DINOv3目标检测入门实战:基于血细胞分类的完整实现
原创
DINOv3目标检测入门实战:基于血细胞分类的完整实现
原创
引言
DINOv3(Self-Supervised Vision Transformer)是Meta AI开发的一种强大的视觉表示学习模型,它通过自监督学习在大量无标注数据上预训练,能够学习到丰富的视觉特征。本文将详细介绍如何使用DINOv3进行目标检测任务,以血细胞分类为例,展示从数据准备到模型训练再到推理部署的完整流程。
1. 概述
目标:训练一个模型,可以输入一张血细胞图片,认出血细胞中的血小板、红细胞、白细胞并获得它们的位置。
1.1 技术架构
本项目采用了一种创新的目标检测方法:
- Backbone: DINOv3 ViT-S/16(冻结的预训练模型)
- 检测头: Random Forest(随机森林分类器)
- 数据集: BCCD (Blood Cell Count and Detection)
- 任务: 检测三种血细胞类型
- Platelets (血小板) - 红色标注
- RBC (红细胞) - 绿色标注
- WBC (白细胞) - 蓝色标注
2. 环境准备
2.1 依赖安装
在4090显卡的服务器中,ubuntu22.04操作系统,Python版本为3.10.19。
pip3 install ftfy
pip3 install omegaconf
pip3 install regex
pip3 install scikit-learn
pip3 install submitit
pip3 install termcolor
pip3 install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu124
pip3 install tqdm
pip3 install torchmetrics
pip3 install safetensors
pip3 install accelerate
pip3 install matplotlib2.2 数据集准备
BCCD数据集包含血细胞显微镜图像,每张图像都有PASCAL VOC格式的XML标注文件。数据集结构如下:
BCCD_Dataset/
├── BCCD/
│ ├── JPEGImages/ # 图像文件 (BloodImage_00***.jpg)
│ ├── Annotations/ # XML标注文件 (BloodImage_00***.xml)
│ └── ImageSets/
│ └── Main/
│ ├── train.txt # 训练集图像列表
│ ├── test.txt # 测试集图像列表
│ ├── val.txt # 验证集图像列表
│ └── trainval.txt # 训练+验证集图像列表
├── dataset/ # 数据集处理脚本
├── scripts/ # 可视化等工具脚本
└── example.jpg # 示例图像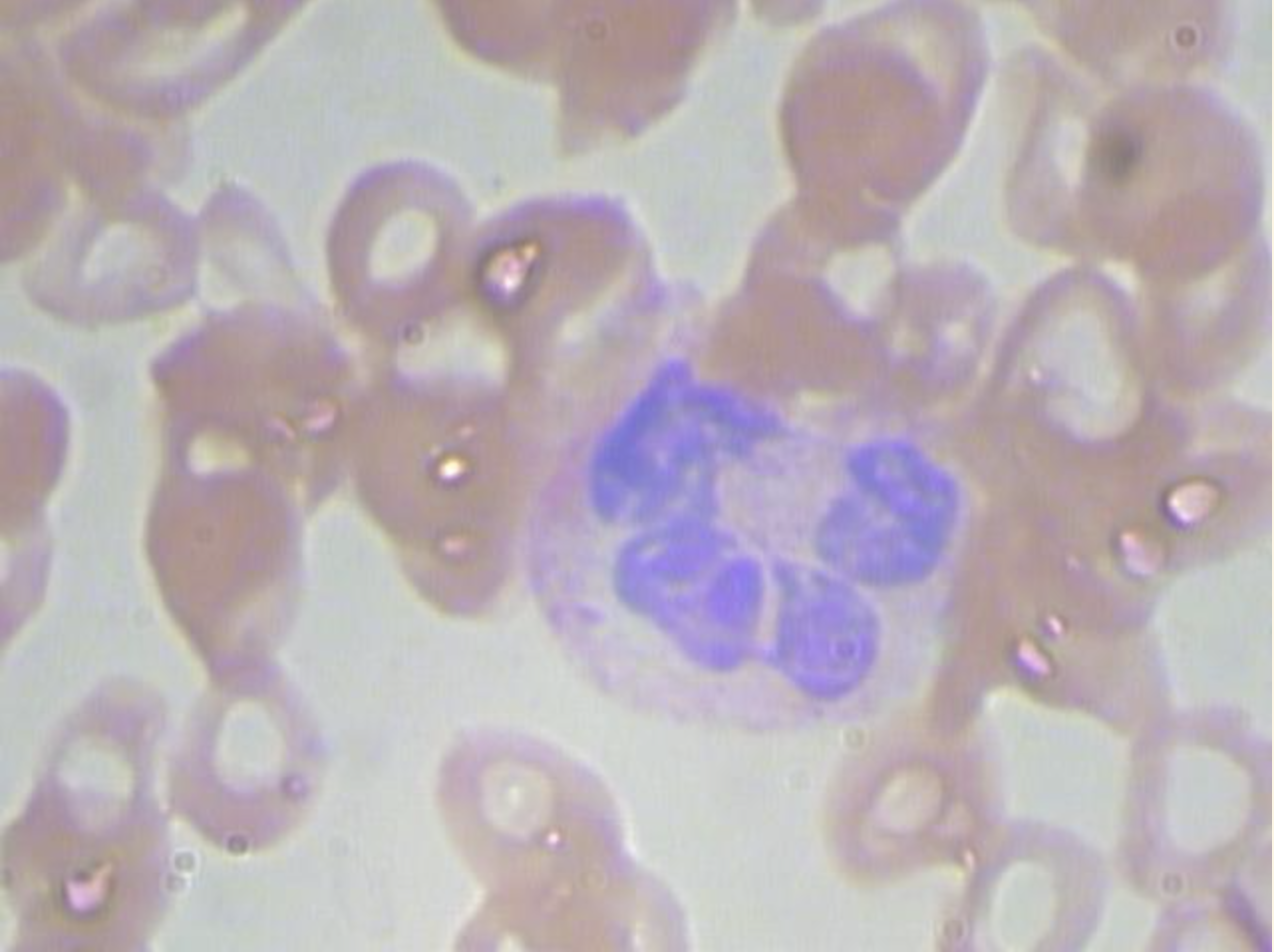
3. 核心实现解析
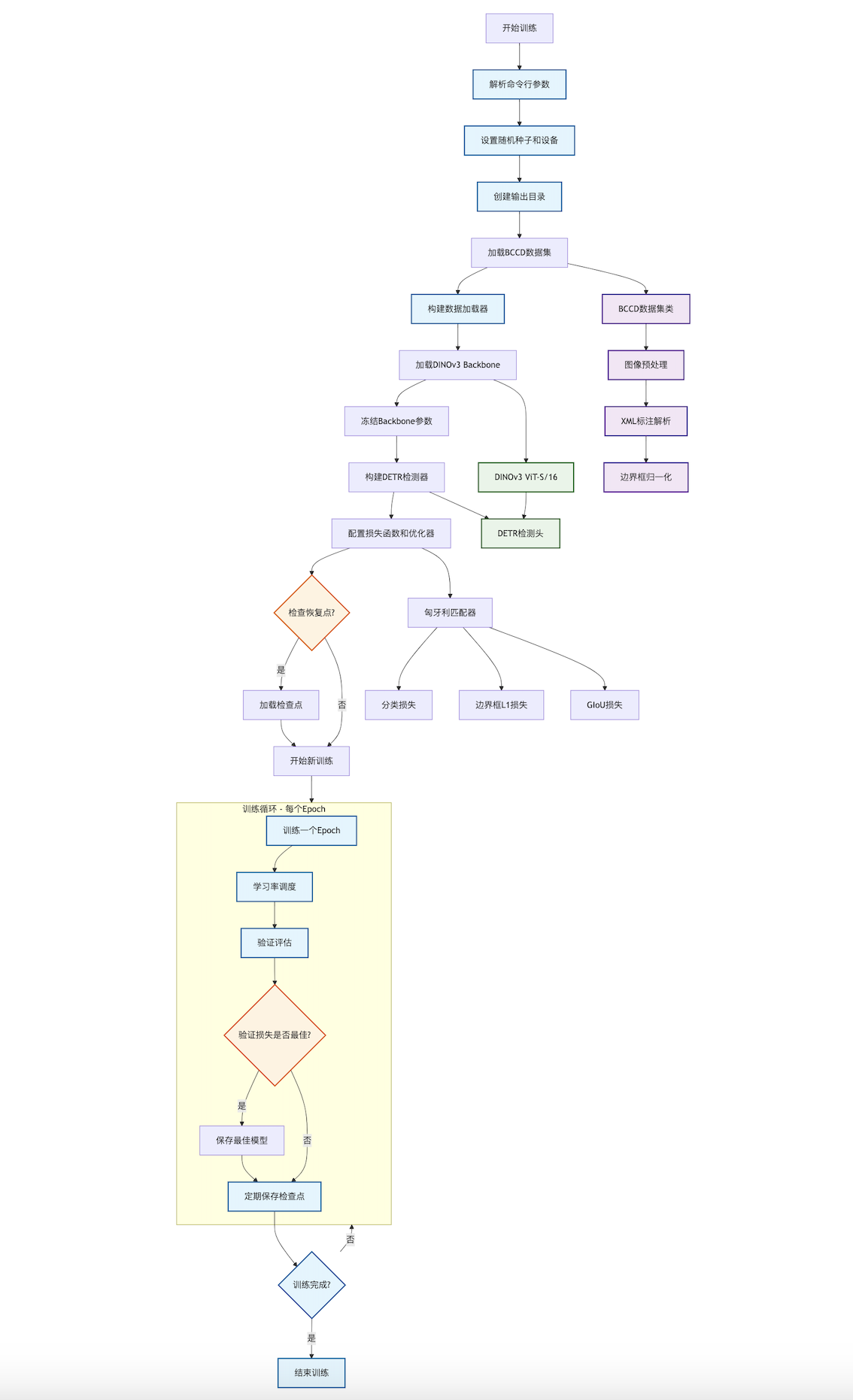
4. 训练流程
4.1 完整训练脚本
训练脚本 bccd_rf_train.py 的主要流程:
- 参数解析和环境设置
- 数据路径验证
- DINOv3模型加载
- 特征提取(训练集和验证集)
- 数据平衡处理
- 随机森林训练
- 模型评估
- 模型和配置保存
"""
血细胞分类训练脚本 - 使用DINOv3特征 + 随机森林分类器
这种方法更简单直接,通常在小数据集上效果更好
DINOv3 使用 patch_size=16,**要求输入图像尺寸必须是 16 的倍数**
"""
import argparse
import os
import sys
import xml.etree.ElementTree as ET
from pathlib import Path
from typing import Dict, List, Tuple, Optional
import pickle
import time
import torch
import numpy as np
from PIL import Image
from torchvision import transforms as T
from tqdm import tqdm
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
import joblib
# 添加项目路径
sys.path.insert(0, os.path.join(os.path.dirname(__file__), ".."))
# 全局配置
CLASS_NAMES = ['Platelets', 'RBC', 'WBC']
CLASS_TO_IDX = {name: idx for idx, name in enumerate(CLASS_NAMES)}
# ============================================================================
# 1. 数据处理相关函数
# ============================================================================
def parse_xml_annotation(xml_file: Path) -> List[Dict]:
"""解析PASCAL VOC格式的XML标注文件
Args:
xml_file: XML文件路径
Returns:
标注对象列表,每个对象包含class_name和bbox
"""
tree = ET.parse(xml_file)
root = tree.getroot()
objects = []
for obj in root.findall('object'):
class_name = obj.find('name').text
bbox = obj.find('bndbox')
xmin = int(bbox.find('xmin').text)
ymin = int(bbox.find('ymin').text)
xmax = int(bbox.find('xmax').text)
ymax = int(bbox.find('ymax').text)
objects.append({
'class_name': class_name,
'bbox': (xmin, ymin, xmax, ymax)
})
return objects
def validate_data_paths(data_root: Path) -> Tuple[Path, Path, Path, Path]:
"""验证数据路径是否存在并返回标准化路径
Args:
data_root: 数据集根目录
Returns:
(train_img_dir, train_ann_dir, test_img_dir, test_ann_dir)
"""
train_img_dir = data_root / 'BCCD' / 'JPEGImages'
train_ann_dir = data_root / 'BCCD' / 'Annotations'
test_img_dir = data_root / 'BCCD_Dataset' / 'BCCD' / 'JPEGImages'
test_ann_dir = data_root / 'BCCD_Dataset' / 'BCCD' / 'Annotations'
# 如果测试集路径不存在,使用训练集路径
if not test_img_dir.exists():
test_img_dir = train_img_dir
test_ann_dir = train_ann_dir
print("注意: 使用训练集作为验证集")
# 验证训练集路径
if not train_img_dir.exists():
raise FileNotFoundError(f"训练图片目录不存在: {train_img_dir}")
if not train_ann_dir.exists():
raise FileNotFoundError(f"训练标注目录不存在: {train_ann_dir}")
return train_img_dir, train_ann_dir, test_img_dir, test_ann_dir
def balance_dataset(X: np.ndarray, y: np.ndarray,
method: str = 'undersample',
random_state: int = 42) -> Tuple[np.ndarray, np.ndarray]:
"""平衡数据集
Args:
X: 特征矩阵
y: 标签数组
method: 平衡方法 ('undersample' 或 'oversample')
random_state: 随机种子
Returns:
平衡后的(特征, 标签)
"""
# 输入验证
if len(X) == 0 or len(y) == 0:
raise ValueError(f"❌ 输入数据为空!X shape: {X.shape}, y shape: {y.shape}")
if len(X) != len(y):
raise ValueError(f"❌ X 和 y 的长度不匹配!X: {len(X)}, y: {len(y)}")
np.random.seed(random_state)
# 统计类别分布
unique, counts = np.unique(y, return_counts=True)
if len(unique) == 0:
raise ValueError(f"❌ 没有找到任何类别!请检查标签数据")
class_counts = dict(zip(unique, counts))
print(f"\n⚖️ 平衡数据集 (方法: {method})")
print(f" 原始分布: {class_counts}")
# 执行平衡操作
if method == 'undersample':
X_balanced, y_balanced = _undersample(X, y, unique, counts)
elif method == 'oversample':
X_balanced, y_balanced = _oversample(X, y, unique, counts)
else:
raise ValueError(f"未知的平衡方法: {method}")
# 打乱数据
shuffle_indices = np.random.permutation(len(X_balanced))
X_balanced = X_balanced[shuffle_indices]
y_balanced = y_balanced[shuffle_indices]
balanced_counts = dict(zip(*np.unique(y_balanced, return_counts=True)))
print(f" 平衡后分布: {balanced_counts}")
print(f" 总样本: {len(X_balanced)} (原始: {len(X)})")
return X_balanced, y_balanced
def _undersample(X: np.ndarray, y: np.ndarray,
unique: np.ndarray, counts: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
"""下采样到最小类别的数量"""
min_samples = min(counts)
balanced_X = []
balanced_y = []
for class_idx in unique:
class_mask = (y == class_idx)
class_X = X[class_mask]
class_y = y[class_mask]
# 随机采样
indices = np.random.choice(len(class_X), min_samples, replace=False)
balanced_X.append(class_X[indices])
balanced_y.append(class_y[indices])
return np.vstack(balanced_X), np.hstack(balanced_y)
def _oversample(X: np.ndarray, y: np.ndarray,
unique: np.ndarray, counts: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
"""上采样到最大类别的数量"""
max_samples = max(counts)
balanced_X = []
balanced_y = []
for class_idx in unique:
class_mask = (y == class_idx)
class_X = X[class_mask]
class_y = y[class_mask]
# 随机采样(允许重复)
indices = np.random.choice(len(class_X), max_samples, replace=True)
balanced_X.append(class_X[indices])
balanced_y.append(class_y[indices])
return np.vstack(balanced_X), np.hstack(balanced_y)
# ============================================================================
# 2. 模型相关函数
# ============================================================================
def load_dinov3_model(model_name: str = 'dinov3_vits16',
weights_path: Optional[str] = None,
device: str = 'cuda',
local_repo: Optional[str] = None) -> torch.nn.Module:
"""加载DINOv3模型用于特征提取
Args:
model_name: 模型名称
weights_path: 预训练权重路径
device: 计算设备
local_repo: 本地仓库路径,如果提供则从本地加载
Returns:
DINOv3模型实例
"""
print(f"📦 加载DINOv3模型: {model_name}")
# 加载模型结构
model = _load_model_structure(model_name, local_repo)
# 加载预训练权重
if weights_path and os.path.exists(weights_path):
_load_pretrained_weights(model, weights_path)
model = model.to(device)
model.eval()
print("✓ DINOv3模型加载完成")
return model
def _load_model_structure(model_name: str, local_repo: Optional[str]) -> torch.nn.Module:
"""加载模型结构"""
if local_repo and os.path.exists(local_repo):
print(f"📂 使用本地仓库: {local_repo}")
model = torch.hub.load(
repo_or_dir=local_repo,
model=model_name,
source='local',
pretrained=False # 稍后手动加载权重
)
else:
model = torch.hub.load(
repo_or_dir='facebookresearch/dinov3',
model=model_name,
source='github',
pretrained=True # 使用预训练权重
)
return model
def _load_pretrained_weights(model: torch.nn.Module, weights_path: str):
"""加载预训练权重到模型"""
print(f"📦 加载预训练权重: {weights_path}")
state_dict = torch.load(weights_path, map_location='cpu', weights_only=False)
# 处理不同的权重格式
if 'teacher' in state_dict:
state_dict = state_dict['teacher']
elif 'model' in state_dict:
state_dict = state_dict['model']
# 过滤并加载权重
model_keys = set(model.state_dict().keys())
filtered_dict = {}
for k, v in state_dict.items():
new_k = k.replace('backbone.', '').replace('module.', '')
if new_k in model_keys:
filtered_dict[new_k] = v
model.load_state_dict(filtered_dict, strict=False)
# ============================================================================
# 3. 特征提取相关函数
# ============================================================================
def extract_patch_features(model: torch.nn.Module,
image: Image.Image,
bbox: Tuple[int, int, int, int],
patch_size: int = 224,
device: str = 'cuda') -> np.ndarray:
"""从图像的单个bbox区域提取DINOv3特征
Args:
model: DINOv3模型
image: PIL图像
bbox: 边界框 (xmin, ymin, xmax, ymax)
patch_size: 输入patch大小
device: 计算设备
Returns:
特征向量(1D numpy array)
"""
# 裁剪并预处理图像patch
patch_tensor = _preprocess_image_patch(image, bbox, patch_size, device)
# 提取特征
with torch.no_grad():
features = model.forward_features(patch_tensor)
feat = _extract_cls_token(features)
feat = feat.cpu().numpy().flatten()
return feat
def _preprocess_image_patch(image: Image.Image,
bbox: Tuple[int, int, int, int],
patch_size: int,
device: str) -> torch.Tensor:
"""预处理图像patch"""
xmin, ymin, xmax, ymax = bbox
# 裁剪bbox区域
patch = image.crop((xmin, ymin, xmax, ymax))
# 转换为tensor
transform = T.Compose([
T.Resize((patch_size, patch_size)),
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
patch_tensor = transform(patch).unsqueeze(0).to(device)
return patch_tensor
def _extract_cls_token(features) -> torch.Tensor:
"""从DINOv3特征中提取CLS token"""
# 优先使用x_norm_clstoken
if hasattr(features, 'x_norm_clstoken'):
return features.x_norm_clstoken
# 尝试使用tokens的第一个
if hasattr(features, 'tokens'):
return features.tokens[:, 0]
# 处理字典格式的输出
if isinstance(features, dict):
if 'x_norm_clstoken' in features:
return features['x_norm_clstoken']
# 使用patch tokens的平均值
feat = features.get('x_norm_patchtokens', features.get('tokens', None))
if feat is not None and feat.dim() > 2:
return feat.mean(dim=1)
# 处理tensor输出
if features.dim() == 3:
return features[:, 0]
return features
def extract_dataset_features(model: torch.nn.Module,
image_dir: Path,
annotation_dir: Path,
split: str = 'train',
device: str = 'cuda',
max_samples: Optional[int] = None) -> Tuple[np.ndarray, np.ndarray]:
"""从数据集中提取所有bbox的特征
Args:
model: DINOv3模型
image_dir: 图像目录
annotation_dir: 标注目录
split: 数据集划分名称(用于显示)
device: 计算设备
max_samples: 最大样本数(用于快速测试)
Returns:
(features, labels) - 特征矩阵和标签数组
"""
print(f"\n📊 提取{split}集特征...")
# 获取图像文件列表
image_files = sorted(list(image_dir.glob('*.jpg')))
if max_samples:
image_files = image_files[:max_samples]
features_list = []
labels_list = []
# 遍历所有图像
for img_file in tqdm(image_files, desc=f"处理{split}集"):
# 提取该图像的所有对象特征
img_features, img_labels = _extract_image_features(
model, img_file, annotation_dir, device
)
features_list.extend(img_features)
labels_list.extend(img_labels)
# 转换为numpy数组
features = np.array(features_list)
labels = np.array(labels_list)
# 打印统计信息
_print_extraction_summary(features, labels, split)
return features, labels
def _extract_image_features(model: torch.nn.Module,
img_file: Path,
annotation_dir: Path,
device: str) -> Tuple[List[np.ndarray], List[int]]:
"""提取单张图像中所有对象的特征"""
# 查找对应的XML标注文件
xml_file = annotation_dir / f"{img_file.stem}.xml"
if not xml_file.exists():
return [], []
# 解析标注
annotations = parse_xml_annotation(xml_file)
if not annotations:
return [], []
# 加载图像
image = Image.open(img_file).convert('RGB')
features_list = []
labels_list = []
# 提取每个bbox的特征
for obj in annotations:
class_name = obj['class_name']
if class_name not in CLASS_TO_IDX:
continue
bbox = obj['bbox']
try:
feat = extract_patch_features(model, image, bbox, device=device)
features_list.append(feat)
labels_list.append(CLASS_TO_IDX[class_name])
except Exception as e:
print(f"警告: 提取特征失败 {img_file.name} - {class_name}: {e}")
continue
return features_list, labels_list
def _print_extraction_summary(features: np.ndarray, labels: np.ndarray, split: str):
"""打印特征提取的统计信息"""
print(f"✓ 提取完成: {len(features)} 个样本")
print(f" 特征维度: {features.shape}")
unique, counts = np.unique(labels, return_counts=True)
class_dist = {CLASS_NAMES[idx]: count for idx, count in zip(unique, counts)}
print(f" 类别分布: {class_dist}")
# ============================================================================
# 4. 训练和评估相关函数
# ============================================================================
def train_random_forest(X_train: np.ndarray,
y_train: np.ndarray,
n_estimators: int = 200,
max_depth: int = 30,
random_state: int = 42) -> RandomForestClassifier:
"""训练随机森林分类器
Args:
X_train: 训练特征
y_train: 训练标签
n_estimators: 树的数量
max_depth: 最大深度
random_state: 随机种子
Returns:
训练好的随机森林分类器
"""
print(f"\n🌲 训练随机森林分类器...")
print(f" 参数: n_estimators={n_estimators}, max_depth={max_depth}")
start_time = time.time()
# 创建并训练随机森林
clf = RandomForestClassifier(
n_estimators=n_estimators,
max_depth=max_depth,
random_state=random_state,
n_jobs=-1, # 使用所有CPU核心
verbose=1,
class_weight='balanced', # 处理类别不平衡
min_samples_split=5,
min_samples_leaf=2
)
clf.fit(X_train, y_train)
train_time = time.time() - start_time
print(f"✓ 训练完成 (用时: {train_time:.2f}秒)")
# 打印特征重要性统计
_print_feature_importance(clf)
return clf
def _print_feature_importance(clf: RandomForestClassifier):
"""打印特征重要性统计"""
print("\n特征重要性统计:")
print(f" 平均重要性: {clf.feature_importances_.mean():.6f}")
print(f" 最大重要性: {clf.feature_importances_.max():.6f}")
print(f" 最小重要性: {clf.feature_importances_.min():.6f}")
def evaluate_model(clf: RandomForestClassifier,
X: np.ndarray,
y: np.ndarray,
split_name: str = "数据集"):
"""评估模型性能
Args:
clf: 训练好的分类器
X: 特征
y: 标签
split_name: 数据集名称(用于显示)
"""
print(f"\n📈 评估{split_name}...")
# 计算准确率
accuracy = clf.score(X, y)
print(f"\n{split_name}准确率: {accuracy:.4f}")
# 预测并生成报告
y_pred = clf.predict(X)
print(f"\n{split_name}分类报告:")
print(classification_report(y, y_pred, target_names=CLASS_NAMES))
print(f"\n{split_name}混淆矩阵:")
print(confusion_matrix(y, y_pred))
# ============================================================================
# 5. 保存和加载相关函数
# ============================================================================
def save_features(output_dir: Path,
X_train: np.ndarray,
y_train: np.ndarray,
X_val: Optional[np.ndarray],
y_val: Optional[np.ndarray],
balance_method: str):
"""保存提取的特征
Args:
output_dir: 输出目录
X_train: 训练特征
y_train: 训练标签
X_val: 验证特征
y_val: 验证标签
balance_method: 数据平衡方法
"""
features_path = output_dir / 'features.pkl'
print(f"\n💾 保存特征到: {features_path}")
with open(features_path, 'wb') as f:
pickle.dump({
'X_train': X_train,
'y_train': y_train,
'X_val': X_val,
'y_val': y_val,
'class_names': CLASS_NAMES,
'class_to_idx': CLASS_TO_IDX,
'balance_method': balance_method
}, f)
def save_model(clf: RandomForestClassifier, output_dir: Path):
"""保存随机森林模型
Args:
clf: 训练好的分类器
output_dir: 输出目录
"""
model_path = output_dir / 'rf_classifier.pkl'
print(f"\n💾 保存随机森林模型到: {model_path}")
joblib.dump(clf, model_path)
def save_config(output_dir: Path, args: argparse.Namespace):
"""保存训练配置
Args:
output_dir: 输出目录
args: 命令行参数
"""
config_path = output_dir / 'config.pkl'
print(f"💾 保存配置到: {config_path}")
config = {
'dinov3_model': args.dinov3_model,
'dinov3_weights': args.dinov3_weights,
'patch_size': args.patch_size,
'n_estimators': args.n_estimators,
'max_depth': args.max_depth,
'balance_method': args.balance_method,
'class_names': CLASS_NAMES,
'class_to_idx': CLASS_TO_IDX
}
with open(config_path, 'wb') as f:
pickle.dump(config, f)
# ============================================================================
# 6. 主程序相关函数
# ============================================================================
def parse_arguments() -> argparse.Namespace:
"""解析命令行参数"""
parser = argparse.ArgumentParser(description='血细胞分类训练 - DINOv3 + 随机森林')
# 数据路径
parser.add_argument('--data_root', type=str, default='../BCCD_Dataset',
help='BCCD数据集根目录')
parser.add_argument('--output_dir', type=str, default='output/bccd_rf_model',
help='输出目录')
# 模型参数
parser.add_argument('--dinov3_model', type=str, default='dinov3_vits16',
choices=['dinov3_vits16', 'dinov3_vitb16', 'dinov3_vitl16', 'dinov3_vitg14',
'dinov3_vith16plus', 'dinov3_vit7b16', 'dinov3_vits16plus', 'dinov3_vitl16plus'],
help='DINOv3模型类型')
parser.add_argument('--dinov3_weights', type=str, default=None,
help='DINOv3预训练权重路径')
parser.add_argument('--patch_size', type=int, default=224,
help='输入patch大小')
# 随机森林参数
parser.add_argument('--n_estimators', type=int, default=200,
help='随机森林树的数量')
parser.add_argument('--max_depth', type=int, default=30,
help='随机森林最大深度')
parser.add_argument('--balance_method', type=str, default='oversample',
choices=['undersample', 'oversample', 'none'],
help='数据平衡方法:undersample(下采样), oversample(上采样), none(不平衡)')
# 训练参数
parser.add_argument('--local_repo', type=str, default='/data/william/Workspace/dinov3',
help='本地DINOv3仓库路径')
parser.add_argument('--device', type=str, default='cuda',
help='设备 (cuda 或 cpu)')
parser.add_argument('--max_samples', type=int, default=None,
help='最大样本数(用于快速测试)')
parser.add_argument('--random_seed', type=int, default=42,
help='随机种子')
return parser.parse_args()
def setup_environment(args: argparse.Namespace):
"""设置运行环境
Args:
args: 命令行参数
"""
# 创建输出目录
output_dir = Path(args.output_dir)
output_dir.mkdir(parents=True, exist_ok=True)
# 设置随机种子
np.random.seed(args.random_seed)
torch.manual_seed(args.random_seed)
# 检查设备
if args.device == 'cuda' and not torch.cuda.is_available():
print("警告: CUDA不可用,使用CPU")
args.device = 'cpu'
def print_header(args: argparse.Namespace):
"""打印程序标题和配置信息"""
print("="*80)
print("血细胞分类训练 - DINOv3特征 + 随机森林分类器")
print("="*80)
print(f"数据集: {args.data_root}")
print(f"DINOv3模型: {args.dinov3_model}")
print(f"随机森林参数: n_estimators={args.n_estimators}, max_depth={args.max_depth}")
print(f"数据平衡方法: {args.balance_method}")
print(f"输出目录: {args.output_dir}")
print(f"设备: {args.device}")
print("="*80)
def validate_extracted_data(X: Optional[np.ndarray],
y: Optional[np.ndarray],
data_type: str,
img_dir: Path,
ann_dir: Path):
"""验证提取的数据是否有效
Args:
X: 特征矩阵
y: 标签数组
data_type: 数据类型名称
img_dir: 图像目录
ann_dir: 标注目录
Raises:
RuntimeError: 如果数据无效
"""
if X is None or y is None or len(X) == 0 or len(y) == 0:
error_msg = f"\n❌ 错误:没有提取到{data_type}数据!\n"
error_msg += f" 请检查:\n"
error_msg += f" 1. {data_type}图片目录是否存在且包含图片: {img_dir}\n"
error_msg += f" 2. 标注目录是否存在且包含标注文件: {ann_dir}\n"
error_msg += f" 3. 图片和标注文件的格式是否正确"
raise RuntimeError(error_msg)
print(f"\n✅ 成功提取{data_type}特征: {len(X)} 个样本")
def main():
"""主函数:协调整个训练流程"""
# 1. 解析参数和设置环境
args = parse_arguments()
setup_environment(args)
print_header(args)
# 2. 验证数据路径
data_root = Path(args.data_root)
train_img_dir, train_ann_dir, test_img_dir, test_ann_dir = validate_data_paths(data_root)
# 3. 加载DINOv3模型
dinov3_model = load_dinov3_model(
model_name=args.dinov3_model,
weights_path=args.dinov3_weights,
device=args.device,
local_repo=args.local_repo
)
# 4. 提取训练集特征
X_train, y_train = extract_dataset_features(
dinov3_model,
train_img_dir,
train_ann_dir,
split='train',
device=args.device,
max_samples=args.max_samples
)
validate_extracted_data(X_train, y_train, '训练', train_img_dir, train_ann_dir)
# 5. 提取验证集特征(如果存在)
X_val, y_val = None, None
if test_img_dir != train_img_dir:
X_val, y_val = extract_dataset_features(
dinov3_model,
test_img_dir,
test_ann_dir,
split='test',
device=args.device,
max_samples=args.max_samples
)
if X_val is not None and len(X_val) > 0:
print(f"✅ 成功提取验证特征: {len(X_val)} 个样本")
# 6. 平衡训练数据
balance_method = None if args.balance_method == 'none' else args.balance_method
if balance_method:
print(f"\n⚖️ 应用数据平衡方法: {balance_method}")
X_train, y_train = balance_dataset(
X_train, y_train,
method=balance_method,
random_state=args.random_seed
)
# 7. 保存特征
output_dir = Path(args.output_dir)
save_features(output_dir, X_train, y_train, X_val, y_val, args.balance_method)
# 8. 训练随机森林
rf_classifier = train_random_forest(
X_train, y_train,
n_estimators=args.n_estimators,
max_depth=args.max_depth,
random_state=args.random_seed
)
# 9. 评估模型
evaluate_model(rf_classifier, X_train, y_train, split_name="训练集")
if X_val is not None and y_val is not None:
evaluate_model(rf_classifier, X_val, y_val, split_name="验证集")
# 10. 保存模型和配置
save_model(rf_classifier, output_dir)
save_config(output_dir, args)
# 11. 打印完成信息
print("\n" + "="*80)
print("训练完成!")
print(f"模型保存在: {output_dir}")
print("="*80)
if __name__ == '__main__':
main()4.2 运行训练
python3 demo/bccd_rf_train.py \
--data_root ./BCCD_Dataset \
--output_dir output/bccd_rf_model \
--dinov3_model dinov3_vits16 \
--n_estimators 200 \
--max_depth 30 \
--balance_method oversample \
--device cuda4.3 训练输出
训练过程会输出详细的统计信息:
================================================================================
血细胞分类训练 - DINOv3特征 + 随机森林分类器
================================================================================
数据集: ./BCCD_Dataset
DINOv3模型: dinov3_vits16
随机森林参数: n_estimators=200, max_depth=30
数据平衡方法: oversample
输出目录: output/bccd_rf_model
设备: cuda
================================================================================
注意: 使用训练集作为验证集
📦 加载DINOv3模型: dinov3_vits16
📂 使用本地仓库: /data/william/Workspace/dinov3
✓ DINOv3模型加载完成
📊 提取train集特征...
处理train集: 100%|█████████████████████████████████████████████████████████████████████| 364/364 [00:16<00:00, 21.89it/s]
✓ 提取完成: 4888 个样本
特征维度: (4888, 384)
类别分布: {'Platelets': np.int64(361), 'RBC': np.int64(4155), 'WBC': np.int64(372)}
✅ 成功提取训练特征: 4888 个样本
⚖️ 应用数据平衡方法: oversample
⚖️ 平衡数据集 (方法: oversample)
原始分布: {np.int64(0): np.int64(361), np.int64(1): np.int64(4155), np.int64(2): np.int64(372)}
平衡后分布: {np.int64(0): np.int64(4155), np.int64(1): np.int64(4155), np.int64(2): np.int64(4155)}
总样本: 12465 (原始: 4888)
💾 保存特征到: output/bccd_rf_model/features.pkl
🌲 训练随机森林分类器...
参数: n_estimators=200, max_depth=30
[Parallel(n_jobs=-1)]: Using backend ThreadingBackend with 32 concurrent workers.
[Parallel(n_jobs=-1)]: Done 136 tasks | elapsed: 0.3s
[Parallel(n_jobs=-1)]: Done 200 out of 200 | elapsed: 0.3s finished
✓ 训练完成 (用时: 0.36秒)
特征重要性统计:
平均重要性: 0.002604
最大重要性: 0.032672
最小重要性: 0.000050
📈 评估训练集...
[Parallel(n_jobs=32)]: Using backend ThreadingBackend with 32 concurrent workers.
[Parallel(n_jobs=32)]: Done 136 tasks | elapsed: 0.0s
[Parallel(n_jobs=32)]: Done 200 out of 200 | elapsed: 0.0s finished
训练集准确率: 0.9999
[Parallel(n_jobs=32)]: Using backend ThreadingBackend with 32 concurrent workers.
[Parallel(n_jobs=32)]: Done 136 tasks | elapsed: 0.0s
[Parallel(n_jobs=32)]: Done 200 out of 200 | elapsed: 0.0s finished
训练集分类报告:
precision recall f1-score support
Platelets 1.00 1.00 1.00 4155
RBC 1.00 1.00 1.00 4155
WBC 1.00 1.00 1.00 4155
accuracy 1.00 12465
macro avg 1.00 1.00 1.00 12465
weighted avg 1.00 1.00 1.00 12465
训练集混淆矩阵:
[[4155 0 0]
[ 0 4154 1]
[ 0 0 4155]]
💾 保存随机森林模型到: output/bccd_rf_model/rf_classifier.pkl
💾 保存配置到: output/bccd_rf_model/config.pkl
================================================================================
训练完成!
模型保存在: output/bccd_rf_model
================================================================================5. 推理部署
5.1 两种推理模式
推理脚本 bccd_rf_inference.py 其支持两种模式:
5.1.1 标注框分类模式
使用已有的标注框进行分类,适用于模型评估:
python3 demo/bccd_rf_inference.py \
--image ./BCCD_Dataset/BCCD/JPEGImages/BloodImage_00000.jpg \
--xml ./BCCD_Dataset/BCCD/Annotations/BloodImage_00000.xml \
--model_dir output/bccd_rf_model \
--output result_annotation.png输出为:
python3 demo/bccd_rf_inference.py \
--image ./BCCD_Dataset/BCCD/JPEGImages/BloodImage_00000.jpg \
--xml ./BCCD_Dataset/BCCD/Annotations/BloodImage_00000.xml \
--model_dir output/bccd_rf_model \
--output result_annotation.png
================================================================================
血细胞分类推理 - DINOv3特征 + 随机森林分类器
================================================================================
📦 加载配置: output/bccd_rf_model/config.pkl
📦 加载随机森林模型: output/bccd_rf_model/rf_classifier.pkl
📦 加载DINOv3模型: dinov3_vits16
📂 使用本地仓库: /data/william/Workspace/dinov3
✓ DINOv3模型加载完成
模式: 使用标注框进行分类
图像: BCCD_Dataset/BCCD/JPEGImages/BloodImage_00000.jpg
标注: BCCD_Dataset/BCCD/Annotations/BloodImage_00000.xml
结果统计:
总数: 20
正确: 19
准确率: 95.00%
各类别准确率:
RBC: 19/19 = 100.00%
WBC: 0/1 = 0.00%
✓ 结果保存到: result_annotation.png
================================================================================
推理完成!
================================================================================5.1.2 滑动窗口检测模式
使用滑动窗口进行完整的目标检测:
python3 demo/bccd_rf_inference.py \
--image ./BCCD_Dataset/BCCD/JPEGImages/BloodImage_00000.jpg \
--model_dir output/bccd_rf_model \
--output result_detection.png \
--conf_threshold 0.7 \
--nms_threshold 0.3这种方式挺慢的。
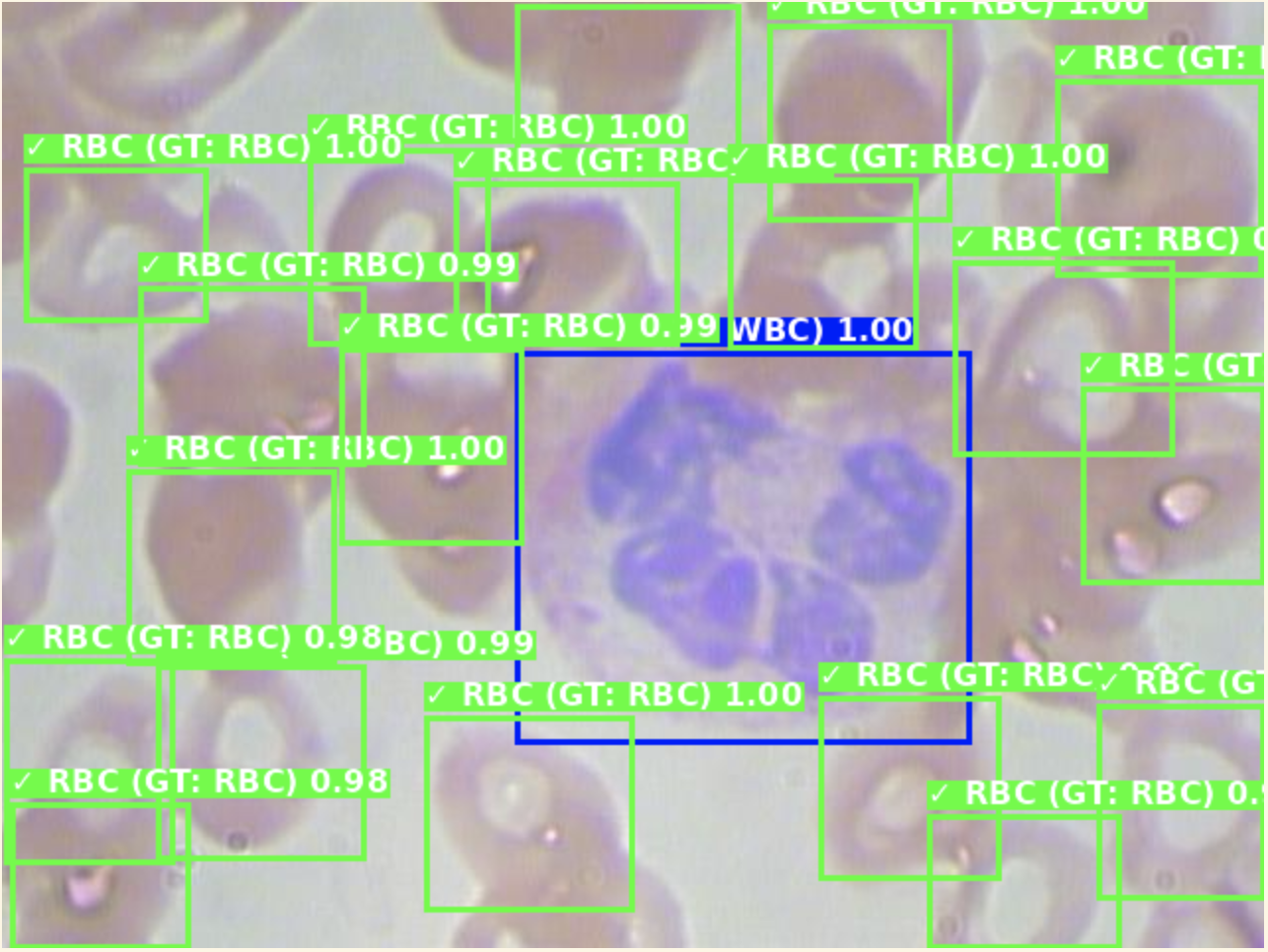
5.2 可视化结果
检测结果的可视化包括:
- 不同颜色表示不同类别(红色-血小板,绿色-红细胞,蓝色-白细胞)
- 边界框绘制
- 置信度分数显示
- 真实标签对比(评估模式)
结语
本文详细介绍了基于DINOv3的目标检测方法,通过血细胞分类的实际案例展示了从数据准备到模型部署的完整流程。这种方法特别适合小数据集和需要快速部署的场景,为计算机视觉应用提供了一个简单而有效的解决方案。
通过结合强大的DINOv3特征提取能力和灵活的随机森林分类器,我们实现了一个既简单又有效的目标检测系统。希望这篇文章能够帮助读者理解并应用DINOv3进行实际的目标检测任务。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
