【网络编程】十四、五种常见IO模型详解

【网络编程】十四、五种常见IO模型详解

Ⅰ. 五种常见IO模型
以前我们在学习系统 IO 的时候,学到了阻塞式 IO 和非阻塞式 IO,但这远远不够,因为在网络通信中,这两种 IO 模型的效率并不高!
此外我们需要明白的是,IO 的本质,其实就是等待 + 数据拷贝。而上述的两种 IO 模型,其实大部分时间都是在等待,这就是它们效率不高的原因!那意思就是说,只要我们 减少等待时间的比重,那不就提高了 IO 的效率了吗!
下面在学习更高效率的 IO 模型之前,我们先来学习常见的五种 IO 模型!
1、举一个钓鱼的例子
直接讲五种 IO 模型的话,会比较生涩,所以这里用一个钓鱼的例子来引入这些模型!
有一个钓鱼的好日子,张三拿着水桶,去一个水塘钓鱼,他拿着鱼竿,将鱼钩和鱼漂往水塘丢去,然后就坐着啥也没干,一直看着鱼漂的情况,一旦有鱼就会往上提竿。
此时李四也来钓鱼,和张三一样,也是拿着鱼竿,将鱼钩和鱼漂往水塘丢去,但不同的是,李四觉得等待鱼上钩时间太长了,并且自己抓着鱼竿是可以迅速提竿的,所以李四在坐着等待的时候,并不是啥也没干,而是过一会就拿着一本书在读,或者拿着手机玩,但是李四会时不时的看向鱼漂是否有动静。
王五也来钓鱼了,但是他的钓鱼方式和前两个人就不太一样了,他用固定架固定好鱼竿之后,将鱼钩和鱼漂往水塘丢去,并且他在鱼漂上面绑上了一个铃铛,然后王王就直接头也不抬的玩手机了,只要铃铛一响,王五才会马上去抓起鱼竿。
此时赵六也来钓鱼了,但和前三者不同,他带了五十只鱼竿,并且用固定架都固定好鱼竿,同时将它们的鱼钩和鱼漂往水塘里丢去,然后赵六就开始在五十只鱼竿之间来回走动,相当于遍历,观察看哪只鱼漂有动静,有动静了就马上进行提竿!
一位老板田七,由驾驶员小明开车准备送去公司,此时路过池塘,看到四人都在钓鱼,而田七是喜欢吃鱼,但他不喜欢钓鱼,所以田七就给小明一套钓鱼装备(和张三差不多)去钓鱼,并且拿了一个桶给小明,让小明钓到整个桶都是鱼之后,打电话告诉田七,田七再来接他回公司,而田七现在自己开车回公司解决业务问题!
你认为上述五个人(张三、李四、王五、赵六、田七)谁钓鱼的效率最高,换句话说,因为 钓鱼时间=等待时间+提竿时间,而提竿时间是差不多的,那么看谁效率高,其实就是看谁的等待时间最短。
可以发现,其实 赵六的钓鱼方式效率最高,因为其等待时间是最短的,因为赵六有多个鱼竿,那么鱼上钩的几率也会大很多,而鱼上钩一多,因为有多个鱼竿,那么赵六提一支之后在很短时间内其实又可以提一支。
可能看似田七都没去钓鱼,效率最高,但其实不是的,因为如果按一个桶的时间来算的话,小明钓的鱼还是比赵六要少很多,效率还是不如赵六的钓鱼方式!
我们可以把上面的例子转变一下:
- 鱼:数据
- 池塘:内核空间
- 鱼漂有动静:数据就绪的事件
- 鱼竿:文件描述符
- 钓鱼的动作:
read/recv系统调用 - 张三/李四/王五/赵六/田七:进程/线程
- 小明:操作系统
这样子我们就能很清晰的映射到系统中的 IO 模型。
而其实上面的五种钓鱼方式,分别对应了五种 IO 模型,如下所示:
- 阻塞式
IO:一直阻塞着直到 - 非阻塞式
IO - 信号驱动式
IO - 多路转接/多路复用
- 异步
IO
其中,前四种 IO 方式,都属于同步IO,因为这些进程或者线程都亲自参与了 IO 处理,而第五种方式是 异步IO,因为该进程/线程不直接参与 IO 处理,而是让操作系统处理完之后(本质也是阻塞或者非阻塞的形式处理)进行通知。
而这五个 IO 模型也是我们在进行 IO 时候最基础的模型!
要注意的是,这里所说的 同步IO,和 线程同步机制 是不一样的,是两个不同的概念,注意不要搞混了!
并且其实前三种 IO 模型,它们的效率都是差不多的,但是 非阻塞式IO 和 信号驱动式IO 可以做其它事情,而 阻塞式IO 则做不到,所以 前三种 IO 模型的差异体现在等待的方式不同!
那还有一个问题,就是 信号驱动式IO,究竟是等待了,还是没等待呢❓❓❓
答案是肯定等待了,不然的话王五就不需要在鱼竿旁边守着了,只不过是等待的方式不同于前两种 IO 模型罢了!
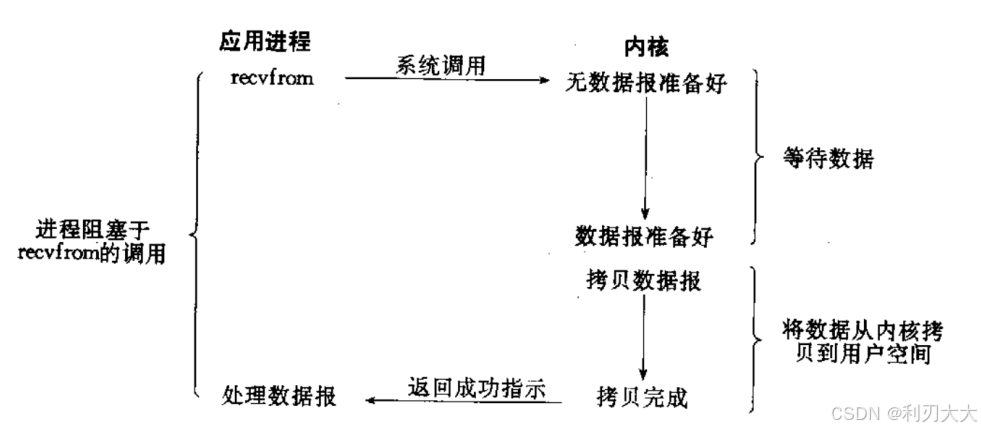
2、阻塞式IO
阻塞式IO:在内核将数据准备好之前,系统调用会一直等待,不做其它事情。所有的套接字接口,默认都是阻塞方式,并且 阻塞式IO 也是最常见的模型,因为它最简单!
3、非阻塞式IO
非阻塞IO:如果内核还未将数据准备好,系统调用仍然会直接返回,并且返回 EWOULDBLOCK 错误码。
这种模型往往需要程序员循环的方式反复尝试读写文件描述符,这个过程称为 轮询。虽说比起 阻塞式IO 来说,这种模型可以做一些其它的事情,但是这对 CPU 来说是较大的浪费,一般只有特定场景下才使用。

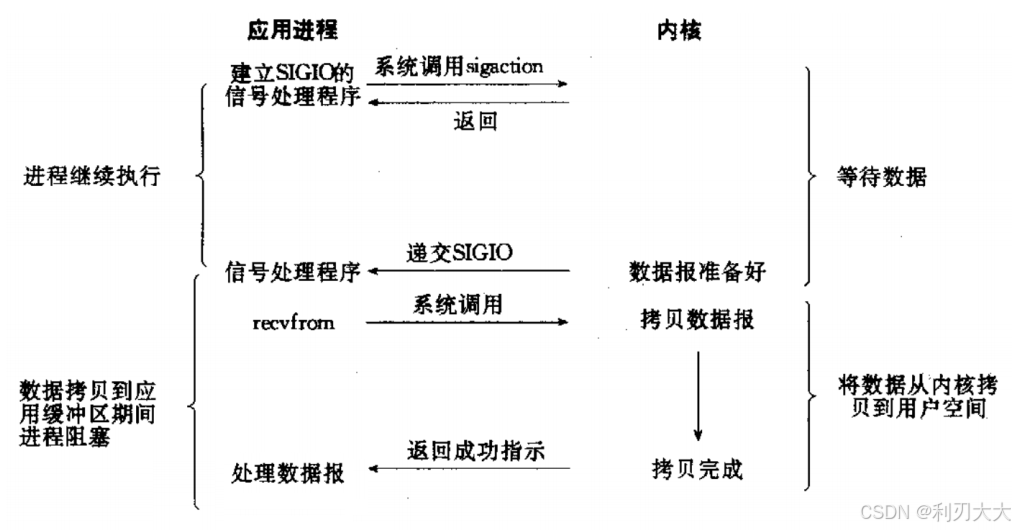
4、信号驱动式IO
信号驱动IO:内核将数据准备好的时候,使用 SIGIO 信号通知应用程序进行 IO 操作。
这个 SIGIO 信号是需要提前设置的。此外,这种模型实际用的也很少!
5、多路转接式IO
多路转接:也称为多路复用,虽然从流程图上看起来和上面的 信号驱动式IO 类似,但实际上 最核心在于多路转接能够同时等待多个文件描述符的就绪状态,而 信号驱动式IO 以及前面的 阻塞/非阻塞式IO 都只是等待一个文件描述符的就绪状态!
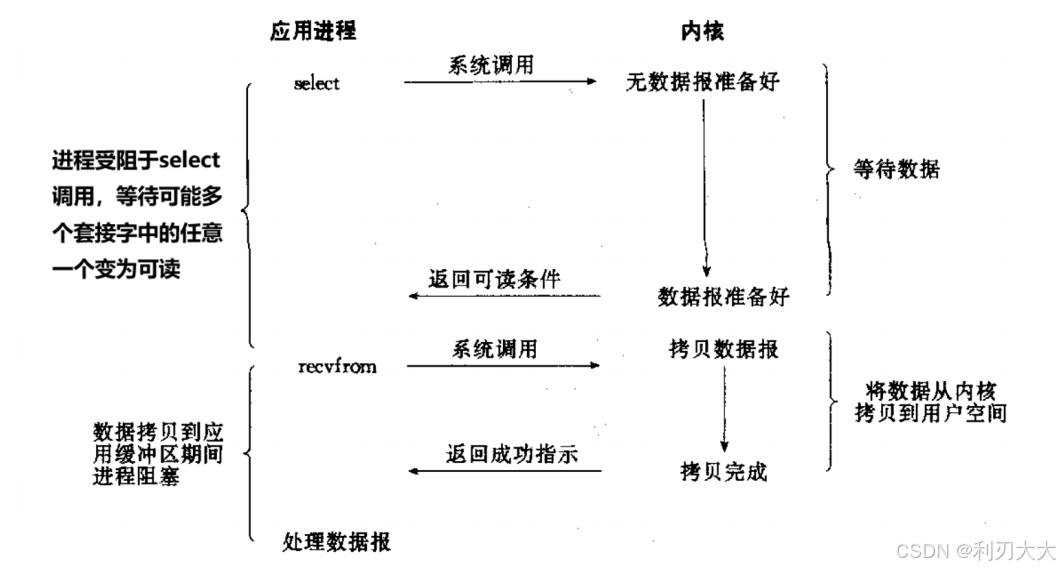
而为了实现多路转接,那么就有了 select、poll、epoll 等系统调用接口供我们使用,这也是我们后面学习的重点!
而多路转接其实效果和开辟多个进程/线程然后进行对多个文件描述符的监听,其实是一样的,但不同的是,通过 select 等接口来进行多路转接的话,其实是对多个文件描述符的聚合,并不会像开辟多个进程/线程一样需要花费很多的资源。
简单地说,select、poll、epoll 等系统调用接口即能达到多路转接效果,又能减少多路转接的资源开销!
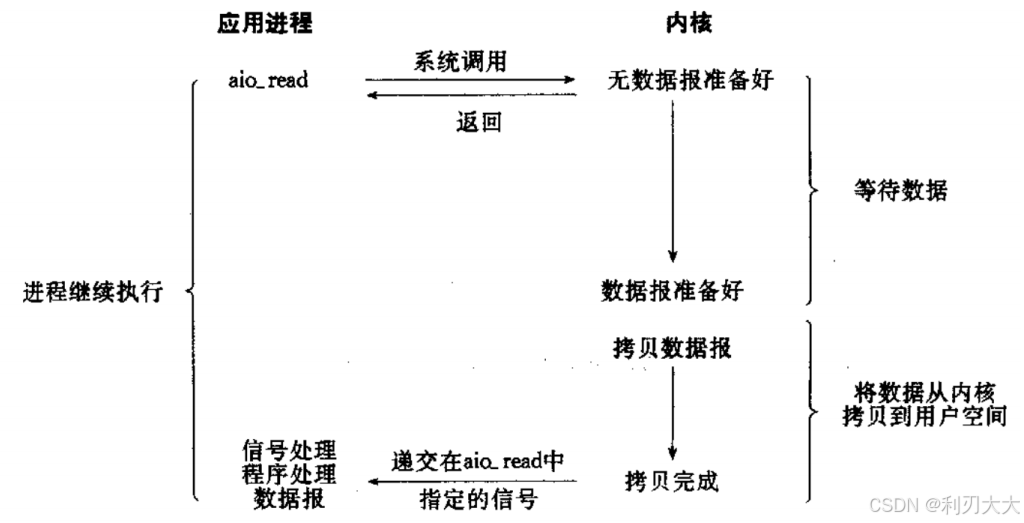
6、异步IO
异步IO:由内核(即操作系统)数据拷贝完成后,通知应用程序进行数据处理即可,而信号驱动是告诉应用程序何时可以开始拷贝数据。
简单地说,异步就是不需要当前进程/线程去执行数据的等待以及拷贝,而 由操作系统替它完成。
小结
任何 IO 过程中,都包含两个步骤:等待 和 拷贝。
而在实际的应用场景中,等待消耗的时间往往都远远高于拷贝的时间。让 IO 更高效,最核心的办法就是让等待的时间尽量少。
Ⅱ. 高级IO重要概念
1、同步 && 异步
首先我们要知道的是,同步(synchronous communication)和异步(asynchronous communication)关注的是消息通信机制,这和之前我们学习的进程/线程同步是不一样的,进程/线程同步是进程/线程之间直接的制约关系!
- 所谓同步,就是在发出一个调用时,在没有得到结果之前,该调用就不返回。但是一旦调用返回,就得到结果了。换句话说,就是由调用者主动等待这个调用的结果。
- 异步则是相反,调用在发出之后,这个调用就直接返回了,所以没有返回结果。换句话说,当一个异步过程调用发出后,调用者不会立刻得到结果;而是在调用发出后,被调用者通过状态来通知调用者,或通过回调函数处理这个调用。
要注意的是,在 IO 模型 中,同步和异步区分的是内核向应用程序通知的是何种 IO 事件(是就绪事件还是已完成事件),以及该由谁来完成 IO(是由应用程序还是内核)。而在 并发模式 中,同步指的是程序完全按照代码序列的顺序执行,异步指的是程序的执行需要由系统事件来驱动。
这几个概念注意区分!
2、阻塞 && 非阻塞
阻塞和非阻塞关注的是程序在等待调用结果(消息 && 返回值)时的状态。
- 阻塞调用是指调用结果返回之前,当前线程会被挂起,调用线程只有在得到结果之后才会返回
- 非阻塞调用指在不能立刻得到结果之前,该调用不会阻塞当前线程
3、其他高级IO
非阻塞IO、纪录锁、系统V流机制、多路转接、readv和 writev 函数以及存储映射IO(mmap),这些统称为高级IO。
Ⅲ. 非阻塞式IO
1、fcntl 函数
一个文件描述符,默认是阻塞 IO,但是我们可以用 fcntl 函数来修改一下!
其函数原型如下所示:
#include <unistd.h>
#include <fcntl.h>
int fcntl(int fd, int cmd, ... /* arg */ );
// 功能:操作文件描述符
// 返回值:cmd不同,成功的返回值也不同;但是失败的话统一返回-1
// 参数:
// fd:要操作的文件描述符
// cmd:本质就是宏,不同的宏代表不同的选项
// 可变参数列表:当cmd参数为设置型参数的时候,该可变参数才会起作用,表示设置的属性 传入的 cmd 的值不同,后面追加的参数也不相同。
所以下面根据 cmd 的值,fcntl 函数可以分为 5 种功能:
- 复制一个现有的描述符(
F_DUPFD) - 获得/设置文件描述符标记(
F_GETFD或F_SETFD) - 获得/设置文件状态标记(
F_GETFL或F_SETFL)- 当设置了
F_SETFL之后,在linux中可以修改O_APPEND、O_ASYNC、O_DIRECT、O_NOATIME和O_NONBLOCK属性,其中我们需要的就是最后一个非阻塞属性!
- 当设置了
- 获得/设置异步I/O所有权(
F_GETOWN或F_SETOWN) - 获得/设置记录锁(
F_GETLK或F_SETLK或F_SETLKW)
下面举例子的时候,我们只用第三种功能,获取/设置文件状态标记,就可以将一个文件描述符设置为非阻塞,即 O_NONBLOCK。
2、举例子感受一下阻塞和非阻塞的区别
阻塞读取
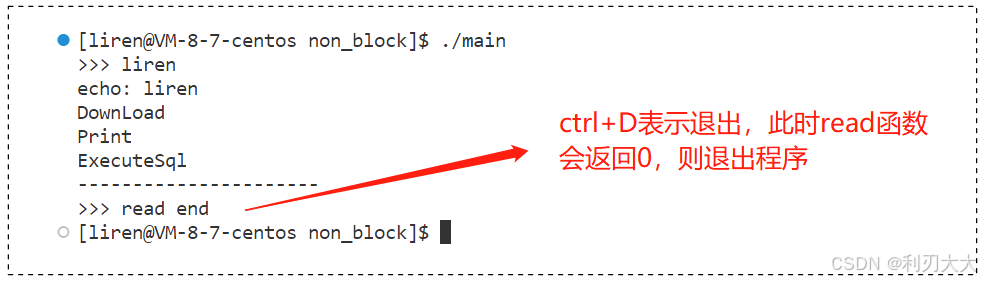
我们在 main.cc 中,采用轮询的方式,读取用户的标准输入,首先我们先来使用阻塞的方式进行读取:
#include <cstdio>
#include <vector>
#include <functional>
#include "util.hpp"
using func_t = std::function<void()>; // 函数类型重命名
// 加载一些功能函数
#define INIT(v) do{\
v.push_back(DownLoad);\
v.push_back(Print);\
v.push_back(ExecuteSql);\
}while(0)
// 执行数组中的功能函数
#define RUN(callbacks) do{\
for(const auto & e : callbacks) e();\
}while(0)
int main()
{
std::vector<func_t> v; // 创建数组,元素类型是函数,相当于是回调函数
INIT(v); // 加载函数
char buffer[1024]; // 接收缓冲区
while(true)
{
printf(">>> ");
fflush(stdout); // 进行刷新,不然>>>会一直在缓冲区没刷出来
// 对标准输入进行读取
ssize_t n = read(0, buffer, sizeof(buffer) - 1);
if(n > 0)
{
// 收到有内容的数据,简单的进行打印
buffer[n - 1] = 0;
std::cout << "echo: " << buffer << std::endl;
}
else if(n == 0)
{
// 表示连接关闭
std::cout << "read end" << std::endl;
break;
}
else
{}
// 执行数组中的功能函数
RUN(v);
std::cout << "----------------------" << std::endl;
}
return 0;
} 而功能函数比较简单,这里在 util.hpp 头文件中实现,如下所示:
#include <iostream>
#include <unistd.h>
#include <fcntl.h>
void DownLoad()
{
std::cout << "DownLoad" << std::endl;
}
void Print()
{
std::cout << "Print" << std::endl;
}
void ExecuteSql()
{
std::cout << "ExecuteSql" << std::endl;
} 下面我们运行代码,看看效果:

然后我们试试看用 ctrl+D 快捷键来关闭输入,看看效果如何:
非阻塞读取
基于 fcntl,首先我们实现一个 setNonBlock 函数,将文件描述符设置为非阻塞,在 util.hpp 中实现,如下所示:
#include <iostream>
#include <unistd.h>
#include <fcntl.h>
void setNonBlock(int fd)
{
int flag = fcntl(fd, F_GETFL); // 获取文件描述符的标记
if(flag == -1)
{
perror("fcntl");
return;
}
// 设置文件描述符的标记为非阻塞
fcntl(fd, F_SETFL, flag | O_NONBLOCK);
} 其中使用 F_GETFL 表示将当前的文件描述符的属性取出来(本质是一个位图)。然后再使用 F_SETFL 将文件描述符设置回去,设置回去的同时,加上一个 O_NONBLOCK 参数表示非阻塞。
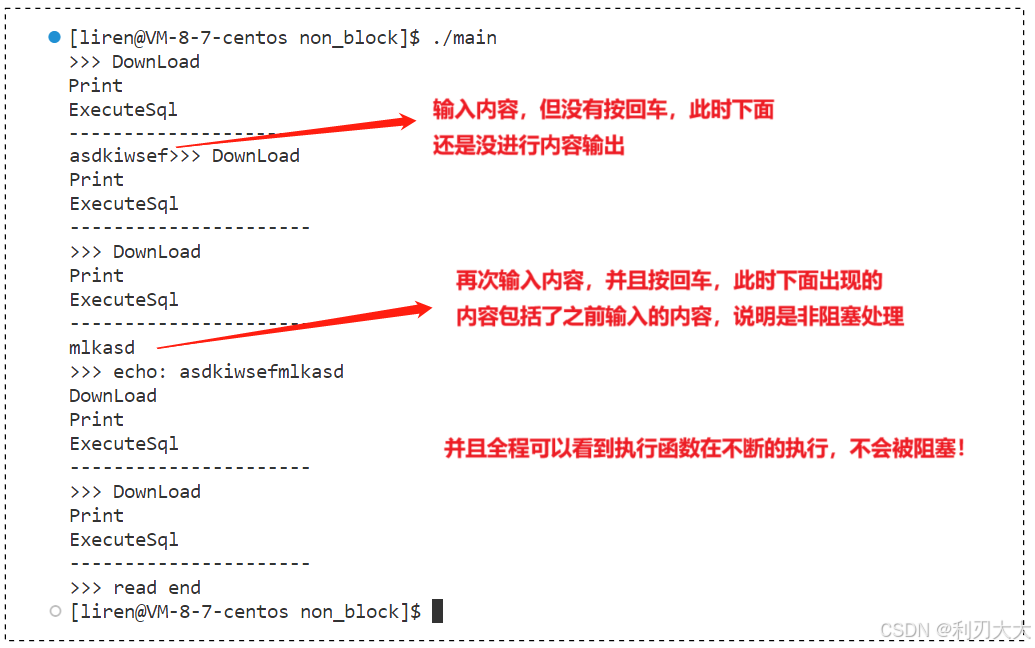
然后我们将 main.cc 中的细节稍加修改(只需要看代码注释的部分即可):
#include <cstdio>
#include <vector>
#include <functional>
#include "util.hpp"
using func_t = std::function<void()>;
#define INIT(v) do{\
v.push_back(DownLoad);\
v.push_back(Print);\
v.push_back(ExecuteSql);\
}while(0)
#define RUN(callbacks) do{\
for(const auto & e : callbacks) e();\
}while(0)
int main()
{
std::vector<func_t> v;
INIT(v);
// 设置非阻塞等待
setNonBlock(0);
char buffer[1024];
while(true)
{
printf(">>> ");
fflush(stdout);
ssize_t n = read(0, buffer, sizeof(buffer) - 1);
if(n > 0)
{
buffer[n - 1] = 0;
std::cout << "echo: " << buffer << std::endl;
}
else if(n == 0)
{
std::cout << "read end" << std::endl;
break;
}
else
{}
RUN(v);
std::cout << "----------------------" << std::endl;
sleep(1); // 睡眠一会
}
return 0;
} 下面来执行一下,看看效果怎么样:
3、错误返回时候的处理
上面其实遗漏了一个问题,就是当 read 函数返回值是 -1 也就是读取失败的情况,其实当我们没有输入的时候,并且这个文件描述符还是非阻塞的状态,那么 read 函数也会返回 -1,如下所示(下面删减了一些不必要的代码和注释):
#include <cstdio>
#include "util.hpp"
#define RUN(callbacks) do{\
callbacks();\
}while(0)
int main()
{
// 设置非阻塞等待
setNonBlock(0);
char buffer[1024];
while(true)
{
printf(">>> ");
fflush(stdout);
ssize_t n = read(0, buffer, sizeof(buffer) - 1);
if(n > 0)
{
buffer[n - 1] = 0;
std::cout << "echo: " << buffer << std::endl;
}
else if(n == 0)
{
std::cout << "read end" << std::endl;
break;
}
else
{
std::cout << "read error" << std::endl;
}
RUN(DownLoad);
std::cout << "---------------------------------------" << std::endl;
sleep(2);
}
return 0;
} 来看看运行效果:

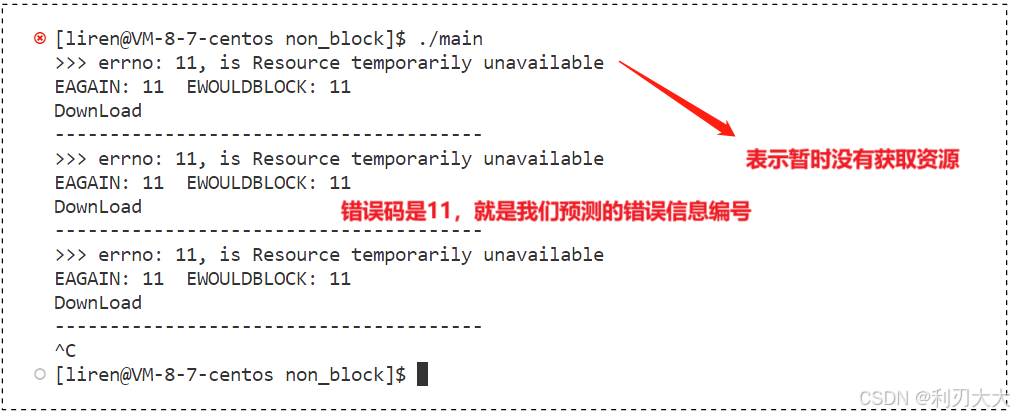
可以看到,当我们没有输入内容的时候,并且标准输入的文件描述符被我们设置为非阻塞,此时 read 函数返回的就是 -1,表示读取错误,但问题是,我们不输入内容,并不能算是错误啊,所以我们 单靠 read 函数的返回值,并不能判断是没有输入信息还是真的读取错误!
所幸 read 函数提供了一些错误信息,也就是宏,我们可以在 man 手册中查到常见的几个:
EAGAIN/EWOULDBLOCK:这两个宏都是一样的,表示非阻塞操作时的一个错误码。当没有数据可供读取,并不表示出现了错误。所以当使用非阻塞IO模式进行读取时,如果没有数据可用于读取,read()函数将立即返回,并设置errno为EAGAIN或者EWOULDBLOCK。EBADF:传入的fd不是一个有效的文件描述符,或者未打开读取通道,read()函数将立即返回,则设置errno为该宏。EFAULT:当传入的缓冲区不在用户能访问的地址空间时候,read()函数将立即返回,则设置errno为该宏。EINTR:当数据还没读取完之前,就被信号中断了,read()函数将立即返回,并且设置errno为该宏。- ……
其中我们这里要关注的,就是第一个 EAGAIN / EWOULDBLOCK,我们可以使用 strerror(errno) 来看看打印的错误信息是什么,所以我们将上面代码稍微改动一下:
else
{
std::cout << "errno: " << errno << ", is " << strerror(errno) << std::endl;
std::cout << "EAGAIN: " << EAGAIN << " EWOULDBLOCK: " << EWOULDBLOCK << std::endl;
}
所以,我们 不能单纯的以 read 函数的错误返回值 -1 来判断出现什么错误,我们还需要根据这些错误信息来分类处理,如下所示:
#include <cstdio>
#include "util.hpp"
#define RUN(callbacks) do{\
callbacks();\
}while(0)
int main()
{
// 设置非阻塞等待
setNonBlock(0);
char buffer[1024];
while(true)
{
printf(">>> ");
fflush(stdout);
ssize_t n = read(0, buffer, sizeof(buffer) - 1);
if(n > 0)
{
buffer[n - 1] = 0;
std::cout << "echo: " << buffer << std::endl;
}
else if(n == 0)
{
std::cout << "read end" << std::endl;
break;
}
else
{
// 分情况讨论,这里只列举两种读取情况,具体可以根据需要自行完善!
if(errno == EAGAIN || errno == EWOULDBLOCK)
{
std::cout << "未输入数据,并不是读取错误!" << std::endl;
}
else if(errno == EINTR)
{
std::cout << "读取被中断,需要继续上一次的读取!" << std::endl;
continue;
}
else
{
std::cout << "读取错误!" << std::endl;
break;
}
}
RUN(DownLoad);
std::cout << "---------------------------------------" << std::endl;
sleep(2);
}
return 0;
}
腾讯云开发者
