专注于实践方面,即:
- brand_new_bert是什么类型的模型?类似 BERT 的仅编码器模型?类似 GPT2 的仅解码器模型?类似 BART 的编码器-解码器模型?如果您对这些之间的区别不熟悉,请查看[model_summary]。
- brand_new_bert的应用是什么?文本分类?文本生成?Seq2Seq 任务,例如,摘要?
- 该模型的新特性是什么,使其与 BERT/GPT-2/BART 不同?
- 已经存在的🤗 Transformers 模型中哪一个与brand_new_bert最相似?
- 使用了什么类型的分词器?是句子片段分词器?词片段分词器?它是否与 BERT 或 BART 使用的相同的分词器?
当您感觉对模型的架构有了很好的概述后,您可能希望向 Hugging Face 团队发送任何可能有的问题。这可能包括有关模型架构、注意力层等的问题。我们将非常乐意帮助您。
2. 接下来准备您的环境
- 点击存储库页面上的“Fork”按钮来 fork 这个存储库。这将在您的 GitHub 用户账户下创建代码的副本。
- 将您的
transformersfork 克隆到本地磁盘,并将基本存储库添加为远程:
git clone https://github.com/[your Github handle]/transformers.git
cd transformers
git remote add upstream https://github.com/huggingface/transformers.git- 设置一个开发环境,例如通过运行以下命令:
python -m venv .env
source .env/bin/activate
pip install -e ".[dev]"根据您的操作系统,由于 Transformers 的可选依赖项数量正在增加,您可能会在此命令中遇到失败。如果是这种情况,请确保安装您正在使用的深度学习框架(PyTorch、TensorFlow 和/或 Flax),然后执行:
pip install -e ".[quality]"这对于大多数用例应该足够了。然后您可以返回到父目录
cd ..- 我们建议将 PyTorch 版本的brand_new_bert添加到 Transformers 中。要安装 PyTorch,请按照
pytorch.org/get-started/locally/上的说明操作。
注意: 您不需要安装 CUDA。使新模型在 CPU 上运行就足够了。
- 要移植brand_new_bert,您还需要访问其原始存储库:
git clone https://github.com/org_that_created_brand_new_bert_org/brand_new_bert.git
cd brand_new_bert
pip install -e .现在您已经设置好了一个开发环境,可以将brand_new_bert移植到🤗 Transformers。
3.-4. 在原始存储库中运行预训练检查点
首先,您将在原始brand_new_bert存储库上工作。通常,原始实现非常“研究性”。这意味着文档可能缺失,代码可能难以理解。但这应该正是您重新实现brand_new_bert的动力所在。在 Hugging Face,我们的主要目标之一是让人们“站在巨人的肩膀上”,这在这里非常好地体现为拿一个可用的模型并重写它,使其尽可能易于访问、用户友好和美观。这是重新实现模型到🤗 Transformers 的首要动机 - 尝试使复杂的新 NLP 技术对每个人都可访问。
因此,您应该首先深入研究原始存储库。
在原始存储库中成功运行官方预训练模型通常是最困难的一步。根据我们的经验,花一些时间熟悉原始代码库非常重要。您需要弄清楚以下内容:
- 在哪里找到预训练权重?
- 如何将预训练权重加载到相应的模型中?
- 如何独立于模型运行分词器?
- 跟踪一次前向传递,以便了解哪些类和函数需要进行简单的前向传递。通常,您只需要重新实现这些函数。
- 能够找到模型的重要组件:模型的类在哪里?是否有模型子类,例如 EncoderModel,DecoderModel?自注意力层在哪里?是否有多个不同的注意力层,例如 self-attention,cross-attention…?
- 如何在存储库的原始环境中调试模型?您是否需要添加print语句,是否可以使用交互式调试器如ipdb,或者是否应该使用高效的 IDE 来调试模型,如 PyCharm?
在开始移植过程之前,非常重要的是您可以有效地调试原始存储库中的代码!还要记住,您正在使用一个开源库,因此不要犹豫在原始存储库中打开问题,甚至提交拉取请求。这个存储库的维护者很可能会对有人查看他们的代码感到非常高兴!
在这一点上,真的取决于您更喜欢使用哪种调试环境和策略来调试原始模型。我们强烈建议不要设置昂贵的 GPU 环境,而是在开始深入研究原始存储库和开始编写🤗 Transformers 模型实现时都使用 CPU。只有在模型已经成功移植到🤗 Transformers 后,才应验证模型在 GPU 上是否按预期工作。
一般来说,有两种可能的调试环境可用于运行原始模型
- Jupyter 笔记本 / google colab
- 本地 python 脚本。
Jupyter 笔记本的优势在于它们允许逐个单元格执行,这有助于更好地将逻辑组件彼此分离,并且具有更快的调试周期,因为中间结果可以被存储。此外,笔记本通常更容易与其他贡献者共享,如果您想要向 Hugging Face 团队寻求帮助,这可能非常有帮助。如果您熟悉 Jupyter 笔记本,我们强烈建议您使用它们。
Jupyter 笔记本的明显缺点是,如果您不习惯使用它们,您将不得不花费一些时间适应新的编程环境,可能无法再使用您已知的调试工具,如ipdb。
对于每个代码库,一个很好的第一步总是加载一个小的预训练检查点,并能够使用一个虚拟整数向量的输入 ID 进行单个前向传递。这样的脚本可能如下所示(伪代码):
model = BrandNewBertModel.load_pretrained_checkpoint("/path/to/checkpoint/")
input_ids = [0, 4, 5, 2, 3, 7, 9] # vector of input ids
original_output = model.predict(input_ids)接下来,关于调试策略,通常有几种选择:
- 将原始模型分解为许多小的可测试组件,并在每个组件上运行前向传递以进行验证
- 将原始模型仅分解为原始tokenizer和原始model,在这些上运行前向传递,并使用中间打印语句或断点进行验证
再次,选择哪种策略取决于你。通常,根据原始代码库的情况,一种或另一种策略都有优势。
如果原始代码库允许您将模型分解为较小的子组件,例如,如果原始代码库可以轻松在急切模式下运行,那么通常值得这样做。在一开始采取更困难的道路有一些重要的优势:
- 在稍后阶段,当将原始模型与 Hugging Face 实现进行比较时,您可以自动验证每个组件是否与🤗 Transformers 实现的相应组件匹配,而不是依赖通过打印语句进行视觉比较
- 它可以让您将将模型移植为较小问题的大问题分解为仅将单个组件移植为结构化工作的更好的方法。
- 将模型分解为逻辑有意义的组件将有助于更好地了解模型的设计,从而更好地理解模型
- 在稍后阶段,这些逐个组件的测试有助于确保在继续更改代码时不会发生退化
Lysandre 的 ELECTRA 集成检查为如何执行此操作提供了一个很好的示例。
然而,如果原始代码库非常复杂,或者只允许以编译模式运行中间组件,那么将模型分解为可测试的较小子组件可能会耗费太多时间,甚至是不可能的。一个很好的例子是T5 的 MeshTensorFlow库,它非常复杂,没有提供将模型分解为子组件的简单方法。对于这种库,人们通常依赖于验证打印语句。
无论您选择哪种策略,推荐的程序通常是相同的,即应该从调试起始图层开始,最后调试结束图层。
建议按照以下顺序检索以下图层的输出,可以通过打印语句或子组件函数来实现:
- 检索传递给模型的输入 ID
- 检索单词嵌入
- 检索第一个 Transformer 层的输入
- 检索第一个 Transformer 层的输出
- 检索以下 n-1 个 Transformer 层的输出
- 检索整个 BrandNewBert 模型的输出
输入 ID 应该由整数数组组成,例如 input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]
以下图层的输出通常由多维浮点数组组成,可能如下所示:
[[
[-0.1465, -0.6501, 0.1993, ..., 0.1451, 0.3430, 0.6024],
[-0.4417, -0.5920, 0.3450, ..., -0.3062, 0.6182, 0.7132],
[-0.5009, -0.7122, 0.4548, ..., -0.3662, 0.6091, 0.7648],
...,
[-0.5613, -0.6332, 0.4324, ..., -0.3792, 0.7372, 0.9288],
[-0.5416, -0.6345, 0.4180, ..., -0.3564, 0.6992, 0.9191],
[-0.5334, -0.6403, 0.4271, ..., -0.3339, 0.6533, 0.8694]]],我们期望每个添加到🤗 Transformers 的模型都经过几个集成测试,这意味着原始模型和🤗 Transformers 中重新实现的版本必须在精度为 0.001 的情况下给出完全相同的输出!由于相同模型在不同库中编写可能会根据库框架给出略有不同的输出,我们接受 1e-3(0.001)的误差容限。如果模型给出的输出几乎相同是不够的,它们必须几乎完全相同。因此,您肯定会多次将🤗 Transformers 版本的中间输出与brand_new_bert的原始实现的中间输出进行比较,在这种情况下,原始存储库的高效调试环境绝对重要。以下是一些建议,以使您的调试环境尽可能高效。
- 找到调试中间结果的最佳方法。原始存储库是用 PyTorch 编写的吗?那么您可能需要花时间编写一个更长的脚本,将原始模型分解为较小的子组件以检索中间值。原始存储库是用 Tensorflow 1 编写的吗?那么您可能需要依赖 TensorFlow 的打印操作,如 tf.print 来输出中间值。原始存储库是用 Jax 编写的吗?那么请确保在运行前向传递时模型未被 jit 编译,例如查看 此链接。
- 使用您能找到的最小的预训练检查点。检查点越小,您的调试周期就越快。如果您的预训练模型太大,导致前向传递超过 10 秒,那就不高效了。如果只有非常大的检查点可用,可能更有意义的是在新环境中创建一个带有随机初始化权重的虚拟模型,并保存这些权重以便与您模型的🤗 Transformers 版本进行比较。
- 确保您正在使用原始存储库中调用前向传递的最简单方法。理想情况下,您希望找到原始存储库中仅调用单个前向传递的函数,即通常称为
predict、evaluate、forward或__call__。您不希望调试多次调用forward的函数,例如生成文本的autoregressive_sample、generate。 - 尝试将标记化与模型的forward传递分开。如果原始存储库显示示例,您必须输入一个字符串,则尝试找出在前向调用中字符串输入何时更改为输入 id,并从此点开始。这可能意味着您可能需要自己编写一个小脚本或更改原始代码,以便您可以直接输入 id 而不是输入字符串。
- 确保您调试设置中的模型不处于训练模式,这通常会导致模型由于模型中的多个 dropout 层而产生随机输出。确保您调试环境中的前向传递是确定性的,以便不使用 dropout 层。或者如果旧实现和新实现在同一框架中,则使用transformers.utils.set_seed。
下一节将为您提供有关如何为brand_new_bert执行此操作的更具体详细信息/提示。
5.-14. 将 BrandNewBert 移植到🤗 Transformers
接下来,您可以开始向🤗 Transformers 添加新代码。进入您🤗 Transformers 分支的克隆:
cd transformers在特殊情况下,如果您要添加的模型的架构与现有模型的模型架构完全匹配,则只需添加一个转换脚本,如此部分所述。在这种情况下,您可以直接重用已存在模型的整个模型架构。
否则,让我们开始生成一个新模型。您在这里有两个选择:
-
transformers-cli add-new-model-like以添加一个类似于现有模型的新模型 -
transformers-cli add-new-model以从我们的模板中添加一个新模型(将看起来像 BERT 或 Bart,具体取决于您选择的模型类型)
在这两种情况下,您将被提示填写有关您的模型的基本信息的问卷。第二个命令需要安装cookiecutter,您可以在这里找到更多信息。
在主 huggingface/transformers 仓库上打开一个拉取请求
在开始调整自动生成的代码之前,现在是时候在🤗 Transformers 中打开一个“进行中的工作(WIP)”拉取请求,例如“[WIP]添加brand_new_bert”,以便您和 Hugging Face 团队可以并肩合作将模型集成到🤗 Transformers 中。
您应该执行以下操作:
- 从主分支创建一个具有描述性名称的分支
git checkout -b add_brand_new_bert- 提交自动生成的代码:
git add .
git commit- 获取并 rebase 到当前主分支
git fetch upstream
git rebase upstream/main- 使用以下命令将更改推送到您的帐户:
git push -u origin a-descriptive-name-for-my-changes- 一旦您满意,转到 GitHub 上您的分支的网页。点击“拉取请求”。确保将 Hugging Face 团队的一些成员的 GitHub 句柄添加为审阅者,以便 Hugging Face 团队在将来的更改中收到通知。
- 点击 GitHub 拉取请求网页右侧的“转换为草稿”将 PR 转换为草稿。
在接下来的过程中,每当您取得一些进展时,不要忘记提交您的工作并将其推送到您的帐户,以便在拉取请求中显示。此外,您应该确保不时使用以下方法更新您的工作与当前主分支:
git fetch upstream
git merge upstream/main总的来说,您可能对模型或您的实现有任何问题都应该在您的 PR 中提出,并在 PR 中讨论/解决。这样,当您提交新代码或有问题时,Hugging Face 团队将始终收到通知。将 Hugging Face 团队指向您添加的代码通常非常有帮助,以便 Hugging Face 团队可以高效地理解您的问题或疑问。
为此,您可以转到“更改的文件”选项卡,在那里您可以看到所有更改,转到您想要提问的行,并单击“+”符号添加评论。每当问题或问题得到解决时,您可以单击已创建评论的“解决”按钮。
同样,Hugging Face 团队在审查您的代码时会开放评论。我们建议在 GitHub 上的 PR 上提出大多数问题。对于一些对公众不太有用的非常一般性的问题,可以通过 Slack 或电子邮件联系 Hugging Face 团队。
5. 为 brand_new_bert 调整生成的模型代码
首先,我们将只关注模型本身,不关心分词器。所有相关代码应该在生成的文件src/transformers/models/brand_new_bert/modeling_brand_new_bert.py和src/transformers/models/brand_new_bert/configuration_brand_new_bert.py中找到。
现在您可以开始编码了 😃. 生成的代码在src/transformers/models/brand_new_bert/modeling_brand_new_bert.py中将具有与 BERT 相同的架构(如果是仅编码器模型)或与 BART 相同的架构(如果是编码器-解码器模型)。此时,您应该回想起您在开始时学到的关于模型理论方面的知识:“该模型与 BERT 或 BART 有何不同?”实现这些变化通常意味着更改self-attention层,规范化层的顺序等等…再次强调,查看 Transformers 中已经存在的类似模型的架构通常是有用的,以更好地了解如何实现您的模型。
注意,在这一点上,您不必非常确定您的代码是否完全正确或干净。相反,建议将原始代码的第一个不干净、复制粘贴版本添加到src/transformers/models/brand_new_bert/modeling_brand_new_bert.py,直到您觉得所有必要的代码都已添加。根据我们的经验,快速添加所需代码的第一个版本,并使用下一节中描述的转换脚本迭代地改进/纠正代码效率更高。在这一点上,唯一需要工作的是您可以实例化🤗 Transformers 实现的brand_new_bert,即以下命令应该可以工作:
from transformers import BrandNewBertModel, BrandNewBertConfig
model = BrandNewBertModel(BrandNewBertConfig())上述命令将根据BrandNewBertConfig()中定义的默认参数创建一个模型,具有随机权重,从而确保所有组件的init()方法正常工作。
请注意,所有随机初始化应该在您的BrandnewBertPreTrainedModel类的_init_weights方法中进行。它应该根据配置的变量初始化所有叶子模块。这里有一个使用 BERT _init_weights方法的示例:
def _init_weights(self, module):
"""Initialize the weights"""
if isinstance(module, nn.Linear):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.Embedding):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)如果需要某些模块的特殊初始化,您可以使用一些自定义方案。例如,在Wav2Vec2ForPreTraining中,最后两个线性层需要使用常规 PyTorch nn.Linear的初始化,但所有其他层应该使用上述初始化。这样编码:
def _init_weights(self, module):
"""Initialize the weights"""
if isinstnace(module, Wav2Vec2ForPreTraining):
module.project_hid.reset_parameters()
module.project_q.reset_parameters()
module.project_hid._is_hf_initialized = True
module.project_q._is_hf_initialized = True
elif isinstance(module, nn.Linear):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()_is_hf_initialized标志在内部用于确保我们只初始化一个子模块一次。通过将其设置为True,我们确保自定义初始化不会被后来覆盖,_init_weights函数不会应用于它们。
6. 编写转换脚本
接下来,您应该编写一个转换脚本,让您可以将您在原始存储库中用于调试brand_new_bert的检查点转换为与您刚刚创建的🤗 Transformers 实现brand_new_bert兼容的检查点。不建议从头开始编写转换脚本,而是查看🤗 Transformers 中已经存在的转换脚本,找到一个已经用于转换与brand_new_bert相同框架编写的类似模型的脚本。通常,复制一个已经存在的转换脚本并稍微调整以适应您的用例就足够了。不要犹豫向 Hugging Face 团队询问是否有类似的已经存在的转换脚本适用于您的模型。
- 如果您正在将模型从 TensorFlow 转换到 PyTorch,一个很好的起点可能是 BERT 的转换脚本此处
- 如果您正在将模型从 PyTorch 转换到 PyTorch,一个很好的起点可能是 BART 的转换脚本此处
接下来,我们将快速解释 PyTorch 模型如何存储层权重并定义层名称。在 PyTorch 中,层的名称由您给予该层的类属性的名称定义。让我们在 PyTorch 中定义一个名为SimpleModel的虚拟模型,如下所示:
from torch import nn
class SimpleModel(nn.Module):
def __init__(self):
super().__init__()
self.dense = nn.Linear(10, 10)
self.intermediate = nn.Linear(10, 10)
self.layer_norm = nn.LayerNorm(10)现在我们可以创建此模型定义的实例,该实例将填充所有权重:dense、intermediate、layer_norm,使用随机权重。我们可以打印模型以查看其架构
model = SimpleModel()
print(model)这将打印如下内容:
SimpleModel(
(dense): Linear(in_features=10, out_features=10, bias=True)
(intermediate): Linear(in_features=10, out_features=10, bias=True)
(layer_norm): LayerNorm((10,), eps=1e-05, elementwise_affine=True)
)我们可以看到层的名称由 PyTorch 中类属性的名称定义。您可以打印特定层的权重值:
print(model.dense.weight.data)查看权重是否已随机初始化
tensor([[-0.0818, 0.2207, -0.0749, -0.0030, 0.0045, -0.1569, -0.1598, 0.0212,
-0.2077, 0.2157],
[ 0.1044, 0.0201, 0.0990, 0.2482, 0.3116, 0.2509, 0.2866, -0.2190,
0.2166, -0.0212],
[-0.2000, 0.1107, -0.1999, -0.3119, 0.1559, 0.0993, 0.1776, -0.1950,
-0.1023, -0.0447],
[-0.0888, -0.1092, 0.2281, 0.0336, 0.1817, -0.0115, 0.2096, 0.1415,
-0.1876, -0.2467],
[ 0.2208, -0.2352, -0.1426, -0.2636, -0.2889, -0.2061, -0.2849, -0.0465,
0.2577, 0.0402],
[ 0.1502, 0.2465, 0.2566, 0.0693, 0.2352, -0.0530, 0.1859, -0.0604,
0.2132, 0.1680],
[ 0.1733, -0.2407, -0.1721, 0.1484, 0.0358, -0.0633, -0.0721, -0.0090,
0.2707, -0.2509],
[-0.1173, 0.1561, 0.2945, 0.0595, -0.1996, 0.2988, -0.0802, 0.0407,
0.1829, -0.1568],
[-0.1164, -0.2228, -0.0403, 0.0428, 0.1339, 0.0047, 0.1967, 0.2923,
0.0333, -0.0536],
[-0.1492, -0.1616, 0.1057, 0.1950, -0.2807, -0.2710, -0.1586, 0.0739,
0.2220, 0.2358]]).在转换脚本中,您应该使用相应层中的确切权重填充这些随机初始化的权重。例如
# retrieve matching layer weights, e.g. by
# recursive algorithm
layer_name = "dense"
pretrained_weight = array_of_dense_layer
model_pointer = getattr(model, "dense")
model_pointer.weight.data = torch.from_numpy(pretrained_weight)在执行此操作时,您必须验证您的 PyTorch 模型的每个随机初始化权重及其对应的预训练检查点权重在形状和名称上完全匹配。为此,必须添加形状的 assert 语句并打印出检查点权重的名称。例如,您应该添加类似以下语句:
assert (
model_pointer.weight.shape == pretrained_weight.shape
), f"Pointer shape of random weight {model_pointer.shape} and array shape of checkpoint weight {pretrained_weight.shape} mismatched"此外,您还应该打印出两个权重的名称,以确保它们匹配,例如
logger.info(f"Initialize PyTorch weight {layer_name} from {pretrained_weight.name}")如果形状或名称不匹配,则您可能将错误的检查点权重分配给了🤗 Transformers 实现的随机初始化层。
不正确的形状很可能是由于在BrandNewBertConfig()中不正确设置配置参数,这些参数与您要转换的检查点使用的参数不完全匹配。但是,也可能是 PyTorch 的层实现要求在之前对权重进行转置。
最后,您还应该检查所有必需的权重是否已初始化,并打印出所有未用于初始化的检查点权重,以确保模型已正确转换。完全正常的是,转换尝试可能会因为错误的形状语句或错误的名称分配而失败。这很可能是因为您在BrandNewBertConfig()中使用了不正确的参数,在🤗 Transformers 实现中有错误的架构,您在🤗 Transformers 实现的一个组件的init()函数中有错误,或者您需要转置一个检查点权重。
应该通过前面的步骤迭代此步骤,直到正确加载所有检查点的权重到 Transformers 模型中。正确加载检查点到🤗 Transformers 实现后,您可以将模型保存在您选择的文件夹中/path/to/converted/checkpoint/folder,该文件夹应包含一个pytorch_model.bin文件和一个config.json文件:
model.save_pretrained("/path/to/converted/checkpoint/folder")7. 实现正向传递
成功将预训练权重正确加载到🤗 Transformers 实现中后,现在应确保正向传递已正确实现。在熟悉原始存储库中,您已经创建了一个脚本,该脚本使用原始存储库运行模型的正向传递。现在,您应该编写一个类似的脚本,使用🤗 Transformers 实现而不是原始实现。它应该如下所示:
model = BrandNewBertModel.from_pretrained("/path/to/converted/checkpoint/folder")
input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]
output = model(input_ids).last_hidden_states🤗 Transformers 实现和原始模型实现很可能不会在第一次给出完全相同的输出,或者前向传递会出错。不要失望 - 这是预期的!首先,您应该确保前向传递不会出错。经常发生使用了错误的维度导致 维度不匹配 错误,或者使用了错误的数据类型对象,例如 torch.long 而不是 torch.float32。如果您无法解决某些错误,请毫不犹豫地向 Hugging Face 团队寻求帮助。
确保 🤗 Transformers 实现正确工作的最后一部分是确保输出精度达到 1e-3。首先,您应该确保输出形状相同,即脚本的 outputs.shape 应该对 🤗 Transformers 实现和原始实现产生相同的值。接下来,您应该确保输出值也相同。这是添加新模型中最困难的部分之一。输出不相同的常见错误包括:
- 某些层未添加,即未添加 激活 层,或者遗忘了残差连接。
- 单词嵌入矩阵未绑定
- 使用了错误的位置嵌入,因为原始实现使用了偏移
- 在前向传递期间应用了辍学。要修复此问题,请确保 model.training 为 False,并且在前向传递期间不会误激活任何辍学层,即将 self.training 传递给 PyTorch 的功能性辍学
通常修复问题的最佳方法是同时查看原始实现和 🤗 Transformers 实现的前向传递,并检查是否有任何差异。理想情况下,您应该调试/打印出两个实现的前向传递的中间输出,以找到 🤗 Transformers 实现显示与原始实现不同输出的网络中的确切位置。首先,确保两个脚本中硬编码的 input_ids 是相同的。接下来,验证 input_ids 的第一个转换的输出(通常是单词嵌入)是否相同。然后逐层向网络的最后一层工作。在某个时候,您会注意到两个实现之间的差异,这应该指向 🤗 Transformers 实现中的错误。根据我们的经验,一个简单而有效的方法是在原始实现和 🤗 Transformers 实现中的相同位置分别添加许多打印语句,并逐步删除显示中间表示值相同的打印语句。
当您确信两个实现产生相同输出时,使用 torch.allclose(original_output, output, atol=1e-3) 验证输出,您已经完成了最困难的部分!恭喜 - 剩下的工作应该很轻松 😊。
8. 添加所有必要的模型测试
在这一点上,您已成功添加了一个新模型。但是,很可能该模型尚未完全符合所需的设计。为确保实现与 🤗 Transformers 完全兼容,所有常见测试都应该通过。Cookiecutter 应该已自动为您的模型添加了一个测试文件,可能位于相同的 tests/models/brand_new_bert/test_modeling_brand_new_bert.py 下。运行此测试文件以验证所有常见测试是否通过:
pytest tests/models/brand_new_bert/test_modeling_brand_new_bert.py在修复所有常见测试后,现在至关重要的是确保您所做的所有工作都经过了充分测试,以便
- a) 社区可以通过查看 brand_new_bert 的特定测试轻松理解您的工作
- b) 对模型的未来更改不会破坏模型的任何重要功能。
首先,应添加集成测试。这些集成测试基本上与您早期用于将模型实现到🤗 Transformers 的调试脚本相同。Cookiecutter 已经添加了这些模型测试的模板,称为BrandNewBertModelIntegrationTests,您只需填写即可。为确保这些测试通过,请运行
RUN_SLOW=1 pytest -sv tests/models/brand_new_bert/test_modeling_brand_new_bert.py::BrandNewBertModelIntegrationTests如果您使用 Windows,应将RUN_SLOW=1替换为SET RUN_SLOW=1。
其次,brand_new_bert特有的所有功能还应在BrandNewBertModelTester/BrandNewBertModelTest下的单独测试中进行额外测试。这部分经常被遗忘,但在两个方面非常有用:
- 通过展示brand_new_bert的特殊功能应该如何工作,将您在模型添加过程中获得的知识传递给社区是有帮助的。
- 未来的贡献者可以通过运行这些特殊测试快速测试模型的更改。
9. 实现分词器
接下来,我们应该添加brand_new_bert的分词器。通常,分词器等同于或非常类似于🤗 Transformers 的已有分词器。
找到/提取原始的分词器文件并成功加载到🤗 Transformers 的分词器实现中非常重要。
为了确保分词器正常工作,建议首先在原始存储库中创建一个脚本,输入一个字符串并返回input_ids。它可能看起来类似于这样(伪代码):
input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
model = BrandNewBertModel.load_pretrained_checkpoint("/path/to/checkpoint/")
input_ids = model.tokenize(input_str)您可能需要再次深入研究原始存储库,找到正确的分词器函数,或者甚至可能需要对原始存储库的克隆进行更改,以仅输出input_ids。编写了一个使用原始存储库的功能性分词脚本后,应创建一个类似于🤗 Transformers 的脚本。它应该看起来类似于这样:
from transformers import BrandNewBertTokenizer
input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
tokenizer = BrandNewBertTokenizer.from_pretrained("/path/to/tokenizer/folder/")
input_ids = tokenizer(input_str).input_ids当input_ids产生相同的值时,最后一步应该添加一个分词器测试文件。
类似于brand_new_bert的建模测试文件,brand_new_bert的分词测试文件应包含一些硬编码的集成测试。
10. 运行端到端集成测试
添加了分词器后,还应在🤗 Transformers 的tests/models/brand_new_bert/test_modeling_brand_new_bert.py中添加一些端到端集成测试,使用模型和分词器。这样的测试应该在一个有意义的文本对文本示例上展示🤗 Transformers 的实现是否符合预期。有意义的文本对文本示例可以包括例如源到目标翻译对、文章到摘要对、问题到答案对等。如果没有任何迁移检查点在下游任务上进行了微调,仅依赖于模型测试就足够了。为了确保模型完全功能正常,建议您还在 GPU 上运行所有测试。有时您可能会忘记向模型的内部张量添加一些.to(self.device)语句,在这样的测试中会显示错误。如果您无法访问 GPU,Hugging Face 团队可以负责为您运行这些测试。
11. 添加文档字符串
现在,brand_new_bert所需的所有功能都已添加 - 您几乎完成了!唯一剩下的是添加一个良好的文档字符串和文档页面。Cookiecutter 应该已经添加了一个名为docs/source/model_doc/brand_new_bert.md的模板文件,您应该填写该文件。您的模型用户通常会在使用您的模型之前首先查看此页面。因此,文档必须易于理解和简洁。向社区添加一些提示以显示模型应如何使用是非常有用的。不要犹豫与 Hugging Face 团队联系有关文档字符串。
接下来,确保添加到src/transformers/models/brand_new_bert/modeling_brand_new_bert.py的文档字符串是正确的,并包含所有必要的输入和输出。我们有关于编写文档和我们的文档字符串格式的详细指南在这里。值得提醒自己的是,文档应该至少像🤗 Transformers 中的代码一样小心对待,因为文档通常是社区与模型的第一个接触点。
代码重构
很好,现在你已经为brand_new_bert添加了所有必要的代码。在这一点上,你应该通过运行以下代码来纠正一些潜在的不正确的代码风格:
make style并验证你的编码风格是否通过了质量检查:
make quality在🤗 Transformers 中还有一些其他非常严格的设计测试可能仍然失败,这会在你的拉取请求的测试中显示出来。这往往是因为文档字符串中缺少一些信息或一些名称不正确。如果你遇到困难,Hugging Face 团队肯定会帮助你。
最后,经过确保代码正确运行后,重新设计代码总是一个好主意。现在所有的测试都通过了,现在是一个好时机再次检查添加的代码并进行一些重构。
恭喜!你现在已经完成了编码部分,太棒了!🎉 你真棒!😎
12. 将模型上传到模型中心
在这最后一部分,你应该将所有检查点转换并上传到模型中心,并为每个上传的模型检查点添加一个模型卡片。你可以通过阅读我们的模型分享和上传页面来熟悉中心的功能。在这里,你应该与 Hugging Face 团队一起工作,决定为每个检查点选择一个合适的名称,并获得所需的访问权限,以便能够将模型上传到作者组织brand_new_bert下。transformers中的所有模型中都有push_to_hub方法,这是将你的检查点快速有效地推送到中心的方法。下面是一个小片段:
brand_new_bert.push_to_hub("brand_new_bert")
# Uncomment the following line to push to an organization.
# brand_new_bert.push_to_hub("<organization>/brand_new_bert")值得花一些时间为每个检查点创建合适的模型卡片。模型卡片应该突出显示这个特定检查点的特定特征,例如这个检查点是在哪个数据集上进行预训练/微调的?这个模型应该用于哪个下游任务?还应该包括一些关于如何正确使用模型的代码。
13. (可选)添加笔记本
添加一个展示brand_new_bert如何用于推理和/或在下游任务上进行微调的详细笔记本非常有帮助。这不是合并你的 PR 所必需的,但对社区非常有用。
14. 提交你完成的 PR
你现在已经完成了编程工作,可以进入最后一步,即将你的 PR 合并到主分支。通常情况下,Hugging Face 团队在这一点上应该已经帮助过你了,但值得花一些时间为你的完成的 PR 添加一个好的描述,并最终为你的代码添加注释,如果你想指出某些设计选择给你的审阅者。
分享你的工作!
现在,是时候从社区中获得一些对你工作的认可了!完成模型添加是对 Transformers 和整个 NLP 社区的重大贡献。你的代码和移植的预训练模型肯定会被数百甚至数千名开发人员和研究人员使用。你应该为自己的工作感到自豪,并与社区分享你的成就。
你又制作了一个对社区中每个人都很容易访问的模型!🤯
如何将🤗 Transformers 模型转换为 TensorFlow?
原始文本:
huggingface.co/docs/transformers/v4.37.2/en/add_tensorflow_model
在🤗 Transformers 中有多个可用的框架可以使用,这使您在设计应用程序时可以灵活发挥其优势,但这意味着必须根据每个模型添加兼容性。好消息是,将 TensorFlow 兼容性添加到现有模型比从头开始添加新模型更简单!无论您希望更深入地了解大型 TensorFlow 模型,做出重大的开源贡献,还是为您选择的模型启用 TensorFlow,本指南都适合您。
本指南授权您,我们社区的一员,贡献 TensorFlow 模型权重和/或架构,以供在🤗 Transformers 中使用,几乎不需要 Hugging Face 团队的监督。编写一个新模型并不是一件小事,但希望这个指南能让它不再像坐过山车🎢那样,而更像在公园里散步🚶。利用我们的集体经验绝对是使这个过程变得更加容易的关键,因此我们强烈鼓励您对本指南提出改进建议!
在深入研究之前,建议您查看以下资源,如果您对🤗 Transformers 还不熟悉:
- 🤗 Transformers 的概述
- 拥抱面的 TensorFlow 哲学
在本指南的其余部分,您将学习添加新的 TensorFlow 模型架构所需的内容,将 PyTorch 转换为 TensorFlow 模型权重的过程,以及如何有效地调试跨 ML 框架的不匹配。让我们开始吧!
您是否不确定您想要使用的模型是否已经有相应的 TensorFlow 架构?
检查您选择的模型的config.json文件中的model_type字段(示例)。如果🤗 Transformers 中相应的模型文件夹有一个以“modeling_tf”开头的文件,这意味着它有一个相应的 TensorFlow 架构(示例)。
逐步指南添加 TensorFlow 模型架构代码
设计大型模型架构的方法有很多,实现该设计的方式也有多种。然而,您可能还记得我们在🤗 Transformers 的概述中提到,我们是一个有主见的团队 - 🤗 Transformers 的易用性依赖于一致的设计选择。从经验中,我们可以告诉您一些关于添加 TensorFlow 模型的重要事项:
- 不要重复造轮子!往往至少有两个参考实现您应该检查:您正在实现的模型的 PyTorch 等效版本以及同一类问题的其他 TensorFlow 模型。
- 出色的模型实现经得起时间的考验。这不是因为代码漂亮,而是因为代码清晰,易于调试和构建。如果您通过在 TensorFlow 实现中复制其他 TensorFlow 模型中的相同模式并最小化与 PyTorch 实现的不匹配,使维护者的生活变得轻松,您就确保您的贡献将长期存在。
- 当遇到困难时寻求帮助!🤗 Transformers 团队在这里帮助您,我们可能已经找到了您面临的相同问题的解决方案。
以下是添加 TensorFlow 模型架构所需步骤的概述:
- 选择您希望转换的模型
- 准备 transformers 开发环境
- (可选)理解理论方面和现有实现
- 实现模型架构
- 实现模型测试
- 提交拉取请求
- (可选)构建演示并与世界分享
1.-3. 准备您的模型贡献
1.选择要转换的模型
让我们从基础知识开始:您需要了解要转换的架构。如果您没有特定的架构,向🤗 Transformers 团队寻求建议是最大化影响的好方法 - 我们将指导您选择在 TensorFlow 方面缺失的最突出的架构。如果您想要在 TensorFlow 中使用的特定模型已经在🤗 Transformers 中具有 TensorFlow 架构实现,但缺少权重,请随时直接转到本页的添加 TensorFlow 权重到 hub 部分。
为简单起见,本指南的其余部分假定您已决定使用 TensorFlow 版本的BrandNewBert(与指南中添加新模型的示例相同)做出贡献。
在开始 TensorFlow 模型架构的工作之前,请仔细检查是否有正在进行的工作。您可以在拉取请求 GitHub 页面上搜索BrandNewBert以确认是否有与 TensorFlow 相关的拉取请求。
2.准备 transformers 开发环境
选择模型架构后,打开一个草稿 PR 以表示您打算进行工作。按照以下说明设置您的环境并打开草稿 PR。
- 通过单击存储库页面上的“Fork”按钮来分叉存储库。这将在您的 GitHub 用户帐户下创建代码副本。
- 将您的
transformers分支克隆到本地磁盘,并将基础存储库添加为远程存储库:
git clone https://github.com/[your Github handle]/transformers.git
cd transformers
git remote add upstream https://github.com/huggingface/transformers.git- 建立一个开发环境,例如通过运行以下命令:
python -m venv .env
source .env/bin/activate
pip install -e ".[dev]"根据您的操作系统,由于 Transformers 的可选依赖项数量正在增加,您可能会在此命令中失败。如果是这种情况,请确保安装 TensorFlow,然后执行:
pip install -e ".[quality]"**注意:**您不需要安装 CUDA。使新模型在 CPU 上运行就足够了。
- 从主分支创建一个具有描述性名称的分支
git checkout -b add_tf_brand_new_bert- 获取并将当前主分支重新设置为基础
git fetch upstream
git rebase upstream/main- 在
transformers/src/models/brandnewbert/中添加一个名为modeling_tf_brandnewbert.py的空.py文件。这将是您的 TensorFlow 模型文件。 - 使用以下命令将更改推送到您的帐户:
git add .
git commit -m "initial commit"
git push -u origin add_tf_brand_new_bert- 一旦您满意了,转到 GitHub 上您的分支的网页。点击“拉取请求”。确保将 Hugging Face 团队的一些成员的 GitHub 句柄添加为审阅者,以便 Hugging Face 团队在未来的更改中收到通知。
- 通过单击 GitHub 拉取请求网页右侧的“转换为草稿”将 PR 更改为草稿。
现在您已经设置了一个开发环境,可以将BrandNewBert移植到🤗 Transformers 中的 TensorFlow 中。
3.(可选)了解理论方面和现有实现
您应该花一些时间阅读BrandNewBert的论文,如果存在这样的描述性工作。论文中可能有一些难以理解的大段内容。如果是这种情况,没关系 - 不要担心!目标不是深入理解论文的理论,而是提取在🤗 Transformers 中使用 TensorFlow 有效重新实现模型所需的必要信息。也就是说,您不必花太多时间在理论方面,而是要专注于实践方面,即现有模型文档页面(例如 BERT 的模型文档)。
在掌握了即将实现的模型的基础知识之后,了解现有的实现是很重要的。这是确认工作实现是否符合您对模型的期望,以及预见 TensorFlow 方面的技术挑战的绝佳机会。
你感到不知所措刚刚吸收了大量信息是非常自然的。在这个阶段,你并不需要理解模型的所有方面。尽管如此,我们强烈鼓励你在我们的论坛中解决任何紧迫的问题。
4. 模型实现
现在是时候开始编码了。我们建议的起点是 PyTorch 文件本身:将modeling_brand_new_bert.py的内容复制到src/transformers/models/brand_new_bert/中的modeling_tf_brand_new_bert.py。本节的目标是修改文件并更新🤗 Transformers 的导入结构,以便你可以成功导入TFBrandNewBert和TFBrandNewBert.from_pretrained(model_repo, from_pt=True),从而加载一个可工作的 TensorFlow BrandNewBert模型。
遗憾的是,没有将 PyTorch 模型转换为 TensorFlow 的规定。但是,你可以遵循我们的一些提示,使这个过程尽可能顺利:
- 将所有类的名称前加上
TF(例如,BrandNewBert变为TFBrandNewBert)。 - 大多数 PyTorch 操作都有直接的 TensorFlow 替代。例如,
torch.nn.Linear对应于tf.keras.layers.Dense,torch.nn.Dropout对应于tf.keras.layers.Dropout等。如果对特定操作不确定,可以使用TensorFlow 文档或PyTorch 文档。 - 在🤗 Transformers 代码库中寻找模式。如果你遇到某个操作没有直接替代,那么很可能有其他人已经遇到了同样的问题。
- 默认情况下,保持与 PyTorch 相同的变量名称和结构。这将使调试、跟踪问题和添加修复更容易。
- 一些层在每个框架中具有不同的默认值。一个显著的例子是批量归一化层的 epsilon(在PyTorch中为
1e-5,在TensorFlow中为1e-3)。务必仔细检查文档! - PyTorch 的
nn.Parameter变量通常需要在 TF Layer 的build()中初始化。参见以下示例:PyTorch / TensorFlow - 如果 PyTorch 模型在函数顶部有
#copied from ...,那么你的 TensorFlow 模型很可能也可以从被复制的架构中借用该函数,假设它有一个 TensorFlow 架构。 - 在 TensorFlow 函数中正确设置
name属性对于进行from_pt=True权重交叉加载至关重要。name几乎总是 PyTorch 代码中相应变量的名称。如果name没有正确设置,加载模型权重时会在错误消息中看到。 - 基础模型类
BrandNewBertModel的逻辑实际上将驻留在TFBrandNewBertMainLayer中,这是一个 Keras 层子类(示例)。TFBrandNewBertModel将简单地是这个层的包装器。 - Keras 模型需要被构建以加载预训练权重。因此,
TFBrandNewBertPreTrainedModel将需要保存模型的输入示例,即dummy_inputs(示例)。 - 如果遇到困难,请寻求帮助 - 我们在这里帮助你!🤗
除了模型文件本身,您还需要添加指向模型类和相关文档页面的指针。您可以完全按照其他 PR 中的模式完成此部分(示例)。以下是所需手动更改的列表:
- 在
src/transformers/__init__.py中包含 BrandNewBert 的所有公共类 - 在
src/transformers/models/auto/modeling_tf_auto.py中将 BrandNewBert 类添加到相应的 Auto 类中 - 在
src/transformers/utils/dummy_tf_objects.py中添加与 BrandNewBert 相关的延迟加载类 - 更新
src/transformers/models/brand_new_bert/__init__.py中公共类的导入结构 - 在
docs/source/en/model_doc/brand_new_bert.md中为 BrandNewBert 的公共方法添加文档指针 - 在
docs/source/en/model_doc/brand_new_bert.md中将自己添加到 BrandNewBert 的贡献者列表中 - 最后,在
docs/source/en/index.md中 BrandNewBert 的 TensorFlow 列中添加一个绿色勾 ✅
当您对实现感到满意时,请运行以下检查表以确认您的模型架构已准备就绪:
- 在训练时行为不同的所有层(例如 Dropout)都使用
training参数调用,并且该参数从顶层类一直传播下去 - 在可能的情况下,您已经使用了
#copied from ... -
TFBrandNewBertMainLayer和所有使用它的类都将其call函数装饰为@unpack_inputs -
TFBrandNewBertMainLayer被装饰为@keras_serializable - 可以使用
TFBrandNewBert.from_pretrained(model_repo, from_pt=True)从 PyTorch 权重加载 TensorFlow 模型 - 您可以使用预期的输入格式调用 TensorFlow 模型
5. 添加模型测试
万岁,您已经实现了一个 TensorFlow 模型!现在是添加测试以确保您的模型表现如预期的时候了。与前一节一样,我们建议您首先将 tests/models/brand_new_bert/ 中的 test_modeling_brand_new_bert.py 文件复制到 test_modeling_tf_brand_new_bert.py 中,然后继续进行必要的 TensorFlow 替换。目前,在所有 .from_pretrained() 调用中,您应该使用 from_pt=True 标志来加载现有的 PyTorch 权重。
完成后,是真相时刻:运行测试!😬
NVIDIA_TF32_OVERRIDE=0 RUN_SLOW=1 RUN_PT_TF_CROSS_TESTS=1 \
py.test -vv tests/models/brand_new_bert/test_modeling_tf_brand_new_bert.py最有可能的结果是您会看到一堆错误。不要担心,这是正常的!调试 ML 模型是非常困难的,成功的关键因素是耐心(和 breakpoint())。根据我们的经验,最困难的问题来自于 ML 框架之间的微妙不匹配,我们在本指南末尾提供了一些指针。在其他情况下,一般测试可能不直接适用于您的模型,这种情况下,我们建议在模型测试类级别进行覆盖。无论问题是什么,请不要犹豫在您的草稿拉取请求中寻求帮助,如果您遇到困难。
当所有测试通过时,恭喜,您的模型几乎可以添加到 🤗 Transformers 库中了!🎉
6.-7. 确保每个人都可以使用您的模型
6. 提交拉取请求
完成实现和测试后,现在是提交拉取请求的时候了。在推送代码之前,请运行我们的代码格式化工具 make fixup 🪄。这将自动修复任何格式问题,否则会导致我们的自动检查失败。
现在是将草稿拉取请求转换为真正拉取请求的时候了。为此,请点击“准备好审查”按钮,并将 Joao (@gante) 和 Matt (@Rocketknight1) 添加为审阅者。模型拉取请求将需要至少 3 名审阅者,但他们会负责为您的模型找到合适的额外审阅者。
在所有审阅者对您的 PR 的状态满意后,最后一个行动点是在 .from_pretrained() 调用中移除 from_pt=True 标志。由于没有 TensorFlow 权重,您将需要添加它们!查看下面的部分以获取如何执行此操作的说明。
最后,当 TensorFlow 权重合并时,你至少有 3 个审阅者的批准,并且所有 CI 检查都是绿色的时候,最后再本地再次检查测试
NVIDIA_TF32_OVERRIDE=0 RUN_SLOW=1 RUN_PT_TF_CROSS_TESTS=1 \
py.test -vv tests/models/brand_new_bert/test_modeling_tf_brand_new_bert.py我们将合并你的 PR!祝贺你达到的里程碑🎉
7. (可选)构建演示并与世界分享
开源项目中最困难的部分之一是发现。其他用户如何了解你出色的 TensorFlow 贡献的存在?当然是通过适当的沟通!
有两种主要的方法可以与社区分享你的模型:
- 构建演示。这些包括 Gradio 演示、笔记本和其他有趣的方式来展示你的模型。我们强烈鼓励你向我们的社区驱动演示添加一个笔记本。
- 在社交媒体上分享故事,比如 Twitter 和 LinkedIn。你应该为自己的工作感到自豪,并与社区分享你的成就 - 你的模型现在可以被全球数千名工程师和研究人员使用!我们将很乐意转发你的帖子,并帮助你与社区分享你的工作。
将 TensorFlow 权重添加到🤗 Hub
假设 TensorFlow 模型架构在🤗 Transformers 中可用,将 PyTorch 权重转换为 TensorFlow 权重将变得轻而易举!
以下是如何做到这一点:
- 确保你已经在终端中登录到你的 Hugging Face 账户。你可以使用命令
huggingface-cli login登录(你可以在这里找到你的访问令牌) - 运行
transformers-cli pt-to-tf --model-name foo/bar,其中foo/bar是包含你想要转换的 PyTorch 权重的模型存储库的名称 - 在🤗 Hub PR 中标记
@joaogante和@Rocketknight1,这是上面命令创建的
就是这样!
跨 ML 框架调试不匹配🐛
在添加新架构或为现有架构创建 TensorFlow 权重时,你可能会遇到关于 PyTorch 和 TensorFlow 之间不匹配的错误。你甚至可能决定打开两个框架的模型架构代码,并发现它们看起来是相同的。发生了什么?
首先,让我们谈谈为什么理解这些不匹配很重要。许多社区成员将直接使用🤗 Transformers 模型,并相信我们的模型表现如预期。当两个框架之间存在较大的不匹配时,这意味着模型至少在一个框架中没有遵循参考实现。这可能导致悄无声息的失败,即模型运行但性能不佳。这可能比根本无法运行的模型更糟!因此,我们的目标是在模型的所有阶段都有小于1e-5的框架不匹配。
就像其他数值问题一样,魔鬼就在细节中。就像任何注重细节的工艺一样,耐心是秘密的关键。以下是我们建议的工作流程,当你遇到这种类型的问题时:
- 找到不匹配的源头。你要转换的模型可能在某个特定点上有几乎相同的内部变量。在两个框架的架构中放置
breakpoint()语句,并以自上而下的方式比较数值变量的值,直到找到问题的源头。 - 现在你已经找到了问题的源头,请与🤗 Transformers 团队联系。可能我们之前见过类似的问题,并且可以迅速提供解决方案。作为备选方案,浏览像 StackOverflow 和 GitHub 问题这样的热门页面。
- 如果看不到解决方案,这意味着你将不得不深入研究。好消息是你已经找到了问题所在,所以你可以专注于有问题的指令,将模型的其余部分抽象出来!坏消息是你将不得不深入研究该指令的源实现。在某些情况下,你可能会发现参考实现存在问题 - 不要放弃在上游存储库中开启问题。
在某些情况下,在与🤗 Transformers 团队讨论后,我们可能会发现修复不匹配是不可行的。当模型的输出层中不匹配非常小(但在隐藏状态中可能很大)时,我们可能会决定忽略它,以便分发模型。上面提到的pt-to-tf CLI 具有一个--max-error标志,可以在权重转换时覆盖错误消息。
t1`) 添加为审阅者。模型拉取请求将需要至少 3 名审阅者,但他们会负责为您的模型找到合适的额外审阅者。
在所有审阅者对您的 PR 的状态满意后,最后一个行动点是在 .from_pretrained() 调用中移除 from_pt=True 标志。由于没有 TensorFlow 权重,您将需要添加它们!查看下面的部分以获取如何执行此操作的说明。
最后,当 TensorFlow 权重合并时,你至少有 3 个审阅者的批准,并且所有 CI 检查都是绿色的时候,最后再本地再次检查测试
NVIDIA_TF32_OVERRIDE=0 RUN_SLOW=1 RUN_PT_TF_CROSS_TESTS=1 \
py.test -vv tests/models/brand_new_bert/test_modeling_tf_brand_new_bert.py我们将合并你的 PR!祝贺你达到的里程碑🎉
7. (可选)构建演示并与世界分享
开源项目中最困难的部分之一是发现。其他用户如何了解你出色的 TensorFlow 贡献的存在?当然是通过适当的沟通!
有两种主要的方法可以与社区分享你的模型:
- 构建演示。这些包括 Gradio 演示、笔记本和其他有趣的方式来展示你的模型。我们强烈鼓励你向我们的社区驱动演示添加一个笔记本。
- 在社交媒体上分享故事,比如 Twitter 和 LinkedIn。你应该为自己的工作感到自豪,并与社区分享你的成就 - 你的模型现在可以被全球数千名工程师和研究人员使用!我们将很乐意转发你的帖子,并帮助你与社区分享你的工作。
将 TensorFlow 权重添加到🤗 Hub
假设 TensorFlow 模型架构在🤗 Transformers 中可用,将 PyTorch 权重转换为 TensorFlow 权重将变得轻而易举!
以下是如何做到这一点:
- 确保你已经在终端中登录到你的 Hugging Face 账户。你可以使用命令
huggingface-cli login登录(你可以在这里找到你的访问令牌) - 运行
transformers-cli pt-to-tf --model-name foo/bar,其中foo/bar是包含你想要转换的 PyTorch 权重的模型存储库的名称 - 在🤗 Hub PR 中标记
@joaogante和@Rocketknight1,这是上面命令创建的
就是这样!
跨 ML 框架调试不匹配🐛
在添加新架构或为现有架构创建 TensorFlow 权重时,你可能会遇到关于 PyTorch 和 TensorFlow 之间不匹配的错误。你甚至可能决定打开两个框架的模型架构代码,并发现它们看起来是相同的。发生了什么?
首先,让我们谈谈为什么理解这些不匹配很重要。许多社区成员将直接使用🤗 Transformers 模型,并相信我们的模型表现如预期。当两个框架之间存在较大的不匹配时,这意味着模型至少在一个框架中没有遵循参考实现。这可能导致悄无声息的失败,即模型运行但性能不佳。这可能比根本无法运行的模型更糟!因此,我们的目标是在模型的所有阶段都有小于1e-5的框架不匹配。
就像其他数值问题一样,魔鬼就在细节中。就像任何注重细节的工艺一样,耐心是秘密的关键。以下是我们建议的工作流程,当你遇到这种类型的问题时:
- 找到不匹配的源头。你要转换的模型可能在某个特定点上有几乎相同的内部变量。在两个框架的架构中放置
breakpoint()语句,并以自上而下的方式比较数值变量的值,直到找到问题的源头。 - 现在你已经找到了问题的源头,请与🤗 Transformers 团队联系。可能我们之前见过类似的问题,并且可以迅速提供解决方案。作为备选方案,浏览像 StackOverflow 和 GitHub 问题这样的热门页面。
- 如果看不到解决方案,这意味着你将不得不深入研究。好消息是你已经找到了问题所在,所以你可以专注于有问题的指令,将模型的其余部分抽象出来!坏消息是你将不得不深入研究该指令的源实现。在某些情况下,你可能会发现参考实现存在问题 - 不要放弃在上游存储库中开启问题。
在某些情况下,在与🤗 Transformers 团队讨论后,我们可能会发现修复不匹配是不可行的。当模型的输出层中不匹配非常小(但在隐藏状态中可能很大)时,我们可能会决定忽略它,以便分发模型。上面提到的pt-to-tf CLI 具有一个--max-error标志,可以在权重转换时覆盖错误消息。