腾讯云 DeepSeek 部署方式怎么选?2025 最新选型策略与扩展技巧
原创腾讯云 DeepSeek 部署方式怎么选?2025 最新选型策略与扩展技巧
原创

前言
腾讯云作为云厂商的第一梯队,也是在开工之日,迅速上线了多种 DeepSeek 的部署方式,既卷价格,又卷速度。那,作为不同的用户,该如何选择平台 / 方式才能让价格最低呢?以及低成本还原官网又该如何做呢?接下来,请跟随本文收获技巧。
方案解析

需求之一:快速部署体验
以上全部产品都可以满足需求。不过根据产品定位,可部署的参数略有区别。
没有预算,可以选择 Cloud Studio,云原生(CNB)。二者都有每月的免费算力提供。

默认提供1.5B、7B,能做一些简单处理。因为显存在16G,14B模型其实也是可以运行的,不过需要自行下载。
(base) root@VM-0-80-ubuntu:/workspace# ollama list
NAME ID SIZE MODIFIED
deepseek-r1:1.5b a42b25d8c10a 1.1 GB 10 days ago
deepseek-r1:7b 0a8c26691023 4.7 GB 10 days ago CNB 则更为简洁,只要fork该示例仓库,最快不到一分钟即可体验。
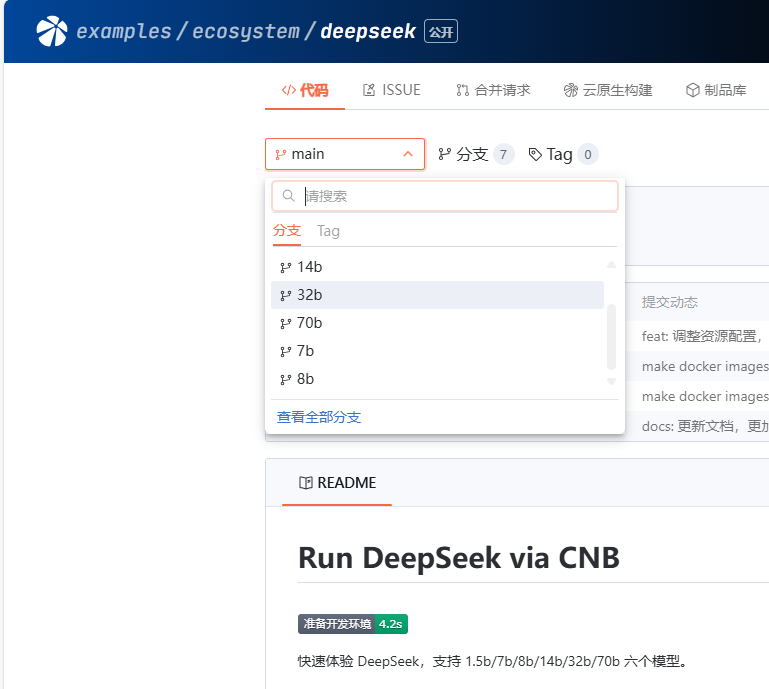
需求之二:云API / 知识库
作为程序员,对话体验已经无法满足需求,他们更可能会用在其他可自由对接大模型的应用上。换句话说,仅仅需要一个 API 而已。而作为企业,则还需要一些私有化的知识库为大模型的数据参考。所以二者一拍即合,大模型知识引擎同时满足了这样的需求。
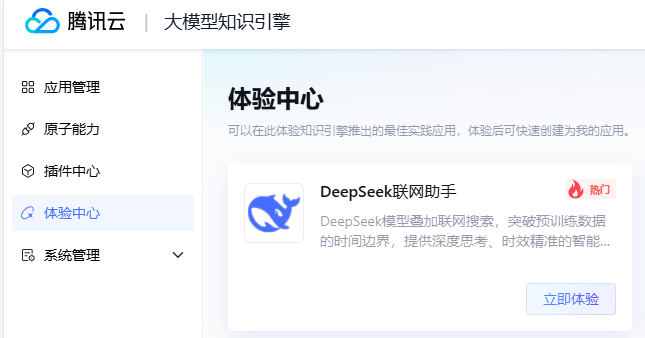
如果有搞过元器等智能体平台的同学,对该产品就会比较轻车熟路。相比较来说,大模型知识引擎更注重“知识”,像知识问答,知识库管理等。所以,该产品还提供了对知识库的原子能力。
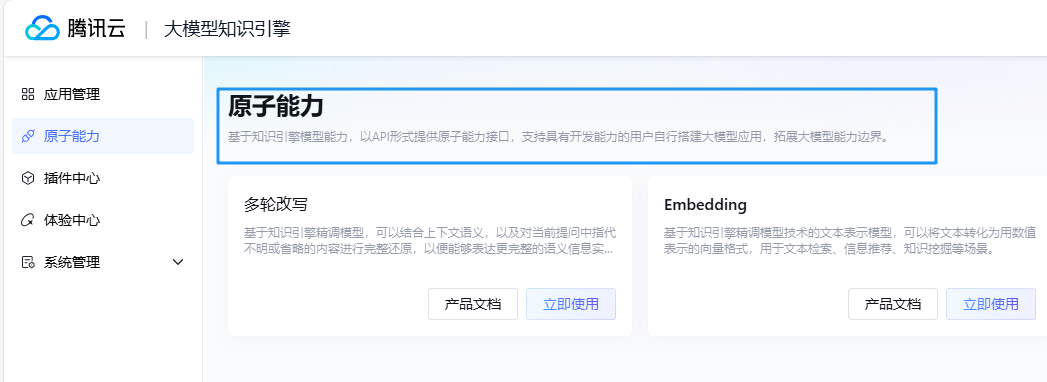
在以上点击任意服务的立即使用,即可以云 API 形式访问,进行在线调试:
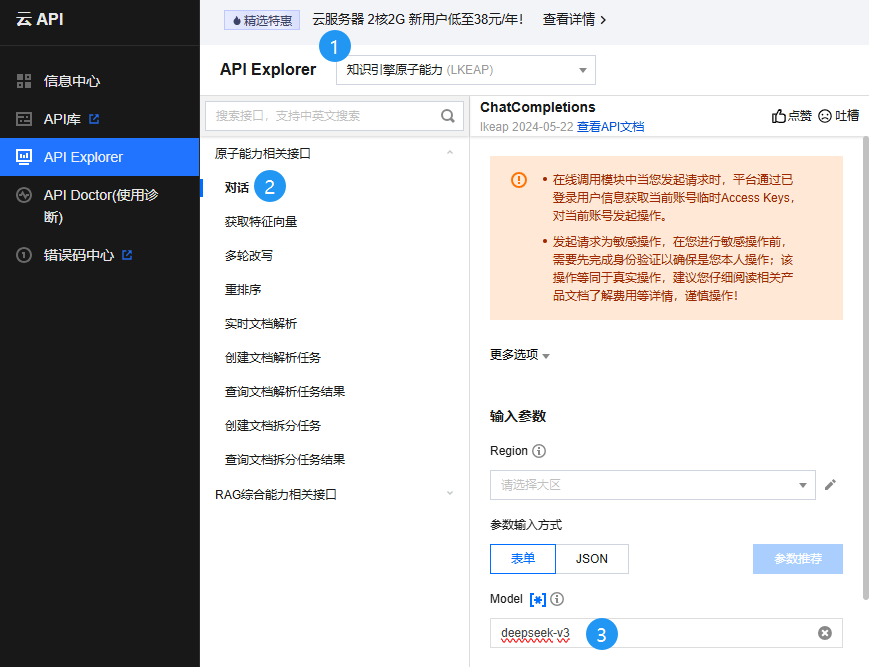
并且,即日至北京时间2025年2月25日23:59:59,本API完全免费。
需求之三:不会编码,也想快速上线
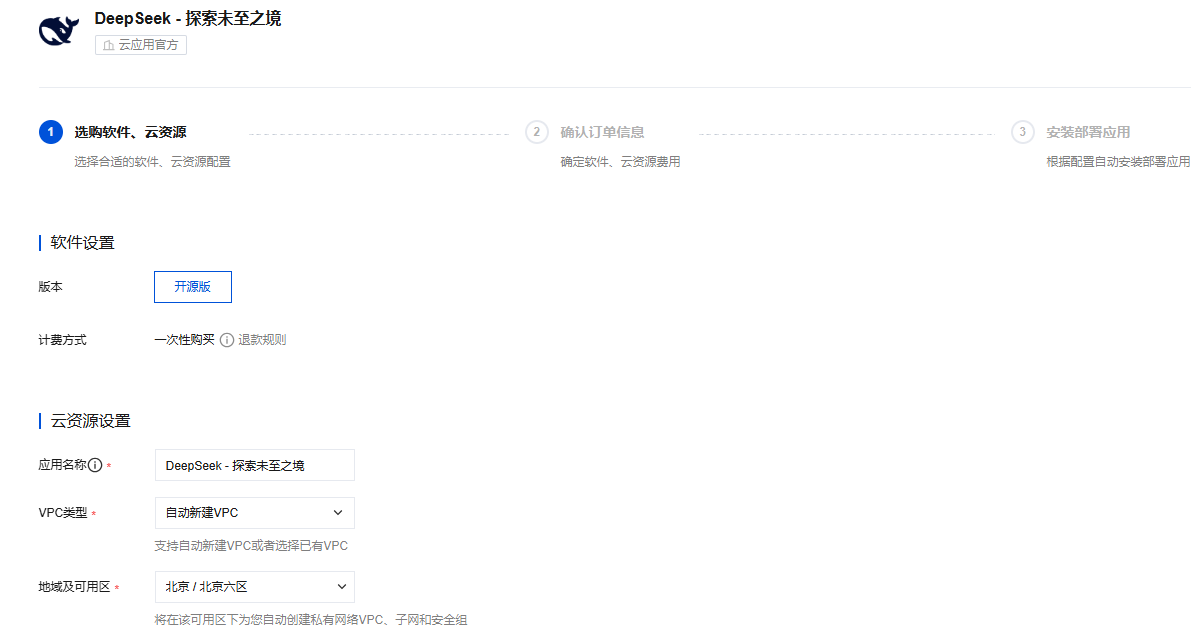
对于代码能力很弱或者没有代码能力,想立刻部署一款 AI 应用或是定制化的传统软件,云应用则是很好的选择。
或是直接购买成品deepseek应用
需求之四:预训练 / 微调
如果是有一定开发能力的 AI 创业公司 / 学校,想训练或者微调专属模型,可以参考这种方式。
服务选择:主推 TI-ONE,其次 HAI。
TI-ONE 是一个全能选手,在预算充足的情况下,大模型的预训练、微调、端侧应用全部可以一手搞定。
HAI 的综合能力弱一些,但对于几百亿(1B 是 10亿)以下的模型,预训练 / 微调也是可以的。
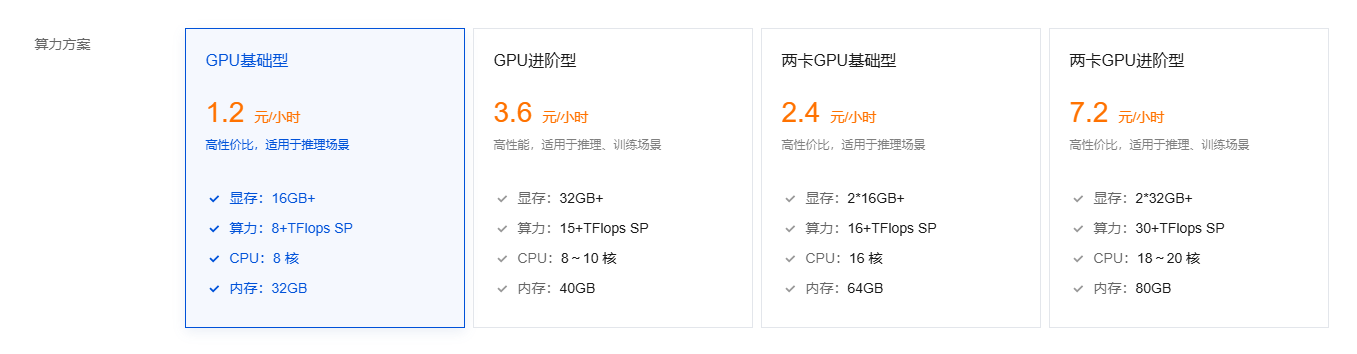
服务器型的个性扩展(HAI 为例)
Tips:模型参数与显存的估算
INT8:320亿参数 × 1字节 = 320亿字节 ≈ 32GB,此为该模型最低需求。
机器选择 32GB+ 即可推理自带的全部模型。以下是价格情况。
多模型选择
目前,HAI 的应用自带的模型中,包括了 1.5~32B的模型。但在特定环境下,用户可能会需要其他的模型。这里以deepseek-code为例,示范如何打开
操作前,请打开学术加速
算力链接:Cloud Studio
终端输入:ollama run deepseek-coder-v2
命令来自于ollama官网,模型大小为 8.9G。预估时间为1小时。可以选择其他人下载好的,替换到对应文件夹。
选择Cloud studio的原因是,可以直接用 IDE 的插件,比如腾讯云AI代码助手,用于体验部署好的模型。
自定义web UI
目前算力链接提供了 5 种方式:

以上已经满足大部分的使用需求,如果想要再自定义,HAI 也是很友好的。
环境内置了python3.10以及conda。假设你想保留旧服务,又增加新的python、第三方库可以使用conda的方式新建。示例如下:
以 Python 3.12 为例
创建环境:
使用 conda create 命令创建一个新的环境,并指定 Python 版本为 3.12。你可以将 myenv 替换为你想要的环境名称。
conda create -n myenv python=3.12激活环境:
创建环境后,使用 conda activate 命令激活该环境。
conda activate myenv- 验证环境: 激活环境后,你可以通过以下命令检查 Python 版本,确保环境已正确设置。
python --version输出应该类似于:
Python 3.12.x命令行的提示会由(base)开头,变为(myenv)开头。这时安装的依赖不会影响其他环境。
最后
以上,是对目前腾讯云部署deepseek的方式一些建议,以及扩展技巧。希望对你有所帮助。(持续更新中)
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
