Transformers 4.37 中文文档(七十二)

Swin2SR
原始文本:
huggingface.co/docs/transformers/v4.37.2/en/model_doc/swin2sr
概述
Swin2SR 模型是由 Marcos V. Conde、Ui-Jin Choi、Maxime Burchi、Radu Timofte 在《Swin2SR:用于压缩图像超分辨率和恢复的 SwinV2 Transformer》中提出的。Swin2R 通过整合SwinIR模型中的 Swin Transformer v2 层来改进模型,从而缓解训练不稳定性、预训练和微调之间的分辨率差距以及数据饥饿等问题。
论文摘要如下:
压缩在通过带限制系统(如流媒体服务、虚拟现实或视频游戏)传输和存储图像和视频中扮演着重要角色。然而,压缩不可避免地会导致伪影和原始信息的丢失,这可能严重降低视觉质量。因此,压缩图像的质量增强已成为一个热门研究课题。虽然大多数最先进的图像恢复方法基于卷积神经网络,但其他基于 Transformer 的方法,如 SwinIR,在这些任务上表现出色。在本文中,我们探索了新颖的 Swin Transformer V2,以改进 SwinIR 用于图像超分辨率,特别是在压缩输入场景下。使用这种方法,我们可以解决训练 Transformer 视觉模型时的主要问题,如训练不稳定性、预训练和微调之间的分辨率差距,以及数据饥饿。我们在三个代表性任务上进行实验:JPEG 压缩伪影去除、图像超分辨率(经典和轻量级)以及压缩图像超分辨率。实验结果表明,我们的方法 Swin2SR 可以改善 SwinIR 的训练收敛性和性能,并且在“AIM 2022 挑战赛:压缩图像和视频的超分辨率”中是前五名解决方案。
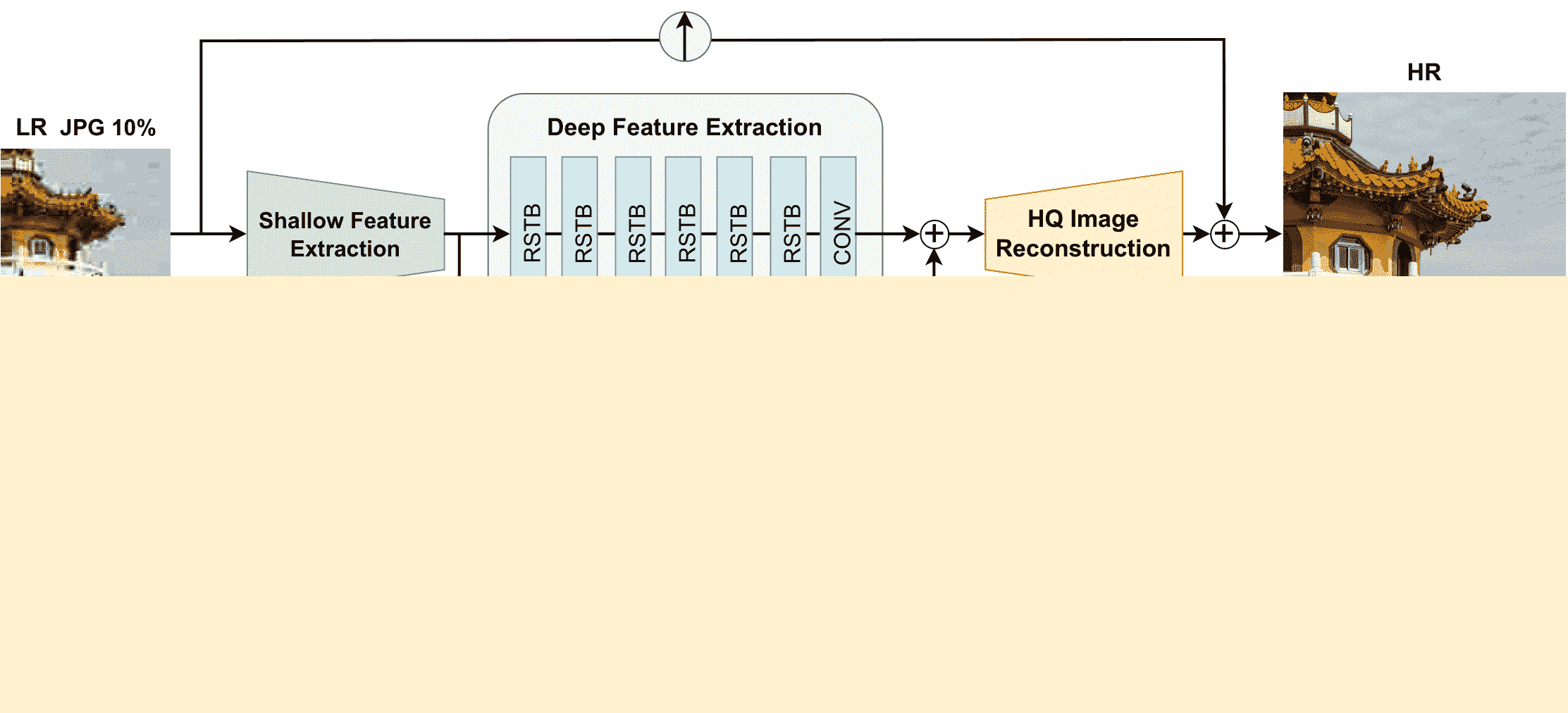
Swin2SR 架构。取自原始论文。
资源
Swin2SR 的演示笔记本可以在这里找到。
可以在这里找到一个 SwinSR 图像超分辨率的演示空间。
Swin2SRImageProcessor
class transformers.Swin2SRImageProcessor
( do_rescale: bool = True rescale_factor: Union = 0.00392156862745098 do_pad: bool = True pad_size: int = 8 **kwargs )参数
-
do_rescale(bool,可选,默认为True) — 是否按指定比例rescale_factor对图像进行重新缩放。可以通过preprocess方法中的do_rescale参数进行覆盖。 -
rescale_factor(int或float,可选,默认为1/255) — 如果重新缩放图像,则使用的比例因子。可以通过preprocess方法中的rescale_factor参数进行覆盖。
构建一个 Swin2SR 图像处理器。
preprocess
( images: Union do_rescale: Optional = None rescale_factor: Optional = None do_pad: Optional = None pad_size: Optional = None return_tensors: Union = None data_format: Union = <ChannelDimension.FIRST: 'channels_first'> input_data_format: Union = None **kwargs )参数
-
images(ImageInput) — 要预处理的图像。期望传入像素值范围从 0 到 255 的单个或批量图像。如果传入像素值在 0 到 1 之间的图像,请设置do_rescale=False。 -
do_rescale(bool,可选,默认为self.do_rescale) — 是否将图像值重新缩放在[0 - 1]之间。 -
rescale_factor(float,可选,默认为self.rescale_factor) — 如果do_rescale设置为True,则重新缩放图像的重新缩放因子。 -
do_pad(bool, 可选, 默认为True) — 是否填充图像以使高度和宽度可被window_size整除。 -
pad_size(int, 可选, 默认为 32) — 用于局部注意力的滑动窗口的大小。 -
return_tensors(str或TensorType, 可选) — 要返回的张量类型。可以是以下之一:- 未设置:返回一个
np.ndarray列表。 -
TensorType.TENSORFLOW或'tf':返回一个tf.Tensor类型的批次,input_data_format=input_data_formate。 -
TensorType.PYTORCH或'pt':返回一个torch.Tensor类型的批次。 -
TensorType.NUMPY或'np':返回一个np.ndarray类型的批次。 -
TensorType.JAX或'jax':返回一个jax.numpy.ndarray类型的批次。
- 未设置:返回一个
-
data_format(ChannelDimension或str, 可选, 默认为ChannelDimension.FIRST) — 输出图像的通道维度格式。可以是以下之一:-
"channels_first"或ChannelDimension.FIRST:图像以 (通道数, 高度, 宽度) 格式。 -
"channels_last"或ChannelDimension.LAST:图像以 (高度, 宽度, 通道数) 格式。 - 未设置:使用输入图像的通道维度格式。
-
-
input_data_format(ChannelDimension或str, 可选) — 输入图像的通道维度格式。如果未设置,则从输入图像中推断通道维度格式。可以是以下之一:-
"channels_first"或ChannelDimension.FIRST:图像以 (通道数, 高度, 宽度) 格式。 -
"channels_last"或ChannelDimension.LAST:图像以 (高度, 宽度, 通道数) 格式。 -
"none"或ChannelDimension.NONE:图像以 (高度, 宽度) 格式。
-
预处理一张图像或一批图像。
Swin2SRConfig
class transformers.Swin2SRConfig
( image_size = 64 patch_size = 1 num_channels = 3 num_channels_out = None embed_dim = 180 depths = [6, 6, 6, 6, 6, 6] num_heads = [6, 6, 6, 6, 6, 6] window_size = 8 mlp_ratio = 2.0 qkv_bias = True hidden_dropout_prob = 0.0 attention_probs_dropout_prob = 0.0 drop_path_rate = 0.1 hidden_act = 'gelu' use_absolute_embeddings = False initializer_range = 0.02 layer_norm_eps = 1e-05 upscale = 2 img_range = 1.0 resi_connection = '1conv' upsampler = 'pixelshuffle' **kwargs )参数
-
image_size(int, 可选, 默认为 64) — 每个图像的大小(分辨率)。 -
patch_size(int, 可选, 默认为 1) — 每个补丁的大小(分辨率)。 -
num_channels(int, 可选, 默认为 3) — 输入通道的数量。 -
num_channels_out(int, 可选, 默认为num_channels) — 输出通道的数量。如果未设置,将设置为num_channels。 -
embed_dim(int, 可选, 默认为 180) — 补丁嵌入的维度。 -
depths(list(int), 可选, 默认为[6, 6, 6, 6, 6, 6]) — Transformer 编码器中每层的深度。 -
num_heads(list(int), 可选, 默认为[6, 6, 6, 6, 6, 6]) — Transformer 编码器每层的注意力头数。 -
window_size(int, 可选, 默认为 8) — 窗口的大小。 -
mlp_ratio(float, 可选, 默认为 2.0) — MLP 隐藏维度与嵌入维度的比率。 -
qkv_bias(bool, 可选, 默认为True) — 是否应该向查询、键和值添加可学习的偏置。 -
hidden_dropout_prob(float, 可选, 默认为 0.0) — 嵌入和编码器中所有全连接层的 dropout 概率。 -
attention_probs_dropout_prob(float, 可选, 默认为 0.0) — 注意力概率的 dropout 比率。 -
drop_path_rate(float, 可选, 默认为 0.1) — 随机深度率。 -
hidden_act(str或function, 可选, 默认为"gelu") — 编码器中的非线性激活函数(函数或字符串)。如果是字符串,支持"gelu"、"relu"、"selu"和"gelu_new"。 -
use_absolute_embeddings(bool, 可选, 默认为False) — 是否将绝对位置嵌入添加到补丁嵌入中。 -
initializer_range(float, 可选, 默认为 0.02) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。 -
layer_norm_eps(float, 可选, 默认为 1e-05) — 层归一化层使用的 epsilon。 -
upscale(int, optional, 默认为 2) — 图像的放大因子。2/3/4/8 用于图像超分辨率,1 用于去噪和压缩伪影减少 -
img_range(float, optional, 默认为 1.0) — 输入图像值的范围。 -
resi_connection(str, optional, 默认为"1conv") — 在每个阶段的残差连接之前使用的卷积块。 -
upsampler(str, optional, 默认为"pixelshuffle") — 重建重建模块。可以是’pixelshuffle’/‘pixelshuffledirect’/‘nearest+conv’/None。
这是用于存储 Swin2SRModel 配置的配置类。根据指定的参数实例化 Swin Transformer v2 模型,定义模型架构。使用默认值实例化配置将产生类似于 Swin Transformer v2 caidas/swin2sr-classicalsr-x2-64 架构的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读 PretrainedConfig 的文档以获取更多信息。
示例:
>>> from transformers import Swin2SRConfig, Swin2SRModel
>>> # Initializing a Swin2SR caidas/swin2sr-classicalsr-x2-64 style configuration
>>> configuration = Swin2SRConfig()
>>> # Initializing a model (with random weights) from the caidas/swin2sr-classicalsr-x2-64 style configuration
>>> model = Swin2SRModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configSwin2SRModel
class transformers.Swin2SRModel
( config )参数
config(Swin2SRConfig) — 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
裸的 Swin2SR 模型变压器输出原始隐藏状态,没有特定的头部。此模型是 PyTorch torch.nn.Module 的子类。将其用作常规的 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有信息。
forward
( pixel_values: FloatTensor head_mask: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.BaseModelOutput or tuple(torch.FloatTensor)参数
-
pixel_values(torch.FloatTensor,形状为(batch_size, num_channels, height, width)) — 像素值。可以使用 AutoImageProcessor 获取像素值。有关详细信息,请参阅 Swin2SRImageProcessor.call()。 -
head_mask(torch.FloatTensor,形状为(num_heads,)或(num_layers, num_heads),optional) — 用于使自注意力模块中选择的头部失效的掩码。掩码值选在[0, 1]之间:- 1 表示头部未被遮罩,
- 0 表示头部被遮罩。
-
output_attentions(bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请查看返回的张量下的attentions。 -
output_hidden_states(bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请查看返回的张量下的hidden_states。 -
return_dict(bool, optional) — 是否返回 ModelOutput 而不是普通元组。
返回值
transformers.modeling_outputs.BaseModelOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.BaseModelOutput 或一个torch.FloatTensor元组(如果传递return_dict=False或config.return_dict=False时)包含各种元素,取决于配置(Swin2SRConfig)和输入。
-
last_hidden_state(形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor)- 模型最后一层的隐藏状态序列。 -
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回)- 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(如果模型有嵌入层,则为嵌入的输出+每个层的输出)。 模型每层输出的隐藏状态以及可选的初始嵌入输出。 -
attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回)- 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每个层一个)。 注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
Swin2SRModel 的前向方法,覆盖__call__特殊方法。
虽然前向传递的步骤需要在此函数内定义,但应该在此之后调用Module实例,而不是在此处调用,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoImageProcessor, Swin2SRModel
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image")
>>> image = dataset["test"]["image"][0]
>>> image_processor = AutoImageProcessor.from_pretrained("caidas/swin2SR-classical-sr-x2-64")
>>> model = Swin2SRModel.from_pretrained("caidas/swin2SR-classical-sr-x2-64")
>>> inputs = image_processor(image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
>>> list(last_hidden_states.shape)
[1, 180, 488, 648]Swin2SRForImageSuperResolution
class transformers.Swin2SRForImageSuperResolution
( config )参数
config(Swin2SRConfig)- 模型的所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
Swin2SR 模型变压器,顶部带有上采样器头,用于图像超分辨率和恢复。
此模型是 PyTorch torch.nn.Module子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有相关信息。
forward
( pixel_values: Optional = None head_mask: Optional = None labels: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.ImageSuperResolutionOutput or tuple(torch.FloatTensor)参数
-
pixel_values(形状为(batch_size, num_channels, height, width)的torch.FloatTensor)- 像素值。可以使用 AutoImageProcessor 获取像素值。有关详细信息,请参阅 Swin2SRImageProcessor.call()。 -
head_mask(形状为(num_heads,)或(num_layers, num_heads)的torch.FloatTensor,可选)- 用于使自注意力模块中选择的头部失效的掩码。在[0, 1]中选择的掩码值:- 1 表示头部未被
masked, - 0 表示头部是
masked。
- 1 表示头部未被
-
output_attentions(bool,可选)- 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 -
output_hidden_states(bool,可选)- 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 -
return_dict(bool,可选)— 是否返回一个 ModelOutput 而不是一个普通的元组。
返回
transformers.modeling_outputs.ImageSuperResolutionOutput或tuple(torch.FloatTensor)
一个transformers.modeling_outputs.ImageSuperResolutionOutput或一个torch.FloatTensor元组(如果传递return_dict=False或config.return_dict=False)包含根据配置(Swin2SRConfig)和输入的不同元素。
-
loss(形状为(1,)的torch.FloatTensor,可选,当提供labels时返回)— 重构损失。 -
reconstruction(形状为(batch_size, num_channels, height, width)的torch.FloatTensor)— 重建的图像,可能是放大的。 -
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回)— 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(如果模型有嵌入层,则为嵌入的输出+每个阶段的输出)。模型在每个阶段输出的隐藏状态(也称为特征图)。 -
attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回)— 形状为(batch_size, num_heads, patch_size, sequence_length)的torch.FloatTensor元组(每层一个)。 在注意力 softmax 之后的注意力权重,用于计算自注意力头中的加权平均值。
Swin2SRForImageSuperResolution 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的配方需要在这个函数内定义,但应该在此之后调用Module实例,而不是在此之后调用,因为前者负责运行预处理和后处理步骤,而后者则默默地忽略它们。
示例:
>>> import torch
>>> import numpy as np
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoImageProcessor, Swin2SRForImageSuperResolution
>>> processor = AutoImageProcessor.from_pretrained("caidas/swin2SR-classical-sr-x2-64")
>>> model = Swin2SRForImageSuperResolution.from_pretrained("caidas/swin2SR-classical-sr-x2-64")
>>> url = "https://huggingface.co/spaces/jjourney1125/swin2sr/resolve/main/samples/butterfly.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> # prepare image for the model
>>> inputs = processor(image, return_tensors="pt")
>>> # forward pass
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> output = outputs.reconstruction.data.squeeze().float().cpu().clamp_(0, 1).numpy()
>>> output = np.moveaxis(output, source=0, destination=-1)
>>> output = (output * 255.0).round().astype(np.uint8) # float32 to uint8
>>> # you can visualize `output` with `Image.fromarray`Table Transformer
原文链接:
huggingface.co/docs/transformers/v4.37.2/en/model_doc/table-transformer
概述
Table Transformer 模型是由 Brandon Smock、Rohith Pesala 和 Robin Abraham 在 PubTables-1M: Towards comprehensive table extraction from unstructured documents 中提出的。作者引入了一个新数据集 PubTables-1M,用于评估从非结构化文档中提取表格、表结构识别和功能分析的进展。作者训练了两个 DETR 模型,一个用于表检测,一个用于表结构识别,被称为 Table Transformers。
论文摘要如下:
最近,在将机器学习应用于从非结构化文档中推断和提取表结构方面取得了重大进展。然而,最大的挑战之一仍然是在规模上创建具有完整、明确的地面真实数据集。为了解决这个问题,我们开发了一个新的更全面的表提取数据集,名为 PubTables-1M。PubTables-1M 包含来自科学文章的近一百万张表,支持多种输入模态,并包含详细的表头和位置信息,对于各种建模方法都很有用。它还通过一种新颖的规范化过程解决了先前数据集中观察到的地面真实不一致的重要来源,称为过分分割。我们展示这些改进导致训练性能显著提高,并在表结构识别的评估中获得更可靠的模型性能估计。此外,我们展示基于 PubTables-1M 训练的基于 transformer 的目标检测模型在检测、结构识别和功能分析的三个任务中产生出色的结果,而无需为这些任务进行任何特殊定制。
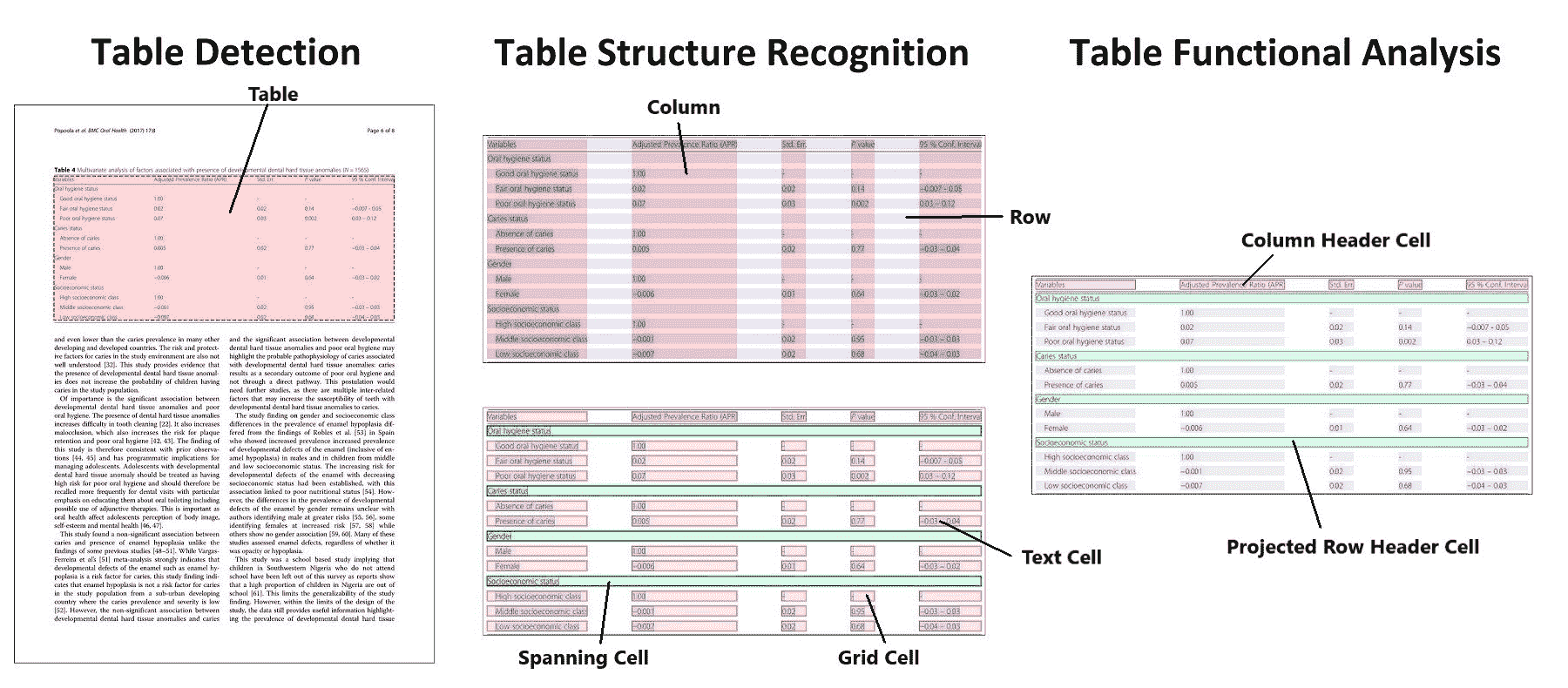
表检测和表结构识别的澄清。摘自原始论文。
作者发布了两个模型,一个用于文档中的表检测,一个用于表结构识别(识别表中的各行、列等任务)。
此模型由 nielsr 贡献。原始代码可以在这里找到 链接。
资源
目标检测
TableTransformerConfig
class transformers.TableTransformerConfig
( use_timm_backbone = True backbone_config = None num_channels = 3 num_queries = 100 encoder_layers = 6 encoder_ffn_dim = 2048 encoder_attention_heads = 8 decoder_layers = 6 decoder_ffn_dim = 2048 decoder_attention_heads = 8 encoder_layerdrop = 0.0 decoder_layerdrop = 0.0 is_encoder_decoder = True activation_function = 'relu' d_model = 256 dropout = 0.1 attention_dropout = 0.0 activation_dropout = 0.0 init_std = 0.02 init_xavier_std = 1.0 auxiliary_loss = False position_embedding_type = 'sine' backbone = 'resnet50' use_pretrained_backbone = True dilation = False class_cost = 1 bbox_cost = 5 giou_cost = 2 mask_loss_coefficient = 1 dice_loss_coefficient = 1 bbox_loss_coefficient = 5 giou_loss_coefficient = 2 eos_coefficient = 0.1 **kwargs )参数
-
use_timm_backbone(bool,可选,默认为True) — 是否使用timm库作为骨干。如果设置为False,将使用AutoBackboneAPI。 -
backbone_config(PretrainedConfig或dict,可选) — 骨干模型的配置。仅在设置use_timm_backbone为False时使用,此时默认为ResNetConfig()。 -
num_channels(int,可选,默认为 3) — 输入通道数。 -
num_queries(int, optional, 默认为 100) — 对象查询的数量,即检测槽位。这是 TableTransformerModel 在单个图像中可以检测到的对象的最大数量。对于 COCO,我们建议使用 100 个查询。 -
d_model(int, optional, 默认为 256) — 层的维度。 -
encoder_layers(int, optional, 默认为 6) — 编码器层的数量。 -
decoder_layers(int, optional, 默认为 6) — 解码器层的数量。 -
encoder_attention_heads(int, optional, 默认为 8) — Transformer 编码器中每个注意力层的注意力头数。 -
decoder_attention_heads(int, optional, 默认为 8) — Transformer 解码器中每个注意力层的注意力头数。 -
decoder_ffn_dim(int, optional, 默认为 2048) — 解码器中“中间”(通常称为前馈)层的维度。 -
encoder_ffn_dim(int, optional, 默认为 2048) — 解码器中“中间”(通常称为前馈)层的维度。 -
activation_function(str或function, optional, 默认为"relu") — 编码器和池化器中的非线性激活函数(函数或字符串)。如果是字符串,支持"gelu","relu","silu"和"gelu_new"。 -
dropout(float, optional, 默认为 0.1) — 嵌入、编码器和池化器中所有全连接层的丢失概率。 -
attention_dropout(float, optional, 默认为 0.0) — 注意力概率的丢失比率。 -
activation_dropout(float, optional, 默认为 0.0) — 全连接层内激活的丢失比率。 -
init_std(float, optional, 默认为 0.02) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。 -
init_xavier_std(float, optional, 默认为 1) — 用于 HM Attention map 模块中的 Xavier 初始化增益的缩放因子。 -
encoder_layerdrop(float, optional, 默认为 0.0) — 编码器的 LayerDrop 概率。更多细节请参阅 LayerDrop 论文)。 -
decoder_layerdrop(float, optional, 默认为 0.0) — 解码器的 LayerDrop 概率。更多细节请参阅 LayerDrop 论文)。 -
auxiliary_loss(bool, optional, 默认为False) — 是否使用辅助解码损失(每个解码器层的损失)。 -
position_embedding_type(str, optional, 默认为"sine") — 在图像特征之上使用的位置嵌入的类型。可以是"sine"或"learned"中的一个。 -
backbone(str, optional, 默认为"resnet50") — 在use_timm_backbone=True时要使用的卷积主干的名称。支持来自 timm 包的任何卷积主干。有关所有可用模型的列表,请参阅 此页面。 -
use_pretrained_backbone(bool, optional, 默认为True) — 是否使用主干的预训练权重。仅在use_timm_backbone=True时支持。 -
dilation(bool, optional, 默认为False) — 是否在最后的卷积块(DC5)中用膨胀替代步幅。仅在use_timm_backbone=True时支持。 -
class_cost(float, optional, 默认为 1) — 匈牙利匹配成本中分类错误的相对权重。 -
bbox_cost(float, optional, 默认为 5) — 匈牙利匹配成本中边界框坐标的 L1 误差的相对权重。 -
giou_cost(float, optional, 默认为 2) — 匈牙利匹配成本中边界框广义 IoU 损失的相对权重。 -
mask_loss_coefficient(float,可选,默认为 1)—全景分割损失中 Focal 损失的相对权重。 -
dice_loss_coefficient(float,可选,默认为 1)—DICE/F-1 损失在全景分割损失中的相对权重。 -
bbox_loss_coefficient(float,可选,默认为 5)—目标检测损失中 L1 边界框损失的相对权重。 -
giou_loss_coefficient(float,可选,默认为 2)—广义 IoU 损失在目标检测损失中的相对权重。 -
eos_coefficient(float,可选,默认为 0.1)—目标检测损失中“无对象”类的相对分类权重。
这是配置类,用于存储 TableTransformerModel 的配置。它用于根据指定的参数实例化一个 Table Transformer 模型,定义模型架构。使用默认值实例化配置将产生类似于 Table Transformer microsoft/table-transformer-detection架构的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读 PretrainedConfig 的文档以获取更多信息。
示例:
>>> from transformers import TableTransformerModel, TableTransformerConfig
>>> # Initializing a Table Transformer microsoft/table-transformer-detection style configuration
>>> configuration = TableTransformerConfig()
>>> # Initializing a model from the microsoft/table-transformer-detection style configuration
>>> model = TableTransformerModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configTableTransformerModel
class transformers.TableTransformerModel
( config: TableTransformerConfig )参数
config(TableTransformerConfig)—模型配置类,具有所有模型参数。使用配置文件初始化不会加载与模型关联的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
裸 Table Transformer 模型(由骨干和编码器-解码器 Transformer 组成),输出原始隐藏状态,没有特定的头部。
此模型继承自 PreTrainedModel。查看超类文档以了解库为所有模型实现的通用方法(例如下载或保存、调整输入嵌入、修剪头等)。
此模型还是 PyTorch torch.nn.Module子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有相关信息。
forward
( pixel_values: FloatTensor pixel_mask: Optional = None decoder_attention_mask: Optional = None encoder_outputs: Optional = None inputs_embeds: Optional = None decoder_inputs_embeds: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.models.table_transformer.modeling_table_transformer.TableTransformerModelOutput or tuple(torch.FloatTensor)参数
-
pixel_values(形状为(batch_size, num_channels, height, width)的torch.FloatTensor)—像素值。默认情况下将忽略填充。 可以使用 DetrImageProcessor 获取像素值。有关详细信息,请参阅 DetrImageProcessor.call()。 -
pixel_mask(形状为(batch_size, height, width)的torch.FloatTensor,可选)—遮罩,避免在填充像素值上执行注意力。遮罩值选择在[0, 1]中:- 1 表示真实像素(即
未遮罩), - 0 表示填充像素(即
遮罩)。
注意力蒙版是什么?
- 1 表示真实像素(即
-
decoder_attention_mask(torch.FloatTensorof shape(batch_size, num_queries), 可选) — 默认情况下不使用。可用于屏蔽对象查询。 -
encoder_outputs(tuple(tuple(torch.FloatTensor), 可选) — 元组包括(last_hidden_state, 可选:hidden_states, 可选:attentions)last_hidden_state的形状为(batch_size, sequence_length, hidden_size),可选) 是编码器最后一层的隐藏状态序列。用于解码器的交叉注意力。 -
inputs_embeds(torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), 可选) — 可选地,您可以选择直接传递图像的扁平化表示,而不是传递扁平化特征图(骨干网络输出+投影层的输出)。 -
decoder_inputs_embeds(torch.FloatTensorof shape(batch_size, num_queries, hidden_size), 可选) — 可选地,您可以选择直接传递嵌入表示,而不是用零张量初始化查询。 -
output_attentions(bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 -
output_hidden_states(bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 -
return_dict(bool, 可选) — 是否返回 ModelOutput 而不是普通元组。
返回
transformers.models.table_transformer.modeling_table_transformer.TableTransformerModelOutput 或 tuple(torch.FloatTensor)
一个transformers.models.table_transformer.modeling_table_transformer.TableTransformerModelOutput或一个torch.FloatTensor元组(如果传递return_dict=False或config.return_dict=False)包含根据配置(TableTransformerConfig)和输入的不同元素。
-
last_hidden_state(torch.FloatTensorof shape(batch_size, sequence_length, hidden_size)) — 模型解码器最后一层的隐藏状态序列。 -
decoder_hidden_states(tuple(torch.FloatTensor), 可选, 当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 元组torch.FloatTensor(一个用于嵌入输出,一个用于每层输出)的形状为(batch_size, sequence_length, hidden_size)。解码器每层输出的隐藏状态加上初始嵌入输出。 -
decoder_attentions(tuple(torch.FloatTensor), 可选, 当传递output_attentions=True或config.output_attentions=True时返回) — 元组torch.FloatTensor(每层一个)的形状为(batch_size, num_heads, sequence_length, sequence_length)。解码器的注意力权重,在注意力 softmax 之后,用于计算自注意力头中的加权平均值。 -
cross_attentions(tuple(torch.FloatTensor), 可选, 当传递output_attentions=True或config.output_attentions=True时返回) — 元组torch.FloatTensor(每层一个)的形状为(batch_size, num_heads, sequence_length, sequence_length)。解码器的交叉注意力层的注意力权重,在注意力 softmax 之后,用于计算交叉注意力头中的加权平均值。 -
encoder_last_hidden_state(torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), 可选) — 模型编码器最后一层的隐藏状态序列。 -
encoder_hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回) —torch.FloatTensor元组(一个用于嵌入的输出 + 一个用于每个层的输出)的形状为(batch_size, sequence_length, hidden_size)。编码器在每个层的隐藏状态加上初始嵌入输出。 -
encoder_attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或当config.output_attentions=True时返回) —torch.FloatTensor元组(每个层一个)的形状为(batch_size, num_heads, sequence_length, sequence_length)。编码器的注意力权重,在注意力 softmax 之后使用,用于计算自注意力头中的加权平均值。 -
intermediate_hidden_states(torch.FloatTensor,形状为(config.decoder_layers, batch_size, sequence_length, hidden_size),可选,当config.auxiliary_loss=True时返回) — 中间解码器激活,即每个解码器层的输出,每个都经过了一个 layernorm。
TableTransformerModel 的前向方法,覆盖了 __call__ 特殊方法。
虽然前向传递的步骤需要在这个函数内定义,但应该在此之后调用 Module 实例,而不是这个,因为前者会处理运行前后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoImageProcessor, TableTransformerModel
>>> from huggingface_hub import hf_hub_download
>>> from PIL import Image
>>> file_path = hf_hub_download(repo_id="nielsr/example-pdf", repo_type="dataset", filename="example_pdf.png")
>>> image = Image.open(file_path).convert("RGB")
>>> image_processor = AutoImageProcessor.from_pretrained("microsoft/table-transformer-detection")
>>> model = TableTransformerModel.from_pretrained("microsoft/table-transformer-detection")
>>> # prepare image for the model
>>> inputs = image_processor(images=image, return_tensors="pt")
>>> # forward pass
>>> outputs = model(**inputs)
>>> # the last hidden states are the final query embeddings of the Transformer decoder
>>> # these are of shape (batch_size, num_queries, hidden_size)
>>> last_hidden_states = outputs.last_hidden_state
>>> list(last_hidden_states.shape)
[1, 15, 256]TableTransformerForObjectDetection
class transformers.TableTransformerForObjectDetection
( config: TableTransformerConfig )参数
config(TableTransformerConfig) — 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型关联的权重,只加载配置。查看 from_pretrained() 方法以加载模型权重。
Table Transformer Model(由主干和编码器-解码器 Transformer 组成),顶部带有目标检测头,用于诸如 COCO 检测之类的任务。
这个模型继承自 PreTrainedModel。查看超类文档以了解库为所有模型实现的通用方法(如下载或保存、调整输入嵌入、修剪头等)。
这个模型也是 PyTorch torch.nn.Module 的子类。将其用作常规的 PyTorch 模块,并参考 PyTorch 文档以了解所有与一般用法和行为相关的事项。
forward
( pixel_values: FloatTensor pixel_mask: Optional = None decoder_attention_mask: Optional = None encoder_outputs: Optional = None inputs_embeds: Optional = None decoder_inputs_embeds: Optional = None labels: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.models.table_transformer.modeling_table_transformer.TableTransformerObjectDetectionOutput or tuple(torch.FloatTensor)参数
-
pixel_values(torch.FloatTensor,形状为(batch_size, num_channels, height, width)) — 像素值。默认情况下将忽略填充。 可以使用 DetrImageProcessor 获取像素值。有关详细信息,请参阅 DetrImageProcessor.call()。 -
pixel_mask(torch.FloatTensor,形状为(batch_size, height, width),可选) — 遮罩,避免在填充像素值上执行注意力。遮罩值选择在[0, 1]中:- 1 代表真实像素(即
not masked), - 0 代表填充像素(即
masked)。
什么是注意力遮罩?
- 1 代表真实像素(即
-
decoder_attention_mask(torch.FloatTensorof shape(batch_size, num_queries), optional) — 默认情况下不使用。可用于屏蔽对象查询。 -
encoder_outputs(tuple(tuple(torch.FloatTensor), optional) — 元组包括(last_hidden_state,可选:hidden_states,可选:attentions)last_hidden_state的形状为(batch_size, sequence_length, hidden_size),可选是编码器最后一层输出的隐藏状态序列。用于解码器的交叉注意力。 -
inputs_embeds(torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — 可选,可以选择直接传递图像的扁平化表示,而不是传递骨干网络+投影层的扁平化特征图。 -
decoder_inputs_embeds(torch.FloatTensorof shape(batch_size, num_queries, hidden_size), optional) — 可选,可以选择直接传递嵌入表示,而不是用零张量初始化查询。 -
output_attentions(bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 -
output_hidden_states(bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 -
return_dict(bool, optional) — 是否返回 ModelOutput 而不是普通元组。 -
labels(List[Dict]of len(batch_size,), optional) — 用于计算二分匹配损失的标签。字典列表,每个字典至少包含以下 2 个键:‘class_labels’和’boxes’(分别是批次中图像的类标签和边界框)。类标签本身应该是长度为(图像中边界框的数量,)的torch.LongTensor,而边界框应该是形状为(图像中边界框的数量, 4)的torch.FloatTensor。
返回
transformers.models.table_transformer.modeling_table_transformer.TableTransformerObjectDetectionOutput 或 tuple(torch.FloatTensor)
一个transformers.models.table_transformer.modeling_table_transformer.TableTransformerObjectDetectionOutput或一个torch.FloatTensor的元组(如果传递return_dict=False或config.return_dict=False时)包含根据配置(TableTransformerConfig)和输入的不同元素。
-
loss(torch.FloatTensorof shape(1,), optional, 当提供labels时返回) — 作为负对数似然(交叉熵)和边界框损失的线性组合的总损失。后者被定义为 L1 损失和广义比例不变 IoU 损失的线性组合。 -
loss_dict(Dict, optional) — 包含各个损失的字典。用于记录。 -
logits(torch.FloatTensorof shape(batch_size, num_queries, num_classes + 1)) — 包括无对象在内的所有查询的分类 logits。 -
pred_boxes(torch.FloatTensorof shape(batch_size, num_queries, 4)) — 所有查询的归一化框坐标,表示为(中心 _x,中心 _y,宽度,高度)。这些值在[0, 1]范围内归一化,相对于批次中每个单独图像的大小(忽略可能的填充)。您可以使用~TableTransformerImageProcessor.post_process_object_detection来检索未归一化的边界框。 -
auxiliary_outputs(list[Dict], optional) — 可选,仅在激活辅助损失(即config.auxiliary_loss设置为True)并提供标签时返回。它是一个字典列表,包含每个解码器层的上述两个键(logits和pred_boxes)。 -
last_hidden_state(torch.FloatTensor,形状为(batch_size, sequence_length, hidden_size),optional) — 模型解码器最后一层的隐藏状态序列。 -
decoder_hidden_states(tuple(torch.FloatTensor),optional,当传递output_hidden_states=True或config.output_hidden_states=True时返回) —torch.FloatTensor元组(嵌入输出和每层输出各一个),形状为(batch_size, sequence_length, hidden_size)。解码器在每层输出的隐藏状态加上初始嵌入输出。 -
decoder_attentions(tuple(torch.FloatTensor),optional,当传递output_attentions=True或config.output_attentions=True时返回) —torch.FloatTensor元组(每层一个),形状为(batch_size, num_heads, sequence_length, sequence_length)。解码器的注意力权重,在注意力 softmax 之后,用于计算自注意力头中的加权平均值。 -
cross_attentions(tuple(torch.FloatTensor),optional,当传递output_attentions=True或config.output_attentions=True时返回) —torch.FloatTensor元组(每层一个),形状为(batch_size, num_heads, sequence_length, sequence_length)。解码器的交叉注意力层的注意力权重,在注意力 softmax 之后,用于计算交叉注意力头中的加权平均值。 -
encoder_last_hidden_state(torch.FloatTensor,形状为(batch_size, sequence_length, hidden_size),optional) — 模型编码器最后一层的隐藏状态序列。 -
encoder_hidden_states(tuple(torch.FloatTensor),optional,当传递output_hidden_states=True或config.output_hidden_states=True时返回) —torch.FloatTensor元组(嵌入输出和每层输出各一个),形状为(batch_size, sequence_length, hidden_size)。编码器在每层输出的隐藏状态加上初始嵌入输出。 -
encoder_attentions(tuple(torch.FloatTensor), optional, 当传递output_attentions=True或config.output_attentions=True时返回) —torch.FloatTensor元组(每层一个),形状为(batch_size, num_heads, sequence_length, sequence_length)。编码器的注意力权重,在注意力 softmax 之后,用于计算自注意力头中的加权平均值。
TableTransformerForObjectDetection 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的步骤需要在此函数内定义,但应该在此之后调用Module实例,而不是在此函数内调用,因为前者会处理运行前后处理步骤,而后者会默默地忽略它们。
示例:
>>> from huggingface_hub import hf_hub_download
>>> from transformers import AutoImageProcessor, TableTransformerForObjectDetection
>>> import torch
>>> from PIL import Image
>>> file_path = hf_hub_download(repo_id="nielsr/example-pdf", repo_type="dataset", filename="example_pdf.png")
>>> image = Image.open(file_path).convert("RGB")
>>> image_processor = AutoImageProcessor.from_pretrained("microsoft/table-transformer-detection")
>>> model = TableTransformerForObjectDetection.from_pretrained("microsoft/table-transformer-detection")
>>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> # convert outputs (bounding boxes and class logits) to Pascal VOC format (xmin, ymin, xmax, ymax)
>>> target_sizes = torch.tensor([image.size[::-1]])
>>> results = image_processor.post_process_object_detection(outputs, threshold=0.9, target_sizes=target_sizes)[
... 0
... ]
>>> for score, label, box in zip(results["scores"], results["labels"], results["boxes"]):
... box = [round(i, 2) for i in box.tolist()]
... print(
... f"Detected {model.config.id2label[label.item()]} with confidence "
... f"{round(score.item(), 3)} at location {box}"
... )
Detected table with confidence 1.0 at location [202.1, 210.59, 1119.22, 385.09]TimeSformer
原始文本:
huggingface.co/docs/transformers/v4.37.2/en/model_doc/timesformer
概述
TimeSformer 模型在 Facebook Research 的论文TimeSformer: Is Space-Time Attention All You Need for Video Understanding?中提出。这项工作是动作识别领域的里程碑,是第一个视频 Transformer。它启发了许多基于 Transformer 的视频理解和分类论文。
论文摘要如下:
我们提出了一种基于自注意力的视频分类无卷积方法,专门建立在空间和时间上。我们的方法名为“TimeSformer”,通过使标准 Transformer 架构适应视频,直接从一系列帧级补丁中实现时空特征学习。我们的实验研究比较了不同的自注意力方案,并建议“分割注意力”,其中在每个块内分别应用时间注意力和空间注意力,是考虑的设计选择中导致最佳视频分类准确性的。尽管设计全新,TimeSformer 在几个动作识别基准数据集上取得了最先进的结果,包括 Kinetics-400 和 Kinetics-600 上报告的最佳准确性。最后,与 3D 卷积网络相比,我们的模型训练速度更快,可以实现显著更高的测试效率(准确性略有下降),还可以应用于更长的视频剪辑(超过一分钟)。代码和模型可在此处找到:此链接。
使用提示
有许多预训练变体。根据模型训练的数据集选择预训练模型。此外,每个剪辑的输入帧数根据模型大小而变化,因此在选择预训练模型时应考虑此参数。
资源
- 视频分类任务指南
TimesformerConfig
class transformers.TimesformerConfig
( image_size = 224 patch_size = 16 num_channels = 3 num_frames = 8 hidden_size = 768 num_hidden_layers = 12 num_attention_heads = 12 intermediate_size = 3072 hidden_act = 'gelu' hidden_dropout_prob = 0.0 attention_probs_dropout_prob = 0.0 initializer_range = 0.02 layer_norm_eps = 1e-06 qkv_bias = True attention_type = 'divided_space_time' drop_path_rate = 0 **kwargs )参数
-
image_size(int,可选,默认为 224)— 每个图像的大小(分辨率)。 -
patch_size(int,可选,默认为 16)— 每个补丁的大小(分辨率)。 -
num_channels(int,可选,默认为 3)— 输入通道数。 -
num_frames(int,可选,默认为 8)— 每个视频中的帧数。 -
hidden_size(int,可选,默认为 768)— 编码器层和池化层的维度。 -
num_hidden_layers(int,可选,默认为 12)— Transformer 编码器中的隐藏层数。 -
num_attention_heads(int,可选,默认为 12)— Transformer 编码器中每个注意力层的注意力头数。 -
intermediate_size(int,可选,默认为 3072)— Transformer 编码器中“中间”(即前馈)层的维度。 -
hidden_act(str或function,可选,默认为"gelu") — 编码器和池化层中的非线性激活函数(函数或字符串)。如果是字符串,支持"gelu"、"relu"、"selu"和"gelu_new"。 -
hidden_dropout_prob(float,可选,默认为 0.0)— 嵌入层、编码器和池化层中所有全连接层的丢弃概率。 -
attention_probs_dropout_prob(float,可选,默认为 0.0)— 注意力概率的丢弃比率。 -
initializer_range(float,可选,默认为 0.02)— 用于初始化所有权重矩阵的截断正态初始化器的标准差。 -
layer_norm_eps(float, 可选, 默认为 1e-06) — 层归一化层使用的 epsilon。 -
qkv_bias(bool, 可选, 默认为True) — 是否向查询、键和值添加偏置。 -
attention_type(str, 可选, 默认为"divided_space_time") — 要使用的注意力类型。必须是"divided_space_time"、"space_only"或"joint_space_time"之一。 -
drop_path_rate(float, 可选, 默认为 0) — 随机深度的丢弃率。
这是用于存储 TimesformerModel 配置的配置类。它用于根据指定的参数实例化一个 TimeSformer 模型,定义模型架构。使用默认值实例化配置将产生类似于 TimeSformer facebook/timesformer-base-finetuned-k600架构的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读 PretrainedConfig 的文档以获取更多信息。
示例:
>>> from transformers import TimesformerConfig, TimesformerModel
>>> # Initializing a TimeSformer timesformer-base style configuration
>>> configuration = TimesformerConfig()
>>> # Initializing a model from the configuration
>>> model = TimesformerModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configTimesformerModel
class transformers.TimesformerModel
( config )参数
config(TimesformerConfig) — 包含模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained()方法以加载模型权重。
裸的 TimeSformer 模型变压器输出原始隐藏状态,没有特定的头部。此模型是 PyTorch torch.nn.Module子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有相关信息。
前向传播
( pixel_values: FloatTensor output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.BaseModelOutput or tuple(torch.FloatTensor)参数
-
pixel_values(torch.FloatTensor,形状为(batch_size, num_frames, num_channels, height, width)) — 像素值。像素值可以使用 AutoImageProcessor 获取。有关详细信息,请参阅 VideoMAEImageProcessor.preprocess()。 -
output_attentions(bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请查看返回张量下的attentions。 -
output_hidden_states(bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请查看返回张量下的hidden_states。 -
return_dict(bool, 可选) — 是否返回 ModelOutput 而不是普通元组。
返回
transformers.modeling_outputs.BaseModelOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.BaseModelOutput 或一个torch.FloatTensor元组(如果传递了return_dict=False或config.return_dict=False时)包含根据配置(TimesformerConfig)和输入的各种元素。
-
last_hidden_state(形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor) — 模型最后一层的隐藏状态序列。 -
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(一个用于嵌入的输出,如果模型有一个嵌入层,+ 一个用于每一层的输出)。 模型在每一层输出的隐藏状态以及可选的初始嵌入输出。 -
attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。 在注意力 softmax 之后的注意力权重,用于计算自注意力头中的加权平均值。
TimesformerModel 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的步骤需要在此函数内定义,但应该在此之后调用Module实例,而不是在此处调用,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> import av
>>> import numpy as np
>>> from transformers import AutoImageProcessor, TimesformerModel
>>> from huggingface_hub import hf_hub_download
>>> np.random.seed(0)
>>> def read_video_pyav(container, indices):
... '''
... Decode the video with PyAV decoder.
... Args:
... container (`av.container.input.InputContainer`): PyAV container.
... indices (`List[int]`): List of frame indices to decode.
... Returns:
... result (np.ndarray): np array of decoded frames of shape (num_frames, height, width, 3).
... '''
... frames = []
... container.seek(0)
... start_index = indices[0]
... end_index = indices[-1]
... for i, frame in enumerate(container.decode(video=0)):
... if i > end_index:
... break
... if i >= start_index and i in indices:
... frames.append(frame)
... return np.stack([x.to_ndarray(format="rgb24") for x in frames])
>>> def sample_frame_indices(clip_len, frame_sample_rate, seg_len):
... '''
... Sample a given number of frame indices from the video.
... Args:
... clip_len (`int`): Total number of frames to sample.
... frame_sample_rate (`int`): Sample every n-th frame.
... seg_len (`int`): Maximum allowed index of sample's last frame.
... Returns:
... indices (`List[int]`): List of sampled frame indices
... '''
... converted_len = int(clip_len * frame_sample_rate)
... end_idx = np.random.randint(converted_len, seg_len)
... start_idx = end_idx - converted_len
... indices = np.linspace(start_idx, end_idx, num=clip_len)
... indices = np.clip(indices, start_idx, end_idx - 1).astype(np.int64)
... return indices
>>> # video clip consists of 300 frames (10 seconds at 30 FPS)
>>> file_path = hf_hub_download(
... repo_id="nielsr/video-demo", filename="eating_spaghetti.mp4", repo_type="dataset"
... )
>>> container = av.open(file_path)
>>> # sample 8 frames
>>> indices = sample_frame_indices(clip_len=8, frame_sample_rate=4, seg_len=container.streams.video[0].frames)
>>> video = read_video_pyav(container, indices)
>>> image_processor = AutoImageProcessor.from_pretrained("MCG-NJU/videomae-base")
>>> model = TimesformerModel.from_pretrained("facebook/timesformer-base-finetuned-k400")
>>> # prepare video for the model
>>> inputs = image_processor(list(video), return_tensors="pt")
>>> # forward pass
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
>>> list(last_hidden_states.shape)
[1, 1569, 768]TimesformerForVideoClassification
class transformers.TimesformerForVideoClassification
( config )参数
config(TimesformerConfig) — 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型关联的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
TimeSformer 模型变压器,顶部带有视频分类头(在[CLS]标记的最终隐藏状态之上的线性层),例如用于 ImageNet。此模型是 PyTorch 的torch.nn.Module子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取与一般用法和行为相关的所有内容。
forward
( pixel_values: Optional = None labels: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.ImageClassifierOutput or tuple(torch.FloatTensor)参数
-
pixel_values(形状为(batch_size, num_frames, num_channels, height, width)的torch.FloatTensor) — 像素值。像素值可以使用 AutoImageProcessor 获取。有关详细信息,请参阅 VideoMAEImageProcessor.preprocess()。 -
output_attentions(bool,可选) — 是否返回所有注意力层的注意力张量。有关更多细节,请参阅返回张量下的attentions。 -
output_hidden_states(bool,可选) — 是否返回所有层的隐藏状态。有关更多细节,请参阅返回张量下的hidden_states。 -
return_dict(bool,可选) — 是否返回 ModelOutput 而不是普通元组。 -
labels(torch.LongTensorof shape(batch_size,),可选) — 用于计算图像分类/回归损失的标签。索引应在[0, ..., config.num_labels - 1]范围内。如果config.num_labels == 1,则计算回归损失(均方损失),如果config.num_labels > 1,则计算分类损失(交叉熵)。
返回
transformers.modeling_outputs.ImageClassifierOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.ImageClassifierOutput 或一个torch.FloatTensor元组(如果传递了return_dict=False或config.return_dict=False时)包含各种元素,取决于配置(TimesformerConfig)和输入。
-
loss(torch.FloatTensorof shape(1,),可选,当提供labels时返回) — 分类(如果config.num_labels==1则为回归)损失。 -
logits(torch.FloatTensorof shape(batch_size, config.num_labels)) — 分类(如果config.num_labels==1则为回归)得分(SoftMax 之前)。 -
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(如果模型有嵌入层,则为嵌入的输出+每个阶段的输出)。模型在每个阶段输出的隐藏状态(也称为特征图)。 -
attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, patch_size, sequence_length)的torch.FloatTensor元组(每层一个)。 注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
TimesformerForVideoClassification 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的方法需要在此函数内定义,但应该在此之后调用Module实例,而不是这个,因为前者负责运行前后处理步骤,而后者会默默地忽略它们。
示例:
>>> import av
>>> import torch
>>> import numpy as np
>>> from transformers import AutoImageProcessor, TimesformerForVideoClassification
>>> from huggingface_hub import hf_hub_download
>>> np.random.seed(0)
>>> def read_video_pyav(container, indices):
... '''
... Decode the video with PyAV decoder.
... Args:
... container (`av.container.input.InputContainer`): PyAV container.
... indices (`List[int]`): List of frame indices to decode.
... Returns:
... result (np.ndarray): np array of decoded frames of shape (num_frames, height, width, 3).
... '''
... frames = []
... container.seek(0)
... start_index = indices[0]
... end_index = indices[-1]
... for i, frame in enumerate(container.decode(video=0)):
... if i > end_index:
... break
... if i >= start_index and i in indices:
... frames.append(frame)
... return np.stack([x.to_ndarray(format="rgb24") for x in frames])
>>> def sample_frame_indices(clip_len, frame_sample_rate, seg_len):
... '''
... Sample a given number of frame indices from the video.
... Args:
... clip_len (`int`): Total number of frames to sample.
... frame_sample_rate (`int`): Sample every n-th frame.
... seg_len (`int`): Maximum allowed index of sample's last frame.
... Returns:
... indices (`List[int]`): List of sampled frame indices
... '''
... converted_len = int(clip_len * frame_sample_rate)
... end_idx = np.random.randint(converted_len, seg_len)
... start_idx = end_idx - converted_len
... indices = np.linspace(start_idx, end_idx, num=clip_len)
... indices = np.clip(indices, start_idx, end_idx - 1).astype(np.int64)
... return indices
>>> # video clip consists of 300 frames (10 seconds at 30 FPS)
>>> file_path = hf_hub_download(
... repo_id="nielsr/video-demo", filename="eating_spaghetti.mp4", repo_type="dataset"
... )
>>> container = av.open(file_path)
>>> # sample 8 frames
>>> indices = sample_frame_indices(clip_len=8, frame_sample_rate=1, seg_len=container.streams.video[0].frames)
>>> video = read_video_pyav(container, indices)
>>> image_processor = AutoImageProcessor.from_pretrained("MCG-NJU/videomae-base-finetuned-kinetics")
>>> model = TimesformerForVideoClassification.from_pretrained("facebook/timesformer-base-finetuned-k400")
>>> inputs = image_processor(list(video), return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
... logits = outputs.logits
>>> # model predicts one of the 400 Kinetics-400 classes
>>> predicted_label = logits.argmax(-1).item()
>>> print(model.config.id2label[predicted_label])
eating spaghettiUPerNet
huggingface.co/docs/transformers/v4.37.2/en/model_doc/upernet
概述
UPerNet 模型是由肖特、刘英成、周博磊、姜玉宁、孙坚在统一感知解析用于场景理解中提出的。UPerNet 是一个通用框架,可以有效地从图像中分割各种概念,利用任何视觉骨干,如 ConvNeXt 或 Swin。
论文摘要如下:
人类在多个层次上识别视觉世界:我们轻松地对场景进行分类,并检测其中的对象,同时还识别对象的纹理和表面以及它们不同的组成部分。在本文中,我们研究了一个称为统一感知解析的新任务,该任务要求机器视觉系统从给定图像中尽可能识别尽可能多的视觉概念。开发了一个名为 UPerNet 的多任务框架和训练策略,以从异构图像注释中学习。我们在统一感知解析上对我们的框架进行基准测试,并展示它能够有效地从图像中分割各种概念。训练的网络进一步应用于发现自然场景中的视觉知识。
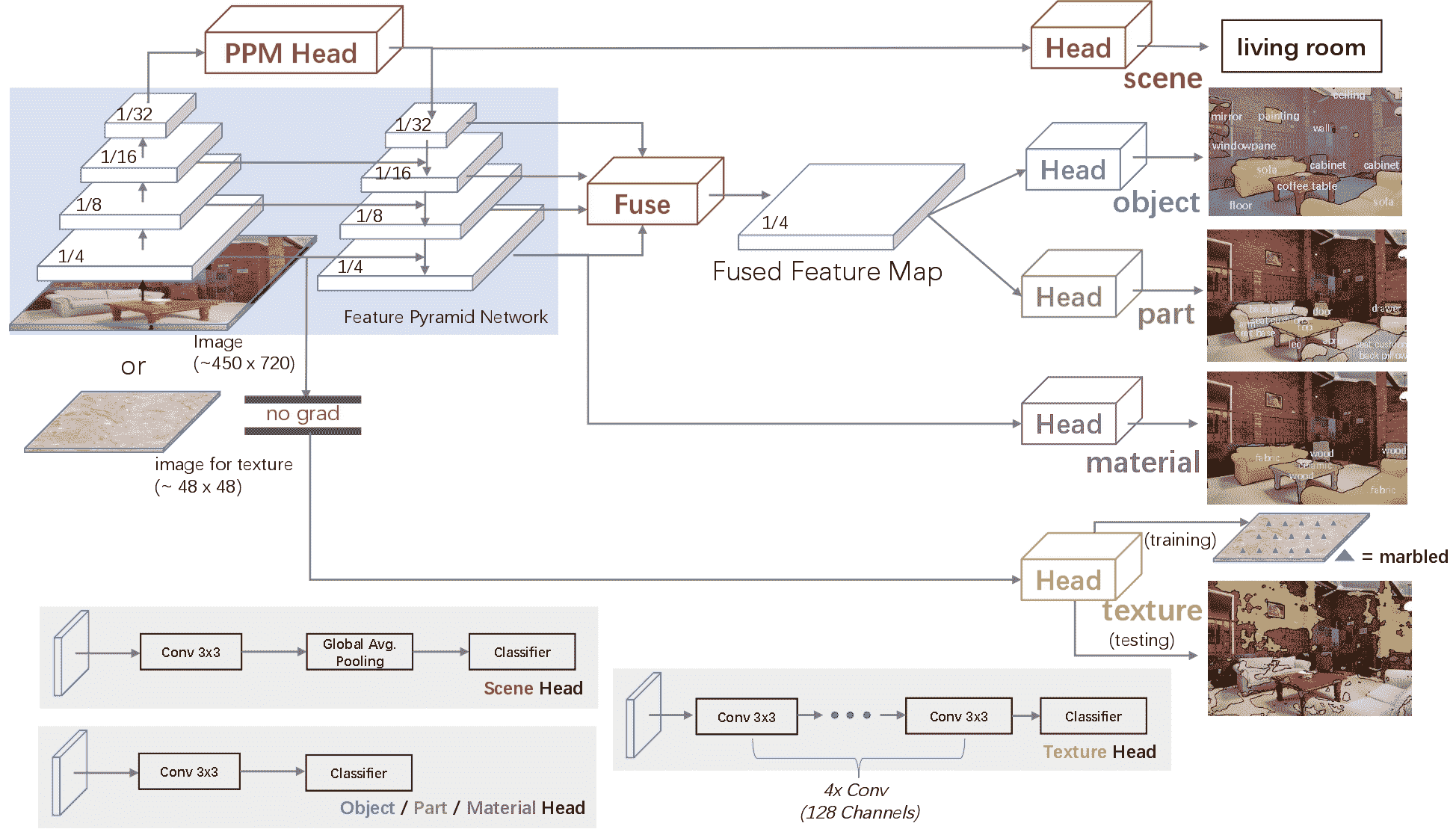
UPerNet 框架。取自原始论文。
该模型由nielsr贡献。原始代码基于 OpenMMLab 的 mmsegmentation 这里。
使用示例
UPerNet 是语义分割的通用框架。可以与任何视觉骨干一起使用,如:
from transformers import SwinConfig, UperNetConfig, UperNetForSemanticSegmentation
backbone_config = SwinConfig(out_features=["stage1", "stage2", "stage3", "stage4"])
config = UperNetConfig(backbone_config=backbone_config)
model = UperNetForSemanticSegmentation(config)要使用另一个视觉骨干,如 ConvNeXt,只需使用适当的骨干实例化模型:
from transformers import ConvNextConfig, UperNetConfig, UperNetForSemanticSegmentation
backbone_config = ConvNextConfig(out_features=["stage1", "stage2", "stage3", "stage4"])
config = UperNetConfig(backbone_config=backbone_config)
model = UperNetForSemanticSegmentation(config)请注意,这将随机初始化模型的所有权重。
资源
官方 Hugging Face 和社区(由🌎表示)资源列表,帮助您开始使用 UPerNet。
如果您有兴趣提交资源以包含在此处,请随时打开一个 Pull Request,我们将进行审查!资源应该展示一些新内容,而不是重复现有资源。
UperNetConfig
class transformers.UperNetConfig
( backbone_config = None hidden_size = 512 initializer_range = 0.02 pool_scales = [1, 2, 3, 6] use_auxiliary_head = True auxiliary_loss_weight = 0.4 auxiliary_in_channels = 384 auxiliary_channels = 256 auxiliary_num_convs = 1 auxiliary_concat_input = False loss_ignore_index = 255 **kwargs )参数
-
backbone_config(PretrainedConfig或dict, 可选, 默认为ResNetConfig()) — 骨干模型的配置。 -
hidden_size(int, 可选, 默认为 512) — 卷积层中隐藏单元的数量。 -
initializer_range(float, 可选, 默认为 0.02) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。 -
pool_scales(Tuple[int], 可选, 默认为[1, 2, 3, 6]) — 应用于最后特征图的 Pooling Pyramid Module 中使用的池化尺度。 -
use_auxiliary_head(bool, 可选, 默认为True) — 训练期间是否使用辅助头。 -
auxiliary_loss_weight(float, 可选, 默认为 0.4) — 辅助头的交叉熵损失的权重。 -
auxiliary_channels(int,可选,默认为 256) — 辅助头中要使用的通道数。 -
auxiliary_num_convs(int,可选,默认为 1) — 辅助头中要使用的卷积层数。 -
auxiliary_concat_input(bool,可选,默认为False) — 是否在分类层之前将辅助头的输出与输入连接。 -
loss_ignore_index(int,可选,默认为 255) — 损失函数忽略的索引。
这是一个配置类,用于存储 UperNetForSemanticSegmentation 的配置。它用于根据指定的参数实例化一个 UperNet 模型,定义模型架构。使用默认值实例化配置将产生类似于 UperNet openmmlab/upernet-convnext-tiny架构的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读 PretrainedConfig 的文档以获取更多信息。
示例:
>>> from transformers import UperNetConfig, UperNetForSemanticSegmentation
>>> # Initializing a configuration
>>> configuration = UperNetConfig()
>>> # Initializing a model (with random weights) from the configuration
>>> model = UperNetForSemanticSegmentation(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configUperNetForSemanticSegmentation
class transformers.UperNetForSemanticSegmentation
( config )参数
-
This模型是 PyTorch torch.nn.Module 子类。使用 -
it作为常规的 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有相关信息。配置(UperNetConfig):模型配置类,包含模型的所有参数。使用配置文件初始化不会加载与模型相关的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
UperNet 框架利用任何视觉骨干,例如 ADE20k,CityScapes。
forward
( pixel_values: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None labels: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.SemanticSegmenterOutput or tuple(torch.FloatTensor)参数
-
pixel_values(torch.FloatTensor,形状为(batch_size, num_channels, height, width)) — 像素值。默认情况下会忽略填充。可以使用 AutoImageProcessor 获取像素值。有关详细信息,请参阅 SegformerImageProcessor.call()。 -
output_attentions(bool,可选) — 是否返回骨干具有注意力张量的所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 -
output_hidden_states(bool,可选) — 是否返回骨干的所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 -
return_dict(bool,可选) — 是否返回 ModelOutput 而不是普通元组。 -
labels(torch.LongTensor,形状为(batch_size, height, width),可选) — 用于计算损失的地面真实语义分割地图。索引应在[0, ..., config.num_labels - 1]范围内。如果config.num_labels > 1,则计算分类损失(交叉熵)。
返回
transformers.modeling_outputs.SemanticSegmenterOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.SemanticSegmenterOutput 或一个torch.FloatTensor元组(如果传递return_dict=False或当config.return_dict=False时)包含根据配置(UperNetConfig)和输入而异的各种元素。
-
loss(torch.FloatTensor,形状为(1,), 可选的, 当提供labels时返回) — 分类(如果 config.num_labels==1 则为回归)损失。 -
logits(torch.FloatTensor,形状为(batch_size, config.num_labels, logits_height, logits_width)) — 每个像素的分类分数。 返回的 logits 不一定与作为输入传递的pixel_values具有相同的大小。这是为了避免进行两次插值并在用户需要将 logits 调整为原始图像大小时丢失一些质量。您应始终检查 logits 的形状并根据需要调整大小。 -
hidden_states(tuple(torch.FloatTensor), 可选的, 当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 形状为(batch_size, patch_size, hidden_size)的torch.FloatTensor元组(一个用于嵌入的输出,如果模型有嵌入层,+ 一个用于每个层的输出)。 模型在每个层输出的隐藏状态以及可选的初始嵌入输出。 -
attentions(tuple(torch.FloatTensor), 可选的, 当传递output_attentions=True或当config.output_attentions=True时返回) — 形状为(batch_size, num_heads, patch_size, sequence_length)的torch.FloatTensor元组(每个层一个)。 注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
UperNetForSemanticSegmentation 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的步骤需要在此函数内定义,但应该在此之后调用Module实例,而不是在此处调用,因为前者会负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoImageProcessor, UperNetForSemanticSegmentation
>>> from PIL import Image
>>> from huggingface_hub import hf_hub_download
>>> image_processor = AutoImageProcessor.from_pretrained("openmmlab/upernet-convnext-tiny")
>>> model = UperNetForSemanticSegmentation.from_pretrained("openmmlab/upernet-convnext-tiny")
>>> filepath = hf_hub_download(
... repo_id="hf-internal-testing/fixtures_ade20k", filename="ADE_val_00000001.jpg", repo_type="dataset"
... )
>>> image = Image.open(filepath).convert("RGB")
>>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> logits = outputs.logits # shape (batch_size, num_labels, height, width)
>>> list(logits.shape)
[1, 150, 512, 512]VAN
原文:
huggingface.co/docs/transformers/v4.37.2/en/model_doc/van
此模型仅处于维护模式,我们不接受任何更改其代码的新 PR。
如果您在运行此模型时遇到任何问题,请重新安装支持此模型的最后一个版本:v4.30.0。您可以通过运行以下命令来执行:pip install -U transformers==4.30.0。
概述
VAN 模型是由 Meng-Hao Guo,Cheng-Ze Lu,Zheng-Ning Liu,Ming-Ming Cheng,Shi-Min Hu 在Visual Attention Network中提出的。
这篇论文介绍了一种基于卷积操作的新型注意力层,能够捕捉局部和远距离关系。这是通过结合普通和大核卷积层来实现的。后者使用扩张卷积来捕捉远距离的相关性。
论文摘要如下:
尽管最初设计用于自然语言处理任务,但自注意机制最近在各种计算机视觉领域引起了轰动。然而,图像的 2D 性质为在计算机视觉中应用自注意带来了三个挑战。(1)将图像视为 1D 序列忽略了它们的 2D 结构。(2)二次复杂度对于高分辨率图像来说太昂贵了。(3)它只捕捉了空间适应性,但忽略了通道适应性。在本文中,我们提出了一种新颖的大核注意力(LKA)模块,以在自注意中实现自适应和长距离相关性,同时避免上述问题。我们进一步介绍了一种基于 LKA 的新型神经网络,即 Visual Attention Network(VAN)。尽管非常简单,VAN 在广泛的实验中大幅超越了最先进的视觉 transformers 和卷积神经网络,包括图像分类、目标检测、语义分割、实例分割等。代码可在此 https URL上找到。
提示:
- VAN 没有嵌入层,因此
hidden_states的长度将等于阶段的数量。
下图展示了 Visual Attention Layer 的架构。摘自原始论文。
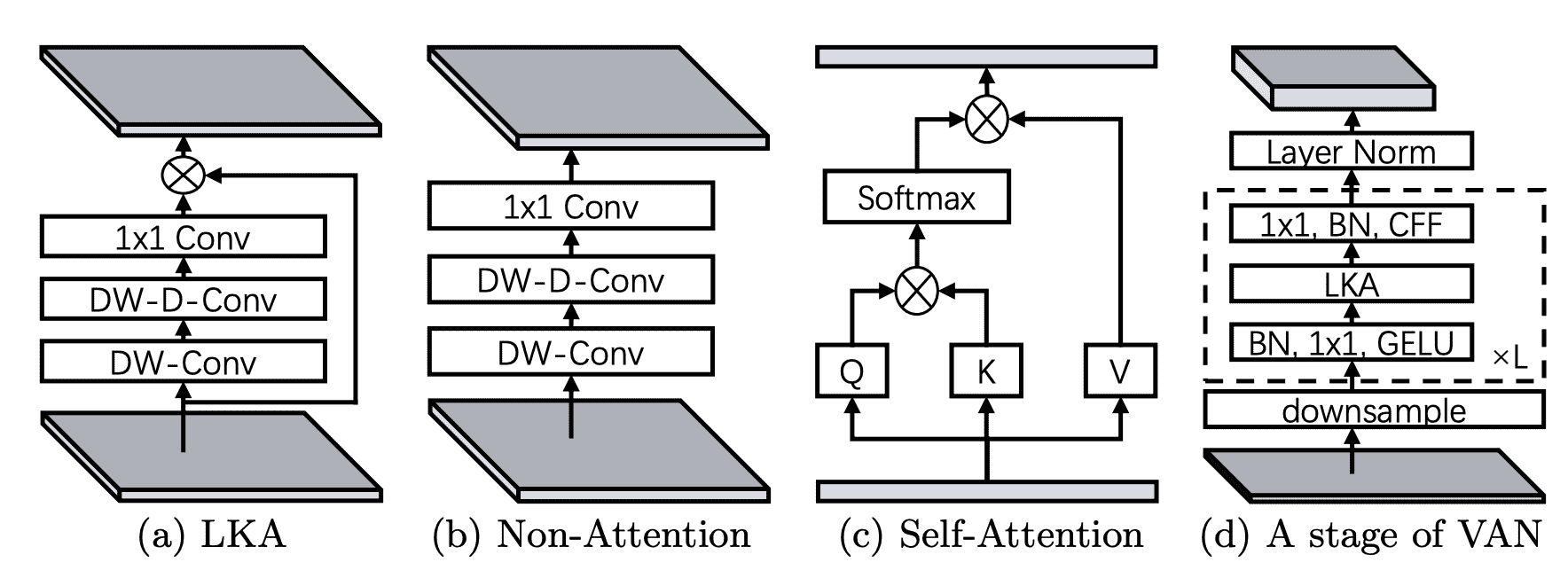
资源
帮助您开始使用 VAN 的官方 Hugging Face 和社区资源列表(由🌎表示)。
图像分类
如果您有兴趣提交资源以包含在这里,请随时打开一个 Pull Request,我们将进行审查!资源应该展示一些新东西,而不是重复现有资源。
VanConfig
class transformers.VanConfig
( image_size = 224 num_channels = 3 patch_sizes = [7, 3, 3, 3] strides = [4, 2, 2, 2] hidden_sizes = [64, 128, 320, 512] depths = [3, 3, 12, 3] mlp_ratios = [8, 8, 4, 4] hidden_act = 'gelu' initializer_range = 0.02 layer_norm_eps = 1e-06 layer_scale_init_value = 0.01 drop_path_rate = 0.0 dropout_rate = 0.0 **kwargs )参数
-
image_size(int,可选,默认为 224)—每个图像的大小(分辨率)。 -
num_channels(int,可选,默认为 3)—输入通道的数量。 -
patch_sizes(List[int],可选,默认为[7, 3, 3, 3])—每个阶段嵌入层中使用的补丁大小。 -
strides(List[int],可选,默认为[4, 2, 2, 2])—每个阶段嵌入层中用于下采样输入的步幅大小。 -
hidden_sizes(List[int], optional, defaults to[64, 128, 320, 512]) — 每个阶段的维度(隐藏大小)。 -
depths(List[int], optional, defaults to[3, 3, 12, 3]) — 每个阶段的深度(层数)。 -
mlp_ratios(List[int], optional, defaults to[8, 8, 4, 4]) — 每个阶段 mlp 层的扩展比率。 -
hidden_act(strorfunction, optional, defaults to"gelu") — 每层中的非线性激活函数(函数或字符串)。如果是字符串,支持"gelu"、"relu"、"selu"和"gelu_new"。 -
initializer_range(float, optional, defaults to 0.02) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。 -
layer_norm_eps(float, optional, defaults to 1e-06) — 层归一化层使用的 epsilon。 -
layer_scale_init_value(float, optional, defaults to 0.01) — 层缩放的初始值。 -
drop_path_rate(float, optional, defaults to 0.0) — 随机深度的 dropout 概率。 -
dropout_rate(float, optional, defaults to 0.0) — 用于 dropout 的 dropout 概率。
这是用于存储 VanModel 配置的配置类。根据指定的参数实例化 VAN 模型,定义模型架构。使用默认值实例化配置将产生类似于 VAN Visual-Attention-Network/van-base 架构的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读 PretrainedConfig 的文档以获取更多信息。
示例:
>>> from transformers import VanModel, VanConfig
>>> # Initializing a VAN van-base style configuration
>>> configuration = VanConfig()
>>> # Initializing a model from the van-base style configuration
>>> model = VanModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configVanModel
class transformers.VanModel
( config )参数
config(VanConfig) — 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained()方法以加载模型权重。
裸的 VAN 模型输出原始特征,没有特定的头部。请注意,VAN 没有嵌入层。此模型是 PyTorch torch.nn.Module子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取与一般用法和行为相关的所有事项。
forward
( pixel_values: Optional output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.BaseModelOutputWithPoolingAndNoAttention or tuple(torch.FloatTensor)参数
-
pixel_values(torch.FloatTensorof shape(batch_size, num_channels, height, width)) — 像素值。像素值可以使用 AutoImageProcessor 获取。有关详细信息,请参阅 ConvNextImageProcessor.call()。 -
output_hidden_states(bool, optional) — 是否返回所有阶段的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 -
return_dict(bool, optional) — 是否返回 ModelOutput 而不是普通元组。
返回
transformers.modeling_outputs.BaseModelOutputWithPoolingAndNoAttention 或 tuple(torch.FloatTensor)
transformers.modeling_outputs.BaseModelOutputWithPoolingAndNoAttention或torch.FloatTensor元组(如果传递了return_dict=False或config.return_dict=False时)包含根据配置(VanConfig)和输入的各种元素。
-
last_hidden_state(torch.FloatTensorof shape(batch_size, num_channels, height, width)) — 模型最后一层的隐藏状态序列。 -
pooler_output(torch.FloatTensorof shape(batch_size, hidden_size)) — 空间维度上池化操作后的最后一层隐藏状态。 -
hidden_states(tuple(torch.FloatTensor), optional, 当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, num_channels, height, width)的torch.FloatTensor元组(如果模型具有嵌入层的输出,则为嵌入输出的输出+每一层的输出)。 模型在每一层输出的隐藏状态以及可选的初始嵌入输出。
VanModel 的前向方法,覆盖__call__特殊方法。
虽然前向传递的步骤需要在此函数内定义,但应该在此之后调用Module实例,而不是在此处调用,因为前者会负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoImageProcessor, VanModel
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image")
>>> image = dataset["test"]["image"][0]
>>> image_processor = AutoImageProcessor.from_pretrained("Visual-Attention-Network/van-base")
>>> model = VanModel.from_pretrained("Visual-Attention-Network/van-base")
>>> inputs = image_processor(image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
>>> list(last_hidden_states.shape)
[1, 512, 7, 7]VanForImageClassification
class transformers.VanForImageClassification
( config )参数
config(VanConfig) — 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型关联的权重,只会加载配置。查看 from_pretrained()方法以加载模型权重。
带有图像分类头部(在池化特征之上的线性层)的 VAN 模型,例如用于 ImageNet。
该模型是 PyTorch torch.nn.Module子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取与一般用法和行为相关的所有事项。
forward
( pixel_values: Optional = None labels: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.ImageClassifierOutputWithNoAttention or tuple(torch.FloatTensor)参数
-
pixel_values(torch.FloatTensorof shape(batch_size, num_channels, height, width)) — 像素值。可以使用 AutoImageProcessor 获取像素值。有关详细信息,请参阅 ConvNextImageProcessor.call()。 -
output_hidden_states(bool, optional) — 是否返回所有阶段的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 -
return_dict(bool, optional) — 是否返回 ModelOutput 而不是普通元组。 -
labels(torch.LongTensorof shape(batch_size,), optional) — 用于计算图像分类/回归损失的标签。索引应在[0, ..., config.num_labels - 1]范围内。如果config.num_labels == 1,则计算回归损失(均方损失),如果config.num_labels > 1,则计算分类损失(交叉熵)。
返回
transformers.modeling_outputs.ImageClassifierOutputWithNoAttention 或tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.ImageClassifierOutputWithNoAttention 或一个torch.FloatTensor元组(如果传递return_dict=False或config.return_dict=False)包含根据配置(VanConfig)和输入的不同元素。
-
loss(torch.FloatTensor,形状为(1,), optional, 当提供labels时返回) — 分类(如果config.num_labels==1则为回归)损失。 -
logits(torch.FloatTensor,形状为(batch_size, config.num_labels)) — 分类(如果config.num_labels==1则为回归)得分(SoftMax 之前)。 -
hidden_states(tuple(torch.FloatTensor), optional, 当传递output_hidden_states=True或config.output_hidden_states=True时返回) —torch.FloatTensor元组(如果模型有嵌入层,则为嵌入的输出 + 每个阶段的输出)的形状为(batch_size, num_channels, height, width)。模型在每个阶段输出的隐藏状态(也称为特征图)。
VanForImageClassification 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的步骤需要在这个函数内定义,但应该在此之后调用Module实例,而不是这个函数,因为前者会处理运行前后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoImageProcessor, VanForImageClassification
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image")
>>> image = dataset["test"]["image"][0]
>>> image_processor = AutoImageProcessor.from_pretrained("Visual-Attention-Network/van-base")
>>> model = VanForImageClassification.from_pretrained("Visual-Attention-Network/van-base")
>>> inputs = image_processor(image, return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> # model predicts one of the 1000 ImageNet classes
>>> predicted_label = logits.argmax(-1).item()
>>> print(model.config.id2label[predicted_label])
tabby, tabby catVideoMAE
原文:
huggingface.co/docs/transformers/v4.37.2/en/model_doc/videomae
概述
VideoMAE 模型由 Zhan Tong, Yibing Song, Jue Wang, Limin Wang 在VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training中提出。VideoMAE 将遮罩自动编码器(MAE)扩展到视频,声称在几个视频分类基准上表现出色。
论文摘要如下:
通常需要在额外大规模数据集上预训练视频变换器,才能在相对小的数据集上实现最佳性能。在本文中,我们展示了视频遮罩自动编码器(VideoMAE)是自监督视频预训练(SSVP)的数据高效学习者。我们受到最近的 ImageMAE 的启发,提出了定制的视频管道遮罩和重建。这些简单的设计对于克服视频重建过程中由时间相关性引起的信息泄漏是有效的。我们在 SSVP 上得出了三个重要发现:(1)极高比例的遮罩比率(即 90% 到 95%)仍然能够产生 VideoMAE 的良好性能。时间上冗余的视频内容使得遮罩比率比图像更高。 (2)VideoMAE 在非常小的数据集上(即约 3k-4k 视频)取得了令人印象深刻的结果,而没有使用任何额外数据。这部分归因于视频重建任务的挑战,以强制进行高级结构学习。 (3)VideoMAE 表明,对于 SSVP,数据质量比数据数量更重要。预训练和目标数据集之间的领域转移是 SSVP 中的重要问题。值得注意的是,我们的 VideoMAE 与基本的 ViT 骨干可以在 Kinects-400 上达到 83.9%,在 Something-Something V2 上达到 75.3%,在 UCF101 上达到 90.8%,在 HMDB51 上达到 61.1%,而没有使用任何额外数据。
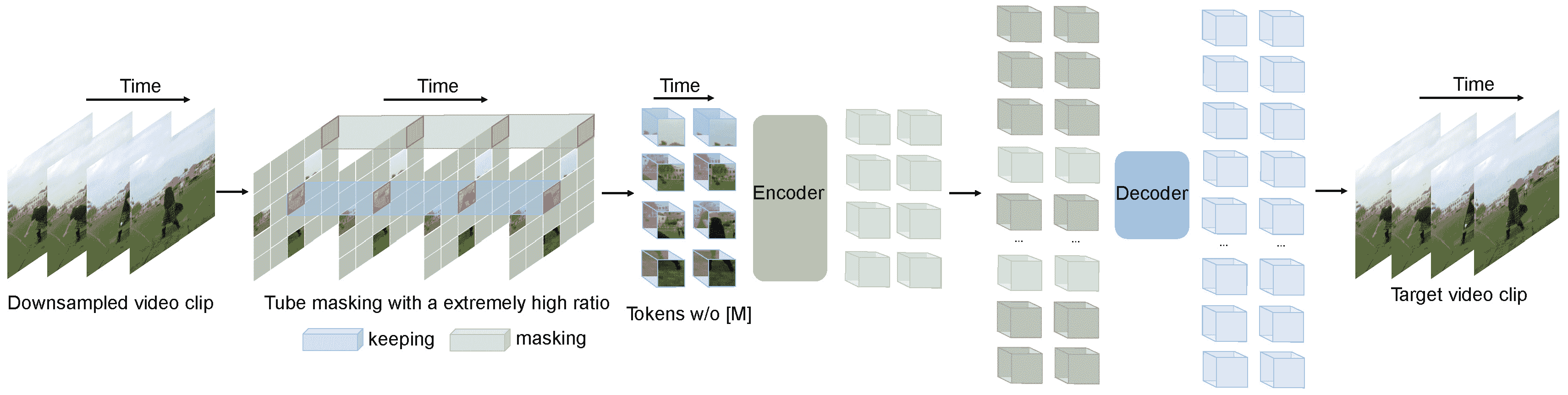
VideoMAE 预训练。摘自原始论文。
资源
官方 Hugging Face 和社区(由 🌎 表示)资源列表,可帮助您开始使用 VideoMAE。如果您有兴趣提交资源以包含在此处,请随时提交拉取请求,我们将进行审核!资源应该展示一些新内容,而不是重复现有资源。
视频分类
VideoMAEConfig
class transformers.VideoMAEConfig
( image_size = 224 patch_size = 16 num_channels = 3 num_frames = 16 tubelet_size = 2 hidden_size = 768 num_hidden_layers = 12 num_attention_heads = 12 intermediate_size = 3072 hidden_act = 'gelu' hidden_dropout_prob = 0.0 attention_probs_dropout_prob = 0.0 initializer_range = 0.02 layer_norm_eps = 1e-12 qkv_bias = True use_mean_pooling = True decoder_num_attention_heads = 6 decoder_hidden_size = 384 decoder_num_hidden_layers = 4 decoder_intermediate_size = 1536 norm_pix_loss = True **kwargs )参数
-
image_size(int, 可选, 默认为 224) — 每个图像的大小(分辨率)。 -
patch_size(int, 可选, 默认为 16) — 每个补丁的大小(分辨率)。 -
num_channels(int, 可选, 默认为 3) — 输入通道数量。 -
num_frames(int, 可选, 默认为 16) — 每个视频中的帧数。 -
tubelet_size(int, 可选, 默认为 2) — 管道大小。 -
hidden_size(int, 可选, 默认为 768) — 编码器层和池化层的维度。 -
num_hidden_layers(int, 可选, 默认为 12) — Transformer 编码器中的隐藏层数量。 -
num_attention_heads(int, optional, 默认为 12) — Transformer 编码器中每个注意力层的注意力头数量。 -
intermediate_size(int, optional, 默认为 3072) — Transformer 编码器中“中间”(即前馈)层的维度。 -
hidden_act(str或function, optional, 默认为"gelu") — 编码器和池化器中的非线性激活函数(函数或字符串)。如果是字符串,支持"gelu"、"relu"、"selu"和"gelu_new"。 -
hidden_dropout_prob(float, optional, 默认为 0.0) — 嵌入层、编码器和池化器中所有全连接层的 dropout 概率。 -
attention_probs_dropout_prob(float, optional, 默认为 0.0) — 注意力概率的 dropout 比率。 -
initializer_range(float, optional, 默认为 0.02) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。 -
layer_norm_eps(float, optional, 默认为 1e-12) — 层归一化层使用的 epsilon。 -
qkv_bias(bool, optional, 默认为True) — 是否为查询、键和值添加偏置。 -
use_mean_pooling(bool, optional, 默认为True) — 是否对最终隐藏状态进行均值池化,而不是使用[CLS]标记的最终隐藏状态。 -
decoder_num_attention_heads(int, optional, 默认为 6) — 解码器中每个注意力层的注意力头数量。 -
decoder_hidden_size(int, optional, 默认为 384) — 解码器的维度。 -
decoder_num_hidden_layers(int, optional, 默认为 4) — 解码器中的隐藏层数量。 -
decoder_intermediate_size(int, optional, 默认为 1536) — 解码器中“中间”(即前馈)层的维度。 -
norm_pix_loss(bool, optional, 默认为True) — 是否对目标补丁像素进行归一化。
这是一个配置类,用于存储 VideoMAEModel 的配置。根据指定的参数实例化一个 VideoMAE 模型,定义模型架构。使用默认值实例化配置将产生类似于 VideoMAEMCG-NJU/videomae-base架构的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读 PretrainedConfig 的文档以获取更多信息。
示例:
>>> from transformers import VideoMAEConfig, VideoMAEModel
>>> # Initializing a VideoMAE videomae-base style configuration
>>> configuration = VideoMAEConfig()
>>> # Randomly initializing a model from the configuration
>>> model = VideoMAEModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configVideoMAEFeatureExtractor
class transformers.VideoMAEFeatureExtractor
( *args **kwargs )__call__
( images **kwargs )预处理一张图像或一批图像。
VideoMAEImageProcessor
class transformers.VideoMAEImageProcessor
( do_resize: bool = True size: Dict = None resample: Resampling = <Resampling.BILINEAR: 2> do_center_crop: bool = True crop_size: Dict = None do_rescale: bool = True rescale_factor: Union = 0.00392156862745098 do_normalize: bool = True image_mean: Union = None image_std: Union = None **kwargs )参数
-
do_resize(bool, optional, 默认为True) — 是否将图像的(高度,宽度)尺寸调整为指定的size。可以被preprocess方法中的do_resize参数覆盖。 -
size(Dict[str, int]optional, 默认为{"shortest_edge" -- 224}): 调整大小后的输出图像尺寸。图像的最短边将被调整为size["shortest_edge"],同时保持原始图像的纵横比。可以被preprocess方法中的size覆盖。 -
resample(PILImageResampling, optional, 默认为Resampling.BILINEAR) — 如果调整图像大小,则要使用的重采样滤波器。可以被preprocess方法中的resample参数覆盖。 -
do_center_crop(bool, optional, 默认为True) — 是否将图像居中裁剪到指定的crop_size。可以被preprocess方法中的do_center_crop参数覆盖。 -
crop_size(Dict[str, int], optional, 默认为{"height" -- 224, "width": 224}): 应用中心裁剪后的图像大小。可以被preprocess方法中的crop_size参数覆盖。 -
do_rescale(bool, optional, 默认为True) — 是否按指定比例rescale_factor重新缩放图像。可以被preprocess方法中的do_rescale参数覆盖。 -
rescale_factor(int或float, optional, 默认为1/255) — 定义要使用的缩放因子,如果重新缩放图像。可以被preprocess方法中的rescale_factor参数覆盖。 -
do_normalize(bool, optional, 默认为True) — 是否对图像进行归一化。可以被preprocess方法中的do_normalize参数覆盖。 -
image_mean(float或List[float], optional, 默认为IMAGENET_STANDARD_MEAN) — 如果归一化图像,则使用的均值。这是一个浮点数或与图像通道数相同长度的浮点数列表。可以被preprocess方法中的image_mean参数覆盖。 -
image_std(float或List[float], optional, 默认为IMAGENET_STANDARD_STD) — 如果归一化图像,则使用的标准差。这是一个浮点数或与图像通道数相同长度的浮点数列表。可以被preprocess方法中的image_std参数覆盖。
构建一个 VideoMAE 图像处理器。
preprocess
( videos: Union do_resize: bool = None size: Dict = None resample: Resampling = None do_center_crop: bool = None crop_size: Dict = None do_rescale: bool = None rescale_factor: float = None do_normalize: bool = None image_mean: Union = None image_std: Union = None return_tensors: Union = None data_format: ChannelDimension = <ChannelDimension.FIRST: 'channels_first'> input_data_format: Union = None **kwargs )参数
-
images(ImageInput) — 要预处理的图像。期望单个或批量图像,像素值范围为 0 到 255。如果传入像素值在 0 到 1 之间的图像,请设置do_rescale=False。 -
do_resize(bool, optional, 默认为self.do_resize) — 是否调整图像大小。 -
size(Dict[str, int], optional, 默认为self.size) — 调整大小后的图像尺寸。 -
resample(PILImageResampling, optional, 默认为self.resample) — 如果调整图像大小,则要使用的重采样滤波器。这可以是枚举PILImageResampling中的一个,仅在do_resize设置为True时有效。 -
do_center_crop(bool, optional, 默认为self.do_centre_crop) — 是否居中裁剪图像。 -
crop_size(Dict[str, int], optional, 默认为self.crop_size) — 应用中心裁剪后的图像尺寸。 -
do_rescale(bool, optional, 默认为self.do_rescale) — 是否将图像值重新缩放在 [0 - 1] 之间。 -
rescale_factor(float, optional, 默认为self.rescale_factor) — 如果do_rescale设置为True,则重新缩放图像的缩放因子。 -
do_normalize(bool, optional, 默认为self.do_normalize) — 是否对图像进行归一化。 -
image_mean(float或List[float], optional, 默认为self.image_mean) — 图像均值。 -
image_std(float或List[float], optional, 默认为self.image_std) — 图像标准差。 -
return_tensors(str或TensorType, optional) — 要返回的张量类型。可以是以下之一:- 未设置: 返回一个
np.ndarray列表。 -
TensorType.TENSORFLOW或'tf': 返回类型为tf.Tensor的批处理。 -
TensorType.PYTORCH或'pt': 返回类型为torch.Tensor的批处理。 -
TensorType.NUMPY或'np': 返回类型为np.ndarray的批处理。 -
TensorType.JAX或'jax': 返回类型为jax.numpy.ndarray的批处理。
- 未设置: 返回一个
-
data_format(ChannelDimension或str,可选,默认为ChannelDimension.FIRST)— 输出图像的通道维度格式。可以是以下之一:-
ChannelDimension.FIRST:图像格式为(通道数,高度,宽度)。 -
ChannelDimension.LAST:图像格式为(高度,宽度,通道数)。 - 未设置:使用推断的输入图像的通道维度格式。
-
-
input_data_format(ChannelDimension或str,可选)— 输入图像的通道维度格式。如果未设置,则从输入图像中推断通道维度格式。可以是以下之一:-
"channels_first"或ChannelDimension.FIRST:图像格式为(通道数,高度,宽度)。 -
"channels_last"或ChannelDimension.LAST:图像格式为(高度,宽度,通道数)。 -
"none"或ChannelDimension.NONE:图像格式为(高度,宽度)。
-
对图像或图像批次进行预处理。
VideoMAEModel
class transformers.VideoMAEModel
( config )参数
config(VideoMAEConfig)— 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只加载配置。查看 from_pretrained() 方法以加载模型权重。
裸的 VideoMAE 模型变压器输出原始隐藏状态,没有特定的头部。此模型是 PyTorch torch.nn.Module 子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有相关信息。
forward
( pixel_values: FloatTensor bool_masked_pos: Optional = None head_mask: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.BaseModelOutput or tuple(torch.FloatTensor)参数
-
pixel_values(形状为(batch_size, num_frames, num_channels, height, width)的torch.FloatTensor)— 像素值。可以使用 AutoImageProcessor 获取像素值。有关详细信息,请参阅 VideoMAEImageProcessor.call()。 -
head_mask(形状为(num_heads,)或(num_layers, num_heads)的torch.FloatTensor,可选)— 用于使自注意力模块中的选定头部失效的掩码。掩码值选定在[0, 1]:- 1 表示头部未被掩盖,
- 0 表示头部被“掩盖”。
-
output_attentions(bool,可选)— 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 -
output_hidden_states(bool,可选)— 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 -
return_dict(bool,可选)— 是否返回 ModelOutput 而不是普通元组。 -
bool_masked_pos(形状为(batch_size, sequence_length)的torch.BoolTensor,可选)— 布尔掩码位置。指示哪些补丁被掩盖(1)哪些不被掩盖(0)。批次中的每个视频必须具有相同数量的掩盖补丁。如果为None,则认为所有补丁都被考虑。序列长度为(num_frames // tubelet_size) * (image_size // patch_size) ** 2。
返回
transformers.modeling_outputs.BaseModelOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.BaseModelOutput 或一个torch.FloatTensor元组(如果传递return_dict=False或当config.return_dict=False时)包含各种元素,具体取决于配置(VideoMAEConfig)和输入。
-
last_hidden_state(形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor)- 模型最后一层的隐藏状态序列的输出。 -
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回)- 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(如果模型有嵌入层,则为嵌入的输出和每一层的输出)。 模型在每一层输出的隐藏状态以及可选的初始嵌入输出。 -
attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或当config.output_attentions=True时返回)- 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。 在注意力 softmax 之后的注意力权重,用于计算自注意力头中的加权平均值。
VideoMAEModel 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的步骤需要在此函数内定义,但应该在此之后调用Module实例,而不是在此处调用,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> import av
>>> import numpy as np
>>> from transformers import AutoImageProcessor, VideoMAEModel
>>> from huggingface_hub import hf_hub_download
>>> np.random.seed(0)
>>> def read_video_pyav(container, indices):
... '''
... Decode the video with PyAV decoder.
... Args:
... container (`av.container.input.InputContainer`): PyAV container.
... indices (`List[int]`): List of frame indices to decode.
... Returns:
... result (np.ndarray): np array of decoded frames of shape (num_frames, height, width, 3).
... '''
... frames = []
... container.seek(0)
... start_index = indices[0]
... end_index = indices[-1]
... for i, frame in enumerate(container.decode(video=0)):
... if i > end_index:
... break
... if i >= start_index and i in indices:
... frames.append(frame)
... return np.stack([x.to_ndarray(format="rgb24") for x in frames])
>>> def sample_frame_indices(clip_len, frame_sample_rate, seg_len):
... '''
... Sample a given number of frame indices from the video.
... Args:
... clip_len (`int`): Total number of frames to sample.
... frame_sample_rate (`int`): Sample every n-th frame.
... seg_len (`int`): Maximum allowed index of sample's last frame.
... Returns:
... indices (`List[int]`): List of sampled frame indices
... '''
... converted_len = int(clip_len * frame_sample_rate)
... end_idx = np.random.randint(converted_len, seg_len)
... start_idx = end_idx - converted_len
... indices = np.linspace(start_idx, end_idx, num=clip_len)
... indices = np.clip(indices, start_idx, end_idx - 1).astype(np.int64)
... return indices
>>> # video clip consists of 300 frames (10 seconds at 30 FPS)
>>> file_path = hf_hub_download(
... repo_id="nielsr/video-demo", filename="eating_spaghetti.mp4", repo_type="dataset"
... )
>>> container = av.open(file_path)
>>> # sample 16 frames
>>> indices = sample_frame_indices(clip_len=16, frame_sample_rate=1, seg_len=container.streams.video[0].frames)
>>> video = read_video_pyav(container, indices)
>>> image_processor = AutoImageProcessor.from_pretrained("MCG-NJU/videomae-base")
>>> model = VideoMAEModel.from_pretrained("MCG-NJU/videomae-base")
>>> # prepare video for the model
>>> inputs = image_processor(list(video), return_tensors="pt")
>>> # forward pass
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
>>> list(last_hidden_states.shape)
[1, 1568, 768]VideoMAEForPreTraining
VideoMAEForPreTraining包括顶部的解码器用于自监督预训练。
class transformers.VideoMAEForPreTraining
( config )参数
config(VideoMAEConfig)- 模型的所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained()方法以加载模型权重。
带有顶部解码器的 VideoMAE 模型变压器,用于自监督预训练。此模型是 PyTorch torch.nn.Module子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有相关信息。
forward
( pixel_values: FloatTensor bool_masked_pos: BoolTensor head_mask: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.models.videomae.modeling_videomae.VideoMAEForPreTrainingOutput or tuple(torch.FloatTensor)参数
-
pixel_values(形状为(batch_size, num_frames, num_channels, height, width)的torch.FloatTensor)- 像素值。可以使用 AutoImageProcessor 获取像素值。有关详细信息,请参阅 VideoMAEImageProcessor.call()。 -
head_mask(形状为(num_heads,)或(num_layers, num_heads)的torch.FloatTensor,可选)- 用于使自注意力模块中选择的头部失效的掩码。掩码值选在[0, 1]之间:- 1 表示头部未被遮蔽,
- 0 表示头部被遮蔽。
-
output_attentions(bool,可选)- 是否返回所有注意力层的注意力张量。有关更多详细信息,请查看返回张量下的attentions。 - output_hidden_states(
bool,可选) - 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 - return_dict(
bool,可选) - 是否返回 ModelOutput 而不是普通元组。 - bool_masked_pos(形状为
(batch_size, sequence_length)的torch.BoolTensor) - 布尔掩码位置。指示哪些补丁被掩盖(1)哪些没有(0)。批次中的每个视频必须具有相同数量的掩码补丁。序列长度为(num_frames // tubelet_size) * (image_size // patch_size) ** 2。
返回
transformers.models.videomae.modeling_videomae.VideoMAEForPreTrainingOutput或tuple(torch.FloatTensor)
一个transformers.models.videomae.modeling_videomae.VideoMAEForPreTrainingOutput或一个torch.FloatTensor元组(如果传递return_dict=False或config.return_dict=False),包括根据配置(VideoMAEConfig)和输入的不同元素。
- loss(形状为
(1,)的torch.FloatTensor) - 像素重建损失。 - logits(形状为
(batch_size, patch_size ** 2 * num_channels)的torch.FloatTensor) - 像素重建 logits。 - hidden_states(
tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回) - 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组。模型在每一层的输出的隐藏状态加上初始嵌入输出。 - attentions(
tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回) - 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
VideoMAEForPreTraining 前向方法,覆盖__call__特殊方法。
虽然前向传递的方法需要在此函数内定义,但应该在此之后调用Module实例,而不是在此处调用,因为前者负责运行前处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoImageProcessor, VideoMAEForPreTraining
>>> import numpy as np
>>> import torch
>>> num_frames = 16
>>> video = list(np.random.randint(0, 256, (num_frames, 3, 224, 224)))
>>> image_processor = AutoImageProcessor.from_pretrained("MCG-NJU/videomae-base")
>>> model = VideoMAEForPreTraining.from_pretrained("MCG-NJU/videomae-base")
>>> pixel_values = image_processor(video, return_tensors="pt").pixel_values
>>> num_patches_per_frame = (model.config.image_size // model.config.patch_size) ** 2
>>> seq_length = (num_frames // model.config.tubelet_size) * num_patches_per_frame
>>> bool_masked_pos = torch.randint(0, 2, (1, seq_length)).bool()
>>> outputs = model(pixel_values, bool_masked_pos=bool_masked_pos)
>>> loss = outputs.lossVideoMAEForVideoClassification
视频分类的 VideoMAEForVideoClassification 类
( config )参数
- config(VideoMAEConfig) - 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型关联的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
VideoMAE 模型变压器,顶部带有视频分类头(所有令牌的平均池化隐藏状态之上的线性层),例如用于 ImageNet。此模型是 PyTorch torch.nn.Module子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有相关信息。
forward
( pixel_values: Optional = None head_mask: Optional = None labels: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.ImageClassifierOutput or tuple(torch.FloatTensor)参数
-
pixel_values(torch.FloatTensor,形状为(batch_size, num_frames, num_channels, height, width)) — 像素值。像素值可以使用 AutoImageProcessor 获得。有关详细信息,请参阅 VideoMAEImageProcessor.call()。 -
head_mask(torch.FloatTensor,形状为(num_heads,)或(num_layers, num_heads),可选) — 用于使自注意力模块中选择的头部失效的掩码。掩码值选定在[0, 1]之间:- 1 表示头部未被
masked, - 0 表示头部被
masked。
- 1 表示头部未被
-
output_attentions(bool,可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回的张量中的attentions。 -
output_hidden_states(bool,可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回的张量中的hidden_states。 -
return_dict(bool,可选) — 是否返回一个 ModelOutput 而不是一个普通元组。 -
labels(torch.LongTensor,形状为(batch_size,),可选) — 用于计算图像分类/回归损失的标签。索引应在[0, ..., config.num_labels - 1]范围内。如果config.num_labels == 1,则计算回归损失(均方损失),如果config.num_labels > 1,则计算分类损失(交叉熵)。
返回值
transformers.modeling_outputs.ImageClassifierOutput 或tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.ImageClassifierOutput 或一个torch.FloatTensor元组(如果传递了return_dict=False或当config.return_dict=False时)包含根据配置(VideoMAEConfig)和输入的不同元素。
-
损失(torch.FloatTensor,形状为(1,),可选,在提供labels时返回) — 分类(如果config.num_labels==1则为回归)损失。 -
logits(torch.FloatTensor,形状为(batch_size, config.num_labels)) — 分类(如果config.num_labels==1则为回归)得分(SoftMax 之前)。 -
hidden_states(tuple(torch.FloatTensor),可选,在传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(如果模型具有嵌入层,则为嵌入的输出+每个阶段的输出)隐藏状态(也称为特征图)在每个阶段的模型输出处。 -
attentions(tuple(torch.FloatTensor),可选,在传递output_attentions=True或当config.output_attentions=True时返回) — 形状为(batch_size, num_heads, patch_size, sequence_length)的torch.FloatTensor元组(每层一个)。 在注意力 softmax 之后的注意力权重,用于计算自注意力头部的加权平均值。
VideoMAEForVideoClassification 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的配方需要在此函数内定义,但应该在此之后调用Module实例,而不是在此处调用,因为前者会负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> import av
>>> import torch
>>> import numpy as np
>>> from transformers import AutoImageProcessor, VideoMAEForVideoClassification
>>> from huggingface_hub import hf_hub_download
>>> np.random.seed(0)
>>> def read_video_pyav(container, indices):
... '''
... Decode the video with PyAV decoder.
... Args:
... container (`av.container.input.InputContainer`): PyAV container.
... indices (`List[int]`): List of frame indices to decode.
... Returns:
... result (np.ndarray): np array of decoded frames of shape (num_frames, height, width, 3).
... '''
... frames = []
... container.seek(0)
... start_index = indices[0]
... end_index = indices[-1]
... for i, frame in enumerate(container.decode(video=0)):
... if i > end_index:
... break
... if i >= start_index and i in indices:
... frames.append(frame)
... return np.stack([x.to_ndarray(format="rgb24") for x in frames])
>>> def sample_frame_indices(clip_len, frame_sample_rate, seg_len):
... '''
... Sample a given number of frame indices from the video.
... Args:
... clip_len (`int`): Total number of frames to sample.
... frame_sample_rate (`int`): Sample every n-th frame.
... seg_len (`int`): Maximum allowed index of sample's last frame.
... Returns:
... indices (`List[int]`): List of sampled frame indices
... '''
... converted_len = int(clip_len * frame_sample_rate)
... end_idx = np.random.randint(converted_len, seg_len)
... start_idx = end_idx - converted_len
... indices = np.linspace(start_idx, end_idx, num=clip_len)
... indices = np.clip(indices, start_idx, end_idx - 1).astype(np.int64)
... return indices
>>> # video clip consists of 300 frames (10 seconds at 30 FPS)
>>> file_path = hf_hub_download(
... repo_id="nielsr/video-demo", filename="eating_spaghetti.mp4", repo_type="dataset"
... )
>>> container = av.open(file_path)
>>> # sample 16 frames
>>> indices = sample_frame_indices(clip_len=16, frame_sample_rate=1, seg_len=container.streams.video[0].frames)
>>> video = read_video_pyav(container, indices)
>>> image_processor = AutoImageProcessor.from_pretrained("MCG-NJU/videomae-base-finetuned-kinetics")
>>> model = VideoMAEForVideoClassification.from_pretrained("MCG-NJU/videomae-base-finetuned-kinetics")
>>> inputs = image_processor(list(video), return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
... logits = outputs.logits
>>> # model predicts one of the 400 Kinetics-400 classes
>>> predicted_label = logits.argmax(-1).item()
>>> print(model.config.id2label[predicted_label])
eating spaghettifor i, frame in enumerate(container.decode(video=0)): … if i > end_index: … break … if i >= start_index and i in indices: … frames.append(frame) … return np.stack([x.to_ndarray(format=“rgb24”) for x in frames])
def sample_frame_indices(clip_len, frame_sample_rate, seg_len): … ‘’’ … Sample a given number of frame indices from the video. … Args: … clip_len (
int): Total number of frames to sample. … frame_sample_rate (int): Sample every n-th frame. … seg_len (int): Maximum allowed index of sample’s last frame. … Returns: … indices (List[int]): List of sampled frame indices … ‘’’ … converted_len = int(clip_len * frame_sample_rate) … end_idx = np.random.randint(converted_len, seg_len) … start_idx = end_idx - converted_len … indices = np.linspace(start_idx, end_idx, num=clip_len) … indices = np.clip(indices, start_idx, end_idx - 1).astype(np.int64) … return indicesvideo clip consists of 300 frames (10 seconds at 30 FPS) file_path = hf_hub_download( … repo_id=“nielsr/video-demo”, filename=“eating_spaghetti.mp4”, repo_type=“dataset” … ) container = av.open(file_path)
sample 16 frames indices = sample_frame_indices(clip_len=16, frame_sample_rate=1, seg_len=container.streams.video[0].frames) video = read_video_pyav(container, indices)
image_processor = AutoImageProcessor.from_pretrained(“MCG-NJU/videomae-base-finetuned-kinetics”) model = VideoMAEForVideoClassification.from_pretrained(“MCG-NJU/videomae-base-finetuned-kinetics”)
inputs = image_processor(list(video), return_tensors=“pt”)
with torch.no_grad(): … outputs = model(**inputs) … logits = outputs.logits
model predicts one of the 400 Kinetics-400 classes predicted_label = logits.argmax(-1).item() print(model.config.id2label[predicted_label]) eating spaghetti
腾讯云开发者
