Python数据分析作业一:NumPy库的使用
Python数据分析作业一:NumPy库的使用

一、前言
NumPy(Numerical Python) 是 Python 中用于科学计算的基础包,用于科学计算和数据分析,也是大量 Python 数学和科学计算包的基础。NumPy 的核心基础是 N 维数组(N-dimensional array,ndarray),即由数据类型相同的元素组成的 N 维数组。
二、题目及答案解析
1、导入Numpy包并设置随机数种子为666
import numpy as np
np.random.seed(666)2、创建并输出一个包含12个元素的随机整数数组r1,元素的取值范围在[30,100)之间
r1 = np.random.randint(30,100,12)
r1np.random.randint(30, 100, 12)利用 NumPy 中的random.randint()函数生成一个包含 12 个元素的随机整数数组,其中30是生成随机整数的最小值(包含),100是生成随机整数的最大值(不包含),12是生成的随机整数数组的长度。
输出结果:
array([32, 75, 60, 92, 60, 66, 91, 81, 90, 58, 44, 93])3、输出上述数组r1的形状、维数和元素个数
print("数组r1的形状是{}、维数是{},元素个数是{}".format(r1.shape,r1.ndim,r1.size))输出结果:
数组r1的形状是(12,)、维数是1,元素个数是124、输出该r1数组的平均值和最大值的位置
print("r1数组的平均值是{},最大值的位置下标是{}".format(r1.mean(),r1.argmax()))输出结果:
r1数组的平均值是70.16666666666667,最大值的位置下标是11 5、原地修改数组r1的形状为4行3列
r1.shape = (4,3)
r1输出结果:
array([[32, 75, 60],
[92, 60, 66],
[91, 81, 90],
[58, 44, 93]])6、对r1数组的每行求和并找出和最小的行的行号
假设r1数组是:

要求输出结果如下所示:

print("和最小的行的行号是:",r1.sum(axis=1).argmin())
r1.sum(axis=1)r1.sum(axis=1):对二维数组r1沿着axis=1的方向(即对每一行进行操作)进行求和,得到每一行元素的和。这将返回一个包含每行和的一维数组。
r1.sum(axis=1).argmin():这行代码找出了数组r1中每行和的最小值所在的索引(即和最小的行的行号)。argmin()函数返回使得最小值出现的第一个位置的索引。
输出结果:
和最小的行的行号是: 0
array([167, 218, 262, 195])7、同时输出r1数组第一行和最后一行的最后两列数据
要求输出后:
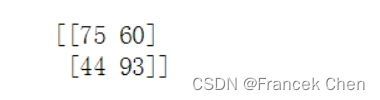
print(r1[[0,-1],-2:])r1[[0, -1], -2:]使用了花式索引来选取数组中的特定行和列。[0, -1]表示要选择第一行和最后一行,-2:表示要选择倒数第二列到最后一列(包括最后一列)。
输出结果:
[[75 60]
[44 93]]8、找到r1数组中值大于等于90的元素的位置(有难度,提示:使用np.where函数)
要求输出后:
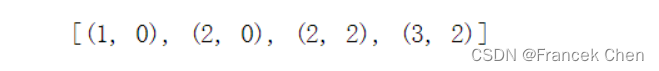
row,col = np.where(r1>=90)
list(zip(row,col))row, col = np.where(r1 >= 90):这行代码使用 NumPy 的where函数来找出数组r1中大于等于 90 的元素所在的行和列。np.where(r1 >= 90)返回一个元组,其中第一个数组是符合条件的元素所在的行的索引,第二个数组是符合条件的元素所在的列的索引。
list(zip(row, col)):这行代码使用zip函数将行和列的索引对应起来,然后通过list()函数将结果转换为列表。最终返回的列表中每个元素都是一个二元组,表示大于等于 90 的元素所在的行和列的组合。
输出结果:
[(1, 0), (2, 0), (2, 2), (3, 2)]9、统计r1数组中值小于60的元素的个数
np.sum(r1<60)r1<60使用条件判断操作,返回一个布尔类型的数组,其中元素为True表示对应位置的元素小于 60,为False则表示对应位置的元素不小于 60。
np.sum(r1<60)利用 NumPy 库中的np.sum()函数对上述条件判断的结果进行求和,由于布尔类型的True在计算时会被转换成 1,False会被转换成 0,因此最终的求和结果就是小于 60 的元素的个数。
输出结果:
310、统计r1数组中每个元素的出现次数(有难度)
要求统计结果如下:

f = r1.flatten() #拉平
counts = np.array([np.sum(f==i) for i in f]) #用列表推导式对每个元素统计出现次数,并转化成numpy数组
counts.shape = r1.shape #把形状从一维修改成二维
print(counts)f = r1.flatten()将二维数组r1拉平成一维数组,即将多维数组转换为一维数组。
counts = np.array([np.sum(f == i) for i in f]):这行代码使用列表推导式对拉平后的一维数组中的每个元素进行统计,计算每个元素在数组中出现的次数,并将结果存储为一个 NumPy 数组。
counts.shape = r1.shape将上一步得到的一维数组重新调整形状为原始二维数组r1的形状,即将一维数组转换为与原始数组相同的二维形状。
输出结果:
[[1 1 2]
[1 2 1]
[1 1 1]
[1 1 1]]11、对r1数组的每一列按降序排序,排序结果放在数组r2中并输出
r2 = np.sort(r1,axis=0)[::-1,:]
r2np.sort(r1, axis=0)使用 NumPy 的sort()函数对二维数组r1按列进行排序,其中axis=0表示沿着列的方向进行排序,即每一列都会单独排序。
[:: -1, :]:列表切片的语法,[::-1]表示倒序选取数组中的元素,即实现了按列降序排序的效果。最后的 : 表示选取所有的行。
r2 = np.sort(r1, axis=0)[::-1, :]表示将排序后的结果赋值给新的数组r2,即得到了按列降序排列的二维数组。
输出结果:
array([[92, 81, 93],
[91, 75, 90],
[58, 60, 66],
[32, 44, 60]])12、将r2数组中小于70的元素值都增加3
r2[r2<70] = r2[r2<70]+3
r2输出结果:
array([[92, 81, 93],
[91, 75, 90],
[61, 63, 69],
[35, 47, 63]])13、删除r2数组的第2、4两行(提示:使用np.delete函数,可以自行百度其用法)
r2 = np.delete(r2,[1,3],axis=0) #这里的axis=0就表示行,而不是跨行
r2np.delete(r2, [1, 3], axis=0)调用了 NumPy 中的np.delete()函数,该函数用于删除数组中的指定行或列。其中,r2是要删除元素的数组,[1, 3]是要删除的行的索引,axis=0表示按行进行操作。
输出结果:
array([[92, 81, 93],
[61, 63, 69]])14、将r1数组转置后并输出
r1.T #r1本身并没有改变输出结果:
array([[32, 92, 91, 58],
[75, 60, 81, 44],
[60, 66, 90, 93]])15、将r1数组的每个元素分别减去所在行的平均值并将结果赋值给r3数组
r3 = r1-r1.mean(axis=1,keepdims=True)
#等价于r3=r1-r1.mean(axis=1).reshape(-1,1)
r3r1.mean(axis=1, keepdims=True)计算了数组r1每行的平均值,并且保持维度一致,即使是在一维数组中也会以列向量形式输出。
r1-r1.mean(axis=1, keepdims=True)使用了广播(broadcasting)的特性,将数组r1中的每行元素都减去对应行的平均值,得到每行元素与平均值的差,最后将这些结果存储在数组r3中。
输出结果:
array([[-23.66666667, 19.33333333, 4.33333333],
[ 19.33333333, -12.66666667, -6.66666667],
[ 3.66666667, -6.33333333, 2.66666667],
[ -7. , -21. , 28. ]])16、创建一个以2为底的等比数列t,其中第一个元素是4,最后一个元素是256,相邻元素比是4
t = np.logspace(2,8,4,base=2,dtype=int)
t
#下面是另一种写法:
#s=2**np.arange(2,9,2)
#snp.logspace(2, 8, 4, base=2, dtype=int)调用了 NumPy 的np.logspace()函数,指定了起始值为
,终止值为
,共计 4 个元素,在以 2 为底的对数空间中均匀分布。dtype=int表示将结果数组的数据类型设定为整数。
输出结果:
array([ 4, 16, 64, 256])17、产生5行3列的标准正态分布数组r4,并且其中的每个元素保留2位小数
r4 = np.round(np.random.randn(5,3),2)
r4np.random.randn(5, 3)调用了 NumPy 的np.random.randn()函数,用于生成服从标准正态分布(均值为 0,标准差为 1)的随机数。指定参数 (5, 3) 表示要生成一个形状为 (5, 3) 的随机数组。
接着使用了np.round()函数,将生成的随机数组中的每个元素保留两位小数。
输出结果:
array([[ 0.75, -0.75, -0.38],
[ 1.2 , -0.88, -0.47],
[ 0.91, 0.92, 0.4 ],
[ 0.54, -0.04, 0.08],
[-0.42, 0.97, -0.21]])18、将上述r4数组的第2行和第4行互换位置(可以考虑使用花式索引和切片)
r4[[3,1],:] = r4[[1,3],:]
r4r4[[3, 1], :]表示对r4数组进行索引操作,选择第 4 行和第 2 行(Python 中索引从 0 开始)。
r4[[1, 3], :]表示对r4数组进行索引操作,选择第 2 行和第 4 行。
r4[[3, 1], :] = r4[[1, 3], :]最终将r4数组中第 2 行和第 4 行的值赋给了r4数组中的第 4 行和第 2 行,实现了交换这两行数据的操作。
输出结果:
array([[ 0.75, -0.75, -0.38],
[ 0.54, -0.04, 0.08],
[ 0.91, 0.92, 0.4 ],
[ 1.2 , -0.88, -0.47],
[-0.42, 0.97, -0.21]])19、使用np.diag函数产生如下所示的三对角数组r5
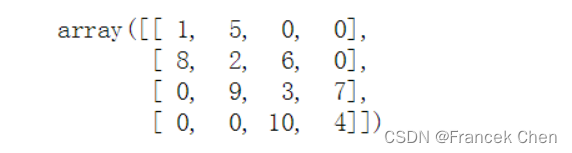
r5 = np.diag([1,2,3,4]) + np.diag([5,6,7],k=1) + np.diag([8,9,10],k=-1)
r5np.diag([1, 2, 3, 4])创建一个对角矩阵,对角线上的元素分别为 1, 2, 3, 4,其他位置的元素为 0。
np.diag([5, 6, 7], k=1)创建一个偏移了一位的对角矩阵,对角线上的元素为 0, 5, 6, 7,处于主对角线上方一位,其他位置的元素为 0。
np.diag([8, 9, 10], k=-1)创建一个偏移了一位的对角矩阵,对角线上的元素为 8, 9, 10, 0,处于主对角线下方一位,其他位置的元素为 0。
输出结果:
array([[ 1, 5, 0, 0],
[ 8, 2, 6, 0],
[ 0, 9, 3, 7],
[ 0, 0, 10, 4]])20、返回上述r5数组中值最大的前3个元素的位置(有难度,可以考虑使用np.argsort函数)
要求输出的结果如下:
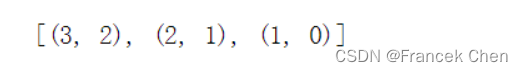
pos = np.argsort(-r5.flatten()) #拉平后按降序排列,并返回相应位置
rows = pos // r5.shape[1]
cols = pos % r5.shape[1]
list(zip(rows,cols))[:3]np.argsort(-r5.flatten()):将矩阵 r5 拉平后,按照元素值的降序返回对应的位置索引。
rows = pos // r5.shape[1]:根据位置索引计算每个元素在原矩阵中的行坐标。
cols = pos % r5.shape[1]:根据位置索引计算每个元素在原矩阵中的列坐标。
list(zip(rows,cols))[:3]:将行列坐标组合成坐标对,并取前三个作为结果返回。
输出结果:
[(3, 2), (2, 1), (1, 0)]腾讯云开发者
