解密prompt系列62. Agent Memory新视角 - MATTS&CFGM&MIRIX
原创
解密prompt系列62. Agent Memory新视角 - MATTS&CFGM&MIRIX
原创
今天我们来聊聊AI智能体中至关重要的组件——记忆系统,它能有效避免的Agent像只有7秒记忆的金鱼,不断重复错误,循环往复。
记忆的两种面孔:LLM Memory vs Agent Memory
之前我们探讨过Mem0和LlamaIndex对大模型记忆的工程化实现,但这两个库更侧重于LLM Memory而非Agent Memory。这两者有何不同?本质上Agent Memory是包含了LLM Memory的。那增量的差异来自
- LLM Memory:更像是事实备忘录,记录对话中的具体事实和场景信息
- Agent Memory:更像是经验笔记本,记录执行轨迹和从历史行动中提炼的智慧
Agent Memory的三大经验维度
🛠️ Tool-工具使用经验:智能体在使用各种工具过程中积累的心得体会
- 比如:每个API能解决什么问题?如何使用搜索API查询效果更好?
🌍 Envirment-环境适应经验:面对不同环境时,如何组合使用工具的智慧
- 比如:在复杂网络环境下,应该优先使用哪些轻量级工具
🔍 Observation-观察反馈经验:根据历史执行结果优化后续行动的决策模式
- 比如:某些错误信息通常意味着需要重试,而非立即放弃
有效记忆带来的双重价值
🚀 更少的执行步骤
- 减少环境探索:熟悉地形就不需要步步为营
- 减少试错成本:知道什么方法有效,什么会失败
- 快速问题定位:历史失败经验让debug更高效
- 减少过度思考:成熟的解决方案无需反复推敲
🎯 更高的成功率
本质上,如果给模型无限的时间和资源,任务完成率其实很高。多数失败源于现实约束:有限的循环次数、Token限制和上下文长度。因此,减少步骤直接提升了成功率。
最近Agent Memory的论文如雨后春笋,但重复度较高。我们将重点分析三篇代表性工作:
- CFGM:离线轨迹经验提取
- ReasoningBank:轨迹经验提取和test-time scaling结合
- MIRIX:提供完整记忆工程方案和全面记忆分类
🌱 CFGM:从执行轨迹中提炼多粒度记忆
Coarse-to-Fine Grounded Memory for LLM Agent Planning
这篇论文对如何从轨迹中提取多粒度记忆给出了有操作性的方案,有几个思路值得一看。
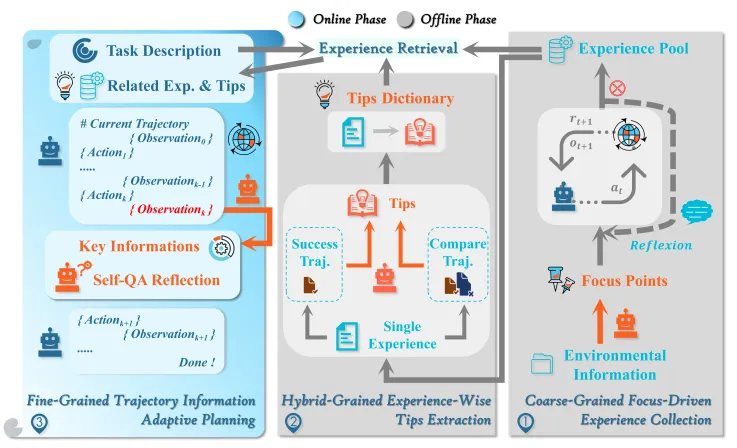
记忆收集和压缩经历两个离线步骤和一个在线步骤,让我们一探究竟。
第一步:粗粒度焦点——经验收集的“战略指南针”
传统的离线轨迹收集多让智能体随机探索同一任务,但CFGM引入了任务焦点(Focus Point)这一创新概念。** 模型会先基于任务描述和任务示例去对任务进行系统性的分析,提炼完成任务的指导原则作为最粗粒度的Tips。随后这些Tips会作为模型上文,让模型更有针对性地收集每个任务的多条执行路径。
例如对于细粒度搜索问题"I'm looking for hair treatments that are sulfate and paraben free and are of high quality too. I need ti in bottle for with 60 capusled and price lower than 50 dollars."
粗粒度提示会包括"Use a Detailed search query that includes specific attributes of the product you are looking for"
有趣的是,焦点概念只用于离线收集,在线执行中并未使用。
第二步:混合粒度提示——成功与失败的“经验结晶”
基于收集到的多条执行路径,CFGM和Memp都采用了相似的路径对比经验总结方案:
- 对比中学习(提炼防错与成功的关键) 这种方式专门针对那些既有成功轨迹又有失败轨迹的任务。通过对比,可以清晰地看出“做什么会失败”以及“做什么才能成功”。
任务:在WebShop中寻找一款特定的护发产品。 失败轨迹:Agent使用了过于简单的搜索词,导致结果不相关。 成功轨迹:Agent使用了包含多个关键属性(如“sulfate paraben free”、“bottle”、“60 capsules”)的详细搜索词。 生成的提示(细粒度):“使用包含产品具体属性(如无硫酸盐、瓶装、60粒)的详细搜索查询。” 这是一个非常具体、可立即执行的操作建议。
- 从纯成功中升华(提炼高阶策略) 这种方式针对那些一次就成功的任务。由于没有失败作为对比,提炼的重点在于总结成功的核心要素和可推广的策略。
第三步:细粒度关键信息支持自适应规划
前两步离线完成,第三步是在线执行中的经验应用。任务开始时,基于任务描述通过向量检索寻找相似历史任务,将其成功轨迹和混合粒度提示作为上文。执行中遇到失败时,采用两步反思机制:
- KIE:基于任务目标,初始环境,之前任务的完成过程抽取任务关键信息。
- KIR:基于KIE,历史相似任务的成功路径和当前路径,先进行自我反思提问,再思考解决方案。

🧠 ReasoningBank: 记忆与推理扩展的完美融合
ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory
对比CFGM先离线构建记忆再在在线推理时检索使用,谷歌这篇ReasoningBank直接用于在线推理,并重点关注把如何使用推理扩展策略进一步提升记忆效果
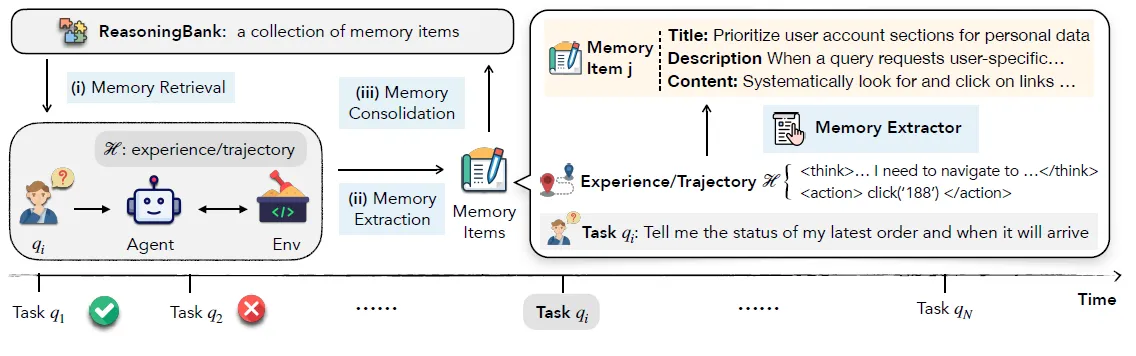
抽取记忆
先来说下记忆Schema的设计,对比CFGM直接使用展平的Tips作为记忆,ReasoningBank的记忆项设计更加结构化,包含三个字段
- 标题:策略的核心标识,如"分页导航策略"
- 描述:一句话总结策略精髓
- 内容:详细的推理步骤和决策依据
抽取出的记忆会直接增量写入的ReasoningBank,论文并没有尝试例如记忆合并、记忆更新之类的剪枝策略。用于检索的向量是使用Input Query构建并用于后续的记忆检索。(这里的简单设计是为了后面更突出Test-Time-Scaling对于记忆的加成)
MATTS:记忆驱动的推理时扩展
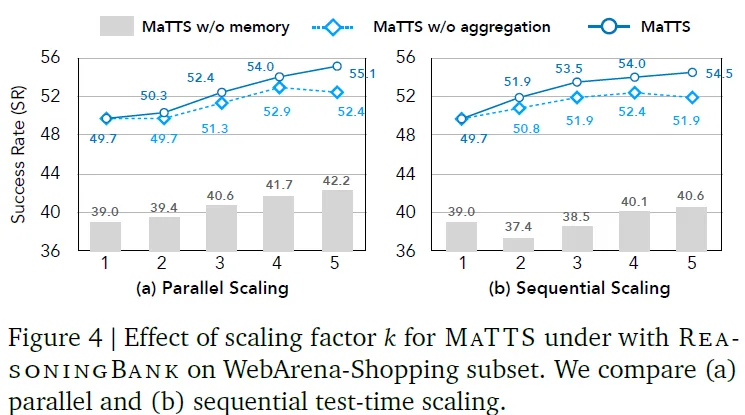
重点来了!这是论文最亮眼的创新——Memory-aware Test-Time Scaling (MATTS)。传统测试时扩展只是简单增加计算资源,而MATTS让记忆系统与扩展过程产生了美妙的化学反应。论文尝试了两种扩展策略分别是
- Parallel Scaling: 通过并行推理得到多个轨迹,并有效使用Self-Contrast进行轨迹对比从而得到
- Sequential Scaling:通过在串行推理过程中不断使用Self-Refine进行推理优化。最终抽取记忆时会使用中间反思的全部内容。
以上两种策略对应的System prompt如下

论文在Webarena上实验了,两种test-time-scaling策略,并发现二者都进一步提升原有memory的使用效果,并切均有较好的扩展效应,其中Parallel策略的效果增益衰减的更慢,扩展效应更好。可能得益于更多并行策略带来的更丰富的空间探索和多样性。
🏗️ MIRIX:工程视角的多种记忆类型
MIRIX: Multi-Agent Memory System for LLM-Based Agents
MIRIX的亮点在于提供了全面的记忆分类,融合了LLM的事实记忆和Agent的轨迹记忆,还考虑了多模态文件和隐私安全。让我们先从分类入手,再透过代码看每种记忆的存储与获取。
MIRIX 的记忆是如何“理解”和“分类”信息的?
早期的COLA论文将记忆分为情景、语义和程序化记忆,MIRIX在此基础上扩展为六大类:
- 核心记忆(Core Memory)- 你的“身份档案” 存储最基础、最持久的信息:姓名、喜好、习惯等,确保每次互动都“认得你”。
- 情景记忆(Episodic Memory)- 你的“生活日记” 记录带时间戳的事件:某次对话、会议或任务完成情况,支持“我上周三做了什么?”这类查询。
- 语义记忆(Semantic Memory) - 你的“知识图谱” 存储抽象概念和事实:“J.K.罗琳是《哈利·波特》的作者”,帮助你理解世界和关系网络。
- 程序记忆(Procedural Memory)- 你的“技能手册” 存放操作流程:“如何报销差旅费”、“怎么设置会议提醒”,引导复杂任务完成。
- 资源记忆(Resource Memory)- 你的“个人文件柜” 保存接触过的文档、图片、语音转录等非结构化内容,方便随时查阅。
- 知识库(Knowledge Vault) - 你的“保险箱” 专门存放敏感信息:密码、地址、联系方式等,严格保护,安全调用。
基于Agent的多分类记忆存储
MIRIX使用PostgreSQL作为存储后端,为六种记忆设计了不同的表结构。
记忆更新由Meta-Agent触发:基于用户最新消息判断是否需要更新记忆,如需更新则调用trigger_memory_update工具,参数指定记忆类型。
记忆类型 | 表字段示例 | 实例说明 |
|---|---|---|
核心记忆 | id, label, value, user_id... | 用户名为Alex,偏好直接沟通,软件工程师 |
情景记忆 | id, event_type, summary, details... | 2025-03-05与大学朋友Sarah共进晚餐,讨论职业转变 |
语义记忆 | id, name, summary, details... | Jane Smith - TechCorp项目经理,敏捷方法专家 |
程序记忆 | id, entry_type, summary, steps... | 晨间例行:1.查邮件 2.看日历 3.优先级排序 4.从最难任务开始 |
资源记忆 | id, title, summary, resource_type... | ProjectPlan.docx - 包含Q1路线图和里程碑详情 |
知识库 | id, entry_type, source, sensitivity... | 敏感信息条目、来源、敏感度 |
根据Meta Agent的工具调用结果,触发相应记忆类型的专门Agent,每个Agent都有特定指令负责该类型记忆的压缩和提取。举个例子,整个记忆更新和读取的流程如下:
- 用户执行了一系列步骤"打开编辑器 -> 创建文件 -> 编写代码 -> 保存文件"
meta_memory_agent检测到这是一个多步骤操作序列,调用trigger_memory_update_with_instruction,指定 memory_type="procedural"- procedural_memory_agent接收请求,基于以下的系统指令推理得到ProceduralMemoryItem
You are the Procedural Memory Manager, one of six agents in a memory system. The other agents are the Meta Memory Manager, Episodic Memory Manager, Resource Memory Manager, Knowledge Vault Memory Manager, and the Chat Agent. You do not see or interact directly with these other agents—but you share the same memory base with them.
The system will receive various types of messages from users, including text messages, images, transcripted voice recordings, and other multimedia content. When messages are accumulated to a certain amount, they will be sent to you, along with potential conversations between the user and the Chat Agent during this period. You need to analyze the input messages and conversations, extract step-by-step instructions, "how-to" guides, and any other instructions and skills, and save them into the procedural memory.
This memory base includes the following components:
1. Core Memory:
Contains fundamental information about the user, such as the name, personality, simple information that should help with the communication with the user.
2. Episodic Memory:
Stores time-ordered, event-based information from interactions—essentially, the "diary" of user and assistant events.
3. Procedural Memory:
Definition: Contains how-to guides, step-by-step instructions, or processes the assistant or user might follow.
Example: "How to reset the router."
Each entry in Procedural Memory has:
(a) entry_type (e.g., 'workflow', 'guide', 'script')
(b) description (short descriptive text)
(c) steps (the procedure in a structured or JSON format)
(d) tree_path: Required hierarchical categorization path for organizing procedures (e.g., ["technology", "networking", "troubleshooting"] for router reset guides, or ["cooking", "baking", "desserts"] for recipe instructions). Use this to create logical groupings and enable better organization of procedural knowledge.
4. Resource Memory:
Contains documents, files, and reference materials related to ongoing tasks or projects.
5. Knowledge Vault:
A repository for static, structured factual data such as phone numbers, email addresses, passwords, or other knowledge that are not necessarily always needed during the conversation but are potentially useful at some future point.
6. Semantic Memory:
Contains general knowledge about a concept (e.g. a new software name, a new concept) or an object (e.g. a person, a place, where the details would be the understanding and information about them.)
When receiving messages and potentially a message from the meta agent (There will be a bracket saying "[Instruction from Meta Memory Manager]"), make a single comprehensive memory update:
**Single Function Call Process:**
1. **Analyze Content**: Examine all messages and conversations to identify step-by-step instructions, "how-to" guides, workflows, or any procedural knowledge.
2. **Make Update**: Use ONE appropriate procedural memory function to save the most important identified procedure or instruction with proper entry_type ('workflow', 'guide', 'script'), description, and detailed steps. When appropriate, include a `tree_path` to categorize the procedure hierarchically (e.g., ["work", "development", "deployment"] for deployment procedures, or ["personal", "health", "exercise"] for workout routines).
3. **Skip Update if Necessary**: If there is no updates to make, then skip the update by calling `finish_memory_update`.
**Important Notes:**
- Make only ONE function call total except for receiving the messages from Chat Agent
- Look for any structured processes, workflows, or instructional content in the messages
- Save procedures with appropriate entry_type ('workflow', 'guide', 'script'), description, and detailed steps
- When relevant, use `tree_path` to create logical hierarchical categories for better organization (e.g., ["technology", "software", "installation"] or ["home", "maintenance", "repair"])
- If there is absolutely nothing procedural to update, do not make any function calls
- Prioritize the most complete or useful procedural information if multiple procedures are present Procedure类型的记忆推理得到的为以下结构体(每种记忆的结构定义不同)
class ProceduralMemoryItemBase(MirixBase):
"""
Base schema for storing procedural knowledge (e.g., workflows, methods).
"""
__id_prefix__ = "proc_item"
entry_type: str = Field(..., description="Category (e.g., 'workflow', 'guide', 'script')")
summary: str = Field(..., description="Short descriptive text about the procedure")
steps: List[str] = Field(..., description="Step-by-step instructions as a list of strings")
tree_path: List[str] = Field(..., description="Hierarchical categorization path as an array of strings")- 调用
procedural_memory_insert函数,计算步骤和摘要的嵌入向量,通过 create_item 方法将数据保存到数据库 - 在收到用户新的聊天信息后,会先通过模型推理判断对话是否出现新的topic,如果有新出现的topic(通过工具调用),会使用新的topic进行记忆检索(BM25 or embedding),然后把检索到的记忆更新到system prompt中。
论文今天就分享这么多,记忆的本质不是存储,而是理解;不是记录,而是进化。 当AI智能体开始从自己的成功与失败中学习,当它们能够积累并应用经验时,我们离真正智能的伙伴就更近了一步。
本文只是Agent Memory领域的冰山一角,更多精彩内容,可移步 >> DecryPrompt
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
