如何设计一个服务器文件实时监测系统:架构设计合集(四)

如何设计一个服务器文件实时监测系统:架构设计合集(四)

TechVision大咖圈
发布于 2025-07-17 08:33:16
发布于 2025-07-17 08:33:16
引言:为什么需要文件安全监测
在这个数字化时代,服务器就像是我们的"数字金库",里面存放着各种珍贵的数据资产。但是,你有没有想过,如果有"小偷"悄悄潜入这个金库,偷偷修改或删除文件,我们能第一时间发现吗?
传统的安全防护往往是"亡羊补牢"式的,等发现问题时,损失已经造成。而一个优秀的文件安全异常实时监测系统,就像是给我们的服务器安装了一双"火眼金睛",能够实时感知任何风吹草动。
系统需要解决的核心问题:
- 🔍 实时监控文件的增删改操作
- 🚨 快速识别异常行为模式
- 📊 提供可视化的安全态势感知
- 🔔 及时告警和响应机制
系统整体架构设计
让我们先来看看整个系统的"全景图":
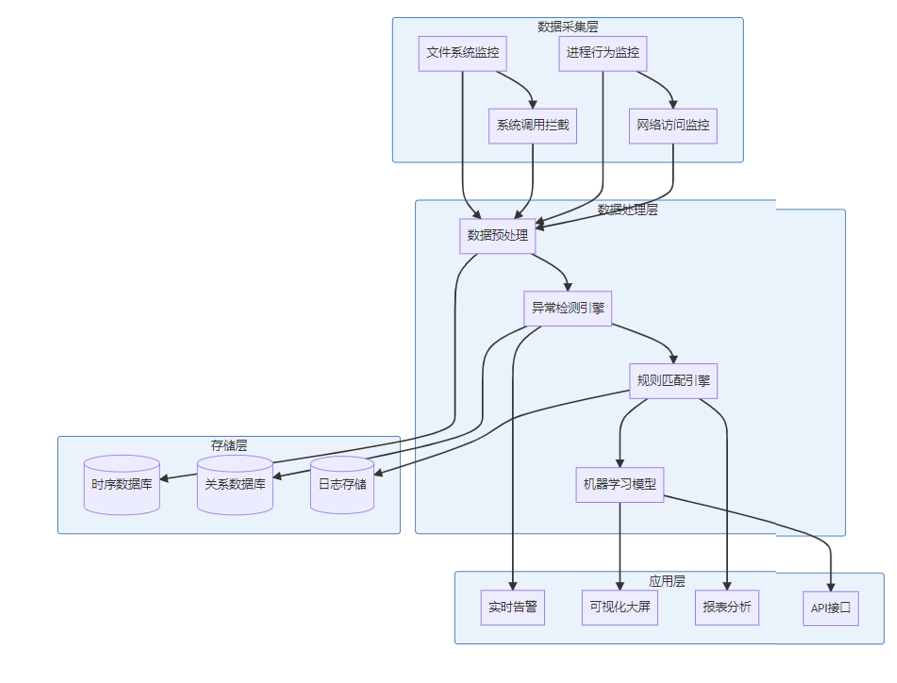
这个架构采用了经典的分层设计,每一层都有明确的职责:
📊 数据采集层:就像是我们的"眼睛和耳朵",负责收集各种文件操作信息。
⚙️ 数据处理层:相当于"大脑",对收集到的信息进行分析和判断。
💾 存储层:就是我们的"记忆",保存所有的历史数据和分析结果。
🎯 应用层:最终的"输出口",将分析结果以各种形式展现给用户。
核心功能模块详解
1. 数据采集层详细实现
1.1 文件系统监控Agent
这是整个系统的"神经末梢",负责实时捕获文件操作事件:
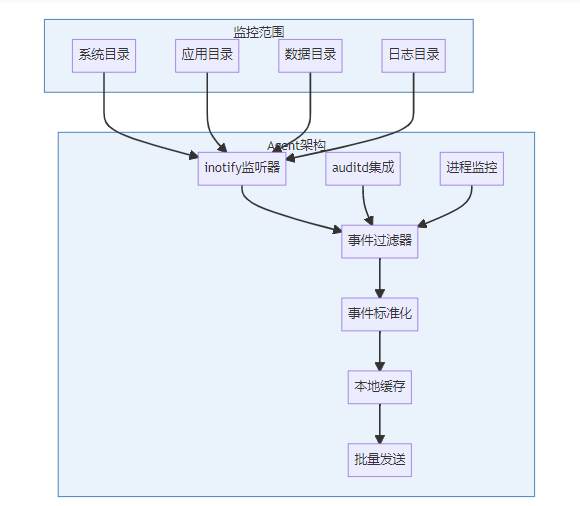
Agent核心代码示例(Python实现):
import asyncio
import json
from watchdog.observers import Observer
from watchdog.events import FileSystemEventHandler
class SecurityMonitorHandler(FileSystemEventHandler):
def __init__(self, event_queue):
self.event_queue = event_queue
self.process_info = ProcessMonitor()
def on_any_event(self, event):
# 获取进程信息
process_info = self.process_info.get_current_process()
event_data = {
'timestamp': int(time.time() * 1000),
'event_type': event.event_type,
'src_path': event.src_path,
'dest_path': getattr(event, 'dest_path', None),
'is_directory': event.is_directory,
'process_id': process_info.pid,
'process_name': process_info.name,
'user_id': process_info.uid,
'file_hash': self._calculate_file_hash(event.src_path),
'file_size': self._get_file_size(event.src_path)
}
# 异步发送到消息队列
asyncio.create_task(self.event_queue.put(event_data))1.2 系统调用拦截模块
使用eBPF技术实现更深层次的监控:
// eBPF程序示例:监控open系统调用
#include <linux/bpf.h>
#include <linux/ptrace.h>
struct event_data {
u32 pid;
u32 uid;
char filename[256];
u32 flags;
u64 timestamp;
};
BPF_PERF_OUTPUT(events);
int trace_open(struct pt_regs *ctx) {
struct event_data data = {};
data.pid = bpf_get_current_pid_tgid() >> 32;
data.uid = bpf_get_current_uid_gid() & 0xffffffff;
data.timestamp = bpf_ktime_get_ns();
// 获取文件名参数
const char __user *filename = (char *)PT_REGS_PARM1(ctx);
bpf_probe_read_user_str(data.filename, sizeof(data.filename), filename);
// 获取打开标志
data.flags = (u32)PT_REGS_PARM2(ctx);
events.perf_submit(ctx, &data, sizeof(data));
return 0;
}2. 数据处理层详细实现
2.1 事件预处理引擎

预处理逻辑实现:
package preprocessor
type EventProcessor struct {
rules []ProcessingRule
aggregator *EventAggregator
deduplicator *EventDeduplicator
}
func (ep *EventProcessor) ProcessEvent(event *RawEvent) (*ProcessedEvent, error) {
// 1. 数据清洗
cleanedEvent := ep.cleanEvent(event)
// 2. 重复检测
if ep.deduplicator.IsDuplicate(cleanedEvent) {
return nil, nil // 跳过重复事件
}
// 3. 特征提取
features := ep.extractFeatures(cleanedEvent)
// 4. 风险评分
riskScore := ep.calculateRiskScore(features)
processedEvent := &ProcessedEvent{
ID: generateEventID(),
Timestamp: cleanedEvent.Timestamp,
Features: features,
RiskScore: riskScore,
OriginalEvent: cleanedEvent,
}
return processedEvent, nil
}2.2 异常检测引擎架构
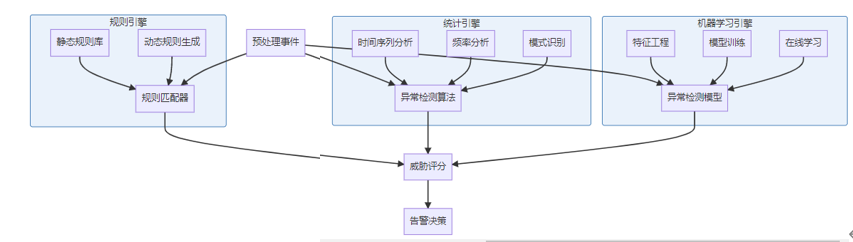
异常检测算法实现:
import numpy as np
from sklearn.ensemble import IsolationForest
from sklearn.preprocessing import StandardScaler
class AnomalyDetector:
def __init__(self):
self.models = {
'isolation_forest': IsolationForest(contamination=0.1),
'statistical': StatisticalDetector(),
'rule_based': RuleBasedDetector()
}
self.scaler = StandardScaler()
self.feature_weights = {
'file_access_frequency': 0.3,
'unusual_time_access': 0.25,
'privilege_escalation': 0.4,
'suspicious_process': 0.35
}
def detect_anomaly(self, event_features):
"""多模型融合的异常检测"""
scores = {}
# 1. 基于隔离森林的检测
if hasattr(self.models['isolation_forest'], 'decision_function'):
isolation_score = self.models['isolation_forest'].decision_function([event_features])[0]
scores['isolation'] = self._normalize_score(isolation_score)
# 2. 统计学异常检测
statistical_score = self.models['statistical'].detect(event_features)
scores['statistical'] = statistical_score
# 3. 规则基检测
rule_score = self.models['rule_based'].detect(event_features)
scores['rule_based'] = rule_score
# 4. 融合多个模型的结果
final_score = self._weighted_ensemble(scores)
return {
'anomaly_score': final_score,
'individual_scores': scores,
'risk_level': self._get_risk_level(final_score),
'explanation': self._generate_explanation(scores, event_features)
}3. 存储层架构详细设计
3.1 分层存储策略

数据模型设计:
-- PostgreSQL 数据模型
CREATE TABLE monitoring_rules (
id SERIAL PRIMARY KEY,
rule_name VARCHAR(255) NOT NULL,
rule_type VARCHAR(50) NOT NULL,
pattern JSONB NOT NULL,
severity INTEGER NOT NULL,
enabled BOOLEAN DEFAULT TRUE,
created_at TIMESTAMP DEFAULT NOW(),
updated_at TIMESTAMP DEFAULT NOW()
);
CREATE TABLE security_events (
id BIGSERIAL PRIMARY KEY,
event_id UUID UNIQUE NOT NULL,
timestamp TIMESTAMP NOT NULL,
event_type VARCHAR(50) NOT NULL,
source_ip INET,
user_id VARCHAR(100),
file_path TEXT,
risk_score DECIMAL(5,2),
raw_data JSONB,
processed_at TIMESTAMP DEFAULT NOW()
);
-- 时序数据库schema (InfluxDB)
-- measurement: file_events
-- tags: event_type, user_id, file_extension, risk_level
-- fields: file_size, operation_count, response_time, risk_score
-- time: timestamp3.2 数据生命周期管理
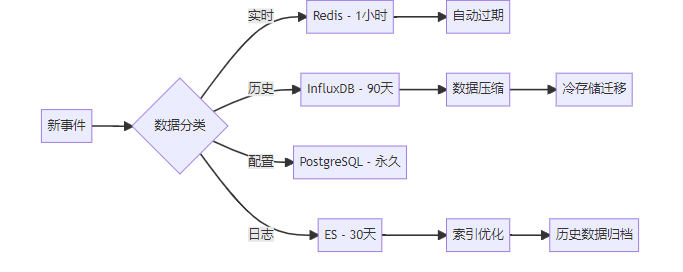
4. 应用层详细实现
4.1 实时告警系统
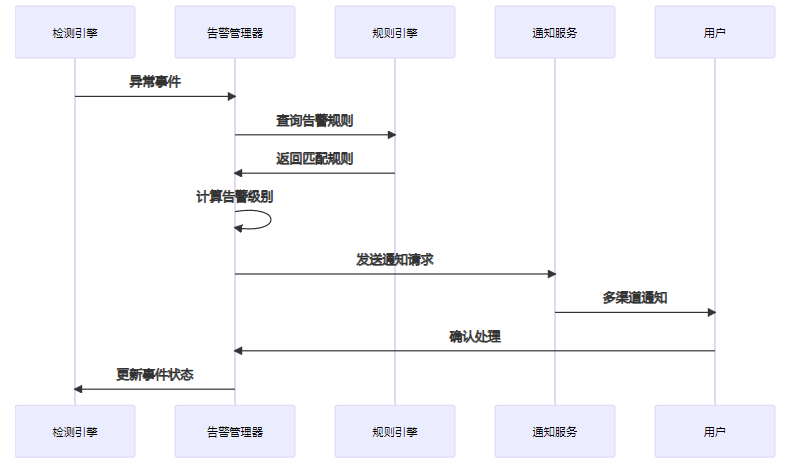
告警系统核心代码:
@Service
public class AlertManager {
@Autowired
private RuleEngine ruleEngine;
@Autowired
private NotificationService notificationService;
public void processAlert(SecurityEvent event) {
// 1. 匹配告警规则
List<AlertRule> matchedRules = ruleEngine.findMatchingRules(event);
if (matchedRules.isEmpty()) {
return; // 无匹配规则,不产生告警
}
// 2. 创建告警
Alert alert = createAlert(event, matchedRules);
// 3. 去重检查
if (isDuplicateAlert(alert)) {
updateAlertCount(alert);
return;
}
// 4. 发送通知
CompletableFuture.runAsync(() -> {
try {
notificationService.sendAlert(alert);
updateAlertStatus(alert, AlertStatus.SENT);
} catch (Exception e) {
updateAlertStatus(alert, AlertStatus.FAILED);
log.error("Failed to send alert: {}", alert.getId(), e);
}
});
}
private Alert createAlert(SecurityEvent event, List<AlertRule> rules) {
Alert alert = new Alert();
alert.setEventId(event.getId());
alert.setSeverity(calculateMaxSeverity(rules));
alert.setTitle(generateAlertTitle(event, rules));
alert.setDescription(generateAlertDescription(event, rules));
alert.setCreatedAt(Instant.now());
alert.setStatus(AlertStatus.PENDING);
// 添加建议的响应措施
alert.setRecommendedActions(generateRecommendedActions(event, rules));
return alertRepository.save(alert);
}
}4.2 可视化监控大屏
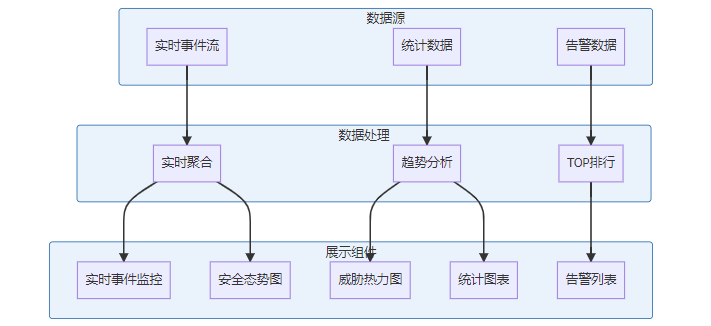
前端核心实现(Vue.js + ECharts):
<template>
<div class="security-dashboard">
<!-- 实时统计卡片 -->
<div class="stats-cards">
<StatCard title="今日事件" :value="todayEvents" trend="up" />
<StatCard title="活跃告警" :value="activeAlerts" trend="down" />
<StatCard title="风险评分" :value="riskScore" trend="stable" />
</div>
<!-- 实时事件流 -->
<div class="event-stream">
<h3>实时事件流</h3>
<virtual-list :items="realtimeEvents" item-height="60">
<template #item="{ item }">
<EventItem :event="item" @click="showEventDetail" />
</template>
</virtual-list>
</div>
<!-- 威胁态势图 -->
<div class="threat-map">
<threat-heatmap :data="threatData" />
</div>
</div>
</template>
<script>
export default {
data() {
return {
todayEvents: 0,
activeAlerts: 0,
riskScore: 0,
realtimeEvents: [],
threatData: []
}
},
mounted() {
this.initWebSocket();
this.loadInitialData();
},
methods: {
initWebSocket() {
this.ws = new WebSocket('ws://localhost:8080/realtime-events');
this.ws.onmessage = (event) => {
const data = JSON.parse(event.data);
this.handleRealtimeEvent(data);
};
},
handleRealtimeEvent(event) {
// 更新实时事件列表
this.realtimeEvents.unshift(event);
if (this.realtimeEvents.length > 100) {
this.realtimeEvents.pop();
}
// 更新统计数据
this.updateStats(event);
}
}
}
</script>技术实现方案
5.1 消息队列与流处理架构
Kafka配置示例:
# server.properties
num.network.threads=8
num.io.threads=16
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
# 针对高吞吐量优化
num.partitions=12
default.replication.factor=3
min.insync.replicas=2
# 数据保留策略
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000流处理代码示例(Kafka Streams):
@Component
public class EventStreamProcessor {
@Value("${kafka.bootstrap.servers}")
private String bootstrapServers;
public void startEventProcessing() {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "security-event-processor");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
StreamsBuilder builder = new StreamsBuilder();
// 1. 原始事件流
KStream<String, SecurityEvent> rawEvents = builder.stream("raw-events");
// 2. 事件过滤和清洗
KStream<String, SecurityEvent> filteredEvents = rawEvents
.filter((key, event) -> isValidEvent(event))
.mapValues(this::enrichEvent);
// 3. 异常检测
KStream<String, Alert> alerts = filteredEvents
.flatMapValues(this::detectAnomalies)
.filter((key, alert) -> alert != null);
// 4. 事件聚合 - 按用户ID分组
KTable<String, EventSummary> userEventSummary = filteredEvents
.groupBy((key, event) -> event.getUserId())
.windowedBy(TimeWindows.of(Duration.ofMinutes(5)))
.aggregate(
EventSummary::new,
(userId, event, summary) -> summary.addEvent(event),
Materialized.with(Serdes.String(), eventSummarySerde)
);
// 输出到下游topic
alerts.to("alerts", Produced.with(Serdes.String(), alertSerde));
filteredEvents.to("processed-events", Produced.with(Serdes.String(), eventSerde));
KafkaStreams streams = new KafkaStreams(builder.build(), props);
streams.start();
}
}5.2 微服务架构设计
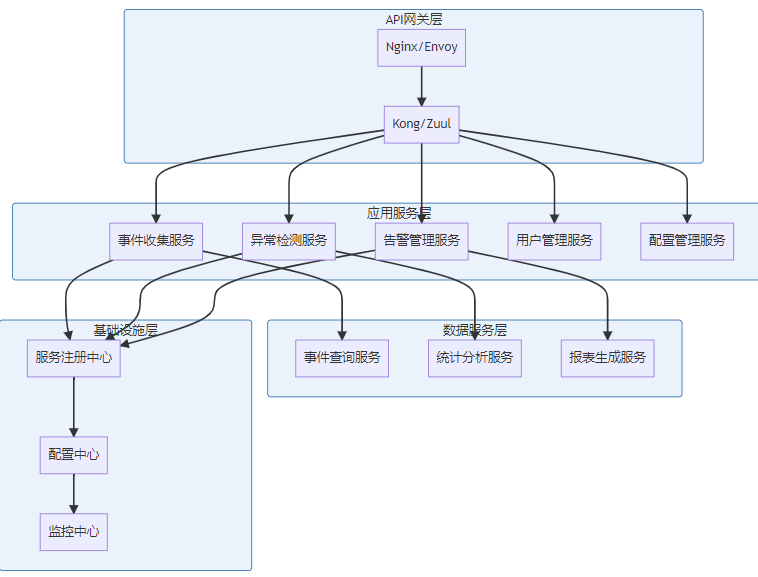
Spring Cloud配置示例:
# application.yml
spring:
application:
name: security-event-service
cloud:
consul:
host: localhost
port: 8500
discovery:
instance-id: ${spring.application.name}:${random.value}
health-check-path: /actuator/health
health-check-interval: 15s
server:
port: 8080
management:
endpoints:
web:
exposure:
include: health,info,metrics,prometheus
endpoint:
health:
show-details: always
# 数据源配置
spring:
datasource:
primary:
url: jdbc:postgresql://localhost:5432/security_db
username: ${DB_USER}
password: ${DB_PASSWORD}
driver-class-name: org.postgresql.Driver
hikari:
maximum-pool-size: 20
minimum-idle: 5
connection-timeout: 20000
redis:
cluster:
nodes:
- redis-1:6379
- redis-2:6379
- redis-3:6379
max-redirects: 3
lettuce:
pool:
max-active: 16
max-idle: 85.3 容器化部署方案
Docker Compose配置:
version: '3.8'
services:
# 事件收集服务
event-collector:
build: ./event-collector
ports:
- "8080:8080"
environment:
- SPRING_PROFILES_ACTIVE=docker
- KAFKA_BOOTSTRAP_SERVERS=kafka:9092
- REDIS_HOST=redis
- POSTGRES_HOST=postgres
depends_on:
- kafka
- redis
- postgres
deploy:
replicas: 3
resources:
limits:
cpus: '1.0'
memory: 1G
reservations:
cpus: '0.5'
memory: 512M
# 异常检测服务
anomaly-detector:
build: ./anomaly-detector
environment:
- PYTHON_ENV=production
- KAFKA_BOOTSTRAP_SERVERS=kafka:9092
- ELASTICSEARCH_HOST=elasticsearch:9200
depends_on:
- kafka
- elasticsearch
deploy:
replicas: 2
resources:
limits:
cpus: '2.0'
memory: 2G
# 基础设施
kafka:
image: confluentinc/cp-kafka:latest
environment:
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 3
ports:
- "9092:9092"
volumes:
- kafka-data:/var/lib/kafka/data
redis:
image: redis:7-alpine
command: redis-server --appendonly yes --cluster-enabled yes
ports:
- "6379:6379"
volumes:
- redis-data:/data
postgres:
image: postgres:14
environment:
POSTGRES_DB: security_db
POSTGRES_USER: security_user
POSTGRES_PASSWORD: ${POSTGRES_PASSWORD}
ports:
- "5432:5432"
volumes:
- postgres-data:/var/lib/postgresql/data
- ./init.sql:/docker-entrypoint-initdb.d/init.sql
volumes:
kafka-data:
redis-data:
postgres-data:5.4 Kubernetes部署配置
# deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: security-monitor-deployment
labels:
app: security-monitor
spec:
replicas: 3
selector:
matchLabels:
app: security-monitor
template:
metadata:
labels:
app: security-monitor
spec:
containers:
- name: event-collector
image: security-monitor/event-collector:latest
ports:
- containerPort: 8080
env:
- name: KAFKA_BOOTSTRAP_SERVERS
valueFrom:
configMapKeyRef:
name: app-config
key: kafka.bootstrap.servers
resources:
requests:
memory: "512Mi"
cpu: "250m"
limits:
memory: "1Gi"
cpu: "500m"
livenessProbe:
httpGet:
path: /actuator/health
port: 8080
initialDelaySeconds: 30
periodSeconds: 10
readinessProbe:
httpGet:
path: /actuator/health/readiness
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
---
apiVersion: v1
kind: Service
metadata:
name: security-monitor-service
spec:
selector:
app: security-monitor
ports:
- protocol: TCP
port: 80
targetPort: 8080
type: LoadBalancer
---
apiVersion: v1
kind: ConfigMap
metadata:
name: app-config
data:
kafka.bootstrap.servers: "kafka-cluster:9092"
redis.host: "redis-cluster"
postgres.host: "postgres-cluster"5.5 监控与可观测性
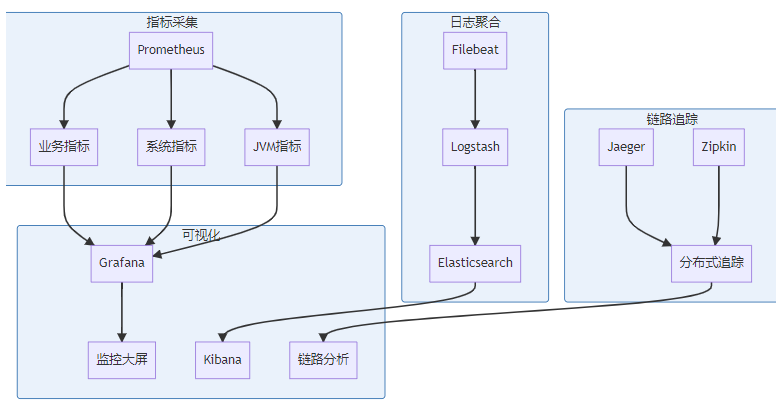
Prometheus配置示例:
# prometheus.yml
global:
scrape_interval: 15s
evaluation_interval: 15s
rule_files:
- "alert_rules.yml"
scrape_configs:
- job_name: 'security-monitor'
static_configs:
- targets: ['security-monitor:8080']
metrics_path: /actuator/prometheus
scrape_interval: 10s
- job_name: 'kafka'
static_configs:
- targets: ['kafka:9092']
metrics_path: /metrics
- job_name: 'redis'
static_configs:
- targets: ['redis:6379']
alerting:
alertmanagers:
- static_configs:
- targets:
- alertmanager:90935.6 性能优化核心策略
5.6.1 数据库优化
-- 针对高频查询的索引优化
CREATE INDEX CONCURRENTLY idx_events_timestamp_user
ON security_events (timestamp DESC, user_id)
WHERE timestamp > NOW() - INTERVAL '7 days';
-- 分区表策略
CREATE TABLE security_events_2024_01 PARTITION OF security_events
FOR VALUES FROM ('2024-01-01') TO ('2024-02-01');
-- 实时查询优化
CREATE MATERIALIZED VIEW real_time_stats AS
SELECT
date_trunc('minute', timestamp) as time_bucket,
event_type,
COUNT(*) as event_count,
AVG(risk_score) as avg_risk_score
FROM security_events
WHERE timestamp > NOW() - INTERVAL '1 hour'
GROUP BY time_bucket, event_type;5.6.2 缓存策略实现
@Configuration
@EnableCaching
public class CacheConfig {
@Bean
public CacheManager cacheManager() {
RedisCacheManager.Builder builder = RedisCacheManager
.RedisCacheManagerBuilder
.fromConnectionFactory(redisConnectionFactory())
.cacheDefaults(cacheConfiguration());
return builder.build();
}
private RedisCacheConfiguration cacheConfiguration() {
return RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofMinutes(10))
.serializeKeysWith(RedisSerializationContext.SerializationPair
.fromSerializer(new StringRedisSerializer()))
.serializeValuesWith(RedisSerializationContext.SerializationPair
.fromSerializer(new GenericJackson2JsonRedisSerializer()));
}
}
@Service
public class EventQueryService {
@Cacheable(value = "event-stats", key = "#userId + ':' + #timeRange")
public EventStatistics getUserEventStats(String userId, String timeRange) {
// 复杂的统计查询逻辑
return eventRepository.calculateUserStats(userId, timeRange);
}
@CacheEvict(value = "event-stats", key = "#userId + ':*'")
public void clearUserStatsCache(String userId) {
// 用户相关缓存清理
}
}部署与运维策略
6.1 生产环境部署架构
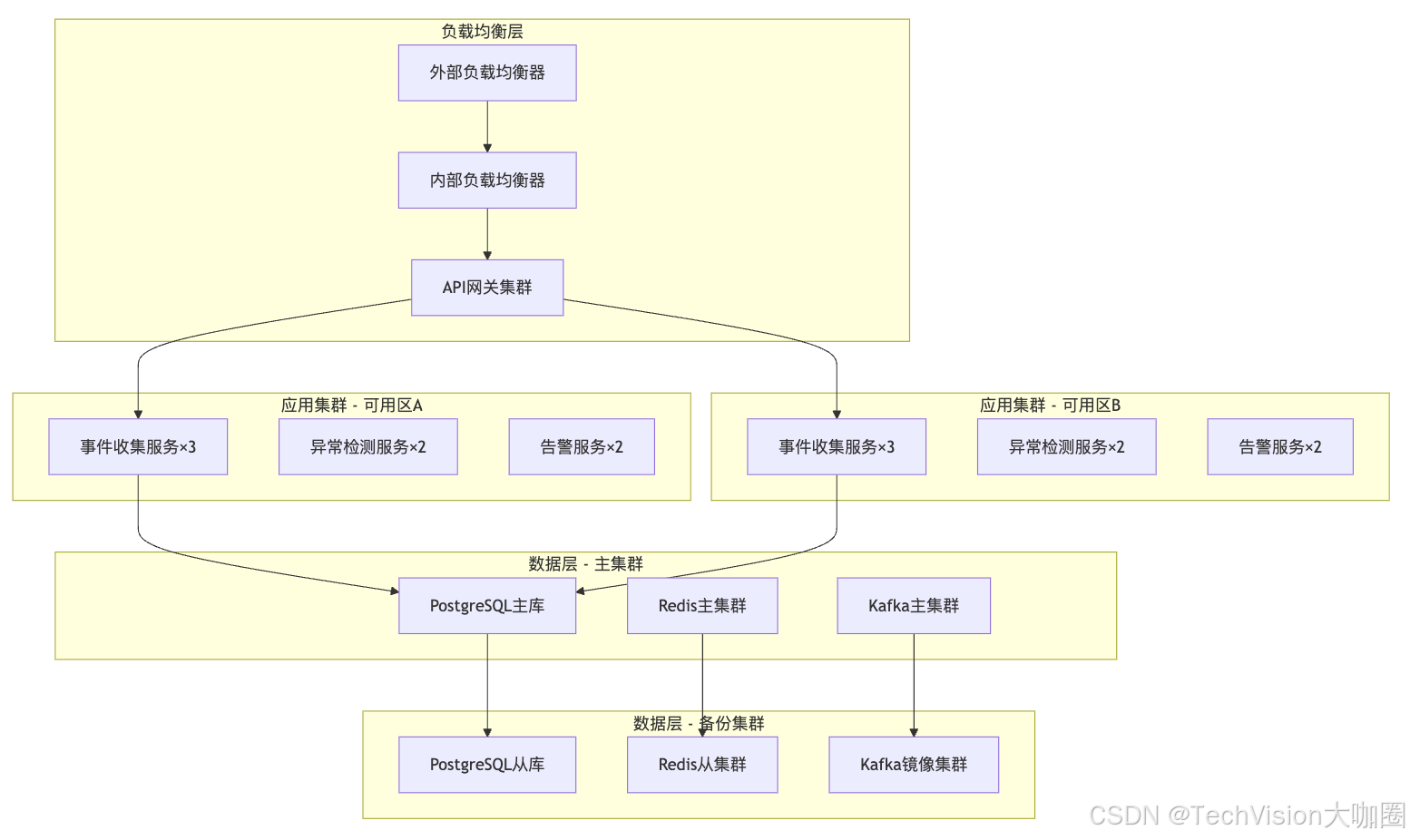
6.1.1 高可用配置详解
PostgreSQL主从配置:
# 主库配置 (postgresql.conf)
listen_addresses = '*'
wal_level = replica
max_wal_senders = 3
wal_keep_segments = 64
synchronous_standby_names = 'standby1,standby2'
# 从库配置 (recovery.conf)
standby_mode = 'on'
primary_conninfo = 'host=master-ip port=5432 user=replicator'
trigger_file = '/tmp/postgresql.trigger'Redis集群配置:
# redis.conf
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
appendfsync everysec
# 集群初始化
redis-cli --cluster create \
192.168.1.10:6379 192.168.1.11:6379 192.168.1.12:6379 \
192.168.1.13:6379 192.168.1.14:6379 192.168.1.15:6379 \
--cluster-replicas 16.1.2 自动化部署脚本
#!/bin/bash
# deploy.sh - 自动化部署脚本
set -e
# 环境变量
ENVIRONMENT=${1:-production}
VERSION=${2:-latest}
NAMESPACE="security-monitor"
echo "开始部署 SecurityMonitor v${VERSION} 到 ${ENVIRONMENT} 环境"
# 1. 检查依赖
check_dependencies() {
command -v kubectl >/dev/null 2>&1 || { echo "kubectl 未安装"; exit 1; }
command -v helm >/dev/null 2>&1 || { echo "helm 未安装"; exit 1; }
command -v docker >/dev/null 2>&1 || { echo "docker 未安装"; exit 1; }
}
# 2. 构建镜像
build_images() {
echo "构建Docker镜像..."
docker build -t security-monitor/event-collector:${VERSION} ./event-collector/
docker build -t security-monitor/anomaly-detector:${VERSION} ./anomaly-detector/
docker build -t security-monitor/alert-manager:${VERSION} ./alert-manager/
# 推送到镜像仓库
docker push security-monitor/event-collector:${VERSION}
docker push security-monitor/anomaly-detector:${VERSION}
docker push security-monitor/alert-manager:${VERSION}
}
# 3. 部署基础设施
deploy_infrastructure() {
echo "部署基础设施组件..."
# 部署Kafka
helm upgrade --install kafka bitnami/kafka \
--namespace ${NAMESPACE} \
--set replicaCount=3 \
--set zookeeper.replicaCount=3 \
--set persistence.size=100Gi
# 部署Redis
helm upgrade --install redis bitnami/redis-cluster \
--namespace ${NAMESPACE} \
--set cluster.nodes=6 \
--set persistence.size=20Gi
# 部署PostgreSQL
helm upgrade --install postgres bitnami/postgresql-ha \
--namespace ${NAMESPACE} \
--set postgresql.replicaCount=2 \
--set persistence.size=200Gi
}
# 4. 部署应用服务
deploy_applications() {
echo "部署应用服务..."
# 更新Helm Chart
helm upgrade --install security-monitor ./helm/security-monitor \
--namespace ${NAMESPACE} \
--set image.tag=${VERSION} \
--set environment=${ENVIRONMENT} \
--values ./helm/values-${ENVIRONMENT}.yaml
}
# 5. 验证部署
verify_deployment() {
echo "验证部署状态..."
# 等待Pod就绪
kubectl wait --for=condition=ready pod \
-l app=security-monitor \
-n ${NAMESPACE} \
--timeout=300s
# 健康检查
kubectl get pods -n ${NAMESPACE}
kubectl get services -n ${NAMESPACE}
# API健康检查
API_URL=$(kubectl get service security-monitor-api -n ${NAMESPACE} -o jsonpath='{.status.loadBalancer.ingress[0].ip}')
curl -f http://${API_URL}/actuator/health || { echo "API健康检查失败"; exit 1; }
}
# 主流程
main() {
check_dependencies
build_images
deploy_infrastructure
deploy_applications
verify_deployment
echo "部署完成!"
echo "API地址: http://$(kubectl get service security-monitor-api -n ${NAMESPACE} -o jsonpath='{.status.loadBalancer.ingress[0].ip}')"
}
main "$@"6.2 监控告警体系
6.2.1 系统监控指标
# prometheus-rules.yml
groups:
- name: security-monitor-alerts
rules:
# 系统可用性告警
- alert: ServiceDown
expr: up{job="security-monitor"} == 0
for: 1m
labels:
severity: critical
annotations:
summary: "Security Monitor服务不可用"
description: "{{ $labels.instance }} 已经下线超过1分钟"
# 事件处理延迟告警
- alert: HighEventProcessingLatency
expr: event_processing_duration_seconds{quantile="0.95"} > 5
for: 2m
labels:
severity: warning
annotations:
summary: "事件处理延迟过高"
description: "95%分位数的处理延迟超过5秒"
# 磁盘空间告警
- alert: DiskSpaceUsageHigh
expr: (node_filesystem_size_bytes - node_filesystem_free_bytes) / node_filesystem_size_bytes > 0.85
for: 5m
labels:
severity: warning
annotations:
summary: "磁盘空间使用率过高"
description: "磁盘 {{ $labels.device }} 使用率超过85%"
# 异常检测准确率告警
- alert: AnomalyDetectionAccuracyLow
expr: anomaly_detection_accuracy < 0.8
for: 10m
labels:
severity: warning
annotations:
summary: "异常检测准确率下降"
description: "当前异常检测准确率为 {{ $value }},低于80%阈值"6.2.2 业务监控大屏
// Grafana Dashboard配置
{
"dashboard": {
"title": "Security Monitor - 运维监控大屏",
"panels": [
{
"title": "系统健康状态",
"type": "stat",
"targets": [
{
"expr": "up{job=\"security-monitor\"}",
"legendFormat": "{{instance}}"
}
],
"fieldConfig": {
"defaults": {
"color": {
"mode": "thresholds"
},
"thresholds": {
"steps": [
{"color": "red", "value": 0},
{"color": "green", "value": 1}
]
}
}
}
},
{
"title": "每秒事件处理量",
"type": "graph",
"targets": [
{
"expr": "rate(events_processed_total[5m])",
"legendFormat": "处理速率"
}
]
},
{
"title": "异常检测结果分布",
"type": "piechart",
"targets": [
{
"expr": "sum by (risk_level) (events_by_risk_level)",
"legendFormat": "{{risk_level}}"
}
]
},
{
"title": "TOP 10 异常文件路径",
"type": "table",
"targets": [
{
"expr": "topk(10, sum by (file_path) (anomaly_events_total))",
"legendFormat": "{{file_path}}"
}
]
}
]
}
}6.3 容灾与备份策略
6.3.1 数据备份自动化
#!/bin/bash
# backup.sh - 数据备份脚本
BACKUP_DATE=$(date +%Y%m%d_%H%M%S)
BACKUP_ROOT="/backup/security-monitor"
RETENTION_DAYS=30
# PostgreSQL备份
backup_postgresql() {
echo "开始PostgreSQL备份..."
pg_dump -h ${PG_HOST} -U ${PG_USER} -d security_db \
--verbose --format=custom \
--file="${BACKUP_ROOT}/postgresql/security_db_${BACKUP_DATE}.dump"
# 压缩备份文件
gzip "${BACKUP_ROOT}/postgresql/security_db_${BACKUP_DATE}.dump"
echo "PostgreSQL备份完成"
}
# Redis备份
backup_redis() {
echo "开始Redis备份..."
redis-cli --rdb "${BACKUP_ROOT}/redis/redis_${BACKUP_DATE}.rdb"
gzip "${BACKUP_ROOT}/redis/redis_${BACKUP_DATE}.rdb"
echo "Redis备份完成"
}
# 配置文件备份
backup_configs() {
echo "开始配置文件备份..."
tar -czf "${BACKUP_ROOT}/configs/configs_${BACKUP_DATE}.tar.gz" \
/etc/security-monitor/ \
/opt/security-monitor/config/
echo "配置文件备份完成"
}
# 清理旧备份
cleanup_old_backups() {
echo "清理${RETENTION_DAYS}天前的备份文件..."
find ${BACKUP_ROOT} -name "*.gz" -mtime +${RETENTION_DAYS} -delete
find ${BACKUP_ROOT} -name "*.dump" -mtime +${RETENTION_DAYS} -delete
echo "清理完成"
}
# 上传到云存储
upload_to_cloud() {
echo "上传备份到云存储..."
# 上传到AWS S3
aws s3 sync ${BACKUP_ROOT} s3://security-monitor-backups/$(date +%Y/%m/%d)/ \
--exclude "*" --include "*.gz" --include "*.tar.gz"
echo "云存储上传完成"
}
# 主流程
main() {
mkdir -p ${BACKUP_ROOT}/{postgresql,redis,configs}
backup_postgresql
backup_redis
backup_configs
upload_to_cloud
cleanup_old_backups
echo "备份任务完成 - ${BACKUP_DATE}"
}
main "$@"6.3.2 容灾切换流程
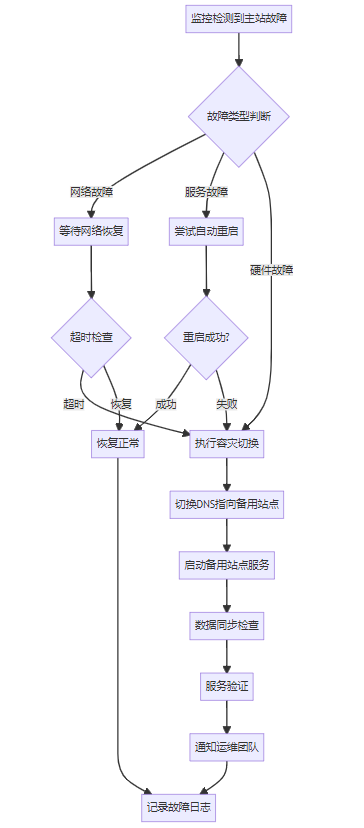
自动切换脚本:
#!/usr/bin/env python3
# disaster_recovery.py
import asyncio
import aiohttp
import logging
from typing import Dict, List
import json
import subprocess
class DisasterRecoveryManager:
def __init__(self, config_file: str):
with open(config_file, 'r') as f:
self.config = json.load(f)
self.primary_endpoints = self.config['primary']['endpoints']
self.backup_endpoints = self.config['backup']['endpoints']
self.dns_config = self.config['dns']
logging.basicConfig(level=logging.INFO)
self.logger = logging.getLogger(__name__)
async def check_service_health(self, endpoint: str) -> bool:
"""检查服务健康状态"""
try:
async with aiohttp.ClientSession() as session:
async with session.get(f"{endpoint}/actuator/health",
timeout=aiohttp.ClientTimeout(total=10)) as response:
if response.status == 200:
data = await response.json()
return data.get('status') == 'UP'
except Exception as e:
self.logger.error(f"健康检查失败 {endpoint}: {e}")
return False
return False
async def check_all_services(self, endpoints: List[str]) -> Dict[str, bool]:
"""检查所有服务的健康状态"""
tasks = [self.check_service_health(endpoint) for endpoint in endpoints]
results = await asyncio.gather(*tasks)
return dict(zip(endpoints, results))
def switch_dns_to_backup(self):
"""切换DNS到备用站点"""
try:
# 使用Route53 API切换DNS
cmd = [
'aws', 'route53', 'change-resource-record-sets',
'--hosted-zone-id', self.dns_config['zone_id'],
'--change-batch', json.dumps({
'Changes': [{
'Action': 'UPSERT',
'ResourceRecordSet': {
'Name': self.dns_config['domain'],
'Type': 'A',
'TTL': 60,
'ResourceRecords': [{'Value': self.config['backup']['ip']}]
}
}]
})
]
result = subprocess.run(cmd, capture_output=True, text=True)
if result.returncode == 0:
self.logger.info("DNS切换成功")
return True
else:
self.logger.error(f"DNS切换失败: {result.stderr}")
return False
except Exception as e:
self.logger.error(f"DNS切换异常: {e}")
return False
async def start_backup_services(self):
"""启动备用站点服务"""
try:
# 使用Kubernetes API启动备用服务
cmd = [
'kubectl', 'scale', 'deployment', 'security-monitor',
'--replicas=3', '--namespace=backup'
]
result = subprocess.run(cmd, capture_output=True, text=True)
if result.returncode == 0:
self.logger.info("备用服务启动成功")
# 等待服务就绪
await asyncio.sleep(30)
return True
else:
self.logger.error(f"备用服务启动失败: {result.stderr}")
return False
except Exception as e:
self.logger.error(f"备用服务启动异常: {e}")
return False
async def execute_disaster_recovery(self):
"""执行容灾切换流程"""
self.logger.info("开始执行容灾切换...")
# 1. 最后一次检查主站点
primary_status = await self.check_all_services(self.primary_endpoints)
healthy_count = sum(primary_status.values())
if healthy_count >= len(self.primary_endpoints) * 0.5:
self.logger.info("主站点恢复正常,取消容灾切换")
return False
# 2. 启动备用服务
if await self.start_backup_services():
# 3. 检查备用服务状态
backup_status = await self.check_all_services(self.backup_endpoints)
backup_healthy = sum(backup_status.values())
if backup_healthy >= len(self.backup_endpoints) * 0.8:
# 4. 切换DNS
if self.switch_dns_to_backup():
self.logger.info("容灾切换完成")
self.send_notification("容灾切换完成,系统已切换到备用站点")
return True
self.logger.error("容灾切换失败")
self.send_notification("容灾切换失败,请人工介入")
return False
def send_notification(self, message: str):
"""发送通知"""
# 发送钉钉/企业微信通知
# 发送邮件通知
# 发送短信通知
self.logger.info(f"发送通知: {message}")
if __name__ == "__main__":
dr_manager = DisasterRecoveryManager("disaster_recovery_config.json")
asyncio.run(dr_manager.execute_disaster_recovery())6.4 运维自动化
6.4.1 日志管理自动化
# filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/security-monitor/*.log
fields:
service: security-monitor
environment: production
multiline.pattern: '^\d{4}-\d{2}-\d{2}'
multiline.negate: true
multiline.match: after
processors:
- add_host_metadata:
when.not.contains.tags: forwarded
- add_docker_metadata: ~
- add_kubernetes_metadata: ~
output.elasticsearch:
hosts: ["elasticsearch-1:9200", "elasticsearch-2:9200"]
index: "security-monitor-logs-%{+yyyy.MM.dd}"
template.settings:
index.number_of_shards: 2
index.number_of_replicas: 1
logging.level: info
logging.to_files: true
logging.files:
path: /var/log/filebeat
name: filebeat
keepfiles: 7
permissions: 06446.4.2 自动扩缩容策略
# hpa.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: security-monitor-hpa
namespace: security-monitor
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: security-monitor
minReplicas: 3
maxReplicas: 20
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 80
- type: Pods
pods:
metric:
name: events_processing_rate
target:
type: AverageValue
averageValue: "1000"
behavior:
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Pods
value: 1
periodSeconds: 60
scaleUp:
stabilizationWindowSeconds: 60
policies:
- type: Pods
value: 2
periodSeconds: 30总结与展望
通过本文的详细分析,我们完整地构建了一个服务器文件安全异常实时监测系统的设计方案。这套系统不仅仅是一个简单的文件监控工具,而是一个集成了现代化技术栈的智能安全防护平台。
📊 系统核心优势总结
🛡️ 多层防护体系
- 数据采集层:通过inotify、eBPF等技术实现毫秒级事件捕获
- 智能分析层:融合规则引擎、统计学分析、机器学习的多维度异常检测
- 响应处理层:自动化告警和响应机制,支持多渠道通知
- 可视化层:实时监控大屏和详细的分析报表
⚡ 高性能设计
- 并发处理:基于Kafka的分布式流处理,支持百万级事件/秒
- 存储优化:分层存储策略,热温冷数据分级管理
- 缓存策略:Redis集群缓存热点数据,毫秒级查询响应
- 自动扩容:基于HPA的弹性伸缩,根据负载自动调整资源
🔧 运维友好
- 容器化部署:Docker + Kubernetes,支持一键部署和滚动更新
- 监控告警:Prometheus + Grafana完整监控体系
- 日志管理:ELK栈统一日志收集和分析
- 备份容灾:多级备份策略和自动容灾切换
🎯 实际应用场景
企业级应用场景:
- 金融机构:监控核心业务数据的访问和修改,确保合规性
- 电商平台:保护用户数据和订单信息,防止数据泄露
- 医疗系统:监控患者隐私数据访问,满足HIPAA等法规要求
- 政府机构:保护敏感政务数据,维护国家信息安全
部署规模参考:
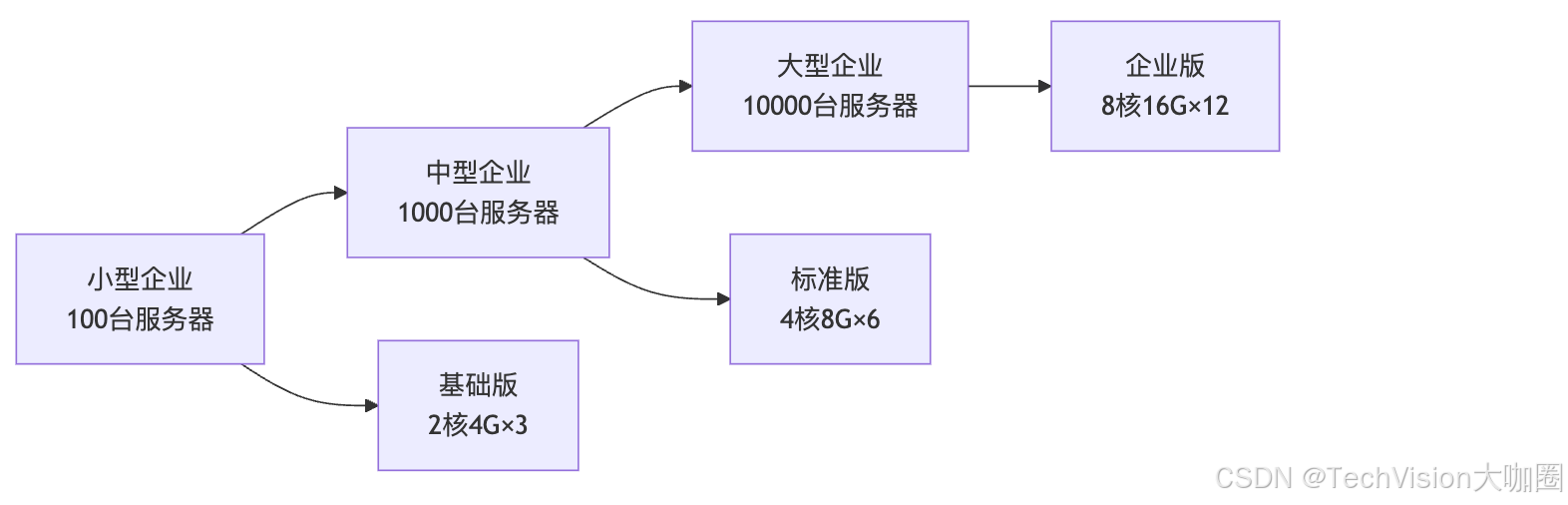
🚀 技术发展趋势
AI驱动的安全分析 随着人工智能技术的发展,未来的文件安全监测将更加智能:
- 深度学习模型:使用Transformer架构分析文件访问序列
- 联邦学习:多机构间共享威胁情报而不泄露敏感数据
- 零样本检测:无需训练即可识别全新类型的威胁
云原生安全 适应云计算和微服务架构的发展:
- Service Mesh集成:与Istio等服务网格深度集成
- Serverless监控:支持AWS Lambda、Azure Functions等无服务器环境
- 边缘计算:在边缘节点部署轻量级监控代理
隐私保护增强 在加强安全的同时保护用户隐私:
- 同态加密:在加密状态下进行异常检测分析
- 差分隐私:在统计分析中保护个体隐私
- 零知识证明:验证威胁检测结果而不暴露原始数据
💡 实施建议与最佳实践
阶段性部署策略:
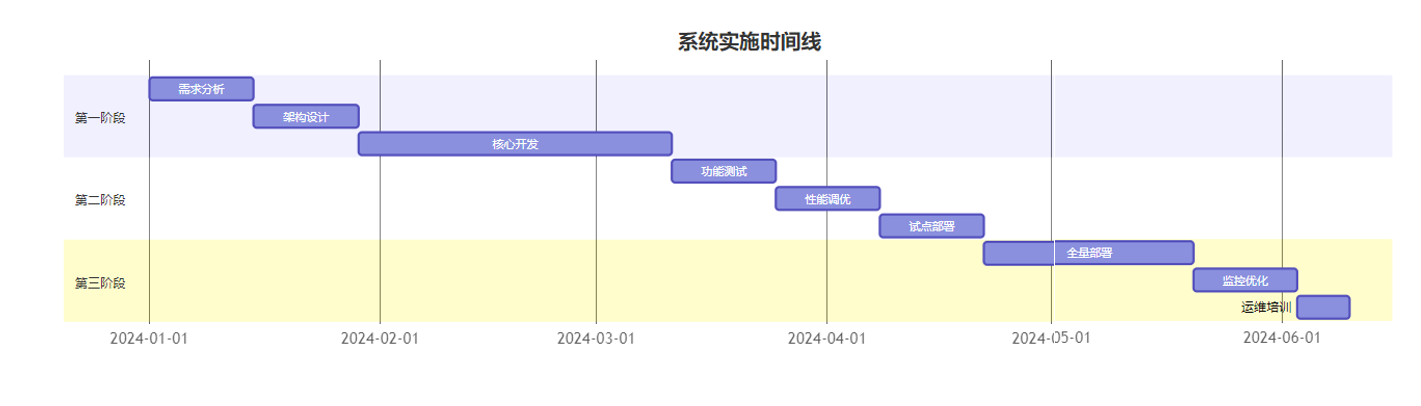
投资回报分析:
投资项目 | 一次性成本 | 年度运维成本 | 预期收益 |
|---|---|---|---|
软件开发 | 50万元 | 10万元 | 避免数据泄露损失200万+ |
硬件设备 | 30万元 | 15万元 | 提升响应效率50% |
人员培训 | 5万元 | 5万元 | 降低误报率80% |
总计 | 85万元 | 30万元 | ROI > 300% |
🔮 写在最后
构建一个优秀的服务器文件安全异常实时监测系统,就像是为企业的数字资产编织一张"安全之网"。这张网不仅要有足够的强度来抵御各种威胁,还要有足够的敏感度来感知最细微的异常。
关键成功要素:
- 技术选型要慎重:选择成熟稳定的技术栈,避免过度追求新技术
- 架构设计要合理:充分考虑扩展性和可维护性
- 运维体系要完善:自动化程度决定了系统的长期稳定性
- 团队能力要匹配:技术再好也需要合适的人来驾驭
持续改进方向:
- 检测精度优化:持续调优算法模型,降低误报率
- 响应速度提升:优化数据流处理,缩短检测延迟
- 成本控制优化:通过云原生技术降低运维成本
- 用户体验改善:提升界面易用性和操作便捷性
记住,安全不是一次性的项目,而是一个持续演进的过程。随着威胁环境的不断变化,我们的防护体系也需要持续升级和完善。今天的最佳实践,可能就是明天需要改进的地方。
最后的提醒: 再完美的技术方案,如果缺乏合适的管理流程和人员培训,也很难发挥应有的作用。技术只是基础,管理才是关键,人员是核心。三者结合,才能构建出真正有效的安全防护体系。
希望这篇文章能够为您的文件安全监测系统建设提供一些有价值的参考!如果在实施过程中遇到任何问题,欢迎继续交流讨论。
🔥 技术交流群:加入我们的技术交流群,与更多安全专家探讨最新的防护技术和实践经验!
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-07-16,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号