Elasticsearch 新的索引 mode: Logsdb 初体验
原创Elasticsearch 新的索引 mode: Logsdb 初体验
原创
引言:Elasticsearch 的持续演进
随着现代 IT 架构中数据量的激增,日志数据的管理成为了企业面临的关键挑战之一。企业在面对数十亿条日志时,不仅需要高效存储,还要求实时查询和分析能力。作为行业领先的分布式搜索与分析引擎,Elasticsearch 一直是日志分析的首选工具。
然而,随着数据量的爆炸式增长,传统的日志存储模式逐渐暴露出瓶颈。Elasticsearch 最初为优化搜索相关性而设计,使用默认的索引模式来处理日志数据会引入冗余且不适用于日志场景的数据结构。这导致了数据膨胀问题——存储占用甚至超出原始数据量。这不仅增加了存储成本的压力,同时也对查询性能造成了负面影响。
为了应对这一挑战,Elasticsearch 8.15 推出了全新的 Logsdb 索引模式。这是一个专为优化日志数据存储而设计的索引模式,目前以技术预览版(Tech Preview)的形式发布,承诺在未来版本中进一步改进与完善。Logsdb 模式通过一系列创新的存储技术,帮助用户大幅减少存储占用,并提升日志查询性能,为企业提供更经济高效的日志管理解决方案。
Logsdb 模式的突破:从膨胀到精简
Logsdb 索引模式是 Elasticsearch 针对日志存储需求专门设计的解决方案,旨在克服传统索引模式中因索引膨胀造成的存储压力。
传统索引模式在存储日志数据时,通常需要保留完整的 _source 字段,并且没有针对日志特点进行优化的索引排序机制。这导致了存储的非线性增长,尤其是在日志数据量爆发的情况下,存储的膨胀率可能达到原始数据的数倍。Logsdb 通过一系列优化措施,减少了索引的冗余信息,提升了存储压缩效率。关键创新包括:
PUT my-index-000001
{
"settings": {
"index": {
"mode": "logsdb"
}
}
}通过这个配置,您可以为索引启用 Logsdb 模式,专门优化日志数据的存储和查询性能。
- 合成 _source (Synthetic source):在 Logsdb 模式下,系统不再直接存储
_source字段(也就是我们通常理解的行存),而是在查询时按需合成。这大幅减少了存储空间,并且对查询性能的影响微乎其微。 - 索引排序 (Index sorting):Logsdb 默认在
host.name和@timestamp字段上进行排序,这一优化能够大幅提高存储压缩率。通过索引排序,日志数据可以更紧凑地存储,进一步减少索引占用。 - 高效压缩 (Efficient compression):Logsdb 模式使用了 ZSTD 等更高效的压缩算法,尤其是在字段启用
doc values时,能够进一步降低存储需求。通过这些压缩技术,存储效率比传统模式提高了数倍。
在日志数据集上进行的基准测试表明,启用 Logsdb 模式后,存储需求可以减少 2.5 倍,这对于那些面临存储压力的企业而言,是一个巨大的改进。
尽管 Logsdb 目前作为预览版功能发布,但其未来发展潜力巨大。随着技术的进一步成熟,Logsdb 很将成为 ELK 的日志分析的默认选择,进一步推动 Elasticsearch 在日志管理领域的领先地位。
Logsdb 配置步骤与实践
启用 Logsdb 模式相对简单,只需在索引配置中指定 index.mode 为 logsdb。下面是一个实际的配置示例,基于 esrally 提供的 http_logs 数据集,该数据集包含 247,249,096 个文档,原始数据大小为 31.1GB。
1. 基本配置
为了启用 Logsdb 模式,你可以通过以下命令创建一个新的索引,并为日志数据优化存储:
PUT http_logs_logsdb
{
"settings": {
"index": {
"mode": "logsdb"
}
},
"mappings": {
"dynamic": "strict",
"properties": {
"clientip": {
"type": "ip"
},
"request": {
"type": "match_only_text"
},
"status": {
"type": "keyword"
},
"size": {
"type": "integer"
},
"geoip": {
"properties": {
"country_name": {
"type": "keyword"
},
"city_name": {
"type": "keyword"
},
"location": {
"type": "geo_point"
}
}
}
}
}
}在这个配置中,我们为 http_logs 数据集启用了 Logsdb 模式。经过存储优化后,索引大小为 10.82GB,相比原始数据的 31.1GB,已经实现了大幅度的存储节省。
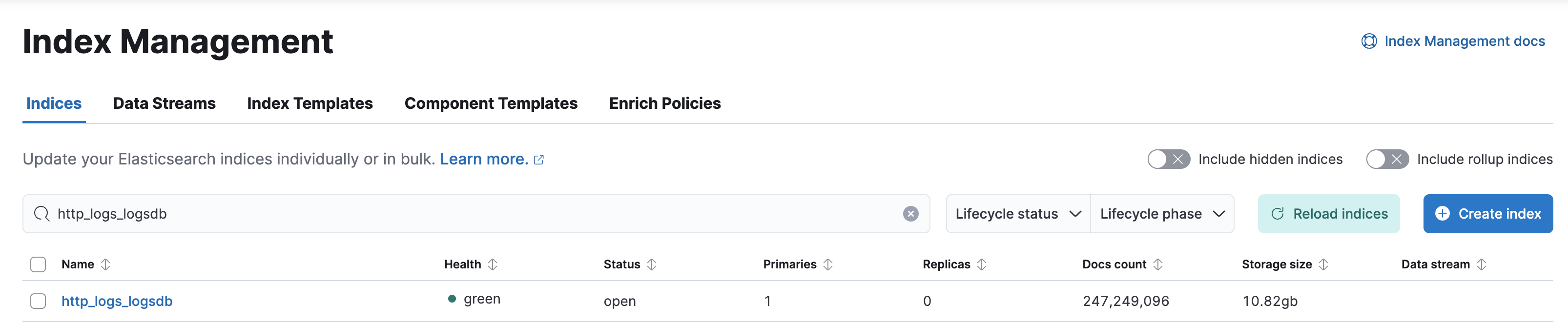
2. Logsdb + Runtime Fields 配置
如果我们进一步利用 runtime fields,则可以在显著减少存储占用的情况下灵活处理字段。例如,我们可以为 request 字段定义一个 runtime field,只在查询时按需计算字段值。这可以带来更大的存储优化,将索引大小进一步减少到 7.17GB:
PUT http_logs_logsdb_with_runtime
{
"settings": {
"index": {
"mode": "logsdb"
}
},
"mappings": {
"dynamic": "strict",
"properties": {
"clientip": {
"type": "ip"
},
"status": {
"type": "keyword"
},
"size": {
"type": "integer"
},
"geoip": {
"properties": {
"country_name": {
"type": "keyword"
},
"city_name": {
"type": "keyword"
},
"location": {
"type": "geo_point"
}
}
}
},
"runtime": {
"request": {
"type": "keyword",
"script": {
"source": """
// 示例:从 request 字段提取自定义信息
if (doc['request'].size() > 0) {
emit(doc['request'].value);
}
"""
}
}
}
}
}通过使用 runtime fields,我们可以动态计算 request 字段的值,而不需要在存储中占用额外的空间。最终索引大小从 10.82GB 进一步缩小到 7.17GB。
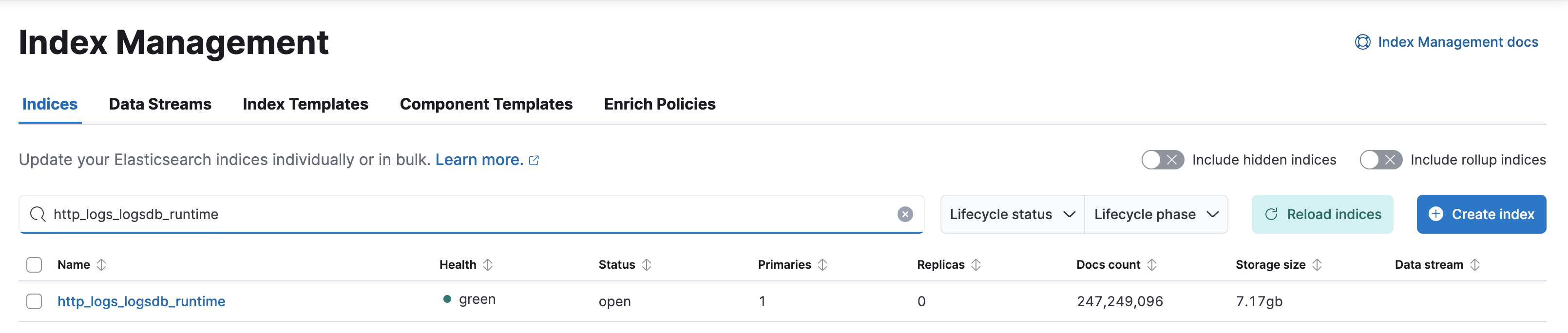
性能和存储对比:传统 vs Logsdb
Logsdb 模式的最大优势之一就是其存储效率的显著提升。通过对 esrally http_logs 数据集的测试,我们可以清晰地看到 Logsdb 与传统索引模式的对比:
- 原始数据集大小:31.1GB
- 传统索引模式下的存储大小:传统 Elasticsearch 索引模式通常会导致数据膨胀,存储占用可能比原始数据高出数倍。通常我们在预估日志大小的时候,会使用 1.2 的索引膨胀率
- Logsdb 模式的存储大小:启用 Logsdb 后,索引大小缩减至 10.82GB,实现了约 2.87 倍 的存储优化。我们可以将索引膨胀率设为 0.3
- Logsdb + Runtime Fields 的存储大小:通过进一步使用 runtime fields,索引大小缩小至 7.17GB,使整体存储需求减少了约 4.34 倍。我们可以将索引膨胀率设为 0.2
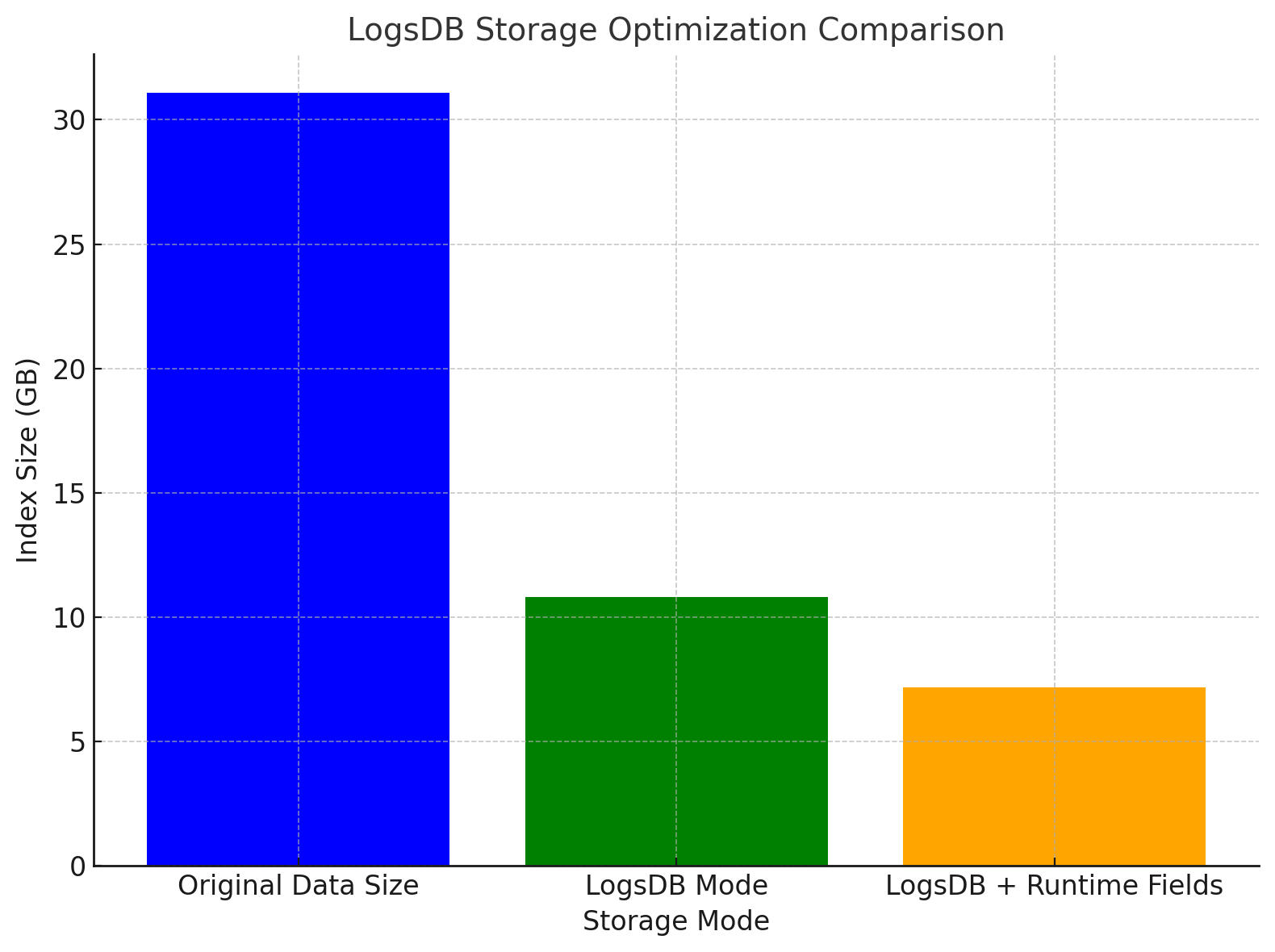
这样的对比清晰展示了 Logsdb 模式的存储优势。通过 Logsdb,用户不仅能够降低存储成本,还能显著提升 Elasticsearch 的查询性能,尤其是在处理大规模日志数据时。
总结:Elasticsearch 的未来
随着 Elasticsearch 8.15 的发布,Logsdb 模式为日志分析领域带来了革命性的改进。这不仅帮助用户显著降低存储需求,还提高了查询效率,让 Elasticsearch 在处理海量日志数据的场景中表现得更加游刃有余。
尽管 Logsdb 当前仍处于技术预览阶段,但它展示了 Elasticsearch 在未来的巨大潜力。随着 Logsdb 技术的进一步成熟和优化,我们可以预见到 Elasticsearch 将继续在日志分析系统中占据领先地位,并为企业提供更智能、更高效的解决方案。
Logsdb 的出现表明,Elasticsearch 不仅仅是一个搜索引擎,更是一个持续创新、不断优化的日志分析平台。如果你还没有尝试 Logsdb 模式,现在正是时候。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
