一文掌握最新数据湖方案Spark+Hadoop+Hudi+Hive整合案例实践总结
一文掌握最新数据湖方案Spark+Hadoop+Hudi+Hive整合案例实践总结

前言
大数据生态发展数年,各种组件版本迭代升级在所难免。组件之间、不同版本之间的适配整合升级,尤为重要。本文主要讲述当前火热的数据湖方案Spark+Hadoop+Hudi+Hive的适配整合案例总结。详细的组件版本信息如下:
Spark | 3.3.2 |
|---|---|
Hadoop | 3.1.1.3.1.5.0-152 |
Hudi | 0.14.1 |
Hive | 3.1.0.3.1.5.0-152 |
说明:HDP-3.1.5.0版本大数据安装包,可以加个人微信免费索要。
Spark整合Hadoop Hive
- 下载spark安装包
[root@felixzh]# wget https://archive.apache.org/dist/spark/spark-3.3.2/spark-3.3.2-bin-hadoop3.tgz
[root@felixzh myHadoopCluster]# tar -xvf spark-3.3.2-bin-hadoop3.tgz2. 修改配置spark-default.conf
[root@felixzh spark-3.3.2-bin-hadoop3]# cp conf/spark-defaults.conf.template conf/spark-defaults.conspark-defaults.conf设置如下:
br3. 修改配置spark-env.sh
[root@felixzh spark-3.3.2-bin-hadoop3]# cp conf/spark-env.sh.template conf/spark-env.shspark-env.sh设置如下:
export HADOOP_CONF_DIR=/etc/hadoop/conf/
export HADOOP_HOME=/usr/hdp/current/hadoop-client/
#删除spark自带的hadoop相关jar,增加自己的hadoop相关jar
export SPARK_DIST_CLASSPATH=${SPARK_DIST_CLASSPATH}:/usr/hdp/3.1.5.0-152/hadoop/client/shaded/hadoop-client-api-3.1.1.3.1.5.0-152.jar:/usr/hdp/3.1.5.0-152/hadoop/client/shaded/hadoop-client-runtime-3.1.1.3.1.5.0-152.jar:/usr/hdp/3.1.5.0-152/hadoop-yarn/hadoop-yarn-server-web-proxy-3.1.1.3.1.5.0-152.jar:/usr/hdp/3.1.5.0-152/hadoop/client/htrace-core4.jar4. 修改配置log4j2.properties,调整相应日志级别
[root@felixzh spark-3.3.2-bin-hadoop3]# cp conf/log4j2.properties.template conf/log4j2.properties5. 剔除spark自带的hadoop相关jar
[root@felixzh spark-3.3.2-bin-hadoop3]# rm -rf jars/hadoop-*6. 拷贝hive-site.xml
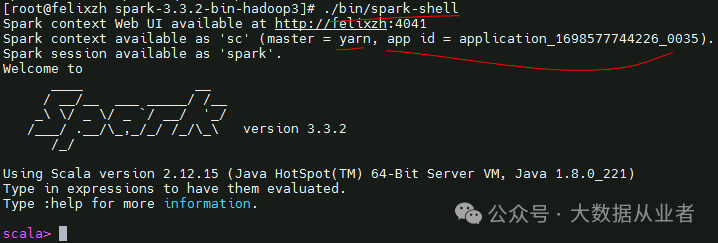
[root@felixzh spark-3.3.2-bin-hadoop3]# cp /etc/hive/conf/hive-site.xml conf/7. 验证效果(spark-sql、spark-shell)

Hudi源码编译
考虑Hudi与其他组件牵涉较多,本文采用源码编译方式自行打包。
[root@felixzh]# git clone -b release-0.14.1 https://github.com/apache/hudi.git
[root@felixzh hudi]# mvn clean package -Dmaven.test.skip=true -Dfast -Dspark3.3 -Dscala-2.12 -Dflink1.17 -Pflink-bundle-shade-hive3 -Drat.skip=true -Dcheckstyle.skip
Hudi项目packaging会生成与其他组件交互的相关jar,如下(Spark/Flink):
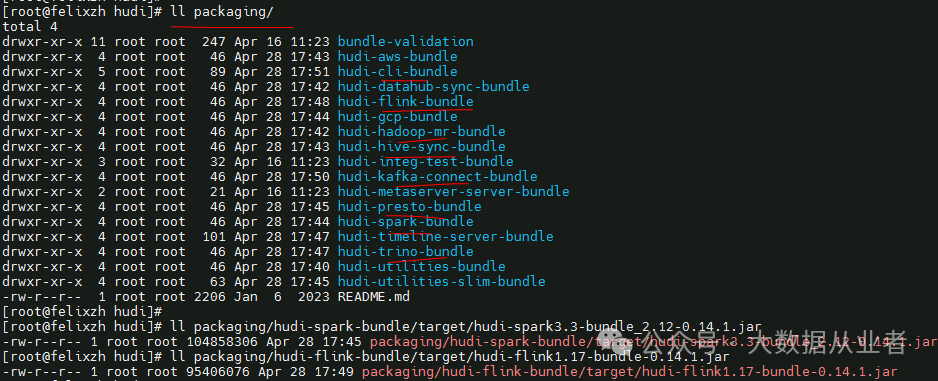
本文主要整合spark,需要将hudi-spark3.3-bundle_2.12-0.14.1.jar拷贝到spark节点,比如:
/home/myHadoopCluster/spark-3.3.2-bin-hadoop3/jarsForHudi/
Hudi SparkSQL实战案例
- 启动spark-sql
https://hudi.apache.org/docs/quick-start-guide#spark-shellsql
[root@felixzh spark-3.3.2-bin-hadoop3]# ./bin/spark-sql --conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' --conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension' --conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' --conf 'spark.kryo.registrator=org.apache.spark.HoodieSparkKryoRegistrar' --jars /home/myHadoopCluster/spark-3.3.2-bin-hadoop3/jarsForHudi/* 2. Create Table
默认创建分区表、类型为cow。可以通过TBLPROPERTIES (type = 'mor')可以设置参数。
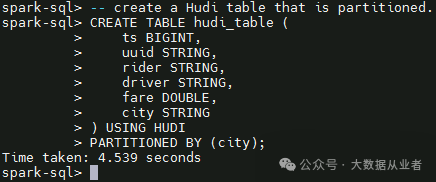
3. Insert data
插入8条数据,如下:
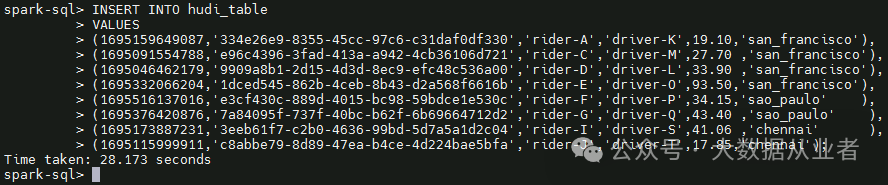
4. Query data
根据条件查询数据,fare大于20,查询到6条数据,如下:

5. Update data
根据条件,更新rider = 'rider-D'的数据中fare为25,如下:

6. Merging Data
创建fare_adjustment表,插入4条数据。然后,将fare_adjustment与hudi_table表进行merge,且根据uuid将两表fare求和,赋值到hudi_table表的fare列。
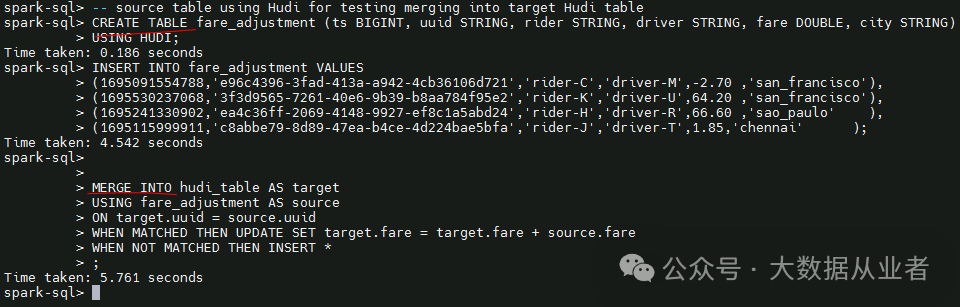
hudi_table原表8条数据,fare_adjustment表4条数据。其中,uuid相同的数据为2条,所以merge后共10(8+4-2)条数据,这条数据的fare值为两表fare求和之后的值,如下:
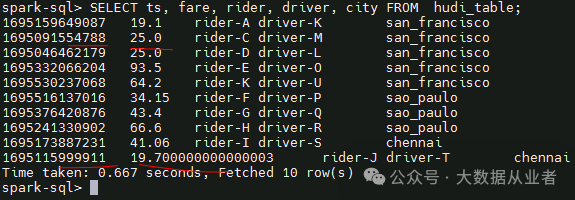
7. Delete data
根据条件删除指定uuid的数据,如下:

8. Time Travel Query
Hudi支持时间旅行查询,也就是查询指定commit time的数据。上文对hudi_table表先后进行insert、update、merge、delete,对应于四次commit,如下:
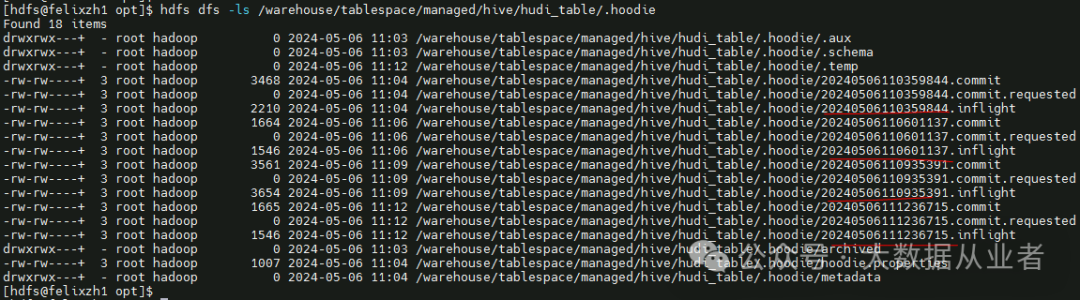
第一次commit 20240506110359844,对应insert,时间旅行查询insert的8条数据:
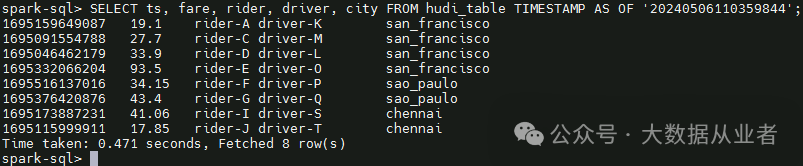
第二次commit 20240506110601137,对应update,时间旅行查询update后的数据:
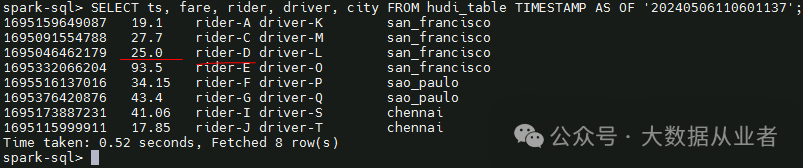
第三次commit 20240506110935391,对应merge,时间旅行查询merge后的数据:
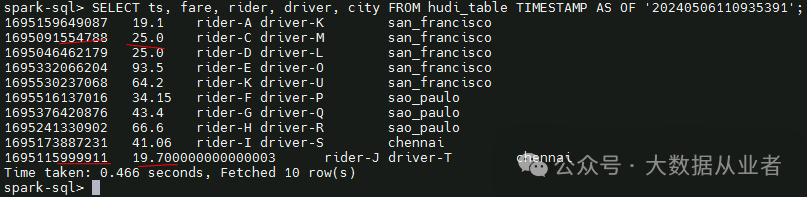
第四次commit 20240506111236715,对应delete,时间旅行查询delete后的数据:
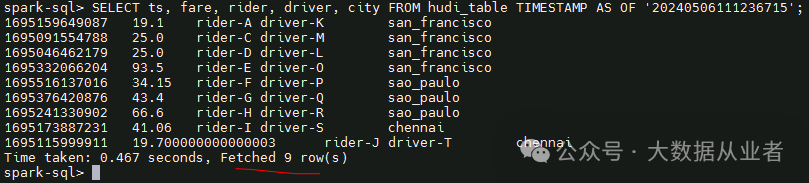
可以看出,因为delete一条数据,所以,第四次commit后数据比第三次少了一条数据。
spark-env.sh配置问题
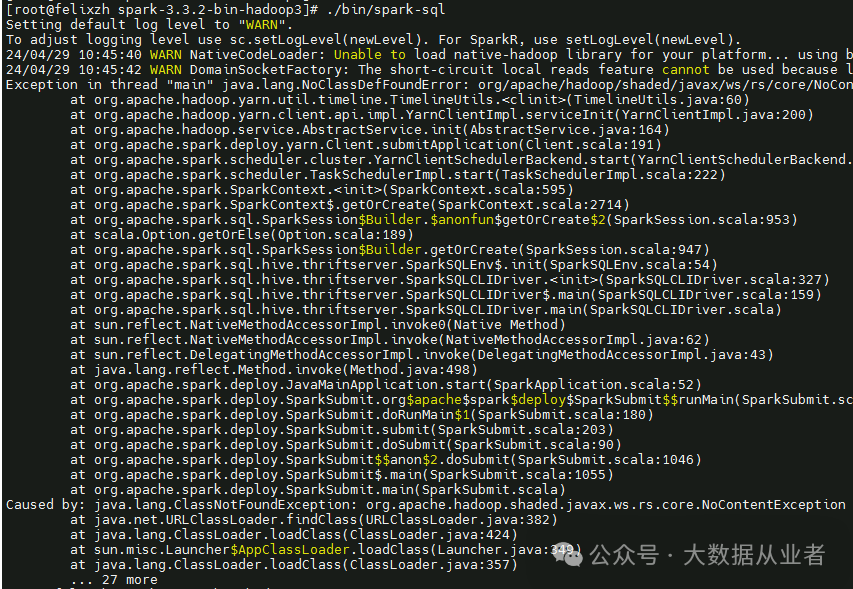
如果遇到本章节异常,需要按照上文检查spark-env.sh配置内容:
1.When running with master 'yarn' either HADOOP_CONF_DIR or YARN_CONF_DIR must be set in the environment

2.ClassNotFoundException: org.apache.hadoop.shaded.javax.ws.rs.core.NoContentException
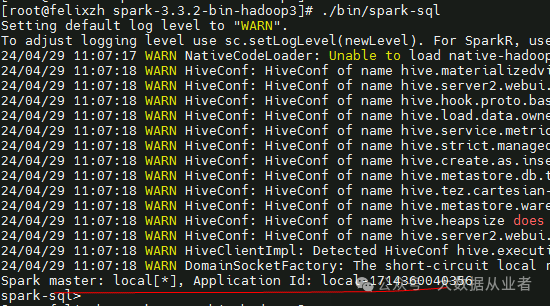
spark-default.conf配置问题
如果遇到本章节异常,需要按照上文检查spark-default.conf配置内容:
1.Spark master: local[*], Application Id: local-1714360040356
spark依赖hudi问题
如果遇到本章节异常,需要按照上文检查spark-sql和spark-shell启动方法:
1.java.lang.ClassNotFoundException: org.apache.spark.sql.hudi.HoodieSparkSessionExtension
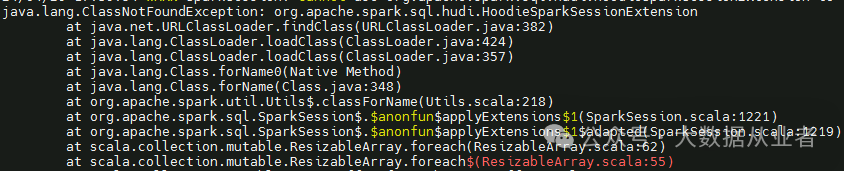
2.Caused by: java.lang.ClassNotFoundException: org.apache.spark.sql.hudi.catalog.HoodieCatalog

3.Caused by: java.lang.IllegalStateException: unread block data

hudi依赖hbase问题
java.lang.NoSuchMethodError: org.apache.hadoop.hdfs.client.HdfsDataInputStream.getReadStatistics()Lorg/apache/hadoop/hdfs/DFSInputStream$ReadStatistics;
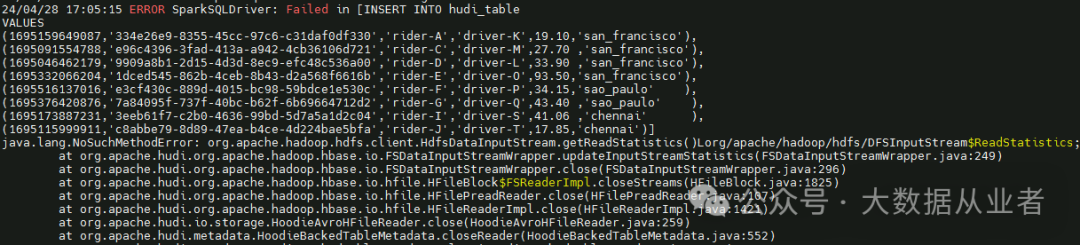
该问题在Hudi官网的Troubleshooting章节有说明,如下:
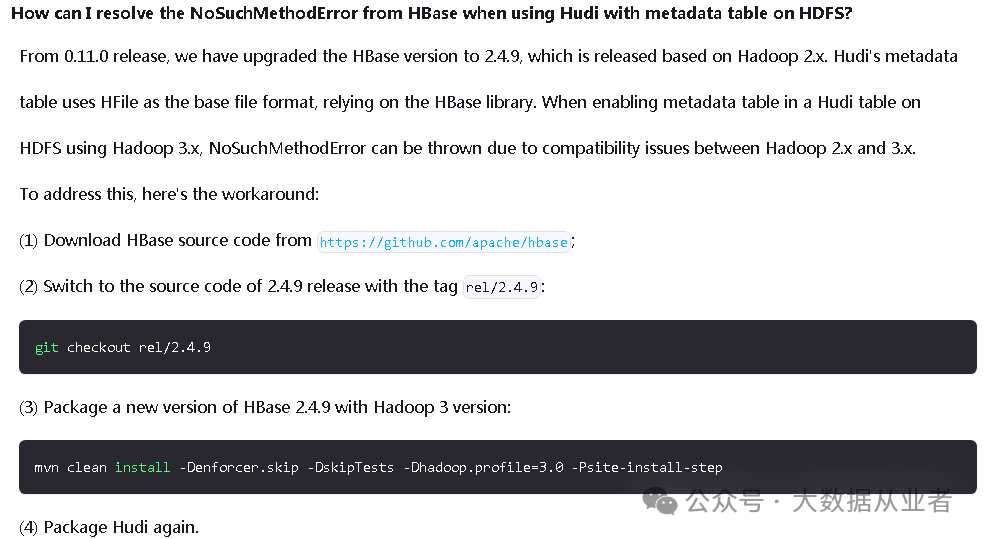
大概意思就是:Hudi所依赖的HBase2.4.9默认基于Hadoop2编译打包的,需要自行基于Hadoop3,重新编译打包HBase2.4.9(注意:install到本地仓库),然后重新编译打包Hudi即可。
[root@felixzh hbase-rel-2.4.9]# mvn clean install -Denforcer.skip -DskipTests -Dhadoop.profile=3.0 -Psite-install-step
[root@felixzh hudi]# mvn clean package -Dmaven.test.skip=true -Dfast -Dspark3.3 -Dscala-2.12 -Dflink1.17 -Pflink-bundle-shade-hive3 -Drat.skip=true -Dcheckstyle.skip总结
本文记录从0到1整合数据湖方案Spark+Hadoop+Hudi+Hive的案例实践操作总结!
腾讯云开发者
