利用增强现实与改进 YOLOv5 检测 !

利用增强现实与改进 YOLOv5 检测 !

AIGC 先锋科技
发布于 2024-07-08 14:16:49
发布于 2024-07-08 14:16:49

随着现代社会的不断发展,全球大多数国家的交通量持续增加,导致路面损坏率上升。因此,实时且高度准确的路面损坏检测与维护已成为当前的需求。在本文中,提出了一种基于CycleGAN和改进的YOLOv5算法的增强型路面损坏检测方法。 作者选取了7644张自行收集的路面损坏样本图像作为初始数据集,并利用CycleGAN对其进行增强。由于CycleGAN生成的图像与真实道路图像之间存在较大差异,作者提出了一种基于改进的Scharr滤波器、CycleGAN和Laplacian金字塔的数据增强方法。 为了提高复杂背景下目标识别效果,并解决YOLOv5网络中的空间金字塔池化-快速模块无法处理多尺度目标的问题,作者引入了卷积块注意力模块的注意力机制,并提出了具有挤压和激励结构的扩张空间金字塔池化。 此外,作者通过将CIoU替换为EIoU来优化YOLOv5的损失函数。 实验结果表明,在检测三种主要类型的路面损坏:裂缝、坑洞和修补时,作者的算法实现了0.872的精确度、0.854的召回率和0.882的平均精度@0.5。 在GPU上,其每秒帧数达到68,满足了实时检测的要求。 其总体性能甚至超过了目前更先进的YOLOv7,在实际应用中取得了良好成果,为路面损坏检测与预防的决策提供了依据。
I Introduction
道路运输对于促进城市和国家之间的交流至关重要。此外,道路建设保证了经济发展,这是人们安全旅行的前提,也是一个国家经济发展的不可或缺条件。路面裂缝和损伤是道路上遇到的最常见问题。
关于路面病害的一阶段检测的研究很少,研究重点在于模型选择、数据集选择和处理以及损失函数的选择。然而,这些研究没有讨论路面病害与一般检测目标区别开来的特征。标准的用于路面病害检测的一阶段方法模型,如YOLO系列,设计用于检测一般目标,并没有充分考虑路面病害的具体特征。因此,研究如何针对路面病害特征改进这些模型至关重要。
路面损害检测对道路维护和道路行驶安全至关重要,因为它可能会破坏路面结构,降低交通速度,缩短道路使用寿命。严重的路面损害还可能削弱路基的承载能力,导致路面塌陷,交通安全问题以及经济损失。因此,及时检测和有效维护路面损害对于确保交通安全,提高交通效率以及保持旅行质量非常重要。然而,在多样化和复杂的环境中准确检测传统的路面损害是一个重大挑战。目前,许多学者已经提出了不同的路面病害检测算法,并取得了良好的效果。目前,基于深度学习的路面损害检测方法被广泛应用,包括基于回归分类的一阶段预测方法,如YOLO系列,以及基于区域建议的两阶段预测方法,如R-CNN系列。尽管两阶段方法具有高的检测准确度,但其检测速度不佳。一阶段方法在保持一定的检测准确度的同时具有较高的检测速度,在路面损害检测中越来越受到重视。为了应对这些挑战,研究团队进行了深入研究并取得了成果[59]。
基于此,本研究进一步对CycleGAN和YOLOv5算法进行了改进,并提出了一种结合这两种算法的新路面损害检测方法。在实验阶段,作者使用了YOLOv5,YOLOv7和Faster R-CNN算法在收集的数据集上测试了所提出的方法。
首先,针对数据集类别不平衡问题,作者提出了一种基于改进的Scharr滤波器、CycleGAN和拉普拉斯金字塔的数据增强方法。其次,为了解决主干网络在损伤特征提取方面的不足,作者引入了一种卷积块注意力模块(CBAM)的注意力机制,以增强模型对感兴趣区域的特征提取。
此外,为了提取多尺度特征,增加有用信息,抑制冗余信息,并确保在保持高图像分辨率的同时获取远距离信息的相关性,作者提出了一种带挤压和激励(AS-SE)结构的扩张空间金字塔池化,并用它替换了原始YOLOv5结构中的SPP模块。通过优化损失函数以降低网络的损失值,作者实现了网络的加速收敛速度,从而提高了整个检测网络的准确性,实现了对路面病害的高精度自动检测和分类。
在本研究中,作者的团队花费了三个月的时间收集和整理了12658个道路图像数据集,用于检测三种主要的道路损伤类别:坑洞(KC)、裂缝(LF)和修补(XB)。在清理了大量无效数据后,作者为本研究选择了1620个坑洞(KC)、1230个裂缝(LF)、794个修补(XB)损伤以及4000个无损伤的图像。
然而,该数据集存在类别不平衡的问题,一些损伤特征没有得到清晰的刻画,背景环境同质化,导致检测准确性低,训练出的网络模型的泛化能力弱,鲁棒性差。为了解决这些限制,本研究提出了一种结合 CycleGAN 和YOLOv5算法的增强型路面损伤检测方法。
II Method
Overall algorithmic framework process
本研究中使用的算法如图2所示:首先对输入图像进行数据增强,然后将数据增强后的图像数据输入到所提出的YOLOv5-ASCE网络中。图2显示了作者对YOLOv5网络的特征提取和融合部分进行了改进,以使最终模型更加稳健和通用。最后,评估模型,并输出检测图像。

Data enhancement methods based on improved Scharr filters, CycleGAN and Laplacian pyramid
为了提高目标检测算法的识别准确度,通常使用数据增强算法在训练和识别之前增强数据集。传统数据增强方法包括欠采样方法、过采样方法和图像转换,这些方法可以在一定程度上调整样本中的类别分布,但不能考虑到样本的整体分布特征。这些方法不够多样化,最终分类准确度的提升有限[63]。同时,更先进的图像增强方法,如 TrivialAugment 和 AutoAugment[64, 65],在多样性、复杂性以及对特定任务的适应性方面存在不足。循环一致性生成对抗模型(CycleGAN)[66]通过生成器与判别器之间的对抗游戏学习原始数据的时间频率特征,并借助多链接的损失函数控制局部数据的一对一映射关系来重构原始数据。该网络可以直接将原始信号时间频谱转换为生成的信号时间频谱,并在生成过程中引入对抗损失函数和循环一致性损失函数,以确保高质量的数据生成。
本文中包含三种图像数据,如裂缝、坑洞和修补区域,使用CycleGAN可以生成现有数据中不常见或未涵盖的图像变体,例如不同大小、形状或严重程度的检测目标。这可以进一步增强数据的多样性,以训练更鲁棒的模型。对于自然收集的数据集中罕见的特殊道路损害情况(例如,大裂缝或坑洞数据),CycleGAN也可以用来补充类似极端情况的图像,从而帮助模型学习识别和处理这种虽不常见但重要的情景。
然而,观察到如果直接由CycleGAN网络生成目标损害图像,CycleGAN网络对输入数据更敏感,无法处理复杂场景。当学习图像中的特征数量或背景过于复杂时,CycleGAN网络将学习各种抽象特征。例如,将路面损害与无关特征(如光影和周围环境)结合将产生一些非真实数据特征,这些不仅包括本研究需要的损害特征,导致生成图像与真实世界路面图像之间存在较大差异(如图3所示)。这进一步导致后续目标检测神经网络训练的网络模型偏差,无法实现对面状损害的准确检测。

如图3所示,直接使用CycleGAN生成的损坏路面图像显示出更多的干扰项,这些与真实路面图像不同,并不满足本研究的要求。
因此,作者提出了一种基于CycleGAN和拉普拉斯金字塔的数据增强算法。数据增强算法如图4所示。
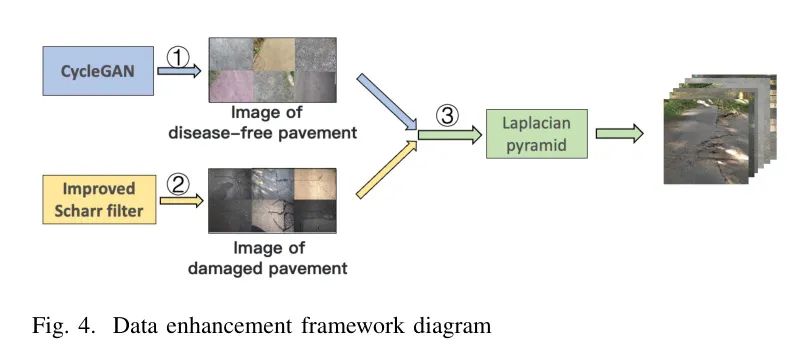
第一步使用CycleGAN网络生成完整的路面图像数据。
第二步通过求解图像在0°、°、90°和135°方向的梯度,即训练集中具有更明显损害特征的图像数据,筛选出数据集中具有明显损害边缘特征的图像。
完成上述两步后,使用第一步由CycleGAN生成的图像作为背景图像,从第二步得到的梯度信息中的损害特征区域作为前景图像,通过拉普拉斯金字塔将两者融合,得到数据增强后的图像数据。
Ii-B1 Image gradient solving
为了更有效地过滤具有明显损坏特征的图像数据,使用了Scharr滤波器[67]来求解原始图像的图像梯度。Scharr滤波器具有计算速度快和准确度高的优点,能够在敏感于相邻像素和灰度变化的同时提取弱边缘特征。然而,如图5所示,传统的Scharr滤波器仅计算图像0°和90°方向的梯度,并未考虑对图像边缘和纹理特征至关重要的对角方向梯度。
在四个方向(0°,45°,90°,135°)计算图像梯度可以更全面地提取这些重要特征,有助于提高图像分析的准确性。此外,与仅在两个方向上求解梯度相比,四个方向上的梯度求解可以更好地保留图像的详细信息,从而提高其分辨率。因此,为了提高梯度近似的准确性并增加图像的分辨率,提出了一个改进的Scharr滤波器,在四个方向上计算图像的梯度:0°,45°,90°和135°。改进原理如图6所示,其中Xi(i=1,2,3,..., n)表示图像中的每个像素点,四个方向的梯度计算可以更全面地分析整个图像。
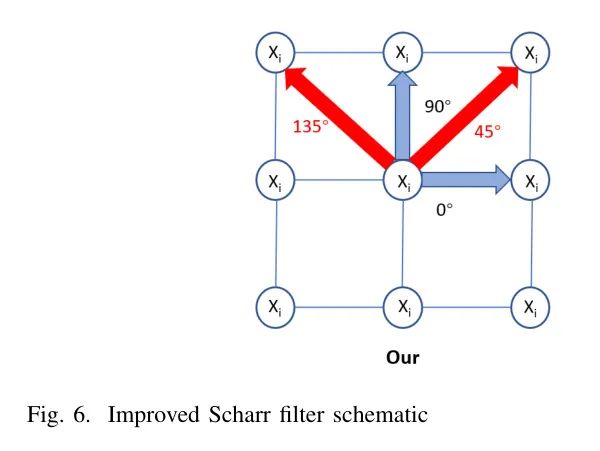
仅在两个方向(例如0°和90°)求解梯度可能会遗漏对角方向的一些特征,而在四个方向(0°,45°,90°,135°)求解梯度则能显著优于仅使用两个方向(0°和90°)求解梯度的原始Scharr滤波器。
为了验证改进的Scharr滤波器的有效性,在同一路面损坏图像上进行了梯度解算的对比实验。在实验中,使用原始和改进的Scharr滤波器获得了图像的梯度解算,并获得了损坏特征的梯度图像,如图7所示。实验图分为三组——A、B和C——以不同放大倍数进行比较。
具体来说,A组展示了100%放大倍数下的特征图像比较,B组展示了300%放大倍数下的特征图像比较,C组展示了500%放大倍数下的特征图像比较。通过仔细观察和比较实验结果,作者可以观察到使用改进的Scharr滤波器求解的特征梯度在清晰度和区分度方面优于使用原始Scharr滤波器获得特征图像。这一发现说明了改进的Scharr滤波器在提取图像细节和突出损坏特征方面的显著优势。此外,它为研究损伤检测和识别提供了有力支持。

因此,可以得出结论,所提出的Scharr滤波器可以更有效地提取路面损坏特征,从而为损伤识别奠定了坚实的基础。
Ii-B2 Image fusion
为了获取高质量的路面损伤图像数据,作者最初尝试使用图像拼接方法生成所需的图像数据。然而,在实际操作中,这种方法得到的图像数据在拼接边缘有明显的边缘接缝,以及前景和背景图像在颜色和亮度上的差异。
为了解决这个问题,作者使用了高斯模糊来处理 Mask 区域,使得前景和背景之间的交界渗透,灰度突变变得平滑,并且前景和背景图像融合。尽管经过这个过程可以获得更自然的图像数据,但随着高斯模糊半径的增加,计算量显著增加,且无法确定合适的高斯模糊半径。此外,使用CycleGAN生成的图像分辨率有限,使得整个过程耗时且效果有限。
为了更高效地获取模拟数据图像并解决上述问题,作者改进了使用拉普拉斯金字塔([68])进行图像融合的方法。拉普拉斯金字塔方法可以在保持较低计算量的同时更好地平滑前景和背景之间的边缘。这种方法可以克服先前方法的局限性,实现更高质量和更自然的图像数据融合,从而为路面损伤图像研究提供更有效的模拟数据。拉普拉斯金字塔的一个作用是恢复高分辨率图像(详细情况见图8)。

拉普拉斯金字塔定义如下:Li = Gi - (Gi + 1)
这里,Li表示拉普拉斯金字塔中的第层,Gi表示高斯金字塔中的第层,而Gi+1 上图每个标记的含义如下:G0,G1,G2和G3分别是高斯金字塔的第0,1,2和3层。L0,L1和L2分别是拉普拉斯金字塔的第0,1和2层。向下的箭头表示下采样过程。右上角的箭头表示上采样操作。"+"号表示附加操作。"-"号表示减法操作。
拉普拉斯金字塔图像融合的核心原理如下:
(1) 创建高斯金字塔
a. 对于图像A,使用函数创建高斯金字塔(gpA)。函数通过下采样和模糊原始图像生成一系列逐渐降低分辨率的图像。
b. 对于图像B,使用函数创建高斯金字塔(gpB)。以与图像A相同的方式处理。
(2) 创建拉普拉斯金字塔
a. 根据图像A的高斯金字塔(gpA)创建相应的拉普拉斯金字塔(lpA)。使用子操作(减法操作)和函数。对于每一层,当前层的高斯金字塔图像减去下一层的图像(经过函数的上采样和模糊处理)。
b. 根据图像B的高斯金字塔(gpB)创建相应的拉普拉斯金字塔(lpB)。以与图像A相同的方式进行处理。
(3) 创建权重图像
生成权重图像,确定图像A和B在各个像素位置的权重。这可以通过使用图像的梯度和亮度等特征来实现。假设权重图像是wA和wB。
(4) 融合拉普拉斯金字塔
对于每个输入图像,使用拉普拉斯金字塔(lpA和lpB)和权重图像(wA和wB)确定最终合成图像中每个像素的权重。通过元素相加的方式得到融合的拉普拉斯金字塔(fused-LP)。
具体操作如下:
(5) 重建融合图像
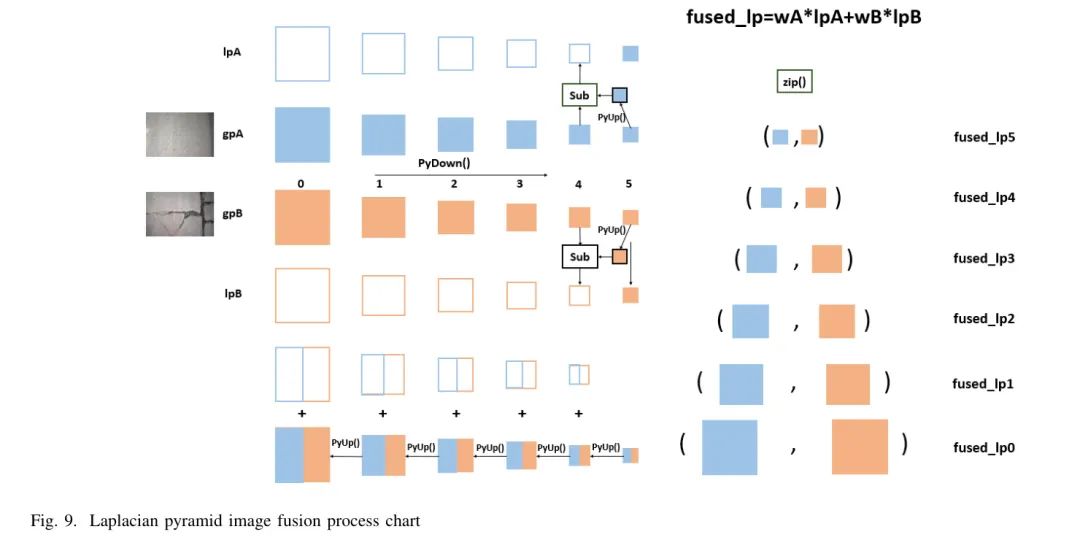
从最粗糙的层次开始,逐层使用zip(0)函数处理fused-LP。当前层的图像通过函数进行上采样和模糊处理后,添加到下一层的图像中(使用Sub操作),直到获得最精细的层次。最终的融合图像如图9所示。使用此方法获得的路面损伤图像数据更接近实际的路面损伤图像,操作方便且有效,有利于作者的研究。
Iii-B3 CycleGAN网络
在本研究中,作者提出了一种基于CycleGAN网络的数据增强方法,用于生成无损伤原始路面图像的多样化和复杂背景,并将过滤后的具有损伤特征的图像中的损伤特征与生成的完整路面图像融合,以获得具有不同背景和明显损伤特征的大量路面图像数据,这便于作者后续的研究。
CycleGAN是一种从生成对抗网络GAN发展而来的无监督机器学习方法,它是一个无配对图像到图像转换网络[69]。CycleGAN的目的是实现X域图像数据与Y域图像数据之间的相互转换,包含两个映射函数,,以及两个判别器D_X, D_Y。对于生成器G,可以将X域转换为Y域数据。对于生成器F,可以将Y域反向转换为X域数据。判别器D_X促使生成器F将Y转换为X。类似地,判别器D_Y促使生成器G将X转换为Y。转换关系如图10所示。

在CycleGAN中引入了两个对抗性损失,并应用于两个映射函数。对于映射函数,给定样本使用以下关系通过判别器D_Y转换为域Y中的数据:
在方程(1)中,表示X域样本空间分布;表示Y样本空间分布;生成器G试图生成尽可能与Y域相似的图像,而则试图区分真实图像y的样本。G的目标是最小化图像,而的目标是最大化,两者形成对抗关系,G。类似地,存在一个映射函数,它与判别器的关系如下:
同样,F的目标是最小化图像,而D的目标是最大化,存在对抗关系,F。
从理论上讲,对抗性训练可以学习到映射G和F,以产生与目标域Y和X相同分布的输出。然而,仅靠对抗性损失可能无法将输入图像的同一集合映射到目标域中任意随机排列的图像,这容易导致图像信息的丢失。CycleGAN通过引入循环一致性损失(如图10-(b)和图10-(c)所示)来克服这一限制,对于X域中的每一张图像x,可以通过循环转换还原到原始图像,即正向循环一致性损失 。同样,对于Y域中的每一张图像y,应满足反向循环一致性 。
可定义的循环一致性损失:
在方程(3)中:G是正向生成器;是反向生成器;和是重构的图像。

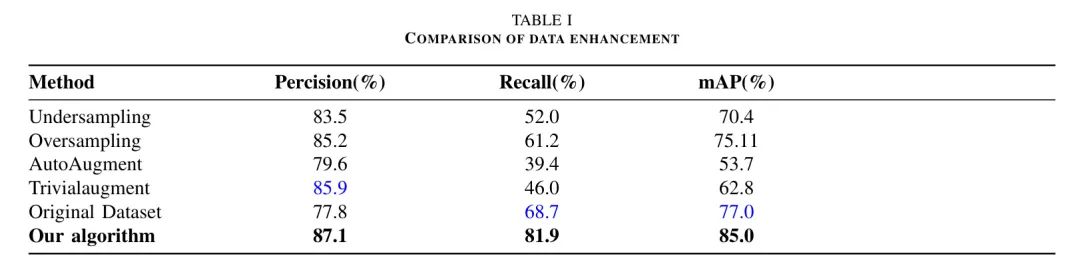
对于数据集,精度提高了13.8%,召回率提高了10.1%,平均平均精度(mAP)@0.5提高了8.1%。
图11显示,通过本文提出的数据增强过程获得的损伤数据比直接使用CycleGAN算法获得的损伤数据更接近真实路面。图像数据没有明显的边缘缝隙,边缘融合部分平滑,显著提高了数据集的质量和规模。为了验证本文提出的数据增强算法的有效性,本研究使用YOLOv5算法对数据增强前后的数据集进行了测试比较(实验平台和参数设置在第四节中给出)。结果如表1所示。可以看出,对于特定检测目标的数据处理,常用的数据增强方法并不奏效。而在本文提出的数据增强方法下,与原始数据集相比,本文使用的CycleGAN网络仅用于生成完整的路面背景图像数据,然后使用拉普拉斯金字塔将经过Scharr滤波器过滤的独特损伤数据集与之融合,生成完整的道路损伤数据集。此方法可以生成具有不同背景和独特特征的大量真实路面损伤数据集。这个数据集高度仿真且可用,为后续的研究和实验奠定了坚实基础。
III Improved YOLOv5 network structure
在完成数据增强部分之后,作者分析了YOLOv5的网络结构,发现其使用的空间金字塔池化快速(SPPF)[70]模块作为空间池化操作影响了图像分辨率,导致细节信息丢失,影响了模型的检测效果。因此,作者将这个模块替换为带孔空间金字塔池化(ASPP)[71]以及由挤压和激励网络(SENets)[72]提出的AS-SE结构,以确保在空间池化操作中在扩大感知场的同时保持图像的高分辨率,并使图像的通道特征更加明显。
为了提高特征融合网络的效率,作者在YOLOv5特征融合网络中不同尺度的三个特征融合层引入了CBAM[73],这增强了复杂背景下目标的显著性,从而提高了外来物体目标的特征表达和检测网络的检测精度。针对上述问题和改进思路,本研究提出了YOLO-ASCE网络结构,如图12所示,以实现路面对损伤目标的准确快速检测。

CBAM(Convolutional Block Attention Module)
将CBAM集成到YOLO框架中的主要目的是优化模型对图像中重要特征的聚焦。对于可能具有特征分散分布的多个区域的路面损伤数据,使用CBAM增强这些特征有助于模型更多地关注可能存在损伤的区域。因此,本研究在降采样阶段的每个C3模块后引入CBAM模块,即在特征融合之前插入。它还确保模型优先从图像中最可能包含裂缝、坑洞或修复的部分进行学习,从而提高检测精度。
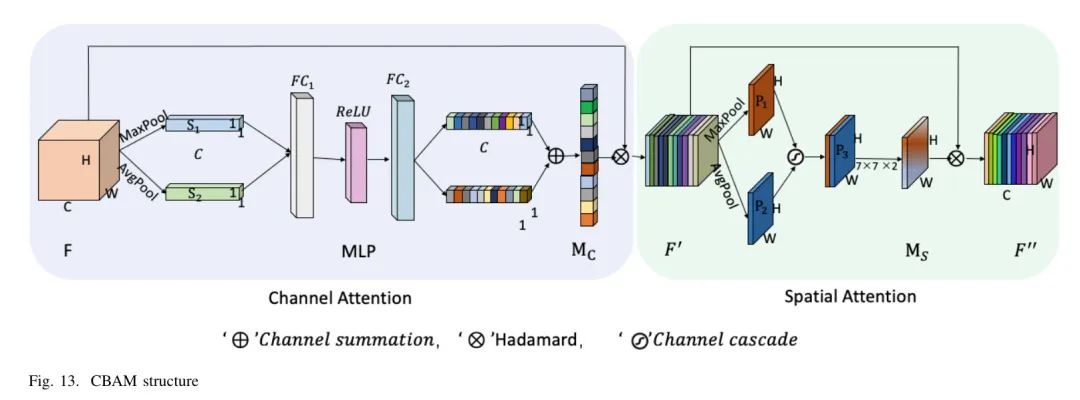
为了提高特征融合网络的效率和模型检测性能,在三个不同尺度上将CBAM模块添加到特征融合层。CBAM注意力机制的整体过程如图13所示。它包括通道注意力机制和空间注意力机制,协同学习图像中的关键局部细节信息,提高神经网络对图像中损伤的关注,并提高网络的特征学习和表达能力。该模块减少了卷积乘法方法所需的计算开销,降低了其模块在复杂性和计算上的低效。因此,它被添加到优化网络结构中,以实现更快、更准确地捕获感兴趣区域。
III-A1 通道注意力机制
特征图的每个通道在确定像素点是否属于道路缺陷时具有不同的重要性水平。
因此,本研究引入通道注意力机制,以建立特征图通道之间的相互关系,使得不同通道的特征信息能够更有效地被利用。
如图13左边的通道注意力部分所示,输入特征图表示为,其中H和W分别是输入特征图的高度和宽度,C是输入特征图的通道数。通过全局最大池化和全局平均池化压缩特征图F的全局空间信息,生成两个大小为的特征图和。将每个通道特征图在整个图中的位置信息融合,避免了由于卷积核尺寸小,在提取特征时由于感知域范围小而引起的网络评估偏差。
和通过共享包括全连接层、和整流线性单元(ReLU)非线性激活函数的多层感知机(MLP),获得两个一维特征图。两个一维特征图在通道上经过求和操作后,通过sigmoid函数进行归一化,得到每个通道的权重统计,其大小为,可以用式(4)表示:
在式(4)中:表示sigmoid函数,表示输入特征图F的第个通道中坐标位置点的像素值。
Iii-A2 Spatial attention mechanism
如图13中的右侧空间注意力部分所示,空间注意力机制以经过通道特征重缩放后得到的特征图作为输入,并在通道维度上进行全局最大池化和平均池化操作,分别得到特征图和。通过通道级联得到特征描述,并使用卷积层对不同位置的信息进行编码和融合,以获得空间加权信息,这可以用来区分图像不同空间位置的重要性,该过程可以用方程(5)表示:
在方程(5)中:表示卷积核是一个7*7大小的卷积层。
Iii-A3 CBAM attention mechanism
输入特征图F与每个通道权重值的两矩阵对应元素相乘,并对F进行特征重缩放处理,以获得能有效反映特征关键通道信息的特征图。基于通道加权,使用 ConCat 的空间注意力机制自适应地加权空间特征信息,并将与空间权重系数的两个矩阵的对应元素相乘,作为空间注意力模块的输入,得到包含通道位置信息和空间位置信息的显著特征图。因此,网络可以增强对路面病害损伤输入特征的注意力,并提高其空间特征选择能力。
该过程可以表示为方程(6):
在方程(6)中:表示两个矩阵的对应元素相乘。
AS-SE module
Iii-B1 ASPP(Atrous Spatial Pyramid Pooling)
将ASPP集成到YOLO框架中的主要目的是优化模型处理路面损伤数据尺度变化的能力。
对于具有大尺度变化范围的路面损伤数据,YOLOv5网络结构中的SPPF模块会影响图像分辨率,导致损失细节信息,影响模型检测效果,而孔洞卷积在保证图像分辨率属性的基础上,减少了参数依赖和计算过程;通过较少的参数就能实现卷积核有效感知域的扩展,有效聚合上下文信息。
对于输出特征图B的每个位置i和滤波器w应用二维孔洞卷积:
在公式(7)中,表示卷积核大小,表示采样率。公式(3-4)表明,在每个连续滤波器之间的每个空间维度插入了_r_-1个零值,然后通过此滤波器对特征图A进行卷积,表示最终获得特征图。因此,通过改变采样率,孔洞卷积可以控制滤波器的感知域和网络输出特征的紧凑性,而无需增加参数数量或计算量。
ASPP的多尺度融合使用具有多级孔洞采样率的孔洞卷积并行采样特征图,使ASPP模块能够从不同的感知域学习图像特征。由于具有较大采样率的孔洞卷积由于图像边界响应无法捕获远程信息而退化为11卷积,因此将通过全局平均池化获得的图像级特征融合到ASPP模块中。即,将图像级特征和来自四个卷积分支的特征图输出输入到11卷积层,然后双线性上采样到特定的空间尺寸,计算如公式(8)。
在公式(8)中,表示具有采样率r和卷积核大小的A的孔洞卷积;image(A)表示使用全局平均池化方法从输入A提取图像级特征,ASPP结构如图14所示。
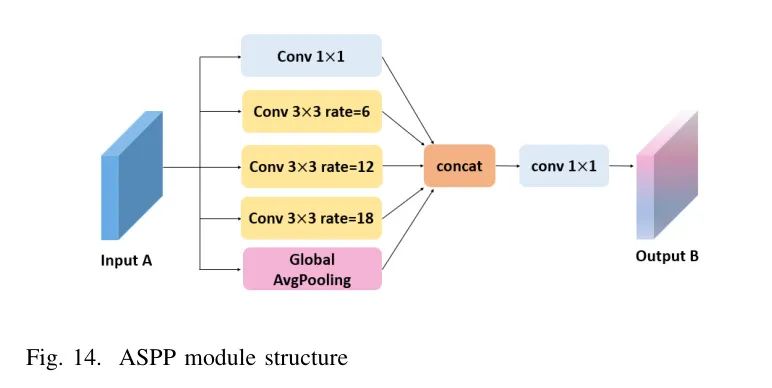
由于YOLOv5网络结构中的SPPF模块计算密集,特征图信息有限,池化操作丢失了一些细节信息[74],而上述ASPP结构通过孔洞卷积的并行多级采样率扩展了感知域并丰富了语义信息。因此,图像级特征可以有效捕获全局上下文信息,并考虑上下文之间的关系,避免陷入局部特征导致分割错误,提高目标分割的准确性。因此,在双线性上采样之前,将包含高级语义信息的特征图输入到ASPP模块以获取不同尺度的特征,有助于提高网络在路面损伤提取方面的性能。
Iii-B2 SENet(Sequence-and-Excitation)
主要目标是将SENet整合到YOLO框架中,以增强模型通道间的特征重新校准能力。在路面损伤检测的背景下,SENet帮助模型根据特定类型损伤与特征的相关性动态调整每个通道的权重,从而提高模型识别路面损伤更细微特征的能力。
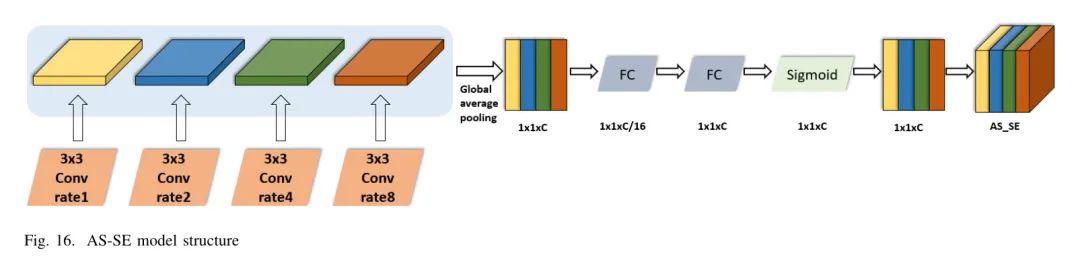
SENet的核心部分是SE模块,它可以嵌入其他分类或检测模型中。该结构由两部分组成,挤压(squeeze)和激励(excitation),通过学习自动获取通道权重并捕获空间相关性,从而提高网络的表征能力。SENet模块的结构如图15所示。
首先,通过压缩过程(挤压)将的全局信息压缩成的一个通道,采用全局平均池化算法拓宽感知场。使用的方程如下:
然后获得激活过程(激励)。通过两个全连接层(全连接)进一步压缩和重建特征后,连接ReLU [75] 和sigmoid [76] 到激活层以获取特征维度的权重信息,目的是捕捉每个通道之间的关系。
在方程(10)中, 是用于压缩的全连接函数, 是用于重建的全连接函数,先进行下采样然后上采样,接着通过sigmoid函数激活以获得相应的权重。最终的输出通过将输入通道与其各自的权重相乘得到,如方程(12)所示:
总之,SE模块通过权重 和 训练具有选择能力的全连接网络,将多通道 特征图转换为压缩特征向量后,使用ReLU和sigmoid激活函数输出每个特征图的权重向量,并将其与原始特征图相乘以获得最终输出。
Iii-B3 AS-SE Modules
ASPP由具有不同采样率的多个扩张卷积组成。输入特征在不同采样率下进行采样;也就是说,从不同尺度提取输入特征,然后融合获得特征以得到最终的特征提取结果。与SPPF相比,ASPP在扩大感知场的同时保证了分辨率,ASPP模块中的全局平均池化操作有助于捕获整幅图像的上下文信息,提高模型对场景的理解,这大大确保了特征提取的丰富性和完整性。在图像处理任务中,作者通常希望在保持高分辨率的同时获得大的感知场。然而,在传统方法中,这两个目标往往是矛盾的。
在池化操作中,作者可以使用更大的卷积核或更大的步长(stride)来获得大的感知场。然而,这两种方法都有局限性;前者导致计算过度,后者降低了特征图的分辨率。
扩张卷积是解决这一矛盾的有效方法,可以在保持分辨率不变的情况下扩大感知场,有效地提取图像特征。这使得可以在不损失过多分辨率的情况下获得大的感知场。尽管ASPP通过稀疏采样输入信号有效地扩大了感受野,但它也导致了从远距离卷积获得的信息之间的相关性降低。
为了解决这个问题,作者可以使用SENet通道注意力机制来加强各个通道之间的相关性,从而更好地利用ASPP中的空间信息。
基于上述发现,本文提出了一种名为AS-SE的模块,将SENet融入到ASPP中。AS-SE模块的主要功能是将SENet生成的通道权重值与原始输入特征相乘,然后用作扩张卷积的输入特征,如图16所示。这种组合使得经过扩张卷积后的路面损伤信息在通道维度上产生了一定的依赖性,进而增强了路面损伤特征提取的效果。通过将SENet与ASPP结合,AS-SE模块充分利用了SENet在通道注意力方面的优势,并加强了不同通道之间的相关性。这反过来又帮助提取更具辨识性的特征。此外,AS-SE模块保持了ASPP在扩大感知场和提高分辨率方面的优势。因此,在复杂的路面损伤图像处理任务中,整体模型的性能更好。
EloU Loss Function
损失函数能够准确反映模型与实际数据之间的差异。在原始YOLOv5网络中,边界回归的损失是通过CIoU损失[77]函数计算的,计算如下:
IoU[78]是预测框与真实框相交面积与合并面积的比例,计算如下:
图16:AS-SE模型结构。在这里,表示预测框与真实框质心之间的欧氏距离,c表示能够同时包含预测框和真实框的最小封闭区域的对角距离。
是以下方程式的权重函数:
是宽高比相似度的度量,定义如下方程式:
在方程(16)中,w、h和、分别表示预测框的高度和宽度以及真实框的高度和宽度。
CIoU损失涵盖了边界框回归的重叠区域、质心距离和宽高比。然而,其公式中的v反映的是高度和宽度上的差异,而不是高度和宽度真实差异及其置信度。因此,这有时会阻止模型有效地优化相似性。为了解决这个问题,本改进算法使用EIoU损失[79]代替原始损失函数,从而在目标框与预测框之间实现更有效的损失计算,计算如下:
在方程(17)中,和分别是覆盖目标框和 Anchor 框的最小外框的宽度和高度。损失函数由三部分组成:重叠、中心距离和宽高损失。前两部分延续了CIoU损失的方法,但宽高损失直接最小化目标框与 Anchor 框在宽度和高度上的差异,使收敛更快。它使回归过程更专注于高质量的 Anchor 框,进而提高预测框的回归精度;在道路病害图像中,具有小回归误差的高质量 Anchor 框的数量通常远小于具有大误差的低质量 Anchor 框的数量,因此会产生过多的梯度,影响训练结果,因此本文引入EIoU也优化了边缘回归中的样本不平衡问题。
IV Model training and result analysis
IV模型训练及结果分析部分的开始。
Experimental configuration and parameters
本研究中使用的实验环境配置为:Python版本=3.7.0,深度学习框架pytorch-gpu=1.12.1,CUDA版本=11.6,cuDNN版本=8.4.0。参数设置为:优化器=SGD,初始学习率=0.01,最终学习率=0.002,权重衰减因子=0.0005,初始化动量参数=0.8,迭代次数=300,批处理大小=32(这些参数的最佳组合是通过多次试验得出的)。
Selection and processing of datasets
在本研究中,作者收集和整理了总共12658个道路图像数据集。在清理了大量无效数据后,总共使用了3644个损伤数据集,分为三类,分别是1620个坑洞(KC)、1230条裂缝(LF)和794处修补(XB),以及4000个无损伤数据集,根据实际需求用于训练和识别深度学习模型,如图17所示。

为了增强训练效果,作者对三种类型损伤的数据量进行了平衡。在图像梯度求解、特征提取、CycleGAN网络生成多样化背景以及特征与背景融合操作之后,作者将坑洞(KC)扩展到2059个,裂缝(LF)到2059个,修补(XB)到2058个,共计6176张图像,然后按照8:1:1的比例将它们分配到训练集、测试集和验证集中:训练集4940张,测试集618张,验证集618张。
Evaluation indicators
在本研究中,作者使用了精确度、召回率、mAP(平均精度均值)、参数、每秒浮点运算数(flops)以及每秒帧数(FPS)来评估路面损伤检测算法的性能。
真正例(TP):它表示模型检测到的结果信息与训练图像中标记的信息完全匹配的样本数量。
假负例(FN):它表示模型检测到的结果信息与训练图像中标记的信息不符的样本数量。
假正例(FP):这意味着模型检测到的结果信息是正确的,而对应的训练图像信息是错误的样本数量。
真负例(TN):这意味着模型检测到的结果信息是错误的,而训练图像的信息也是错误的样本数量。
准确度:算法模型中正确预测的正样本数量占所有样本总数的比例。
精确度:正确预测的正样本数量占所有正确预测实例的比例。
召回率:正确预测的样本数量占所有正确标记样本的比例。
FPS是评估网络模型在执行检测任务时的图像处理速度的一个评价指标;该值越高,每秒可以处理的帧数越多。
参数(params)用于评估模型的空间复杂度。参数数量表征了模型占用的内存大小,并指每个网络层中的总字节数。
每秒浮点运算数(flops)用于评估模型的时间复杂度。计算量表征了模型的检测时间,并指每秒的浮点运算次数。
Ablation experiment
为了验证本研究中改进方法对路面损伤检测的影响,表4展示了基于数据增强验证每种改进方法的消融实验结果(参数来源于多次实验的最终结果)。
从表4和图18可以得出以下结论:在引入CBAM注意力机制后,相比于原始的YOLOv5,整个模型的参数和相应的计算量有所增加,但检测准确率mAP值也得到了提升;
在使用EIoU损失替代YOLOv5原始的CIoU损失函数后,参数和计算量保持不变,以最小的代价提高了检测准确率;
在使用AS-SE模块替代原始的SPPF模块后,感知范围扩大,使得通道特征更加明显,并保证了图像的高分辨率。如图18所示,当同时进行上述改进时,不同改进效果并非简单的精度、召回率增长或降低的叠加。因为精度和召回率相互影响,提高精度往往会降低召回率;追求召回率的增加通常会导致精度的降低。
在消融实验的结果中,所有改进方法都提高了mAP,这证明了每个改进点的有效性。
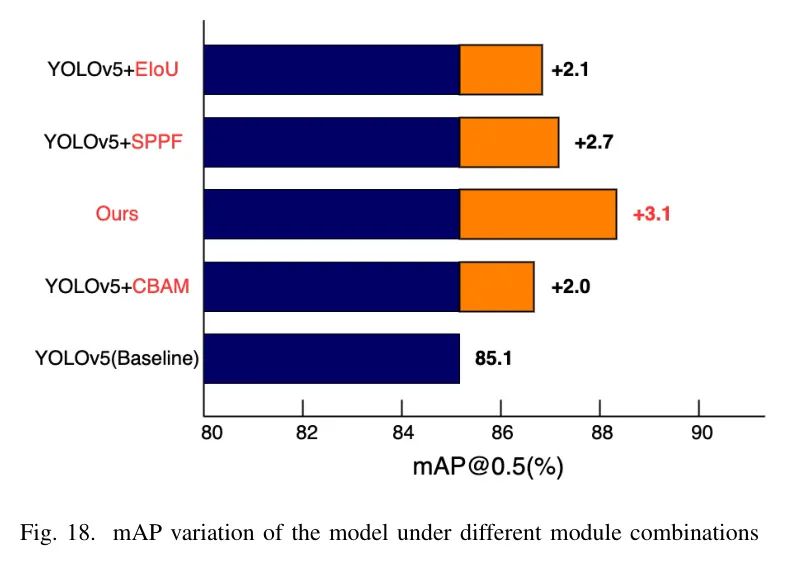
Experimental comparison analysis
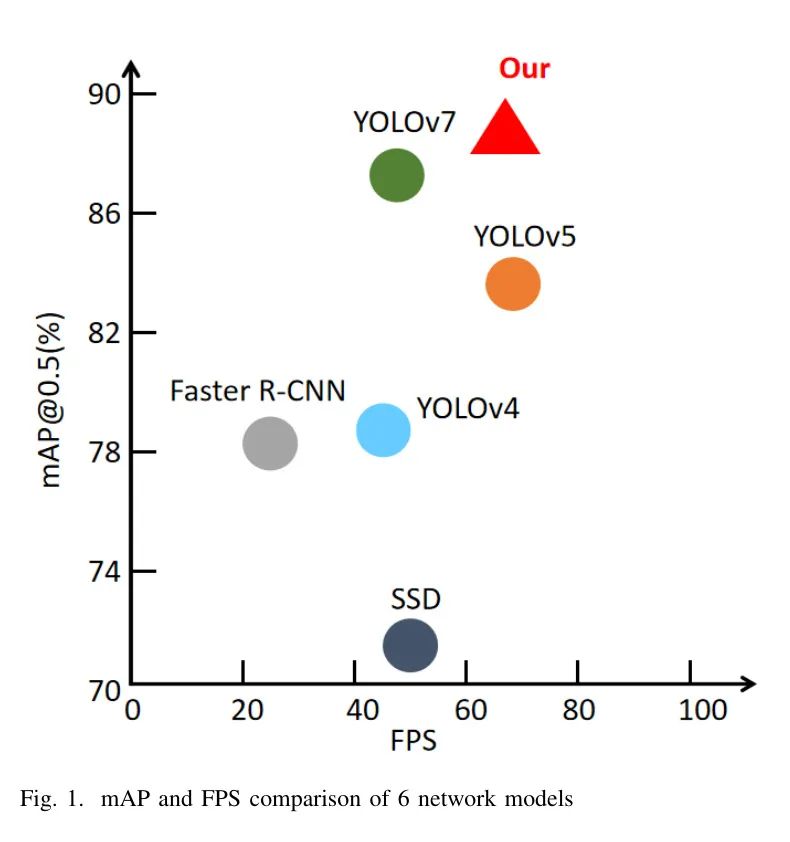
图18:不同模块组合下模型mAP的变化如表格5所示,Faster R-CNN(ResNet50)算法需要最长的检测时间;SSD检测速度更快,但检测准确度较低。
YOLOv7具有最快的收敛速度和极高的mAP,但检测速度低于其他主流目标检测算法。本研究中对同一数据集改进的算法取得了88.2%的mAP值,这是测试模型中最高的,比原始YOLOv5高3.1%,比目前更先进的YOLOv7高0.3%。模型的轻量化仅略低于YOLOv5s,其空间复杂度和时间复杂度远低于YOLOv7。
此外,网络模型引入了AS-SE模块,并引入了CBAM模块,这增加了部分计算量,导致与原始YOLOv5s模型相比,模型的检测率有所下降。然而,总的来说,所提出算法的FPS高达68,这仍然在检测速度方面提供了显著优势。
为了进一步评估性能,本研究对YOLOv4、YOLOv5、YOLOv7、Faster R-CNN和SSD目标检测算法在实验数据集上进行训练和测试。
实验环境配置如上所述的实验环境,以比较和测试不同模型的性能,比较结果概述在表格5中,数据集测试结果如图19所示。为了验证YOLOv4、YOLOv5、YOLOv7、Faster R-CNN、SSD及改进算法在本次研究数据集上对路面损伤检测的有效性,随机选取三组路面损伤特征图测试YOLOv4、YOLOv5、YOLOv7、Faster R-CNN、SSD和改进算法的检测效果。在检测结果所示的标签中,LF代表裂缝,KC代表坑洞,XB代表修补。测试结果如图20所示。

图19:6种网络模型mAP变化曲线的比较从图20中可以看出,这六种算法可以有效检测路面损伤。尽管Faster R-CNN能更好地识别修补损伤,但对坑洞存在误检,这表明在提取坑洞特征时算法受到干扰信息的影响。这表明算法在识别裂缝时不准确,容易受到阴影环境的影响。
由于SSD的低级特征卷积层较少,在强光条件下对裂缝的检测被遗漏,这表明SSD的浅层特征能力不够强,检测准确度低。YOLOv4对所有三种损伤的检测效果较好。然而,由于待检测目标接近背景环境的灰度值,在修复类损伤的检测中存在遗漏,未能检测到更细小的修复损伤。
原始YOLOv5漏检了裂缝和坑洞,并将裂缝误识别为坑洞。作为更先进的目标检测算法,YOLOv7对所有三类损伤的置信度更高,但在修复类别中将干扰项检测为修补。
改进算法对所有三类损伤的检测置信度更高。本文提出的改进算法使用AS-SE结构,增强了目标特征提取,并引入了CBAM模块,强化了目标特征,增强了目标特征的表达。然后可以准确检测目标,更好地解决漏检问题,即使在复杂背景下也能保持高准确度。
参考
[1].Cycle-YOLO: A Efficient and Robust Framework for Pavement Damage Detection.
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-06-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号