SLAM | 融合激光雷达与图像数据,通过3D高斯溅射实现室内精确定位!

SLAM | 融合激光雷达与图像数据,通过3D高斯溅射实现室内精确定位!

AIGC 先锋科技
发布于 2024-07-08 13:10:35
发布于 2024-07-08 13:10:35

同步定位与地图构建(SLAM),即对由(3D)地图表示的环境进行重建并与姿态估计同时进行,已经取得了惊人的进展。 同时,面向复杂环境如工厂车间或建筑工地进行数据收集的大规模应用变得可行。然而,与小规模场景,如单个房间的室内建筑相比,车间或施工区域需要在可能没有纹理的区域和困难光照条件下进行更大距离的测量。 由于这类室内应用通常没有GNSS测量值,姿态估计的难度进一步加大。在作者的工作中,作者通过一个配备有四个立体相机以及一个3D激光扫描器的机器人系统在一个大型工厂大厅进行数据收集。 作者应用了最先进的激光雷达和视觉SLAM方法,并讨论了在这种环境下进行轨迹估计和生成密集地图时不同传感器类型的各自优缺点。 此外,通过3D高斯溅射生成了密集且精确的深度图,作者计划在旨在自动施工和工地监控的项目背景下使用这些深度图。
1 Introduction
光学传感器外方位估计以及同时重建三维(3D)环境的问题在计算机视觉领域中通常被称为SfM(Structure from Motion),在机器人学中被称为SLAM(Simultaneous Localisation and Mapping)[1]。
在SLAM的背景下,外方位的估计是连续实时进行的,经常旨在从图像和/或激光扫描数据在各种室内场景中进行数据采集。本文所展示的工作是由斯图加特大学综合计算设计与建筑集群卓越中心(IntCDC,2024a)的一个项目推动的,该项目旨在监测建筑工地。这项工作的总体目标是利用数字技术为建筑行业的制造和施工带来潜力。建筑业历来是劳动密集型行业,但它可以从承诺比人工或传统方法更准确、更高效的自主机器人中受益。
在这种背景下,一个关键任务是直接对建筑工地进行数字数据捕获和监测,例如用于生成BIM和数字孪生。这种记录是地理测量捕获3D点云的重要应用场景。
在过去,固定站的陆地激光扫描(TLS)定义了标准方法,而现在,采用SLAM方法的移动系统越来越多地被使用。在这种场景中进行数据收集的最先进技术,例如由Hiti SLAM挑战赛[16]的结果所展示。对于这个基准测试,数据采集是由一个手持系统完成的,该系统配备了IMU、多相机头和激光扫描设备[12]。
根据所应用的传感器类型,SLAM算法分为激光雷达(LiDAR)和视觉SLAM。当前的视觉SLAM方法可以相当好地提供密集表示,但通常限于纹理丰富的环境和相对较小的空间,例如单个房间,这些通常在较短的测量距离处捕获。
相比之下,大型室内场景(如建筑工地和工厂大厅)的实际应用仍然具有挑战性,并且可能从激光雷达扫描更大的测量范围中受益。图1举例展示了作者论文中讨论的激光雷达和视觉SLAM方法的重建点云和轨迹。
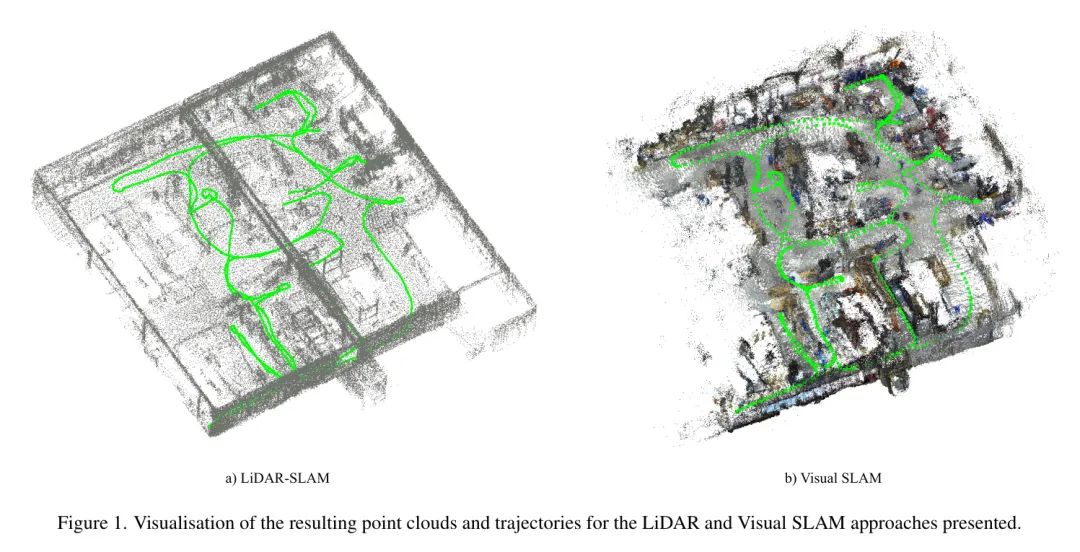
尽管局限于平面2D空间的方法已经相当成熟并已进入消费市场,但使用3D点云的方法仍然是研究的主题;然而,这样的努力受到了与自主驾驶和机器人技术相关应用的强烈推动。视觉SLAM算法应用单目、立体甚至RGB-D图像。与激光雷达传感器相比,相机的成本显著降低,因此可以支持更广泛的应用范围。
此外,捕获图像的分析不仅限于定位和建图过程中的几何信息提取。由于RGB图像中蕴含的丰富信息,视觉SLAM在可视化和环境的语义分割方面具有优势。另一方面,典型RGB-D设备的传感器原理限制了它们在近距离场景中的应用,而单目SLAM经常受到尺度漂移[20]的影响。尽管激光雷达传感器的角分辨率随着距离的增加因衍射而降低,但实际上,直接的测距原理允许与视觉SLAM方案相比更大的场景范围。
因此,当前基准测试[14]显示,基于激光雷达的方法在轨迹重建方面显著提高了准确性。然而,这一点在很大程度上取决于扫描模式和由传感器空间分辨率定义的线密度。通过融合IMU或里程计数据等额外的补充观测,可以提高两组方法的定位可靠性和准确性。
为了支持建筑工地和工厂大厅等大型环境的数据收集,作者同时采用激光雷达和立体相机的措施。例如,作者选择了一个工厂大厅,在其中监测室内建设活动(IntCDC,2024b)。图1已经展示了作者通过激光雷达和视觉SLAM得到的结果示例。
本文的其余部分组织如下:下一节关于相关工作首先介绍了当前针对与作者的任务相似场景的基准测试:在大型复杂动态环境中的数据收集。此外,还介绍了适用于此类应用的激光雷达和视觉SLAM方法。
第3节然后介绍由作者的机器人系统进行的数据收集(参见第3.1节)以及作者的激光雷达和视觉SLAM处理流程(参见第3.2节和第3.3节)。第4节呈现了在广泛工厂大厅收集的数据的结果。由于作者未来的工作旨在结合激光雷达和视觉SLAM,作者特别讨论了在这种环境中进行数据收集时,相应传感器的优缺点。
2 Related Work
第一节介绍了用于SLAM应用的标准数据集,并强调了其最重要的特性。在此背景下,只考虑公共可获取的资源。随后,将介绍激光雷达和视觉SLAM领域的既定和最新方法。
Large-Scale SLAM Benchmarks
在过去的几年里,针对计算机视觉、同时定位与地图构建(SLAM)和机器人技术领域的各种应用,已经创建了多个数据集。大部分资源主要关注捕捉紧凑区域,如小房间,并提供相机或激光雷达(LiDAR)数据,以支持视觉或激光雷达SLAM。用于评估相应SLAM方法的最为常见的大规模多模态数据集之一是KITTI数据集。它包含了立体图像、由360度激光雷达获取的点云以及附着在汽车上的惯性测量单元(IMU)的读数。基于这一资源,已经派生出了各种用于计算深度图、里程计估计或目标检测与跟踪任务的基准。一个可比较的甚至更大的驾驶数据集合,包括雷达信息和用于360度视角的额外摄像头,是nuScenes[1]数据集。这两个资源都提供了来自各种传感器的高质量数据,但仅限于在街道上捕捉的户外场景。与作者的使用案例部分最为接近的数据收集是HILTI基准。
该收集的三个场景的数据是通过一个配备有3D前置激光雷达、四个用于360度环视的RGB-D摄像头和一个IMU的移动机器人捕获的。由于所有场景都是在建筑工地上拍摄的,环境条件也是相似的。然而,HILTI基准的重点是机器人的精确定位。因此,所驾驶的轨迹并没有针对建筑物或周围物体的详细重建进行优化。
此外,机器人只在一个有控制照明条件的地下停车场内移动,因此几乎没有任何眩光或反射效应。此外,在机器人的视野内没有进行任何工作,即除了漫游车和跟随它的指导者之外,场景是静态的。
在以下各节中,将介绍与作者的工作相关的视觉和激光雷达SLAM应用算法,并对其进行更详细的描述。
LiDAR SLAM
尽管激光雷达SLAM领域起源于2D激光雷达传感器,但本概述将重点放在更近期的3D激光雷达SLAM方法上。早期流行的一种实时方法是LOAM [11]。在这里,从激光雷达点集提取平面和边缘特征。通过最小化相应特征误差,从高频里程计函数和低频映射函数确定传感器的姿态。较新的方法还包括像Scan Context [12]或LoGG3D-Net [13]这样的机制来检测已经映射过位置的再次访问(闭环),并通过姿态图优化[1],[1]来提高一致性。在一些现代方法中,预处理的点仍然被简化为边缘和平面特征,而在其他方法中,点被组合成类似圆盘的表面元素或者在所谓的密集方法中简单地使用(下采样)点。在现代激光雷达SLAM系统中,使用IMU数据来增加在快速移动情况下的鲁棒性,并通过重力估计减少定向漂移。在无IMU的激光雷达SLAM方法中,通常将单次扫描内的轨迹建模为线性运动而IMU支持的激光雷达惯性SLAM方法能够实现更高分辨率的轨迹表示,这可能导致精度提高。
在最近的工作中,为了获得更一致的地图,提出了使用环境神经网络的表示进行激光雷达SLAM。然而,在基准数据集上,它们还未能达到传统方法的精度。
Visual SLAM
ORB-SLAM(Mur-Artal等人,2015年)是一种高效、鲁棒且实时可行的SLAM方法,它包括了用于闭环检测和全局优化的地点识别能力,并结合了进行长期建图的能力,这对于探索大型环境尤为重要。ORB-SLAM及其后续版本ORB-SLAM2(Mur-Artal和Tardos,2017年)和ORB-SLAM3(Campos等人,2021年)使用了手工设计的特征提取算法和优化方法,专注于提高跟踪精度。
这导致了在运行过程中计算要求低,但也造成了相对稀疏的点云和在创建的地图中细节水平较低。较新的方法如DROID-SLAM(Teed和Deng,2021年)集成了神经网络,并在各种场景上进行训练,以通过减少累积漂移和因特征轨迹丢失导致的失败次数来进一步提高鲁棒性。
一种完全可微的方法设计允许结合和调整神经网络层,例如用于密集像素匹配或更新相机姿态,与标准算法结合,例如执行全局优化。此外,将前端(执行图像输入流的时间关键任务)和后端(将计算密集型过程外包)明确分开,仍然允许实时能力。 Zhang等人(2022年)的研究表明,DROID-SLAM在具有平面运动的机器人应用中具有很高的有效性。
最新的方法正在解决结果地图的可视化和表示问题。传统的SLAM方法采用 Voxel 网格、点云或网格表示作为场景表示来构建密集建图。然而,这些方案在获取细粒度的密集地图方面面临严重挑战。如HI-SLAM(Zhang等人,2024年)等方法扩展了现有概念,包括将神经辐射场(NeRF)(Mildenhall等人,2020年)作为环境的3D表示。为此,利用关键帧的姿态和深度估计值来逐步优化集成神经网络对应的权重。此外,通过多分辨率哈希编码(Muller等人,2022年),可以显著减少所需的训练时间,允许快速更新生成的神经地图。
最近,3D高斯溅射被提出作为一种高效的辐射场渲染技术,用于高质量、低内存消耗的密集建图(Kerbl等人,2023年)。除了对高分辨率图像渲染的效率之外,高斯溅射还保持了显式的几何场景结构和外观,得益于场景表示的确切建模。这项技术已经被迅速应用于多个领域,并且对于后续的3D建模也极具前景,这是作者项目的长期目标之一。
3 SLAM-based mapping of a large factory Hall
在以下各小节中,将介绍用于捕捉环境的传感器系统,并提供对所记录建筑物特征的研究(参见第3.1章)。随后概述了在本工作中采用并评估的激光雷达和视觉SLAM方法(参见第3.2/3.3章)。
Sensor Platforms and Data Acquisition
作为测试环境,选择了卓越集群IntCDC的大规模建设机器人实验室(LCRL)的一部分(IntCDC, 2024b)。建筑包括一个大型施工大厅,内含多个机器人建筑部件预制工厂、指导工作区、材料库和传统加工工具。设置包括开阔空间的大面积区域以及小型走廊。在录制区域内,有多座由混凝土、钢材或木材等不同材料建造的结构。为了支持对生成的点云进行评估,在大厅内的不同位置放置了标记。数据采集是在正常运营期间进行的,因此现场工作行人会经过传感器,机器人和物体在作者录制期间移动。
传感器平台是一个6轮式机器人系统,提供基本功能,如供电、计算资源和驾驶能力(见图2)。一个3D激光雷达传感器(RoboSense BPearl),具有32条线并能在最大100m(30m@10% NIST)范围内进行检测,安装在机器人前部。此外,四个ZED 2立体相机提供了一个360
的环境环绕视图,并附着在机器人中心的可伸出塔上。所有相关传感器的方向都通过先前的校准得知。由于物流原因,只有大约1600
的大厅的三分之一是由机器人平台探索的。为了对施工现场进行最详细的重建,机器人能够到达的所有区域都进入了其外形尺寸范围。为了提供一个非常精确的参考点云,使用了Trimble X7测绘级地面激光雷达站。在数据收集期间,在大厅的LCRL中八个扫描位置捕捉了360
扫描,并使用可用的参考点将它们合并成最终的地图。

DMSA LiDAR SLAM
在本工作中,作者研究了三种激光雷达SLAM方法来处理作者记录的激光雷达/IMU数据。具体来说,作者选择了KISS-ICP(Vizzo等人,2023年),这是一种声称易于集成且健壮性强的流行激光雷达SLAM方法,CT-ICP(Dellenbach等人,2022年),这是一种高精度的仅激光雷达开源算法,以及作者的DMSA SLAM(Skuddis和Haala,2024年)。在使用相应作者提出的标准参数设置时,SLAM方法KISS-ICP和CT-ICP在处理仅几秒后便发散了。作者怀疑这些方法在处理RoboSense BPearl非常稀疏的激光雷达数据时存在困难。因此,第4章中详细呈现的结果仅由作者的DMSA SLAM方法生成。
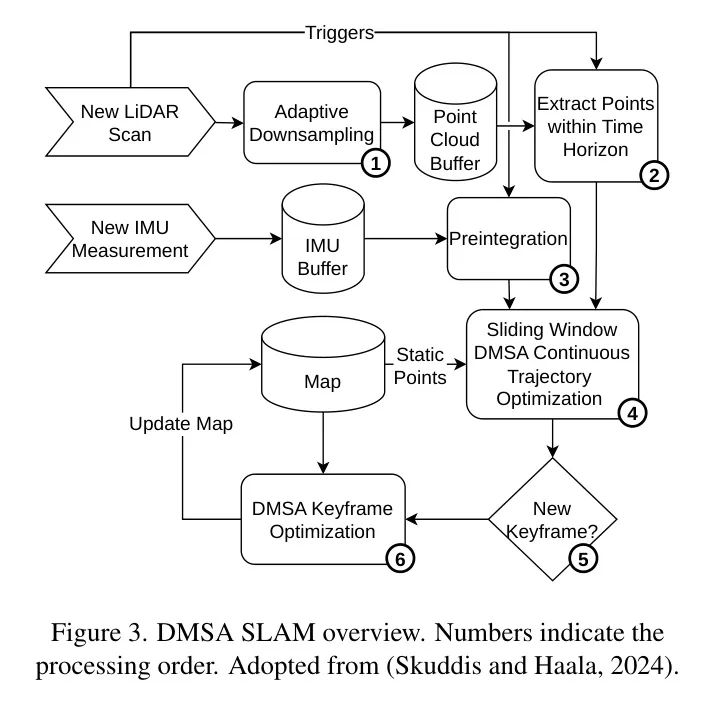
在DMSA SLAM中,滑动时间窗口内的激光雷达点与所谓的静态点以及IMU数据以紧密耦合的方式一起优化。为了处理本工作中捕获的数据,选择了0.8秒的滑动窗口时间范围。预处理中的自适应降采样使得能够处理来自狭窄空间以及宽敞场所的激光雷达数据。新关键帧基于重叠和距离阈值进行选择。除了属于关键帧的激光雷达点外,还会估计并添加重力方向到关键帧数据中。当新的关键帧添加到地图中时,与当前关键帧有显著重叠的所有关键帧都会被优化。图3给出了处理步骤的概览。具体细节作者参考(Skuddis和Haala,2024年)。
Dense Multi-Camera RGB-D SLAM Pipeline
在四个摄像头图像的处理链中,作者开发了一个密集视觉SLAM流水线,如图4所示。为了充分利用360度环视视野,首先通过DROID-SLAM方法(Teed和Deng,2021)处理每个摄像头的数据。在这个阶段,根据相邻图像之间的光流距离,自适应地选择每个摄像头视图的关键帧。对于这些关键帧,通过预测密集流并针对每个摄像头流执行捆绑调整来估计每个像素的密集深度,以最小化与预测流作为参考的再投影误差。随后,使用摄像头之间的已知外部参数,作者将每个摄像头的关键帧姿态转换到公共坐标系中,以前摄像头的光心作为参考坐标。
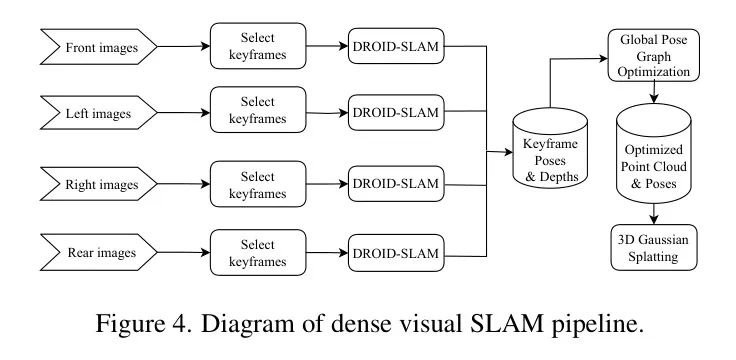
尽管这个过程产生了整合所有摄像头视图和观测的全局地图,但由于单独为每个摄像头估计的参数中仍存在的错误(如轨迹漂移),尤其是在没有闭环的情况下,仍可能产生不一致。为了构建一个全局一致性的地图,作者结合了来自四个摄像头的所有关键帧进行联合捆绑块调整。为此,作者采用了DROID-SLAM后端的全球捆绑调整。这种优化技术识别了不同摄像头视图和不同时间的观测之间的闭环。
典型的视觉SLAM流水线(Campos等人,2021;Teed和Deng,2021)通常产生点云地图。然而,这种格式对于机器人在导航避障时在地图内定位自己可能不够充分,因为点云固有的稀疏性。此外,诸如沿着新渲染路径通过场景的第一人称导航等应用需要从新视点产生的真实图像。为了克服这些挑战,作者采用了3D高斯溅射方法(Kerbl等人,2023)来训练场景的辐射场。这种方法使用了在最后阶段产生的估计姿态和全局一致点云作为初始高斯位置。
虽然在遵循(Kerbl等人,2023)的默认配置的同时,作者通过添加立体深度进行额外的监督,从而改进了几何重建。图6展示了输入立体深度的一个例子,由于低纹理或有限的立体 Baseline 等问题,这种深度通常是完整的。使用作者训练的3D高斯模型渲染的深度图像有效地解决了这些问题,生成了完全完整的深度图,物体边界更清晰。

4 Results
在下面,作者逐步讨论了前述方法的性能。虽然图1a)和b)已经展示了包括来自作者的激光雷达和视觉SLAM方法确定的轨迹在内的结果点云。图5进一步评估并可视化了这些结果,与TLS参考数据进行了比较(见图5a)。为了将创建的地图与TLS参考数据进行比较,每个点云的对应点被转换到参考坐标系统,然后使用迭代最近点(ICP)进行精细调整。图5b和Sc的颜色化是基于到参考点云最近邻的欧几里得距离。
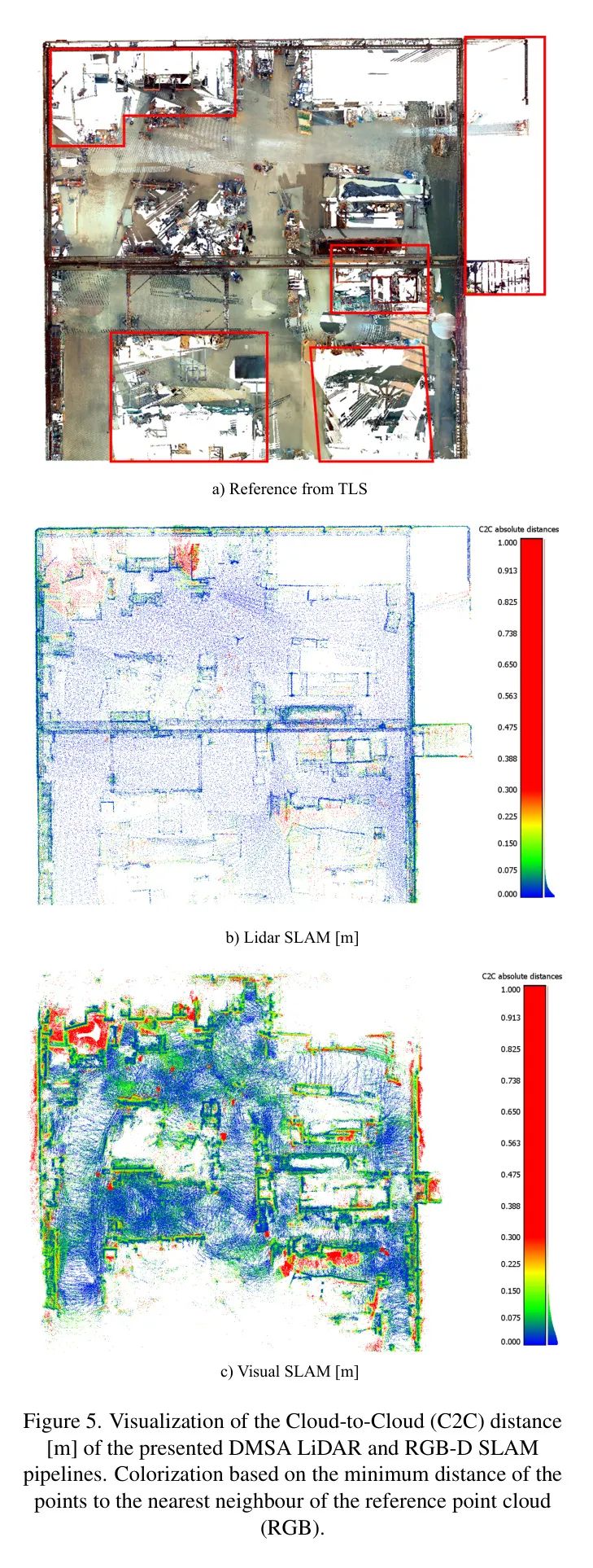
正如图表所展示的,来自激光雷达SLAM方法的点云(见图5b)提供了相对稀疏但精确的环境表示。通过对最初发布的流水线/参数进行一些调整,作者能够使用DMSA SLAM(Skuddis和Haala,2024)成功处理激光雷达传感器数据以及IMU数据。基于视觉SLAM创建的环境表示的校准表明,产生的地图相对于参考数据缩小了大约5%。单目SLAM中通常会出现缩放问题,但可以通过利用RGB-D相机(Campos等人,2021年)在各种应用中解决这些问题。然而,由于这类相机经常应用立体或结构光,它们通常受到测量范围的限制(最大
),并且与激光雷达传感器相比,提供的深度信息不太精确。例如,所应用的ZED2相机具有
的立体 Baseline 。根据制造商的说法,在深度精度显著下降之前,ZED2的最大范围是
。作者认为特别是在广阔区域环境下,这些限制仍然会导致(显著)比例误差。然而,为了简化比较,在以下评估中,作者通过相应地放大受影响的点云来校正作者的视觉SLAM结果的比例。
尽管激光雷达SLAM通常不会遭受尺度问题,并且在相当远的距离上提供可靠的测距结果,但作者使用四个RGB-D相机进行的视觉SLAM在全球优化后生成了更密集的点云。然而,它经常受到更高的噪声影响。这尤其在礼堂的左右墙壁上变得尤为明显,与激光雷达数据得到的结果相比,这些墙壁看起来相当崎岖。一方面,这是由立体相机生成的深度估计可靠性较低造成的,特别是对于远处的物体;另一方面,也是由于捕获环境中的光照条件具有挑战性。由于这两种方法不像仅从礼堂内少数特定扫描位置测量的参考点云那样受到阴影效果的影响,因此参考云中无信息的区域会导致评估中的距离变大。这些区域一方面影响通过ICP进行微调,另一方面限制了可能的质量评估。因此,作者排除了那些观察次数不足的区域(参见红色方框 - 图5a)。基于剩余的数据,作者得到了所呈现激光雷达SLAM方法创建的点云的平均点距离
(
),以及作者视觉SLAM Pipeline 生成结果的平均点距离
(
)。
大厅内暂时静止的物体(半静态物体)在几帧中位于相同的位置,这导致基于相机的方法的点云中计算出的距离出现局部最大值(绿色/红色点),从而在点云中表现为红色或绿色簇(见图5b/c)。这些物体如果从它们最初观察到的位置移动,相应的点将作为碎片留在生成的点云中。例如,跟随机器人的操作员或暂时在某个位置工作的员工。由于机器人的摄像头提供
的视角,因此它们对半静态物体的敏感度高于仅扫描机器人前方的激光雷达传感器。此外,激光雷达的分辨率显著低于摄像头收集的数据。因此,与基于相机的方法相比,BPearl传感器生成的点云中半静态物体出现的频率较低。使用3D高斯溅点作为环境表示的优势在图6中展示。通过使用高斯溅点,可以创建几乎照片级的真实环境表示,甚至可以渲染和可视化机器人数据收集期间未访问过的新视角。此外,多个观察结果的结合显著提高了深度信息。因此,即使是小细节,如测速三角架或空调系统的出风口,这些在原始传感器生成的深度图中不太清晰可见的部分也变得可以识别(见图6c/d)。高斯溅点方法中的优化过程可能由于偶尔对相同建筑部分的冗余观察而使某些半静态物体不可见(见图6d/e/f/g),这对于图像采集过程中在具有挑战性光照条件的姿态下的图像渲染也是有帮助的(见图6h/i)。(Kerbl et al., 2023)提出的有效渲染方法还使典型消费者级GPU上能够动态加载和实时可视化大型环境模型。作者使用NVIDIA GeForce RTX 3090 Ti获得了超过30 fps的更新率。此外,每个(虚拟)工作站改进的深度信息对于后续的增强现实或高精度导航应用非常有帮助。
5 Conclusions and Future Work
作者的主要贡献是证明了基于SLAM的方法在大型工厂车间或建筑工地的获取和地图绘制中的可行性。基于作者多传感器平台的数据,作者确认了最初的假设,即激光雷达传感器在大规模环境重建过程中提供高几何精度,而基于相机的方法可以生成有用的细节,这些细节可以通过3D高斯溅射极佳地可视化。与传统的地形测量方法(如TLS)相比,可以识别出基于SLAM的方法在大型建筑物内部地图绘制中的一系列优势。一般来说,移动平台灵活的数据收集有助于避免在复杂环境中被遮挡的区域,这对于固定测量来说是劳动密集型的。尽管作者的SLAM流程(还)不允许实时处理,但它已经非常节省时间。如图1所示的分析的工厂车间序列在0.3小时内捕获,而TLS数据采集需要1小时准备和2小时进行采集。简而言之,环境几何越复杂越精细,移动方法的时间节省越多。结合基于地图的轨迹规划和自动引导,甚至可以想象一个完全自主的采集过程。
尽管作者方法的(平均)精度(4-8厘米)足以通过捕获的环境进行导航,但建筑工地上的许多任务,如安装门、窗或类似的内置部件,需要更精确的测量。因此,作者未来的工作旨在融合激光雷达和图像数据,力求两全其美——从激光雷达SLAM中获得可靠的位置估计和几何形状,并结合视觉SLAM中丰富的环境表示。为了获得结果轨迹和地图的更可靠的精度估计,作者还计划将位于大厅内的参考点集成到作者的评估过程中。
由于3D高斯溅射在内存使用方面具有效率,并且结合已经开发的渲染方法,计算功率要求低,因此它们为表示大型环境模型提供了理想的机会。由于表示形式的明确性,它们也为后续的3D分割任务(Kim等人,2024年)提供了良好的基础。在作者不断努力提高由视觉SLAM流程生成的可视化效果和3D点云的精度和质量的过程中,作者还在改进四个相机的联合校准和摄影测量评估。如果确定了语义信息,还可以基于收集的数据创建或更新数字建筑计划,如建筑信息模型(BIM)或建筑与习惯目标模型(BoHM)。这样,可以设想自动生成的建筑物状态报告,这些报告将实际状态与目标状态进行比较。
参考
[1].SLAM for Indoor Mapping of Wide Area Construction Environments.
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-05-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号