第七章 AI数据质量-2

第七章 AI数据质量-2

7.5 样本数据快速扩充
数据增强是机器学习中的一项重要技术,用于生成大量高质量、多样化的训练数据集的方法。这种方法的出现背景主要是由于以下几个原因。
1.数据不足:对于许多AI任务,特别是计算机视觉任务,需要大量的标注数据来训练模型。然而,在现实世界中获取这些数据可能非常困难和昂贵,尤其是对于稀有或危险的场景。
2.数据多样性:为了训练出泛化能力强的AI模型,需要具有多样性的训练数据。然而,现实世界中的数据往往存在偏差,这可能导致模型在某些场景下表现不佳。
3.数据隐私:在某些应用场景下,使用真实数据可能涉及到隐私和法律问题。例如,在医疗领域,患者数据的使用受到严格的法律限制。
该技术旨在通过对现有数据应用各种变换来创建人工数据。数据增强的主要目标是使模型更加健壮,减少对原始训练数据集的依赖。在本节中,我们将讨论机器学习中常用的一些数据增强技术。
1.图像增强
图像增强是计算机视觉任务中常用的技术,如目标检测、图像分类和分割。该技术涉及对图像应用各种变换,如旋转、翻转、缩放、裁剪和剪切。这些变换有助于创建与原始图像相似但略有变化的新图像。例如,水平或垂直翻转图像可以创建原始图像的镜像图像,这在目标检测等任务中非常有用。
2.文本增强
文本增强是自然语言处理(NLP)任务中常用的技术,如情感分析、文本分类和机器翻译。该技术涉及对文本应用各种变换,如交换单词、改变单词顺序和添加同义词。这些变换有助于创建与原始句子相似但略有变化的新句子。例如,将单词“happy”更改为“delighted”可以创建一个具有类似含义的新句子。
3.音频增强
音频增强是语音识别、音乐分类和声音事件检测中常用的技术。该技术涉及对音频信号应用各种变换,如改变音调、添加噪声和时间拉伸。这些变换有助于创建与原始信号相似但略有变化的新音频信号。例如,改变声音的音调可以创建一个具有不同音调的新声音。
4.视频增强
视频增强是视频分析、动作识别和物体跟踪中常用的技术。该技术涉及对视频帧应用各种变换,如裁剪、缩放和翻转。这些变换有助于创建与原始帧相似但略有变化的新视频帧。例如,水平或垂直翻转视频帧可以创建原始帧的镜像图像。
5.合成数据生成
合成数据生成是一种使用计算机生成模型创建新数据的技术。当现实世界的数据不足或现有数据获取或标记成本高昂时,这种技术特别有用。合成数据生成涉及使用模型来模拟现实世界的数据来创建新数据。例如,可以训练一个模型来生成汽车的合成图像,以用于训练计算机视觉模型来检测现实世界中的汽车。
合成数据我们既可以通过AI的方式来合成,如传统的生成对抗网络(GAN: Generative Adversarial Networks)以及最新的扩散模型(Diffusion Model)来合成数据,同时我们也可以借助3D渲染引擎来合成数据,细节我们将在下面的章节展开。
总之,数据增强是一种强大的技术,可以帮助提高机器学习模型的性能。通过对现有数据应用各种变换,我们可以创建与原始数据相似但略有变化的新数据。这种技术可以帮助使模型更加健壮,减少对原始训练数据集的依赖。根据数据类型和任务的不同,可以使用多种数据增强技术。
下面我们将重点介绍几种合成数据的技术。
7.5.1 基于CV图像增强生成数据
本小节将介绍一些基于计算机视觉(CV: Computer Vision)的图像增强技术,包括旋转、翻转、缩放、裁剪、变形、加噪、滤波、颜色抖动等。
1.翻转:水平或垂直翻转图像是一种简单的增强技术,可以用来创建新的图像。这种技术特别适用于方向不重要的图像,如物体或景观的照片。水平翻转图像也可以用于增强面部识别等任务的数据集,其中同一人的图像可能来自不同的角度。
2.旋转:旋转图像可以用来创建不同角度旋转的新图像。这种技术特别适用于包含可以从不同角度查看的对象图像的数据集,如车辆或建筑物。通过旋转图像,我们可以创建模拟不同视角的新图像。
3.缩放:缩放图像涉及改变图像的大小。这对于包含对象可能以不同比例出现的数据集非常有用,如动物或植物的图像。通过缩放图像,我们可以创建模拟与对象的不同距离的新图像。
4.裁剪:裁剪图像涉及删除图像的一部分以创建新的图像。这种技术特别适用于对象可能部分遮挡或图像中可能有多个对象的数据集。通过裁剪图像,我们可以创建专注于特定对象或对象部分的新图像。
5.平移:平移图像涉及将图像在不同方向上移动。这种技术特别适用于对象可能出现在不同位置的数据集,如人或动物的图像。通过平移图像,我们可以创建模拟不同位置的新图像。
6.噪声:向图像添加噪声涉及向图像的像素值引入随机变化。这种技术特别适用于图像可能被损坏或噪声干扰的数据集,如医学图像或卫星图像。通过向图像添加噪声,我们可以创建模拟不同噪声或损坏程度的新图像。
7.颜色抖动:颜色抖动涉及通过调整图像的亮度、对比度、饱和度和色调来改变图像的颜色。这种技术特别适用于颜色可能很重要的数据集,如服装或艺术品的图像。通过应用颜色抖动,我们可以创建模拟不同光照条件或颜色变化的新图像。
8.弹性变换:弹性变换涉及通过对图像的像素应用随机变形来扭曲图像。这种技术特别适用于对象可能被扭曲或变形的数据集,如医学图像或地质形态的图像。通过应用弹性变换,我们可以创建模拟不同程度的变形或扭曲的新图像。
不同的图像增强技术可以根据具体的应用场景和数据类型进行选择和组合,以实现更好的机器学习和深度学习应用。除了上述技术外,还有一些其他的图像增强技术,如对比度增强、直方图均衡化、局部对比度增强等,这些技术可以进一步提高图像增强的效果和质量。
下面我们举一个基于Python的imgaug库的图像增强的例子,代码清单如代码段 1所示。
代码段1 图像增强示例
import imgaug.augmenters as iaa
import cv2
# 读取图像
image = cv2.imread("bird.jpg")
# 定义增强器
seq = iaa.Sequential([
iaa.Flipud(p=0.5), # 上下翻转
iaa.Affine(rotate=(-45, 45)), # 旋转
iaa.GaussianBlur(sigma=(0, 3.0)), # 高斯模糊
iaa.AdditiveGaussianNoise(scale=(0, 0.1*255)), # 加入高斯噪声
iaa.Crop(percent=(0, 0.2)) # 裁剪
])
# 对图像进行增强
image_aug = seq(image=image)
# 显示增强后的图像
cv2.imshow("Augmented Image", image_aug)
cv2.waitKey(0)
这个例子使用了imgaug库中的一些常用增强器,包括上下翻转、旋转、高斯模糊、加入高斯噪声和裁剪。首先,我们读取一张图像,然后定义一个增强器序列,其中包含了多个增强器。接着,我们使用增强器对图像进行增强,最后显示增强后的图像。实际效果如图7-5所示。

图7-5 原图与图像增强效果图
7.5.2 基于AI合成数据
合成数据生成技术是一种通过计算机程序或模型来生成人工数据的技术,可以用于增加数据集的大小和多样性,从而提高机器学习模型的性能和鲁棒性。
下面我们重点讲解下图像合成技术,介绍几种典型的合成方案。
图像合成是使用计算机算法生成图像的过程。它是计算机视觉、机器学习和人工智能等各个领域中的重要工具。通过图像合成生成的合成数据可以用于训练深度学习模型、测试算法和模拟真实世界的场景等各种应用。目前有许多流行的图像合成工具,本节将介绍其中一些常用的工具。
1.生成对抗网络(GAN)
生成对抗网络(GAN)是一种常用的图像合成工具。GAN由两个网络组成,一个是生成器网络,另一个是判别器网络。生成器网络生成合成数据,而判别器网络区分真实数据和合成数据。这些网络以对抗的方式进行训练,生成器试图生成可以欺骗判别器的合成数据,而判别器试图区分真实数据和合成数据。GAN已被用于各种图像合成应用,包括生成逼真的图像、风格迁移和数据增强等。
2.变分自编码器(VAE)
变分自编码器(VAE: Variational Autoencoder)是另一种常用的图像合成工具。VAE是一种生成模型,学习表示输入数据的概率分布。VAE由一个编码器网络和一个解码器网络组成。编码器网络将输入数据映射到一个潜在空间,解码器网络将潜在空间映射回输入数据空间。VAE被训练以最大化输入数据的似然性,同时最小化潜在分布和先验分布之间的距离。VAE已被用于各种图像合成应用,包括生成新图像、图像插值和数据增强等。
2.StyleGAN
StyleGAN是一种生成高质量图像的GAN,具有逼真的细节和多样的风格。StyleGAN使用一种新颖的架构,将高级特征和低级细节的生成分离。高级特征使用控制图像整体外观的样式向量生成,而低级细节使用添加随机性的噪声向量生成。StyleGAN已被用于各种图像合成应用,包括生成逼真的人脸、动物和风景等。
3.CycleGAN
CycleGAN是一种无需成对数据即可学习将图像从一个域转换到另一个域的GAN。CycleGAN由两个GAN组成,一个是将输入图像从一个域转换到另一个域的生成器网络,另一个是区分真实图像和合成图像的判别器网络。CycleGAN使用循环一致性损失进行训练,以确保转换后的图像可以转换回原始域。CycleGAN已被用于各种图像合成应用,包括风格迁移、物体变形和图像着色等。
5.Deepfake技术
Deepfake是一种利用深度学习技术生成虚假视频或图片的技术。它可以将一个人的脸部特征和表情合成到另一个人的身上,从而制作出看起来非常逼真的虚假视频或图片。
Deepfake技术使用生成对抗网络(GAN)或是基于自编码器(Autoencoder)技术来实现。下面我们简单介绍下基于自编码器实现换脸的基本原理。
自编码器是一种无监督学习模型,它由编码器(Encoder)和解码器(Decoder)两部分组成。编码器将输入图像压缩成一个低维向量,解码器将这个向量还原成原始图像。在训练过程中,自编码器的目标是最小化输入图像和重构图像之间的差异。在训练阶段,我们使用相同的Encoder来将两个人脸的共性特征(如:表情、姿态等)提取出来,然后用两个不同的Decoder分别还原各自的人脸,如图7-6所示。
接着在换脸阶段,如图7-7所示,我们通过交换Decoder,将其中一个人脸的特征用另一个人脸来呈现,从而达到换脸的目的。
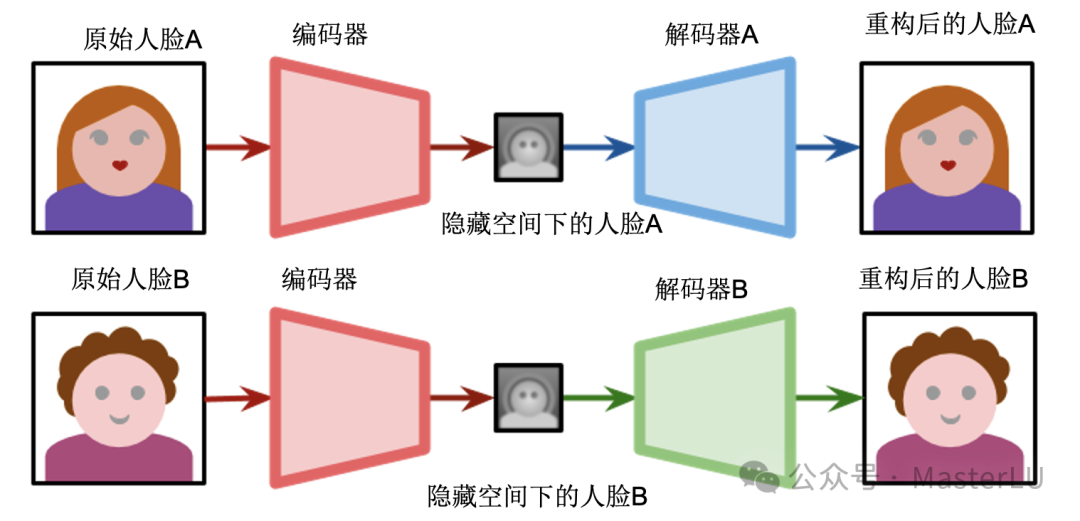
图7-6 基于Autoencoder的Deepfake训练阶段
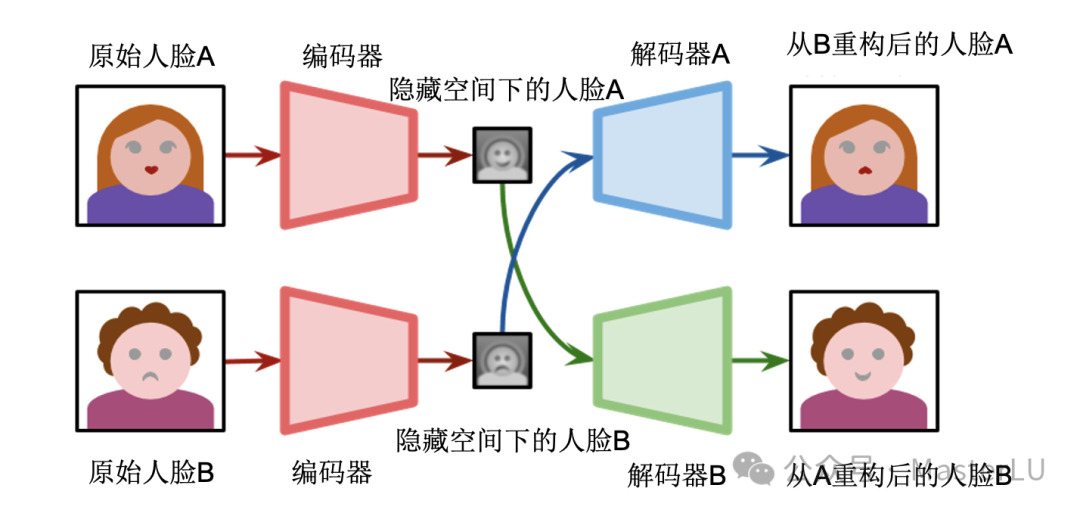
图7-7 基于Autoencoder的Deepfake换脸
为了创建Deepfake视频或图像,生成网络会在大量的被复制人的图像或视频数据集上进行训练。然后,网络使用这些训练数据来创建被复制人的数字模型,该模型可以被操纵以产生所需的面部表情或动作。生成网络的输出然后被馈送到判别网络中,判别网络评估视频或图像的真实性。
这个过程会重复多次,直到生成网络的输出足够逼真,可以欺骗判别网络。一旦判别器被欺骗,输出就被认为是一个成功的Deepfake。
Deepfake技术可以帮助我们增加测试样本,因为它可以生成逼真的虚假图像和视频,这些虚假数据可以用于训练和测试机器学习模型。通过使用Deepfake技术生成虚假数据,我们可以扩大数据集的规模,从而提高模型的准确性和鲁棒性。
例如,在人脸识别领域,使用Deepfake技术可以生成大量的虚假人脸数据,这些数据可以用于训练和测试人脸识别模型。这些虚假数据可以包括不同年龄、性别、种族和表情的人脸,从而使模型更加全面和准确。
需要注意的是,使用Deepfake技术生成虚假数据也存在一些风险和挑战,例如虚假数据可能会导致模型过度拟合或无法泛化到真实数据上。因此,在使用Deepfake技术进行数据增强时,需要谨慎评估其效果和风险,并采取适当的措施来确保模型的准确性和鲁棒性。
腾讯云开发者
