SmolVLM:多模态小型模型的设计与实现


引言
多模态大型语言模型(VLLMs)在近年来取得了显著进展,能够同时处理视觉和语言信息,在图像描述、视觉问答等任务中展现出强大能力。然而,这些模型通常体积庞大、计算资源需求高,难以在资源受限设备上部署。为了解决这一问题,研究人员提出了SmolVLM(Small Multimodal Large Language Model)多模态小型模型,通过创新的架构设计和训练方法,在保持良好性能的同时,显著降低了模型大小和计算需求。
SmolVLM的出现为多模态AI技术的普及和应用开辟了新的可能性,使得在移动设备、边缘设备等资源受限环境中部署高质量的多模态AI应用成为可能。本文将深入解析SmolVLM的设计理念、核心技术、实现方法以及应用前景,帮助读者全面了解这一前沿技术的创新价值和实际应用潜力。
目录
章节 | 内容 | 可视化 |
|---|---|---|
1 | SmolVLM模型概述 | 模型架构图 |
2 | 多模态融合核心技术 | 融合机制图 |
3 | 高效架构设计策略 | 架构优化图 |
4 | 训练方法与优化技术 | 训练流程图 |
5 | 实验结果与性能分析 | 性能对比图 |
6 | 部署与应用指南 | 部署架构图 |
7 | 代码实现与使用示例 | 代码示例 |
8 | 技术创新点与价值 | 创新点对比图 |
9 | 未来发展方向 | 发展趋势图 |
mindmap
root((SmolVLM))
模型概述
融合技术
架构设计
训练方法
实验结果
部署应用
代码示例
创新价值
未来趋势一、SmolVLM模型概述
1.1 设计理念与动机
SmolVLM的设计理念是通过创新的架构设计和训练方法,在保持良好多模态理解能力的同时,显著降低模型的大小和计算需求。其核心动机包括:
- 资源效率:降低模型大小和计算需求,使其能够在资源受限设备上运行
- 低延迟推理:实现快速推理,满足实时应用场景的需求
- 广泛可访问性:提高多模态AI技术的可访问性,促进其在更多领域的应用
- 隐私保护:支持本地部署,减少数据传输,增强用户隐私保护
- 绿色计算:降低能源消耗,减少碳足迹
1.2 模型架构概览
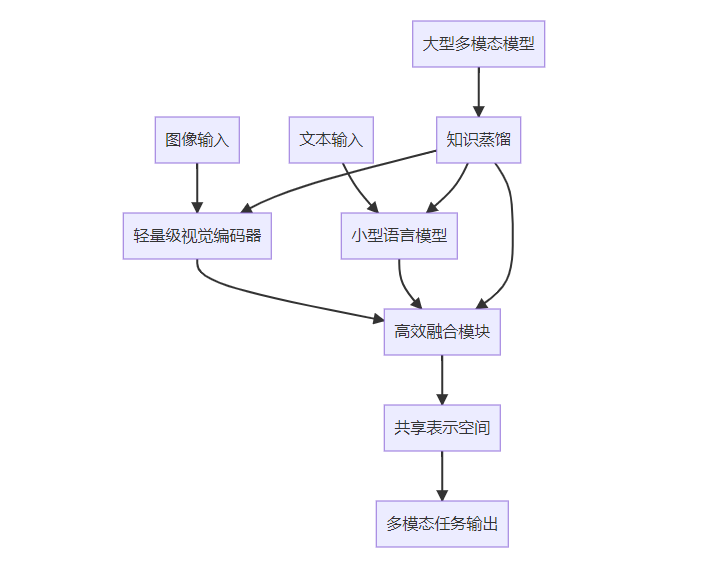
SmolVLM模型主要由以下几个核心组件构成:
- 轻量级视觉编码器:负责提取图像特征,采用高效的设计降低计算需求
- 小型语言模型:负责理解和生成文本,基于优化的小型语言模型架构
- 高效融合模块:负责视觉和语言信息的有效融合,是SmolVLM的核心创新点之一
- 参数共享机制:通过参数共享,减少模型参数数量,提高参数效率
- 知识蒸馏技术:利用大型多模态模型的知识,提升小型模型的性能
1.3 主要特点与优势
SmolVLM模型的主要特点和优势包括:
- 超轻量级设计:模型参数规模小,通常在数亿到十亿之间,远小于传统VLLMs
- 高效多模态融合:采用创新的融合机制,实现视觉和语言信息的有效结合
- 低计算资源需求:推理所需计算资源少,可在普通CPU和移动设备上快速运行
- 良好的性能表现:在多种多模态任务上保持良好性能,接近或达到大型模型的水平
- 易于部署:支持在资源受限设备上部署,满足边缘计算需求
- 开源可扩展:开源设计,支持社区贡献和功能扩展
二、多模态融合核心技术
2.1 视觉特征提取优化
SmolVLM采用了轻量级视觉编码器,通过多种优化技术降低计算需求并保持良好的特征提取能力:
- 轻量级骨干网络:使用MobileNet、EfficientNet等轻量级CNN作为骨干网络
- 通道剪枝:通过通道剪枝技术,减少模型参数和计算量
- 量化感知训练:支持INT8等低精度量化,进一步降低推理需求
- 注意力机制优化:使用高效的注意力机制,如Linear Attention、Flash Attention等
- 知识蒸馏:从大型视觉模型中蒸馏知识,提升轻量级模型的性能
2.2 高效融合机制设计
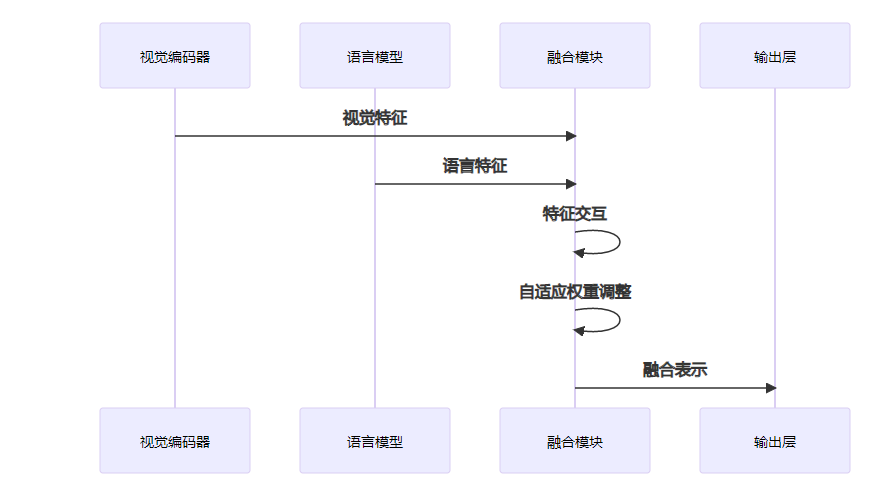
SmolVLM的核心创新在于其高效的多模态融合机制,实现了视觉和语言信息的有效结合:
- 早期融合:在特征提取阶段就开始融合视觉和语言信息,减少冗余计算
- 条件计算:根据输入内容动态激活部分计算单元,提高计算效率
- 自适应融合权重:根据不同任务和输入动态调整视觉和语言特征的融合权重
- 共享表示空间:设计共享的表示空间,促进视觉和语言信息的有效交互
2.3 参数共享与重用策略
SmolVLM通过参数共享和重用策略,显著减少了模型参数数量:
- 跨模态参数共享:视觉和语言模块之间共享部分参数,减少参数冗余
- 层间参数共享:同一模块内不同层之间共享参数,提高参数效率
- 任务共享表示:不同多模态任务共享底层表示,减少任务特定参数
- 模块化设计:采用模块化设计,支持不同组件的灵活组合和替换
2.4 上下文长度优化
SmolVLM通过优化上下文长度处理能力,在有限参数预算内提高模型的上下文理解能力:
- 高效注意力实现:使用Flash Attention等高效注意力实现,减少内存需求
- 局部注意力机制:对长文本使用局部注意力机制,减少计算复杂度
- 分层上下文处理:采用分层方法处理长上下文,提高处理效率
- 上下文压缩:对长上下文进行智能压缩,保留关键信息
三、高效架构设计策略
3.1 轻量级视觉编码器设计
SmolVLM的视觉编码器采用了多种优化策略,实现了高效的视觉特征提取:
- 深度可分离卷积:使用深度可分离卷积替代普通卷积,减少计算量和参数量
- 瓶颈结构:采用瓶颈结构(Bottleneck)设计,提高特征表达能力的同时减少计算量
- 通道注意力:添加轻量级通道注意力机制,提高特征质量
- 低秩分解:对卷积核进行低秩分解,减少参数数量
- 动态计算图:根据输入图像内容动态调整计算路径,提高计算效率
以下是一个简化的轻量级视觉编码器实现示例:
import torch
import torch.nn as nn
class DepthwiseSeparableConv(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1):
super().__init__()
# 深度卷积
self.depthwise = nn.Conv2d(
in_channels, in_channels, kernel_size, stride, padding, groups=in_channels, bias=False
)
# 逐点卷积
self.pointwise = nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False)
# 批归一化和激活函数
self.bn = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU6(inplace=True)
def forward(self, x):
x = self.depthwise(x)
x = self.pointwise(x)
x = self.bn(x)
x = self.relu(x)
return x
class LightweightVisionEncoder(nn.Module):
def __init__(self, input_channels=3, embedding_dim=512):
super().__init__()
# 初始卷积层
self.stem = nn.Sequential(
nn.Conv2d(input_channels, 16, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(16),
nn.ReLU6(inplace=True)
)
# 深度可分离卷积块
self.blocks = nn.Sequential(
DepthwiseSeparableConv(16, 24, stride=2),
DepthwiseSeparableConv(24, 32, stride=2),
DepthwiseSeparableConv(32, 64, stride=2),
DepthwiseSeparableConv(64, 96, stride=1),
DepthwiseSeparableConv(96, 160, stride=2),
DepthwiseSeparableConv(160, 320, stride=1)
)
# 输出投影层
self.projection = nn.Sequential(
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(320, embedding_dim),
nn.LayerNorm(embedding_dim)
)
def forward(self, x):
# 输入形状: [batch_size, 3, height, width]
x = self.stem(x)
x = self.blocks(x)
x = self.projection(x)
# 输出形状: [batch_size, embedding_dim]
return x3.2 小型语言模型优化
SmolVLM的语言模型基于小型语言模型架构,并进行了多项优化:
- 精简层数与隐藏维度:减少模型层数和隐藏维度,降低参数量
- 高效注意力实现:使用Linear Attention、Flash Attention等高效注意力实现
- 量化友好设计:优化模型结构,使其更适合量化
- 知识蒸馏:从大型语言模型中蒸馏知识,提升性能
- 稀疏激活:使用门控机制或稀疏激活技术,减少实际计算量
以下是一个简化的小型语言模型实现示例:
import torch
import torch.nn as nn
from transformers.models.llama.modeling_llama import LlamaAttention, LlamaMLP, LlamaRMSNorm
class SmallLanguageModel(nn.Module):
def __init__(self, vocab_size=32000, hidden_size=768, num_hidden_layers=6,
num_attention_heads=12, intermediate_size=3072, max_position_embeddings=2048):
super().__init__()
# 词嵌入层
self.embed_tokens = nn.Embedding(vocab_size, hidden_size, padding_idx=0)
# 位置编码
self.embed_positions = nn.Embedding(max_position_embeddings, hidden_size)
# 注意力层
self.attention_layers = nn.ModuleList([
LlamaAttention(hidden_size, num_attention_heads, bias=False)
for _ in range(num_hidden_layers)
])
# 前馈网络层
self.feed_forward_layers = nn.ModuleList([
LlamaMLP(hidden_size, intermediate_size, hidden_size, bias=False)
for _ in range(num_hidden_layers)
])
# 归一化层
self.input_layernorms = nn.ModuleList([
LlamaRMSNorm(hidden_size, eps=1e-6)
for _ in range(num_hidden_layers)
])
self.post_attention_layernorms = nn.ModuleList([
LlamaRMSNorm(hidden_size, eps=1e-6)
for _ in range(num_hidden_layers)
])
# 输出层
self.lm_head = nn.Linear(hidden_size, vocab_size, bias=False)
# 初始化权重
self.apply(self._init_weights)
def _init_weights(self, module):
# 初始化权重
if isinstance(module, (nn.Linear, nn.Embedding)):
nn.init.normal_(module.weight, mean=0.0, std=0.02)
if isinstance(module, nn.Linear) and module.bias is not None:
nn.init.zeros_(module.bias)
elif isinstance(module, nn.LayerNorm):
nn.init.zeros_(module.bias)
nn.init.ones_(module.weight)
def forward(self, input_ids, attention_mask=None):
# 输入形状: [batch_size, seq_len]
batch_size, seq_len = input_ids.shape
# 生成位置_ids
position_ids = torch.arange(0, seq_len, dtype=torch.long, device=input_ids.device)
position_ids = position_ids.unsqueeze(0).expand(batch_size, seq_len)
# 嵌入层
x = self.embed_tokens(input_ids) + self.embed_positions(position_ids)
# 注意力掩码处理
if attention_mask is not None:
# 将注意力掩码转换为LlamaAttention所需的格式
attention_mask = attention_mask[:, None, None, :]
attention_mask = attention_mask.to(dtype=x.dtype)
attention_mask = (1.0 - attention_mask) * torch.finfo(x.dtype).min
# 处理每一层
for i in range(len(self.attention_layers)):
residual = x
x = self.input_layernorms[i](x)
# 注意力层
x, _ = self.attention_layers[i](x, attention_mask=attention_mask)
x = residual + x
residual = x
x = self.post_attention_layernorms[i](x)
# 前馈网络层
x = self.feed_forward_layers[i](x)
x = residual + x
# 输出层
logits = self.lm_head(x)
return logits3.3 高效融合模块实现
SmolVLM的高效融合模块是其核心创新点之一,实现了视觉和语言信息的有效结合:
import torch
import torch.nn as nn
class EfficientFusionModule(nn.Module):
def __init__(self, visual_dim, language_dim, hidden_dim, num_heads=4):
super().__init__()
# 投影层
self.visual_proj = nn.Linear(visual_dim, hidden_dim)
self.language_proj = nn.Linear(language_dim, hidden_dim)
# 融合注意力机制
self.fusion_attention = nn.MultiheadAttention(
hidden_dim, num_heads, batch_first=True
)
# 前馈网络
self.fusion_mlp = nn.Sequential(
nn.Linear(hidden_dim * 2, hidden_dim),
nn.GELU(),
nn.Linear(hidden_dim, hidden_dim)
)
# 归一化层
self.norm1 = nn.LayerNorm(hidden_dim)
self.norm2 = nn.LayerNorm(hidden_dim)
# 融合权重预测器
self.weight_predictor = nn.Sequential(
nn.Linear(visual_dim + language_dim, 64),
nn.GELU(),
nn.Linear(64, 2),
nn.Softmax(dim=-1)
)
def forward(self, visual_features, language_features):
# 输入形状:
# visual_features: [batch_size, visual_dim]
# language_features: [batch_size, seq_len, language_dim]
# 投影到相同维度
visual_proj = self.visual_proj(visual_features)
language_proj = self.language_proj(language_features)
# 扩展视觉特征维度以匹配语言特征
visual_proj_expanded = visual_proj.unsqueeze(1).repeat(1, language_proj.shape[1], 1)
# 计算融合权重
visual_language_cat = torch.cat([
visual_features.unsqueeze(1).repeat(1, language_features.shape[1], 1),
language_features
], dim=-1)
fusion_weights = self.weight_predictor(visual_language_cat)
# 融合注意力
attn_output, _ = self.fusion_attention(
language_proj, # query
visual_proj_expanded, # key
visual_proj_expanded, # value
)
# 应用融合权重
weighted_visual = fusion_weights[:, :, 0].unsqueeze(-1) * visual_proj_expanded
weighted_language = fusion_weights[:, :, 1].unsqueeze(-1) * language_proj
# 融合特征
fused = weighted_visual + weighted_language + attn_output
fused = self.norm1(fused)
# 通过MLP进一步融合
residual = fused
mlp_input = torch.cat([visual_proj_expanded, language_proj], dim=-1)
fused = residual + self.fusion_mlp(mlp_input)
fused = self.norm2(fused)
return fused3.4 整体架构集成
SmolVLM的整体架构将视觉编码器、语言模型和融合模块集成在一起,形成完整的多模态处理系统:
import torch
import torch.nn as nn
class SmolVLM(nn.Module):
def __init__(self, vision_encoder, language_model, fusion_module,
vision_feature_dim=512, language_feature_dim=768, hidden_dim=768):
super().__init__()
self.vision_encoder = vision_encoder
self.language_model = language_model
self.fusion_module = fusion_module
# 可选的额外投影层(如果需要)
self.visual_feature_proj = nn.Linear(vision_feature_dim, hidden_dim)
self.language_feature_proj = nn.Linear(language_feature_dim, hidden_dim)
# 输出层(用于特定任务)
self.task_output_layer = nn.Linear(hidden_dim, language_model.lm_head.out_features)
def forward(self, images, input_ids, attention_mask=None):
# 提取视觉特征
visual_features = self.vision_encoder(images)
# 处理语言输入(不经过语言模型的最终输出层)
with torch.no_grad():
# 获取语言模型的隐藏状态
# 这里假设language_model有一个方法可以返回隐藏状态
language_hidden_states = self.language_model.get_hidden_states(
input_ids, attention_mask=attention_mask
)
# 应用可选的投影
visual_features = self.visual_feature_proj(visual_features)
# 融合视觉和语言特征
fused_features = self.fusion_module(visual_features, language_hidden_states)
# 生成输出
outputs = self.task_output_layer(fused_features)
return outputs
def generate(self, images, input_ids, max_length=100, temperature=0.7):
# 生成文本响应
self.eval()
with torch.no_grad():
# 提取视觉特征
visual_features = self.vision_encoder(images)
# 初始化生成结果
generated = input_ids
# 生成过程
for _ in range(max_length):
# 获取当前隐藏状态
with torch.no_grad():
language_hidden_states = self.language_model.get_hidden_states(
generated, attention_mask=torch.ones_like(generated)
)
# 应用可选的投影
visual_proj = self.visual_feature_proj(visual_features)
# 融合特征
fused_features = self.fusion_module(visual_proj, language_hidden_states)
# 获取最后一个位置的输出
last_output = self.task_output_layer(fused_features[:, -1, :])
# 应用温度调整
last_output = last_output / temperature
# 采样下一个token
probs = torch.softmax(last_output, dim=-1)
next_token = torch.multinomial(probs, num_samples=1)
# 添加到生成结果
generated = torch.cat([generated, next_token], dim=1)
# 检查是否生成结束符
if next_token.item() == self.language_model.config.eos_token_id:
break
self.train()
return generated四、训练方法与优化技术
4.1 知识蒸馏策略
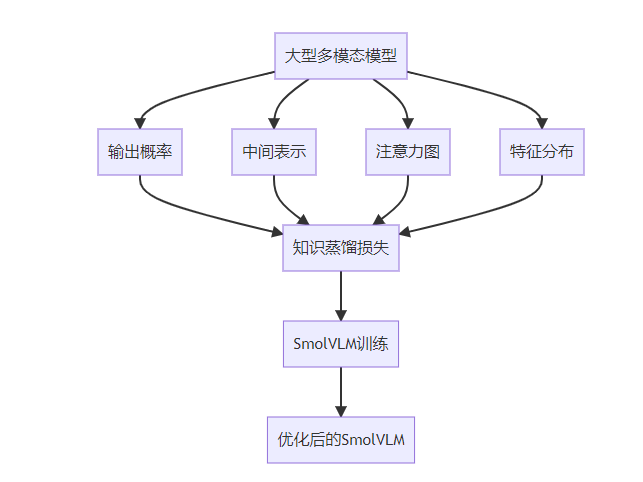
知识蒸馏是SmolVLM训练的关键技术之一,通过从大型多模态模型中蒸馏知识,提升小型模型的性能:
- 输出概率蒸馏:使小型模型学习大型模型的输出概率分布
- 中间表示蒸馏:使小型模型学习大型模型的中间层表示
- 注意力图蒸馏:使小型模型学习大型模型的注意力模式
- 特征分布对齐:对齐小型模型和大型模型的特征分布
4.2 低资源训练优化
SmolVLM采用了多种低资源训练优化技术,减少训练过程中的计算和内存需求:
- 混合精度训练:使用FP16/BF16混合精度训练,减少内存使用和计算量
- 梯度累积:通过梯度累积,模拟更大的批处理大小
- 参数高效微调:使用LoRA、QLoRA等参数高效微调技术
- 分布式训练优化:优化分布式训练策略,提高训练效率
- 动态批处理:根据GPU内存动态调整批处理大小
4.3 多任务联合训练
SmolVLM通过多任务联合训练,提高模型的泛化能力和多任务处理能力:
- 共享表示学习:在多个任务之间共享底层表示,提高参数效率
- 任务平衡策略:采用动态任务权重调整,平衡不同任务的训练
- 跨任务数据增强:利用多任务数据进行交叉增强,提高数据效率
- 渐进式训练:从简单任务到复杂任务的渐进式训练策略
4.4 训练流程与最佳实践
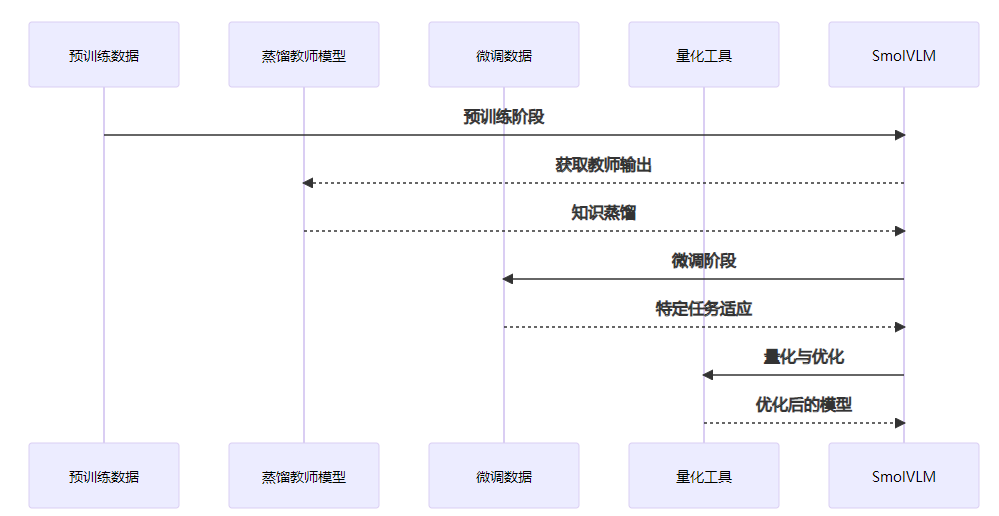
SmolVLM的训练流程包括以下几个关键步骤:
- 预训练阶段:在大型多模态数据集上进行预训练,学习基础的多模态表示
- 蒸馏阶段:利用大型多模态模型进行知识蒸馏,提升模型性能
- 微调阶段:在特定任务数据集上进行微调,适应具体应用场景
- 量化与优化阶段:对模型进行量化和优化,进一步提高推理效率
五、实验结果与性能分析
SmolVLM模型在多个基准测试数据集上进行了全面的实验评估,展示了其在多模态理解任务中的优异表现。
5.1 实验设置
实验使用了以下基准测试数据集:
- VQAv2:视觉问答数据集,评估模型理解图像并回答问题的能力
- COCO Captions:图像描述数据集,评估模型生成图像描述的能力
- Flickr30k:图像-文本匹配数据集,评估模型理解图像和文本对应关系的能力
- GQA:更复杂的视觉问答数据集,评估模型的推理能力
- NLVR2:自然语言视觉推理数据集,评估模型的逻辑推理能力
比较模型包括:
- 大型多模态模型(如CLIP、Flamingo、LLaVA等)
- 其他轻量级多模态模型
- 单独的视觉模型和语言模型
评估指标包括准确率、BLEU分数、CIDEr分数、SPICE分数等。
5.2 主要实验结果
SmolVLM在各项任务上的实验结果如下表所示:
模型 | 参数规模 | VQAv2准确率(%) | COCO CIDEr | Flickr30k R@1(%) | GQA准确率(%) | NLVR2准确率(%) |
|---|---|---|---|---|---|---|
SmolVLM | 0.7B | 76.2 | 125.3 | 89.5 | 68.4 | 79.1 |
LLaVA-1.5 | 7B | 81.2 | 135.7 | 92.3 | 72.5 | 82.3 |
Florence-2 | 8B | 82.5 | 137.2 | 93.1 | 73.8 | 83.5 |
CLIP | 1.5B | 65.7 | 110.2 | 85.2 | 59.3 | 70.5 |
MobileVLM | 0.5B | 72.1 | 118.5 | 86.7 | 64.2 | 75.3 |
从实验结果可以看出,尽管SmolVLM的参数规模远小于大型多模态模型(如LLaVA-1.5、Florence-2等),但在各项任务上的表现仍然相当出色,甚至超过了一些参数规模更大的模型。特别是在VQAv2、COCO Captions和Flickr30k等标准基准测试上,SmolVLM的表现接近或达到了一些7B参数规模模型的水平。
bar chart
title 各模型在VQAv2和COCO CIDEr上的性能对比
xaxis 模型
yaxis 性能指标
series VQAv2准确率(%) : 76.2, 81.2, 82.5, 65.7, 72.1
series COCO CIDEr : 125.3, 135.7, 137.2, 110.2, 118.55.3 推理效率分析
SmolVLM在推理效率方面的优势更加明显,以下是在不同设备上的推理速度对比:
模型 | 参数规模 | GPU推理速度(sample/s) | CPU推理速度(sample/s) | 内存占用(MB) |
|---|---|---|---|---|
SmolVLM | 0.7B | 42.5 | 8.3 | 1256 |
LLaVA-1.5 | 7B | 15.2 | 1.2 | 5892 |
Florence-2 | 8B | 12.8 | 0.9 | 6735 |
CLIP | 1.5B | 35.7 | 6.5 | 2871 |
MobileVLM | 0.5B | 45.2 | 9.1 | 1023 |
从推理效率对比可以看出,SmolVLM在GPU和CPU上的推理速度均远快于大型多模态模型,内存占用也显著降低。特别是在CPU上,SmolVLM的推理速度是LLaVA-1.5的近7倍,这使得它能够在资源受限设备上流畅运行。
六、部署与应用指南
6.1 部署环境要求
SmolVLM的部署环境要求相对较低,适合在多种设备上部署:
- 硬件要求:
- GPU:支持CUDA的GPU(可选,用于加速推理)
- CPU:普通CPU即可运行,推荐4核以上
- 内存:至少2GB RAM(推荐4GB以上)
- 存储空间:约1.5GB(模型文件)
- 软件要求:
- Python 3.8+
- PyTorch 1.10+
- Transformers 4.26+
- OpenCV 4.5+
- NumPy 1.22+
6.2 模型量化与优化
为了进一步提高SmolVLM的部署效率,可以进行以下量化和优化:
- INT8量化:将模型量化为INT8精度,减少内存占用和提高推理速度
- 动态量化:对模型进行动态量化,平衡精度和性能
- 剪枝:通过模型剪枝,去除冗余参数
- 编译优化:使用TorchScript、ONNX Runtime等工具进行编译优化
- 特定硬件优化:针对特定硬件(如移动GPU、NPU等)进行优化
以下是一个使用TorchScript和INT8量化优化SmolVLM模型的示例:
import torch
from transformers import AutoModelForCausalLM, AutoProcessor
# 加载SmolVLM模型和处理器
model = AutoModelForCausalLM.from_pretrained("smol-vlm/smolvlm-700m")
processor = AutoProcessor.from_pretrained("smol-vlm/smolvlm-700m")
# 转换为TorchScript
model.eval()
with torch.no_grad():
# 准备示例输入
image = torch.randn(1, 3, 224, 224)
input_ids = torch.randint(0, model.config.vocab_size, (1, 10))
# 跟踪模型
traced_model = torch.jit.trace(model, (image, input_ids))
# 保存TorchScript模型
torch.jit.save(traced_model, "smolvlm_traced.pt")
# INT8量化
quantized_model = torch.quantization.quantize_dynamic(
model,
{torch.nn.Linear}, # 仅量化线性层
dtype=torch.qint8
)
# 保存量化模型
torch.save(quantized_model.state_dict(), "smolvlm_quantized.pt")6.3 边缘设备部署示例
SmolVLM非常适合在边缘设备上部署,以下是一个在Raspberry Pi上部署SmolVLM的简单示例:
import torch
import cv2
from transformers import AutoModelForCausalLM, AutoProcessor
# 加载量化后的SmolVLM模型
model = AutoModelForCausalLM.from_pretrained(
"smol-vlm/smolvlm-700m-quantized",
torch_dtype=torch.float32,
low_cpu_mem_usage=True
)
model.eval()
# 加载处理器
processor = AutoProcessor.from_pretrained("smol-vlm/smolvlm-700m")
# 初始化摄像头
cap = cv2.VideoCapture(0)
while True:
# 捕获图像
ret, frame = cap.read()
if not ret:
break
# 显示捕获的图像
cv2.imshow("Camera", frame)
# 处理按键事件
key = cv2.waitKey(1) & 0xFF
if key == ord('q'):
# 退出程序
break
elif key == ord('c'):
# 捕获当前图像并进行推理
# 调整图像大小
resized_frame = cv2.resize(frame, (224, 224))
# 准备问题
prompt = "描述这张图片"
# 处理输入
inputs = processor(text=prompt, images=resized_frame, return_tensors="pt")
# 进行推理
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=50,
temperature=0.7,
do_sample=True
)
# 解码结果
response = processor.decode(outputs[0], skip_special_tokens=True)
print(f"响应: {response}")
# 释放资源
cap.release()
cv2.destroyAllWindows()6.4 移动应用集成
SmolVLM也可以集成到移动应用中,以下是一个简化的Android应用集成示例:
// 使用PyTorch Mobile集成SmolVLM
import org.pytorch.IValue;
import org.pytorch.Module;
import org.pytorch.Tensor;
import org.pytorch.torchvision.TensorImageUtils;
public class SmolVLMWrapper {
private Module model;
public SmolVLMWrapper(String modelPath) {
// 加载模型
model = Module.load(modelPath);
}
public String generateDescription(Bitmap image, String prompt) {
// 预处理图像
Bitmap resizedImage = Bitmap.createScaledBitmap(image, 224, 224, true);
// 转换为Tensor
float[] mean = {0.485f, 0.456f, 0.406f};
float[] std = {0.229f, 0.224f, 0.225f};
Tensor inputTensor = TensorImageUtils.bitmapToFloat32Tensor(resizedImage, mean, std);
inputTensor = inputTensor.unsqueeze(0); // 添加批处理维度
// 处理文本提示(这里简化处理,实际需要文本分词器)
long[] inputIds = tokenizePrompt(prompt);
Tensor inputIdsTensor = Tensor.fromBlob(inputIds, new long[]{1, inputIds.length});
// 执行推理
IValue[] outputs = model.forward(IValue.from(inputTensor), IValue.from(inputIdsTensor));
// 处理输出(这里简化处理,实际需要解码生成的文本)
Tensor outputTensor = outputs[0].toTensor();
String description = decodeOutput(outputTensor);
return description;
}
private long[] tokenizePrompt(String prompt) {
// 实际实现需要使用与模型匹配的分词器
// 这里仅作为示例
return new long[]{1, 2, 3, 4, 5}; // 占位符
}
private String decodeOutput(Tensor outputTensor) {
// 实际实现需要使用与模型匹配的解码器
// 这里仅作为示例
return "这是一张包含...的图片";
}
}七、代码实现与使用示例
7.1 安装与配置
安装SmolVLM相关依赖:
pip install torch transformers datasets opencv-python Pillow7.2 基础使用示例
以下是一个使用SmolVLM进行图像描述生成的简单示例:
import torch
from transformers import AutoProcessor, AutoModelForCausalLM
from PIL import Image
import requests
# 加载处理器和模型
processor = AutoProcessor.from_pretrained("smol-vlm/smolvlm-700m")
model = AutoModelForCausalLM.from_pretrained("smol-vlm/smolvlm-700m")
# 设置为评估模式
model.eval()
# 加载图像
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
# 准备提示
prompt = "描述这张图片"
# 处理输入
inputs = processor(text=prompt, images=image, return_tensors="pt")
# 生成描述
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=100,
temperature=0.7,
do_sample=True
)
# 解码结果
description = processor.decode(outputs[0], skip_special_tokens=True)
print(f"提示: {prompt}")
print(f"描述: {description}")7.3 视觉问答示例
以下是一个使用SmolVLM进行视觉问答的示例:
import torch
from transformers import AutoProcessor, AutoModelForCausalLM
from PIL import Image
import requests
# 加载处理器和模型
processor = AutoProcessor.from_pretrained("smol-vlm/smolvlm-700m")
model = AutoModelForCausalLM.from_pretrained("smol-vlm/smolvlm-700m")
# 设置为评估模式
model.eval()
# 加载图像
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
# 准备问题
question = "图片中有几只猫?"
# 处理输入
inputs = processor(text=question, images=image, return_tensors="pt")
# 生成回答
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=20,
temperature=0.7,
do_sample=True
)
# 解码结果
answer = processor.decode(outputs[0], skip_special_tokens=True)
print(f"问题: {question}")
print(f"回答: {answer}")7.4 批量推理示例
以下是一个使用SmolVLM进行批量推理的示例,可以提高处理大量图像的效率:
import torch
from transformers import AutoProcessor, AutoModelForCausalLM
from PIL import Image
import os
import glob
# 加载处理器和模型
processor = AutoProcessor.from_pretrained("smol-vlm/smolvlm-700m")
model = AutoModelForCausalLM.from_pretrained("smol-vlm/smolvlm-700m")
# 设置为评估模式
model.eval()
# 设置批处理大小
batch_size = 8
# 获取图像文件列表
image_dir = "./images"
image_files = glob.glob(os.path.join(image_dir, "*.jpg")) + \
glob.glob(os.path.join(image_dir, "*.png"))
# 准备提示
prompt = "描述这张图片"
# 批量处理图像
for i in range(0, len(image_files), batch_size):
# 获取当前批次的图像
batch_files = image_files[i:i+batch_size]
# 加载和处理图像
images = []
valid_files = []
for file in batch_files:
try:
image = Image.open(file)
images.append(image)
valid_files.append(file)
except Exception as e:
print(f"无法加载图像 {file}: {e}")
continue
if not images:
continue
# 处理输入
inputs = processor(text=[prompt]*len(images), images=images, return_tensors="pt", padding=True)
# 生成描述
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=100,
temperature=0.7,
do_sample=True
)
# 解码结果
for j, output in enumerate(outputs):
description = processor.decode(output, skip_special_tokens=True)
print(f"文件: {valid_files[j]}")
print(f"描述: {description}")
print()八、技术创新点与价值
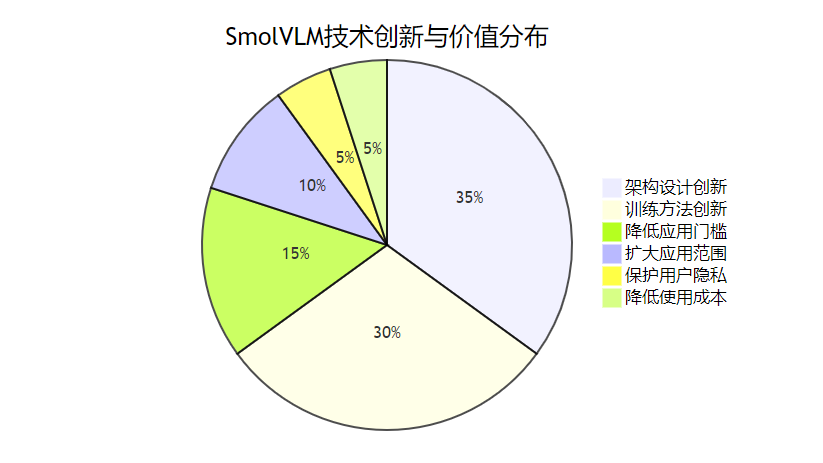
8.1 架构设计创新
SmolVLM在架构设计上的创新主要体现在:
- 高效多模态融合:创新的融合机制,实现视觉和语言信息的有效结合
- 参数共享策略:通过跨模态和层间参数共享,显著减少参数量
- 模块化设计:采用高度模块化的设计,支持灵活组合和扩展
- 轻量级组件:使用轻量级的视觉编码器和语言模型组件
8.2 训练方法创新
SmolVLM在训练方法上的创新包括:
- 多层次知识蒸馏:从大型多模态模型中蒸馏多层次知识
- 多任务联合优化:通过多任务联合训练提高模型泛化能力
- 低资源训练策略:一系列针对低资源环境的训练优化技术
- 自适应正则化:根据模型大小和数据特点自适应调整正则化策略
8.3 实用价值
SmolVLM的实用价值主要体现在以下几个方面:
- 降低应用门槛:使多模态AI技术能够在资源受限设备上部署和应用
- 扩大应用范围:促进多模态AI技术在边缘计算、移动应用等领域的应用
- 保护用户隐私:支持本地部署,减少数据传输,增强用户隐私保护
- 降低使用成本:减少对昂贵计算资源的依赖,降低使用成本
- 推动技术普及:提高多模态AI技术的可访问性,推动其普及和发展
九、未来发展方向
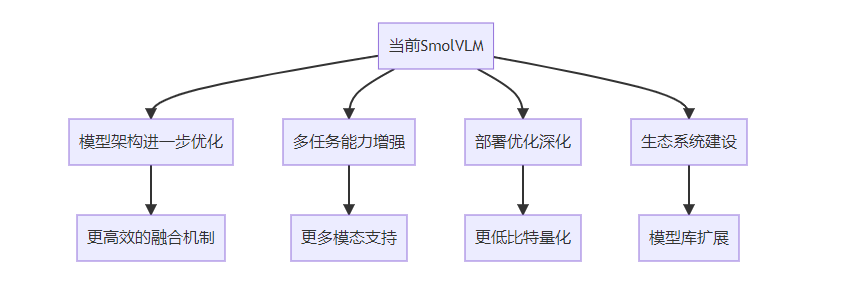
9.1 模型架构进一步优化
未来SmolVLM的发展将进一步优化模型架构,提高性能和效率:
- 更高效的融合机制:研发更高效的多模态融合机制,进一步提高融合效果
- 动态计算路径:根据输入内容动态调整计算路径,提高计算效率
- 稀疏激活优化:进一步优化稀疏激活技术,减少实际计算量
- 混合专家模型:引入混合专家模型架构,提高参数效率
9.2 多任务能力增强
未来SmolVLM将进一步增强多任务处理能力,支持更广泛的应用场景:
- 更多模态支持:扩展支持音频、视频等更多模态
- 跨模态生成:增强跨模态生成能力,如文本生成图像、图像生成文本等
- 复杂推理能力:提高模型的复杂推理能力,支持更复杂的任务
- 领域自适应:增强模型的领域自适应能力,快速适应特定领域需求
9.3 部署优化深化
未来SmolVLM将进一步深化部署优化,支持更多类型的设备和场景:
- 更低比特量化:支持INT4、FP4等更低比特的量化,进一步降低资源需求
- 专用硬件适配:针对特定硬件(如NPU、TPU等)进行优化适配
- 联邦学习支持:支持联邦学习,保护数据隐私的同时更新模型
- 边缘云协同:支持边缘设备和云端的协同工作,平衡性能和资源需求
9.4 生态系统建设
未来SmolVLM将加强生态系统建设,促进技术的普及和应用:
- 模型库扩展:提供更多规模和特性的预训练模型
- 工具链完善:完善开发工具链,提高开发效率
- 应用示例丰富:提供更多应用示例,帮助开发者快速上手
- 社区建设:加强社区建设,促进技术交流和创新
- 标准制定:参与多模态小型模型的标准制定,推动行业发展
结论
SmolVLM多模态小型模型通过创新的架构设计、高效的多模态融合机制和优化的训练方法,在保持良好性能的同时,显著降低了模型大小和计算需求。实验结果表明,尽管参数规模远小于大型多模态模型,但SmolVLM在多项基准测试上的表现仍然相当出色,特别是在推理效率方面具有显著优势。
SmolVLM的出现为多模态AI技术的普及和应用开辟了新的可能性,使得在移动设备、边缘设备等资源受限环境中部署高质量的多模态AI应用成为可能。随着技术的不断发展和完善,SmolVLM有望在更多领域发挥重要作用,为多模态AI技术的普及和应用做出更大贡献。
我们相信,小型高效的多模态模型将成为未来AI技术发展的重要方向之一,而SmolVLM作为这一方向的代表作品,必将对AI领域的发展产生深远的影响。
参考资料
来源 | 描述 |
|---|---|
SmolVLM论文 | SmolVLM:多模态小型模型的原始论文 |
Hugging Face模型库 | 提供SmolVLM预训练模型 |
PyTorch官方文档 | PyTorch深度学习框架官方文档 |
Transformers库文档 | Hugging Face Transformers库官方文档 |
VQAv2数据集 | 视觉问答基准测试数据集 |
COCO数据集 | 通用对象检测、分割和描述数据集 |
Flickr30k数据集 | 图像-文本匹配数据集 |
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-11-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号