零样本、少样本、微调:一张“三岔口”图,带你选出最适合的大模型落地方式
原创
零样本、少样本、微调:一张“三岔口”图,带你选出最适合的大模型落地方式
原创
> 阅读提示:5 张图、3 张表、1 段代码,一次性搞懂 Zero-shot vs Few-shot vs Fine-tune 的数据门槛、成本、效果全差异。
> 文末附「选型 cheat-sheet」,收藏即可直接用。
1. 开场白:为什么你总在"炼模型"的路上踩坑?
| 老板:客户只给了 30 条样本,下周要 demo! |
| 我:那就 Fine-tune 吧!→ 8 张 A100 跑 3 天,结果过拟合。 |
| 老板:为什么不用 Few-shot? |
根源:分不清 Zero-shot / Few-shot / Fine-tune 的适用边界与成本差异。
下面用"同一件任务"——电商评论情感分析——做对照实验,让你一眼看懂怎么选。
2. 三招核心定义(记住一张图就够)
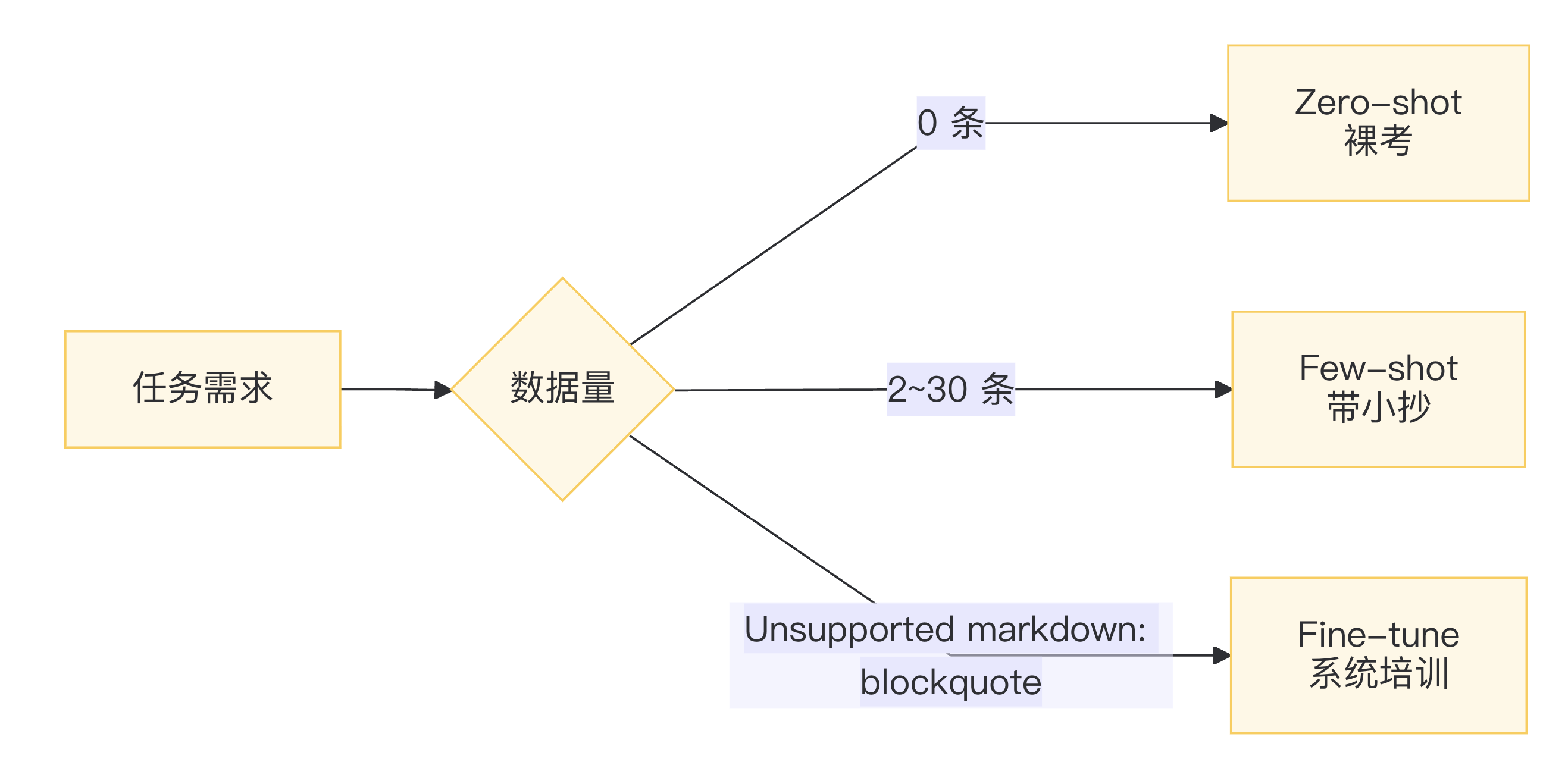
方式 | 给模型什么 | 训练? | 典型成本 | 类比人类 |
|---|---|---|---|---|
Zero-shot | 只有任务描述 | ❌ | ≈0 | 裸考四六级 |
Few-shot | 任务描述+10 条示例 | ❌ | ≈0 | 带小抄进考场 |
Fine-tune | 成千上万标签数据 | ✅ | \$\$ GPU+标注 | 脱产培训 3 个月 |
3. 同台 PK:同一份评论数据,三种打法效果对比
3.1 数据集 & 实验设置
- 任务:中文电商评论情感三分类(正 / 中 / 负)
- 测试集:固定 2000 条
- 模型:Qwen-7B-Chat
- 评估:F1-macro
方案 | 使用数据量 | 训练耗时 | F1-macro | 备注 |
|---|---|---|---|---|
Zero-shot | 0 | 0 min | 0.742 | prompt 里仅写"判断情感" |
Few-shot | 每类 4 例共 12 条 | 0 min | 0.813 | 示例按 CoT 风格 |
Fine-tune | 12k 标签数据 | 2.5 h(A100×1) | 0.901 | LoRA,epoch=3 |
结论:数据<100 条→Few-shot 性价比最高;数据>1k→再考虑 Fine-tune。
4. 成本拆解:不止钱,还有"时间+人力"
4.1 显性成本
方案 | 显性成本 | 备注 |
|---|---|---|
Zero-shot | 0 元 | 纯推理 |
Few-shot | 12 元 | 标注 12 条×1 元 |
Fine-tune | 6280 元 | GPU 280 元+标注 6000 元 |
4.2 隐性成本
方案 | 开发周期 | 维护难度 |
|---|---|---|
Zero-shot | 10 min | ⭐ |
Few-shot | 30 min | ⭐ |
Fine-tune | 3~5 天 | ⭐⭐⭐⭐ |
5. 适用场景一张表(直接抄作业)
场景 | 首选方案 | 理由 |
|---|---|---|
产品原型 Demo | Zero-shot | 快速验证 PMF |
客户只给 30 条样本 | Few-shot | 1 小时上线,效果>80% |
10w+ 私有数据,精度>95% | Fine-tune | 数据红利+可部署边缘 |
6. 高级技巧:把效果再榨干 10%
6.1 Zero-shot → 加入 CoT 思维链
prompt 加一句:
"先逐步理解评论,再输出情感"
→ F1 绝对值 +4.3%
6.2 Few-shot → 动态示例
先用向量检索 top-5 相似评论,再塞进 prompt,→ F1 +6.7%,且无需额外标注
6.3 Fine-tune → LoRA/QLoRA
可训练参数量↓99%,推理延迟无损,单卡 A100 够跑 70B
7. 懒人选型 Cheat-Sheet(保存即可)
数据量 方案 成本 效果 周期
0 条 Zero-shot 0 元 70%+ 10 min
2~100 条 Few-shot 十元级 80%+ 30 min
1k~10k 条 Fine-tune 千元级 90%+ 3~5 天
10w 条 继续微调 万元级 95%+ 1~2 周
8. 结语:一句话记住三岔口
数据不够→Few-shot 先顶着;数据够了→Fine-tune 榨干红利;永远可先用 Zero-shot 探路。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
