【数据处理包Pandas】DataFrame数据的基本操作

【数据处理包Pandas】DataFrame数据的基本操作

Francek Chen
发布于 2025-01-22 20:57:27
发布于 2025-01-22 20:57:27
一、DataFrame数据的查询
首先,导入 NumPy 和 Pandas 库。
import numpy as np
import pandas as pd设置数据显示的编码格式为东亚宽度,以使列对齐。
pd.set_option('display.unicode.east_asian_width', True)
data = [[110,105,99],[105,88,115],[109,120,130],[112,115]]
name = ['甲','乙','丙','丁']
columns = ['语文','数学','英语']
df = pd.DataFrame(data=data, index=name, columns=columns)
print(df)输出结果:
语文 数学 英语
甲 110 105 99.0
乙 105 88 115.0
丙 109 120 130.0
丁 112 115 NaN(一)查询单行数据
查询一行数据时既可以使用loc索引器(标签索引器),也可以使用iloc位置索引器。查询单行的结果是一个 Series 对象。
# 使用loc索引器(标签索引器)
row1 = df.loc['甲']
print(row1)
# 查询单行的结果是一个Series对象
print(type(row1))
# 使用iloc位置索引器
print(df.iloc[2])输出结果:
语文 110.0
数学 105.0
英语 99.0
Name: 甲, dtype: float64
<class 'pandas.core.series.Series'>
语文 109.0
数学 120.0
英语 130.0
Name: 丙, dtype: float64(二)查询多行数据
查询多行数据,既可以使用loc标签索引器,也可以使用iloc位置索引器。查询多行的结果是一个 DataFrame 对象。
# 使用loc标签索引器
row2 = df.loc[['甲','丙']]
print(row2)
# 查询多行的结果是一个DataFrame对象
print(type(row2))
# 使用iloc位置索引器
print(df.iloc[[0,2]])输出结果:
语文 数学 英语
甲 110 105 99.0
丙 109 120 130.0
<class 'pandas.core.frame.DataFrame'>
语文 数学 英语
甲 110 105 99.0
丙 109 120 130.0练习:
# 用loc索引器查询从甲到丁的成绩
print(df.loc['甲':'丁'])
# 用iloc索引器查询从甲到丁的成绩
print(df.iloc[0:4])
# 比较两种索引器的查询范围的区别:比较两种索引器的查询范围的区别:
loc索引器使用的是行和列的标签进行索引,因此loc['甲':'丁']会包括标签为'丁'的行。iloc索引器使用的是行和列的整数位置进行索引,因此iloc[0:4]会包括索引位置从0到3的行,不包括索引位置为4的行。
(三)查询列数据
查询列数据,既可以直接使用列名(主要基于把 DataFrame 看成字典的观点),更建议使用loc或iloc索引器,此时行索引不能省略。
# 查询列数据,既可以直接使用列名(主要基于把DataFrame看成字典的观点):
print(df[['语文','数学']])
# 更建议使用loc或iloc索引器,此时行索引不能省略:
print(df.loc[:,['语文','数学']]) # 查询“语文”和“数学”
print(df.iloc[:,[0,1]]) # 查询第1列和第2列
print(df.loc[:,'语文':]) # 查询从“语文”开始到最后一列
print(df.iloc[:,:2]) # 查询连续从1列开始到第3列,但不包括第3列输出结果:
语文 数学
甲 110 105
乙 105 88
丙 109 120
丁 112 115
语文 数学
甲 110 105
乙 105 88
丙 109 120
丁 112 115
语文 数学
甲 110 105
乙 105 88
丙 109 120
丁 112 115
语文 数学 英语
甲 110 105 99.0
乙 105 88 115.0
丙 109 120 130.0
丁 112 115 NaN
语文 数学
甲 110 105
乙 105 88
丙 109 120
丁 112 115(四)查询指定的行列数据
查询指定的行、列数据时,loc和iloc索引器都可以使用,行列下标的位置上都允许切片和花式索引。
print(df.loc['乙','英语']) # “英语”成绩
print(df.loc[['乙'],['英语']]) # “乙”的“英语”成绩
print(df.loc[['乙'],['数学','英语']]) # “乙”的“数学”和“英语”成绩
print(df.iloc[[1],[2]]) # 第2行第3列
print(df.iloc[1:,[2]]) # 第2行到最后一行的第3列
print(df.iloc[1:,[0,2]]) # 第2行到最后一行的第1列和第3列
print(df.iloc[:,2]) # 所有行,第3列注意: 第1个查询结果是一个数,而从第2个开始的后面几个查询结果是一个 DataFrame。
输出结果:
115.0
英语
乙 115.0
数学 英语
乙 88 115.0
英语
乙 115.0
英语
乙 115.0
丙 130.0
丁 NaN
语文 英语
乙 105 115.0
丙 109 130.0
丁 112 NaN
甲 99.0
乙 115.0
丙 130.0
丁 NaN
Name: 英语, dtype: float64查询指定的行、列数据的结果是一个 DataFrame 对象。
print(type(df.loc[['乙'],['英语']]))<class 'pandas.core.frame.DataFrame'>二、DataFrame数据的编辑
(一)增加数据
1、一次增加一列数据
(1)在尾部增加一列,使用df['列名']=值的形式,类似于字典增加键值对的dt['键']=值。
df['物理'] = [88,79,60,50](2)赋值号左侧也可以使用loc索引器。
df.loc[:,'化学'] = [80,69,70,93]
print(df)输出结果:
语文 数学 英语 物理 化学
甲 110 105 99.0 88 80
乙 105 88 115.0 79 69
丙 109 120 130.0 60 70
丁 112 115 NaN 50 93(3)在中间某个任意位置增加一列,要使用insert函数。
insert函数原型:DataFrame.insert(loc, column, value, allow_duplicates=False)
loc:要插入新列的位置索引,即要插入的列的位置,是一个整数值,表示插入的列在 DataFrame 中的列索引位置。column:新列的列名,即要插入的列的名称。value:要插入的列的值,可以是一个标量值、数组、Series或可转换为Series的其他数据结构。如果是标量值,它将被广播到整个列中。allow_duplicates:可选参数,默认为False,表示是否允许插入重复的列名。如果设置为True,则允许插入具有与现有列相同名称的列。
sw = [68,89,73,56]
df.insert(3,'生物',sw)
print(df)输出结果:
语文 数学 英语 生物 物理 化学
甲 110 105 99.0 68 88 80
乙 105 88 115.0 89 79 69
丙 109 120 130.0 73 60 70
丁 112 115 NaN 56 50 932、一次增加一行数据
(1)在尾部增加一行,建议用.loc属性而非append。
df.loc['戊'] = [100,120,99,70,80,90]
print(df)输出结果:
语文 数学 英语 生物 物理 化学
甲 110 105 99.0 68 88 80
乙 105 88 115.0 89 79 69
丙 109 120 130.0 73 60 70
丁 112 115 NaN 56 50 93
戊 100 120 99.0 70 80 903、一次增加多列(行)数据
注意: append()函数会产生新对象,而不是在原来的DataFrame上增加。
append()函数更适合将一个数据框合并到另一个数据框的尾部,类似于df.concat(df1,axis=0)。
df_insert = pd.DataFrame(np.arange(1,19).reshape(3,6),index=['己','庚','辛'],columns=['语文','数学','英语','生物','物理','化学'])
df1 = df.append(df_insert)
print(df1)
print(df)输出结果:
语文 数学 英语 生物 物理 化学
甲 110 105 99.0 68 88 80
乙 105 88 115.0 89 79 69
丙 109 120 130.0 73 60 70
丁 112 115 NaN 56 50 93
戊 100 120 99.0 70 80 90
己 1 2 3.0 4 5 6
庚 7 8 9.0 10 11 12
辛 13 14 15.0 16 17 18
语文 数学 英语 生物 物理 化学
甲 110 105 99.0 68 88 80
乙 105 88 115.0 89 79 69
丙 109 120 130.0 73 60 70
丁 112 115 NaN 56 50 93
戊 100 120 99.0 70 80 90(二)删除数据
推荐使用drop,虽然del也可以实现删除。区别如下:
drop()方法:
- drop() 是 DataFrame 对象的方法,用于删除行或列,并返回一个新的 DataFrame,原始 DataFrame 不会被修改。
- drop() 方法通常用于删除行或列,通过指定
axis参数来指定删除的是行还是列,默认情况下删除行,即axis=0。 - drop() 方法可以同时删除多行或多列,并且可以通过
inplace=True参数来就地修改原始 DataFrame,而不返回新的 DataFrame。
del关键字:
- del 是 Python 的关键字,用于删除对象的引用,包括 DataFrame 中的列。
- del 关键字直接在原始 DataFrame 上操作,不返回新的 DataFrame,而是直接修改原始对象。
- del 关键字只能用于删除列,不能用于删除行。
1、删除一列(行)
drop函数原型:DataFrame.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise')
labels:要删除的行或列的索引标签或列表。axis:要删除的轴,可以是 0(行)或 1(列)。默认为 0,即删除行。index:与labels参数功能相同,用于指定要删除的行的索引标签或列表。columns:与labels参数功能相同,用于指定要删除的列的索引标签或列表。level:如果 DataFrame 具有多层索引(MultiIndex),则可以指定要删除的索引级别。inplace:是否在原始 DataFrame 上直接修改,而不返回新的 DataFrame 。默认为False。errors:如果指定的标签不存在于索引或列中,控制报错行为。可选值为'raise'(默认,抛出异常)、'ignore'(忽略)和'coerce'(将无效的标签转换为空),其中'coerce'只对标签为None的情况有效。
这里axis=0表示行,axis=1表示列(Numpy中axis=0表示跨行,axis=1表示跨列)。
# df.drop(columns='数学',inplace=True) # 删除columns为“数学”的列
# print(df)
# df.drop(labels='数学', axis=1,inplace=True) # 删除列标签为“数学”的列
# print(df)
# df.drop(['甲','乙'],inplace=True) # 删除某行
# print(df)
# df.drop(index='甲',inplace=True) # 删除index为“甲”的行
# print(df)
df1.drop(labels='甲', axis=0, inplace=True) # 删除行标签为“甲”的行
print(df1)输出结果:
语文 数学 英语 生物 物理 化学
乙 105 88 115.0 89 79 69
丙 109 120 130.0 73 60 70
丁 112 115 NaN 56 50 93
戊 100 120 99.0 70 80 90
己 1 2 3.0 4 5 6
庚 7 8 9.0 10 11 12
辛 13 14 15.0 16 17 182、删除多列(行)
# 可以一次删除多列
df1.drop(['生物','化学'],axis=1,inplace=True)
print(df1)输出结果:
语文 数学 英语 物理
乙 105 88 115.0 79
丙 109 120 130.0 60
丁 112 115 NaN 50
戊 100 120 99.0 80
己 1 2 3.0 5
庚 7 8 9.0 11
辛 13 14 15.0 17删除含有NaN的列也可以使用dropna函数:
dropna函数原型:DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
axis:指定删除的轴,可以是 0(删除行)或 1(删除列)。默认为 0。how:确定要删除的行或列的方式。'any':只要有任何缺失值就删除整行或整列。'all':只有全部为缺失值才删除整行或整列。默认为'any'。thresh:指定在行或列中非缺失值的最小数量。如果某行或某列中的非缺失值数量低于 thresh,则删除该行或该列。subset:只在特定的列或行中查找缺失值并删除。可以传入一个列名或列名的列表。inplace:是否在原始 DataFrame 上直接修改,而不返回新的 DataFrame。默认为False。
df1.dropna(axis=1,inplace=True)
print(df1)输出结果:
语文 数学 物理
乙 105 88 79
丙 109 120 60
丁 112 115 50
戊 100 120 80
己 1 2 5
庚 7 8 11
辛 13 14 17(三)修改数据
修改数据使用loc或iloc索引器配合赋值操作。
# 使用loc属性修改数据
print(df)
df.loc['甲']=[120,115,109,70,80,90]
print(df)
df.loc['甲']=df.loc['甲']+10
print(df)
df.loc[:,'语文']=[115,108,112,118,106]
print(df)
df.loc['甲','语文']=135
print(df)
# # 使用iloc属性修改数据
# df.iloc[0,0]=115 # 修改某一数据
# df.iloc[:,0]=[115,108,112,118,123] # 修改整列数据
# df.iloc[0,:]=[120,115,109,90,90,90] # 修改整行数据输出结果:
语文 数学 英语 生物 物理 化学
甲 110 105 99.0 68 88 80
乙 105 88 115.0 89 79 69
丙 109 120 130.0 73 60 70
丁 112 115 NaN 56 50 93
戊 100 120 99.0 70 80 90
语文 数学 英语 生物 物理 化学
甲 120 115 109.0 70 80 90
乙 105 88 115.0 89 79 69
丙 109 120 130.0 73 60 70
丁 112 115 NaN 56 50 93
戊 100 120 99.0 70 80 90
语文 数学 英语 生物 物理 化学
甲 130.0 125.0 119.0 80.0 90.0 100.0
乙 105.0 88.0 115.0 89.0 79.0 69.0
丙 109.0 120.0 130.0 73.0 60.0 70.0
丁 112.0 115.0 NaN 56.0 50.0 93.0
戊 100.0 120.0 99.0 70.0 80.0 90.0
语文 数学 英语 生物 物理 化学
甲 115 125.0 119.0 80.0 90.0 100.0
乙 108 88.0 115.0 89.0 79.0 69.0
丙 112 120.0 130.0 73.0 60.0 70.0
丁 118 115.0 NaN 56.0 50.0 93.0
戊 106 120.0 99.0 70.0 80.0 90.0
语文 数学 英语 生物 物理 化学
甲 135 125.0 119.0 80.0 90.0 100.0
乙 108 88.0 115.0 89.0 79.0 69.0
丙 112 120.0 130.0 73.0 60.0 70.0
丁 118 115.0 NaN 56.0 50.0 93.0
戊 106 120.0 99.0 70.0 80.0 90.0用index属性赋值修改行标题。
# 用index属性赋值修改行标题
print(df1)
df1.index = ['A','B','C','D','E','F','G']
print(df1) 语文 数学 物理
乙 105 88 79
丙 109 120 60
丁 112 115 50
戊 100 120 80
己 1 2 5
庚 7 8 11
辛 13 14 17
语文 数学 物理
A 105 88 79
B 109 120 60
C 112 115 50
D 100 120 80
E 1 2 5
F 7 8 11
G 13 14 17用columns属性赋值修改列标题。
# 用columns属性赋值修改列标题
df1.columns = ['Chinese','Math','Physics']
print(df1)
df1.columns输出结果:
Chinese Math Physics
A 105 88 79
B 109 120 60
C 112 115 50
D 100 120 80
E 1 2 5
F 7 8 11
G 13 14 17
Index(['Chinese', 'Math', 'Physics'], dtype='object')(四)查询数据
1、带条件查询
# 带条件查询
df = pd.DataFrame({'姓名':['甲','乙','丙','丁'],
'语文':[110,105,109,99],
'数学':[105,88,120,90],
'英语':[99,115,130,120]})
print(df)
''' 逻辑运算符号:> 、>=、 <、 <=、 == (双等于)、!=(不等于)'''
print(df[df['语文']>105])
print(df[df['英语']>=115])
print(df[df['英语']==115])
'''复合逻辑运算符:&(并且) 、|(或者)'''
'''查询“语文”大于105并且“数学”大于88'''
print(df[(df['语文']>105) & (df['数学']>88)])
'''查询“语文”大于105或者数学大于88'''
print(df[(df['语文']>105) | (df['数学']>88)])输出结果:
姓名 数学 英语 语文
0 甲 105 99 110
1 乙 88 115 105
2 丙 120 130 109
3 丁 90 120 99
姓名 数学 英语 语文
0 甲 105 99 110
2 丙 120 130 109
姓名 数学 英语 语文
1 乙 88 115 105
2 丙 120 130 109
3 丁 90 120 99
姓名 数学 英语 语文
1 乙 88 115 105
姓名 数学 英语 语文
0 甲 105 99 110
2 丙 120 130 109
姓名 数学 英语 语文
0 甲 105 99 110
2 丙 120 130 109
3 丁 90 120 992、query()方法简化查询代码
'''# query()方法简化查询代码'''
# df1 = df[df['语文']>105]
df2 = df.query('语文>105')
print(df2)输出结果:
姓名 数学 英语 语文
0 甲 105 99 110
2 丙 120 130 1093、逻辑运算方法
(1)between()方法
'''逻辑运算方法:between()方法'''
df3 = df[df['语文'].between(100,120)]
print(df3)输出结果:
姓名 数学 英语 语文
0 甲 105 99 110
1 乙 88 115 105
2 丙 120 130 109(2)isin()方法
'''逻辑运算方法:isin()方法'''
'''判断整个数据中包含45和60的数据'''
df = pd.DataFrame({'姓名':['甲','乙','丙'],
'语文':[110,105,109],
'数学':[105,60,120],
'英语':[99,115,130],
'物理':[60,89,99],
'化学':[45,60,70]})
df4 = df[df.isin([45,60])]
print(df4)
'''判断“化学”中包含45和60的数据'''
df5 = df[df['化学'].isin([45,60])]
print(df5)输出结果:
化学 姓名 数学 物理 英语 语文
0 45.0 NaN NaN 60.0 NaN NaN
1 60.0 NaN 60.0 NaN NaN NaN
2 NaN NaN NaN NaN NaN NaN
化学 姓名 数学 物理 英语 语文
0 45 甲 105 60 99 110
1 60 乙 60 89 115 105df1 = pd.DataFrame({'姓名':['甲','乙','丙'],
'语文':[110,105,109],
'数学':[105,60,120],
'英语':[99,115,130],
'物理':[60,89,99],
'化学':[45,60,70]})
print(df1)
df2 = pd.DataFrame({'姓名':['甲','乙','丙'],
'性别':['男','女','女'],
'年龄':[16,15,16]})
print(df2)
'''逻辑运算方法:isin()方法'''
'''利用df2中的性别一列,来对df1中的数据进行筛选'''
df1 = df1[df2['性别'].isin(['女'])]
print(df1)输出结果:
化学 姓名 数学 物理 英语 语文
0 45 甲 105 60 99 110
1 60 乙 60 89 115 105
2 70 丙 120 99 130 109
姓名 年龄 性别
0 甲 16 男
1 乙 15 女
2 丙 16 女
化学 姓名 数学 物理 英语 语文
1 60 乙 60 89 115 105
2 70 丙 120 99 130 109三、DataFrame数据的排序
# 设置数据显示的编码格式为东亚宽度,以使列对齐
pd.set_option('display.unicode.east_asian_width', True)
data = [[110,105,99],[105,88,115],[109,120,130],[110,115,100]]
name = ['甲','乙','丙','丁']
columns = ['语文','数学','英语']
df = pd.DataFrame(data=data, index=name, columns=columns)
print(df)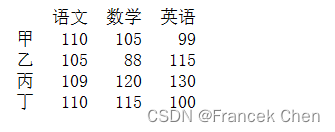
df.sort_values()方法原型:
DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last', ignore_index=False, key=None)
参数说明:
by:指定要根据哪些列进行排序,可以是列名或列名的列表。axis:指定按行排序还是按列排序,默认为按行排序,即axis=0。ascending:排序顺序,默认为升序,设置为False则为降序。inplace:是否在原 DataFrame 上进行排序,如果设置为True,则会就地修改 DataFrame 并返回None,默认为False,即返回排序后的副本。kind:排序算法,默认为快速排序('quicksort'),也可以选择归并排序('mergesort')或堆排序('heapsort')。na_position:缺失值在排序中的位置,默认为'last',表示缺失值会排在最后;设置为'first'则会排在最前面。ignore_index:是否忽略索引,默认为False,即保留原索引;如果设置为True,则会重新生成索引。key:用于排序的函数,可以是自定义的函数或者lambda表达式。
df1 = df.sort_values("英语")
print(df1)
print(df)排序后df的记录顺序保持不变,因为inplace参数默认为False。
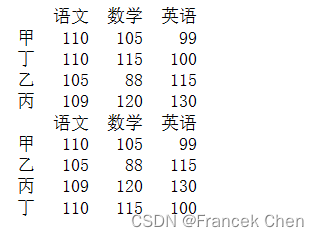
df.sort_values(['语文','数学'],ascending=[False,True],inplace=True)
df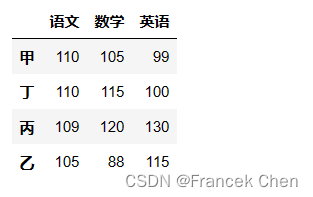
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-04-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号