解密prompt系列40. LLM推理scaling Law
原创解密prompt系列40. LLM推理scaling Law
原创
OpenAI的O-1出现前,其实就有已经有大佬开始分析后面OpenAI的技术路线,其中一个方向就是从Pretrain-scaling,Post-Train-scaling向Inference Scaling的转变,这一章我们挑3篇inference-scaling相关的论文来聊聊,前两篇分别从聚合策略和搜索策略来优化广度推理,最后一篇全面的分析了各类广度深度推理策略的最优使用方案。
广度打分策略
Are More LM Calls All You Need? Towards the Scaling Properties of Compound AI Systems
第一篇论文的出发点比较简单,简单说就是论证Inference Ensemble是否有效,既让模型多次回答同一个问题,再通过voting或filter-voting等不同的ensemble打分策略对答案进行投票,分析对回答准确率的影响。这里filter vote借助以下LLM prompt对推理得到的答案进行筛选再做major votte
[User Question]: {query}
[Answer]:{answer}
Instruction: Review your previous answer and find problems with your answer. Finally, conclude with either ’[[correct]]’ if the above answer is correct or ’[[wrong]]’ if it is incorrect. Think step by step.
Verdict:论文在MMLU和QA等有标准答案的数据集上进行了测试,结果得到了下图非单调的曲线,会发现随着推理次数的上升,不论是vote还是filter vote的回答准确率都是非单调的,其中vote会先上升在下降,filter vote的表现在不同数据集上存在差异。这里我们就看下major vote,毕竟filter vote又引入一步模型推理所以其实有两层变量。
回到了最熟悉的data analysis领域,U-Shape,∩-shape模式多数情况下都是因为数据中存在多个表现各异的分组,有的组内指标先上升后稳定,有的组内指标稳定下降,多个小组的指标汇总后就会出现,先升后降或者先降后升的模式。所以这种U-Shape,∩-shape模式的解决思路就是寻找那个可以显著区分指标走势的confounder变量。
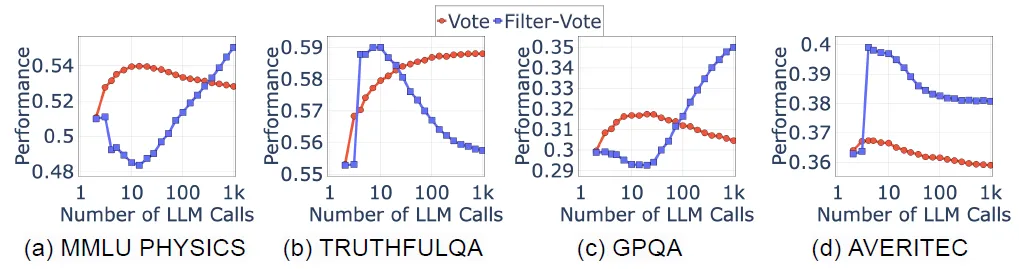
论文定位到的confounder变量是Query难度,使用一个问题最终能否被回答作为衡量这个问题难度的定义。其实个人认为不是query难度,而是该问题在模型内化知识空间中对的答案和错的答案本身的概率分布,当模型更高的概率得到正确答案时,更多的LLM推理和major vote才能生效。所以随着推理次数增加简单问题的回答准确率先上升后趋于平稳,而复杂问题的准确率持续下降,合并起来就出现了先升后降的趋势。
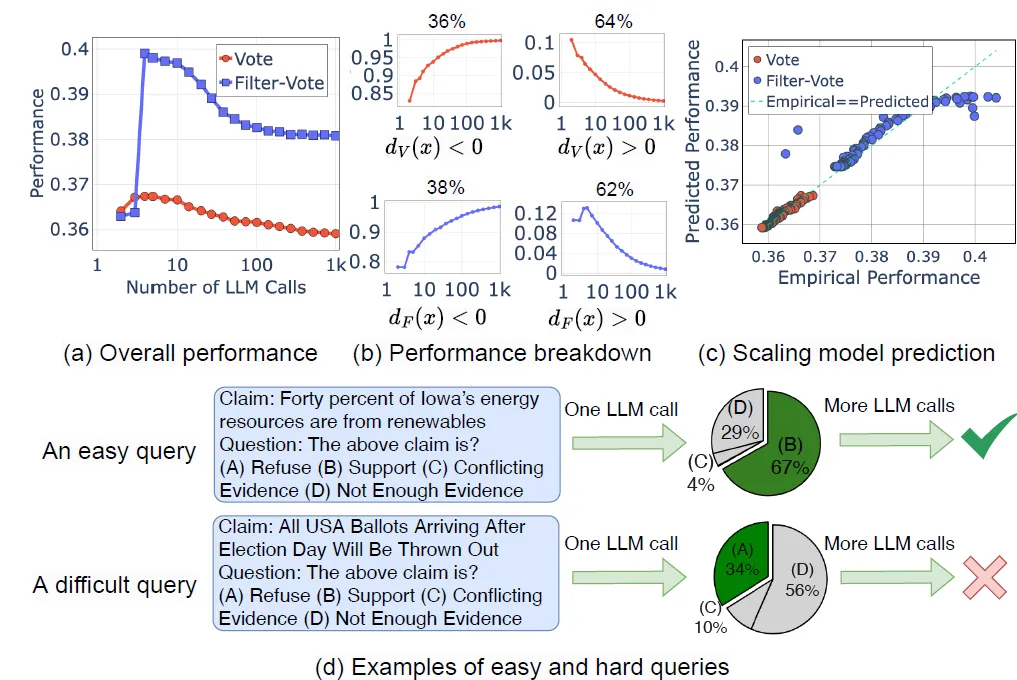
第一篇论文其实是用来做个首尾呼应,这里论文发现了Query难度会影响推理打分策略的效果,和后面谷歌的推理策略最优化不谋而合。
广度搜索策略
REBASE:An Empirical Analysis of Compute-Optimal Inference for Problem-Solving with Language Models
广度推理策略,其实包含两个部分一个是如何生成推理链路(搜索策略),一个是如何对推理链路进行打分
- 广度搜索:包括像前一篇论文直接随机采样生成多个推理,还有更复杂类似TOT,MCTS的树形多步推理
- 打分:包括major vote,filter major vote, weighted major vote,还有基于reward打分的best-of-n(包括基于结果的ORM和基于过程的PRM)
前面一篇论文说了major vote等打分策略,但搜索策略只用了简单的多次随机推理,这里我们再看一篇对搜索策略进行优化的论文REBEASE。论文采用了树形搜索,在搜索逻辑上REBEASE和TOT相似,通过实验提供了推理准确率和推理成本之间balance的一些insight。
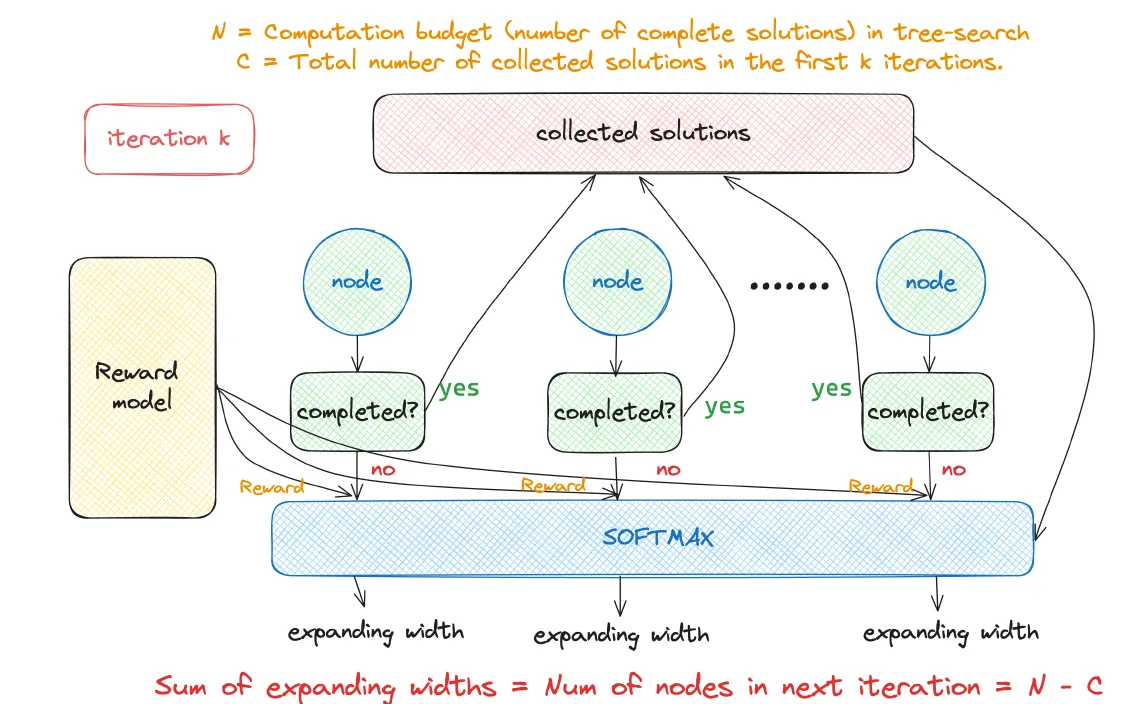
树形搜索的流程如下,
- 第一步针对问题生成N个候选答案,推理Budget=N
- 使用PRM模型对N个候选推理步骤进行打分,同时使用模型判断这N个候选步骤中是否有推理完成的节点,如果有C个节点推理完成,则budget-=C
- 对未完成的节点,根据PRM打分进行加权采样,采样后的节点进行下一步推理
- 直至Budget=0,也就是成功生成N个推理结果后终止
- 对最终得到的N个候选答案,可以使用各类广度打分策略来进行聚合,这里论文采用了理论上效果更好的weighted major vote和Best-of-N
在MATH和GSM8k数据集上,论文使用PRM数据集微调了Llemma-34B模型作为Reward模型,分别使用在MeatMath数据集上微调过的Mistral-7B,llema-7B,Llema-34B作为推理模型,以下是REBEASE和其他广度搜索策略,以及不考虑Budget的属性搜索策略的效果对比
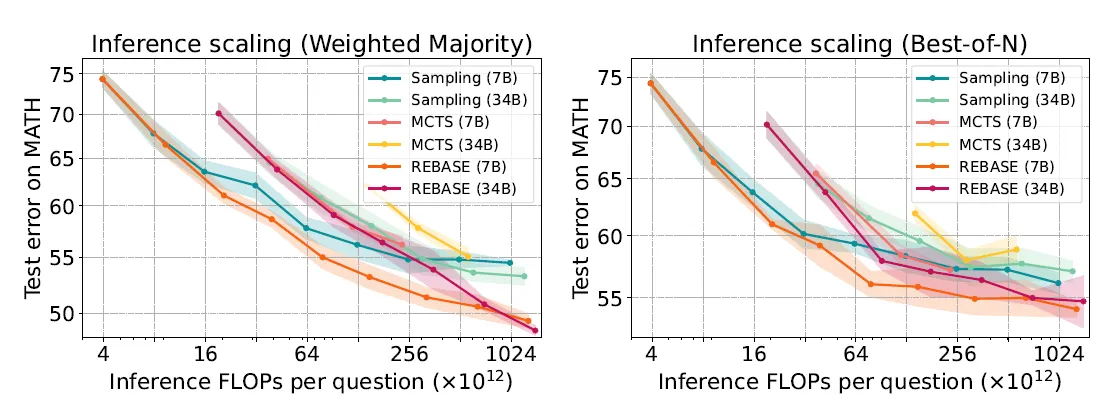
效果上,相同的推理错误率,使用REBEASE搜索策略,相比随机采样和MCTS需要更低的推理成本,并且随错误率降低,推理量级的上升幅度相比其他策略更低。
同时在同一个模型系列中,相同错误率下,使用推理广度或者树形搜索策略,7B模型相比34B所需的推理成本更低。 这里的观点就很有意思了也就是小模型通过更优的推理策略,是有可能用更低的成本达到大模型的效果的,这个观点在后面谷歌的论文中得到了更全面细致的论证。
全面分析:Test Time Scaling
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters RISE:Recursive introspection: Teaching foundation models how to self-improve MATH-SHEPHERD: VERIFY AND REINFORCE LLMS STEP-BY-STEP WITHOUT HUMAN ANNOTATIONS
如果说前两篇论文各自选了推理策略中的一个方向去做优化和分析,那谷歌的这篇论文就是一网打尽式的把各个推理策略和优化方向都全面考虑在内,给出了一个综合的推理策略选择最优方案。论文的目标就是回答在给定prompt和推理budget的前提下如何选择最优的推理策略, 以及该推理策略对推理效果的提升,是否比直接换个大模型要来的更显著?
论文提出优化推理效果,本质上是调整模型推理的token分布,一种是让模型自我调整,例如通过RL对齐让模型生成中间推理过程(STaR),也可以让模型通过自我优化,对推理结果给出优化建议并针对建议进行优化,论文称之为“Proposal”。另一种就是面向一个打分模型进行搜索优化,论文称之为“Verifier”。我理解其实前者的本质就是深度策略(例如self-refine,self-critique,self-reflection),而后者的本质广度策略(例如best-of-n)。
论文提出以上不同的策略适配不同难度的问题,那第一步就是对问题的难度进行分类,这里论文使用MATH数据集,使用基座模型对每个样本生成2048个推理结果,然后使用打分模型评估这些推理结果是否正确,对正确率进行分桶,总共分成5个桶,代表不同的难度分层。有了难度分类,下面我们分别看下优化Verifier和Proposal的效果
Verifier
Verifier依赖打分模型,所以首先是PRM模型的训练,不熟悉PRM的可以先读这篇解密prompt系列34. RLHF之训练另辟蹊径:循序渐进 & 青出于蓝。这里论文参考了MATH-SHEPHERD的全自动标注方案,通过对同一个问题生成多个推理过程,过程中的每个节点,都使用该节点通向正确答案的概率作为该节点的标签来训练PRM模型。
至于如何使用PRM来优化推理,其实包含两个步骤:多个推理链路的搜索生成,以及对多个链路打分投票得到最终答案。
先说推理链路的搜索策略,这里论文尝试了三种方案包含简单广度搜索和树形搜索,分别是
- Best-of-N:随机采样生成N个推理链路
- Beam Search:生成N个初始节点,每一步都基于PRM选择Top M个节点继续推理,最终保留N个得分最高的推理链路
- Lookahead Search:同样是Beam Search只不过每一步保留哪些节点,不由当前节点的打分决定,而是再向前推理K步,由K步之后的节点打分决定,当K=0其实就是Beam Search。虽然看起来是最科学的搜索策略,但是也带来了额外的计算成本。
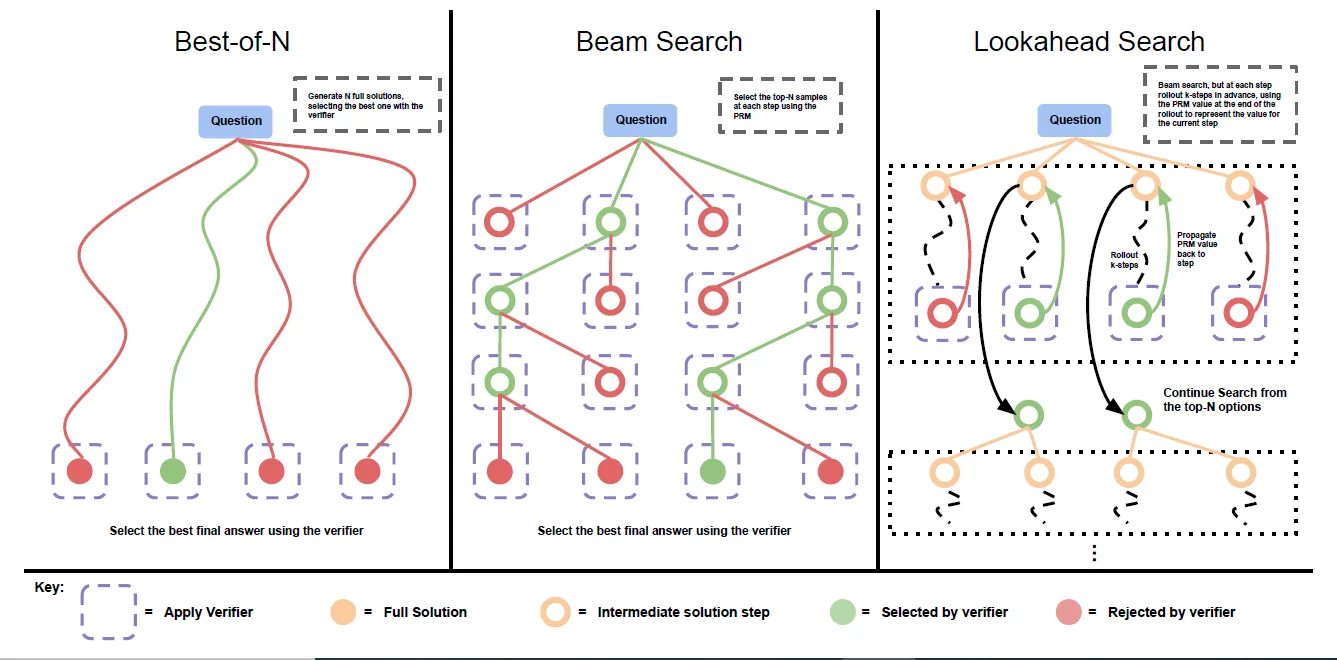
再来说下打分投票策略,以上不同的搜索策略都会得到N个推理链路,论文对每个推理链路进行整体打分,这里没有使用多个步骤的PRM打分聚合而是直接使用了最后一个节点的PRM打分作为整个推理链路的得分。得到打分后,使用weighted best-of-n来得到最终答案,也就是对每个答案计算所有得到该答案的推理链路的总分,得分最高的答案作为最终答案。
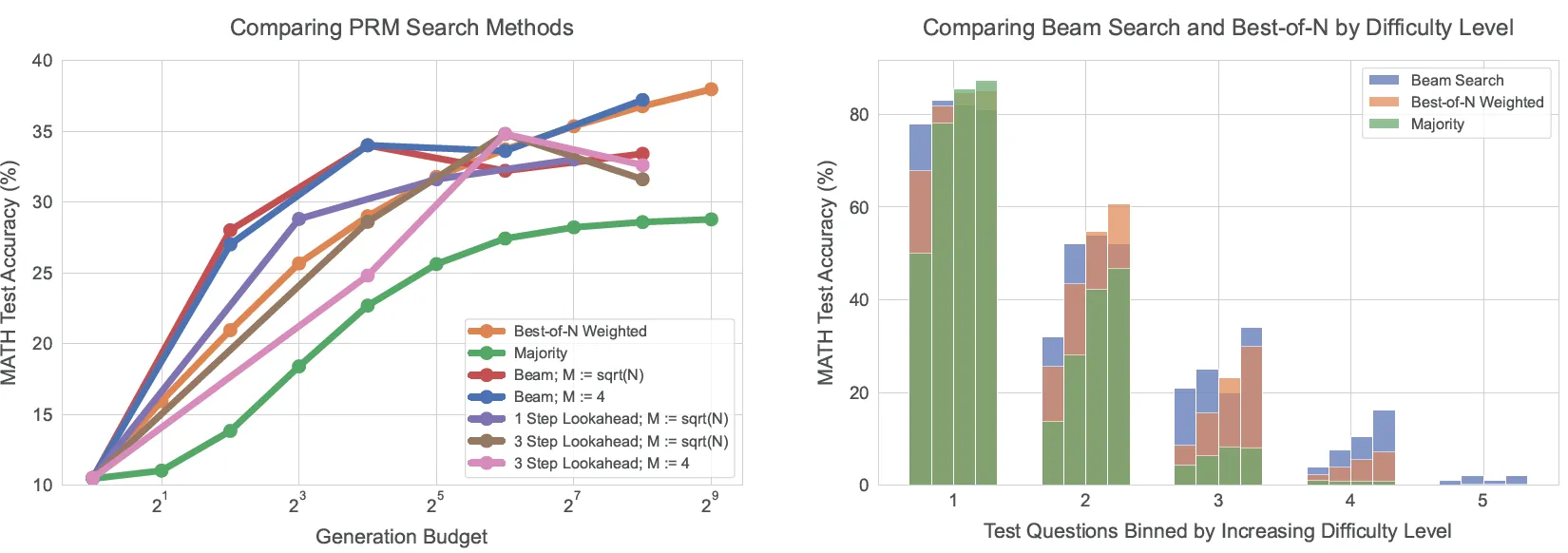
不同策略的效果对比能得到以下几个结论
- 当推理budget有限时,Beam Search的效果最好,当N逐渐变大后Best-of-N逐渐展现出了暴力就是奇迹的优越性能
- 相同Budget下,Lookahead的效果是最差的,论文怀疑是过度的搜索层的优化会导致一些例如推理链路过短的过度优化问题(先前推N步后early stop了)。但我有点怀疑是因为向前推的部分论文使用的是temperature=0进行外推,影响了推理质量
- 在不同难度的问题上,简单问题(level 1-2)随着budget上升,Best-of-N的效果会逐渐变得更好,提示广度策略对于简单问题的有效性。而较难的问题(level3-4),beam-search持续有更优的效果,对于最难的问题(level5)啥也不好使
一言以蔽之问题越简单搜索策略越简单,推理资源越多搜索策略越简单
Proposal
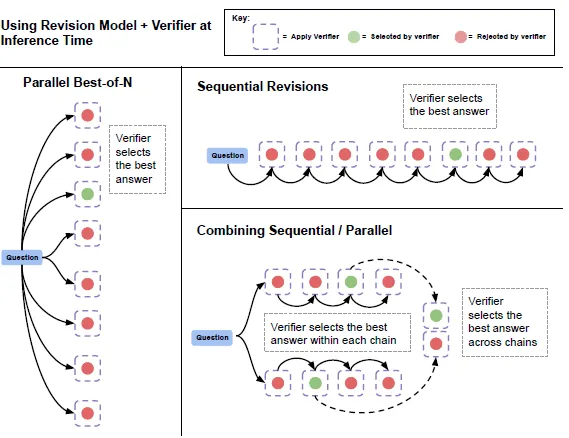
Proposal依赖模型自我反思优化的能力,所以首先是训练Revision模型,论文参考了RISE的方案,只不过采用了离线构建多轮回答的方案。论文对每个样本独立采样64次,从中把正确的回答和0-4个错误的回答(随机采样)进行配对,把错误回答作为上文,正确回答作为最终的回答构建多轮对话作为训练数据。
配对过程选用了编辑距离来挑选和正确回答最相近的错误回答,帮助模型更容易找到正确和错误之间的关联性,真的是去学习从错误中定位原因进行优化,而非跳过错误的上文,直接去尝试生成正确答案。然后使用以上样本对模型进行微调。
但以上的样本存在bias,也就是上文只有错误答案,最终的推理答案都和上文不同,而真正在推理过程中使用多个结果作为上文,其中是可能存在正确答案的,也就是有可能模型会把正确答案给改成错误答案。因此论文选择把revision和verifier进行结合,也就是使用打分模型从revision序列生成的多个推理结果中选择最正确的。
效果上论文发现,在不同的推理budget下,同样是N个推理链路,revision深度搜索的效果都要优于parallel广度搜索。但论文认为本质上两种策略应该在不同场景中各有优劣,广度策略更善于全局搜索,而深度策略依赖最开始已经选择了正确的方向然后进行持续的局部优化。因此论文尝试把广度策略和深度策略进行合并,并寻找最优的合并比例,给定budget多少用来做深度搜索,多少做广度搜索。
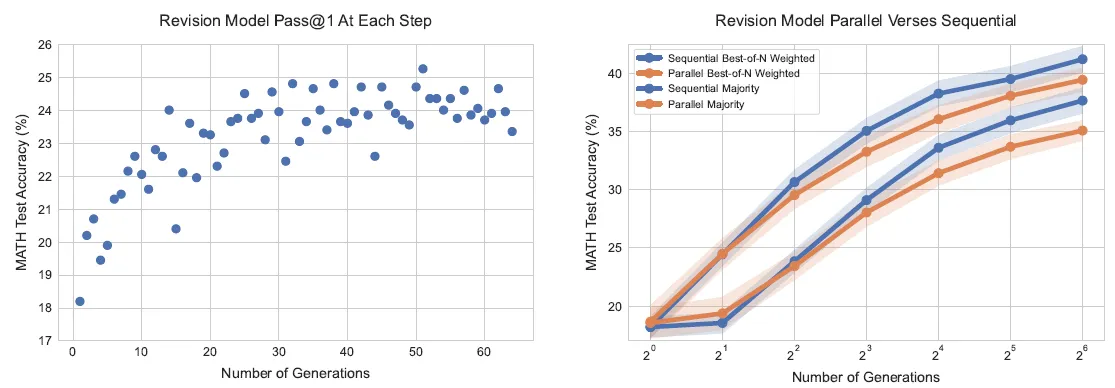
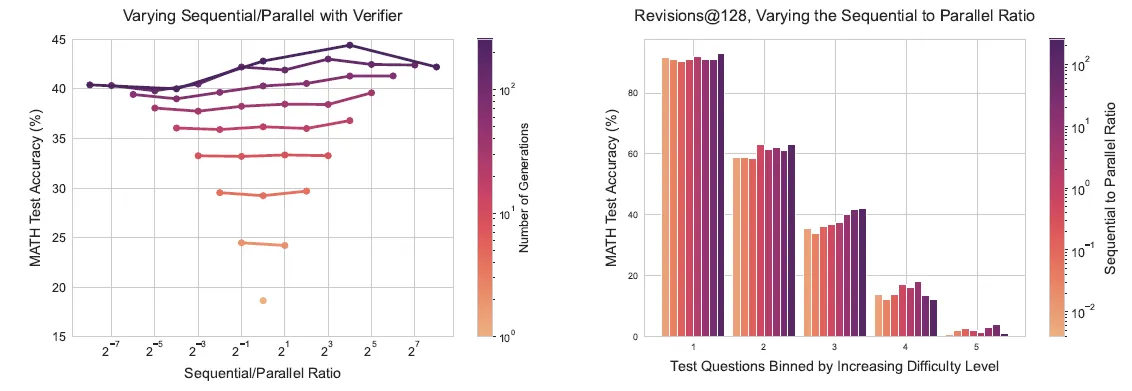
论文认为在不同的budget和问题难度下应该存在广度和深度策略的最优ratio,老实说下图的趋势并不是非常的明显,能推理出的结论有
- Budget有限,revision更多的效果更好,Budget很大时存在最优ratio。但我的感觉是这并非balance ratio,而是广度策略对budget的依赖更明显存在突变点,就是当budget>threshold会在部分问题上效果有更显著的提升,而revision随budget的效果提升更平滑
- 简单问题,revision更多效果更好,复杂问题存在最优ratio,在解决复杂问题时深度和广度策略可以互相补充
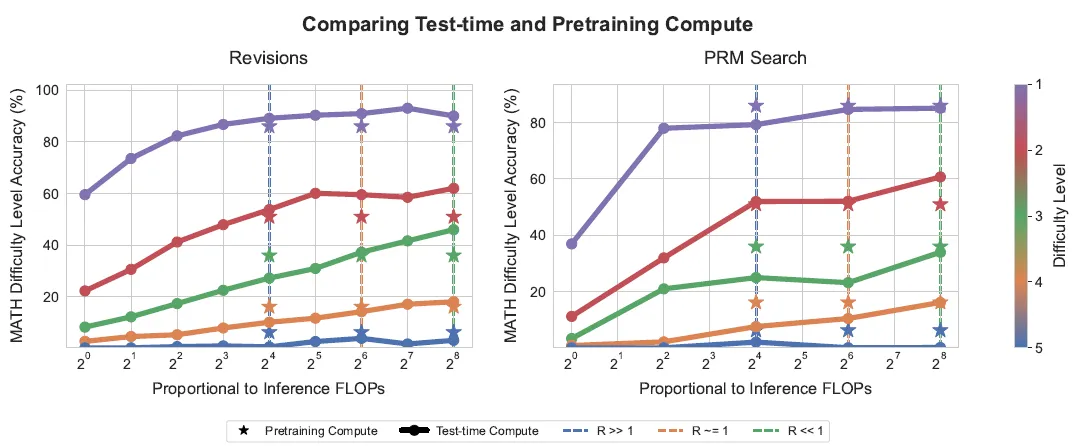
最后还有一个问题没有回答就是推理效果提升和预训练之间的balance,直接上图,具体数据不是很重要因为和模型以及数据集都相关,所以只说下insight
- 简单问题:更多推理资源能覆盖更多预训练能解决的问题,所以小模型更多推理资源更合适
- 复杂问题:对于模型能力以外的复杂问题,预训练是提升模型能力的核心
想看更全的大模型相关论文梳理·微调及预训练数据和框架·AIGC应用,移步Github >> DecryPrompt
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
