解密prompt系列51. R1实验的一些细节讨论
原创
解密prompt系列51. R1实验的一些细节讨论
原创
风雨中的小七
发布于 2025-03-21 07:34:40
发布于 2025-03-21 07:34:40
DeepSeek R1出来后业界都在争相复现R1的效果,这一章我们介绍两个复现项目SimpleRL和LogicRL,还有研究模型推理能力的Cognitive Behaviour,项目在复现R1的同时还针对R1训练策略中的几个关键点进行了讨论和消融实验,包括
- RL和SFT对比对于模型习得能力泛化性的影响?
- RL训练的领域外泛化效果
- 小模型是否能通过RL习得推理能力
- RL中规则目标函数的设定
- 前期warmup是否有必要
- 思考过程中的语言混合是否影响推理效果
- Kimi-1.5中使用的课程学习是否能提升测试集效果
- 是否所有模型都能通过RL激发出慢思考能力
LogicRL
Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning
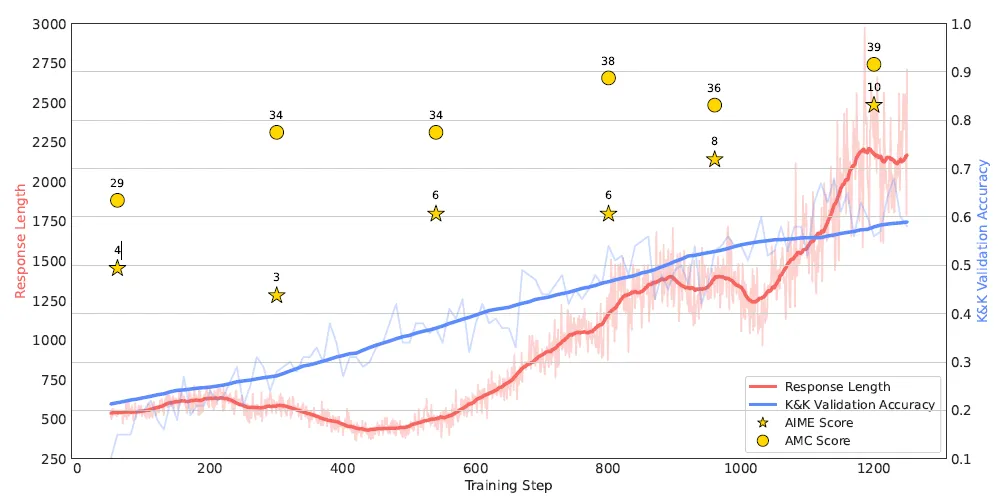
论文给出了在7B模型上有效,泛化性极佳的复现DeepSeek R1 RL训练的技术报告,并在训练过程中的几个关键变量上做了消融实验。这里我们只对比和R1-Zero训练的异同,以及技术报告在实验中的一些有趣发现,对DeepSeek R1技术细节不清楚的同学,可以先看解密prompt系列48. DeepSeek R1 & Kimi 1.5长思维链 - RL Scaling。
核心差异主要有2点,Logic-RL使用了7B的Qwen小模型,并验证了在小模型上RL训练同样带来领域外思考能力的显著提升在AIME提升125%,AMC提升52.5%。其次是数据集,论文训练采用可以程序化生成并人为控制难度的Knights & Knaves(K&K)逻辑谜题,只用5K的小样本训练就能在AIME,AMC等数学竞赛提上获得显著的跨领域提升。
和R1-Zero相同,LogicRL也采用了基于规则的奖励函数的设计,同样包含两个部分,分别是回答格式的约束和答案正确与否的约束,其中格式奖励函数定义为:

最终RL的奖励函数是以上两个函数的加和,论文选在在Qwen2.5-7B-Base模型上进行训练,RL训练的超参如下,lr=4*10^-7, temperature =0。7,观测训练阶段的稳定收敛

在训练过程中论文还有几个有趣的发现(哈哈个人感觉不太重要的几个点就不提了)
- 特定thinking Token(Wait,verify,yet)会带来模型reward打分的提升:不过感觉这个消融实验可以更严谨些,只对比了reward没有对比在测试集打分,以及是否带有特定thinking Token可能本身就会引入题目难度或类型的差异。
- 思考过程出现语言混合同样会降低模型reward打分:因此语言一致性penalty可能不只是为了提升可读性,也能提升推理效果。不过个人感觉这一点需要更充分的实验论证,有一点不太符合直觉。
- RL训练会带来显著的领域外迁移能力:逻辑思维是一种能力,不局限于训练的单一领域
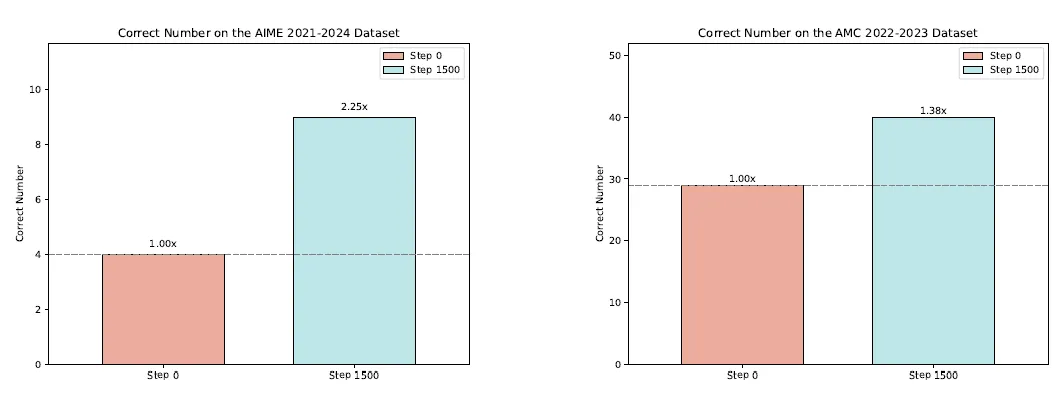
- RFT(SFT+Reject sampling)和RL的效果对比中RL显示出极佳的泛化性:论文的测试方案是对比不同训练策略下输入扰动对训练集准确率的影响。输入扰动越大SFT训练的模型效果越差,说明SFT确实更多通过强记进行学习。
- 课程学习在测试集上会带来效果提升:通过依次提升训练样本的思考难度(KK数据集的人数设定)让模型逐渐习得思考能力
- 使用Base还是Instruct模型效果上差异不大:但是看response Length的增长曲线Base模型训练中的波动更大,可能会比Instruct模型有多的可行空间探索。因为Instruct模型前期的SFT训练还是会对模型推理形成一定范围的约束。可能也需要更多的论证。
SimpleRL
同样是使用 Qwen2.5-Math-7B-Base,SimpleRL是使用8K的MATH数据集进行RL训练,SimpleRL在AIME和AMC上同样有非常显著的领域外的效果提升。
论文采用的奖励函数如下, 比Logic-RL的奖励函数设计还要更加简单
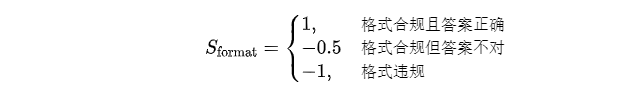
并且论文对是否需要进行Long-COT SFT warm-up进行了对比实验,
- 方案1:MATH数据进行RL训练,和R1-Zero相同
- 方案2:先使用QWQ-32B-Preview在8K的MATH样本上生成Long-COT数据,使用这部分数据进行SFT让模型先模仿学习长思考能力,之后再使用相同的数据进行RL探索适合自己的长思考能力,和R1相同
方案1的训练过程如下,在8个Benchark上,在训练过程中,准确率均能稳定上升,回答长度先下降再上升(来源于基模型本身偏向于输出代码,经过一段RL训练后代码风格消失带来的前期长度下降,前期的下降换个模型不一定能复现)。
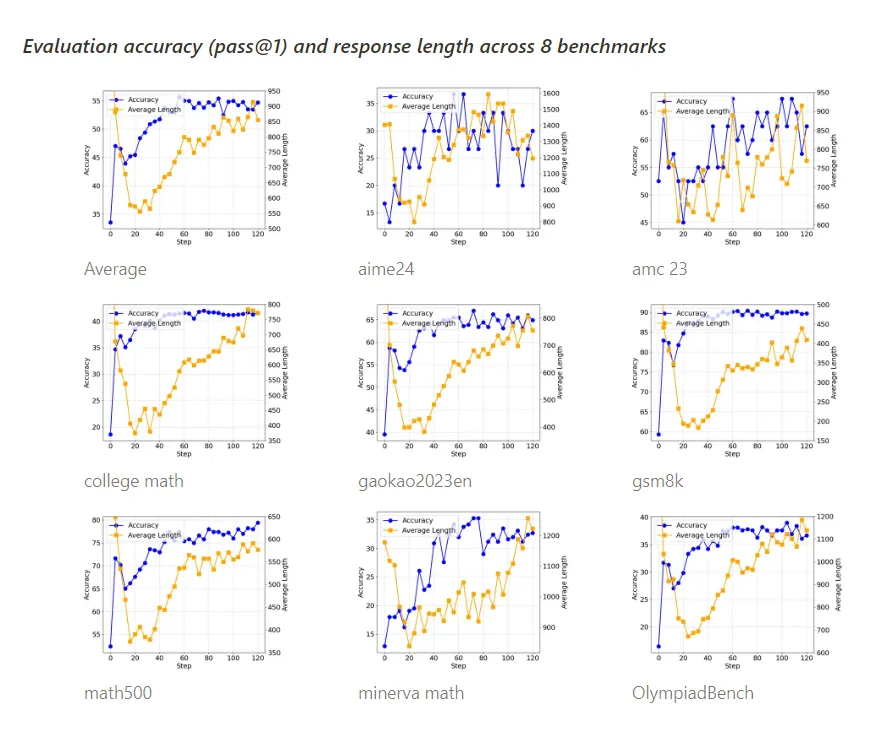
在step=40左右,观测到了模型反思类的思考过程的出现。
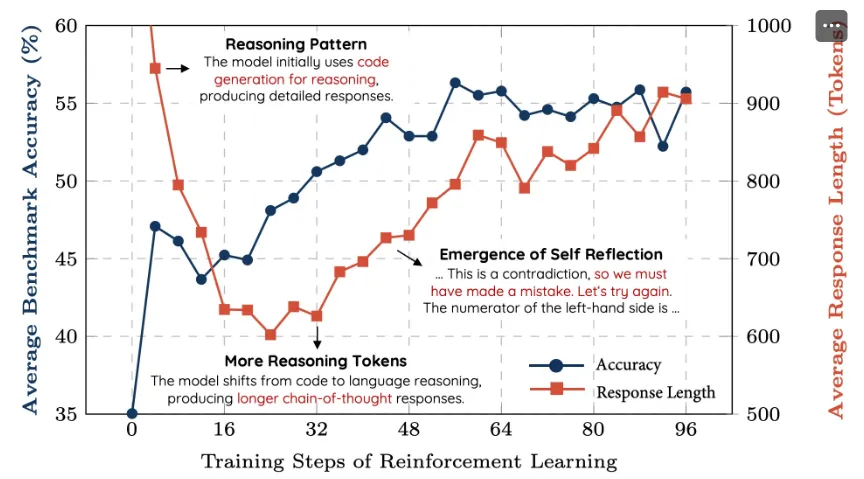
而方案2的训练过程和方案1类似,模型回答长度同样经历了先下降再上升的过程。说明前期模仿学习要么underfit,要么QWQ的输出分布和Qwen-7B存在显著差异,模型在RL过程中进行了重新的思考链路的探索。 效果对比上经过warmup的模型对比没有经过warmup的模型在3个基准上有提升,但是在AIME上有很显著的下降,因此是否需要warmup个人感觉还需要更多实验。几个值得进一步实验的点包括
- warmup和RL的数据集是否应该是不同的,甚至warmup的数据集难度是否应该更简单,从而避免在warmup阶段模型的过度模仿
- warmup的数据来源是否应该是输出分布更一致的模型系列,例如7B模型按方案1训练后再拒绝采样得到预热的样本集,而非从其他模型得到
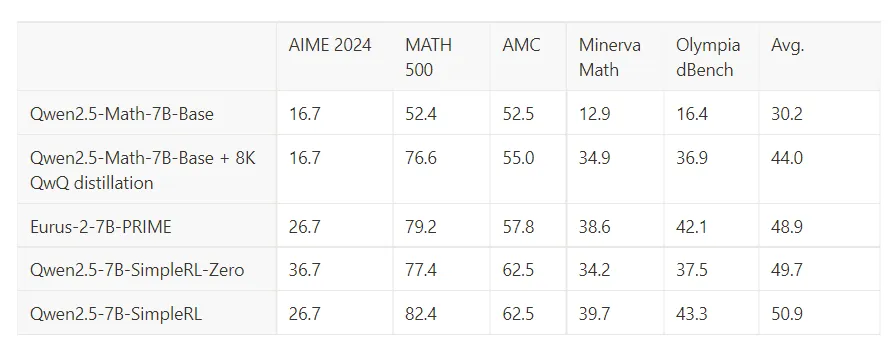
而前面准备测试的warmup数据的问题,在最近看到DeepSeek-R1复现:拒绝采样微调加速RL收敛及模型遗忘问题探究的博客中已经做了部分实验论证也。对比直接使用GSM8k的数据集做SFT,和使用RL训练后的模型推理生成的数据在原Base模型上重新做SFT,前者效果全面下降而后者在GSM8k上的效果和RL近似并且在其他领域外的效果也并未损失,说明warmup数据和基模型的分布一致性很重要。
Cognitive Behaviour
Cognitive Behaviors that Enable Self-Improving Reasoners, or, Four Habits of Highly Effective STaRs
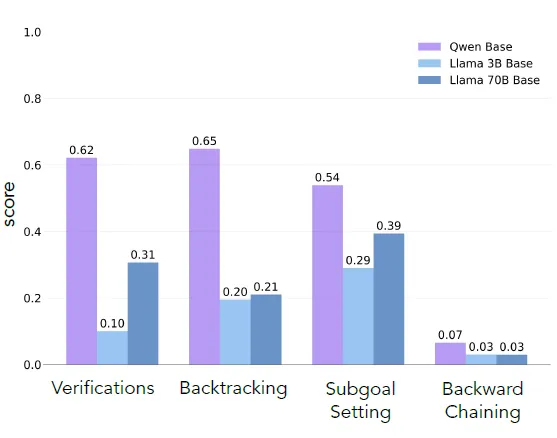
其他R1复现论文中心都在后面的训练以及数据构造流程,而这篇论文把关注点放在了Base模型上,论文发现不同的Base模型,经过相同的RL训练后,激发出的思考能力是不同的,例如Qwen-2.5-3B会显著优于Llama-3.2-3B,如下图所示,经过相同的RL训练,Qwen的思考能力和回答长度的提升要显著更加明显
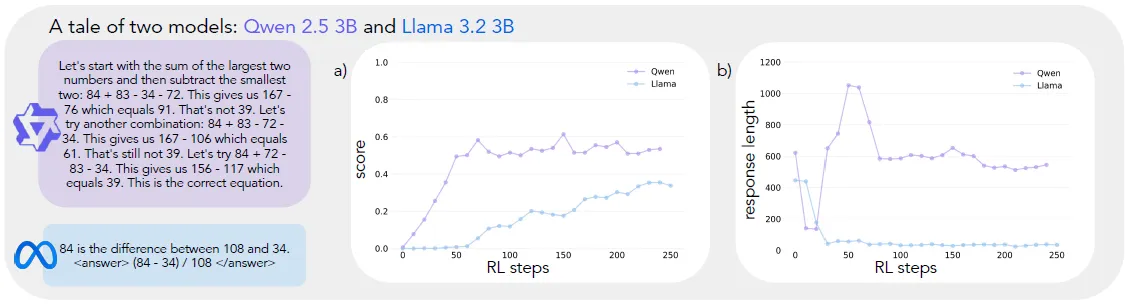
而论文给出的可解释观点是基模型的差异来自模型本身是否有基础的认知能力,包含但不限于Verification(错误检查), Backtracking(失败重试), Subgoal Setting(问题拆解), Backward Chaining(逆向思维)等思维模式。 论文选择这四种,只不过这些能力在大模型推理过程中更常见到,且更容易通过特殊Token或pattern进行识别。
这里论文是给出了这四种思维方式的定义,并借助GPT-4O-mini直接对思维过程进行分类识别,看是否出现了以上四种能力。(哈哈虽然但是有这么多论文在分析模型思维方式,但万一思维方式只是模型推理效果的Confounder而非Mediator呢?)
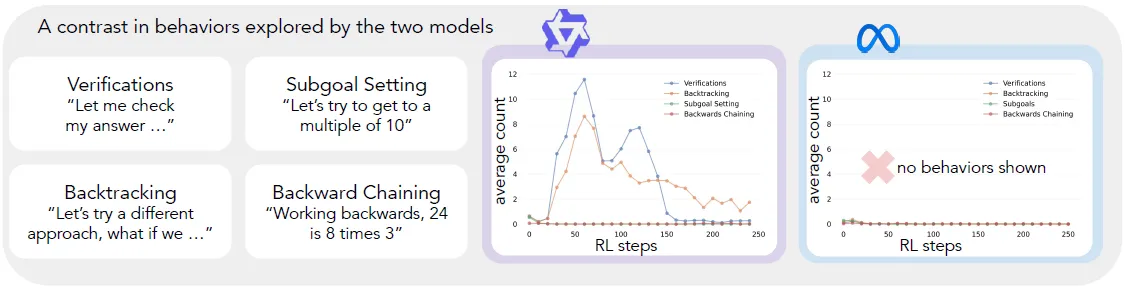
首先论文对比了Qwen2.5-3B,Llama-3B,Llama-70B原始的基座模型在推理过程中,以上四种能力的出现比例,发现Qwen原模型中四类思考模式的出现概率就要显著更高,而Llama系列显著更低,不过更大的Llama模型思考比例会出现明显上升。这个现象就可以形成一个猜测那原生基模型是否具备不同的思维方式,是否会影响后续RL激发思维能力的效果了呢?
论文分别从两个角度去尝试论证这个假设,分别通过SFT和修改预训练数据,增加不同类型的思维模式数据,让基模型在RL之前就具备不同的思维能力,再去做RL激发复杂长思考能力,并观测效果变化。
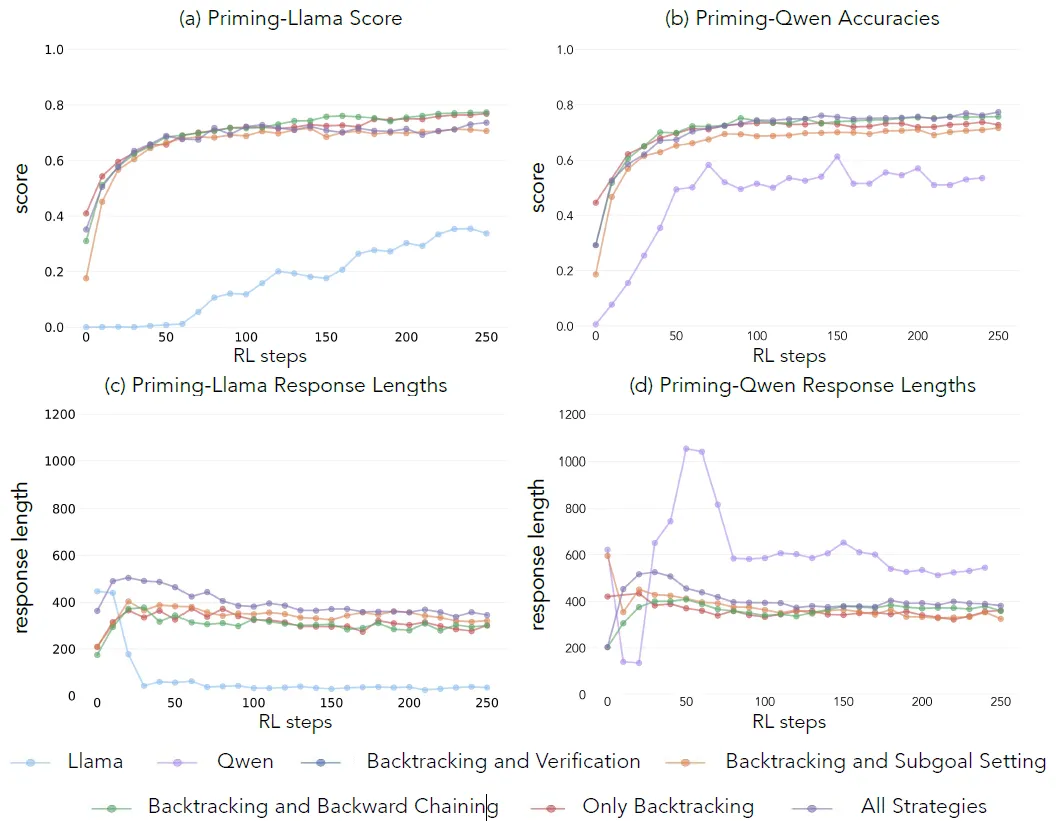
其次论文尝试从不同模型中引导出以上四种思维能力。论文使用CountDown数据集,并使用Claude-3.5-Sonnet模型用不同指令,让模型分别生成带有以上四种不同思维模式(但每种都有BackTracking),包含所有4种思维模式,不包含任意一种思维模式的COT,和COT长度相同但只有placeholder的思维链,总共7份数据集。并且以上数据集论文还单独做了一份答案全部错误的版本,相当于只训练能力,不训练模型作对题目。这样通过对比实验就能初步定为每一种思维模式对模型的具体影响。
实验结果显示,使用以上包含所有思维模式的数据集对模型思维模式进行冷启动后,再使用RL训练,在Qwen和Llama上均有明显的效果提升,Llama尤其明显,几乎可以打平Qwen,如下图所示。论文还更多对比了不同思维模式之间的抑制关系,不过感觉这部分的结论和数据集以及测试任务本身会有比较强的关联性,这里就不细展开啦。
最后论文还验证了预训练数据中思维能力相关的模式出现频率,使用Qwen-32B对OpenWebMath和FineMath等数学领域预训练模型进行识别,论文发现即便在数学领域的预训练数据中以上思维模式出现的频率也是很低的,说明预训练阶段对于学习以上思维模型并不充足,随后论文尝试在预训练数据中通过改写加入包含以上特定思考行为的样本,预训练后的Llama模型,再使用RL进行训练可以得到和以上Qwen相似的效果。
整体论文切入点比较有趣,但下一步更让人好奇的是Llama和Qwen基模型中思维模式的差异究竟是什么带来的呢?
想看更全的大模型论文·微调预训练数据·开源框架·AIGC应用 >> DecryPrompt
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号