基于 Transformer 进行检测,没有花哨的技巧,ChangeVi 取得最先进的表现 !
基于 Transformer 进行检测,没有花哨的技巧,ChangeVi 取得最先进的表现 !


在遥感图像中的变化检测对于追踪地球表面的环境变化至关重要。尽管视觉 Transformer (ViTs)作为许多计算机视觉应用的主干网络取得了成功,但它们在变化检测中的应用仍然不足,而在变化检测中,卷积神经网络(CNNs)因其强大的特征提取能力而继续占据主导地位。 在本文中,作者的研究揭示了ViTs在大规模变化辨别方面的独特优势,这是CNNs所欠缺的能力。利用这一洞见,作者引入了ChangeViT框架,该框架采用简单的ViT主干网络来提升大规模变化的性能。 这个框架辅以一个细节捕捉模块,用于生成详细的空间特征,以及一个特征注入器,它有效地将细粒度的空间信息整合到高级语义学习中。 特征整合确保了ChangeViT在检测大规模变化和捕捉细粒度细节方面都表现出色,实现了跨多种尺度的全面变化检测。 无需任何花哨的技巧,ChangeViT在三个流行的高分辨率数据集(即LEVIR-CD、WHU-CD和CLCD)和一个低分辨率数据集(即OSCD)上均取得了最先进的表现,这强调了ViTs在变化检测中未被充分利用的潜力。 此外,彻底的定量和定性分析验证了所引入模块的有效性,巩固了作者的方法的有效性。 源代码可在https://github.com/zhuduowang/ChangeViT获取。
I Introduction
变化检测在遥感领域扮演着至关重要的角色,它使用在不同时间获取的同一地理区域的双时相图像对来追踪地球表面随时间的变化[1]。它已被广泛应用于各种应用,如灾害评估[2]、城市规划[3]、耕地保护[4]和环境管理[5]。近年来,卷积神经网络(CNNs)已成为最先进变化检测器的主要 Backbone 选择,因为它们可以提取丰富的层次特征以检测不同大小的变化。
在过去的几年里,视觉 Transformer (ViTs)[11]实际上已经取代了CNN,成为各种计算机视觉任务中的主导 Backbone ,例如目标检测、图像分割、图像修边和姿态估计,这些任务的性能优于基于CNN的方法,得益于其长距离建模能力。尽管在一些初步研究中已经探讨了 Transformer 在变化检测的背景下,但它们的性能尚未达到领先CNN模型的水平。因此,本文旨在研究ViTs对变化检测的潜在益处,力求在这一领域发挥其有效性。
为了评估ViTs在变化检测任务中的有效性,作者首先对利用ViTs和三种已建立的CNN架构作为 Backbone 的变化检测器进行了全面的性能比较,即ResNet18、VGG16 和UNet 。这个评估涵盖了三个著名的数据集,即LEVIR-CD、WHU-CD 和CLCD,如图1(a)所示。此外,作者通过将来自 DeiT、DINO和DINOv2 的预训练权重纳入作者的分析,探讨了各种模型初始化的影响。具体来说,ResNet18、VGG16、UNet和ViT-S(DeiT)在ImageNet-1k上使用有监督训练进行预训练,而ViT-S(DINO)和ViT-S(DINOv2)则使用自我监督训练在ImageNet-1k、ImageNet-22k和Google地标等进行预训练。
结果表明:
(1)无论是有监督还是自我监督学习,CNN模型在所有数据集上的性能都显著优于所有ViTs,突显了CNN在变化检测任务中的主导地位。
(2)即使使用相同的数据初始化(即ImageNet-1k),ViTs的性能仍然低于基于CNN的模型。
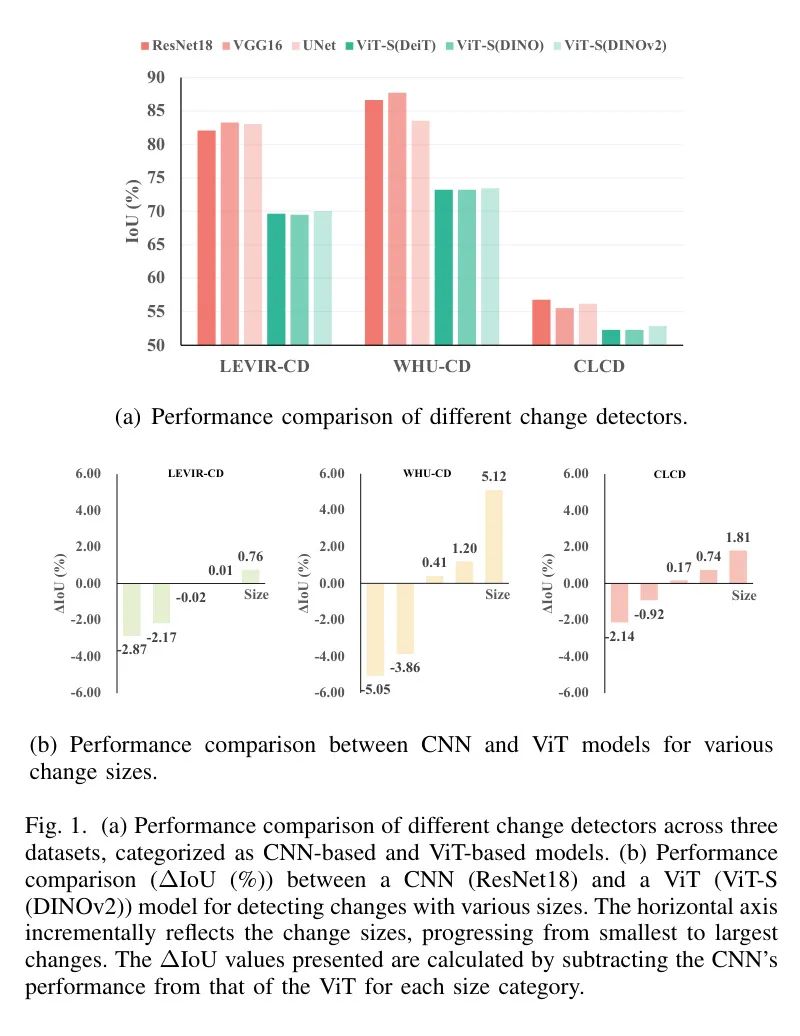
为了深入了解模型的性能,作者对一个ViT模型(使用DeiT预训练的ViT-S)和一个CNN模型(使用ImageNet-1k预训练的ResNet18)在不同目标大小下的变化检测能力进行了深入分析,如图1(b)所示。作者将每个数据集的测试样本根据图像中不同目标占据的像素比例进行组织。具体来说,作者首先按照变化目标占图像总像素比例的升序对图像进行排序。然后,作者将这个有序序列均匀地分为五个类别,从最小的比例到最大的比例。作者计算了在每个类别中ViT和CNN模型之间的平均性能差异。结果显示,尽管ViT在检测较小变化方面落后于CNN,但它们在所有数据集中对较大目标的可靠性有所增强。这些洞察表明,尽管ViT不能像CNN那样有效地捕捉到细粒度细节,但它们在大规模变化检测方面表现出色。因此,这种之前未充分利用的优势有可能有效地缓解CNN架构固有的局限性。
基于作者之前分析的洞察,作者提出了ChangeViT,这是一个简单而有效的框架,它以普通的ViT框架为核心,捕捉大规模目标信息,并结合了一个专门用于关注细粒度特征的细节捕捉模块。细节捕捉模块作为一个辅助网络,包含了ResNet18 [20]的选择层(C2-C4),与完整的CNN模型(1120万参数)相比,其提供了更紧凑的足迹(270万参数)。为了将这些细粒度细节无缝地注入到ViT的特征表示中,作者在ViT的表示和细粒度特征之间建立了联系。这种整合是通过将ViT特征视为 Query ,并应用交叉注意力机制合并细粒度特征来完成的。
在四个广泛认可的数据集上进行了大量实验,即LEVIR-CD [23],WHU-CD [24],CLCD [25],和OSCD [29],ChangeViT在所有方面都达到了最先进的性能。此外,作者将所提出的模块与各种分层 Transformer 结合使用,例如Swin Transformer [30],PVT [31]和PIT [32]。在这些架构中,所提出的模块一致地提高了性能,从而进一步证实了它们的有效性。值得注意的是,尽管与这些先进的分层网络相比,普通ViT存在一些局限性,但ChangeViT仍然超越了使用这些复杂模型的方法,展示了作者在变化检测领域有效地释放了普通ViT的潜力。
本文的主要贡献可以总结如下:
- 作者深入研究了普通ViT的性能,并确定了它们在检测大规模变化方面的潜力。受到这一发现的启发,作者提出了ChangeViT,这是一个简单而有效的框架,它使用普通的ViT作为变化检测任务的主要特征提取器。
- 为了增强对不同尺寸变化的检测,作者整合了一个细节捕捉模块,特别用于解决ViT在识别小物体时的局限性。
- 此外,作者引入了一个特征注入器,将提取的细节特征与来自ViT的高级特征融合,确保模型内部具有全面的特征表示。 ChangeViT在四个流行数据集上取得了最先进的表现,即LEVIR-CD、WHU-CD、CLCD和OSCD,证明了作者提出方法的优势。
- 此外,彻底的定量和定性分析验证了作者引入模块的有效性,进一步巩固了作者方法的有效性。
II Related Work
Change Detection
关于网络架构,目前采用深度学习的变化检测方法大致可以分为两类:基于CNN的方法和基于Transformer的方法。
基于CNN的方法。 基于CNN的变化检测方法在文献中长期为主流框架,以其分层特征建模能力而闻名。这些工作主要关注多尺度特征提取、差异建模、轻量级架构设计以及前景-背景类别不平衡问题。例如,文献[35, 39]中的方法利用全卷积网络来捕获分层特征,以学习多尺度特征表示。为了充分进行差异特征建模,文献[33, 36]中的方法结合了注意力机制来建立双时相特征之间的关系依赖。相比之下,Changer[34]引入了一种无参数的方法,该方法简单交换每个阶段的特点,以捕捉和感知彼此的信息。文献[3, 9]中的方法专注于设计高效有效的网络架构,使用轻量级特征提取器[40, 41]作为主干。一些研究[37, 7]通过开发创新的损失函数来解决前景-背景类别不平衡这一重大挑战,这些损失函数优先考虑前景变化,同时最小化来自背景噪声的干扰(例如,季节变化,气候变化)。
基于Transformer的方法。 最近,Vision Transformer[11]及其变体[30, 31, 42]在多种视觉任务中超越了CNN,并成为主导主干[12, 14, 43, 15]。受这些成果的启发,一些工作[6, 16, 17, 18, 19, 44, 45]探索了Transformer在变化检测任务中的应用。其中一些方法[18, 45]使用纯Transformer,而其他方法[6, 16, 17, 44]采用CNN-Transformer混合架构。文献[18, 45]中的方法基于swin transformer[30]引入了分层Transformer网络。其他方法通常遵循这样一种范式:CNN提取的特征作为语义标记,然后使用Transformer块在双时相标记之间进行上下文关系建模。文献[19]中介绍的方法展现了一种有效的调优策略,包括在引入额外可训练参数的同时冻结Transformer编码器的参数。然而,由于对Transformer的优势和局限性探索不足,这种方法未能提供最佳结果。这阻止了更有效地应用模型能力,从而限制了性能潜在增益。
与之前主要使用分层网络的方法不同,所提出的ChangeViT应用普通的ViT作为基石特征提取器,作者发现它在检测大规模变化方面具有先前未被识别的潜力。
Plain ViT for Downstream Tasks
ViT [11]是一种简单而非分层的架构,它是图像分类中标准CNN的有力替代品。由于ViT中的自注意力计算开销巨大,后续研究专注于设计更高效的架构,如Swin [30],PVT [31]和PiT [32]。这些研究继承了CNN的一些设计,包括分层结构、滑动窗口和卷积。最近,研究行人开始研究ViT在各类下游任务中的潜力,这受到了大型预训练模型出现的影响,例如DeiT [26],DINO [46],DINOv2 [28],MAE [47]和CLIP [48]。简单的ViT已经在密集预测[12, 13, 43]、姿态估计[15]、图像修整[14]等方面取得了显著进展。ViTDet [12]首次采用简单的非分层ViT作为目标检测的 Backbone 网络,并进行了最小的适配,即构建了一个简单的特征金字塔用于单尺度特征,并辅助少量跨窗口进行信息传播。ViT-Adapter [43]引入了一种无需重新设计架构的、免预训练的 Adapter ,为各种密集预测任务向ViT注入先验知识。同样,SimpleClick [13]和ViTPose [15]将纯ViT作为特征提取器来获取单尺度特征。对于图像修整,ViTMatte [14]是首个通过简洁适配来释放ViT潜力的工作。
受到上述工作的启发,作者旨在释放简单ViT模型的潜力,使其能够很好地适应变化检测任务。
III Proposed Method
整个架构如图2所示。对于双时相图像 和 ,它们被并行输入到ViT和一个细节捕捉模块中。ViT提取高级特征 ,其中 代表两个阶段,而细节捕捉模块获取细粒度的多尺度特征 (,)。为了增强在高级特征中复杂细节的检测,作者引入了一个特征注入器,旨在将低级细粒度信息集成到 中。最后,应用了一个多尺度特征融合解码器来预测变化概率图 。
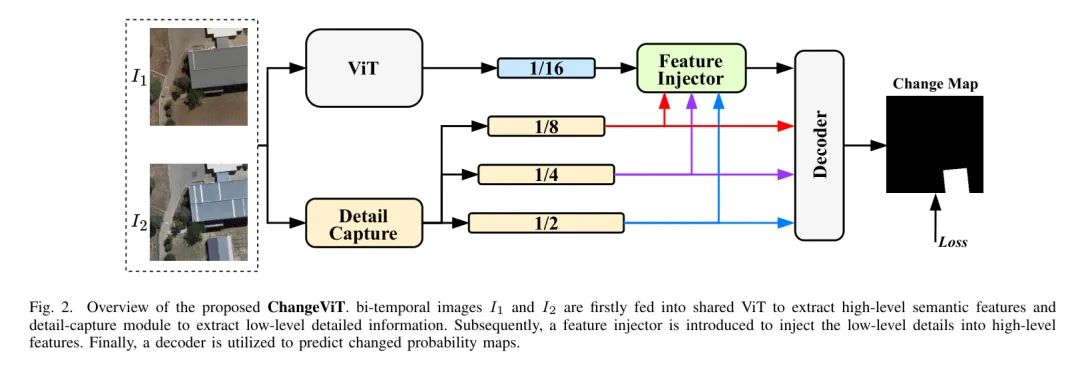
Feature Extraction
特征提取器由一个普通的ViT组成,以及一个如下所述的细节捕捉模块:
普通ViT。 双时态图像 、 被送入切块嵌入层,将它们划分为非重叠的 块。这些块随后被展平并投影到 维度的标记,特征分辨率降低到原始图像的 。之后,位置嵌入被添加到这些标记中,它们通过 个 Transformer 层。每一层由一个层归一化(LN)、一个多头自注意力(MHSA)和一个前馈网络(FFN)组成。这些层的公式由方程式1和方程式2给出:
其中 表示第 个 Transformer 层的输出。ViT主干的最终输出表示为 ,其中 等于 。
细节捕捉。 如第一节所讨论,ViT在大变化检测方面表现出色,但对于小变化的检测效果降低。为了解决这一挑战,作者引入了一个细节捕捉模块,旨在补偿对于变化检测至关重要的细粒度局部线索的缺失。该模块由三个残差卷积块(C2-C4)组成,这些块改编自ResNet18 [20]。通过细节捕捉模块处理输入图像后,生成了三个尺度的详细特征,即 、 和 ,表示为 ()。
Feature Injector
在变化检测任务中,保留详细的空间特征至关重要,因为它们可以帮助检测小物体。确保低级细节有效地传递到高级语义特征是至关重要的。
因此,作者引入了一个特征注入器,它由三个交叉注意力块[49]组成,如图3(a)所示。它将低级特征视为键和值向量,将高级特征视为 Query 向量。从直观上讲,这是合理的,因为它允许特征注入器根据提供的键信息收集最相关的信息,并将其整合到 Query 中。通过启用跨层特征传播,可以将详细信息融入到ViT的高级表示中,记作。的计算如下:
其中表示低级层的索引,作为 Query ,分别作为键和值。是一个核大小为的2D深度卷积,表示沿通道维度的拼接操作。
此外,作者探讨了特征注入器的另一种方法,如图3(b)所示,它将低级特征视为 Query ,将ViT的语义信息视为键和值,以根据分层详细特征的特点细化ViT的表示。
Decoder and Optimization
与现有方法[6, 7, 36, 44]相比,后者采用复杂技术来建模差异信息并预测变化概率图,作者选择了一个更简单的解码器来更好地展示ChangeViT的学习能力。具体来说,作者使用一个直接的特征融合层来捕获双时相特征之间的差异。随后采用级联卷积层以及上采样操作,从深层到浅层逐步聚合差异特征,最终将其恢复到原始分辨率。差异建模公式如下如Eq. 5所示:
其中 (),是一个具有核大小以及ReLU激活函数的三层2D卷积网络,表示在通道维度上进行拼接,表示绝对值操作。
为了恢复变化图的原始分辨率,作者使用了一个简单的级联上采样操作,表示如下:
其中是一个具有核大小的2D卷积,用于减少通道维度,表示具有核大小和步距大小的2D反卷积,用于上采样特征图。
最后,将一个分类层应用于最浅的特征以生成变化图,如Eq. 7所示:
其中是一个具有核大小的2D卷积,函数将特征图映射到范围内,然后根据预定义的阈值(例如0.5)将其转换为二值图,即。
如之前的工作[7, 9]所述,变化目标的比例显著低于未变化目标的比例。遵循这些工作,作者采用二元交叉熵(BCE)和Dice损失(Dice)[50]来减轻类别不平衡问题。变化检测损失定义如Eq. 8所示:
BCE和Dice损失定义如下:
其中表示第个像素,是总像素数,表示 GT 情况,(例如1e-5)是一个平滑项,用于避免零除。
IV Experiments
作者在三个广泛使用的高分辨率数据集上进行了大量实验,分别是LEVIR-CD [23]、WHU-CD [24]和CLCD [25],以及一个具有挑战性的低分辨率数据集OSCD [29],以证明所提出方法的有效性。为了更好地理解ChangeViT的每个组成部分,作者在第IV-E节中进行了广泛的诊断实验。除非另有说明,作者在三个高分辨率数据集上的实验使用的是ChangeViT-S。
Implementation Details
作者采用标准的ViT [11] 作为主要的基础网络架构,特别是其小型和微型版本,构建了两个模型,分别命名为ChangeViT-T和ChangeViT-S。作者分别使用DeiT [26] 和DINOv2 [28] 的预训练权重进行初始化。作者的模型使用PyTorch框架 [51] 实现,并在一个计算平台上执行,该平台配备了一个NVIDIA GeForce RTX 3090 GPU和一个Intel(R) Xeon(R) Gold 6138 CPU。对于优化,作者选择Adam优化器 [52],将beta值设置为(0.9,0.99),权重衰减为1e-4。初始学习率为2e-4,并根据预定减少公式逐渐降低:(1-(curr_iter/max_iter)) lr,其中 设置为0.9,max_iter 分别针对LEVIR-CD和WHU-CD设置为80K迭代,CLCD数据集为40K,OSCD为10K。所有实验中的批处理大小保持在16。为了增强训练数据并提高模型的鲁棒性,作者应用了随机翻转和裁剪数据增强方法。 的通道维度分别设置为64、128和256。此外,为确保比较的一致性和公平性,作者精心对齐了与原论文中指定的比较方法的实验设置。
Datasets
Iv-B1 LEVIR-CD
这个数据集[23]包含了637对高分辨率(1024×1024,0.5米/像素)的双时相图像对,数据来源于谷歌地球。这些图像代表了德克萨斯州各个城市中的20个不同区域,包括奥斯汀、拉克韦eway、比伊洞穴Bee Cave、布达Buda、凯尔Kyle、曼纳Manor、普夫鲁格维尔Pflugervilletex、滴水泉Dripping Springs等地。该数据集包含了31333个单体建筑变化的标注,覆盖了从2002年到2018年在不同地点捕获的图像。按照[6]中建立的裁剪方法,每张图像被分割成16个独特的256×256块。因此,数据集被划分为7120对用于训练,1024对用于验证,以及2048对用于测试。
Iv-B2 WHU-CD
这个公开可用的数据集[24]专注于建筑变化检测,包括高分辨率(0.2米)的双时相航拍图像,总像素为3250715354。它主要包含受地震影响及随后重建的区域,主要是建筑翻新。遵循[33]中详细描述的标准程序,将数据集图像划分为256256的不重叠块。数据集被划分为5947个训练对,744个验证对和744个测试对。
Iv-B3 CLCD
CLCD[25]数据集由耕地变化样本组成,包括建筑物、道路、湖泊等。CLCD的双时相图像分别于2017年和2019年由我国广东省的高分二号卫星收集,空间分辨率从0.5米到2米不等。按照[6]中详细描述的标准流程,数据集中的每张图像被分割成256×256的 Patch 。因此,CLCD数据集分别被划分为1440、480和480对用于训练、验证和测试。
Iv-B4 Oscd
OSCD数据集[29]是一个相对低分辨率的数据集,其分辨率在10米到60米之间。该数据集由Sentinel-2卫星在不同城市化水平的各国捕获,并经历了城市增长或变化。这种分辨率使得可以在图像对中检测到大建筑物。然而,较小变化,如小建筑物的出现、现有建筑物的扩建或道路车道的增加可能不明显,这使得多样性的变化检测具有挑战性。该数据集由大约600×600像素的24个区域组成。按照通常的做法,数据集中的每个图像被裁剪成256×256的块。因此,OSCD数据集被划分为75个训练对和28个测试对。
Evaluation Metrics and Compared Methods
评估指标与比较方法部分的开头。
Iv-C1 Evaluation Metrics
在作者的变化检测任务中,遵循广泛使用的评估协议,作者使用了三种准确度指标,即F1分数()、交并比(_IoU_)和总体准确度(),来评估作者提出的方法。它们如下所示:
其中TP、FP、TN和FN分别表示真正例、假正例、真负例和假负例。对于所有指标,值越高意味着检测性能越好。
Iii-B2 Compared Methods
为了验证所提出方法的有效性,选择了以下九种具有代表性的开源方法进行对比,具体如下:
a) DTCDSCN [38]:引入了一种双任务约束的深度孪生卷积网络,能够完成变化检测和语义分割。它应用通道和空间注意力来改善交互特征表示。
b) SNUNet [53]:通过密集连接的孪生网络提取双时相差分特征,不仅关注高级语义特征,也关注低级细粒度特征。
c) ChangeFormer [18]:通过分层swin-transformer编码器和解码器提取多尺度长距离特征,并采用多层感知机。
d) BIT [16]:将双时相图像表示为语义标记,然后使用 Transformer 编码器建模上下文,以及 Transformer 解码器细化富含上下文的标记。
e) ICIFNet [33]:一种内尺度交叉互动和间尺度特征融合网络,共同捕捉时空上下文信息,并获得双时相特征短-长距离表示。
f) DMINet [36]:一种跨时相联合注意力模块,包括自注意力和交叉注意力块,旨在建模输入图像的全局关系。
g) GASNet [7]:这是一种CNN-transformer模型,使用CNN作为 Backbone 网络提取多尺度特征,并采用 Transformer 编码器-解码器建模上下文信息。
h) AMTNet [6]:提出了一种全局感知网络,该网络建模场景和前景之间的关系,以解决变化检测任务中的类别不平衡问题。
i) EATDer [44]:一种边缘辅助检测器,它融合了一个边缘感知解码器来整合编码器获得的边缘信息,从而增强变化区域的特征表示。
Comparison with State-of-the-Art Approaches
如表格I所示,作者将ChangeViT与之前的方法在三个高分辨率数据集上进行比较,即LEVIR-CD、WHU-CD和CLCD。值得注意的是,所有比较的方法都采用分层 Backbone 网络作为主要特征提取器。具体来说,DTCDSCN、BIT、ICIFNet、DMINet、GASNet和AMTNet应用ResNet[20]或其变体[54]作为 Backbone 网络,SNUNet和EATDer分别应用嵌套UNet[22]和堆叠非局部块[55]。相比之下,作者的方法采用非分层的、普通的ViT作为核心 Backbone ,包括ViT-T和ViT-S,并结合一个轻量级的细节捕捉模块,作为辅助网络。
从表格I中,作者可以总结以下有价值的研究发现:
(1)尽管使用了ViT的小型 Backbone ,ChangeViT在所有数据集和评价指标上始终优于现有工作,这证明了其有效性。
(2)尽管ViT中的主要特征提取器是非分层的,但与基于分层的方法相比仍显示出有竞争力的性能。这凸显了大规模预训练ViT在特征提取和表示能力方面的强大性能,充分实现了其潜力。
(3)值得注意的是,ChangeViT-T和ChangeViT-S在WHU-CD数据集上比SOTA方法(即AMTNet)分别高出3.99%和4.54%的IoU。这一发现是合理的,因为WHU-CD中的变化范围很广,与较小和较大的物体相比,中等大小的物体较少。这一观察与图1(b)中间部分所示的结果一致,强调了作者提出的方法在捕捉全局特征和提取细粒度空间信息方面的有效性。
(4)随着主要特征提取器大小的增加,ChangeViT显示出增强的性能。值得注意的是,仅包含2.7M参数的细节捕捉模块,与每个模型的参数总数(即11.68M和32.13M)相比,其轻量级特性非常突出。作者提出的ChangeViT与之前的方法相比,在效率和效果之间取得了更好的平衡,突显了其优越性。
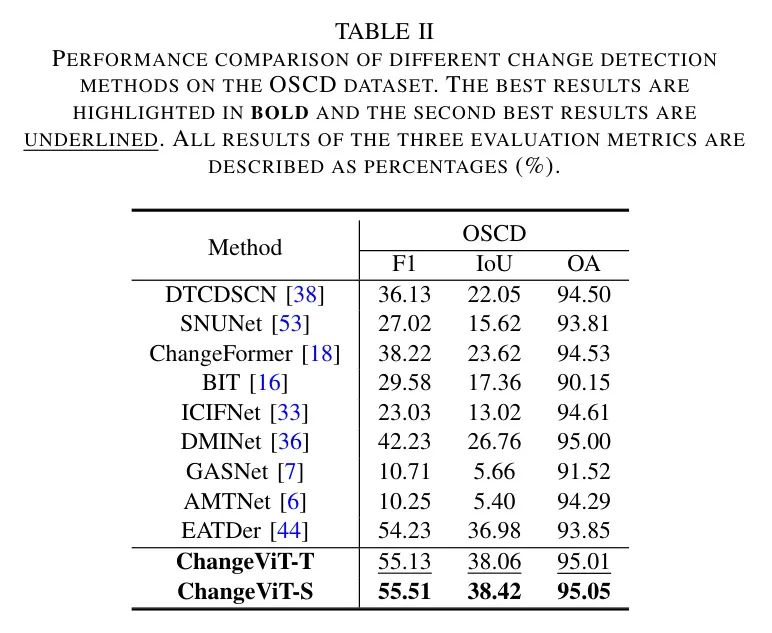
如表2所示,作者还将在低分辨率数据集OSCD上对ChangeViT与几种现有方法进行比较。OSCD中的目标相对于高分辨率数据集来说较小,这加剧了前景-背景不平衡问题,使得检测较小目标变得具有挑战性。从表2中,作者可以注意到以下要点:(1)尽管使用了ViT的小型或小型模型,提出的ChangeViT在三个评价指标上均优于所有比较方法,这证明了其在低分辨率数据集上的有效性。(2)GASNet和AMTNet在这个数据集上的表现不佳,可能是由于它们在检测小目标方面的效率不高。尽管GASNet引入了前景感知模块来处理前景和背景之间的类别不平衡,但在检测低分辨率遥感图像中的变化时仍然表现不佳。
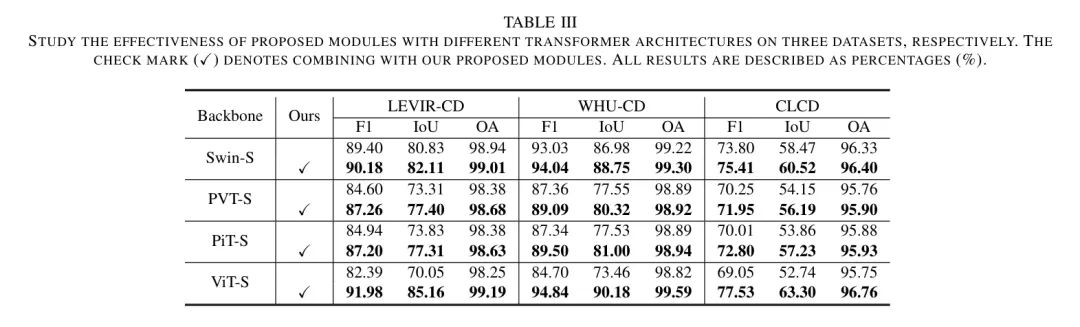
Diagnostic Study
不同架构下的有效性。 如表3所示,作者研究了所提出模块在不同架构下的有效性,包括分层(例如,Swin-S [30],PVT-S [31],PiT-S [32])和非分层(即,ViT-S [11]) Transformer 。
从表中可以得出几个关键观察结果:
(1)在没有结合作者提出的模块的情况下,非分层的ViT-S在所有指标上均低于其他分层方法在三个数据集上的表现。
(2) 当集成作者的 Proposal 模块后,所有 Transformer 都显示出性能提升,这表明作者的方法无论 Transformer 架构如何都是有效的。(3) 当装备了作者提出的模块后,ViT-S比分层 Transformer 获得了显著的性能提升,这表明作者的模块有效地缓解了ViT-S在捕捉细节信息以检测较小物体方面的局限性。
Proposal 模块的有效性。 为了研究 Proposal 模块的有效性,作者在三个数据集上进行了全面的诊断实验。如表4所示,作者考虑了各种组件的组合,并探索了每个模块的贡献。作者将ViT作为 Baseline ,它包括一个普通的ViT和一个解码器。结合细节捕捉模块,ViT可以发挥其潜力,与 Baseline 相比,在三个数据集上的F1分别提高了8.81%,8.60%和6.18%,这表明细节捕捉模块可以补充对变化检测任务至关重要的详细空间信息。此外,当结合特征注入器时,F1还有额外的0.78%,1.54%和2.17%的性能提升,这表明在更高层次上融合详细信息是有效的。总之,作者提出的所有模块在ChangeViT框架中都是必要的和有效的。
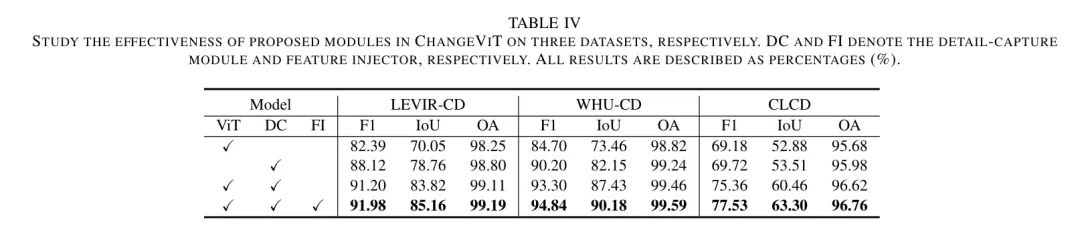
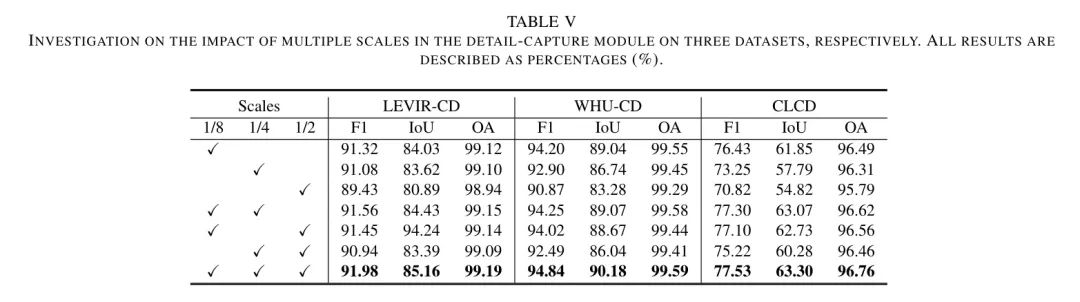
多尺度的影响。 为了研究在细节捕捉模块中捕获多尺度的必要性,作者使用多尺度特征(即1/2,1/4,1/8)进行了实验。如表5所示,作者可以得到以下关键观察结果:
(1) 单一尺度特征通常会导致较差的结果,而多尺度特征的结合可以带来性能的提升。
(2) 有趣的是,高级特征或其组合可以实现比低级特征更好的性能。
(3) 此外,包含三个尺度特征会导致相互改进,这表明多尺度特征可以利用跨互补层次的的空间线索。
预训练权重的影响。 为了研究预训练权重对ChangeViT的影响,作者采用了各种模型初始化方法,包括随机初始化以及几种公开可获得的大规模预训练权重,这些权重来自于在各类数据集上采用监督和自监督训练策略的预训练。如Tab. VI所示,作者观察到以下关键点:(1) 与随机初始化相比,ChangeViT-T和ChangeViT-S在利用预训练权重时展现出了检测精度的提升。(2) DINOV2-S为ChangeViT-S模型提供了最有效的预训练权重,这得益于大规模数据预训练。(3) 当DMINet、GASNet、AMTNet和ChangeViT在相同数据上,即ImageNet-1k上进行预训练时,所提出的ChangeViT优于所有基于CNN的方法,这证明了将大型预训练ViT模型的优先级转移到变化检测任务中的有效性。
Query 、键和值的选取。 如Tab. VII所示,作者在特征注入器中进行了两项实验,以研究不同的建模方法。在第一个实验中,作为 Query ,作为键和价值,得到了最佳性能。这一结果与第三节B中的猜想一致,表明特征注入器有效地捕捉到与高级 Query 最相关的低级价值信息,并将其重新整合回 Query 中。因此,通过交叉注意力机制,高级细粒度特征可以与低级特征无缝融合。
变化大小与性能的关系。 如图4(a)所示,作者在三个数据集上使用细节捕捉模块、ViT-S和作者所提出的方法进行实验,以定量分析每种方法在不同变化大小下的性能。细节捕捉模块和ViT-S都与ChangeViT相同的解码器整合。结果表明,细节捕捉模块擅长检测较小的变化目标,而ViT-S在检测较大的目标时表现出优势。作者的方法利用ViT强大的特征表达能力,同时利用细节捕捉模块挖掘细粒度信息。这种全面的方法使所有大小的目标都能获得优越的性能。
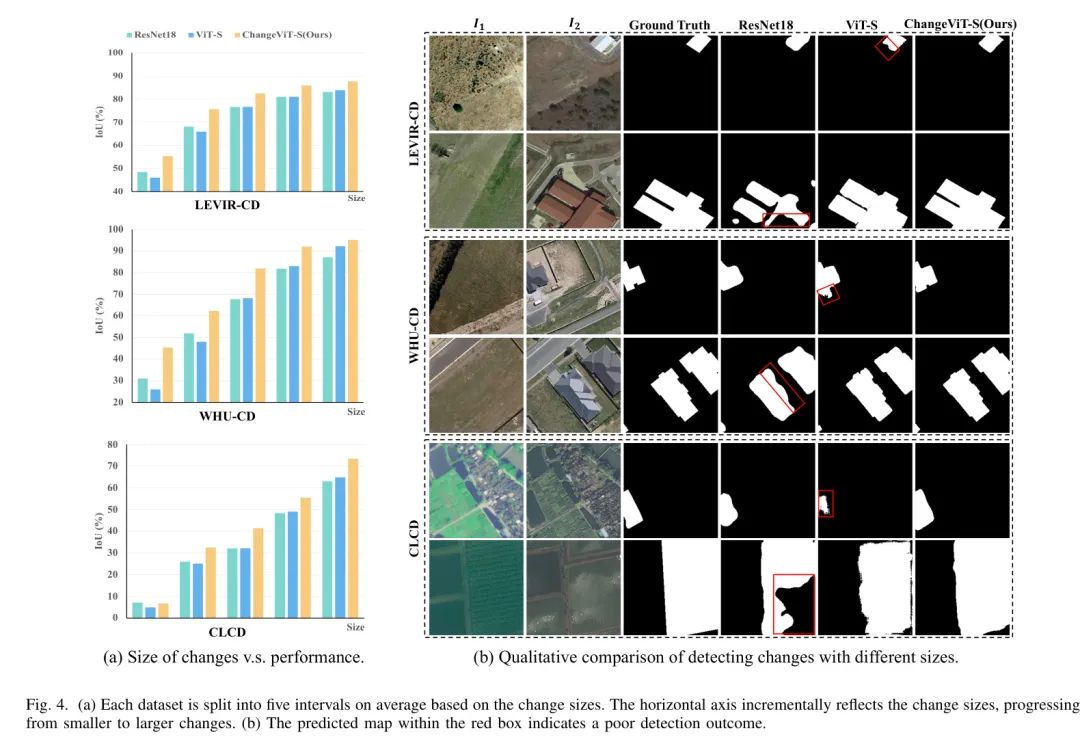
定性结果。 作者在三个数据集上展示了代表性的可视化结果,比较了细节捕捉模块、ViT-S和作者所提出方法的性能,以证明ChangeViT的有效性。如图4(b)所示,每个数据集的第一行展示了较小目标的测试结果,而第二行对应较大目标的结果。从结果可以看出,细节捕捉模块擅长检测较小目标,而ViT-S在检测较大目标时表现出优势。基本的区别在于CNN的局部感受野,使其能够提取复杂的局部特征,而ViT具有全局感受野,有助于提取全面的全局信息。所提出的方法有效地整合了全局和局部信息,从而获得了更优的性能。
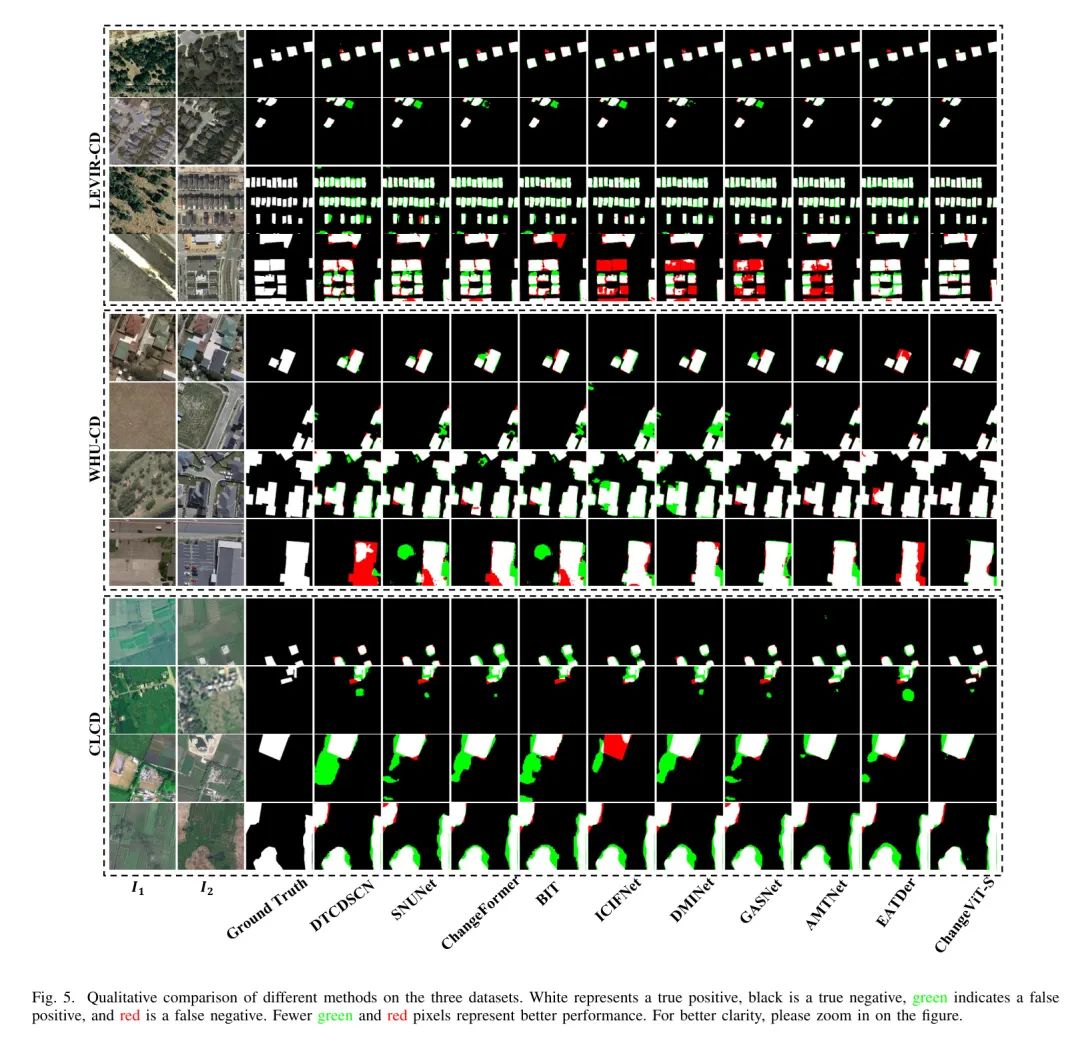
为了与先前的方法进行定性比较,作者提供了涵盖小、大、稀疏和密集目标的全面样本,如图5所示。从这些样本中,直观地得出几个关键观察结果:
(1)作者提出的方法在各种各样的变化大小上始终优于所有比较方法。这归功于ViT的健壮全局建模能力和细节捕捉模块提取复杂空间信息的能力。此外,特征注入器将低 Level 的细粒度空间特征整合到ViT的高级语义表示中,增强了ChangeViT检测不同大小变化的能力。
(2)在检测密集目标时,无论其大小如何,ChangeViT始终比先前方法更能清晰地勾勒出边界。这突显了ChangeViT在捕捉相邻目标的全球语义信息和局部空间细节方面的有效性。
V Conclusion
在本论文中,作者提出了一种简单而有效的框架,名为ChangeViT,它以普通的ViT作为其主要特征提取器来捕捉大规模变化。结合一个专注于细粒度空间特征的细节捕捉模块,ChangeViT通过跨注意力机制将这些细节无缝地融入到ViT的特征表示中。
实验结果表明,在四个广泛采用的数据集上,ChangeViT在所有评估指标上均优于精心设计的分层模型,凸显了普通ViT在变化检测中尚未发掘的潜力。
此外,全面的分析诊断和可视化结果提供了对每个模块贡献的见解。
作者希望本研究能为研究界提供有价值的见解,并激发对普通ViT在其它相关计算机视觉任务中的应用探索,例如变化描述。
参考
[1].ChangeViT: Unleashing Plain Vision Transformers for Change Detection.
腾讯云开发者
