【数据处理包Pandas】数据载入与预处理
【数据处理包Pandas】数据载入与预处理

目录
- 一、数据载入
- 二、数据清洗
- (一)Pandas中缺失值的表示
- (二)与缺失值判断和处理相关的方法
- 三、连续特征离散化
- 四、哑变量处理
准备工作
导入 NumPy 库和 Pandas 库。
import numpy as np
import pandas as pd一、数据载入
对于数据分析而言,数据大部分来源于外部数据,如常用的 CSV 文件、 Excel 文件和数据库文件等。 Pandas 库将外部数据转换为 DataFrame 数据格式,处理完成后再存储到相应的外部文件中。
1、读 / 写文本文件
文本文件是一种由若干行字符构成的计算机文件,它是一种典型的顺序文件。
txt 文件:是 Windows 操作系统上附带的一种文本格式,文件以 .txt 为后缀。
Pandas 中使用read_table来读取文本文件:
pd.read_table(filepath_or_buffer, sep=’\t’, header=’infer’, names=None, index_col=None, dtype=None, engine=None, nrows=None)
2、读 / 写 CSV 文件
CSV 文件:是 Comma-Separated Values 的缩写,用半角逗号(’ ,’ )作为字段值的分隔符。
Pandas 中使用read_csv函数来读取 CSV 文件:
pd.read_csv(filepath_or_buffer, sep=’,’, header=’infer’, names=None, index_col=None, dtype=None, engine=None, nrows=None)
read_table和read_csv常用参数及其说明:
参数名称 | 说明 |
|---|---|
filepath | 接收string,代表文件路径,无默认 |
sep | 接收string,代表分隔符。read_csv默认为 “,”,read_table默认为制表符 “\t”,如果分隔符指定错误,在读取数据的时候,每一行数据将连成一片 |
header | 接收int或sequence,表示将某行数据作为列名,默认为infer,表示自动识别 |
names | 接收array,表示列名,默认为None |
index_col | 接收int、sequence或False,表示索引列的位置,取值为sequence则代表多重索引,默认为None |
dtype | 接收dict,代表写入的数据类型(列名为key,数据格式为values),默认为None |
engine | 接收c或者python,代表数据解析引擎,默认为c |
nrows | 接收int,表示读取前n行,默认为None |
文本文件的存储和读取类似,结构化数据可以通过 Pandas 中的to_csv函数实现以 CSV 文件格式存储文件。
DataFrame.to_csv(path_or_buf = None, sep = ’,’, na_rep, columns=None, header=True, index=True, index_label=None, mode=’w’, encoding=None)
3、读 / 写 Excel 文件
Pandas 提供了read_excel函数读取 “xls” 和 “xlsx” 两种 excel 文件,其格式为:
pd.read_excel(io, sheetname, header=0, index_col=None, names=None, dtype)
read_excel函数和read_table函数的部分参数相同。
read_excel常用参数及其说明:
参数名称 | 说明 |
|---|---|
io | 接收string,表示文件路径,无默认 |
sheetname | 接收string、int,代表excel表内数据的分表位置,默认为0 |
header | 接收int或sequence,表示将某行数据作为列名,默认为infer,表示自动识别 |
names | 接收int、sequence或者False,表示索引列的位置,取值为sequence则代表多重索引,默认为None |
index_col | 接收int、sequence或者False,表示索引列的位置,取值为sequence则代表多重索引,默认为None |
dtype | 接收dict,代表写入的数据类型(列名为key,数据格式为values),默认为None |
将文件存储为 Excel 文件,可使用to_excel方法。其语法格式如下:
DataFrame.to_excel(excel_writer=None, sheetname=None’, na_rep=”, header=True, index=True, index_label=None, mode=’w’, encoding=None)
与to_csv方法的常用参数基本一致,区别之处在于指定存储文件的文件路径参数excel_writer,增加了一个sheetnames参数,用来指定存储的 Excel sheet 的名称,默认为 sheet1 。
# 读取excel文件:
df_excel = pd.read_excel('员工表.xlsx')
df.head()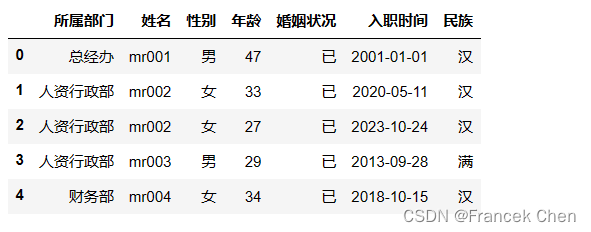
数据集员工表.xlsx下载地址: 链接:https://pan.quark.cn/s/6a0f78a28256 提取码:2yek
二、数据清洗
(一)Pandas中缺失值的表示
Pandas 表示缺失值的一种方法是使用NaN(Not a Number),它是一个特殊的浮点数;另一种是使用 Python 中的None,Pandas 会自动把None转变成NaN。
data = pd.Series([1, np.nan, 'hello', None])
data0 1
1 NaN
2 hello
3 None
dtype: object(二)与缺失值判断和处理相关的方法
isnull():判断每个元素是否是缺失值,会返回一个与原对象尺寸相同的布尔性 Pandas 对象notnull():与isnull()相反dropna():返回一个删除缺失值后的数据对象fillna():返回一个填充了缺失值之后的数据对象
1、缺失值判断
data.isnull()0 False
1 True
2 False
3 True
dtype: bool判断缺失值的个数:
data.isnull().sum()2用布尔数组进行检索:
data[data.notnull()]0 1
2 hello
dtype: object2、删除缺失值
df = pd.DataFrame([[1, np.nan, 2],
[2, 3, 5],
[np.nan, 4, 6]])
df.isnull().sum().sum() # 统计缺失值的个数2在缺失值的处理方法中,删除缺失值是常用的方法之一。通过dropna方法可以删除具有缺失值的行。
dropna方法的格式:
dropna(axis=0, how=‘any’, thresh=None, subset=None, inplace=False)
dropna的参数及其使用说明:
参数说明 | 使用说明 |
|---|---|
axis | 默认为axis=0,当某行出现缺失值时,将该行丢弃并返回,当axis=1,当某列出现缺失值时,将该列丢弃 |
how | 表示删除的形式。any表示只要有缺失值存在就执行删除操作。all表示当且仅当全部为缺失值时执行删除操作。默认为any。 |
thresh | 阈值设定,当行列中非空值的数量少于给定的值就将该行丢弃 |
subset | 表示进行去重的列/行,如:subset=[ ’a’ ,’d’],即丢弃子列 a d 中含有缺失值的行 |
inplace | bool取值,默认False,当inplace=True,即对原数据操作,无返回值 |
dropna默认删除任何包含缺失值的整行数据。
df.dropna()
使用axis=1或axis='columns'删除任何包含缺失值的整列数据。
df.dropna(axis='columns')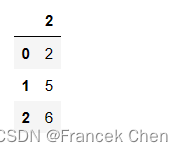
更精确的缩小删除范围,需要使用how或thresh(阈值)参数。
df[3] = np.nan
df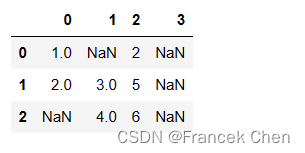
只有全为空值的列才会被删除。
df.dropna(axis='columns', how='all')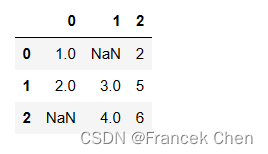
通过thresh参数,那些非缺失值的个数大于等于阈值的行或列将保留。
df.dropna(axis='rows', thresh=3)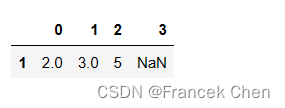
3、填充缺失值
缺失值所在的特征为数值型时,通常利用其均值、中位数和众数等描述其集中趋势的统计量来填充;缺失值所在特征为类别型数据时,则选择众数来填充。
Pandas 库中提供了缺失值替换的方法fillna,格式如下:
DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None)
fillna参数说明:
参数名称 | 参数说明 |
|---|---|
value | 用于填充缺失值的标量值或字典对象 |
method | 插值方式 |
axis | 待填充的轴,默认 axis=0 |
inplace | 修改调用者对象而不产生副本 |
limit | (对于前向和后向填充)可以连续填充的最大数量 |
(1)用单个值填充
df.fillna(0)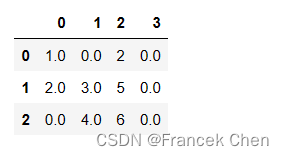
(2)从前向后填充(forward-fill)
df.fillna(method='ffill')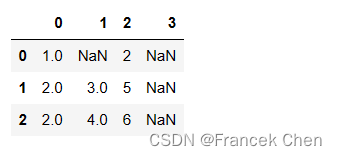
(3)从后向前填充(back-fill)
df.fillna(method='bfill')
上面填充的方向默认是axis=0,即垂直方向填充;如果希望水平方向填充,需要设置axis=1。
df.fillna(method='bfill',axis=1)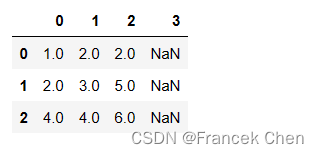
(4)插值法填充
下面的示例:线性插值、沿着水平方向从前向后填充
df.interpolate(method='linear', limit_direction='forward', axis=1)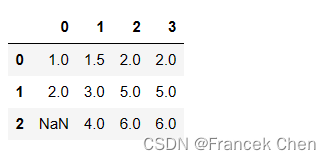
上面的方法都不是原地修改原对象,如果需要原地修改,则需要设置inplace=True。
print(df)
df.interpolate(method='linear', limit_direction='forward', axis=1,inplace=True)
df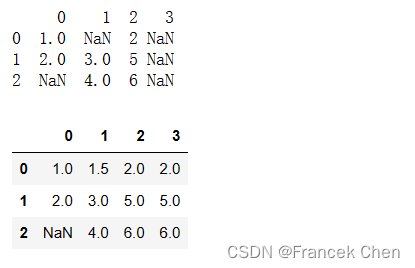
4、处理重复数据
在 DataFrame 中利用duplicates方法判断各行是否有重复数据。duplicates方法返回一个布尔值的 series ,反映每一行是否与之前的行重复。
duplicates格式为:
DataFrame.duplicated(subset=None, keep='first')
subset:可选参数,用于指定要检查重复值的列名或列名列表。默认为 None,表示检查所有列。keep:可选参数,指定如何处理重复值。可选值为 ‘first’、‘last’ 和 False。默认为 ‘first’,表示将第一个出现的重复值标记为 True,后续出现的标记为 False;‘last’ 表示将最后一个出现的标记为 True,前面出现的标记为 False;False 表示标记所有重复值为 True。
# 识别重复值——duplicated()、删除重复值——drop_duplicates()
df2 = pd.DataFrame({
'brand': ['Yum Yum', 'Yum Yum', 'Indomie', 'Indomie', 'Indomie'],
'style': ['cup', 'cup', 'cup', 'pack', 'pack'],
'rating': [4, 4, 3.5, 15, 5]
})
df2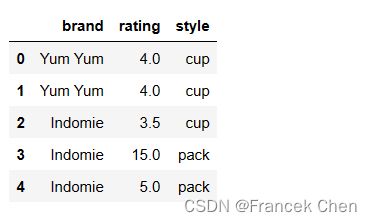
df2.duplicated()
df2.duplicated(keep=False)
# 只查看sytle列上的重复项
# 除第一个重复项外,其他重复项均标记为True
df2.duplicated('style') 
Pandas 通过drop_duplicates删除重复的行,格式为:
DataFrame.drop_duplicates(subset=None, keep='first', inplace=False, ignore_index=False)
subset:可选参数,用于指定要检查重复值的列名或列名列表。默认为 None,表示检查所有列。keep:可选参数,指定如何处理重复值。可选值为 ‘first’、‘last’ 和 False。默认为 ‘first’,表示保留第一个出现的重复值;‘last’ 表示保留最后一个出现的重复值;False 表示删除所有重复值。inplace:可选参数,指定是否在原地修改 DataFrame。默认为 False,表示返回一个新的 DataFrame;如果设为 True,则在原 DataFrame 上进行操作,并返回 None。ignore_index:可选参数,指定是否重新设置索引。默认为 False,表示保留原索引;如果设为 True,则在删除重复值后重新设置索引。
df2.drop_duplicates(inplace=True)
df2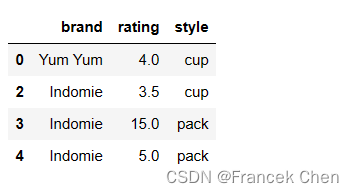
# 只删除brand列上的重复项
df2.drop_duplicates(['brand'],inplace=True)
df2
详情参考:https://www.gairuo.com/p/pandas-duplicated
三、连续特征离散化
series = pd.Series([1, 6, 7, 8, 9, 15])
series1 = pd.cut(series, bins=3)
print('离散化前的数据为:\n', series, '\n', '等宽离散化后的数据为:\n', series1)
print('离散化后各区间数据数目为:\n', series1.value_counts())离散化前的数据为:
0 1
1 6
2 7
3 8
4 9
5 15
dtype: int64
等宽离散化后的数据为:
0 (0.986, 5.667]
1 (5.667, 10.333]
2 (5.667, 10.333]
3 (5.667, 10.333]
4 (5.667, 10.333]
5 (10.333, 15.0]
dtype: category
Categories (3, interval[float64]): [(0.986, 5.667] < (5.667, 10.333] < (10.333, 15.0]]
离散化后各区间数据数目为:
(5.667, 10.333] 4
(10.333, 15.0] 1
(0.986, 5.667] 1
dtype: int64def SameRateCut(data, k):
w = data.quantile(np.arange(
0, 1 + 1.0 / k, 1.0 / k))
data = pd.cut(data, w)
return data
series1 = SameRateCut(series, 3)
print('等频离散化后数据为:\n', series1, '\n',
'离散化后数据各区间数目为:\n', series1.value_counts())等频离散化后数据为:
0 NaN
1 (1.0, 6.667]
2 (6.667, 8.333]
3 (6.667, 8.333]
4 (8.333, 15.0]
5 (8.333, 15.0]
dtype: category
Categories (3, interval[float64]): [(1.0, 6.667] < (6.667, 8.333] < (8.333, 15.0]]
离散化后数据各区间数目为:
(8.333, 15.0] 2
(6.667, 8.333] 2
(1.0, 6.667] 1
dtype: int64四、哑变量处理
dit = {'one': ['高', '低', '低', '高', '中'],
'two': [1, 4, 6, 7, 8]}
df = pd.DataFrame(dit)
print('创建的DataFrame为:\n', df)
print('哑变量处理后的DataFrame为:\n', pd.get_dummies(df)) #又称为独热编码创建的DataFrame为:
one two
0 高 1
1 低 4
2 低 6
3 高 7
4 中 8
哑变量处理后的DataFrame为:
two one_中 one_低 one_高
0 1 0 0 1
1 4 0 1 0
2 6 0 1 0
3 7 0 0 1
4 8 1 0 0腾讯云开发者
