FouRA:傅里叶域中的创新低秩方法提升文本到图像生成多样性 !
FouRA:傅里叶域中的创新低秩方法提升文本到图像生成多样性 !


尽管低秩适应(LoRA)已被证明能有效地微调大型模型,但经过LoRA微调的文本到图像扩散模型在生成的图像中缺乏多样性,因为模型倾向于复制观察到的训练样本中的数据。 这种效应在 Adapter 强度值较高以及在高秩 Adapter 微调较小数据集时变得更加明显。为了解决这些挑战,作者提出了 FouRA,这是一种新颖的低秩方法,它在傅里叶域中学习投影,并学习一种灵活的输入相关 Adapter 秩选择策略。 通过大量的实验和分析,作者展示了 FouRA 成功解决了与数据复制和分布崩溃相关的问题,同时显著提高了生成的图像质量。作者证明,由于 FouRA 的自适应秩选择,它增强了微调模型的泛化能力。 作者还展示了在频率域学习的投影是去相关的,并且在合并多个 Adapter 时证明是有效的。虽然 FouRA 是为视觉任务而启发的,但作者还在 GLUE 基准上展示了它在语言任务中的优势。
1 Introduction
图1:使用LoRA导致的分布崩溃。由Realistic Vision 3.0模型生成的视觉结果,该模型使用LoRA和FouRA训练了“蓝火”和“折纸”风格 Adapter ,跨越四个种子。虽然LoRA图像遭受分布崩溃且缺乏多样性,但作者观察到FouRA生成了多样化的图像。

参数高效微调(PEFT)[22]方法,如低秩适配[14],为快速适应大型基础模型(包括大型视觉模型(LVMs)和大型语言模型(LLMs))到新任务[20; 16; 3]提供了一种有前景的解决方案。LoRA模块具有优雅的设计,可以在不改变底层基础模型的情况下快速适应新风格或概念,从而有效保持先前知识并防止灾难性遗忘。尽管LoRAs在快速适应新风格方面非常有效,但它们存在多个挑战,LoRA模块的秩是一个高度敏感的参数。由于LoRA是为了使用小训练集适应新任务而构建的,当秩较高时,它倾向于过拟合到小训练集的分布。最近的工作[34; 35]观察到,当扩散模型过拟合到小训练集时,它们表现出反复“复制”训练集中的少量样本的倾向。因此,在较小数据上训练的LoRAs倾向于生成数据复制伪影,这也称为分布崩溃。生成的图像缺乏多样性,这种现象与在GANs中观察到的模式崩溃非常相似。作者在图1中说明了这种倾向,特别是在不同种子的高 Adapter 强度值下。
此外,随着秩的减少, Adapter 的强度降低,由于拟合不足,LoRA生成多样化图像的能力减弱。因此,秩是一个非常敏感的参数。
门控机制已被提出[3],用于在每一层产生动态排名,为LLM任务中的 Adapter 提供灵活性。然而,作者认为动态排名降低在视觉任务中仍然不够灵活,因为该排名是在训练期间计算的,并且在推理时不会变化。作者观察到,文本到图像的扩散模型从可以在推理期间沿扩散时间步变化的排名适应机制中大大受益。
此外,尽管所有之前的工作都在特征空间中应用低秩适应,作者认为存在一个变换域,在该域上微调低秩适应模块可以生成更丰富的表示。作者提供了理论和分析证据来表明,在频域中进行低秩适应产生了一种高度紧凑的表示,有效地减少了泛化误差。因此,这有可能推动适应性排名选择机制更好地泛化,不仅降低了排名降低时的欠拟合风险,也减少了高排名时的过拟合风险。此外,也有尝试将多个LoRA概念和/或风格作为多个LoRA的线性加权组合来合并[29]。
最近的研究[40; 10; 17]凭经验显示这种方法容易产生噪声和不准确的输出,并提出了在低秩子空间中带有可学习门控的 Adapter 联合微调的方法。然而,作者认为联合训练多个LoRA模块在需要灵活组合多个不同LoRA的实际用例中是高度受限且同样繁琐的。作者开发的频域门控方法能够灵活地混合多个 Adapter 。
在本文中,作者提出了FouRA(傅里叶低秩适应),一种用于解决LoRA上述挑战的PEFT技术。作者将输入特征变换到频域,并在该频域中应用下投影(到低秩)和上投影(回到高秩)。在推理期间,作者将 Adapter 强度折叠到低秩子空间中。FouRA在低秩子空间内学习自适应 Mask ,以动态地丢弃某些频域变换基,有效地为每一层变化排名。自适应 Mask 选择依赖于输入,并在扩散过程中变化。通过严格的分析,作者展示了FouRA相对于LoRA(和其他自适应门控方法)具有明显的优势,并生成高质量的多样化图像。作者展示了在低排名时增加FouRA中 Adapter 权重的影响并不会降低原始模型的表示能力。此外,作者展示了FouRA为频域中的低秩 Adapter 提供了一个丰富的解纠缠正交基,使其有利于合并多种风格。
作者的贡献总结如下:
- 作者介绍了FouRA,这是第一个在频率域沿特征空间的像素或通道维度执行低秩变换的低秩 Adapter 模块。
- 作者提出了一种频率域中的自适应可学习 Mask 策略,该策略灵活地改变每个网络中FouRA层的有效秩,从而使得模型即使在小训练集的情况下也能很好地泛化。
- 作者证明FouRA成功为频率域中的低秩 Adapter 提供了一个去相关的正交基,使其在无需联合训练的情况下,对合并两种风格或概念非常有帮助。
- 通过大量实验和理论分析,作者展示了与LoRA相比,FouRA如何一致地产生一系列在美学上得到改善的图像,并且对于LLM任务同样有效。
2 Related Work
文本到图像扩散模型:最近提出了多种基于扩散的图像生成模型。这些模型展示了出色的文本到图像生成能力,并且可以通过LoRA[14]适配到新的风格。
生成文献中的傅里叶变换:最近的工作[15]表明,在充足数据上训练的去噪模型的潜在变量位于具有振荡模式的自适应基底上。其他研究显示,作者可以使用傅里叶算子进行非参数回归任务,并将自注意力视为核回归问题。[23]显示它为输入提供了更平滑的表示,并更好地捕捉了 Query 和键之间的相关性。[18]已经证明,傅里叶谱滤波器在连续域中操作,并且在将图像表示为连续函数方面表现良好。进一步的空间域卷积可以在傅里叶空间中表示为乘法,因此谱滤波器可以作为全局卷积算子。据作者所知,将这些变换应用于低秩空间尚未被探索。
许多研究分析了变换到谐波基底的信号的特征扩散。[1],分析了将这些变换应用于从马尔可夫过程中采样的信号的效果,并显示傅里叶变换在最小均方设置中使此类信号去相关。
低秩适配:LoRAs[14]在生成图像的保真度和多样性之间存在权衡。[3]试图通过稀疏正则化来缓解这个问题。SVDiff[12]只显式地更新奇异值,同时保持子空间。在高秩设置中,这种方法是可以接受的。然而,在FouRA中,作者是在低秩子空间中进行学习。其他像AdaLORA应用于语言模型的工作,进一步使用奇异值分解参数化了权重矩阵,并通过重要性评分指标联合优化特征向量和奇异值。O-lora[37]计算了不同任务之间的正交梯度空间,使得模型可以顺序地适应新任务,而不会灾难性遗忘。在损失函数中应用近端梯度门控来学习重要的子空间并 Mask 其余部分。尽管所有这些论文都是直接通过对权重矩阵的子空间进行约束来操作,但作者在论文中显示,傅里叶域隐式地实施了这些特性,而优化中没有约束。作者显示,在频率域中应用门控提供了一个更紧凑的表示,并具有稳定的泛化误差边界。此外,每个层的结果都降低了有效秩。作者还显示,不同 Adapter 之间学习到的空间也具有去相关的基底。MoLE,ZipLoRA[32]和Mix of Show探索了各种策略来合并LoRAs。这是通过使用监督或自监督目标来联合训练对应于两个 Adapter 的权重来完成的。
随着 Adapter 数量的增加,作者认为这种两阶段的合并 Adapter 方法不够灵活且相当繁琐。而FouRA则不需要任何微调,并且确实是一种无需训练即可合并多个 Adapter 的方法。
编辑的解缠空间[38][11]已经探索了用于解缠可解释潜在表示的扩散模型。虽然LoRAs已经被提出用于个性化,[8]提出了一种在保持原始图像特征的同时进行图像细粒度编辑的方法。他们识别语义方向并在这些方向上的潜在空间中移动。概念滑块已经被应用于实际应用中,例如修复扩散生成图像中的失真。
作者在工作中显示,作者的方法比LoRA识别出更紧凑的解缠表示,因此在细粒度编辑上提供了更多的性能改进。
3 Proposed Approach
作者的方法旨在解决当前技术在处理XX问题时所面临的挑战。具体来说,作者提出了一种新的 YY 方法,该方法基于 ZZ 理论,并能够实现 AA 目标。以下小节详细介绍了所提方法的各个组成部分及其工作原理。
Formulation of Low Rank Adaptation
作者在图2中展示了基本的LoRA模块。考虑原始的预训练权重集合 ,其中 和 分别代表输入和输出的嵌入维度。LoRA模块由下采样层 和上采样层 组成,它们将输入特征投射到和从秩为 的低秩子空间。考虑一个输入特征 ,其中 是输入 Token 的数量,经过低秩适应后的输出 给出为 。在这里, 和 分别来自原始分支和低秩分支的输出,而 是混合两个分支的标量。作者将学习的 Adapter 矩阵表示为 ,如[14]中所示。
Low Rank Adaptation in the Frequency Domain
将输入投影到低秩子空间以及从低秩子空间恢复往往会造成信息丢失。为了缓解这一问题,作者 Proposal 将输入转换到一个内在紧凑表示的域,即频域。作者受到这样的启发:转换到频域可以保留有价值的信息,这是由于它的固有去相关性能力[9; 13]。作者在第4.1节通过分析频域变换对模型权重的影响来进一步验证这一点。
给定预训练权重矩阵 ,作者在频域应用低秩变换 和 。受到[33]的启发,作者将混合参数 折叠到低秩子空间内,实际上在频域中充当了缩放因子的作用。作者以下列方式应用频域变换。
这里, 和 分别是归一化的正向和反向频域变换。
Frequency Transforms
作者研究了离散傅里叶变换(DFT)和离散余弦变换(DCT)在低秩空间中的性质。在子空间分解之前,作者将一维DFT应用于嵌入维度 。对于 Adapter 分支的输入 ,作者在方程(5)中展开 ,
其中 是由DFT表示的基的频率。由于作者没有应用任何填充,变换的维度保持了 的维度。在作者的实验中,作者在自注意力和交叉注意力层的每个标记上应用了一维变换到嵌入维度 。
为了推广FouRA跨任务的想法,例如有针对性的编辑[8],需要一个解耦的潜在空间以控制生成的图像,作者进一步探索了具有紧凑子空间(特征扩散)的离散余弦变换(DCT),这导致了过拟合的减少。作者在附录B.1和图4中展示了FouRA的子空间彼此更不相关。作者观察到对于某些任务,DCT提供了一个更平滑的表示,因为隐含的窗口是DFT信号的两倍。对于一个给定的有限长度信号 ,作者按照以下方式计算DCT。作者首先通过以下方式构建一个双倍长度的偶数信号

然后计算 的DFT作为DCT。
Adaptive Rank Gating Method
LoRA方法为所有层预定义了秩。最近的方法[3]在训练过程中具有自适应秩,但在推理时是固定的,因此缺乏灵活性。在作者的方法中,作者提出了一种学习的自适应门控机制,它可以在训练和推理过程中根据输入变化每个层的秩。作者在频率域内的低秩子空间内引入了作者的可学习门控机制 。考虑表示为 的低秩表示,作者的门控操作定义为:
图2:LoRA与FouRA对比。 对于FouRA,作者将特征图变换到频率域,在那里作者学习上下 Adapter 投影以及作者提出的自适应秩门控模块。
这里, 和 分别表示熵和sigmoid函数, 表示可学习的多层感知机(MLP)的权重, 是一个函数,用于学习低秩子空间中每个奇异值的权重。图3所示的FouRA输出,然后由以下给出:
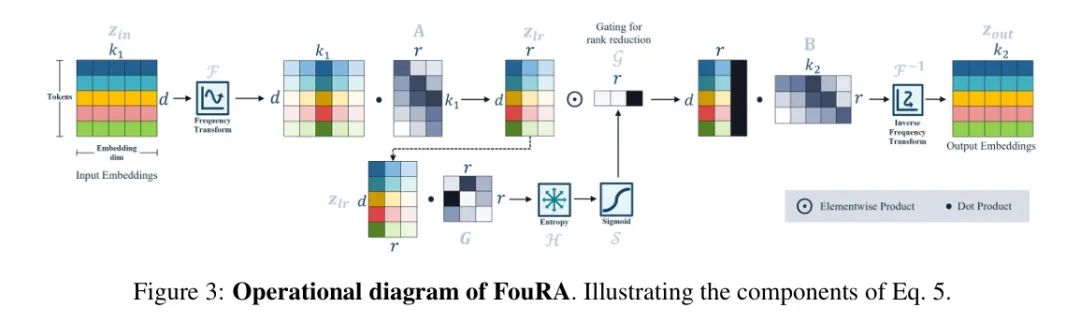
根据3.1节中的表示法,学习到的FouRA Adapter 权重是 。
作者在4.2节中对提出的门控函数进行了进一步分析,研究其在扩散时间步和各种分辨率下的行为。此外,作者证明了它在固定LoRA和最近的固定推理时自适应秩选择方法(SoRA[3])上的有效性。
Combining multiple adapters
合并LoRA Adapter 在多个实际用例中都有应用[29]。作者根据任务的不同,采用不同的方法来合并两个 Adapter 。
文本到图像的风格迁移:遵循标准方法,作者在推理过程中通过 Adapter 和 输出的线性组合来合并两个基于FouRA风格的 Adapter 。
使用概念滑块进行图像编辑: 与[8]类似,作者在第5.3节使用FouRA基于文本的编辑进行概念滑块评估。给定 个概念滑块,作者定义第 个滑块的概念 (例如“非常古老”)和 作为负概念(例如“非常年轻”)。作者在epsilon 空间中合成 Adapter ,合成得分函数 ,并从因式分解分布 中采样。
对于两种风格的合并,以及在不同强度 下两个概念 Adapter 的组合,作者观察到与LoRA相比,FouRA Adapter 的特征空间纠缠程度更低。进一步的分析包含在附录B.4和B.2中。
4 Theoretical Analysis
Frequency Domain Fine Tuning
频域变换去相关输入表示,最小化谱冗余[42],并且在压缩中有效,因为它们将大部分能量集中在少数几个系数上[13]。在频谱域的学习被证明可以实现更快的收敛和更稀疏的权重矩阵[9]。受到这些优势的启发,作者 Proposal 在频域微调 Adapter 。
作者在图4中经验性地分析了作者训练的UNet模型最后一层的 和 的 阶近似的奇异值分布。与LoRA相比,FouRA的奇异值分布更为紧凑。因此,使用引理4.1,作者可以说,对于低阶近似,LoRA Adapter 的累积误差将大于相同阶数的FouRA Adapter 。
Gated Frequency Domain Fine Tuning
受到[3; 19]中观察的启发,作者提出的排名门控机制旨在改变网络中每个低秩 Adapter 的有效排名。作者将每层的有效排名描述为未被学习到的门控函数 Mask 的奇异值的数量。利用[6; 19]中的观察,作者提出以下引理:
引理4.2.: 考虑一个 Adapter ,其排名高于适应训练数据分布所需的排名。当 Adapter 的有效排名降低时,微调此 Adapter 的一般化误差 的上界降低。将有效排名降低到某一特定值后,随着排名进一步降低,一般化误差的上界将增加.
推论4.2.1.: 此外,当 Adapter 权重 的奇异值分布更加紧凑时,一般化边界更稳定.
作者在附录B.2中提供了证明。可变排名选择的有效性可以使用引理4.2进行证明。随着LoRA排名的降低,模型倾向于欠拟合。然而,将排名提高到适应训练分布所需的排名之上会导致过拟合,这降低了模型的性能。在每个层中动态确定有效排名会产生有希望的结果,因为它在过拟合和一般化之间提供了一个可学习的权衡。
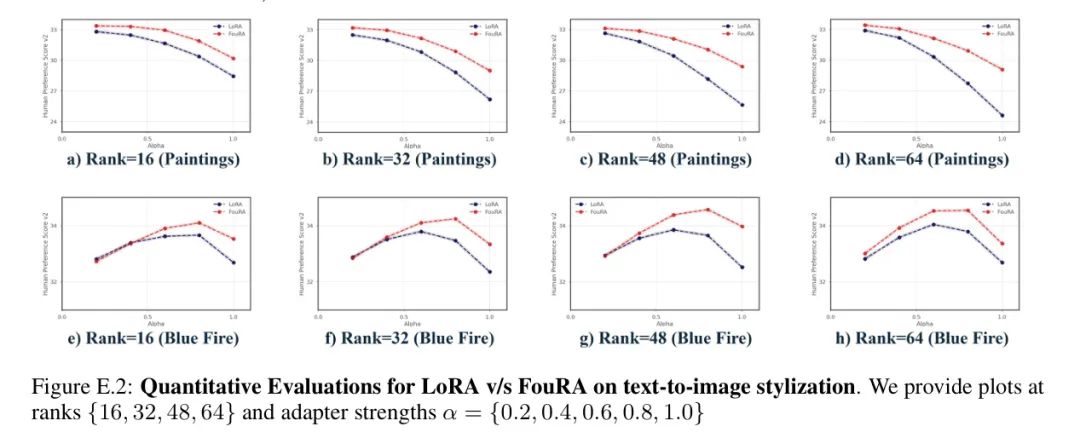
在图5中,作者绘制了去噪UNet在反向扩散过程20次迭代中的FouRA平均有效排名。作者的分析显示,对于高分辨率层,学到的有效排名高于低分辨率层。此外,随着去噪过程的进行,有效排名降低。这本质上意味着噪声输入需要更多的奇异值进行更新。作者在图9中进一步观察到,作者提出的自适应 Mask (在推理时变化)显著优于诸如SoRA(在训练后冻结其 Mask )的方法。
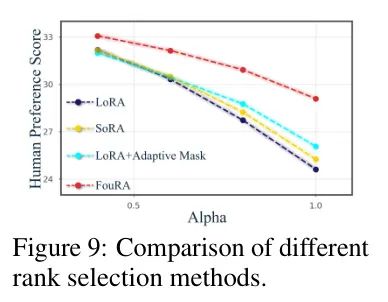

此外,从推论4.2.1和图4中观察到的性质的后果来看,由于FouRA获得了紧凑的奇异值分布,作者可以确定,与特征空间相比,在低有效排名下,频率域中的一般化边界更稳定。作者在图9中验证了这一点,因为FouRA凭借作者提出的自适应 Mask 优于SoRA和LoRA。图1中LoRA模型观察到的数据复制伪影是过拟合的结果。这是最近针对数字伪造[34; 35]的研究观察到的。由于FouRA显著降低了泛化误差,因此它可以生成一组多样化的图像。此外,作者在附录E.2.1中还观察到,与LoRA相比,FouRA能够更好地推广到未见过的概念。
5 Experiments
Experimental setup
数据集: 对于风格转换,作者在四个从公共领域收集的数据集上评估FouRA,包括_蓝焰_、_绘画_、_3D_和_折纸_风格,详细情况见附录C.1.2。作者的结果是通过对30个随机种子平均得出的,总共1530张图像。对于复合滑块的评估,类似于[8],作者训练了3个滑块_“年龄”_、_“头发”_、_“惊讶”_,并进行了将_“年龄”_和_“头发”_结合的复合实验。尽管作者的方法是为了视觉任务而设计的,但作者也对FouRA在语言任务上的表现进行了评估,并在MNLI、CoLA、SST2、STSB、MRPC和QNLI任务的GLUE基准上测试了作者的 Adapter 的性能。
模型: 对于文本到图像生成的实验,作者使用了Stable Diffusion-v1.5 [28],既用于基本模型权重,也用于RealisticVision-v3.0预训练权重进行风格转换任务。对于概念编辑,作者在Stable Diffusion-v1.5 [28]的基础权重上进行训练。对于通用语言理解任务,作者使用RoBERTA-Base [21]。
指标: 为了量化FouRA和LoRA微调扩散模型生成的图像质量,作者报告了HPSv2.1 [39]和LPIPS多样性[44]分数。HPSv2指标评估了图像质量以及与提示/风格的契合度。LPIPS多样性分数捕捉了所有可能生成的图像对之间的多样性。作者在附录D中对这些指标进行了深入分析。对于图像编辑任务,作者使用LPIPS相似性(与基本图像比较)来比较编辑后的图像。对于语言模型,作者在通用语言理解评估(GLUE)基准[36]上报告结果。
Text-to-Image Stylized Generation
图6:FouRA与LoRA对比:左边的提示是“田野中的足球”,右边是“神秘森林中的人”。在保持 Adapter 风格更忠实的同时,FouRA的输出在视觉上比LoRA更好,后者在高值时会出现明显的伪迹。附加结果在附录E中。

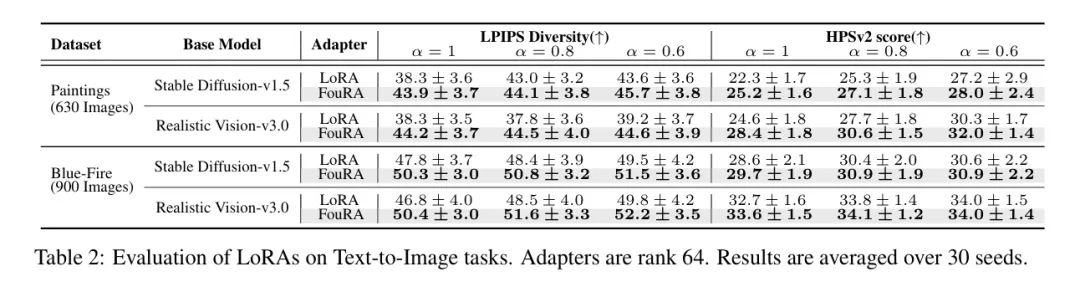
在图6中,作者展示了在_Paintings_和_Bluefire_风格任务上LoRA和FouRA的视觉结果。与LoRA相比,FouRA能够在一系列 Adapter 强度下生成高质量图像。作者观察到,在Paintings Adapter 的情况下,LoRA在高值时会出现伪迹。表2比较了所有模型的LPIPS多样性和HPSv2得分,显示FouRA在这两个指标上都显著优于LoRA。作者在App. D中的分析显示,这种LPIPS多样性和HPS得分的差距相当大,特别是在更高的值下,FouRA与LoRA相比显示出显著的增益。这可能是因为在较低的值下, Adapter 效应会减弱,因此两张图像看起来更真实。这些结果表明,FouRA图像既具有多样性(即使在高的 Adapter 强度下),又在视觉上保持连贯。
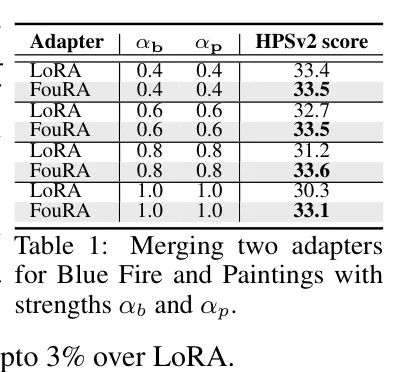
多 Adapter :图7展示了各种提示(如鸟、车、狐狸)在三种风格_Paintings_、_Bluefire_和_3D_下的风格转移合并图像。作者还提供了LoRA和FouRA线性组合在这两个任务上的输出。作者看到,合并后的LoRA图像有时会失去其中一个概念(例如,熊猫和狗的蓝色火焰消失了)或出现严重的伪迹(例如,多头狐狸和无头鸟)。相比之下,FouRA合并 Adapter 的图像保留了概念,并未显示任何失真。这种FouRA的性质是App. B.3中分析的直接结果,从表1中报告的HPSv2也明显可以看出,在更高的 Adapter 强度下,FouRA比LoRA高出3%。

Text-to-Image Concept Editing
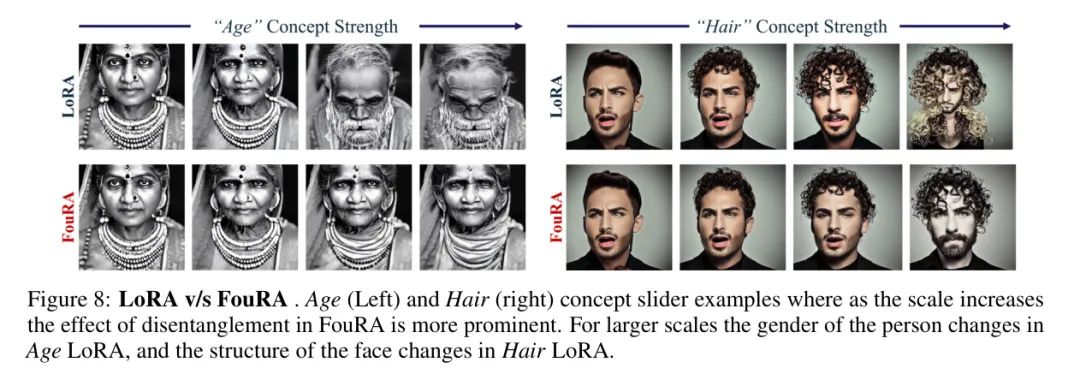
作者通过使用概念滑块[8]中提出的解耦目标来训练FouRA,以此建立针对特定目标图像的细致编辑任务上的方法性能。作者使用描述编辑概念的提示对来训练LoRA和FouRA模块。图8展示了编辑_Age_(年龄)和_Hair_(头发)概念的结果。观察发现,尽管Age Adapter 是用解耦目标进行训练的,但LoRA改变了主体的性别,并在高尺度上产生了伪影。而FouRA则能够优雅地对年龄进行编辑,同时保留其原始特征。同样,_Hair_ FouRA产生了更平滑的表示。作者在附录5.3中提供了定量评估,并观察到在更高强度下,FouRA在LPIPS得分上始终优于LoRA。
复合滑块:作者在附录5.3中对LoRA和FouRA之间的复合_'hair'(头发)和'age'_(年龄) Adapter 进行了定性评估。作者分别针对目标提示“A女性印度人”和“A男性白人”展示了结果。总体而言,作者观察到FouRA在合成这两个滑块方面做得更好,因为它在概念之间产生了平滑的过渡。相比之下,LoRA在高 Adapter 尺度上扭曲了主体的脸部,并干扰了其他面部特征。
通用语言理解任务
虽然作者对FouRA的设计选择主要是为了视觉任务,但作者还是在表3中评估了它在语言任务上的有效性,并与专为语言任务设计的另一种自适应排名选择方法SoRA进行了比较[3]。结果显示,在六个GLUE基准测试中的四个上,FouRA在频域中的排名选择优于SoRA,这表明FouRA引起的特征解耦可以应用于视觉任务之外。
Ablation Studies
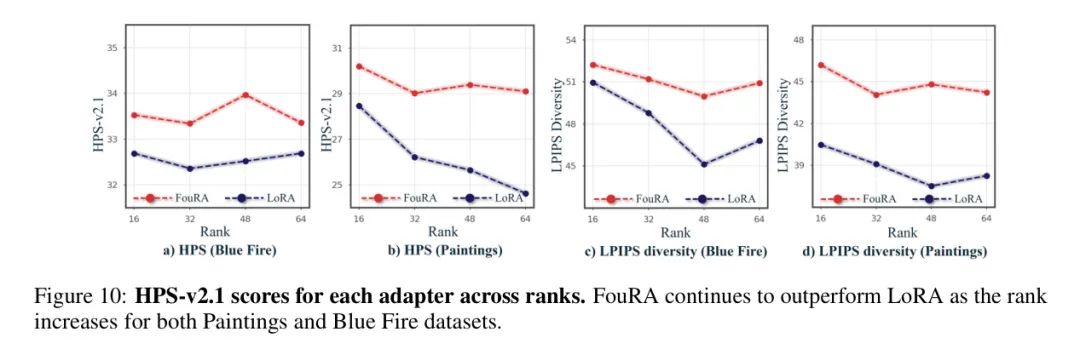
在文本到图像风格生成中变化排名:在图10中,作者研究了FouRA在不同输入排名值上的影响,并与LoRA进行了比较。作者观察到,对于LoRA来说,排名是一个非常敏感的参数。然而,FouRA在各个排名上的HPS分数都高于LoRA在任何排名上达到的最高HPS分数,这突显了频域中门控的效果。这帮助FouRA在排名降低时避免欠拟合,在排名增加时避免过拟合。此外,FouRA在所有排名上都生成了一组多样化的图像。
6 Conclusion
在本文中,作者提出了FouRA,一种在频域内的高效参数微调方法。通过大量的实验和严格的分析,作者展示了FouRA成功解决了与数据复制和分布崩溃相关的问题,同时在生成图像质量上显著优于LoRA。
作者还对转换域中低秩子空间的紧凑表示的影响进行了深入研究。
此外,作者展示了FouRA可以利用作者提出的自适应 Mask 排名方法,并进一步推动PEFT模型的泛化能力,而不会欠拟合。此外,作者还证明了FouRA在合并两个概念方面的有效性,因为频域作为多个 Adapter 之间的去相关子空间。
在评估FouRA的性能时,作者感到鼓舞,认为在未来的几年里, Adapter 在频域的微调可能成为一个热门的研究方向。
参考
[1].FouRA: Fourier Low Rank Adaptation.
腾讯云开发者
