Linux进阶命令-awk&uniq


作者介绍:简历上没有一个精通的运维工程师。请点击上方的蓝色《运维小路》关注我,下面的思维导图也是预计更新的内容和当前进度(不定时更新)。
经过上一章Linux日志的讲解,我们对Linux系统自带的日志服务已经有了一些了解。我们接下来将讲解一些进阶命令,主要从以下几个方面来讲解:一些系统操作,系统查看处理,Linux文本处理,逻辑判断,重定向,网络传输,服务启动,文件句柄等内容。通过这些操作,让你对Linux的操作更加得心应手,具体分成以下章节进行讲解:
Linux进阶命令-echo&date&alias
Linux进阶命令-top
Linux进阶命令-ps&kill
Linux进阶命令-sort&wc
Linux进阶命令-sed&split
Linux进阶命令-awk&uniq(本章节)
Linux进阶命令-逻辑或&逻辑与
Linux进阶命令-重定向
Linux进阶命令-scp
Linux进阶命令-rsync
Linux进阶命令-rsync-daemon
Linux进阶命令-nohup&screen
Linux进阶命令-lsof
Linux进阶命令-小结
shell的三剑客我们前面已经讲过了grep和sed,今天我们讲awk。无论是grep 还是sed 相对都比较简单,awk可以简单,也可以复杂,复杂它可以算一门编程语言,甚至有多本图书来介绍这个命令。当然我们这里只介绍常规的操作,或者说我最常用的方法。
awk 是一种强大的文本处理工具,可以用于对文本文件中的数据和文本进行扫描和处理。它特别适合于处理结构化的文本数据,支持灵活的文本模式匹配、字段分割、条件语句和循环等功能。awk 常用于命令行环境下,可以作为一个完整的编程语言来处理数据。
awk
基本语法
awk 'pattern { action }' filepattern:模式或条件,用于选择匹配的行。{ action }:动作块,对符合模式的行执行的操作。file:要处理的文件名。
基本工作流程
awk逐行读取文件或标准输入。- 对于每一行,检查是否匹配指定的模式。
- 如果匹配,则执行定义的动作块。
常用操作
打印操作:
awk '{ print $1 }' file.txt这会打印文件 file.txt 的每一行的第一个字段。
自定义分隔符和字段操作:
awk -F',' '{ print $2 }' data.csv这会使用逗号作为分隔符,打印文件 data.csv 的每行的第二个字段。
循环和逻辑控制:
awk '{ for (i=1; i<=NF; i++) if ($i ~ /pattern/) print $i }' file.txt这会逐行遍历文件 file.txt,并打印每行中包含 pattern 的字段。
示例
打印文件 students.txt 的每一行:
awk '{ print }' students.txt计算文件 grades.txt 中第二列的平均值:
awk '{ sum += \$2 } END { print "Average:", sum/NR }' grades.txt打印文件 sales.csv 中包含日期 2023-01-01 的行:
awk '/2023-01-01/ { print }' sales.csv使用场景
- 数据提取和报告生成: 从结构化文件中提取特定字段或行,并生成报告。
- 数据转换和清洗: 根据特定规则或条件对数据进行转换和清理。
- 日志分析和过滤: 在日志文件中查找特定模式或条件,并分析相关数据。
- 批量处理: 对大量数据进行统计、分析或格式化处理。
uniq
uniq 是一个用于处理文本文件的命令行工具,主要功能是去除重复的行。它通常与 sort 命令一起使用,因为 uniq 只能去除相邻的重复行。
基本用法
uniq [选项] [输入文件] [输出文件]常用选项
-c:在输出行前面加上每行出现的次数。-d:仅显示重复出现的行。-u:仅显示不重复的行。-i:忽略大小写差异。-w N:仅比较前 N 个字符来判断重复。
示例
去除重复行并保留唯一行:
sort file.txt | uniq这个命令首先对 file.txt 进行排序,然后 uniq 去除重复行。
显示每行出现的次数:
sort file.txt | uniq -c仅显示重复的行:
sort file.txt | uniq -d这个命令会显示在 file.txt 中重复出现的行。
忽略大小写的重复:
sort -f file.txt | uniq -i这个命令会忽略大小写,并去除重复行。
总结
- 其实还有个cut命令也能实现部分awk的切割功能,只是它分割符要求比较严格,我都是学Linux的时候学习过这个命令,工作中没用过。
- 一般总结这些命令会组合起来用,主要用于分析web服务器的访问日志。
#统计访问者ip数量
cat access.log |awk '{print $1}' |sort |uniq |wc -l
#统计访问量最大的10个ip地址
#检查攻击痕迹
cat access.log |awk '{print $1}' |sort |uniq -c|head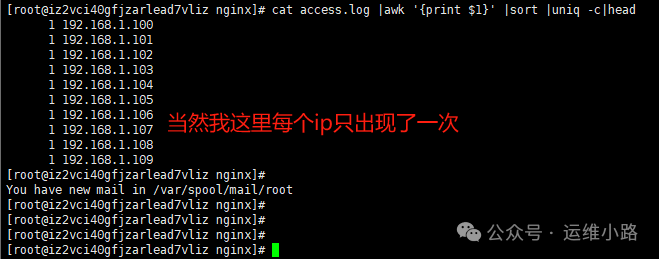
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-08-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号