【AI绘画】Midjourney前置指令/describe、/shorten详解

【AI绘画】Midjourney前置指令/describe、/shorten详解

CSDN-Z
发布于 2024-10-17 18:06:32
发布于 2024-10-17 18:06:32
💯前言
- 之前我们已经在【AI绘画】Midjourney前置指令/settings设置详解、【AI绘画】Midjourney前置/imagine与单图指令详解、【AI绘画】Midjourney前置指令/blend、/info、/subscribe详解中深入学习了/settings、/imagin、/blend、/info、/subscribe这些前置指令的应用,为我们在使用Midjourney时提供了丰富的功能和灵活的操作方式。
- 接下来,我们将继续深入探讨Midjourney中的其他前置指令,包括/describe和/shorten。这些指令在生成图像和优化输出时同样具有重要作用,通过学习这两个前置指令,我们也可以很好的提升Midjourney提示词的书写水平。
- Midjourney官方使用手册
💯Midjourney前置指令/describe
上传一张图片,Midjourney根据图片生成提示词
- 在使用AI绘画的过程中,许多人都会遇到这样的情况:你偶然发现一张非常吸引人的图片,明确知道它是通过AI生成的,却无从得知具体的提示词,即使尝试自己编写提示词进行复刻,最终的效果也总是差强人意。那么,有没有一种方法可以帮助我们解析出这张图片背后可能使用的提示词呢?

- 这就是Midjourney的/describe指令所能帮助实现的。/describe的功能是通过上传一张图片或图片链接,让Midjourney根据图像的内容来生成可能的提示词。它可以帮助我们推测出这张图片在生成时大概使用了哪些提示词,从而为我们提供一个更接近原作效果的提示词基础。
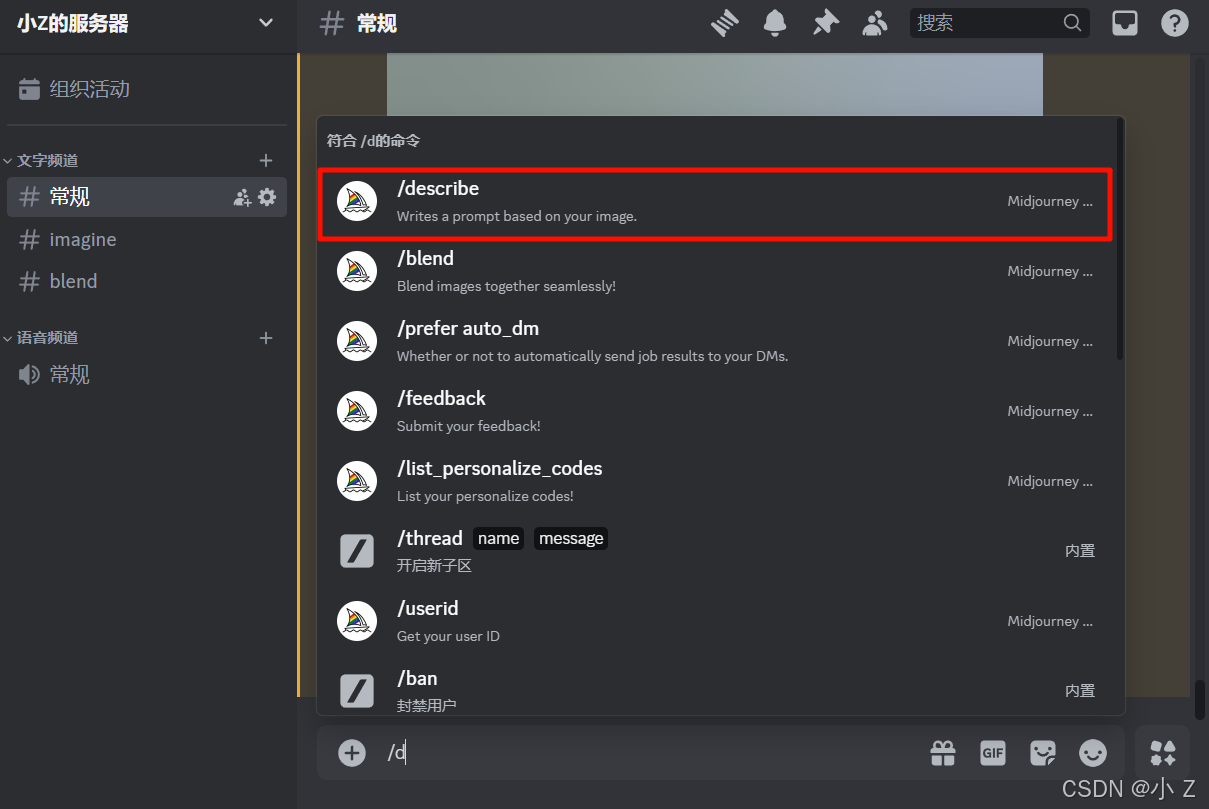
使用方法
- 当你选择使用/describe指令后,系统会提示你上传一张图片或提供一个图像链接。
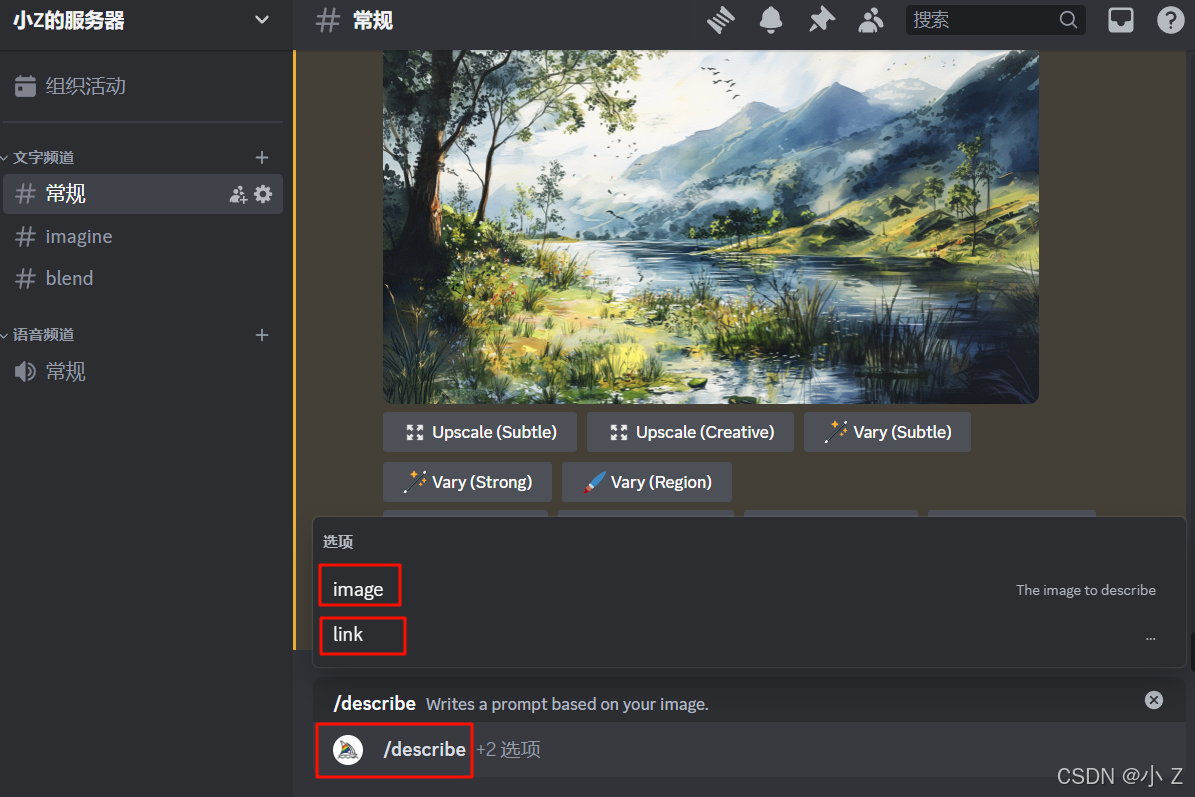
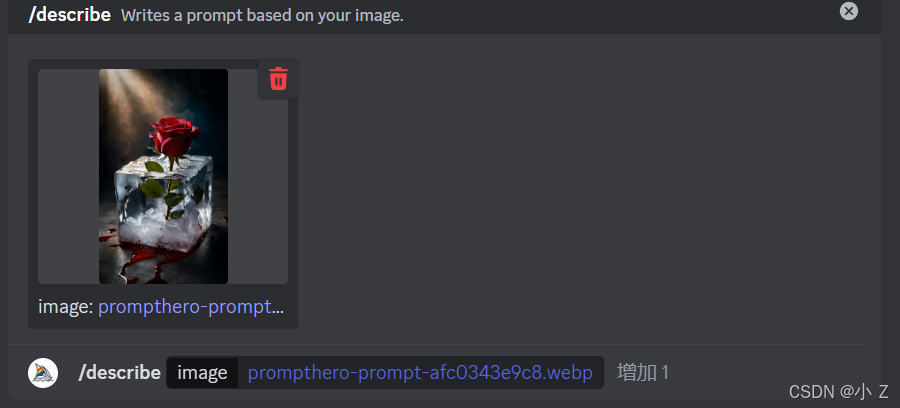
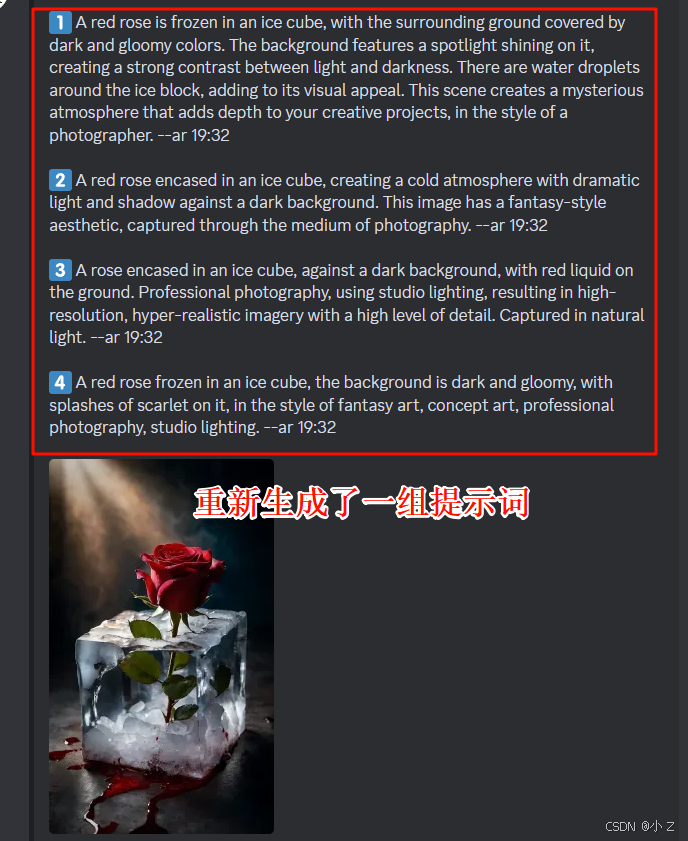
- 上传图片后,Midjourney会自动对图像的提示词进行分析和推测,并给出四组可能的提示词。这些提示词每一组都对图像的特征进行了不同角度的描述。
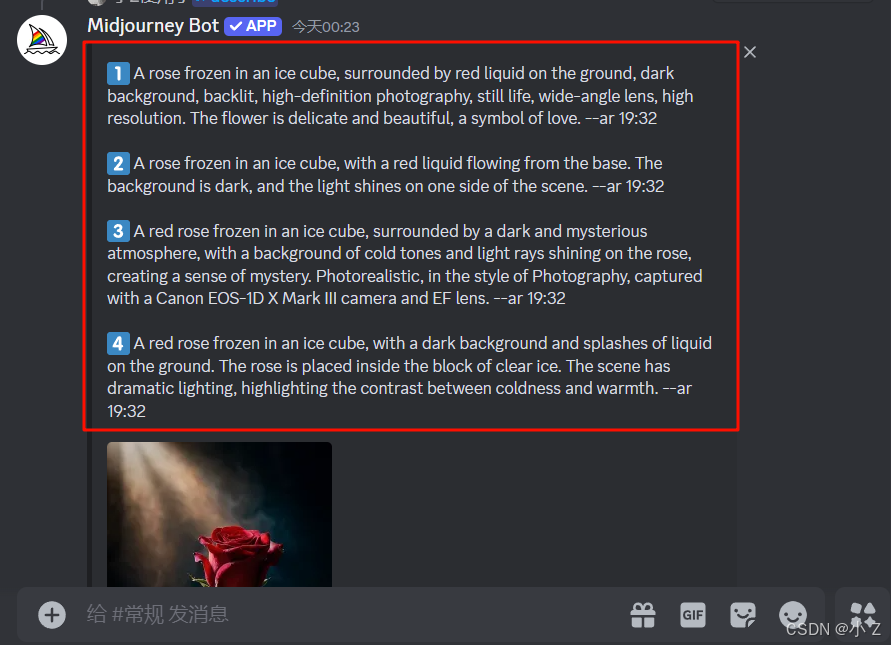
1️⃣2️⃣3️⃣4️⃣(选择对应提示词生成图片)
- 这时你可能会选择将这些提示词复制下来,然后再手动输入到Midjourney进行图像生成。但其实,你完全不需要这么做,因为Midjourney在这些提示词的下方提供了一排按钮 1️⃣2️⃣3️⃣4️⃣,你可以直接点击这些按钮来生成对应提示词的图像。
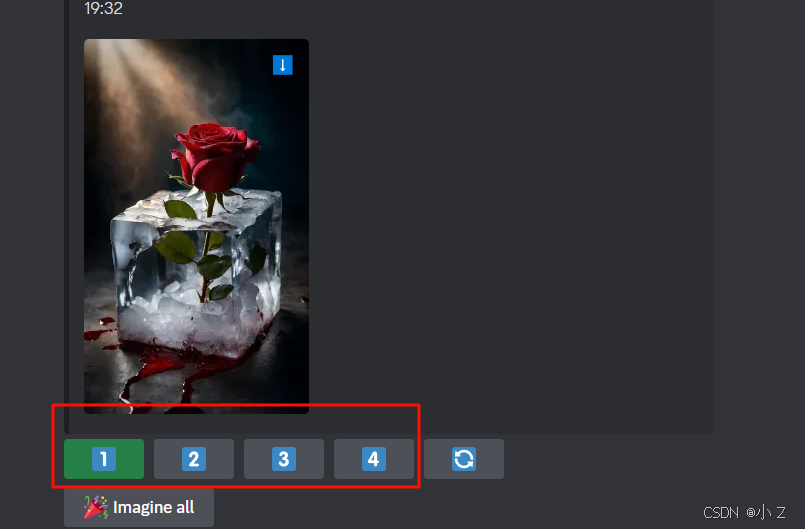
- 当你点击对应的按钮后,系统会直接将你带入到/imagine提示词编辑界面。在这个界面中,你会看到上面系统推测出的提示词已经自动填入。你可以在这里对提示词进行进一步的编辑和调整
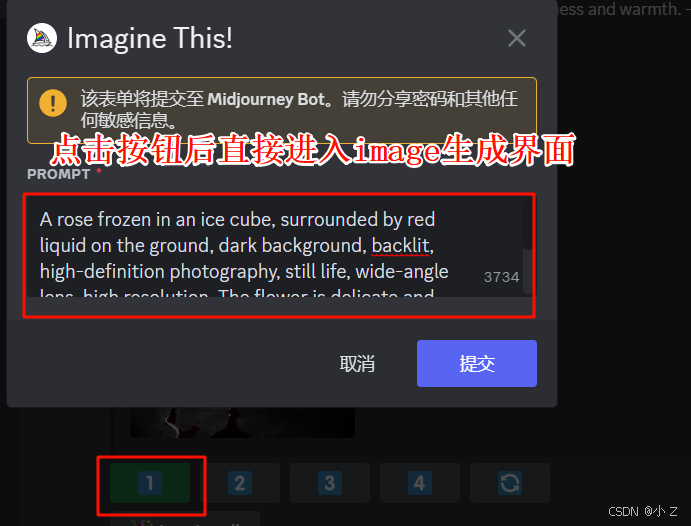
🔄(重新识别生成一组提示词)
- 如果你希望找到另一套更接近你期望效果的提示词,Midjourney提供了一个简单的方法。你只需点击“🔄”按钮,系统就会重新为你生成四组不同的提示词。每次点击刷新,Midjourney都会根据上传的图片,生成一组全新的提示词,这样你可以在不同的提示词中选择最适合的一组。
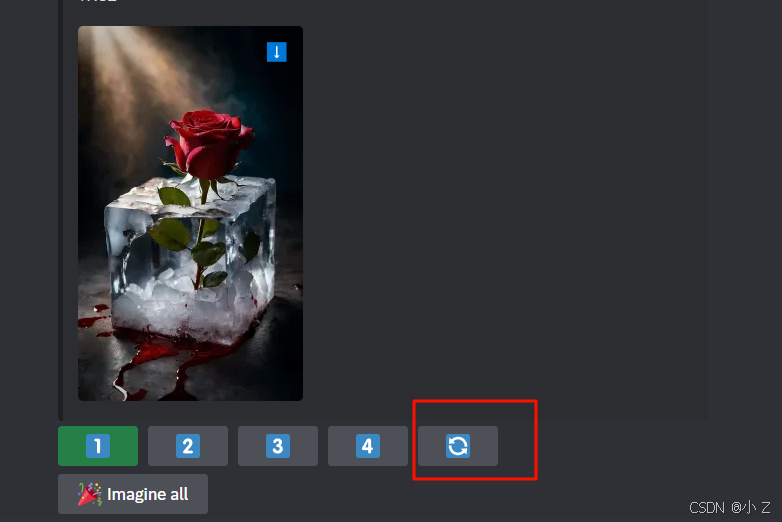
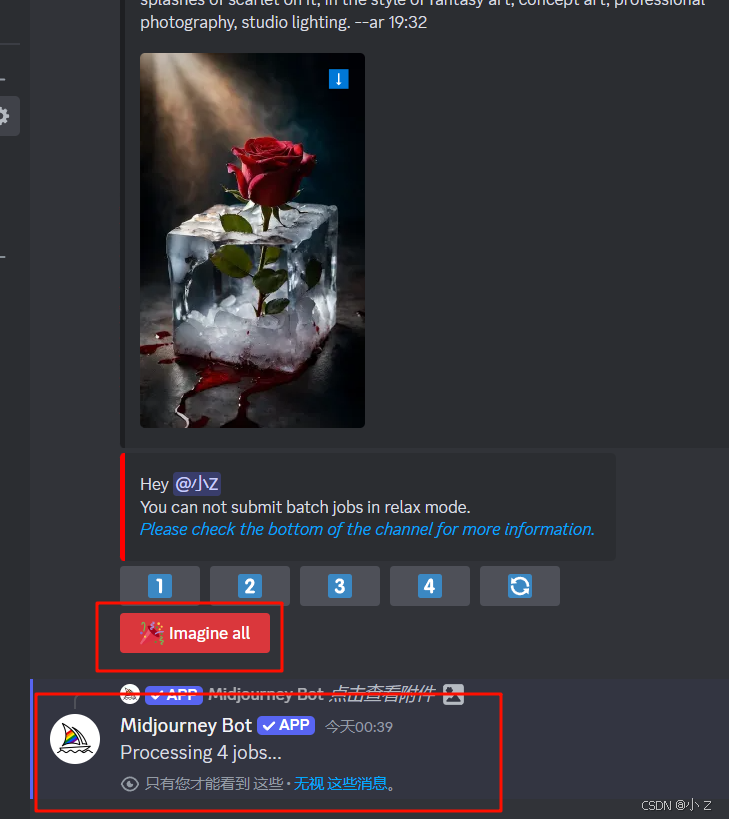
🎉Imagine all(一次性生成所有提示词对应的图片)
如果你觉得逐一点击每个提示词来生成图像比较麻烦,可以直接点击“Imagine all”按钮。系统将会自动生成四组提示词对应的四幅图像,可以一次性查看所有结果。
注意
Midjourney对生成图片的提示词进行猜测,不能用于准确复刻上传的图像
- Midjourney对图片的提示词生成只是基于图像特征的推测,并不能用于准确复刻上传的图片。即使你将Midjourney生成的图像重新上传并使用/describe指令生成提示词,它依然无法完全还原原始图像所使用的提示词。
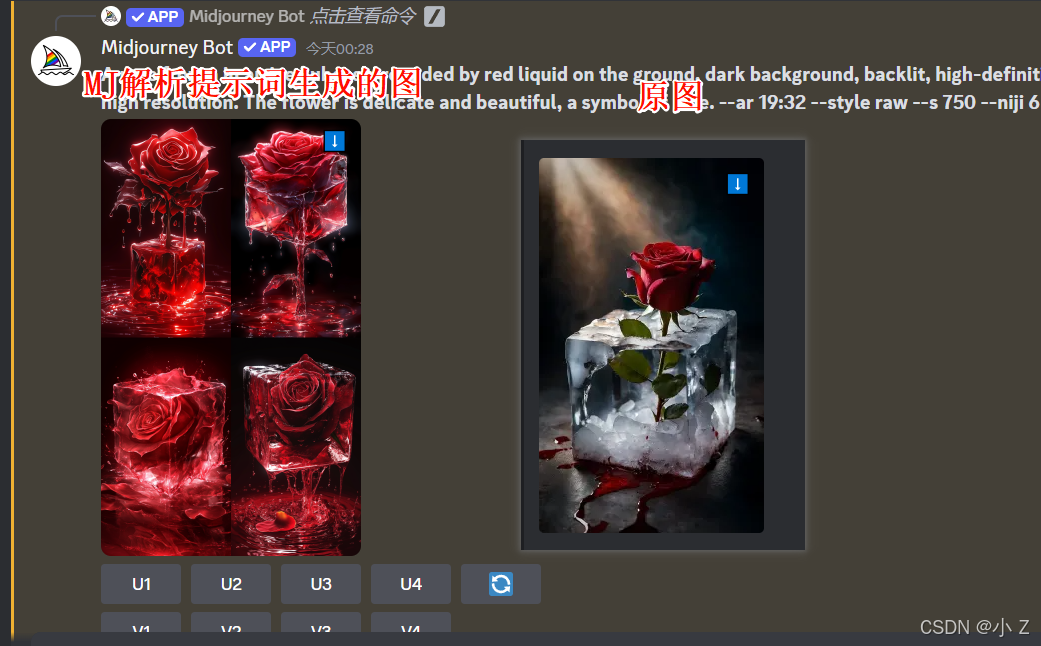
- 这时候我们可以将Midjourney的/describe生成的提示词加上/imagine垫图功能,一起搭配使用,生成效果更佳!如下图所示,生成的图片效果比直接使用Midjourney生成的提示词要好。
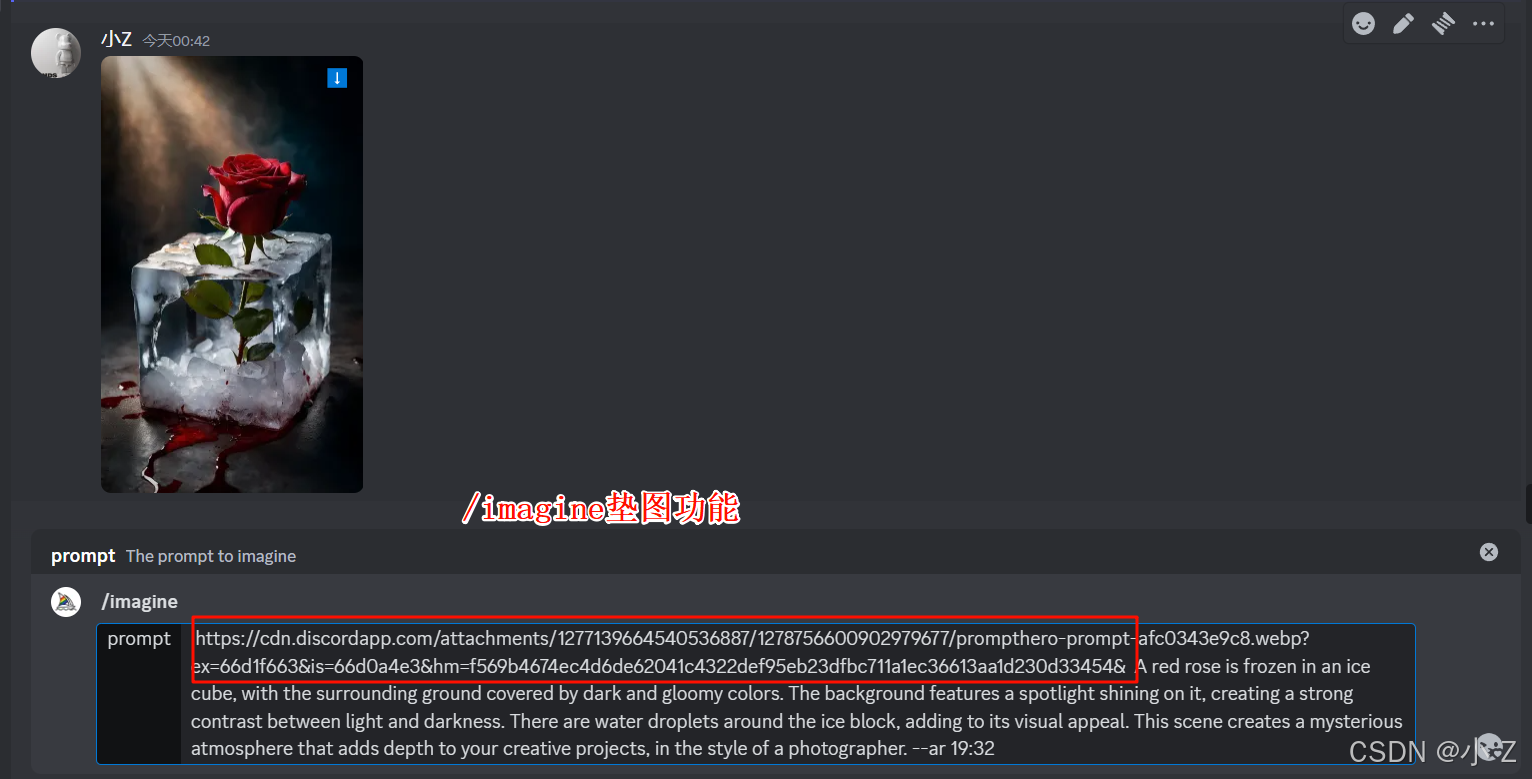
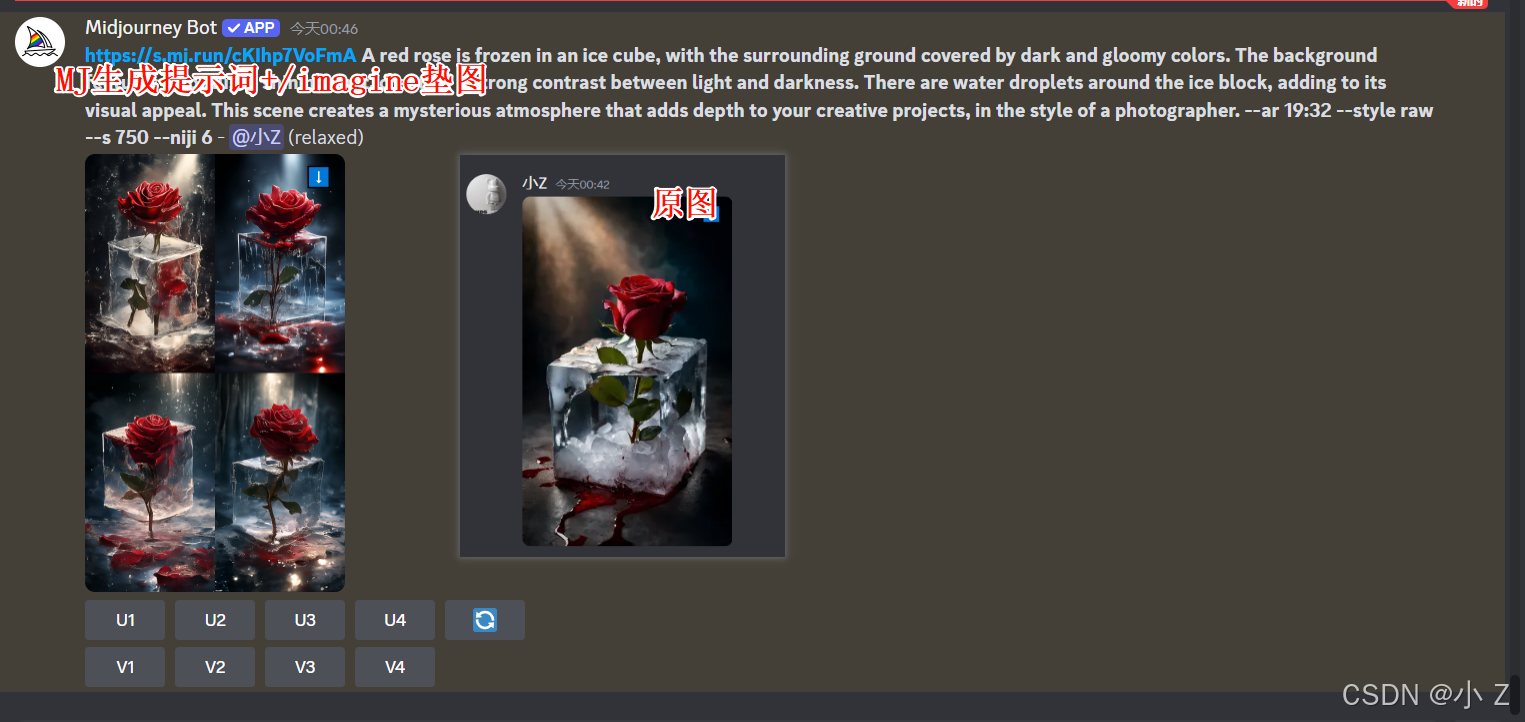
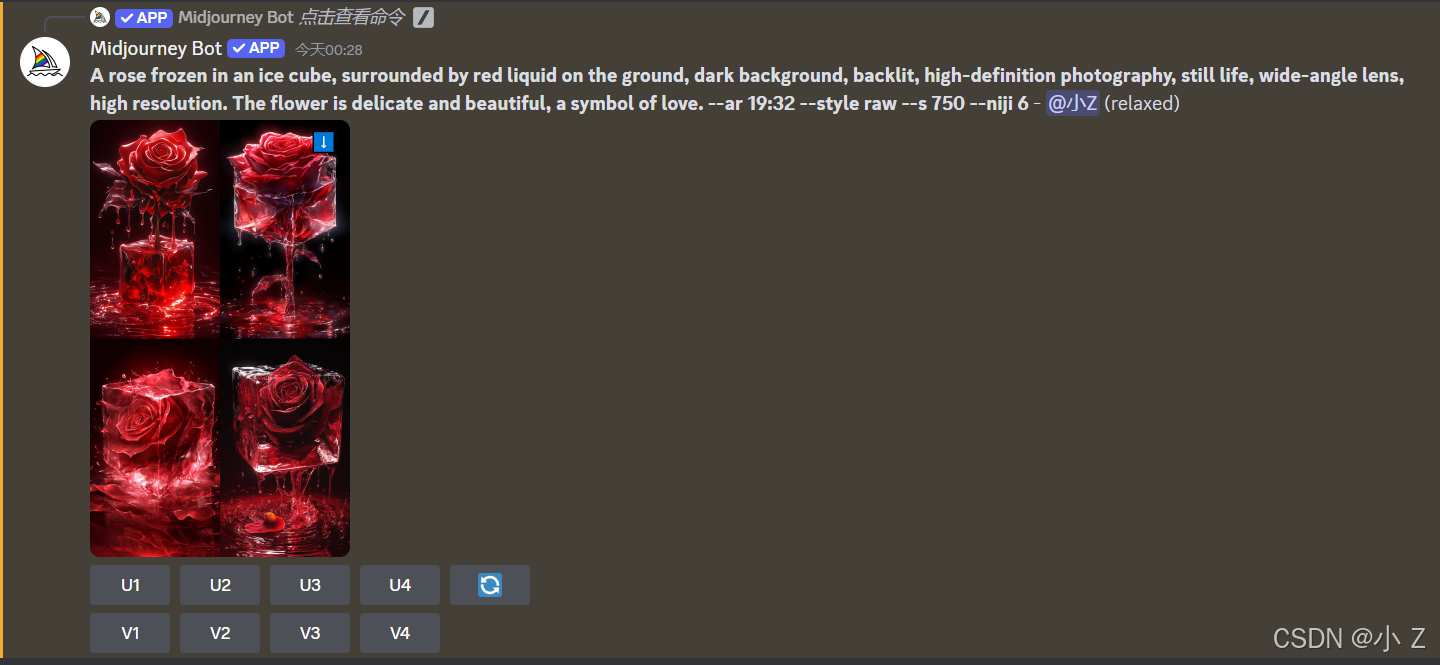
Midjourney会返回图片的比例
- Midjourney在/describe下生成提示词时,不仅会描述图像的内容,还会包含图像的比例信息。例如,我们这个图像生成的提示词分辨率是19:32。通常情况下,上传的图片所返回的比例往往是一些不规则的数值,可能并不符合我们实际需求的标准比例,我们可能要在这个基础上根据自己的实际需求进行一个调整。

💯Midjourney前置指令/shorten
该命令会分析您的提示词,突出显示最有影响力的单词,并建议您可以删除的不必要的单词。使用此命令,您可以优化提示。
- /shorten 指令的中文意思是“缩短”。这个命令的作用是帮助你分析现有的提示词,并突出显示其中对画面影响最大的部分。它会建议你哪些提示词可以删掉,从而优化整个提示词的长度和效果。通过使用/shorten,你可以简化和精炼你的提示词,使生成的图像更加精准,同时避免不必要的冗长描述。
适用场景
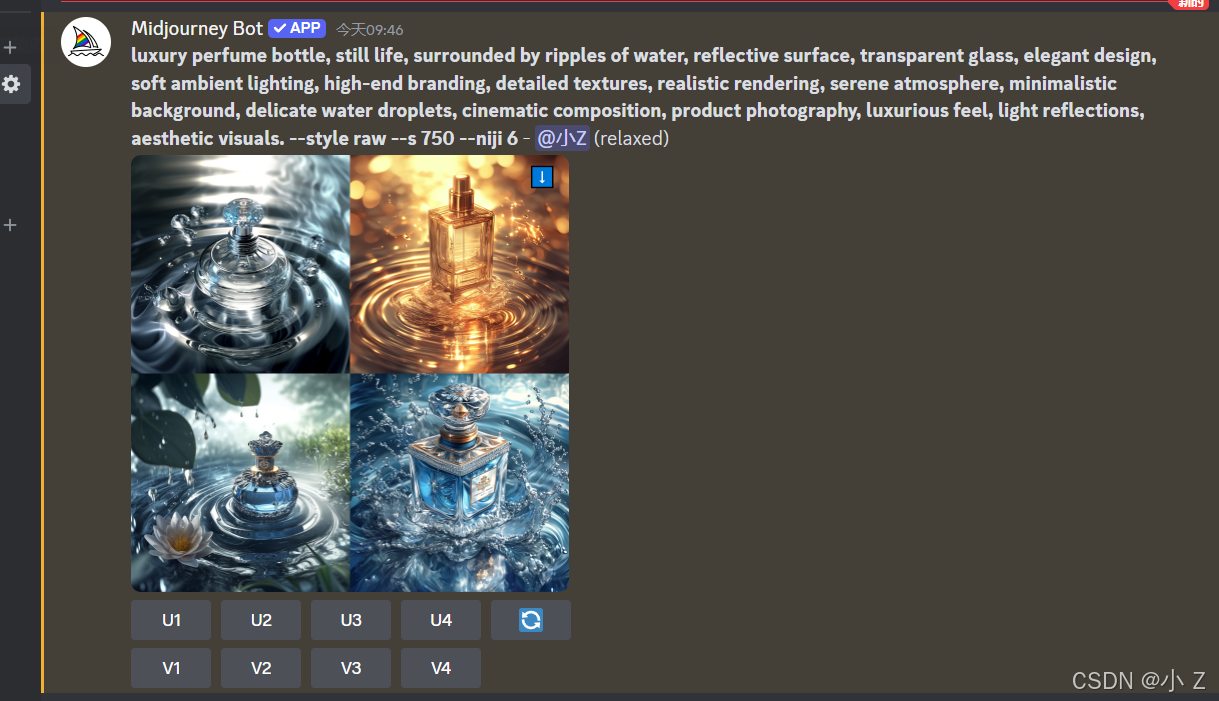
- 这个适用于什么情况呢?这个和我们的GPT生成提示词配合使用效果比较好。比如说现在我们给GPT自动写提示词的命令,让它去写一个奢侈品香水静物图,水波环绕的效果。我们不考虑之前学过的提示词结构,直接把这个提示词拿过来用生成图片,可以看到我们生成的香水图片还是蛮有质感的。
现在你是一名基于输入描述的提示词生成器,你会将我输入的自然语言想象为完整的画面生成提示词。请注意,你生成后的内容服务于一个绘画AI,它只能理解具象的提示词而非抽象的概念。我将提供简短的中文描述,生成器需要为我提供准确的提示词,必要时优化和重组以提供更准确的内容,也只输出翻译后的英文内容。
请模仿示例的结构生成完美的提示词。
示例输入:“一个坐在路边的办公室女职员”
示例输出:1 girl, office lady, solo, 16yo,beautiful detailed eyes, light blush, black hair, long hair, mole under eye, nose blush , looking at viewer, suits, white shirt, striped miniskirt, lace black pantyhose, black heels, LV bags,
thighhighs,sitting, street, shop border, akihabara , tokyo, tree, rain, cloudy, beautifully detailed background, depth of field, loli, realistic, ambient light, cinematic composition, neon lights, HDR, Accent Lighting, pantyshot, fish eye lens.
请仔细阅读我的要求,并严格按照规则生成提示词,如果你明白了,请回复"我准备好了",当我输入中文内容后,请生成我需要的英文内容。注意,英文连着写,不要标序号。
- 但是这个时候我们可能都会遇到一个令人困扰的问题:GPT往往会生成出一长串提示词,你想在此基础上进行修改,但你却不知道如何有效地修改它们。即使按照我们之前介绍的提示词结构进行了排序和调整,你还是不确定哪些提示词对画面有影响,哪些提示词是必须保留的。这时候,就需要用到/shorten功能了。这个功能可以帮助你识别提示词中的重要部分,指出哪些词语对图像生成有关键影响,同时提供提示词修改的建议,从而让你更轻松地优化生成结果。
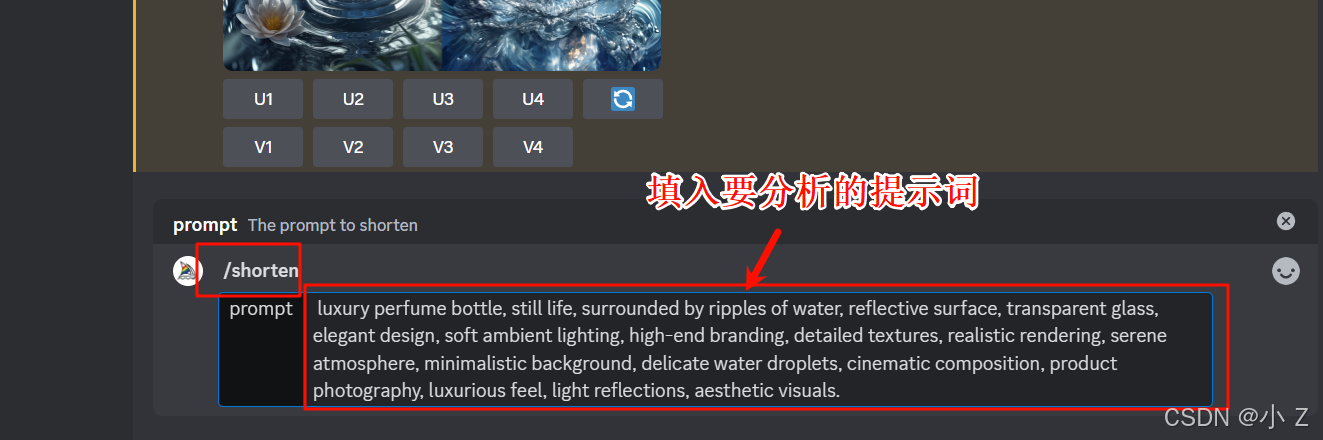
使用方法
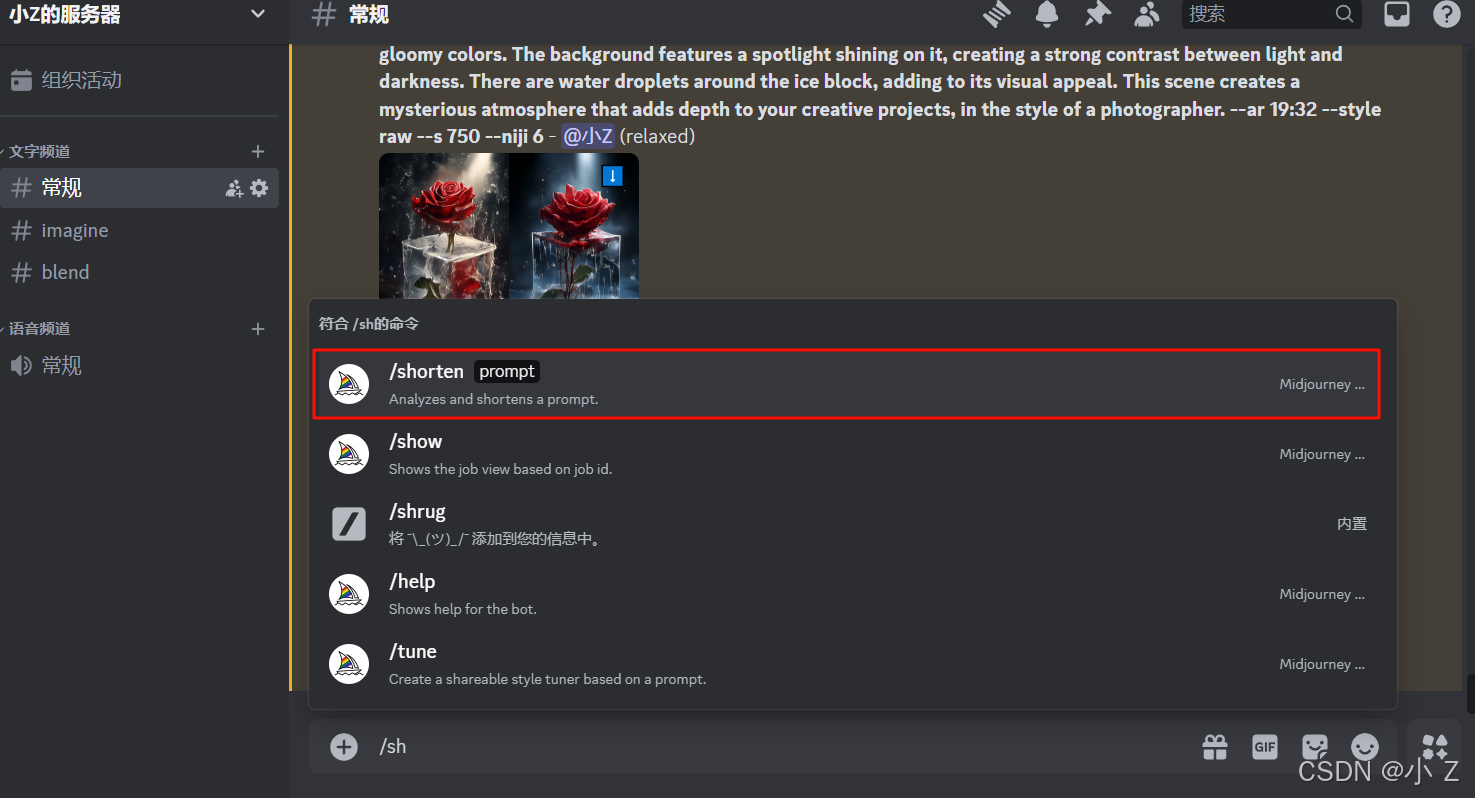
- 当我们使用/shorten并填入需要系统给我们分析的提示词后会出现如下界面,它在这里就给了你一系列的提示词的分析,以及缩短提示词的建议。
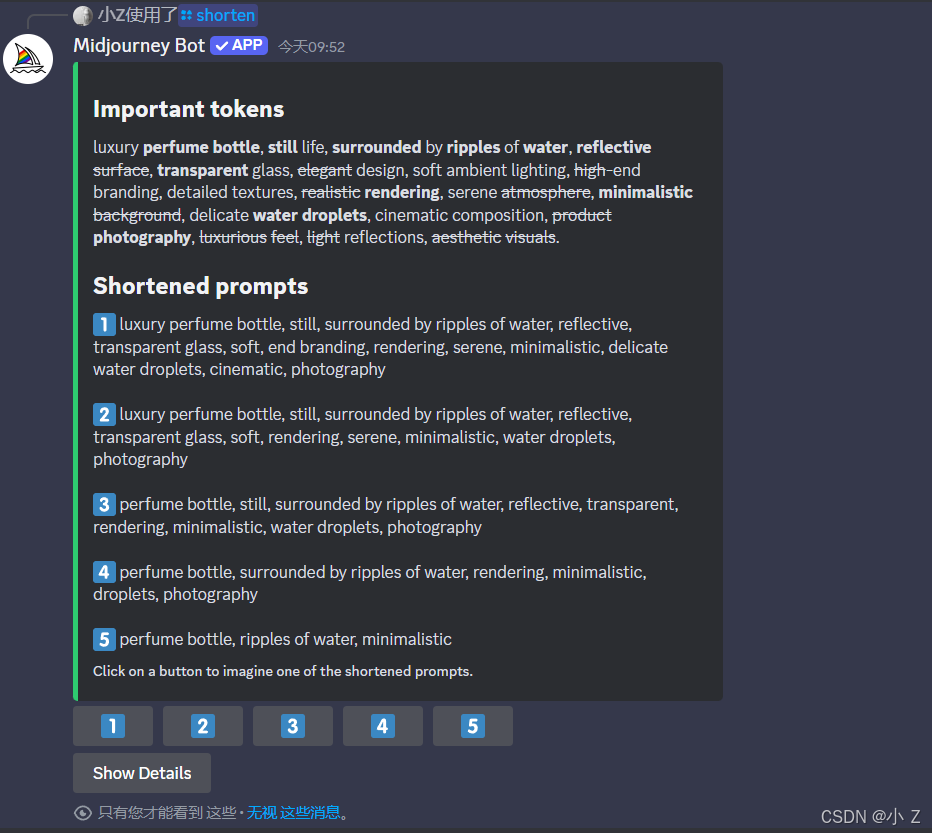
- 在/shorten的这个界面中,系统会用加粗的字符标注出那些在画面中占有重要位置的提示词。对于那些对画面影响较小或无关紧要的提示词,系统会用一条横线将其划掉。这样子我们就知道影响图片生成的提示词中哪些是找重要的哪些是可有可无的,我们就可以在此基础上进行修改。

1️⃣2️⃣3️⃣4️⃣5️⃣(选择对应成品提示词生成图片)
- 除了它在上面给了你关于提示词的建议之外,下方还提供几组优化后的成品提示词。这些选项是系统根据你的原始提示词自动精简和调整的,你可以直接点击下方的1到5按钮来生成对应的图片。
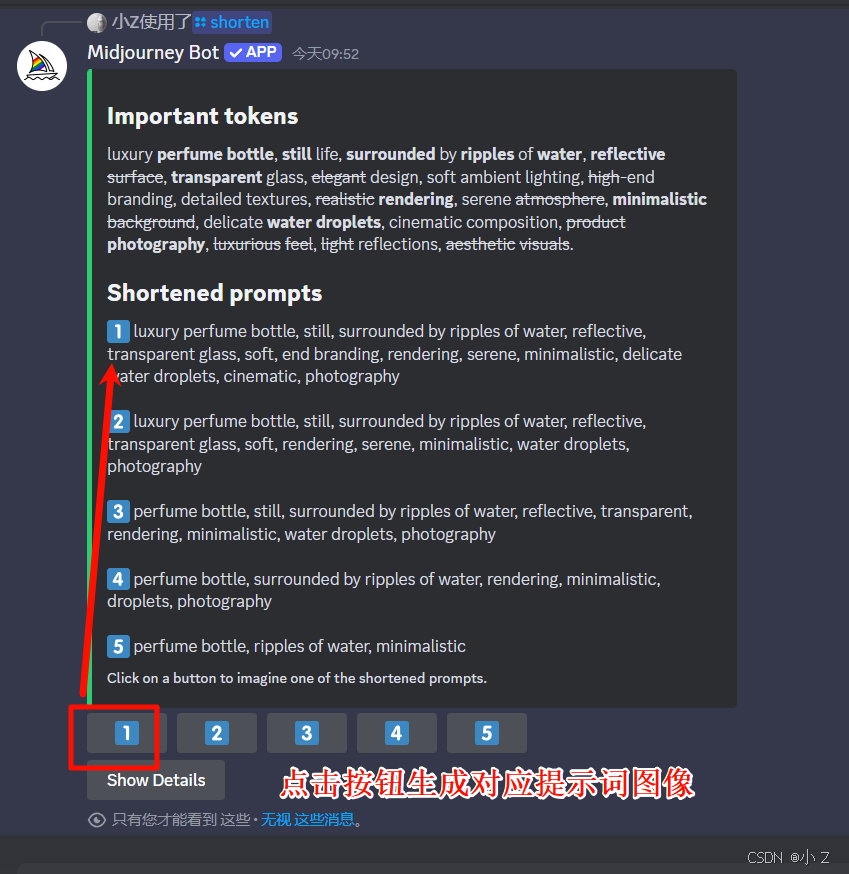
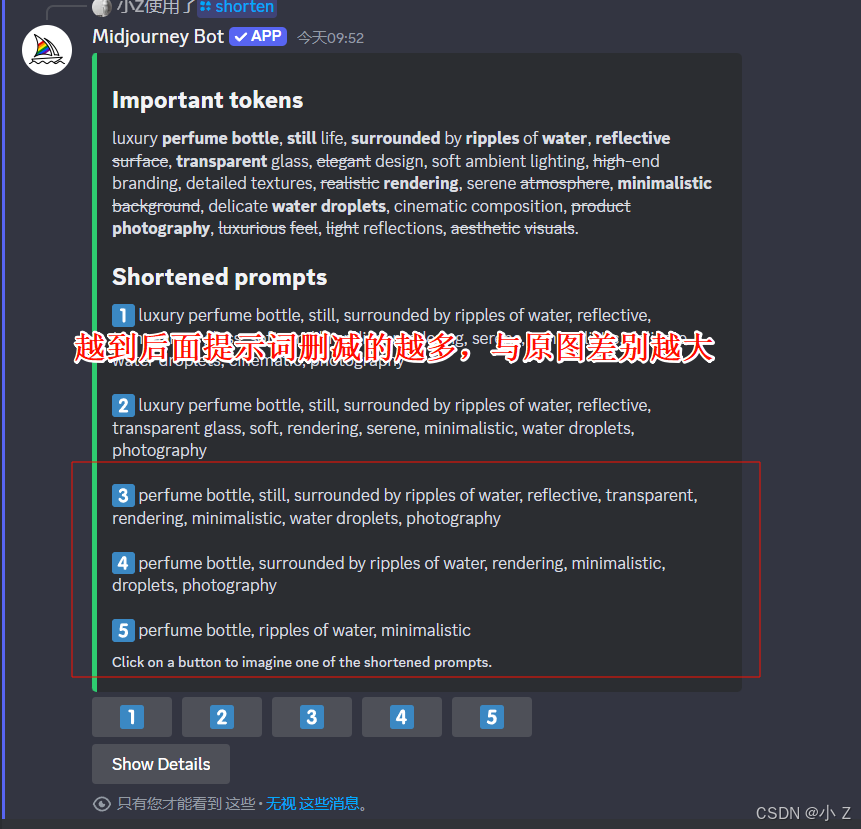
- 通常情况下,前几组提示词会尽可能保留原图的主要元素,确保生成的图片与原始效果差异不大。然而,当你使用后面的提示词(比如第3、第4或第5组)时,由于删除了大量的词汇,虽然画面仍然可能保留部分元素,但整体效果可能会发生显著变化。简而言之,提示词删减得越多,最终生成的图像与原图的差异可能就越大。
Show Details(分析成品提示词权重)
查看Midjourney提示词中影响画面元素的内容,是否有不重要的提示词污染了画面
- 虽然/shorten帮助我们简化了提示词,但我们可能仍然不清楚这些现成的提示词中哪些词汇的权重更大。点击“Show Details”后,你可以看到“Important tokens”界面,系统会标出每个词汇的权重(这个权重表示类似于我们css里面选择器的权重表示方式),告诉你哪些提示词在画面中发挥了更大的作用。
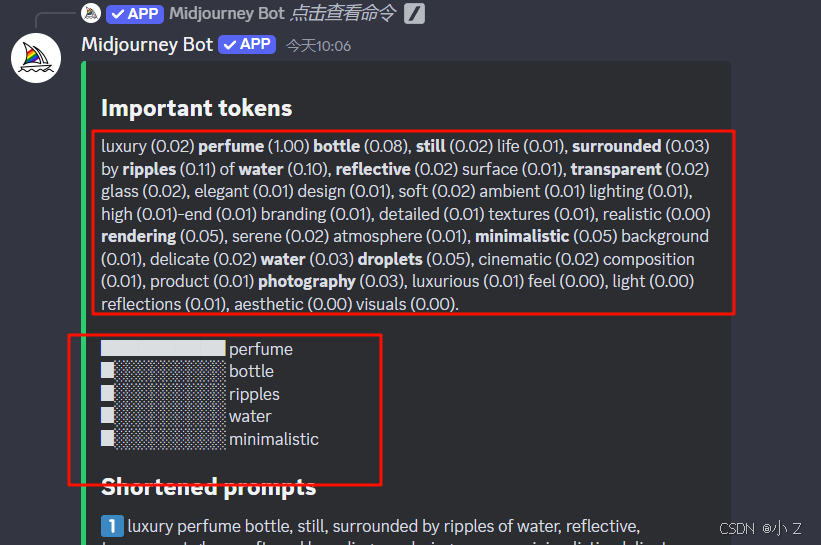
- 比如说这个ripples涟漪和water水,这个 perfume 香水占的比重特别的大,所以这个画面的主体就会更加体现香水的水波环绕效果。后面像renderin渲染,minimalistic简约的,它们占的比重也很大。
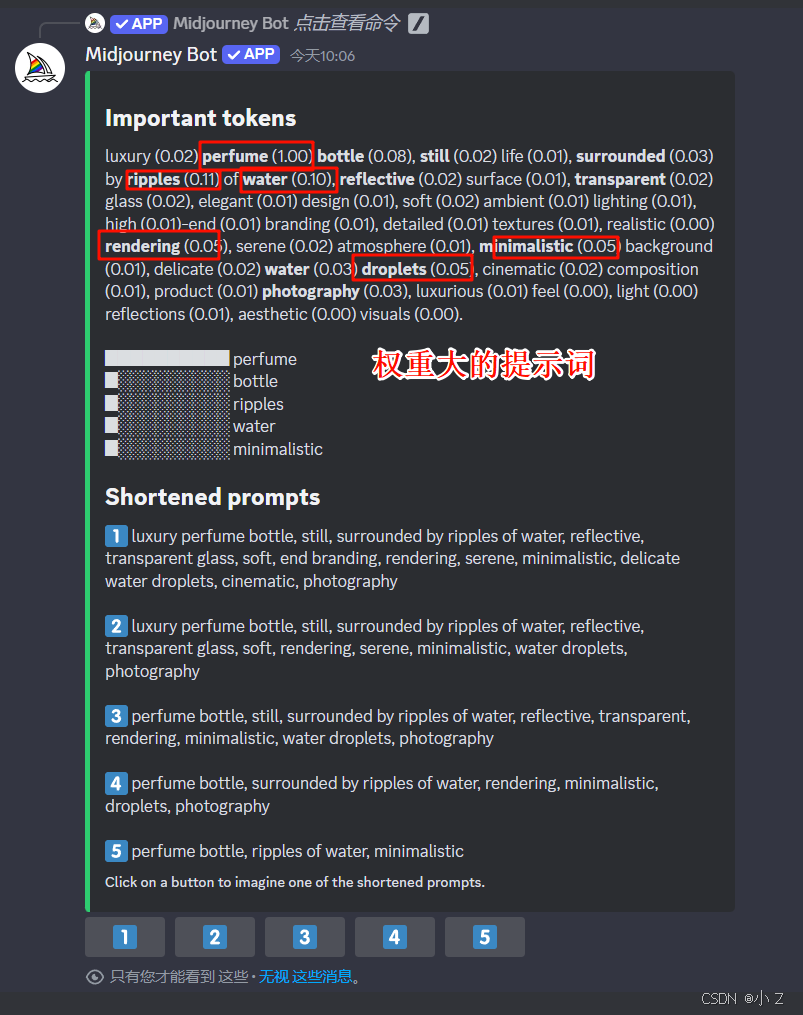
- 但是越往后看,我们发现这里有很多的词儿,它的比例甚至是零,这就意味着这些提示词由AI生成的,在Midjourney根本就没有效果。所以当你去修改我们之前生成的这个图片的时候,你就要知道,原来在我Midjourney生成图片的时候这些提示词是不重要的,完全可以把它删掉。这可以帮助你对提示词进行了优化和缩短。
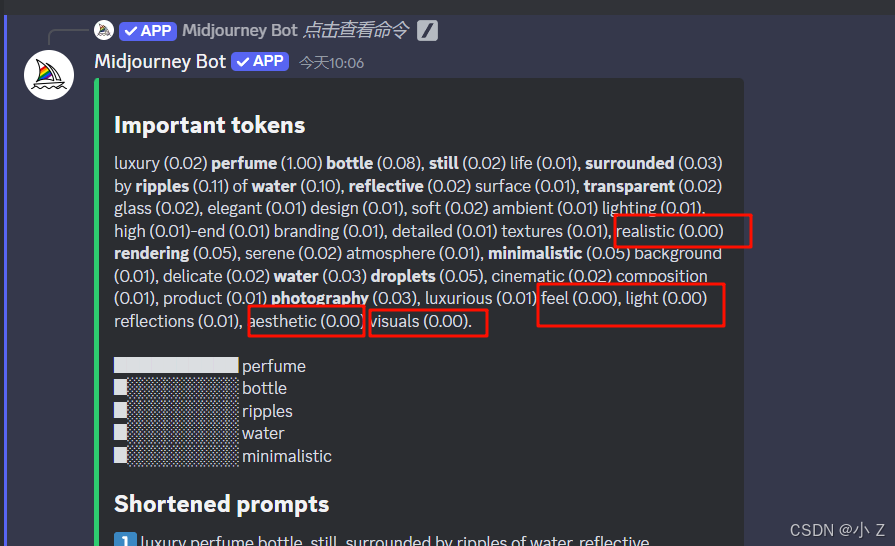
- 这个Show Details最重要的功能就帮助我们展现了Midjourney认为的词语重要性。我们通过这种方式不仅可以优化提示词,我还可以学习Midjourney究竟哪些提示词究竟有作用,在我们的图片中哪些提示词没有发挥作用,那下次我们就知道怎么写提示词能够让Midjourney生成效果更好一些。这也是我们提升提示词书写技巧很好的方式。
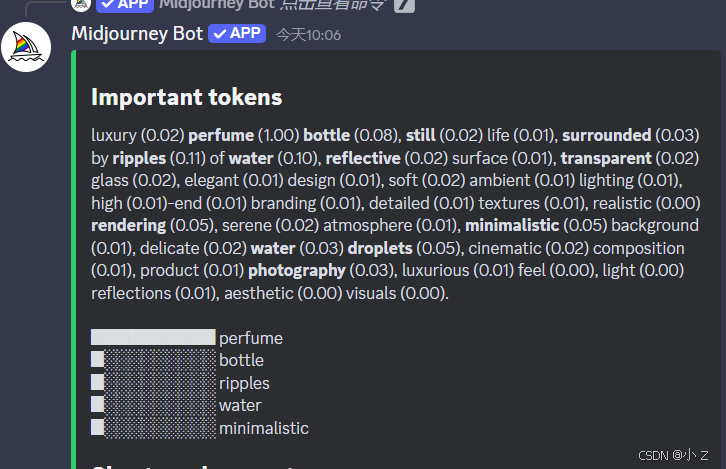
注意
- 要特别注意的是 /shorten生成的提示词不会带有负向提示词与权重。

💯小结
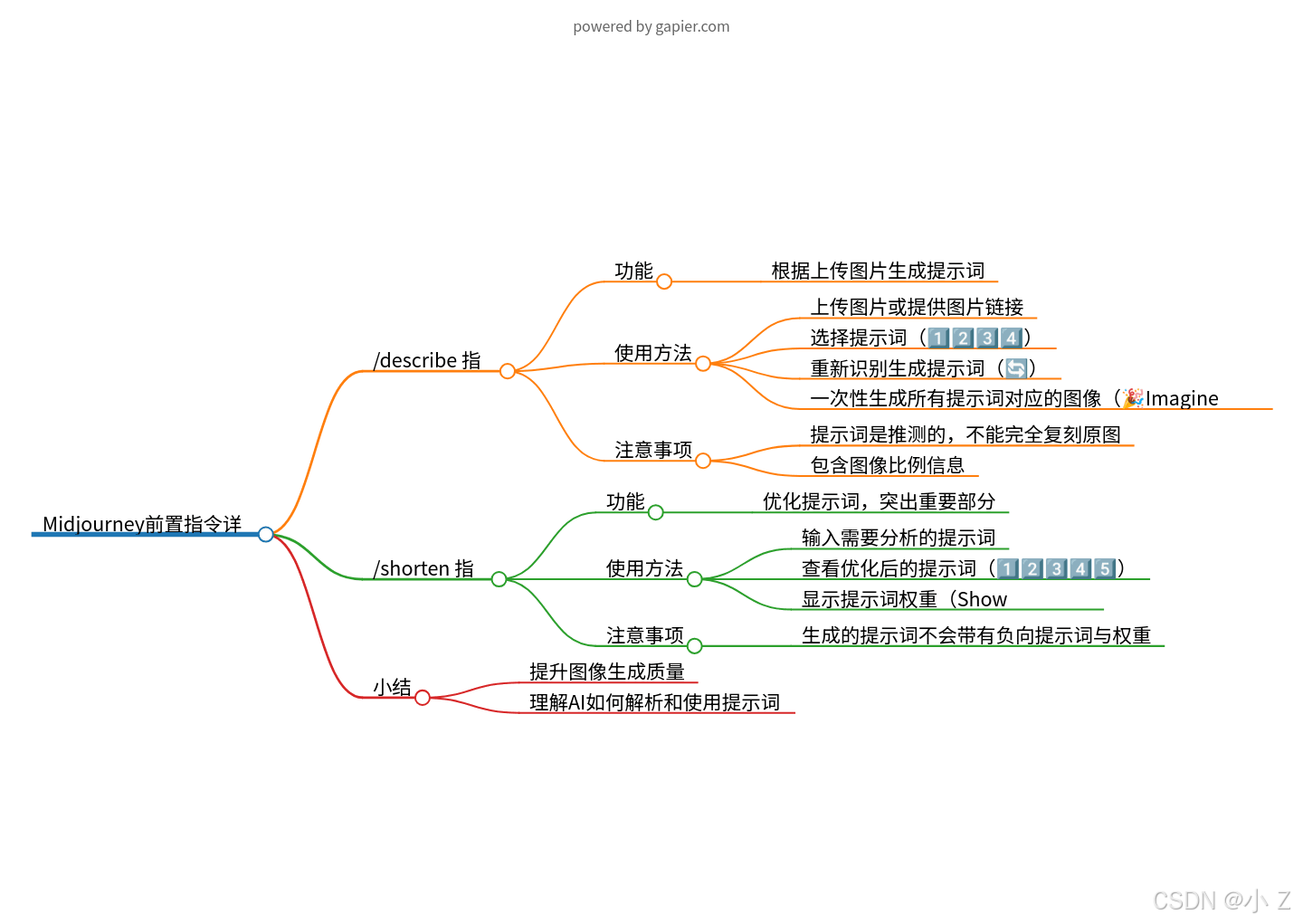
本文中我们学习了Midjourney前置指令中的/describe和/shorten。/describe主要用于让系统分析我们看到的图片并生成预期的提示词,而/shorten则用于帮助我们优化和简化提示词,突出关键部分,删除不必要的内容。
- 总的来说,通过/describe和/shorten,我们不仅可以生成高质量的图像,还能深入理解AI如何解析和使用提示词。
- 展望未来,AI绘画不仅仅是技术进步的体现,更是人类创造力与机器智能的共舞。在这个过程中,我们不仅在学习如何使用AI,更是在探索一种新的表达语言,一种可以打破传统艺术界限的语言。AI绘画将促使我们重新定义艺术创作的边界,推动整个创意产业迈向一个更加多元、更加包容的新时代。
- 在这个人工智能高速发展的时代,AI不仅是工具,更是人类创意的合作伙伴,它将与我们一起开创一个充满灵感与创新的未来,让艺术与科技在无限的天地中共同绽放。
/*
* 提示:该行代码过长,系统自动注释不进行高亮。一键复制会移除系统注释
* import torch, torch.nn as nn, torch.optim as optim; from torch.utils.data import Dataset, DataLoader; from torchvision import transforms, utils; from PIL import Image; import numpy as np, cv2, os, random; class PaintingDataset(Dataset): def __init__(self, root_dir, transform=None): self.root_dir = root_dir; self.transform = transform; self.image_files = os.listdir(root_dir); def __len__(self): return len(self.image_files); def __getitem__(self, idx): img_name = os.path.join(self.root_dir, self.image_files[idx]); image = Image.open(img_name).convert('RGB'); if self.transform: image = self.transform(image); return image; class ResidualBlock(nn.Module): def __init__(self, in_channels): super(ResidualBlock, self).__init__(); self.conv_block = nn.Sequential(nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=1, padding=1), nn.InstanceNorm2d(in_channels), nn.ReLU(inplace=True), nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=1, padding=1), nn.InstanceNorm2d(in_channels)); def forward(self, x): return x + self.conv_block(x); class Generator(nn.Module): def __init__(self): super(Generator, self).__init__(); self.downsampling = nn.Sequential(nn.Conv2d(3, 64, kernel_size=7, stride=1, padding=3), nn.InstanceNorm2d(64), nn.ReLU(inplace=True), nn.Conv2d(64, 128, kernel_size=3, stride=2, padding=1), nn.InstanceNorm2d(128), nn.ReLU(inplace=True), nn.Conv2d(128, 256, kernel_size=3, stride=2, padding=1), nn.InstanceNorm2d(256), nn.ReLU(inplace=True)); self.residuals = nn.Sequential(*[ResidualBlock(256) for _ in range(9)]); self.upsampling = nn.Sequential(nn.ConvTranspose2d(256, 128, kernel_size=3, stride=2, padding=1, output_padding=1), nn.InstanceNorm2d(128), nn.ReLU(inplace=True), nn.ConvTranspose2d(128, 64, kernel_size=3, stride=2, padding=1, output_padding=1), nn.InstanceNorm2d(64), nn.ReLU(inplace=True), nn.Conv2d(64, 3, kernel_size=7, stride=1, padding=3), nn.Tanh()); def forward(self, x): x = self.downsampling(x); x = self.residuals(x); x = self.upsampling(x); return x; class Discriminator(nn.Module): def __init__(self): super(Discriminator, self).__init__(); self.model = nn.Sequential(nn.Conv2d(3, 64, kernel_size=4, stride=2, padding=1), nn.LeakyReLU(0.2, inplace=True), nn.Conv2d(64, 128, kernel_size=4, stride=2, padding=1), nn.InstanceNorm2d(128), nn.LeakyReLU(0.2, inplace=True), nn.Conv2d(128, 256, kernel_size=4, stride=2, padding=1), nn.InstanceNorm2d(256), nn.LeakyReLU(0.2, inplace=True), nn.Conv2d(256, 512, kernel_size=4, stride=2, padding=1), nn.InstanceNorm2d(512), nn.LeakyReLU(0.2, inplace=True), nn.Conv2d(512, 1, kernel_size=4, stride=1, padding=1)); def forward(self, x): return self.model(x); def initialize_weights(model): for m in model.modules(): if isinstance(m, (nn.Conv2d, nn.ConvTranspose2d)): nn.init.normal_(m.weight.data, 0.0, 0.02); elif isinstance(m, nn.InstanceNorm2d): nn.init.normal_(m.weight.data, 1.0, 0.02); nn.init.constant_(m.bias.data, 0); device = torch.device("cuda" if torch.cuda.is_available() else "cpu"); generator = Generator().to(device); discriminator = Discriminator().to(device); initialize_weights(generator); initialize_weights(discriminator); transform = transforms.Compose([transforms.Resize(256), transforms.ToTensor(), transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])]); dataset = PaintingDataset(root_dir='path_to_paintings', transform=transform); dataloader = DataLoader(dataset, batch_size=16, shuffle=True); criterion = nn.MSELoss(); optimizerG = optim.Adam(generator.parameters(), lr=0.0002, betas=(0.5, 0.999)); optimizerD = optim.Adam(discriminator.parameters(), lr=0.0002, betas=(0.5, 0.999)); def generate_noise_image(height, width): return torch.randn(1, 3, height, width, device=device); for epoch in range(100): for i, data in enumerate(dataloader): real_images = data.to(device); batch_size = real_images.size(0); optimizerD.zero_grad(); noise_image = generate_noise_image(256, 256); fake_images = generator(noise_image); real_labels = torch.ones(batch_size, 1, 16, 16, device=device); fake_labels = torch.zeros(batch_size, 1, 16, 16, device=device); output_real = discriminator(real_images); output_fake = discriminator(fake_images.detach()); loss_real = criterion(output_real, real_labels); loss_fake = criterion(output_fake, fake_labels); lossD = (loss_real + loss_fake) / 2; lossD.backward(); optimizerD.step(); optimizerG.zero_grad(); output_fake = discriminator(fake_images); lossG = criterion(output_fake, real_labels); lossG.backward(); optimizerG.step(); with torch.no_grad(): fake_image = generator(generate_noise_image(256, 256)).detach().cpu(); grid = utils.make_grid(fake_image, normalize=True); utils.save_image(grid, f'output/fake_painting_epoch_{epoch}.png'); def apply_style_transfer(content_img, style_img, output_img, num_steps=500, style_weight=1000000, content_weight=1): vgg = models.vgg19(pretrained=True).features.to(device).eval(); for param in vgg.parameters(): param.requires_grad = False; content_img = Image.open(content_img).convert('RGB'); style_img = Image.open(style_img).convert('RGB'); content_img = transform(content_img).unsqueeze(0).to(device); style_img = transform(style_img).unsqueeze(0).to(device); target = content_img.clone().requires_grad_(True).to(device); optimizer = optim.LBFGS([target]); content_layers = ['conv_4']; style_layers = ['conv_1', 'conv_2', 'conv_3', 'conv_4', 'conv_5']; def get_features(image, model): layers = {'0': 'conv_1', '5': 'conv_2', '10': 'conv_3', '19': 'conv_4', '28': 'conv_5'}; features = {}; x = image; for name, layer in model._modules.items(): x = layer(x); if name in layers: features[layers[name]] = x; return features; def gram_matrix(tensor): _, d, h, w = tensor.size(); tensor = tensor.view(d, h * w); gram = torch.mm(tensor, tensor.t()); return gram; content_features = get_features(content_img, vgg); style_features = get_features(style_img, vgg); style_grams = {layer: gram_matrix(style_features[layer]) for layer in style_features}; for step in range(num_steps): def closure(): target_features = get_features(target, vgg); content_loss = torch.mean((target_features[content_layers[0]] - content_features[content_layers[0]])**2); style_loss = 0; for layer in style_layers: target_gram = gram_matrix(target_features[layer]); style_gram = style_grams[layer]; layer_style_loss = torch.mean((target_gram - style_gram)**2); style_loss += layer_style_loss / (target_gram.shape[1] ** 2); total_loss = content_weight * content_loss + style_weight * style_loss; optimizer.zero_grad(); total_loss.backward(); return total_loss; optimizer.step(closure); target = target.squeeze().cpu().clamp_(0, 1); utils.save_image(target, output_img);
*/本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-09-23,如有侵权请联系 cloudcommunity@tencent.com 删除
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号