TimeDistill:跨架构知识蒸馏,使用 MLP 实现高效长程时间序列预测

TimeDistill:跨架构知识蒸馏,使用 MLP 实现高效长程时间序列预测

时空探索之旅
发布于 2025-03-10 13:23:56
发布于 2025-03-10 13:23:56
论文标题:TimeDistill: Efficient Long-Term Time Series Forecasting with MLP via Cross-Architecture Distillation
作者: Juntong Ni (倪浚桐), Zewen Liu (刘泽文), Shiyu Wang(王世宇), Ming Jin(金明), Wei Jin(金卫)
机构:埃默里大学(Emory),格里菲斯大学(Griffith)
论文链接:https://arxiv.org/abs/2502.15016
TL;DR:提出了一种跨架构知识蒸馏(Cross-Architecture Knowledge Distillation)框架TimeDistill,将MLP作为学生模型,其他复杂先进架构(如Transformer和CNN)作为教师模型,通过蒸馏复杂模型的优势至轻量级模型,实现计算负担大幅降低的同时显著提升预测精度,相比于教师模型,TimeDistill加快了最多7倍推理速度,降低了最多130倍参数量,同时TimeDistill还在多个数据集上展现了超越教师模型的SOTA表现,为构建高效、高精度的时序预测模型提供了全新思路。
关键词:长程时间预测,知识蒸馏

点击文末阅读原文跳转本文arXiv链接
时序人:跨架构知识蒸馏:TimeDistill新范式助力高效时序预测
摘要
基于 Transformer 和 CNN 的方法在长期时间序列预测中表现出色。然而,它们对计算和存储的高要求可能会阻碍大规模部署。为了解决这一限制,我们建议使用知识蒸馏 (KD) 将轻量级 MLP 与高级架构集成。本文初步研究表明,不同的模型可以捕获互补模式,特别是时域和频域中的多尺度和多周期模式。基于这一观察,本文引入了 TimeDistill,这是一个跨架构的 KD 框架,可将这些模式从教师模型(例如 Transformer、CNN)转移到 MLP。此外,提供了理论分析,证明我们的 KD 方法可以解释为一种特殊形式的混合数据增强。TimeDistill 将 MLP 性能提高了 18.6%,在八个数据集上超越了教师模型。它还实现了高达 7 倍的推理速度,并且所需的参数减少了 130 倍。此外,进行了广泛的评估,以突出 TimeDistill 的多功能性和有效性。
1. 问题背景
传统的时序预测模型(如基于 Transformer 或 CNN 的复杂结构)虽在精度上表现卓越,但计算开销往往难以满足实际部署需求。而轻量级 MLP(多层感知器) 虽然具备较高的推理速度,却常因建模能力不足,导致预测精度较低。这引出了一个有趣的问题:
是否可以将 MLP 与其他先进架构(如Transformer 和 CNN)结合,以构建一个既强大又高效的模型?
一个直觉的解决方案是知识蒸馏(Knowledge Distillation),通过将更大、更复杂的模型(教师模型)的知识迁移到较小、更简单的模型(学生模型),使其在提升性能的同时实现更高的计算效率。
作者将 MLP 作为学生模型,其他复杂先进架构(如 Transformer 和 CNN)作为教师模型。通过蒸馏,TimeDistill在多个数据集上取得超越教师模型的预测精度并实现了最佳的效率平衡。
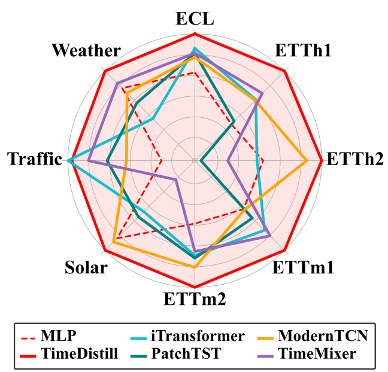
性能比较
性能比较
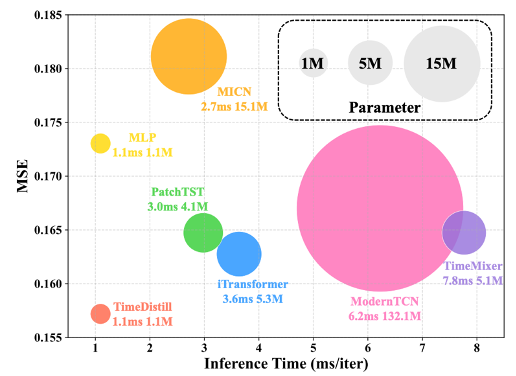
模型效率比较
模型效率比较
2. 设计思路
首先,作者对 MLP 与其他时序模型的预测模式进行了对比分析。研究发现,尽管 MLP 的整体预测精度较低,但往往在某一部分样本上表现出色,这突显了其与教师模型之间存在一定的优势互补,强调了通过知识蒸馏向教师模型的学习互补知识的重要性。
为了进一步探索需要蒸馏的时序“知识”,作者聚焦于两个关键的时序模式:
- 时间域的多尺度模式(Multi-Scale Pattern):真实世界的时序数据通常在多个时间尺度上呈现不同的变化。作者观察到,在最细粒度时间尺度上表现良好的模型通常在较粗粒度上也能保持较高的准确性,而 MLP 在大多数尺度上均表现不佳。
- 频率域的多周期模式(Multi-Period Pattern):时序数据往往存在多个周期性。作者发现,性能较好的模型能够捕捉到与真实数据接近的周期性特征,而 MLP 无法有效识别这些周期性结构。
因此,为了增强 MLP 的时序预测能力,从教师模型中蒸馏并整合多尺度和多周期模式至关重要。
3. TimeDistill模型方法
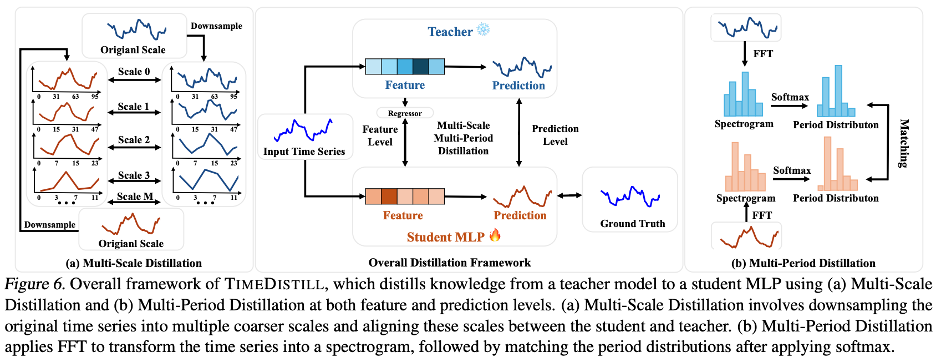
TimeDistill
TimeDistill
跨架构知识蒸馏(Cross-Architecture Distillation)
对于任意教师模型,TimeDistill 均能有效提炼其在时序预测中的多种模式,并将其压缩进轻量学生模型(例如MLP),使后者具备更强的预测能力。
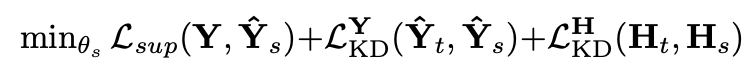
其中即学生模型的预测,即学生模型的中间特征,S即预测长度,D即中间特征维度,C即变量数量。下标为t即代表教师模型。
多尺度、多周期特征的系统性提炼
多尺度蒸馏(Multi-Scale Distillation):在不同的时间分辨率上分别下采样教师模型与学生模型的预测和中间特征,确保学生模型同时捕捉粗粒度的整体趋势与细粒度的瞬时变化。
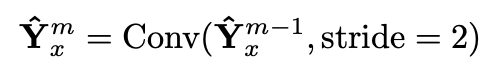
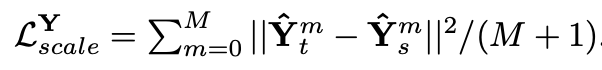
多周期蒸馏(Multi-Period Distillation):通过傅里叶变换(FFT)分析频域信息,将教师模型在周期性模式上的优势提炼并传递给学生模型,使后者在应对长周期波动(如季节、年度周期)与短周期干扰(如日内流量峰谷变化)时,都能维持稳定高精度。
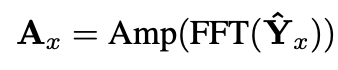
由于FFT得到的频谱往往包含很多低频噪声,作者通过低温蒸馏使得频率(周期)分布更加锋利,使得学生模型可以直接学习最显著的频率(周期)分量。
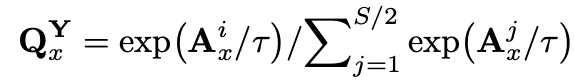
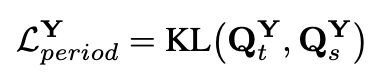
理论解释
从理论上,作者将多尺度和多周期蒸馏损失诠释为一种数据增强策略,类似于分类任务中的标签平滑(Label Smoothing)。蒸馏过程实际上等同于将教师模型的预测结果与真实标签进行混合,类似生成了经过 Mixup 变换的增广样本,这种数据增强带来了以下三个益处:增强泛化,显式融合多种模式,稳定训练,为TimeDistill的优异表现提供了理论支撑。
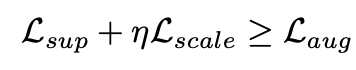
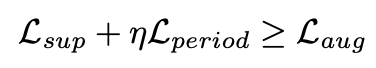
4. 实验效果
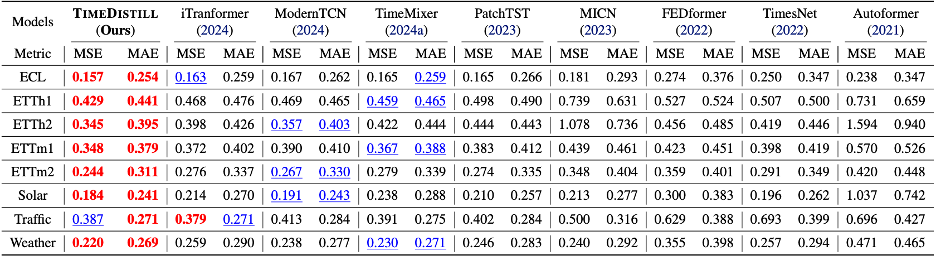
效果全面领先
TimeDistill在8个时序数据集上进行实验,其中7个数据集的MSE指标优于基线教师模型,在所有数据集的MAE指标上均取得最佳表现,展现出卓越的预测能力。
长时预测平均结果
长时预测平均结果
兼容多种教师模型
TimeDistill适用于多种教师模型,能够有效蒸馏知识并提升MLP学生模型的性能,同时相较教师模型本身也有显著提升。
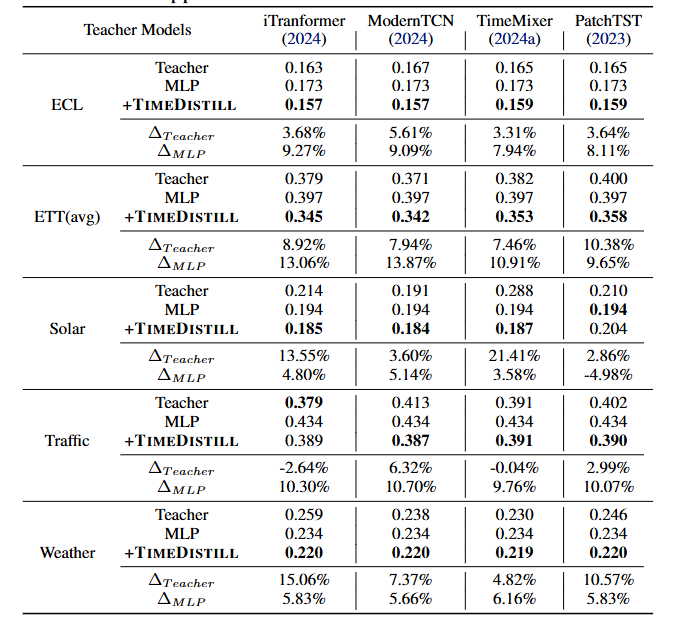
兼容多种教师模型
兼容多种教师模型
兼容多种学生模型
TimeDistill不仅适用于 MLP 结构,还可以增强轻量级学生模型的性能。例如,在以ModernTCN作为教师模型的实验中,TimeDistill使两个轻量模型TSMixer和LightTS的MSE分别降低6.26%和8.02%,验证了其在不同学生模型上的适应性。
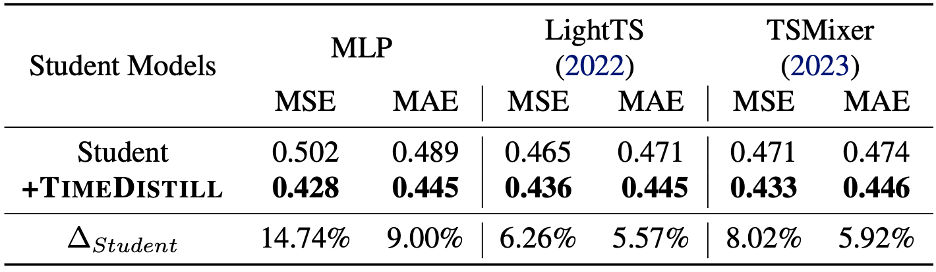
兼容多种学生模型
兼容多种学生模型
兼容多种回溯窗口长度
时序模型的预测性能往往随回溯窗口(历史观测长度)变化而波动,而 TimeDistill在所有窗口长度下均能提升MLP表现,甚至超越教师模型,体现出对不同时间依赖模式的强大适应能力。
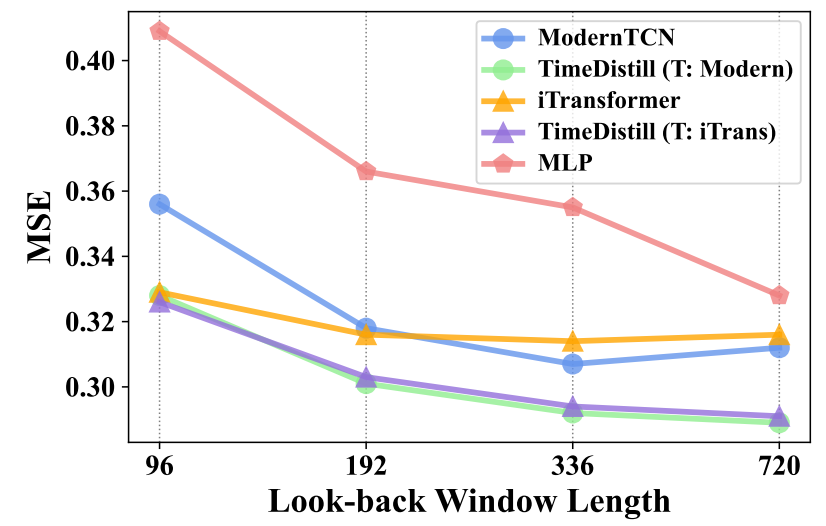
兼容多种回溯窗口长度
兼容多种回溯窗口长度
消融实验
TimeDistill通过消融实验进一步验证了模型设计的合理性。值得注意的是,即使去掉Ground Truth监督信号(w/o sup),TimeDistill仍然能够显著提升MLP预测精度,表明其可以从教师模型中有效学习到丰富的知识。
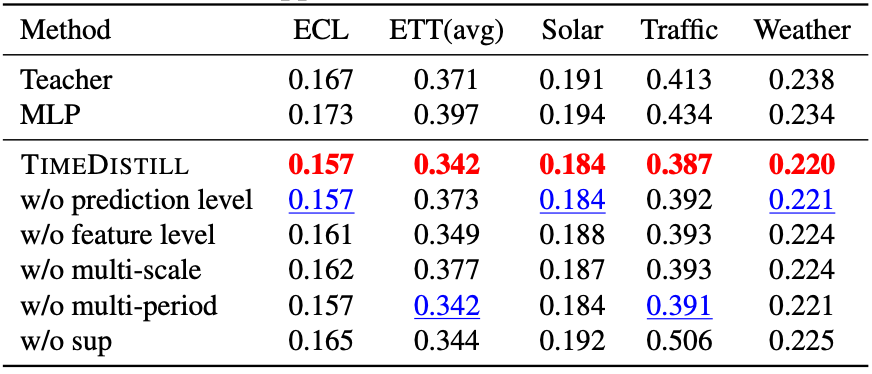
消融实验
消融实验
总结
TimeDistill 的提出,标志着时序预测领域正在向更高效、更通用的方向发展。它不仅展示了轻量级模型在蒸馏复杂模型知识后所能达到的卓越性能,还为学术界和工业界提供了新的思考方向:如何在计算成本、模型规模与预测精度之间找到最优平衡?如何通过知识蒸馏让轻量模型超越其原有能力上限?未来,期待更多研究机构与企业推动 TimeDistill 在金融、能源、流量预测等领域的广泛应用,为数据驱动时代的时序分析注入新的动力。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-03-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号