ETL vs. ELT:数据集成的最佳实践是什么?

ETL vs. ELT:数据集成的最佳实践是什么?

Tapdata
发布于 2024-07-24 14:19:54
发布于 2024-07-24 14:19:54
点击上方蓝字 关注我们 SUBSCRIBE to US
在当今快速发展的数字化时代,企业数据中台的构建变得尤为关键。TapData 作为一家领先的数据集成产品提供商,深刻理解到数据处理框架——无论是 ETL(提取、转换、加载)还是 ELT(提取、加载、转换)——对企业在管理、分析及实现数据驱动决策过程中的重要性。
ETL,一种传统的数据处理模式,强调在数据被加载到目标系统之前进行转换。这种方法适用于那些需要高度精确数据清洗和转换的场景,但可能会延迟数据的可用性。相反,ELT 允许数据先被快速加载到目标系统,然后再进行转换和处理,这不仅加速了数据的可用性,还提高了处理大规模数据的灵活性。
在今年的第十三届『数据技术嘉年华』(DTC 2024) 上,Tapdata 联合创始人兼 CTO 肖贝贝受邀出席,并在「数据库生态软件」专场中,围绕“ETL vs. ELT:数据集成的最佳实践是什么”这一议题展开分享,尝试通过具体鲜活的企业数据中台案例,帮助与会观众直观感受这两种架构的区别与各自的优劣势,从而得以在需求来临时,快速做出更加合理的选择。以下为本次分享的核心内容总结。
在快速发展的数据管理领域,选择合适的数据集成策略对于企业有效利用数据至关重要。随着数据量的不断增加和数据分析需求的日益复杂,传统的数据集成方案正在面临着越来越多的挑战。
下面,让我们从事务型数据库和分析型数据仓库的发展史起笔,共同探讨数据需求的变化和数据技术侧重点的差异。
一、事务型与分析型数据库发展史
如果让我用一句话总结事务型和分析型数据库这两个产品,大抵会是——“人生最大的遗憾,是一个人无法同时拥有青春和对青春的感受”。
什么是事务数据库与分析数据库?
上图展示的是典型的事务型数据库和分析型数据库的使用场景。其中,左侧对应的是事务型数据库,其逻辑类似于我们每天的日常生活——吃饭、喝水、上班、下班、看剧——这些事件不断产生并被记录。
但就像我们一般不会从历史和时间的角度去研究我们上个月吃了多少次饭一样,在事务型数据库中,我们会不断进行读写操作,但这些操作通常涉及的数据量较少,不会同时查询或更新大量数据。此外,这类数据库的并发操作比较高,可能会同时有很多操作在进行,每秒事务数(RPS)可以达到几千乃至数万。
但对于分析型数据库而言,我们可以快速感知过去一段时间内所做的事情,例如一个月内坐了几次车等等。但在这些事件发生时,不太可能实时记录所有操作和变更,RPS 整体上不会特别高。

正是因为这两种数据库的使用场景不同,它们的设计和技术栈也存在很大的差异。事务型数据库更关注事务管理、并发控制、树索引、事务日志以及高可用等能力;而分析型数据库则侧重于列存储、并行计算、数据压缩、稀疏索引、分区存储和异步合并等特性。也正是由于这些巨大差异,至今尚未出现一种新的方案设计能够同时满足这两种不同场景的需求,即使是一些头部产品也未能做到这一点。
分析数据库发展史
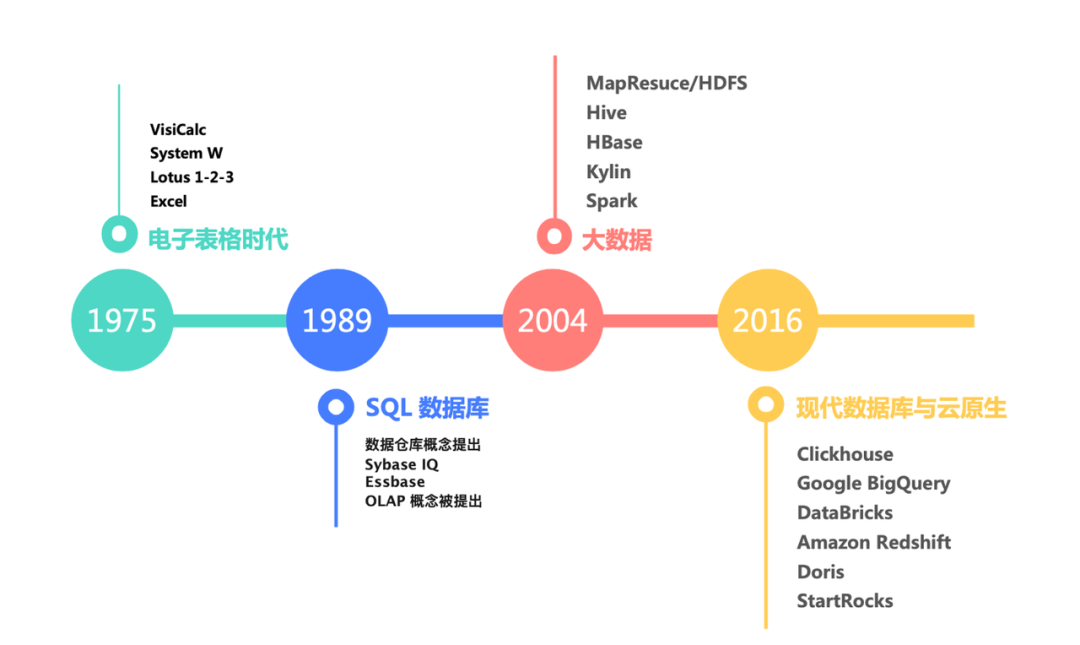
从发展历史来看,分析型数据库的出现比我们想象得更早一些。最初是在 1975 年,一些表格类产品如 Excel 开始出现,人们尝试在表格中直接做分析,这是所有现代分析型数据库的雏形。到了 1989 年,一些以 SQL 语言为查询接口的数据库开始出现,典型代表是 Sybase IQ。2004 年,大数据概念被提出,以 Map/Reduce 为代表的各种大数据套件以及在此基础上的产品(如 Hive、HBase、Spark)开始流行,并在未来十几年内产生了巨大的影响。自 2016 年起,我们熟知的现代分析型数据库出现,以 ClickHouse 为代表,这些数据库具备更多先进特性,如云原生的部署架构和更加完善的产品化设计。
除去这两种类型的数据库之外,更多新型数据库也在不断涌现。例如,以 MongoDB 为代表的文档数据库、以 Redis 为代表的内存数据库、随着 AI 兴起的向量数据库以及工业上的时序数据库……这些新型数据库与传统的事务型和分析型数据库一起,构成了今天我们所见的庞大的数据库产品体系。
数据集成的价值

一方面,传统的数据库在其适合的领域中的地位依然根深蒂固,像是 Oracle 在传统行业的交易数据库中长期占据着非常大的比重,基本看不到被替换的可能性。另一方面,新的数据库也各自在擅长的领域不断发挥自身价值。因此,我们没有理由相信会存在“一个”数据库一统天下的未来。
但是同时,数据的产生不会因为被使用的场景不同而自动生成多份。举个例子,AI 需要使用交易数据,分析师也需要使用交易数据,而交易数据的原始位置依然是业务系统——这便是数据集成的价值所在——通过实时的方式,将原始数据迅速传递到每个有需要的地方,充分发挥不同数据库的特点,创造出各自独特的价值。
我的观点是,在未来多种数据产品共存的情况下,数据集成工具将扮演一个不可或缺的生态角色。它绝非一个临时存在的产物,而是一个长久的重要组成部分。
接下来,让我们一起来看数据集成中的一些思考和实践。
二、数据集成:ETL vs. ELT
关于 ETL 和 ELT 的博弈,我的感受是,性能和准确性总是无法同时获得满分。
ETL 与 ELT: T 好像很关键
在具体实施层面,有两个非常常用的词:ETL 和 ELT。E 代表抽取(Extract),即从数据源中采集数据;L 代表加载(Load),即将数据写入目标数据库;T 代表转换(Transform),这一过程包含许多操作,例如过滤、去重、分组、校验、聚合、富集、增强、分割、脱敏和转换等。从操作数量上看,转换是最复杂的部分。
让我们按步骤逐一分析:
1. 抽取
抽取技术包括全量抽取和增量抽取两个部分。全量抽取相对简单,涉及范围抽取、并发和哈希分片等可控的技术点,总体上没有特别复杂的问题。而增量抽取是一个难点,尤其是对于一些闭源的商业数据库(如 Oracle、Sybase、DB2)。由于这些数据库的事务日志格式无法查阅,而这些数据库又占据着核心位置,如何实时、准确地采集这些数据库的增量数据,是数据集成产品的核心壁垒之一。
2. 转换
转换的难点主要在于状态一致性。转换过程可分为三类:
- 无状态转换:例如常见的过滤、映射和编码转换,这是最容易实现的部分。
- 幂等转换:虽然存在一些状态,但状态主要存储在目标数据库中,可以重复处理数据而不产生错误,例如宽表构建、数据富集和增强。
- 状态精确转换:依赖数据的精确一次处理,例如聚合计算和去重排序。如果同一数据出现两次,最终结果会不准确,这是转换中最困难的部分。
3. 加载
加载的难点较少,只需正确映射表结构、转换基本数据类型,然后调用驱动将数据写入目标数据库。特别是大多数作为目标的现代数据库,它们的开放性、文档和相关知识都优于传统数据库,因此加载过程通常不会成为特别大的问题。
数据集成: E + 无状态/幂等的 T + L

回到我们的实践,ETL 指在数据集成过程中完成转换工作,ELT 指在数据入仓后在数仓中进行各种数据转换加工。那么,什么是我们认为的最佳实践呢?经过一些试错和实践,我们得出的结论如下:
对于所有无状态和幂等的转换过程,采用 ETL 方式推进,可以在数据准确性、性能和稳定性三方面取得较好的平衡。然而,对于不幂等且需要精确一次的转换过程,保证存储和中间状态的一致性成本非常高,因此更适合在目标数据库中完成。
对于数据集成产品来说,最佳实践是提供稳定高效的抽取和导入功能,并在此基础上利用目标数据库的特性进行聚合和分析转换。这样可以形成独特的产品能力,既保证了数据集成过程的稳定性和高效性,又充分发挥了目标数据库在数据处理方面的优势。
三、TapData 数据集成产品:做自己专业的事情, 与数据库做好朋友
作为近年来数据集成赛道的“新秀”,集功能性、易用性、安全性、可集成性于一体,TapData 是一个以低延迟数据移动为核心优势构建的新一代的企业数据基础软件,具备为企业的新型数据需求如数据交换、传统应用改造升级、上云跨云,及运营分析等场景提供开箱即用的解决方案。同时提供云版、本地部署版本,以及开源的社区版本(即将全面上线)。接下来我会重点介绍 TapData 的一些能力:

首先,从基础能力开始,我们支持全量采集和基于 SQL 的部分数据采集,同时也支持基于日志和字段轮询的增量采集。在不同数据库之间同步数据时,我们的工具能够自动转换表结构,完成全自动建表,并对市面上常见的各种开源和闭源数据库都有良好的支持。
实用功能介绍
1. 数据校验:在数据集成任务运行后,数据的准确性是一个非常重要的考量。我们的产品支持全量计数、全字段、采样以及全表哈希的数据对比方式,能够快速验证数据是否准确。一旦发现数据不准确,可以一键修复,保证数据的最终一致性。
2. 增量日志缓存:在有大量同步任务时,增量日志缓存可以有效降低源库的资源消耗。
3. 心跳事件:通过在源库内增加一个定时产生事件的心跳表,不仅能更准确地检测实时同步的延迟,还可以快速推进日志消费点,提高任务的稳定性。
除此之外,TapData 还具备可视化构建自定义处理器、便捷的指标进度监控、日志查看、报错告警等其他诸多特性。正是这些功能使得企业在使用过程中体验到极大的便捷性。
产品架构:轻量架构,支持云服务
我们的产品架构非常轻量,支持以云服务的形式提供数据集成能力。用户只需下载一个小型计算引擎到本地,即可使用全部产品功能。
特色能力:以 MongoDB 为目标的数据丰富能力
最后介绍一个 TapData 的特色能力:我们支持以所有数据源作为数据来源,以 MongoDB 为目标构建文档宽表。通过拖拉拽的方式,用户可以在产品中构建包括层级文档和层级数组在内的复杂数据模型,并存储到 MongoDB 中。这里整个过程都是批流一体的,目标数据的延迟可保持在秒级,是与 MongoDB 整合最好的建模工具。
关于 TapData
TapData Inc.「深圳钛铂数据有限公司」,成立于2019年9月,核心员工来自 MongoDB、Oracle、百度等,研发人员占比超80%,至今已获五源资本等多家头部风投数千万美元融资。已服务中国移动、中国联通、南方电网、中国一汽、中芯国际、周生生、富邦银行等数十家行业标杆企业。TapData 坚持“开放+开源”战略,推出 TapData Cloud,将无代码数据实时同步的能力以 SaaS 的形式免费开放,目前已积累 1,000+ 云版和企业版客户,覆盖金融、制造、零售、能源、政府等多个行业。此外,TapData 社区版也已发布,正在面向开发者逐步共享其核心功能。
TapData Live Data Platform是一个以低延迟数据移动为核心优势构建的现代数据平台。企业可以用来实现核心数据系统之间的实时同步、实时交换及实时处理。当实时数据需求日益增多时,企业可以结合分布式存储,使用 TapData 将孤岛数据无缝集中到中央数据平台,为众多下游业务提供一站式的实时数据交换和发布服务。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-07-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号